基于殘差生成對抗網絡的調制識別算法
2022-05-23 09:15:26秦博偉齊子森
系統工程與電子技術 2022年6期
關鍵詞:信號
秦博偉, 蔣 磊, 許 華, 齊子森
(空軍工程大學信息與導航學院, 陜西 西安 710077)
0 引 言
通信信號的自動調制分類識別(automatic modulation classification, AMC)是認知無線電系統的關鍵技術之一,在非協作通信系統條件下,接收端在信號調制信息未知的情況下能否快速準確地判別接收信號的調制樣式,是后續對信號進行解調的關鍵前提。復雜電磁環境下,AMC技術在戰場偵察、信號參數估計和頻譜監測等方面都發揮重要作用。
調制識別技術發展至今,無論是基于人工設計特征的傳統方法還是基于深度學習的算法均已取得了豐碩的研究成果。傳統方法方面,文獻[3-5]通過構造不同似然函數來實現信號的調制分類,文獻[6-8]利用信號的循環譜特征來區分不同調制方式的信號,文獻[9-11]利用信號的高階累積量實現信號的調制方式識別。深度學習算法方面,文獻[12-14]分別利用卷積神經網絡(convolution neural network, CNN)和殘差網絡(residual network, Resnet)完成了對11種調制信號的分類識別,并且使用監督學習思想建立調制信號端到端的識別模型。文獻[15]將自編碼器和CNN結合,實現對數據的降維處理,一定程度上降低了算法復雜度。FAN等人提出了一種聯合噪聲估計的調制識別算法,該算法同時將原始信號數據和信噪比作為神經網絡的輸入,仿真結果表明這種算法在不同信噪比、不同頻偏下的識別準確率已經接近理論識別準確率的上限。Qi等人設計了一種多模特征匹配殘差網絡,大樣本條件下對調制信號的識別準確率在10 dB可以達到94%。文獻[18]從數據生成的角度出發,首次將生成式對抗網絡(generative adversarial networks, GAN)應用于數據的分類識別。Bu等人則將GAN引入到遷移學習中,利用GAN生成的虛假數據來訓練網絡,最后遷移到真實數據的調制樣式識別。
傳統調制識別方法依賴人工設計特征、可識別的信號種類較少、網絡泛化能力較弱;而基于深度學習的調制識別算法往往需要利用大量的標簽數據來訓練網絡、算法復雜度較高。針對上述問題,本文提出一種基于殘差GAN(Residual GAN, Res-GAN)的調制識別算法,首先生成網絡學習不同分布域數據的特征信息,通過噪聲生成高質量的虛假數據來擴充數據集;其次設計了一種由新殘差單元組成的Resnet作為判別網絡,有效提升了網絡的特征提取能力,更好地區分相似信號。實驗證明,本文提出的算法在小樣本條件下識別準確率顯著提升,模型收斂速度加快,算法復雜度明顯降低。
1 Res-GAN
1.1 網絡模型設計
網絡深度不僅決定了網絡提取信號特征的復雜性,而且會影響模型整體性能,網絡層的數量堆積可以豐富特征級別,層堆疊的方式可以獲得信號高維特征空間的參量,但是由于深層網絡反向傳播時,層數堆積的累積效應會造成梯度消失或梯度爆炸,導致深層網絡性能退化。因此需要合理選擇網絡深度使模型的整體性能達到最佳。CNN可以對信息進行較為廣泛的特征提取,而Resnet則被證實在信號的細微特征提取和改善網絡梯度訓練方面具有很好的效果,因此本文算法的網絡模型用CNN作為生成器(generator,G)網絡,用新殘差單元組成的Resnet作為判別器(discriminator,D)網絡。
為了達到網絡生成虛假數據并實現信號分類的目的,將網絡輸出層修改為兩部分:判別數據的真假屬性和類別屬性。根據G、D網絡間的邏輯關系,Res-GAN結構如圖1所示。
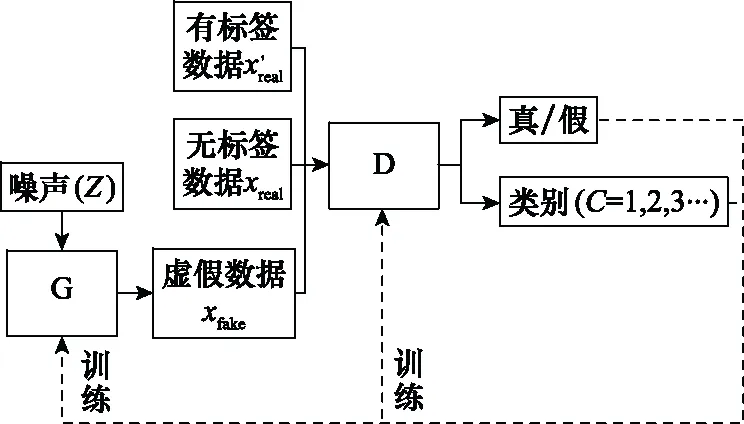
圖1 Res-GAN結構
G輸入為噪聲、輸出為虛假數據,D輸入為無標簽數據、有標簽數據和虛假數據,輸出為兩部分:真假分類器判定虛假數據與無標簽數據的相似度,類別分類器判定有標簽數據的類別屬性。通過D的輸出結果分別訓練G和D,當訓練一方時,固定另一方的參數和網絡權值,從而實現兩者之間對抗訓練、互相提高的目的。
組成D網絡的新殘差單元結構如圖2所示,利用Leakyrelu作為隱藏層激活函數并去除池化層,一方面較好地保留了初始信息量,另一方面在執行反向傳播過程中對輸入小于零的部分也可以計算得到梯度(而不是像ReLU一樣值為0),更好地實現了網絡參數和偏置項的最優化更新。Leakyrelu表達式為
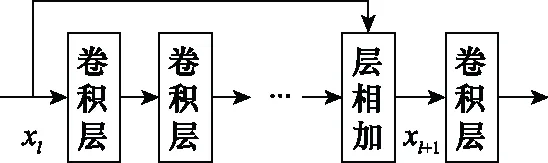
圖2 殘差單元的網絡結構
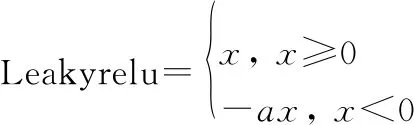
(1)
式中:表示神經網絡某一層的輸入數據;為(0,1)之間的一個常數。
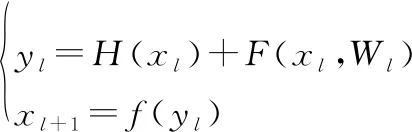
(2)
式中:代表神經網絡第層的輸入數據;代表第層的輸入數據;(·)代表直接映射;(·)代表殘差部分;(·)代表激活函數;代表卷積操作。假設本文的Resnet存在個殘差單元,則式(2)變為
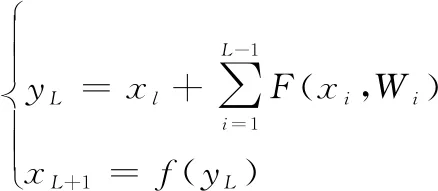
(3)
式中:=1,2,…,-1。
根據梯度下降算法中使用導數的鏈式法則,損失函數關于的梯度可以表示為
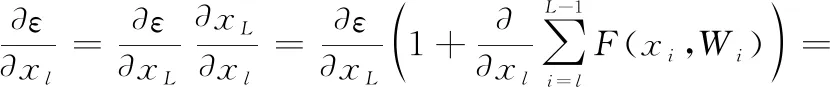
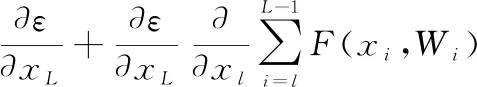
(4)
從式(4)中可以得出本文Resnet的兩個屬性:
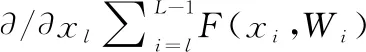
(2) ??表示層的梯度可以直接傳遞到任何一個比其淺的層。
1.2 損失函數
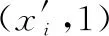
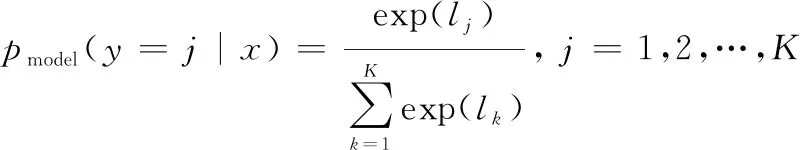
(5)
為了簡化算法復雜度,將輸出向量擴展為+1維向量,第+1維向量用來判定無標簽數據的訓練情況,由于只需要判定數據的真假性,因此第+1維向量可以被判定為前個向量中的任意一個類別,這樣本文的損失函數表達如下所示:
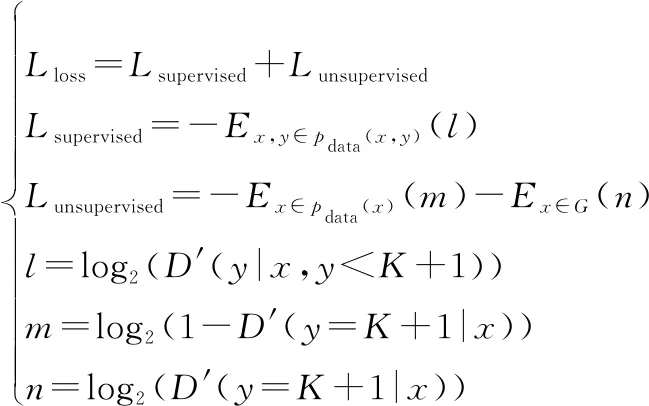
(6)
式中:和分別代表監督學習下的損失函數和無監督學習下的損失函數;′代表殘差判別器映射的可微函數;是求期望,表示標簽數據被判定為第維向量(=1,2,…,);表示無標簽數據被判定為第+1維向量;表示生成的虛假數據被判定真實數據。目標函數為最小化,假設輸入數據服從~c()分布,則目標函數為
min=
min [exp(())+exp(+1())]=
c()(=,)(?<+1)+c()()
(7)
式中:c()意為信號總是服從于同一種分布。
2 基于Res-GAN的調制識別算法
2.1 網絡參數設置
考慮到本文設定的小樣本條件,參照文獻[13]對于網絡層數的選擇標準,本文通過大量對比實驗得出G網絡選擇3層卷積結構,D網絡選擇4個殘差單元,殘差單元選擇3層卷積結構時網絡的性能最好。圖3和圖4分別為殘差單元和G、D網絡的結構參數圖。圖4中,zeropadding(·)為零填充。
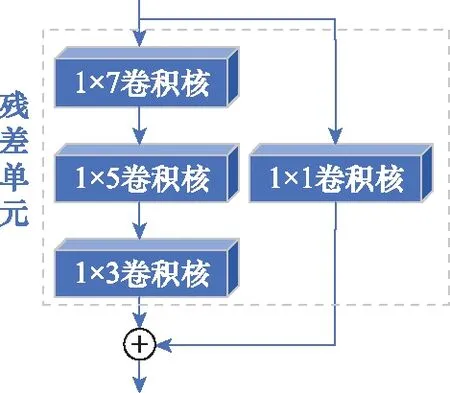
圖3 殘差單元的結構參數
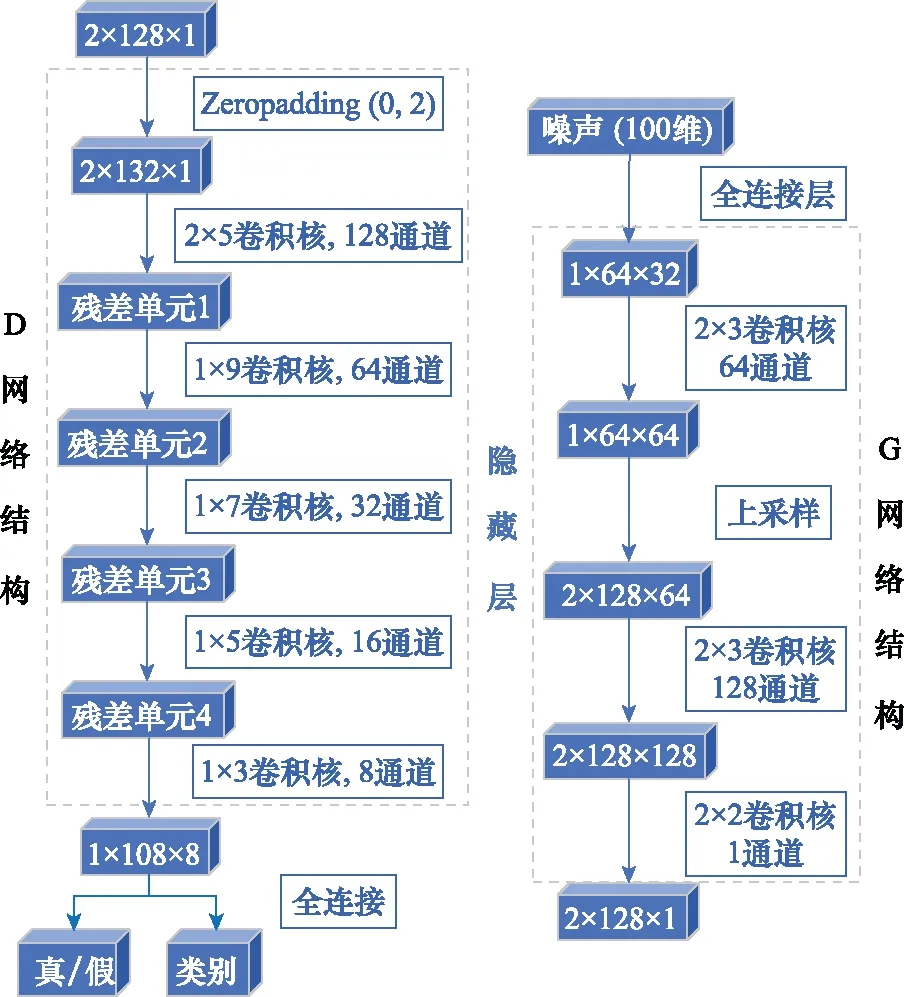
圖4 G、D網絡的結構參數
2.2 算法實現
基于Res-GAN的調制識別算法實現分為訓練和測試兩個階段,訓練階段G和D交替訓練,最終網絡的收斂結果為G生成的虛假數據與真實數據相似度最高,D則可以準確地分辨出信號的調制樣式。測試階段則是為了進一步檢驗網絡的性能。Res-GAN算法的具體步驟如下所示。

算法 1 Res-GAN算法輸入 噪聲、調制信號數據集。輸出 生成數據的真假概率、分成各個類別概率。1. 初始化2. 設置Adam,epoch,Dropout2.1 利用服從同一分布的噪聲信息生成L個100維的噪聲向量{z1,z2,…,zm}2.2 將噪聲向量通過G生成L個無標簽虛假樣本{x1,x2,…,xm}2.3 將步驟2.2中L個無標簽虛假樣本分別送入G網絡和殘差判別網絡中執行梯度下降訓練2.4 設置終止條件2.5 保存訓練好的G網絡和殘差判別網絡結構參數和網絡權重2.6 讀取m個帶標簽真實數據,通過G網絡生成等量的虛假樣本2.7 將2m個帶標簽數據送入G網絡和殘差判別網絡中,導入步驟2.5中保存的網絡繼續執行梯度下降訓練2.8 設置終止條件2.9 保存網絡模型和權重3. 輸出訓練分類結果4. 讀取q個帶標簽數據作為測試數據5. 讀取步驟2中保存的網絡模型,進行網絡測試,輸出測試結果
殘差單元和G、D網絡分別去除了批量歸一化層和池化層,添加零填充層并且采用步幅為1的非對稱遞減小卷積核,這樣選擇的理論依據如下:
(1)去除批量歸一化層和池化層可以最大限度地保留信號的原始信息。
(2)添加零填充層可以增大感受野范圍,步幅為1的非對稱卷積有助于提取邊緣特征信息。
(3)遞減小卷積核可以提取信號的不同層次特征,明顯減少網絡參數和降低算法復雜度。
3 實驗仿真與結果分析
3.1 仿真環境及數據集
本文的網絡模型訓練均使用Python的Keras環境,配置為Nvidia GTX 1650 GPU,借助Tensorflow后端進行訓練,調制信號數據集采用Deepsig公開調制識別數據集RML 2016.10b,表1為本文采用的數據集信息。調制樣式選擇10種常見的模擬調制和數字調制樣式,分別為二進制相移鍵控(binary phase shift keying, BPSK)、四進制相移鍵控(quadrature phase shift keying, QPSK)、八進制相移鍵控(8 phase shift keying, 8PSK)、高斯頻移鍵控(Gaussian frequency shift keying, GFSK)、連續相位頻移鍵控(continuous phase frequency shift keying, CPFSK)、四連續脈沖振幅調制(4-level pulse amplitude modulation, PAM4)、16種符號正交振幅調制(16 quadrature amplitude modulation, QAM16)、64種符號正交振幅調制(64 quadrature amplitude modulation, QAM64),雙邊帶調幅(amplitude modulation double side band, AM-DSB)和寬帶調頻(wide band frequency modulation, WBFW)。每種調制樣式采樣128個點并選擇I/Q兩路信號,每2 dB為一個信噪比區間。
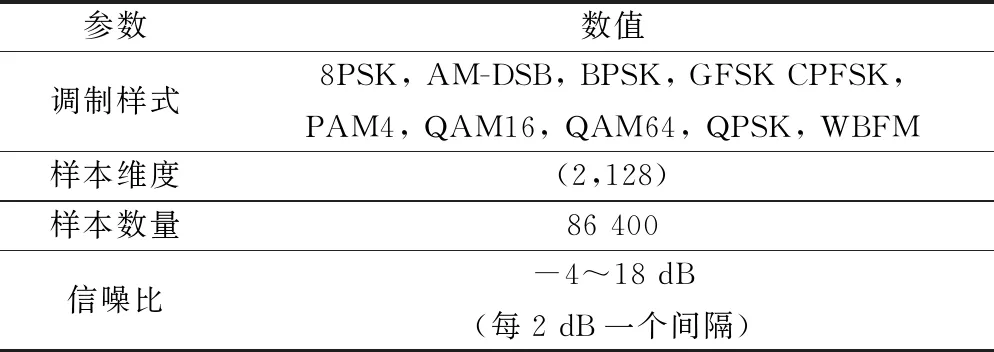
表1 調制信號數據集
3.2 實驗一:網絡初始參數設置
根據3通道原則,將數據維度由(2,128)增加為(2,128,1),因為數據集信號已經進行歸一化,所以直接利用服從(0,1)高斯分布噪聲進行擬合數據,訓練輪數設置為90個epoch。
本文通過大量實驗對比了網絡層數、不同的梯度優化算法和隱藏層激活函數對網絡性能的影響。網絡層數方面,用代表殘差單元的卷積層個數,用代表D網絡殘差單元的個數,分別對比和不同取值下的網絡性能,實驗結果如圖5所示。
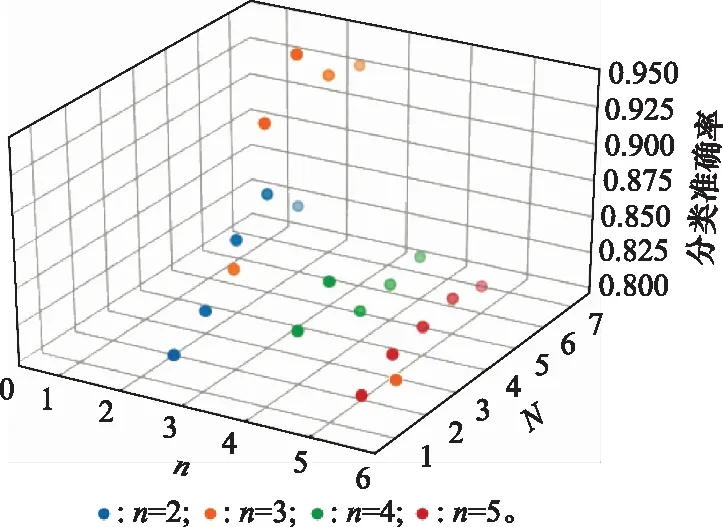
圖5 不同網絡層數結果對比
從圖5中可以得出殘差單元為3層卷積結構、D網絡選取4個殘差單元可以最大限度實現網絡模型的最優化。
為證明本文選擇的梯度下降算法的優勢,對比隨機梯度下降(stochastic gradient descent,SGD)算法、動量梯度下降(momentum gradient descent,Momentum)算法、微分加權平均(root mean square prop,RMSProp)算法和自適應估計(adaptive moment estimation,Adam)算法。不同梯度優化算法結果對比圖如6所示。
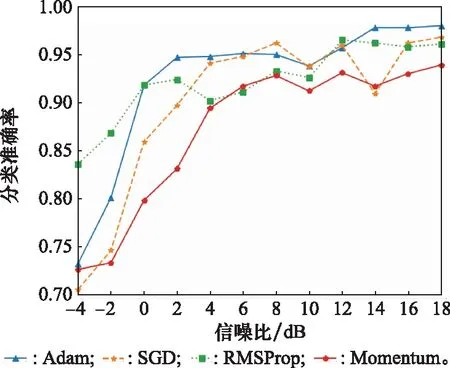
圖6 不同梯度優化算法結果對比
Adam梯度優化算法相比較于其他3種算法,低信噪比下收斂速度較快、高信噪比下穩定性強,算法適應性好。具體原因為Adam優化算法采用一階矩和二階矩分別對加權后的梯度進行誤差校正。同時由于網絡測試時使用的樣本數量較少,因此曲線會呈現非單調的波動趨勢。
當改變Adam學習率的默認設置時,發現網絡無法訓練,所以Adam學習率設置為默認值0.000 2。結合Leakyrelu表達式,分別對比取不同數值和不同激活函數下的網絡性能,實驗結果如圖7和圖8所示。
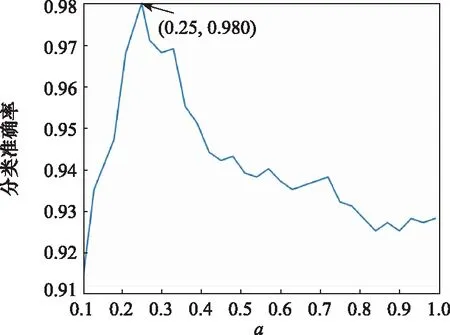
圖7 Leakyrelu不同參數下的結果
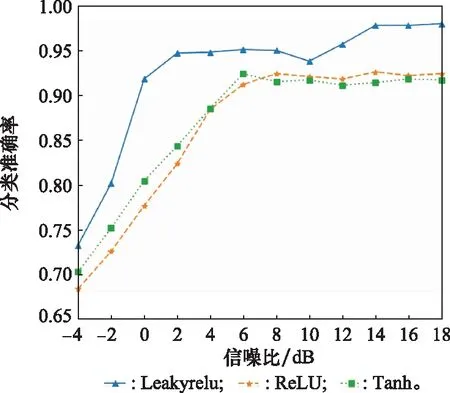
圖8 不同激活函數結果對比
結合圖7和圖8結果,Leakyrelu中參數值取0.25時網絡性能最好,相比較另外兩種激活函數收斂更快,識別準確率提升2%~4%。除此之外,在基于Adam優化算法的前提下還通過大量實驗對比了不同Batch-size、Dropout和Adam參數設置下的網絡性能,部分實驗結果如表2所示。

表2 不同參數下的網絡性能對比
綜合上述實驗結果,Res-GAN算法選擇Adam梯度優化算法(學習率設置為0.000 2,第一指數衰減率設置為0.5),激活函數選擇Leakyrelu(=0.25),Dropout設置為0.05, Batch-size設置為64。對比實驗結果,發現不同的初始化參數對模型性能還是有一定影響(準確率浮動范圍為3%~5%)。由此得出通過實驗優選網絡模型的初始化參數集合是必要的。
3.3 實驗二:調制信號分類識別
按照實驗一的網絡參數初始值設定和表1的具體算法步驟,將(-4~18 dB)信噪比下的每種信號分別隨機選取660,1 800,3 600,7 200,15 000,30 000,60 000個標簽數據(取值),取86 400,取500,將選取后的數據按照8∶1∶1比例劃分為訓練集、驗證集和測試集進行。選取模型最優化的結果,圖9為損失函數曲線,圖10為網絡測試后的混淆矩陣結果。Res-GAN算法訓練階段先訓練D網絡,從圖9(a)可以看出損失函數曲線總體保持平穩下降趨勢,在60個epoch以后驗證集已經達到收斂狀態。D網絡訓練結束后將參數固定,接著訓練G網絡,由圖9(b)的損失函數曲線看出驗證集和訓練集擬合程度較高,網絡訓練沒有出現過擬合問題。
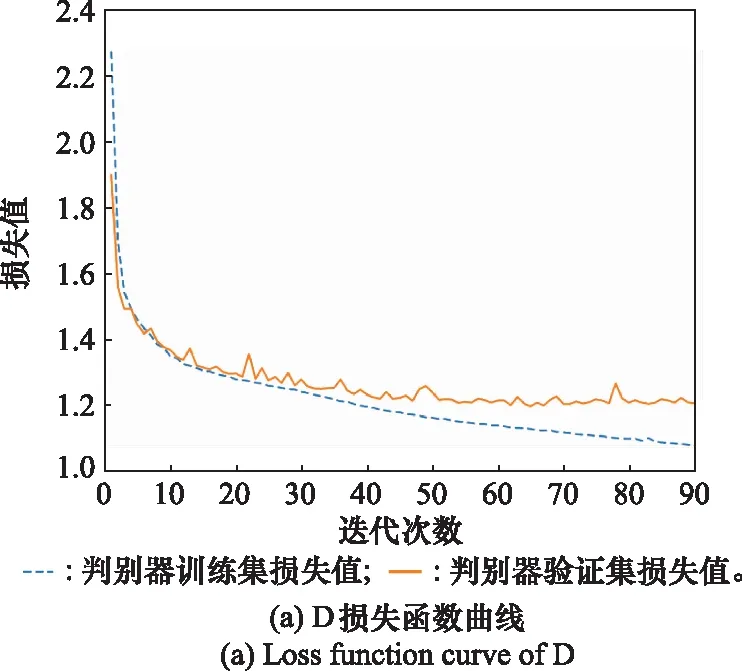
圖9 損失函數曲線
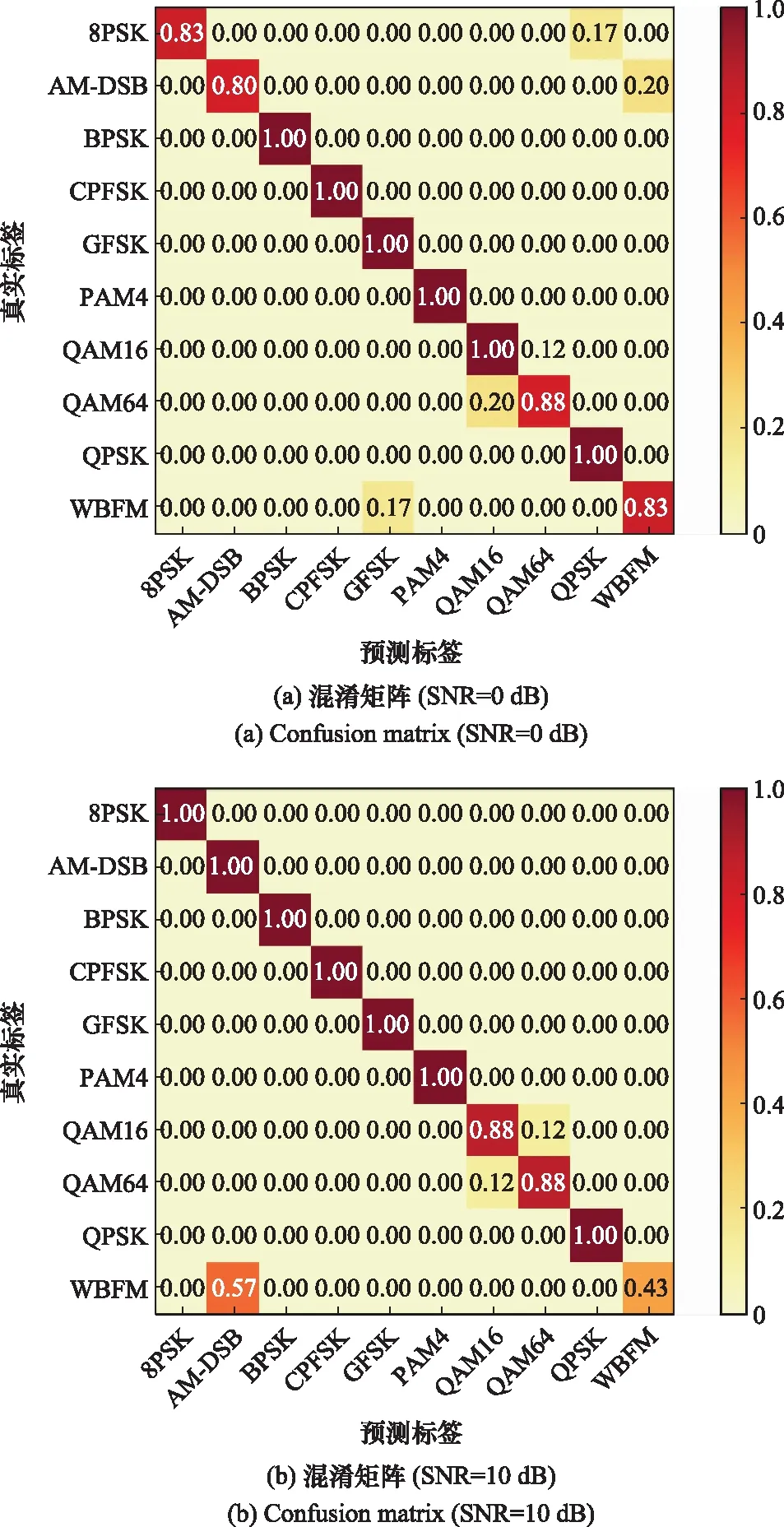
圖10 混淆矩陣結果
從網絡測試后的混淆矩陣圖可以看出,Res-GAN算法在信噪比SNR=0 dB時識別準確率可以達到91%,在SNR=18 dB時識別準確率可以達到98%。除WBFM和AM-DSB以外的信號均可以達到精準識別。由于原始數據集中兩種信號的幅值圖相似程度較高,因此會出現識別混淆的情況。
3.4 實驗三:對比實驗
為了充分說明本文設計的殘差單元可以更好地提取信號的多層維度信息,更好地區分調制信號,將Res-GAN算法分別對比文獻[14]設計的卷積長短時全連接網絡(convolutional long short-term memory fully connected deep neural networks, CLDNN)模型、文獻[15]設計的自編碼卷積神經網絡(automatic convolutional neural networks,AUCNN)模型、文獻[17]提出的多模匹配殘差融合神經網絡(residual networks with a waveform-spectrum multimodal fusion, Resnet-WSMF)算法和文獻[18]設計的輔助分類GAN(auxiliary classifier GAN, ACGAN)模型,選取5種網絡的最優化結果,圖11和表3分別為網絡分類準確率和網絡參數之間的對比。
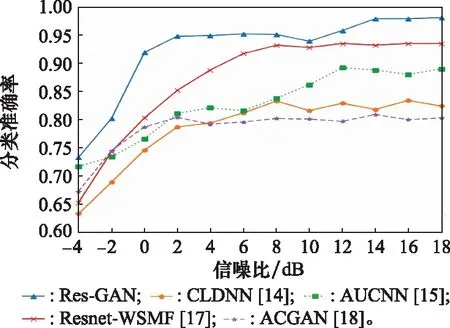
圖11 分類準確率結果對比
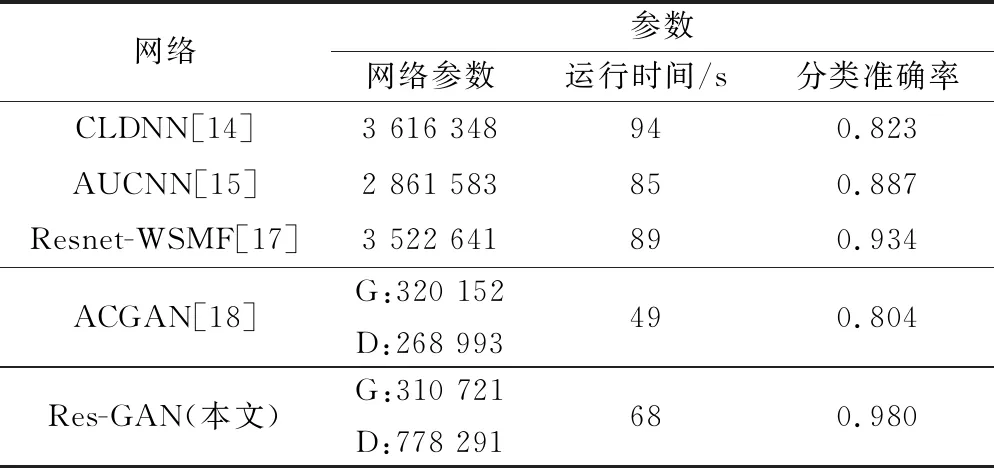
表3 不同網絡參數對比
運行時間代表一個epoch時間,從圖11和表3結果可以得出,在本文設定的小樣本條件下。ACGAN的網絡參數最少,識別準確率最低; CLDNN網絡參數較多,識別性能一般;AUCNN和Resnet-WSMF 網絡性能穩定,但訓練時間較長,相比較于上述4種網絡,Res-GAN算法取得了最高的識別準確率,而網絡參數和時間復雜度僅比ACGAN略高。
為了驗證小樣本條件下本文算法的性能,分別選取不同數量的標簽樣本數量進行對比實驗,結果記錄在表4中。對比表4的結果可以得出,在標簽樣本量為660左右時,除了本文算法,其他網絡的識別準確率均較低,隨著標簽樣本量的增加,對比網絡性能均有不同程度的提升。綜合表3和表4結果,本文算法一方面驗證了在小樣本條件下的實用性,另一方面在降低算法復雜度上也具有一定優勢。網絡收斂的最小標簽樣本量為660左右。

表4 不同標簽樣本量對網絡的性能影響
4 結 論
針對小樣本條件下信號識別準確率不高、算法復雜度高的問題,本文提出了一種基于Res-GAN的調制識別算法,借助GAN模型用CNN和新殘差單元組成的Resnet作為基本網絡,通過定義新的目標函數,將半監督學習與監督學習結合起來,充分利用了無標簽數據并有效實現了樣本數量的擴充。仿真實驗結果證明,新殘差單元不僅可以豐富特征提取的復雜度,還能更好地實現網絡參數的最優化更新;相比較于近年來廣泛應用的其他算法,本文算法具有識別準確率高、實現過程簡單、穩定性較好、復雜度低的特點。小樣本條件下針對10種調制信號識別準確率在SNR=18 dB時可以達到98%,驗證了本文算法的有效性。下一步將針對識別混淆的信號進行預處理,通過添加輔助信息來使得網絡可以更好地區分相近信號。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
