基于高度殘缺信息的分布式語言信任網絡群決策方法
2022-05-23 09:59:12曾守楨胡英杰
系統工程與電子技術 2022年6期
曾守楨, 胡英杰
(1. 寧波大學商學院, 浙江 寧波 315211; 2. 復旦大學管理學院, 上海 200433)
0 引 言
近年來,社會網絡背景下的群決策問題受到學者的廣泛關注[1-4],如群體旅游路線評價、網商信用評價、風險投資項目評估等都是一個社會網絡群決策問題。在社會網絡群決策問題的研究中有兩個主要問題不能忽視:① 評價與決策專家間的信任關系網絡。由于群決策過程中專家涉及不同的專業領域,在知識、經驗等方面都有其獨特的特點,這意味著不同專家對決策結果有不同的影響,這種影響體現在專家權重的差異上[5],而專家間的信任關系作為專家權重的重要來源,其在群決策過程中的重要性不容忽視。相較于人為設定的專家權重,由信任關系網絡獲取的專家權重顯得更加客觀;② 專家評價信息的殘缺(不完全)性問題。由于部分或所有專家對所涉及的問題缺乏深入的了解,經常會出現專家評價信息殘缺或不完全的情況,其直接影響最終的決策結果,故專家評價信息的殘缺性問題同樣不能忽視。
關于專家間信任關系網絡的研究,需關注以下兩個方面。① 關于專家間信任關系的表征方式的研究,傳統上主要以精確值(離散值與連續值)或二進制數表示為主[6-9]。其中文獻[6]對Film Trust網站上的用戶進行研究,其利用信任度為1~10的范圍對電影進行信任度評估(1:最不值得信任;10:最值得信任)。文獻[7]利用二元離散值(信任或不信任)表示用戶間的信任關系。文獻[8]利用區間[-1,1]的連續值來表示主體與推薦人之間的信任關系。文獻[9]利用[0,1]間的實數來表示專家間的信任程度。然而,考慮到信任的主觀性、模糊性和不確定性,人們往往更愿意用語言術語來表達信任程度,文獻[10]則提出分布式語言信任函數來表征專家間的信任關系,并通過“高”、“中”、“低”3個等級來表達他們的信任,比傳統的二元關系(信任或不信任)更加符合實際情況。② 關于信任傳遞算子的研究,研究者提出了包括T-norm、Uninorm (U)算子等眾多信任傳遞算子[2-3,9,11-13]。如文獻[2]基于Frank T-norm、T-conorm設計傳遞直覺模糊信任關系的信任傳遞算子。文獻[9]基于T-norm設計傳遞實數的信任傳遞算子。文獻[3]和文獻[11]分別基于U算子和Einstein T-norm、T-conorm構造信任傳遞算子以傳遞專家間的信任函數關系。文獻[12]基于代數T-norm設計了信任傳遞規則。文獻[13]基于Archimedean T-norm 和T-conorm設計了區間值雙重信任傳遞算子以傳遞區間值信任函數關系。上述研究都是以實數、直覺模糊數、信任函數等信任表征方式來設計信任傳遞算子,然而并沒有基于分布式語言信任關系的信任傳遞算子的相關研究。此外,現有關于分布式語言信任社會矩陣的研究,沒有對存在缺失的信任關系進行補全,且專家權重的獲取方法都是基于Q量詞,并未考慮社會矩陣中專家間的信任關系對專家權重的影響[14-15]。基于此,需提出一種能夠傳遞分布式語言信任關系的傳遞算子來補全社會矩陣,進而基于信任社會矩陣確定專家權重。考慮到已有的信任傳遞算子并不適用于分布式語言信任環境,故本文提出一種新的基于代數T-norm的分布式語言信任傳遞算子來補全缺失的信任關系,并基于完整的分布式語言信任社會矩陣定義個體、群體信任中心度的概念以確定專家權重。
針對專家評價信息的殘缺性問題,國內外已有眾多學者對殘缺信息的評估和補全方法進行了分析。文獻[4]通過改進的 PageRank 算法和專家信任網絡確定專家重要度,進而基于專家的重要度填充不完全的猶豫模糊評價信息。文獻[12]利用二元語義表示專家的評價信息,并基于專家間的相對信任得分評估不完全二元語義決策矩陣中未知的二元語義值。文獻[16]利用相對信任度和余弦相似度來評估不完全的基于精確數的評價信息。文獻[17]提出一種基于相似度和貼近度的集聚度,并基于集聚度補全不完全偏好關系。文獻[18-19]則分別基于信任得分和期望信任度提出專家間的相對信任度,并基于相對信任度評估專家的殘缺評價信息。文獻[20]提出了一種基于乘法一致性的不完全猶豫模糊偏好關系的歸一化和缺失元素的估計方法。文獻[21]通過其他類似專家的偏好來估計具有高度殘缺(即一些專家可能無法提供關于替代方案的任何單一判斷)的偏好信息。
目前,對于殘缺偏好信息的研究成果比較多[4,12,20-22],但是基于高度殘缺信息的多屬性決策方法還不多見。高度或極端殘缺信息在偏好關系環境下是指方案間的偏好關系存在某一行和某一列都未知的情形[21],而在多屬性群決策問題中高度殘缺信息可看成是某一方案下關于所有屬性的評價信息都未知的情形。同時關于殘缺值評估方法,上述大多數文獻都是基于其他所有專家的現有評價意見來對殘缺值進行評估和補全[4,12,16-19],這可能會導致某些專家的評價意見并不能被存在殘缺信息的專家所接受。而且,根據意見動力學理論,人們更傾向于接受來自相似同伴的意見[23]。因此,在高度殘缺的分布式語言信任評價信息背景下,本文提出一種基于K-近鄰算法的評估方法。首先找出與存在殘缺評價信息的專家距離最近(最相似)的K個專家,然后基于這K個專家的信息對殘缺值進行評估。K-近鄰算法保證了殘缺信息的評估依靠與其最相似的專家意見,而非所有專家。
除了上述兩個需注意的問題之外,對方案排序方法的選擇也不能忽視。本文將改進的逼近理想解排序(technique for order preference by similarity to an ideal solution,TOPSIS)法引入分布式語言信任決策環境中,提出一種改進的基于分布式語言信任函數距離測度的TOPSIS評價方法,能夠一定程度上降低僅由單個集成算子決策時造成的信息失真。
綜上所述,針對現有研究存在的缺陷,本文提出一種基于高度殘缺信息的分布式語言信任網絡群決策方法。具體而言,首先提出一種分布式語言信任傳遞模型,進而補全殘缺的分布式語言信任社會矩陣。在此基礎上,利用分布式語言信任社會矩陣定義個體信任中心度和群體信任中心度,并通過它們的距離測度獲取專家權重。其次,在專家評價信息高度殘缺的情況下,根據K-近鄰算法評估和補全專家的殘缺評價信息。最后,利用分布式語言信任加權平均算子融合各決策矩陣,并基于改進的TOPSIS評價方法對方案進行排序。
1 預備知識
本節主要介紹分布式語言信任函數的一些基本概念以及分布式語言信任網絡。
1.1 分布式語言信任函數
定義 1[10]設D={Dα|α=1,2,…,ξ}為一個語言術語集,則分布式語言信任函數T定義如下:
T={(Dα,φα)|α=1,2,…,ξ}
(1)
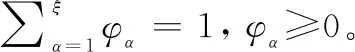
其中對于任意兩個分布式語言信任函數T1和T2,其運算法則表示如下(η,η1,η2>0):
(2)ηT={(Dα,ηφα)|α=1,2,…,ξ};
(3) (η1+η2)T=η1T⊕η2T;
(4)T1⊕T2=T2⊕T1;
(5)η(T1⊕T2)=ηT1⊕ηT2。
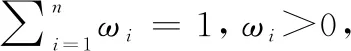
(2)
為了比較分布式語言信任函數的大小,文獻[10]定義了分布式語言信任函數的期望度E和不確定性度U如下:
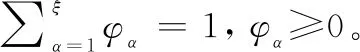
(3)
(4)
式中:E(T)越大,函數T的分值度就越大;U(T)越大,函數T的分值度就越小。
1.2 分布式語言信任網絡
群決策過程中專家間的信任網絡是由專家節點和專家節點間的有向邊(即信任關系)組成。而分布式語言信任網絡則是指用分布式語言來表示專家間的信任關系,進而構成分布式語言信任網絡,如圖1所示。其中有向箭頭表示專家間的分布式語言信任關系,如專家e1對專家e5是一種直接的信任關系。從圖中可以看出,專家e1對專家e2的信任關系未知,沒有直接相連的有向箭頭,是一種間接的信任關系,可通過中間專家節點(如e3和e5)的傳遞得到專家e1對專家e2的間接信任。
1.3 T-norm與代數T-norm
T-norm是決策過程中信息聚合的重要工具,目前也被廣泛應用于構造社會網絡決策過程中的信任傳遞算子,定義如下:
定義 4[24]二元函數N:[0,1]2→[0,1]被稱為T-norm當且僅當滿足
(1) 交換性
?x,y∈[0,1],N(x,y)=N(y,x)
(2) 結合性
?x,y,z∈[0,1],N(N(x,y),z)=N(x,N(y,z))
(3) 單調性
若x≤x1,y≤y1,則N(x,y)≤N(x1,y1)
(4) 單位元
?x∈[0,1],N(1,x)=x
代數T-norm(表示為A?)也是一個T-norm,其數學表達式為
A?(x,y)=x?y=xy
(5)
由于T-norm具有結合性,故代數T-norm也具有結合性,即
(6)
代數T-norm的一個重要性質為:T-norm小于等于最小算子min,數學表達式為
A?(x1,x2,…,xn)≤min {x1,x2,…,xn}
(7)
上述性質保證了由代數T-norm構造的信任傳遞算子在傳遞過程中信任值是遞減的。
因此考慮到代數T-norm的結合性、小于等于最小算子min等特性,下節將提出一種基于代數 T-norm的分布式語言信任環境下信任傳遞模型。
2 基于分布式語言信任函數的信任傳遞模型
目前分布式語言信任社會矩陣大多都是不完整的[10,14-15],且基于此類不完整的分布式語言信任社會矩陣所求得的專家權重是不精確的,這將影響最終的決策結果。本文通過定義分布式語言信任傳遞和聚合算子,將不完整的分布式語言信任網絡補全。
2.1 基于分布式語言信任函數的信任傳遞算子
定義 5設是分布式語言信任函數的集合。分布式語言信任傳遞算子PA,PA:×→,其中T1表示專家e1對專家e2的直接信任關系,T2表示專家e2對專家e3的直接信任關系,則專家e1對專家e3的信任關系T3可表示為
(8)
其中,
下面對信任傳遞算子PA的特殊情形作簡要分析。
(1) 當專家e1完全信任專家e2且專家e2完全信任專家e3時,可得專家e1完全信任專家e3。
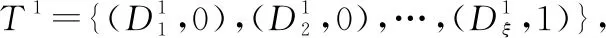
{(D1,0),(D2,0),…,(Dξ,1)}
即專家e1完全信任專家e3。
(2) 分以下兩種情況討論:①當專家e1完全信任專家e2且專家e2完全不信任專家e3時,可得專家e1完全不信任專家e3;②當專家e1完全不信任專家e2且專家e2完全信任專家e3時,可得專家e1完全不信任專家e3。
下面證明情況①,其中情況②的證明與情況①類似。
由①可知,
故專家e1對專家e3的信任關系為
{(D1,1),(D2,0),…,(Dξ,0)}
即專家e1完全不信任專家e3。
(3) 當專家e1完全不信任專家e2且專家e2對專家e3的信任關系未知時,可得專家e1完全不信任專家e3。即
{(D1,1),(D2,0),…,(Dξ,0)}
即專家e1完全不信任專家e3。
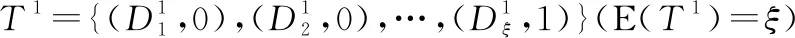
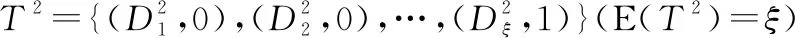
因此,專家e1對專家e3的信任關系可表示成如下形式:
T3=PA(T1,T2)=
(9)
由于在路徑傳遞的過程中可能會出現專家個數大于3,即中間的專家節點數大于2的情形,因此需要對傳遞路徑上中間的專家節點數大于2的情形進行討論以得出最終的信任關系。
當中間的專家節點數n=3時,有
--------------------
--------------------
其中,代數T-norm (A?)具有結合性,即
且有
則當n≥3可得:
(10)
(1) 當n=3時等式成立,已證。
(2) 假設當n=k時等式成立,則當n=k+1時,有
Tk+2=PA(T1,T2,…,Tk,Tk+1)=PA(PA(T1,T2,…,Tk),Tk+1)=
其中
基于式(6)和式(10),可得
Tn+1=PA(T1,T2,…,Tn)=PA(PA(T1,T2,…,Tn-1),Tn)=
(11)
2.2 基于分布式語言信任函數的信任聚合算子
考慮到信任傳遞過程中存在多條傳遞路徑的情況,本文提出一種基于路徑長度的誘導有序加權平均(induced ordered weighted averaging operator based on path length,L-IOWA)算子來聚合多條路徑的信任信息,以保證每條路徑的信任信息得到充分利用。首先定義在多條路徑情形下路徑Pi優于路徑Pj的情況。
定義 6設L表示路徑的長度,E表示分布式語言信任函數的期望,則路徑Pi優于路徑Pj的定義如下:
(1)L(i) (2)L(i)=L(j)∧E(Ti)>E(Tj)?PifPj。 基于路徑間的優先排序以及路徑權重,我們提出一種基于路徑長度的誘導有序加權平均算子以融合多路徑的信任信息,定義如下。 (12) 在得到完整的分布式語言信任網絡后,本文提出一種基于個體信任中心度和群體信任中心度的專家權重求解方法,定義如下。 定義 8設Ths表示分布式語言信任網絡中專家eh對專家es的信任關系,則個體信任中心度(individual trust centrality,ITC)和群體信任中心度(group trust centrality,GTC)分別為 (13) (14) 故專家es權重定義為 (15) (16) 該距離測度滿足以下性質: (1) 0≤d(T1,T2)≤1; (2)d(T1,T2)=0當且僅當T1=T2; (3)d(T1,T2)=d(T2,T1); (4)d(T1,T3)≤d(T1,T2)+d(T2,T3)。 在現實的群決策過程中經常會存在這樣的情況,即部分專家對所涉及的問題缺乏深入的了解,導致專家提供的評價信息存在殘缺的情形。目前對于偏好信息殘缺或不完全問題的研究成果比較多[4,12,17,20-22],但基于高度殘缺信息的多屬性決策方法還不多見。同時,關于殘缺信息評估方法,很多文獻都是基于其他所有專家的評價意見來評估殘缺值[4,12,16-19],忽略了存在殘缺評價信息的專家對其他專家評價意見的接受意愿,而且人們更傾向于接受來自相似同伴的意見[23]。基于此,本文研究在分布式語言信任決策環境下評價信息存在高度殘缺的情形,并利用K-近鄰算法評估專家的高度殘缺評價信息以保證評估值能被存在殘缺評價信息的專家所接受,即通過找出與決策矩陣中具有高度殘缺評價信息的專家距離最近的K個專家,即K個與具有高度殘缺評價信息的專家最相似且屬于同一類別的專家,并基于這K個專家評估殘缺的評價信息。具體過程如下: (1) 計算其他專家與存在高度殘缺評價信息專家的距離; (2) 通過距離測度,確定K個距離最近的專家; (3) 利用式(2)評估殘缺的評價信息。 其中第一步中的距離測度通過以下公式進行計算。即假設有l個專家es(s=1,2,…,l),相應的決策矩陣為As(s=1,2,…,l),有m個備選方案Xi(i=1,2,…,m),n個評價屬性Cj(j=1,2,…n)。設Ah為具有高度殘缺評價信息的專家決策矩陣,則Ah與As之間的距離測度定義為 (17) 在補全分布式語言信任決策矩陣后,根據式(2)將各個分布式語言信任決策矩陣整合成分布式語言信任群決策矩陣,表示為 此時,可計算分布式語言信任正、負理想解,用X+表示分布式語言信任正理想解,X-表示分布式語言信任負理想解: (18) (19) 根據式(18)和式(19)以及定義9的距離測度公式可計算每個方案Xi與分布式語言信任正理想解X+、負理想解X-之間的距離,即 (20) (21) 其中,d(Xi,X+)越小,表明方案Xi越好;d(Xi,X-)越大,表明方案Xi越好。 因此,可計算每個方案Xi的改進貼近度(improved closeness degree,ICD)為 (22) 進而基于ICD(Xi)對方案進行排序。 綜上,基于高度殘缺信息的分布式語言信任網絡群決策方法的具體步驟如下。 步驟 1基于分布式語言信任傳遞算子式(11)和聚合算子式(12)將分布式語言信任社會矩陣補全。 步驟 2基于式(16),計算個體信任中心度和群體信任中心度的距離測度,進而獲取專家權重。 步驟 3基于K-近鄰算法獲取與存在高度殘缺信息的專家距離最近的K個專家,并通過專家權重和式(2)將殘缺信息補全。 步驟 4計算群決策矩陣A,并利用式(18)~式(21)計算每個方案Xi與分布式語言信任正理想解X+和負理想解X-之間的距離。 步驟 5基于式(22),計算每個方案Xi的貼近度ICD(Xi),并根據其大小對方案進行排序。 相應地,該群決策方法的流程如圖2所示。 綜上分析,該群決策方法的特點及創新點主要體現在以下幾個方面。 (1) 設計了傳遞分布式語言信任關系的信任傳遞模型,并基于信任關系定義個體信任中心度ITC和群體信任中心度GTC,進而獲取專家權重,克服了已有文獻關于分布式語言信任社會矩陣的研究中存在缺失信任關系的缺陷,同時彌補了專家權重獲取時未考慮專家間信任關系的不足。 (2) 基于高度殘缺信息的決策問題,提出了在高度殘缺分布式語言評價信息環境下的K-近鄰算法,相較于基于其余專家的評價信息對殘缺值進行評估的方法,利用相似專家的評價意見評估殘缺值,更能反映存在殘缺信息的專家對評價意見的接受意愿,即并非所有專家的評價意見都能被接受。 (3) 將改進的TOPSIS引入分布式語言環境中,并結合DTWA算子對方案擇優,可有效避免由單個DTWA算子對方案擇優所帶來的信息失真問題。 假設有3個外賣平臺{X1,X2,X3},相應的屬性為餐品的安全性、外賣的配送快慢程度、餐品下單的優惠力度、餐品的美味程度,即屬性集{C1,C2,C3,C4},屬性權重分別為w=[0.35,0.3,0.15,0.2]T。現需為大學新生推薦一款性價比最高的外賣平臺,故咨詢五位在校大學生{e1,e2,e3,e4,e5},利用式(1)中分布式語言信任函數T,并綜合上述4個屬性對3個外賣平臺進行評價,以選出性價比最高的外賣平臺。其中,假定式(1)中ξ=3,且令D1=“低”,D2=“中等”,D3=“高”。此外,上述5位大學生可構成如下的分布式語言信任社會矩陣: -------------------- -------------------- 式中:“-”表示專家間不存在直接信任關系;“×”表示專家對自我的信任不予考慮。 步驟 1根據信任傳遞算子式(11)和信任聚合算子式(12),將分布式語言信任社會矩陣補全。以專家e1對專家e4的信任關系為例,專家e1到專家e4有3條信任傳遞路徑,分別為L1:e1→e2→e4、L2:e1→e5→e3→e4和L3:e1→e5→e3→e2→e4,根據式(11)可得 上述3條傳遞路徑的權重可由Q量詞計算,令a=0.5,可得w1=0.58,w2=0.24,w3=0.18。故專家e1對專家e4的信任關系為 其他專家間的信任關系可類似計算,故可得如下完整的分布式語言信任社會矩陣: -------------------- 步驟 2根據式(13)和式(14),可得決策專家的信任中心度和群體信任中心度: ITC(e1)={(D1,0.652 5),(D2,0.115 0),(D3,0.232 5)} ITC(e5)={(D1,0.357),(D2,0.140),(D3,0.503)} 進而根據式(15),得到專家權重為 ω1=0.197 步驟 3根據K-近鄰算法計算與專家e1距離最近的K個專家,并利用K個專家的權重評估專家e1的殘缺值。其中5位專家的分布式語言信任評估矩陣分別如表1~表5所示。 表1 專家e1的分布式語言信任評估矩陣 表2 專家e2的分布式語言信任評估矩陣 表3 專家e3的分布式語言信任評估矩陣 表4 專家e4的分布式語言信任評估矩陣 表5 專家e5的分布式語言信任評估矩陣 通過式(17)計算專家e1與其余專家的距離測度,可得 d(e1,e2)=0.356 取K=3,則根據上述距離測度可得,與專家e1距離最近的3個專家分別為專家e3,e4,e5,故專家e1的殘缺值可評估為 (23) 其中,ρ1,ρ2,ρ3為專家e3,e4,e5的權重標準化后的值,即ρ1=0.333,ρ2=0.352,ρ3=0.315。進一步計算可得 步驟 4計算每個方案Xi與分布式語言信任正理想解X+和負理想解X-之間的距離d(Xi,X+)和d(Xi,X-)。首先根據式(2)計算群決策矩陣,結果如表6所示。 表6 基于分布式語言信任函數的群決策矩陣 根據表6可計算正負理想解X+和X-: X+={((D1,0.116),(D2,0.458),(D3,0.426)), ((D1,0.241),(D2,0.435),(D3,0.324)), ((D1,0.175),(D2,0.424),(D3,0.401)), ((D1,0.358),(D2,0.185),(D3,0.457))} X-={((D1,0.584),(D2,0.297),(D3,0.119)), ((D1,0.463),(D2,0.412),(D3,0.125)), ((D1,0.564 4),(D2,0.382 3),(D3,0.053 3)), ((D1,0.374),(D2,0.544),(D3,0.082))} 則可得 d(X1,X+)=0.020 步驟 5根據式(22)計算每個方案Xi的貼近度ICD(Xi),i=1,2,3: ICD(X1)=0 因此方案排序為:X1>X3>X2,即第一個外賣平臺X1的綜合性價比最高。 在上述決策過程中,對于信任聚合時路徑權重的計算,需注意的是,其假定參數a=0.5。顯然當參數a取不同值時,每條路徑權重不同,相應地信任聚合結果也會不同,進而會對決策結果產生影響。因此,下面考慮參數a的變化對方案排序結果的影響,鑒于a=0時,路徑權重計算會出現00,沒有意義;a=1時,當兩條路徑長度不同時,路徑權重都為0.5。事實上,路徑越短權重應越大,路徑越長權重應越小,故參數a=1也不可取。因此,本文以0.2為步長,在區間(0,1)內對參數a進行取值以分析最終的決策結果,即取a=0.1,0.3,0.5,0.7,0.9。具體的方案貼近度ICD以及排序結果如表7所示。 表7 參數a對方案排序的影響 相應地,方案的貼近度ICD與排序隨參數a變化的趨勢如圖3和圖4所示。 由圖3可以看出,隨著參數a的不斷增大,方案X2與X3的貼近度ICD呈現遞減的趨勢,但波動幅度不大。而X1的ICD不變,始終保持在最大值0。圖4中,考慮到a=0.1,0.3,0.5,0.7,0.9時方案排序始終保持一致,即X1>X3>X2,因此圖4中只畫出一條折線,由于最優方案都為X1,方案排序一致。因此,本文提出的方法是相對穩定的,同時也說明方案排序對參數a的選擇并不敏感。 為體現本文方法的可行性與有效性,下面采用兩種方法來計算實例,進而與本文方法(a=0.5)進行對比分析。 方法 1利用文獻[10]中分布式語言信任關系的入度中心度的期望值來獲取專家權重,并利用文獻[19]中基于期望信任度的相對信任度評估殘缺值,在此基礎上,利用DTWA算子集成決策矩陣,并基于改進的TOPSIS聚合評價信息。 方法 2利用文獻[14]中的Q量詞獲取專家權重,并利用文獻[4]中殘缺信息的評估方法評估殘缺值,在此基礎上,利用DTWA算子聚合決策矩陣,同時基于改進的TOPSIS聚合評價信息。 不同方法得到的ICD值如圖5所示,其中ICD(Xi)表示方案Xi的貼近度,本文方法與方法1、方法2所得ICD(X1)的值均為0,故圖5中不顯示。 從圖5可看出,本文方法與方法1、方法2所得ICD(X2)與ICD(X3)的值均不同,但3種方法所得到的排序結果均為ICD(X1)>ICD(X3)>ICD(X2),最優方案都為X1,說明本文所提出的方法是可行的。 為進一步體現本文方法的優越性,下面從專家權重的獲取方法與殘缺信息的評估方法兩個角度進行分析,具體結果如表8所示。 表8 不同方法的對比分析 從表8可以看出,不同方法所得專家權重與殘缺信息的評估也不同。具體而言: (1) 方法1中專家權重的獲取雖基于專家間的信任關系,但并未將殘缺的分布式語言信任社會矩陣補全,基于殘缺的分布式語言信任關系得到的期望值并不準確,進而獲取的專家權重也不準確。同時基于其余專家信任關系的期望的相對信任度評估殘缺值并沒有考慮到存在殘缺評價信息的專家對其余專家評價信息的接受意愿。而本文方法不僅通過提出的信任傳遞模型將殘缺的分布式語言信任社會矩陣補全,進而基于分布式語言信任關系的個體和群體信任中心度獲取專家權重,結果更準確。而且通過提出的分布式語言K-近鄰算法對殘缺評價信息進行評估,一定程度上反映了存在殘缺評價信息的專家對其余專家評價信息的接受意愿。 (2) 方法2中專家權重的獲取基于量詞Q,雖是以專家間信任關系的大小為誘導變量來獲取權重,但信任關系本身并沒有用于專家權重的求解,且分布式語言信任社會矩陣是殘缺的,以殘缺的信任關系作為誘導變量也存在問題。此外,基于其余專家的重要度來評估殘缺的評價信息,同樣沒有考慮到存在殘缺評價信息的專家對其余專家評價信息的接受意愿。而本文方法的提出恰好能克服上述兩個缺陷。 本文提出一種基于高度殘缺信息的分布式語言信任網絡群決策方法,主要體現在以下幾個方面:第一,針對殘缺的分布式語言信任社會矩陣,結合代數T-norm的優良性質,提出一種分布式語言環境下基于代數T-norm的信任傳遞算子。并考慮到多條傳遞路徑存在的情形,提出一種基于分布式語言的信任聚合算子。第二,針對目前分布式語言信任群決策問題在專家權重計算時并未利用專家間信任關系這一情形,定義了基于分布式語言信任關系的個體信任中心度和群體信任中心度,并通過它們的距離測度來獲取專家權重。第三,針對專家評價信息高度殘缺的情形,提出一種基于K-近鄰算法的評估方法,通過確定與存在高度殘缺評價信息的專家距離最近(最相似)的K個專家來評估殘缺的評價信息,而非基于所有專家的評價意見進行評估,因為可能某些專家的評價意見并不能被存在高度殘缺評價信息的專家所接受。值得注意的是,本文研究的群決策方法是以分布式語言為決策背景的,事實上還可將其拓展到其他非確定性數據環境中,如概率語言集[19]、猶豫模糊集[26]、直覺模糊集[2]等。同時,本文所提出的群決策方法未考慮共識交互模型對決策結果的影響[9,13,19],相關研究筆者在未來的工作中會繼續跟進。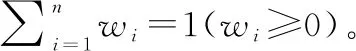
2.3 基于分布式語言信任網絡的專家權重獲取
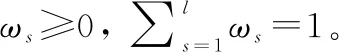
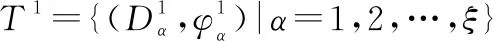
2.4 高度殘缺信息的評估(K-近鄰算法)
3 基于高度殘缺信息的分布式語言信任網絡群決策方法
3.1 基于分布式語言信任函數的改進TOPSIS方法
3.2 基于高度殘缺信息的分布式語言信任網絡群決策方法
4 決策應用分析
4.1 實例分析
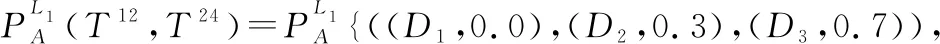
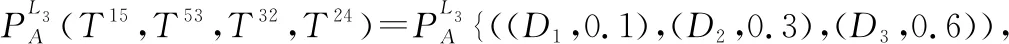
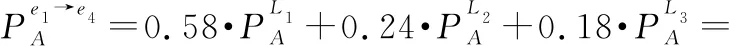
ITC(e2)={(D1,0.402),(D2,0.208),(D3,0.390)}
ITC(e3)={(D1,0.630),(D2,0.109),(D3,0.261)}
ITC(e4)={(D1,0.561),(D2,0.123),(D3,0.316)}
GTC(eg)={(D1,0.520 5),(D2,0.139 0),(D3,0.340 5)}
ω2=0.200
ω3=0.201
ω4=0.212
ω5=0.190




d(e1,e3)=0.218
d(e1,e4)=0.238
d(e1,e5)=0.258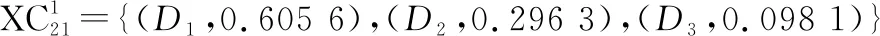

d(X2,X+)=0.275
d(X3,X+)=0.164
d(X1,X-)=0.271
d(X2,X-)=0
d(X3,X-)=0.171
ICD(X2)=-13.54
ICD(X3)=-7.4414.2 參數敏感性分析

4.3 對比分析

5 結 論
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
中華手工(2017年2期)2017-06-06 23:00:31
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中外會展(2014年4期)2014-11-27 07:46:46
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
體育師友(2012年4期)2012-03-20 15:30:10
