基于子圖分解的圖聚類神經網絡
2022-05-27 15:45:34鄧祥俞璐姚昌華朱瑾
計算機時代 2022年5期
鄧祥 俞璐 姚昌華 朱瑾

摘? 要: 聚類是機器學習的核心任務之一,其主要目的是將無標簽數據中的不同簇數據進行分離。深度聚類算法使用深度神經網絡聯合優化聚類目標與特征提取,極大地提高了聚類性能。圖聚類是深度聚類領域近兩年研究的一個重要分支,其在處理圖結構數據上有極大的優勢。提出一種新的圖聚類方案:基于子圖分解的圖聚網絡,該模型在圖自編碼器的基礎上通過構建多個子圖,并在子圖的嵌入空間中加以組稀疏約束達到最終的聚類目的。
關鍵詞: 模式識別; 圖神經網絡; 深度學習; 深度聚類
中圖分類號:TP181? ? ? ? ? 文獻標識碼:A? ? ?文章編號:1006-8228(2022)05-06-05
Graph clustering neural network based on subgraph decomposition
Deng Xiang Yu Lu ?Yao Changhua ?Zhu Jin
Abstract: Clustering is one of the core tasks of machine learning. Its main purpose is to separate different cluster data from unlabeled data. Deep clustering algorithm uses deep neural network to jointly optimize clustering objectives and feature extraction, which greatly improves the clustering performance. Graph clustering is an important branch in the field of deep clustering in past two years. It has great advantages in processing graph structure data. In this paper, a new graph clustering scheme, graph clustering network based on subgraph decomposition, is proposed. Based on graph Auto-encoder, this model achieves the final clustering purpose by constructing multiple subgraphs and imposing group sparse constraints in the embedded space of subgraphs.
Key words: pattern recognition; graph neural network; deep learning; deep clustering
引言
聚類任務的主要目的是把相似的數據聚成一簇,其關鍵是如何有效地度量樣本之間的相似性。在人工數據集中由于數據沒有冗余信息、具有分離的數據結構所以聚類難度較低。在大數據時代數據包含了大量的冗余信息且有高度復雜的結構,極大地增加了聚類的難度,所以近些年的聚類算法更多的關注如何進行特征提取,在保持有效特征的同時去除冗余噪聲的干擾以降低聚類的難度。
隨著近些年深度學習的發展,神經網絡的表示學習能力越來越強,因此使用神經網絡進行特征處理是現如今聚類方案應對復雜數據集的方法之一。基于深度學習的聚類方案主要有兩種方式。其一是使用神經網絡進行無監督特征學習,學得一個高維數據的低維嵌入,之后在這個低維嵌入特征上進行傳統聚類。這類方法雖然在一定程度上去除了冗余噪聲,但是由于缺少全局的聚類聚目標函數,導致提取的特征不是利于聚類的特征,并沒有充分地發揮神經網絡的優勢。其二是以聚類目標為導向的深度聚類方案,讓聚類目標指導神經網絡的特征提取工作,使神經網絡提取的特征是利于聚類的特征。這種方案可以更好地利用神經網絡的表示學習能力和非線性逼近能力,可以很好地處理現如今越加復雜的數據集。
1 相關工作
1.1 相關理論
近年來隨著深度聚類不斷發展涌現出了大量杰出的算法,根據深度聚類算法所使用的神經網絡不同,文獻[1,2]將現有的深度聚類方法劃分為基于不同神經網絡的聚類方法,其大致可以分為以下幾個類別:基于自編碼器的聚類算法、基于生成對抗網絡的聚類算法、基于變分自編碼器的聚類算法等。發展這些基于不同神經網絡的深度聚類算法的目的是為了應對不同類型、不同應用環境的復雜數據集。
以上這些深度聚類算法能夠處理大多數的結構化數據,但面對非結構化數據如圖數據集時卻無能為力。而近兩年,隨著圖神經網絡的提出,非結構化數據的處理不再是一個困擾性的問題,因此人們期望借助圖神經網絡的能力來獲取無標簽數據的簇結構信息,以此來提取利于聚類的特征表示,達到提升聚類效果的目的。
基于圖神經網絡的深度聚類模型中較成功的有Embedding Graph Auto-Encoder(EGAE)[3],DeepAttentional Embedded GraphClustering(DAEGC)[4],Structural Deep Clustering Network(SDCN)[5],adaptive graph convolution (AGC)[6],Adversarial Graph Auto-Encoders(AGAE)[7]等。其中AGAE的輸入是相似性矩陣,利用圖卷積神經網絡處理相似性矩陣提取特征,并把它與特征先驗分布中得到的特征一同進行對抗性訓練, 得到一個能完成聚類的概率分布。DAEGC將注意力機制引入圖神經網絡,在圖自編碼器的圖結構重構過程中關注邊的權重變化,之后在這個圖神經網絡提取的特征上進行自訓練聚類,其自訓練聚類參考了DEC[8]模型,把特征與聚類中心的相似度轉化為概率分布p,對分布p進行置信度加強形成分布q,最小化分布p,q的KL散度達到聚類目標。SDCN模型則是在引入圖自編碼器的同時引入經典自編碼器,使用雙重自監督模塊使兩類自編碼器提取特征時能夠互相監督,這里的雙重自監督模塊與DAEGC模型一樣都借鑒了DEC模型提出的聚類分布,即求自編碼器中間特征與聚類中心相似度轉化的概率分布p與置信度加強分布q的KL散度。AGC模型與SDCN模型相似都使用了多層圖卷積神經網絡來提取高階結構信息,并通過逐漸增加K的方式來達到自適應地選擇聚合信息的階數。EGAE模型同樣是在多層圖卷積神經網絡的基礎上設計的聚類模型,該模型在圖卷積神經網絡提取的帶有結構信息的特征上設計兩個類似于k-means聚類和譜聚類的損失項,通過這種聯合訓練的方式來取得更好的聚類效果。
對上述基于圖卷積神經網絡的聚類模型研究可以發現,圖神經網絡聚類算法都需要在圖自編碼器網絡上設計的聚類損失函數,其主要原因是借助圖自編碼的結構捕捉能力來獲取帶有簇結構信息的低維嵌入特征,本文同樣選擇在圖自編碼器上開發聚類算法,不同于上述算法對中間特征設計聚類的損失項,本文算法從圖自編碼器的結構重構能力出發,將數據的圖結構劃分為不同的子圖,這些子圖代表不同的聚類簇,利用圖自編碼器重構出子圖結構,以達到聚類的目的。本文主要貢獻:使用圖自編碼器神經網絡探索聚類簇的子圖結構。
1.2 圖卷積
結構化數據可以用卷積操作來提取特征信息,而卷積操作并不能處理非結構化數據,如社交網絡、知識圖譜、蛋白質結構、萬維網等,對于這些非結構化數據,如何像卷積操作一樣提取有效的特征信息是一些應用的關鍵。圖卷積[9]操作是在圖上進行的卷積操作,能夠捕獲數據的結構信息。圖卷積操作定義如下:給定一個圖G(V,E,X),V代表圖的頂點集合,E代表圖上存在的邊的集合,X代表節點的特征矩陣,由此可以得到圖的鄰接矩陣A,和鄰接矩陣的度矩陣D,該矩陣是一個對角矩陣,對角線上的值為對應節點的度。如圖卷積操作表示中,[?()]是激活函數,Z是圖卷積操作提取的特征信息。
⑴
在具體實現中,我們對圖卷積操作做如下處理:
⑵
其中[A=A+I]、[D]是(A+I)的度矩陣,其同樣是一個對角矩陣,對角線上的點是(A+I)節點的度。
1.3 圖自編碼器
圖自編碼器[10]利用多層圖卷積操作提取節點的特征信息,經典自編碼器的目標是重構出原始樣本的信息,而圖自編碼器不同于經典自編碼器,它的目標是使用圖卷積操作提取的特征來重構出原始的圖結構,在保證圖結構信息不變的情況下,捕獲帶有聚類簇結構的節點信息。其定義如下:
⑶
其中[Zl]是第l層圖卷積的輸出,[Wl]是第l層的權重。這里輸入層圖卷積的[Zl]為節點的特征矩陣X,編碼器輸出層圖卷積的[Zl+1]為嵌入特征Z。
對編碼器的嵌入特征Z與Z的轉置,做矩陣運算得到一個圖結構矩陣[A],使用這個矩陣重構原圖,以達到圖結構不變的目的。
⑷
⑸
2 基于子圖分解的圖聚類網絡
2.1 本文算法的聚類思想
譜聚類算法是最著名的圖聚類算法,對于非圖結構的數據集,譜聚類通過k近鄰、全連接、[ε-]領域等方法將數據樣本之間的相似性轉化為圖的邊權重。再將構建的圖結構切割成不同的子圖,這些不同的子圖代表了不同的聚類簇結構,譜聚類的核心聚類思想是讓切割之后的子圖間邊權重低,而子圖內邊權重高。因此如何進行子圖切割是譜聚類的關鍵。
本文受譜聚類的啟發使用神經網絡進行子圖切割,借助圖卷積神經網絡提取不同子圖的嵌入特征,再使用不同的嵌入特征重構出不同的子圖結構,達到聚類的目的。
2.2 子圖劃分
本文算法借助圖卷積神經網絡將數據集的圖結構劃分為K個子圖,其具體的結構如圖1所示,劃分的思想是將來自淺層圖卷積F的特征送入K個子圖網絡中,每個子圖網絡都將生成一個對應的子圖。其中[ZlkN×d']是第k個子圖第l層的圖卷積輸出特征,[AkN×N]是第k個子圖的鄰接矩陣。
⑹
⑺
為了達到子圖劃分的目的,我們增加了一個判別網絡用來輸出樣本屬于各簇的概率[QN×K],用這個概率向量對重構的圖結構進行篩選,得到K個聚類簇的結構圖。篩選的方法為:樣本屬于第i簇概率乘以第i個子網絡產生的特征[Zi]和子圖[Ai]。其具體的篩選步驟為如下兩種情況(其中[(x)p,q]是定義的維度擴展操作將x擴展到p、q維):
⑴ 樣本j屬于第i簇則理想狀態[QN×Kj,i=1],對[QN×Kj,i=1]進行維度擴展,將第二維擴展到N維,得到[Q1=(QN×Kj,i=1)1×N],將第二維擴展到d'維得到[Q2=(QN×Kj,i=1)1×d'],再分別與[Aij:]和[Zij:]做點乘,從而將樣本j的嵌入特征和子圖結構保留在第i簇。
⑵ 樣本j不屬于第i簇則理想狀態[QN×Kj,i=0],對[QN×Kj,i=0]進行維度擴展,將第二維擴展到N維得到[Q1=(QN×Kj,i=0)1×N],將第二維擴展到d'維得到[Q2=(QN×Kj,i=0)1×d']再分別與[Aij:]和[Zij:]進行點乘,從而將樣本j的嵌入特征和子圖結構從第i簇中去除。
以上這兩種情況可以統一為如下公式:
⑻
⑼
⑽
這里我們對判別網絡輸出的概率分布進行一個加權指數的操作[QαN×K],用來增加模型的自由度和靈活性。
2.3 先驗知識
先驗知識能夠輔助聚類,不同的先驗知識對聚類算法的影響程度不同,在聚類算法中最常見的先驗知識是聚類簇的數目K,根據聚類算法設計角度的不同,可能需要設置不同的先驗知識。在本文中由于我們需要使用樣本屬于各簇的概率向量來篩選子圖,為了使樣本在篩選子圖時不陷入極端解(如預測為同一簇),我們假設模型預測樣本簇的概率分布的先驗知識為均勻分布。模型預測的簇分布為q ,先驗分布為均勻分布p,則本文算法的先驗損失項為q和p的KL散度。
⑾
⑿
⒀
2.4 本文算法描述
前文中,我們生成了K個子圖,并引入了均勻分布作為聚類簇分布的先驗知識,至此,我們完成了使用圖卷積神經網絡定義聚類簇結構,但仍然缺少關鍵的聚類引導項來保證不同簇的嵌入特征和子圖結構向正確的方向劃分。這里我們使用圖自編碼器來完成這個工作,假設得到K個正確的子圖劃分,則這個K個子圖的合并將逼近原數據的圖結構。
⒁
⒂
因此,本文提出的深度聚類算法的聚類引導項選擇使用圖自編碼器讓圖結構[A]重構出原數據的圖結構A。在保證每個子圖都在原始圖結構中時,使用圖卷積提取各自子圖的嵌入特征,同時選擇均勻分布保證了模型的解不至于陷入極端解,如把所有樣本劃分為同一簇。本文的算法描述如表1所示,由此可以得出本文聚類算法的損失公式:
⒃
3 實驗及結果分析
3.1 數據集
本文選擇Cora數據集[11]用來驗證本文提出的圖深度聚類算法,Cora數據集由七類深度學習論文組成,其中包含基于案例、遺傳算法、神經網絡、概率網絡、強化學習、規則學習、理論這七方面的論文。整個數據語料庫中共包含2708篇論文,每篇論文至少被一篇論文引用,同時至少引用一篇論文。數據集包含了論文之間引用關系的索引,依據這些索引位置可以建立論文之間引用關系的鄰接矩陣。對每篇論文進行詞干提取、去除詞尾,刪去詞頻小于10的詞等操作后保留了1433個特有的詞,對這些詞建立詞向量,形成了圖節點的特征矩陣X。
3.2 評估指標
本文選用互信息(NMI)[12]指標,來評估本文提出的深度聚類算法的聚類性能。NMI指標能夠評估一個變量包含另一個變量的信息量。NMI 指標的取值范圍是[0,1],越接近1說明變量Y包含變量X的信息量越小,變量X確定性越大。
⒄
3.3 模型的實現
模型的具體實現圖卷積網絡F采用一層圖卷積操作。網絡G是七個并列的子網絡,每個網絡都是一層圖卷積操作,且其輸入是來自網絡F的淺層嵌入特征。網絡Q是四層線性網絡,其輸入是節點的特征矩陣X,輸出是樣本所屬簇的預測結果。聚類簇數目設為7,迭代周期設置為10000,優化函數選擇Adam[13]算法,學習率lr=0.01,加權指數[α=2]。
3.4 實驗結果
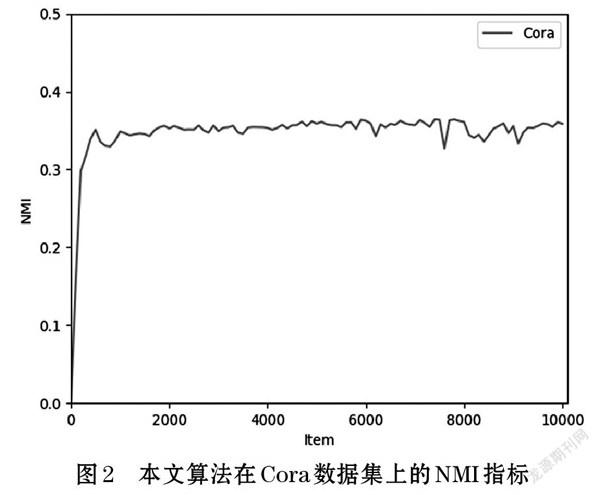
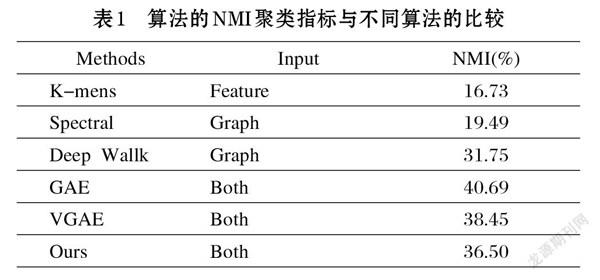
表2展示了本文算法在Cora數據集上的實驗結果,該結果取自多次實驗的最優結果,圖2展示了算法的NMI指標在模型訓練過程中的變化情況。表2中我們選擇了三類作用在不同輸入上的聚類算法與本文提出的算法做比較。
觀察表2可以看出本文提出的圖神經網絡聚類算法要明顯優于只作用于數據特征上的聚類算法和只作用圖結構上的聚類算法。這表明基于圖卷積神經網絡的聚類算法有效地利用了數據集的圖結構和節點的特征。
觀察圖2可以看出本文的算法在輪次為0的時候NMI指標為0,此時不具備聚類能力,隨著訓練地進行在各損失項的相互約束下,逐漸具備聚類的能力,最終結果收斂在0.36附近。
圖2和表2的結果表明本文提出的基于子圖分解的圖聚類網絡具有聚類劃分的能力。
4 結束語
本文提出的基于子圖分解的圖聚類網絡在圖自編碼器的基礎上對原始數據集的圖結構進行子圖劃分,以不同的子圖結構來區分數據集中的不同簇結構以達到聚類劃分的目的。該算法在Cora數據集上取得了較好的結果。本文算法的下一步工作是對劃分的子圖做進一步的約束以期能夠達到更高的聚類效果。
參考文獻(References):
[1] ALJALBOUT E.Clustering with deep learning: taxonomy
and new methods[J/OL].(2018-09-13) [2021-04-02].http://export.arxiv.org/abs/1801.07648
[2] MINE.A survey of clustering with deep learning:from the
perspective of network architecture[J].IEEE Access,2018,6:39501-39514
[3] Li X, Zhang H, Zhang R. Embedding graph auto-encoder
with joint clustering via adjacency sharing[J].arXiv e-prints,2020: arXiv:2002.08643
[4] Wang C, Pan S, Hu R, et al. Attributed graph clustering:A
deep attentional embedding approach[J]. arXiv preprint arXiv:1906.06532,2019
[5] Bo D, Wang X, Shi C, et al. Structural deep clustering
network[C]//Proceedings of The Web Conference 2020,2020:1400-1410
[6] Zhang X, Liu H, Li Q, et al. Attributed graph clustering via
adaptive graph convolution[J]. arXiv preprint arXiv:1906.01210,2019
[7] TAO Z,LIU H,LI J,etal.Adversarial graph embedding for
ensemble clustering[C]//Twenty-Eighth International Joint Conference on Artificial Intelligence IJCAI-19,2019
[8] Xie J, Girshick R, Farhadi A. Unsupervised deep
embedding for clustering analysis[C]//International conference on machine learning. PMLR,2016:478-487
[9] Niepert M, Ahmed M, Kutzkov K. Learning convolutional
neural networks for graphs[C]//International conference on machine learning. PMLR,2016:2014-2023
[10] Kipf T N, Welling M. Variational graph auto-encoders[J].
arXiv preprint arXiv:1611.07308,2016
[11] Sen P, Namata G, Bilgic M, et al. Collective classification
in network data[J]. AI magazine,2008,29(3):93-93
[12] P. A. Estévez, M. Tesmer, C. A. Perez, and J. M. Zurada,
“Normalized mutual information feature selection,” IEEE Trans. Neural Netw.,2009,20(2):189-201
[13] DiederikKingma and Jimmy Ba. Adam: A method for
stochastic optimization. arXiv preprint arXiv:1412.6980,2014
收稿日期:2021-09-22
*基金項目:國家自然科學基金面上項目(No.61971439); 江蘇省自然科學基金面上項目(No.BK20191329); 中國博士后科學基金項目(No.2019T120987); 南京信息工程大學人才啟動經費(No.2020r100)
作者簡介:鄧祥(1994-),男,安徽六安人,碩士研究生,主要研究方向:模式識別與深度學習。
猜你喜歡
中成藥(2018年2期)2018-05-09 07:19:52
電子測試(2017年23期)2017-04-04 05:06:50
智能系統學報(2017年5期)2017-01-22 11:21:30
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
海軍航空大學學報(2015年1期)2015-11-11 17:17:57
