Clickhouse在采油廠數據湖技術生態中的應用前景
2022-05-30 10:48:04任明浩
電腦知識與技術 2022年21期
關鍵詞:大數據
任明浩
摘要:在數據量日益增長的當下,傳統數據庫的查詢性能已滿足不了業務需求。近年來大量開源架構為探索流批一體實時數倉的大數據研發工程師提供了豐富的資源,同時也增加了工程師在學習成本、框架的多樣化和復雜度等方面選擇合適工具的難度。此情景下,整合開源框架、工具、庫、平臺勢在必行。該文引入Clickhouse數據庫管理系統,并在數字化油田構建實時數倉的建設中構想其應用前景。
關鍵詞:OLAP;大數據;Clickhouse
中圖分類號:TP3? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2022)21-0015-03
開放科學(資源服務)標識碼(OSID):
油田開發中后期,開采成本日益上升,為了降本增效以及提高整個企業的安全狀況,物聯網及數據工程師考慮依靠數據驅動油田,將大數據技術用于監控設備性能和環境條件。通過使用制造業和工程行業的先進技術,架設于設備上的傳感器可以收集現場操作中的數據,并用于保障原油平穩安全生產的可行性分析[1]。未來數字化建設考慮數據中臺,將原本存在各關系型數據庫、實時歷史數據庫、非結構化數據庫等的數據實時接入數據區域湖,區域湖再將不同類型的數據模型進行歸一化處理,并且在數據分析平臺提供統一的查詢入口,再由油藏、采油工程師找到數據背后有價值的信息,在大數據中預測分析,指導生產。
而今,大量開源架構為探索流批一體實時數倉的大數據研發工程師提供了豐富的資源,同時也增加了工程師選擇合適工具的難度,主要體現在學習成本、框架的多樣化和復雜度。如Kafka、HDFS、Spark、Hive等大數據生態技術經過組合才能產生最后的分析結果。此情景下,整合開源框架、工具、庫、平臺勢在必行。
面向智慧油田的數據管控體系主要研究在“采”“存”“管”“用”四個方面。
“采”:數據變更抓取系統,解決多源異構數據一致性的問題。相較于專注流程控制和中間處理過程靈活性但不追求性能的傳統數據提取轉換和加載系統而言,數據變更抓取系統對實時性要求比較高。
“存”“管”:數倉分層存儲和維度表管理均由數據湖承擔。
“用”:一個思路是將聚合分析計算由數據分析引擎承擔。相較于Flink、Spark或者Storm,它的優點是自由度高,可以滿足實時分析需求,減輕實時計算部分的聚合處理壓力;缺點是必須要求消息隊列中保存存量數據,且因為是將計算部分的壓力轉移到了查詢層,對查詢引擎的吞吐和實時攝入性能要求較高。
本文主要對基于數據分析引擎的云數據庫管理系統Clickhouse在“用”的方面即查詢分析方面做深入探討。
1 Clickhouse概述
1.1 Clickhouse發展迅猛
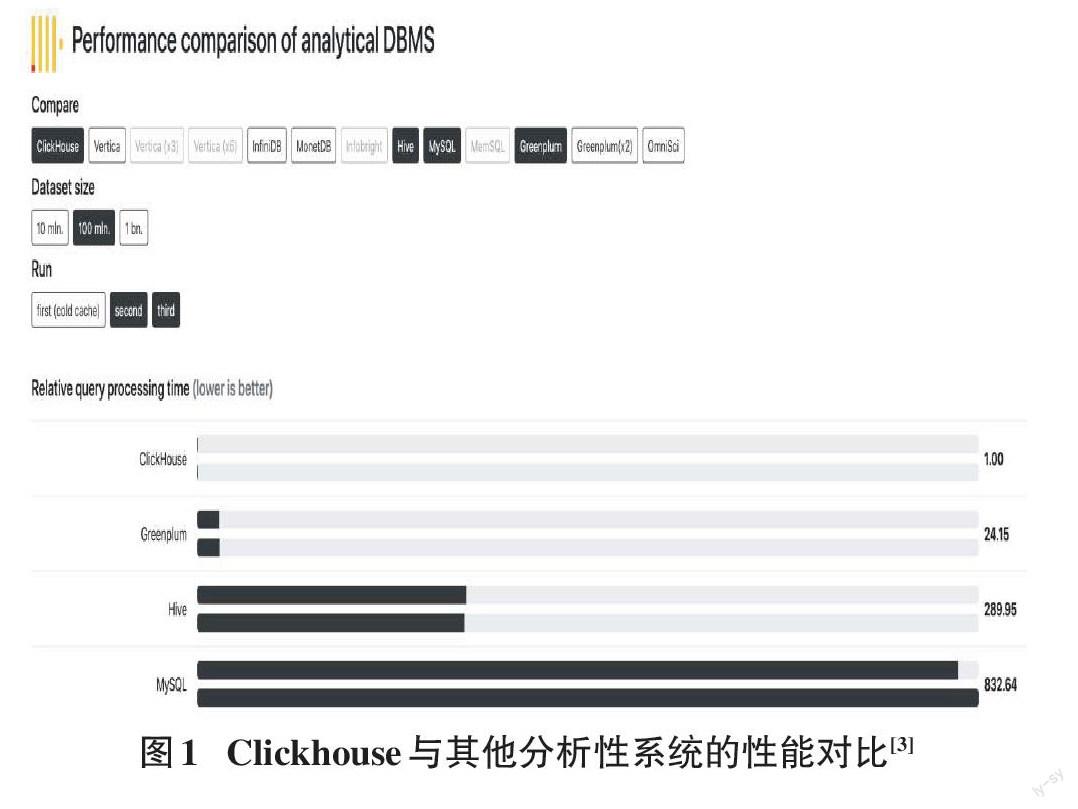
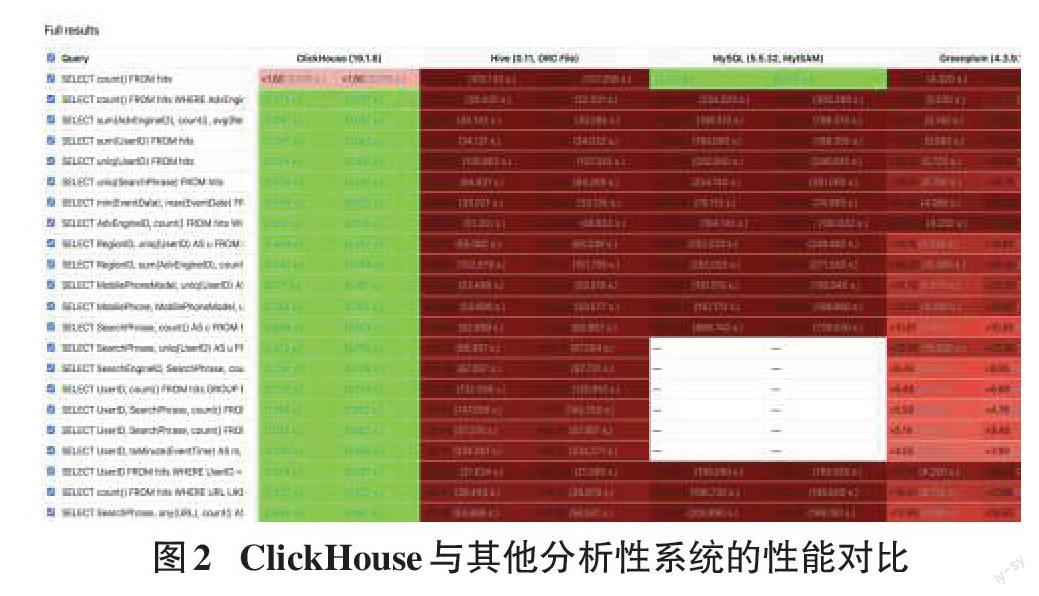
Yandex在2016年6月15日開源了一個數據分析的數據庫管理系統,即ClickHouse,它是分布式實時分析型列式存儲數據庫管理系統,主要用于數據分析領域。開源時間雖短,但是社區熱度高,跑分超過很多流行的商業數據庫軟件。各個大廠紛紛跟進大規模使用。今日頭條內部用ClickHouse來做用戶行為分析,內部一共幾千個ClickHouse節點,單集群最大1200節點,總數據量幾十PB,日增原始數據300TB左右。騰訊內部用ClickHouse做游戲數據分析,并且為之建立了一整套監控運維體系。攜程內部從2018年7月開始接入試用,目前80%的業務都跑在ClickHouse上。每天數據增量十多億,近百萬次查詢請求。快手內部也在使用ClickHouse,存儲總量大約10PB,每天新增200TB,90%查詢小于3秒[2]。
1.2 為什么需要ClickHouse
為何ClickHouse獲得了如此廣泛的關注,得到了社區的青睞,也得到了諸多廠商的應用呢?
企業目前使用的傳統關系型數據庫在數據規模比較小、索引大小適合內存、數據緩存命中率足夠高的情形下能正常提供服務。但殘酷的是,這種理想情形最終會隨著業務的增長走到盡頭,查詢會變得越來越慢。雖然可通過縱向擴展數據庫來解決問題,通過增加更多的內存或者訂購更快的磁盤等,但這只是拖延解決實質問題。
在未來數字化油田的實時數倉工作中,日志量劇增,雖然經過數倉的分層以及數據匯總層通用維度指標可以進行預計算,但有些個性化的分析場景還是需要直接編寫程序或數據庫查詢語句,這種情況下hive SQL、spark SQL的查詢性能也無法滿足需求[4]。
(1)數據時效性:傳統方案中只能拿到次天數據,但想要獲得及時的實時數據,復合指標、多維度指標生成需要整個數據鏈路提供實時數據。
(2)通用指標體系:傳統方案中只能針對每個分析對象創建一個結果表,但想要獲得每個分析對象可支持所有指標,需要更適合的數據模型支持更多的分析對象[5]。
(3)靈活的數據分析:傳統方案中只能“選擇”“連接”“分組”,但想要獲得無限制的交互式分析,獲得自定義維度,需要跨數據庫查詢能力。
(4)大寬表:傳統方案中窄表嚴格按照數據庫設計三范式。這么設計為的是盡量減少數據冗余,但是缺點是修改一個數據可能需要修改多張表。為了查詢性能的提高與便捷,在業務、數據提取轉換和加載、指標屬性、數據來源等角度來看,讓高度內聚的屬性、描述、度量放在一張邏輯上的數據庫表中,這對于刷新效率、容錯能力、擴展能力都是一個很大的挑戰。以空間換時間,便于訓練迭代、減少表關聯數量,修改少量數據時不需要改多張表[6-7]。
在即將到來的大數據時代,面臨的難題有三:計算和存儲的成本、流水線式工作流程、高峰每秒查詢率、95%的查詢時間[5]。如果需求是解決怎樣方便快捷地查詢出結果,需要一個數據分析引擎。
1.3 ClickHouse建設架構
快是Clickhouse的最大優勢,還有集群的擴展能力,相比hadoop套件也更容易部署,其核心都是圍繞如何在數據分析場景下做到極致的快,在存儲結構和計算并行上都有巧妙的設計[8]。
1.3.1 OLAP場景的特點
讀多于寫:
不同于事務處理場景,在原地進行大量增加、刪除、修改操作,數據分析場景通常更加關注寫入吞吐,要求海量數據能夠盡快導入完成。一旦導入完成,歷史數據往往作為存檔,不會再做更新、刪除操作。將數據批量導入后,再進行任意維度的靈活探索、制作報表等。
數據一次性寫入后,業務人員需要嘗試從各個角度對數據進行分析,發現業務變化的趨勢。在反復試錯、不斷調整、持續優化的過程中,數據的讀取次數多于寫入次數。這就要求底層數據庫為這個特點做專門設計,而不是盲目采用傳統數據庫的技術架構。
在數據分析場景中,通常存在一張或是幾張多列的寬表(例如M科室做產能區塊投產效果查詢庫,需要連續多年跟蹤月產量,X科室做數據回遷視圖時需要多表聯合查詢)。對數據分析處理時,選擇其中的少數幾列作為維度列、其他少數幾列作為指標列,然后對全表或某一個較大范圍內的數據做聚合計算。這個過程會掃描大量的行數據,但是只用到了其中的少數列,而聚合計算的結果集小得多。
1.3.2 ClickHouse存儲層
ClickHouse從數據分析場景需求出發,定制開發了一套全新的高效列式存儲引擎,并且實現了數據有序存儲、主鍵索引、稀疏索引、數據分享、數據劃片、數據生存時間、主備復制等豐富功能。以上功能共同為ClickHouse極速的分析性能奠定了基礎。
1)列式存儲
與行存將每一行的數據連續存儲不同,列存將每一列的數據連續存儲。相比于行式存儲,列式存儲在分析場景下有著許多優良的特性。
(1)在行存模式下,數據按行連續存儲,所有列的數據都存儲在一個數據塊中,不參與計算的列在輸入輸出時也要全部讀出,讀取操作被嚴重放大。而列存模式下,只需要讀取參與計算的列即可,極大地減低了輸入輸出消耗,加速了查詢。
(2)同一列中的數據屬于同一類型,壓縮效果顯著。列存往往有著高達十倍甚至更高的壓縮比,節省了大量的存儲空間,降低了存儲成本。更高的壓縮比意味著更小的數據規模,從磁盤中讀取相應數據耗時更短。高壓縮比意味著同等大小的內存能夠存放更多數據,系統緩存效果更好。
官方數據顯示,通過使用列存,在某些分析場景下,能夠獲得100倍甚至更高的加速效應。
2)主鍵索引
ClickHouse支持主鍵索引,它將每列數據按照索引粒度(默認8192行)進行劃分,每個索引粒度的開頭第一行被稱為一個標記行。主鍵索引存儲該標記行對應的主鍵的值。
對于where條件中含有主鍵的查詢,通過對主鍵索引進行二分查找,直接定位到對應的索引粒度,避免了全表掃描從而加速查詢。
但是值得注意的是:ClickHouse的主鍵索引與MySQL等數據庫不同,它并不用于去重,即便主鍵相同的行也可以同時存在于數據庫中。要想實現去重效果,需要結合具體的表引擎ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree實現。
3)數據TTL
在數據分析場景中,數據的價值隨著時間流逝而不斷降低,多數業務出于成本考慮只會保留最近幾個月的數據,ClickHouse通過TTL提供了數據生命周期管理的能力。
1.3.3 ClickHouse計算層
ClickHouse在計算層做了非常細致的工作,竭盡所能榨干硬件能力,提升查詢速度。它實現了單機多核并行、分布式計算、向量化執行與SIMD指令集、代碼生成等多種重要技術。
1)多核并行
ClickHouse將數據劃分為多個分片,每個分片再進一步劃分為多個索引粒度,然后通過多個CPU核心分別處理其中的一部分來實現并行數據處理。在這種設計下,單條查詢就能利用整機所有CPU。極致的并行處理能力極大地降低了查詢延時。
2)分布式計算
除了優秀的單機并行處理能力,ClickHouse還提供了可線性拓展的分布式計算能力。ClickHouse會自動將查詢拆解為多個任務下發到集群中,進行多機并行處理,最后匯聚結果。
3)向量化執行與SIMD指令集
ClickHouse不僅將數據按列存儲,而且按列進行計算。傳統事務分析數據庫通常采用按行計算,原因是事務處理中以單元點查詢為主,數據庫查詢語句計算量小,實現這些技術的收益不夠明顯。但在數據分析場景下,單個查詢語句所涉及計算量可能極大,將每行作為一個基本單元處理會帶來嚴重的性能損耗。
1.3.4 ClickHouse建設
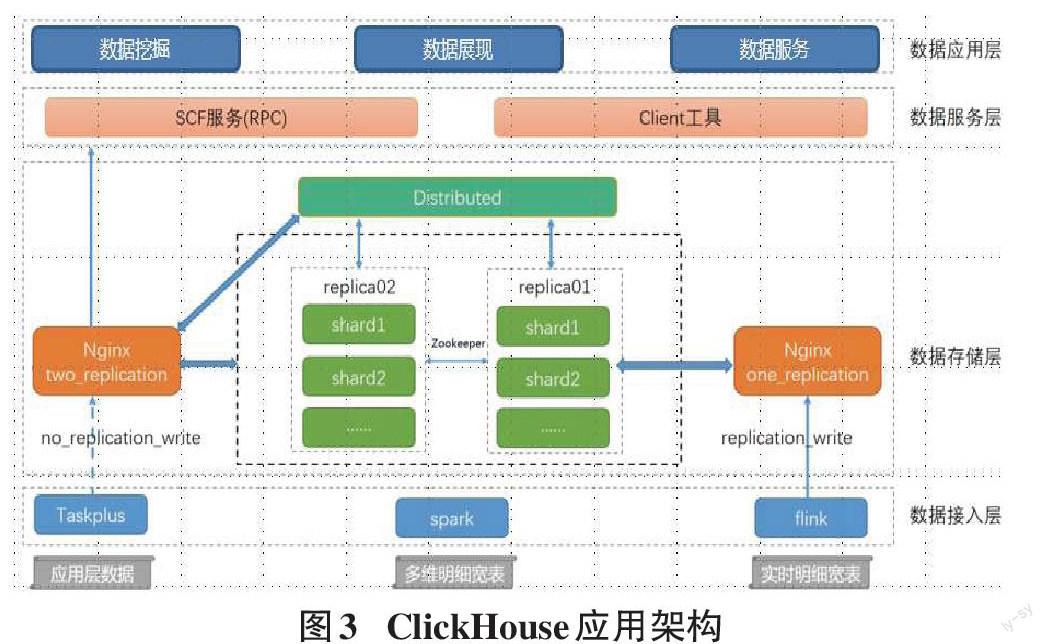
依據數據的流向將ClickHouse的應用架構劃分為4個層級:
1)數據接入層
提供了數據導入相關的服務及功能,按照數據的量級和特性抽象出三種ClickHouse導入數據的方式。
方式一:數倉應用層小表導入
這類數據量級相對較小,且分布在不同的數據源如hdfs、es、hbase等,這時提供基于DataX自研的TaskPlus數據流轉+調度平臺導入數據,單分區數據無并發寫入,多分區數據小并發寫入,且能和線上任務形成依賴關系,確保導入程序的可靠性。
方式二:離線多維明細寬表導入
這類數據一般是匯總層的明細數據或者是用戶基于Hadoop生產的大量級數據,基于Spark開發了一個導入工具包,用戶可以根據配置直接拉取hdfs或者hive上的數據到ClickHouse,同時還能基于配置查詢語句對數據進行提取轉換和加載處理,工具包會根據配置集群的節點數以及ClickHouse集群負載情況對本地表進行高并發的寫入,達到快速導數的目的。
方式三:實時多維明細寬表導入
實時數據接入場景比較固定,封裝了通用的ClickHouseSink,將每日百億級的數據通過Flink接入ClickHouse,ClickHouseSink也提供了“單次導入數據量”及“單次導入時間間隔”供用戶選擇。
2)數據存儲層
數據存儲層采用雙副本機制來保證數據的高可靠,同時用代理集群,通過域名的方式進行讀寫操作,實現了數據均衡及高可靠寫入,且對于域名的響應時間及流量有對應的實時監控,一旦響應速度出現波動或異常能在第一時間收到報警通知。
3)數據服務層
對外:將集群查詢統一封裝為scf服務,供外部調用。
對內:提供了客戶端工具直接供工程師及研發人員使用。
4)數據應用層
埋點系統:對接實時集群,提供秒級別的數據分析查詢功能。
用戶分析平臺:通過標簽篩選的方式,從用戶訪問總集合中根據特定的用戶行為捕獲所需用戶集。
商業智能:提供數據應用層的可視化展示,對接單分片多副本集群,可橫向擴展。
2 結論
在數據量日益增長的當下,傳統數據庫的查詢性能已滿足不了業務需求。在不遠的將來,隨著油田數字化進程日益加深,在大數據分析領域中,傳統的大數據分析也需要不同框架和技術組合才能達到最終的效果,大數據分析在人力成本、技術能力和硬件成本上以及維護成本上變成了昂貴的事情。
而ClickHouse在數據分析領域的快速崛起引起了的注意,由于ClickHouse正是以不依賴Hadoop生態、安裝和維護簡單、查詢速度快、可以支持SQL等特點在大數據分析領域越走越遠。當前社區仍舊在迅猛發展中,相信后續會有越來越多好用的功能出現。如果引入ClickHouse提供高可用集群環境,結合大數據生態定制一套完善的數據分析方案,打造完備的運維管理平臺以降低維護成本,將極大地助力油田數字化建設快捷迅猛發展。
參考文獻:
[1] Bernard Marr.大數據實踐[M].北京:電子工業出版社,2020:19-22.
[2] liuzx32.簡書:ClickHouse概述[EB].(2018-12-29)[2021-07-21].https://www.jianshu.com/p/350b59e8ea68.
[3] Wping_1c08.簡書:Flink+Clickhouse在廣投集團實時數倉的最佳實踐[EB].(2021-05-07)[2021-07-21].https://www.jianshu.com/p/4d521a62d534.
[4] 過往記憶.CSDN:Clickhouse的實踐之路[EB].(2021-12-17)[2021-07-21].https://iteblog.blog.csdn.net/article/details/111 351075.
[5] iteye_4537.CSDN:解耦寬表體系[EB].(2012-03-09)[2021-07-21].https://blog.csdn.net/iteye_4537/article/details/82296002?ops_request_misc=%257B%2522request%255Fid%252 2%253A%2522165726550216781685339704%2522%252C%2522scm%2522%253A%252220140713.130102334..%252 2%257D&request_id=165726550216781685339704&biz_id=
0&utm_medium=distribute.pc_search_result.none-task-blog-?? ?2~blog~sobaiduend~default-1-82296002-null-null.185^v2^control&utm_term=%E8%A7%A3%E8%80%A6%E5%AE%BD%E8%A1%A8%E4%BD%93%E7%B3%BB&spm=1018.2226.30
01.4450.
[6] SmartShylyBoy.CSDN:一個例子搞懂寬表和窄表的區別[EB].(2018-11-13)[2021-07-21].https://blog.csdn.net/SmartShylyBoy/article/details/84026074?ops_request_misc=%257B%2522
request%255Fid%2522%253A%252216572655581678166786
8016%2522%252C%2522scm%2522%253A%252220140713.
130102334..%2522%257D&request_id=1657265558167816678
68016&biz_id=0&utm_medium=distribute.pc_ search_result.none-task-blog-2~all~sobaiduend~default-1-84026074-null-null.142^v32^down_rank,185^v2^control&utm_term=%E4%B8%
80%E4%B8%AA%E4%BE%8B%E5%AD%90%E6%90%9E%E6%87%82%E5%AE%BD%E8%A1%A8%E5%92%8C%E7%AA%84%E8%A1%A8%E7%9A%84%E5%8C%BA%E5%88%AB&spm=1018.2226.3001.4187.
[7] 老茶葉館.51CTO博客:認識clickhouse[EB].(2020-12-06)[2021-07-21].https://blog.51cto.com/imysql/3171455.
[8] 阿里云云棲號.知乎:ClickHouse深度揭秘[EB].(2019-12-19)[2021-07-21].https://zhuanlan.zhihu.com/p/98135840.
【通聯編輯:代影】
猜你喜歡
中國市場(2016年36期)2016-10-19 04:41:16
中國市場(2016年36期)2016-10-19 03:31:48
中國市場(2016年35期)2016-10-19 01:30:59
商(2016年27期)2016-10-17 06:26:00
今傳媒(2016年9期)2016-10-15 23:35:12
今傳媒(2016年9期)2016-10-15 22:09:11
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
