面向多故障模式的多尺度相似性集成壽命預測
2022-06-07 01:31:22舒俊清許昱暉夏唐斌潘爾順奚立峰
上海交通大學學報 2022年5期
設備剩余使用壽命(RUL)預測對于提高設備可靠性和預警故障失效具有重要意義.隨著傳感器和在線采集技術的發展,海量數據驅動的預測方法已成為RUL預測領域的主流方法,可大致分為統計與機器學習方法兩類.在工業界,相較于統計方法使用的一些假設限制,機器學習方法應用相對較為廣泛.
按照預測步驟的不同,當今主流機器學習方法主要包含RUL直接映射法與基于相似性的方法兩類.前者借助機器學習算法直接建立狀態監測數據特征與RUL間的映射關系,常用的算法有支持向量機(SVM)、隱馬爾科夫模型與人工神經網絡等.但是由于設備的壽命長度間可能存在較大差異,在歷史數據不足時,這類方法的準確性相對較低.而基于相似性的方法通過構建并匹配退化曲線獲得的相似度來預測RUL,可有效避免上述問題.
自從基于相似性的方法被提出以來,大量研究已證明其在RUL預測領域的有效性.文獻[12]將基于相似性的回歸與證據理論相結合,無需運行至失效的退化數據用于參考,即可實現RUL預測.文獻[13]引入核方法雙樣本檢驗(KTST)來評估多維傳感信號的相似度,并采用威布爾分布來提供RUL置信區間.此外,一些學者直接將多維狀態監測數據轉化為一維健康指標(HI)曲線,相較于使用多維退化曲線進行相似性匹配,可有效減小相似度測量的計算規模以提高預測速度.目前,線性回歸模型、主成分分析、深度神經網絡等算法已被學者們用于HI的建立.文獻[3]和[15]將雙向長短期記憶(LSTM)結構嵌入自編碼器中以構建準確性更高的HI,并提出了一種零中心化規則,應對設備初始退化水平間的差異.文獻[16]采用受限玻爾茲曼機構建設備HI,并綜合利用相似性方法與雙向LSTM模型,以提高RUL預測精度.
上述基于相似性的研究已取得較好成果,但仍存在一些可改進之處:一是不同設備退化時會出現多種失效模式,失效模式不同的設備退化過程往往也存在差異,現有研究通常并未考慮失效模式,而是將所有退化軌跡一起進行相似性匹配,計算量大且影響匹配準確度.二是為確保每條退化軌跡都能參與匹配,現有研究通常將匹配時間尺度設置為某個小于所有軌跡長度的常數.在實際中,某些測試設備可提供的退化軌跡可能很短,這種單尺度設置方法將導致其他測試設備退化數據無法被充分利用,從而造成較高的預測誤差.此外,各測試設備的退化速度也不一致,難以確定適合所有設備的最優匹配尺度.三是現有基于一維健康指標相似性的研究,通常僅進行RUL的單點預測,而無法表征預測不確定度.在實際工程應用中,以概率形式表達預測結果,描述設備RUL預測的不確定性,對制定合理的維護方案、實現預知維護具有重要意義.
針對上述問題,本文提出多故障模式下多尺度相似性集成(MFM-MSEN)方法.該方法通過故障模式識別,實現分類相似性匹配,并降低匹配復雜度,在此基礎上提出多尺度集成策略,提高預測精度與泛化性能,最終擬合出RUL概率分布以提供預測置信區間.將MFM-MSEN方法在數據集中應用,證明了其在多故障模式下應對退化差異的優越性.
1 問題描述
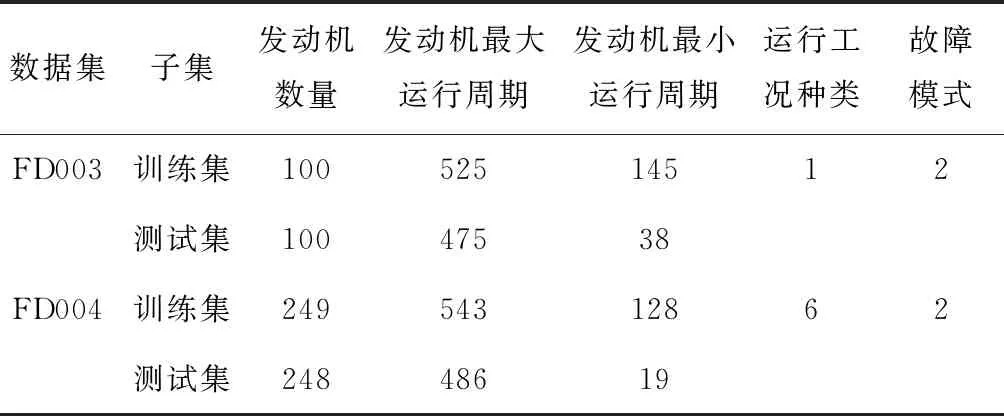
以渦扇發動機為研究對象,分析美國國家航空航天局(NASA)的民用模塊化航空推進系統仿真(CMAPSS)數據集,旨在提出一種多尺度相似性方法,以提高渦扇發動機在多故障模式下的RUL預測精度.CMAPSS數據集通過模擬渦扇發動機的退化過程所得,由故障模式與工況種類數不同的4個子集組成,記錄了21個由傳感器實時采集的狀態信號及3個運行工況參數,其中數據集采用的時間單位為運行周期.
考慮到一些狀態信號與退化特征無關,其數值僅在幾個常數上波動,為了使HI更好地表征退化過程,最終選用了傳感器編號為2、3、4、 7、8、9、 11、12、 13、 14、15、 17、 20與21的14個信號.此外,渦扇發動機在運行初期幾乎不會衰退,本文引入了分段線性函數來對RUL標簽進行修正.根據文獻[13],將臨界值設置為125,RUL標簽中大于125的部分將被修正為125.
跡與所有的訓練發動機退化軌跡進行匹配,則會影響匹配的準確度,并且匹配規模的增大會進一步導致匹配計算量與時間消耗的增加.此外,子集FD004包含6種運行工況,這意味著同一個發動機單元在其運行過程中,工況可能會發生變化,而不同工況下其狀態信號的波動范圍也不一致,從而造成了預測難度的增加.
2 基礎理論方法
2.1 自編碼神經網絡


編碼器對輸入網絡的高維數據進行編碼,壓縮為低維特征向量,即隱含層輸出,而解碼器則將其解碼為′,期望還原成輸入數據.AE的訓練目標即最小化重構誤差,則有

(1)
在此種無監督訓練方式下,只使用正常狀態數據訓練AE,重構誤差的大小則可有效反映設備異常程度.此外,通過采用合適的非線性激勵函數,編碼器可將高維輸入數據非線性映射至低維特征數據,且該低維數據可通過解碼器進行還原,據此有效克服線性降維方法造成的信息損失問題.因此,本研究將自編碼網絡用于健康指標建立以及故障特征提取之中.
2.2 支持向量機
支持向量機是一種有監督的二分類模型,其核心思想是找到一個合適的超平面能在最大限度上將不同類別樣本分開.單個SVM模型只能處理二分類問題,但通過設計多個SVM模型,并采用投票法綜合多個模型的結果可實現多分類功能.本文采用“一對一”SVM多分類方法,其思想是在任意兩類樣本之間設計一個SVM模型, 對于包含′類樣本的訓練集,則需設計′(′-1)2個SVM模型假定訓練集樣本總數為,即={(,), (,), …, (,)},其中維向量∈,類標簽∈{1, 2, …,′},=1, 2, …,,那么第類與第類樣本間SVM模型的優化問題可表示為
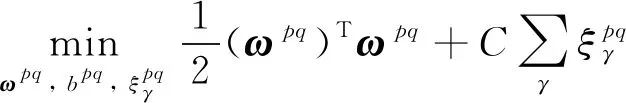
(2)
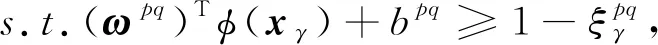
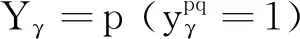



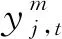
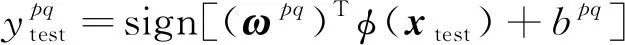
(3)
1933年春,持志中學,即私立持志學院①今上海外國語大學的前身。1924年 12月,何世楨與其弟何世枚,在上海體育會西路興辦“私立持志大學”。校名源自何園主人何芷舠的別字“汝持”。附屬中學,成立了持鐘劇社。持鐘劇社成立時恰逢左翼戲劇運動的浪潮。1933年,《持志半月刊》刊載的一篇題為《持鐘劇社成立之前》的文章,很好地體現了持鐘劇社的創社宗旨:
2.3 核密度估計
核密度估計(KDE)是一種用于估計未知概率密度函數的非參數方法,其在研究數據分布特征時,不做任何先驗假定,目前在理論和應用領域都受到了高度重視.假定,, …,為獨立同分布的個樣本點,其在KDE下的概率密度函數(PDF)為
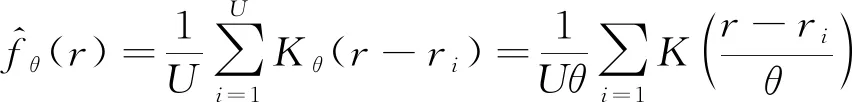
(4)
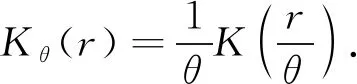
3 MFM-MSEN預測方法
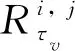

3.1 基于AE重構誤差的健康指標建立
作為相似性方法的基礎,HI的構建能簡化退化模型,進而提升相似性匹配的效率.考慮到在實際工業環境中,往往存在一些未監控因素會造成設備間的差異.若直接使用多維監測數據的壓縮表示作為HI,則魯棒性較差.因此,本文基于AE重構誤差來建立健康指標.
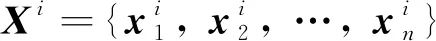


(5)

3.2 基于AE-SVM的故障模式識別
為提升多故障模式下相似性匹配的速度與準確度,將AE-SVM與時序加權預測相結合,對設備故障模式進行識別與分類.為提取更多故障模式信息,減小非線性信息損失,以AE編碼器輸出的低維特征向量,即原始狀態監測數據的壓縮表示為故障特征.考慮到設備運行初期的故障特征往往并不明顯,使用-means對故障模式進行聚類時,只選用其即將失效時的特征.假設存在類設備故障,聚類后第類故障的特征矩陣為

其中:為×矩陣,為第類故障的故障特征樣本數量,為故障特征的維度,即AE隱含層神經元的數量.對應的類標簽可表示為×1矩陣=[…]

老板娘呢?老板娘站在榆樹下,轉著金環、銀環、玉環的手腕剔指甲,看“老黃”帶著他的儺戲班大包小包回村去,村里柴門聞吠,風雪夜歸人,狗吠兒啼之后,鬧完梁二狗的洞房,再灌一肚子的黃粱酒,睡!人聲漸寂,一盞一盞燈火熄滅,他們布下的這一出黃粱夢,終于弄到了錢過年,也沒有傷到人,自己自薦做老板娘,十余日的辛勞,還是值得的。明年鳥窩大師他們還會繼續設局吧,這樣的浮華世界,桃源故事,就像酒席上面開胃的山珍野菜,在這個盛世華年里,當然可以賣出好價錢。

(6)
=1, 2, …,

群眾文化不僅體現了國家的特色,還在一定程度上代表著民族的特色。我國是一個多民族國家,各民族對群眾文化都有自身的見解,各民族的文化建設方式也各有不同。但是,文化建設的本質是一成不變的,都是在娛樂活動中,滿足人民群眾的精神需求,并提高人民群眾的文化素養,進而促進國家的快速發展。通常情況下,文化建設在文化藝術活動的基礎上,應用各種各樣的文化內容、管理模式,提升文化建設水平。

(7)
=1, 2, …,
而對于IV類潤滑劑而言,由于其主要成分為合成油聚α烯烴,其對橡膠材料各類性能參數的影響略有不同。當被浸泡在IV潤滑油中時,丁腈橡膠吸入潤滑油的量小于溶解在潤滑油中的橡膠添加劑的量,內部的網狀結構被壓縮,橡膠試樣內部分子鏈的自由度變小,導致其體積減小、硬度增大、拉斷伸長率減小;而體積增大使得內部的網狀結構被壓縮,增大了網狀鏈結構中的相互作用力,使得其抗拉伸能力有所增強,所以其斷裂拉伸強度增大。
3.3 多時間尺度相似性匹配
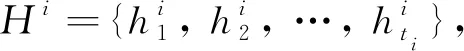

(8)
=1, 2, …,-+1
由此可見,時間尺度是影響相似性匹配準確性的關鍵因素.由于各測試軌跡長度間差異較大,若采用單個時間尺度,將無法充分利用所有測試樣本的數據信息.此外,退化速率不同的測試樣本適合的匹配尺度也不同.例如對于正在加速衰退的測試樣本,由于其HI值變化十分迅速,采用較短的軌跡片段即可準確匹配.
(2)學生明確測試的自變量(測試橋的結構),控制無關變量(橋的長度、跨度),掌握科學的實驗方法,對實驗過程作好記錄。
針對上述問題,本研究提出了多尺度集成(MSEN)策略,將退化軌跡截取為多個不同長度的軌跡片段.假定匹配時間尺度集合為{,, …,},其中為尺度數量,且有0<<<…<,則尺度需滿足以下條件:
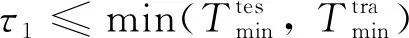
(9)
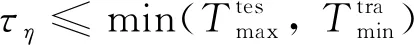
(10)

混合式教學的一大優勢就是對學生的考核是過程性的全方位的。本課程對學生的考核包括線上線下兩部分,線上主要包括在線作業、在線測試和在線學習行為;線下主要包括學生的出勤、學生課堂表現和小組匯報成績。其中,學生的在線學習行為主要包括在線時長、課程論壇、學習材料學習、學習筆記等等。線上的成績可以通過系統設定,自動生成。線下成績可以導入平臺,通過平臺實現對學生高效的綜合管理與評價,進而激勵學生持續認真的學習。

(11)
=1, 2, …,
在每個時間尺度下,選擇與測試樣本相似度較高的參考樣本用于預測RUL概率分布.

3.4 基于MSEN策略的RUL分布預測

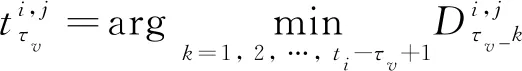
(12)
=1, 2, …,
基于參考樣本,測試樣本的RUL預測值可表示為
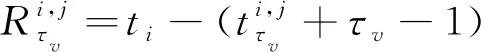
(13)
=1, 2, …,

(14)

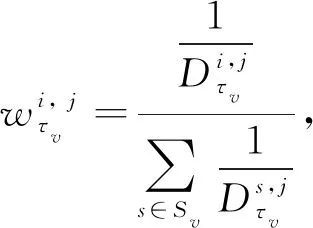
∈,=1, 2, …,
(15)


(16)
式中:為測試樣本的RUL.
基于KDE的RUL概率分布擬合如圖4所示,其中:?為核密度值;為剩余壽命預測值.依據預測值和對應的權重,基于KDE的RUL概率分布預測可提供不同水平的置信區間.此外,通過計算所擬合分布的均值,可得到最終的RUL點估計值為

(17)
通過集成多個尺度的預測值,具有不確定性的RUL最終預測結果可以為預知維護提供更準確和可靠的支持.

4 案例研究
4.1 數據預處理
由于不同工況下傳感信號的波動范圍不同,所以對于包含6種工況的FD004,在歸一化處理前需根據工況參數,對傳感信號進行-means聚類.對子集中屬于同種工況的信號數據,本文采用最小-最大值規范化方法來消除量綱的影響,公式如下:
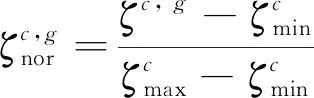
(18)
由于難以選擇使預測誤差最小的最優時間尺度,本文提出了MSEN策略集成多尺度RUL預測結果,從而提高預測的準確性與泛化性能.由圖3可知,測試樣本的預測結果根據與其相似的多尺度參考軌跡片段得到.假設在時間尺度下,參考樣本中與測試樣本最相似的軌跡片段的起始時刻可以表示為

選擇包含兩種故障模式的子集FD003與FD004用于分析,具體信息如表1所示.由表1可知,訓練集與測試集可提供的運行周期數間存在較大差異.訓練集記錄了訓練發動機單元從開始運行至失效的全壽命周期狀態監測數據,測試集則只包含測試發動機單元運行至失效前某個時刻的狀態監測數據,需要對該時刻設備的 RUL進行預測.此外,CMAPSS數據集提供了各測試發動機的RUL實際值,以驗證預測方法的性能.在子集FD003與FD004中,發動機單元既可能因為高壓壓氣機出現故障而失效,也可能由于渦扇故障而失效,本文中以“故障1”和“故障2”來區分兩類故障.故障模式不同的發動機單元,退化數據的變化趨勢也會存在差異.因此,在進行相似性匹配時,若將測試發動機退化軌
4.2 預測實現
(1) 健康指標建立.
使用聚類后的故障特征訓練故障分類模型,模型采用高斯核函數,懲罰系數設為1.最終,綜合考慮10個時刻的故障特征,加權系數設為0.4,識別測試單元的故障模式.

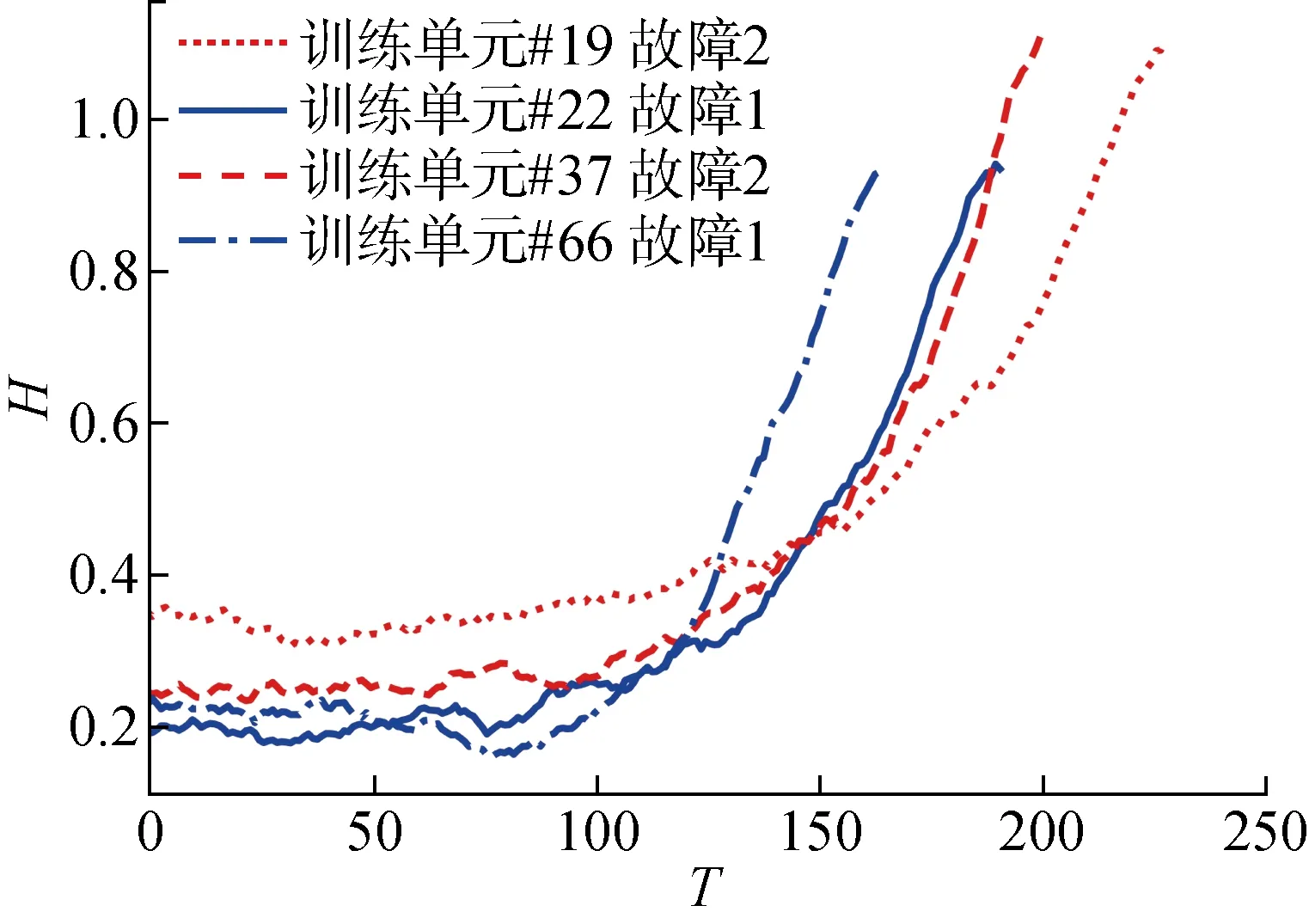
子集FD003部分訓練單元的HI曲線如圖5所示.在運行初期,軌跡的斜率接近于0,在即將失效時,HI值迅速上升.這表明退化軌跡可較好地表征發動機的退化過程.此外,可發現圖5中處于兩種不同故障模式的訓練單元最大健康指標值間存在一定差異,側面證明了多故障模式識別以及分類相似性匹配的必要性.
根據全國水資源綜合規劃成果,受水區多年平均水資源總量為434.76億m3,占全國水資源總量的1.53%,其中地表水資源量為232.41億m3,地下水資源量為284.54億m3。
(2) 多故障模式識別.
在多故障模式識別中,首先需確定提取故障特征的維數.通過AE對訓練數據的重構誤差大小來判斷特征向量是否包含足夠的故障信息,同時考慮重構誤差值與故障特征聚類復雜度,設定特征維數為2.因此,AE編碼器與解碼器之間的隱含層2神經元數目設置為2,網絡其他參數與HI建立模型相同,使用訓練單元全壽命周期的數據對網絡進行訓練.為確保發動機已出現明顯故障,僅選擇每個訓練單元最后10個運行周期的特征用于聚類分析,訓練集的聚類效果如圖6所示, 其中:和分別為提取的故障特征1與故障特征2.由圖6可知,在FD003與FD004中兩類故障均有顯著差異,表明故障特征提取與聚類方法具有較好的泛化性.
在保證發動機正常運行的情況下盡量增加訓練數據樣本,本文選擇各訓練單元總壽命周期中前20%的狀態監測數據用于訓練HI建立模型.模型參數如表2所示.輸入層與輸出層神經元數量均設置為所選信號的數量.為增強模型的非線性映射能力,采用3個全連接層為隱含層.其中,隱含層1與隱含層3均采用 ReLU激勵函數,有助于實現網絡的稀疏連接.考慮到歸一化的信號數據范圍是 [0, 1],輸出層采用tanh激勵函數對數據進行規范化處理.模型訓練時批尺寸設為128,最大訓練周期數設為30,采用自適應矩估計算法作為優化器.設定平滑因子為20,對AE模型的重構誤差進行平滑化處理,以生成最終的HI.
(3) 多尺度匹配.
鑒于研究內容具有極強的專業性及發表文章語言的局限性,為使更多的國內讀者及時了解竹藤研究前沿進展,本刊將及時跟蹤GABR成果,對原文內容進行精簡、提煉,以中文形式呈現給讀者。本期介紹全球首次報道的棕櫚藤基因組的情況。
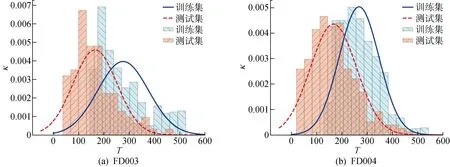
數據集運行周期數分布如圖7所示,其中:為概率密度.由圖7與表1可知,訓練集與測試集退化軌跡長度間均存在較大差異,這也意味著渦扇發動機的退化速度各不相同.因此,本文針對FD003與FD004分別設計了一個時間尺度集合.為充分利用退化數據信息,將最小尺度設置為測試發動機的最小運行周期數.此外,考慮到過長的軌跡片段將包含過多無用信息干擾匹配,最大尺度應小于100.為避免尺度過多導致匹配時間過長,最終選擇間隔為20的4個時間尺度構成集合.將測試單元按軌跡長度分成四個組別,使用不同數量的時間尺度進行匹配,具體信息如表3所示.


(4) RUL分布預測.
第一個辦法就是在飲食上做出改變。每一樣食物在體內的消化速度是不一樣的,有些食物很快被消化,短時間內就能為身體提供能量。像富含蛋白質和纖維的食物就有助于加快新陳代謝。
完成多尺度匹配后,設定松弛因子為1.5來選擇用于RUL預測的相似參考軌跡.最終,采用帶寬為0.7的高斯核密度估計器,集成多尺度預測結果,擬合RUL的概率分布,如圖8所示.由圖8可知,隨著運行周期的增加,RUL預測值越來越接近于真實值,且置信區間在逐漸縮小,證明了MFM-MSEN方法的有效性.
預設N=20,M=3,L=6,圖2和圖3分別為隨機選取單個SU的信道和功率策略概率演化過程.從圖中可以看出經過200次迭代后,用戶信道選擇概率向量由初始值{1/3,1/3,1/3}最終收斂到{0,0,1},并維持恒定不變.同時用戶在6個功率等級上的選擇概率也同樣的表現,結論與定理1和定理2相符.
3、棚溫控制:下種后棚溫白天保持在30~35℃之間,夜間保持在15℃以上,注意下種后棚內溫度不能超過38℃以上,因為達到40℃高溫時,種子不利于發芽。根據實踐經驗,幼苗出土后,如果溫度超過26℃時,下胚軸會急速伸長,而形成高腳苗,所以幼苗拱土后,白天棚內溫度降到25~22℃之間,特別要注意的是此時晚間棚內溫度不能超過10℃以上,不能低于5℃,控制夜間苗不生長,棚內高溫、高濕會導致幼苗徒長。第一片真葉見長后白天要適當加大棚內溫度,溫度白天保持在28~33℃之間,夜間5~10℃之間。真葉見長后噴一次“金元寶”液肥,可增加植株葉綠素含量及生根量,使幼苗生長旺盛健壯,提高幼苗抗寒能力。

5 結果分析與討論
為消除自編碼神經網絡隨機性的影響,本文取10次重復實驗的結果,用于MFM-MSEN方法的效果驗證.
5.1 預測結果
為更全面地評價預測性能,采用兩個度量標準:均方根誤差(RMSE)以及Score函數.Score函數針對RUL預測中高估RUL會帶來更嚴重的損失這一特性,給予高估RUL更高的懲罰,Score函數及RMSE的計算公式如下:
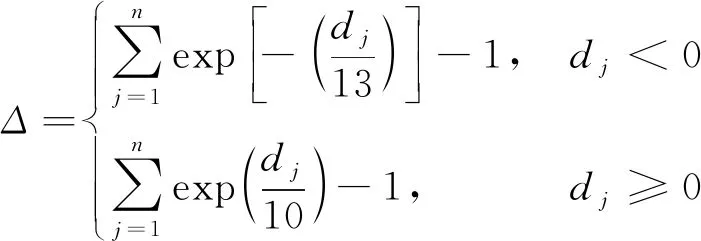
(19)

(20)

將車身擺放到合適的位置,展示其升級后的懸掛減震系統,是展示路虎衛士品質的好方式,滑板公園的坡道也非常適合展示這種定制改裝的效果。
2.1.2 兩種檢測方法陽性與復發時間比較 骨髓形態學檢測復發的5份AML標本中有1份在提前于形態學3個月發現MRD陽性,另外4份同時發現MRD陽性。骨髓形態學檢測復發的4份ALL標本中有1份在提前于形態學1個月發現MRD陽性,另外3份同時發現MRD陽性。
按照RUL標簽從小到大的順序,FD003測試單元的預測結果如圖9所示,其中:為測試發動機按RUL標簽從小到大順序的編號.由圖9可知,總體預測效果較好,RMSE值達到15.07.將MFM-MSEN方法與現有先進研究方法對比,結果如表4所示.由表4可知,MFM-MSEN方法的總計RMSE和Score值達到了所有預測方法中的最低.對于預測難度較高的子集FD004,可發現所提方法的RMSE值接近于所有預測方法中最優值,且Score值達到了所有方法中的最優,證明了MFM-MSEN方法在復雜工況數據集上的優越性.其次,MFM-MSEN方法在FD003上也取得了不錯效果,RMSE值優于其他相似性方法,表明該方法具有較好的泛化能力.
此外,將傳統單尺度方法與所提方法進行比較,傳統方法中采用測試單元最小運行周期數作為匹配時間尺度.由表4可發現,MFM-MSEN方法顯著提升了預測精度,進一步證明了故障模式識別與MSEN策略的有效性.

5.2 故障識別效應分析
為探究故障識別對預測效果的影響,將MFM-MSEN方法與未經故障分類的MSEN方法進行比較,結果如表5所示.其中,提升比率:
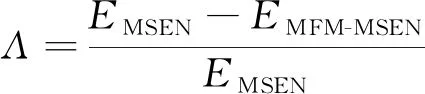
(21)
式中:與分別為對應方法的評價指標值.由表5可知,在兩個子集上,MFM-MSEN的RMSE與Score值均顯著低于MSEN方法,尤其對于FD003,Score值降低高達51.1%.這是由于故障模式相同的發動機單元退化過程通常更為相似,按照故障模式進行分類匹配有助于提高匹配準確性.此外,分類匹配可有效縮小匹配規模與計算量,并且發動機數量越多,匹配規模縮小量越大.因此,MFM-MSEN方法顯著縮短了匹配時間,特別是對于發動機數量較多的FD004,時間縮短接近6 min.

5.3 多尺度集成策略效應分析
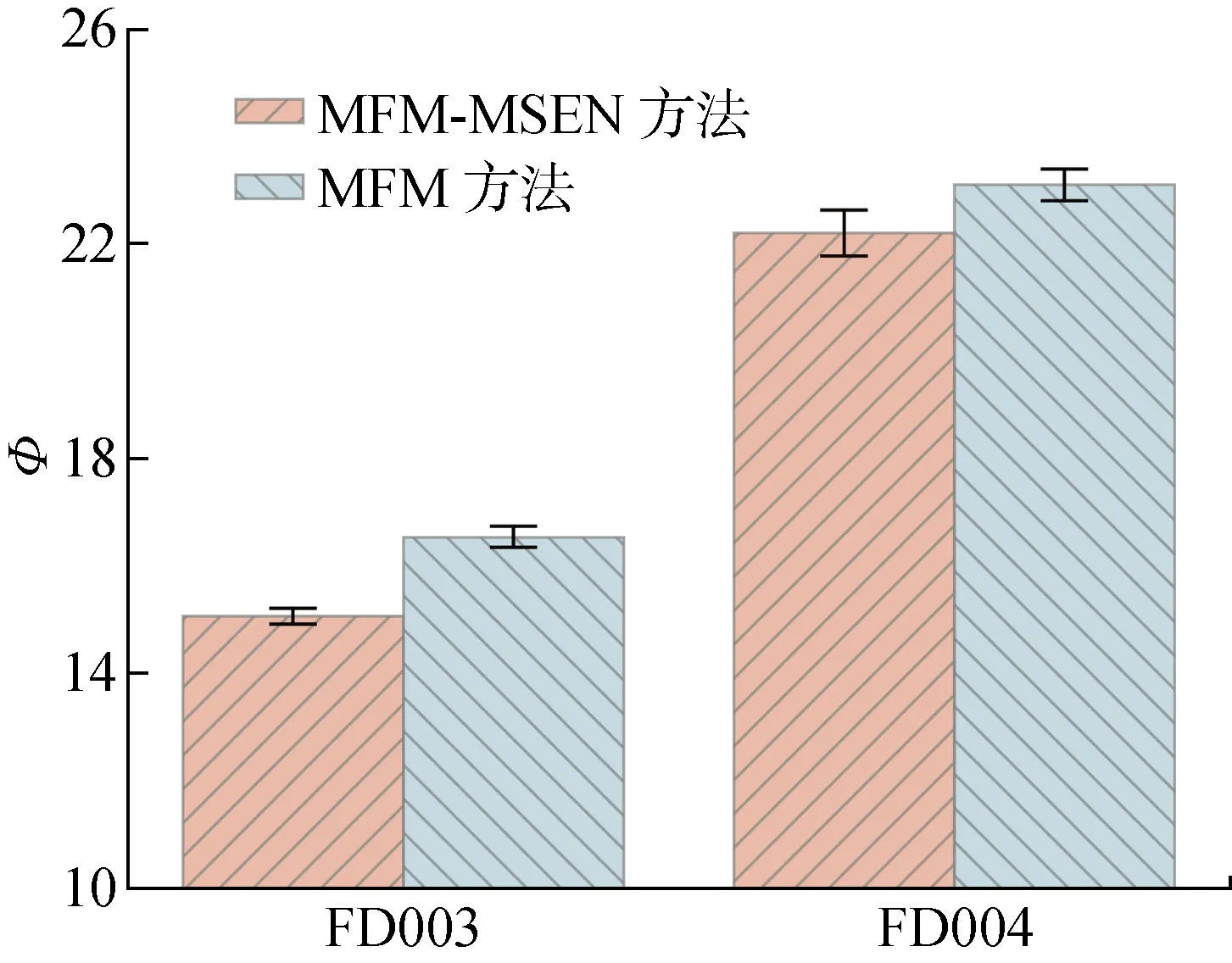
設定測試單元最小運行周期數作為單一匹配尺度,面向多故障模式的單尺度(MFM)方法與MFM-MSEN方法的對比結果如圖10所示.在兩個子集上,MFM-MSEN方法的RMSE值均低于MFM方法.這證明了MSEN策略的優越性,可有效解決單尺度方法造成的退化數據利用率低的問題.
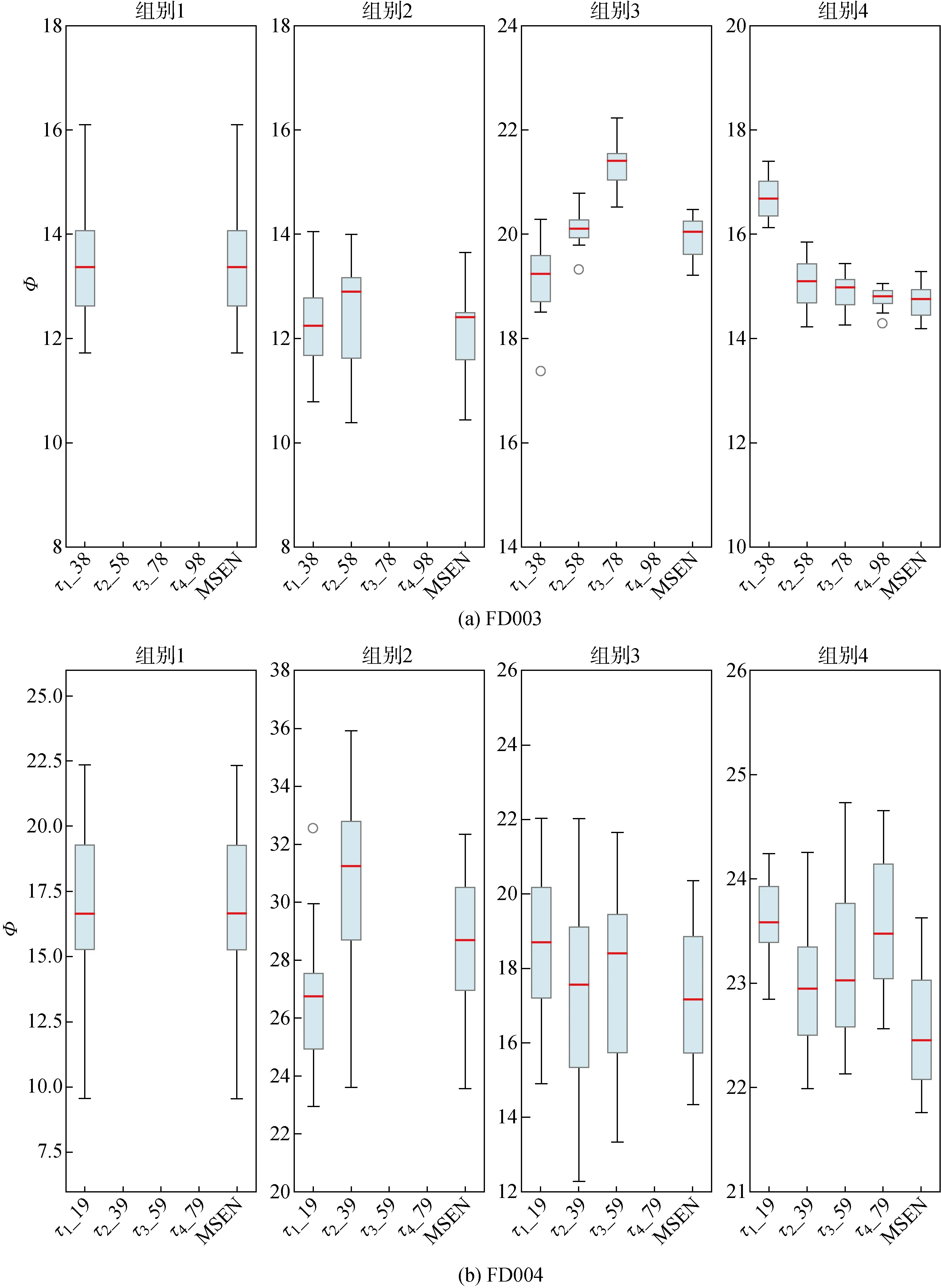
為進一步探究集成策略的必要性,將測試單元按軌跡長度分成4個組別,各組別在不同匹配尺度下的預測結果如圖11所示.可發現各組別最優尺度并不一定是最大或最小尺度,這意味著無法根據軌跡長度直接判斷出最優尺度.而通過集成策略將多個尺度的預測結果結合,可有效避免最優尺度選擇困難的問題.并且在所有測試組別上,多尺度預測的RMSE值均低于或接近最優單尺度.綜上,MSEN策略有效提高了預測泛化性能與精度.
6 結語
考慮到設備故障模式多樣性、退化速度差異性以及可提供數據長度的不一致性,本文提出了MFM-MSEN壽命預測方法.在該方法中,通過故障特征提取與故障聚類等實現故障分類模型的訓練,并設計時序加權預測策略來識別測試設備故障模式,以進行分類匹配,提高預測精度的同時降低了匹配的計算復雜度.此外,該方法提出MSEN策略實現了多尺度相似性匹配,并采用KDE法集成多尺度結果擬合概率分布,有效提高了數據利用率與預測泛化性能,且能提供RUL置信區間.在CMAPSS數據集上驗證方法的效果,相較于現有其他先進方法,MFM-MSEN方法總體上取得了最高的精度,效應分析也進一步證明了故障識別與MSEN策略的優越性.未來將采用更多復雜數據集驗證預測方法的泛化性,并設計相關實驗以量化其魯棒性.此外,可優化多尺度預測結果集成時權重的設置機制,以進一步提升預測性能.
