基于車輛視角數據的行人軌跡預測與風險等級評定*
2022-06-08 02:08:36張哲雨李景行熊光明吳紹斌龔建偉
汽車工程 2022年5期
關鍵詞:模型
張哲雨,呂 超,李景行,熊光明,吳紹斌,龔建偉
(北京理工大學機械與車輛學院,北京 100081)
前言
在智能車領域,行人保護和風險估計近年來受到了極大的關注。在擁擠的城區環境中,汽車往往會在各種路口、轉彎處碰見橫穿馬路的行人。此時,采取合適的駕駛策略既能節省汽車通過路口的時間,也能規避潛在的碰撞風險。在輔助駕駛領域,為了增強駕駛員對關鍵場景的感知和理解,并提供有預見性的駕駛風險警告,許多主動安全系統被開發和提出,其中,行人軌跡預測和風險等級評價是重要一環。
在行人軌跡預測領域,許多學者進行了不同方向的研究。早期的方法通過建立復雜的運動學模型來預測行人軌跡,包括使用卡爾曼濾波器、隨場景切換的線性動態系統等。這類模型通常假設行人具有固定的行為模式,但在城區場景下,行人和車輛均處于高動態場景中,其行動隨時都有可能發生變化。運動學模型計算量大、靈活性低的缺點使其難以充分捕捉人車間的交互。為了克服這種缺陷,近年來,基于數據驅動的行人軌跡預測研究得到了大量關注,包括使用基于長短期神經網絡的方法預測擁擠的街道中行人的行走軌跡、根據行人骨架信息預測行人意圖等。這類方法能夠從大量已知的行人軌跡中隱式地學習行人的行動模式和人群間的交互模式,省去繁瑣的運動學建模步驟。然而,這些工作大多聚焦于路基視角的行人軌跡進行研究。這種路基視角軌跡通常由架設在道路上的傳感器獲取,位于靜止大地坐標系下,具有直觀易于分析的特點,但在實際應用中,這類數據并不能直接由行駛在道路上的車輛直接獲取,實用范圍受到限制。
在行人風險等級評價方面,通常基于碰撞模型的方法來估計車輛和行人之間的碰撞風險。早期的方法中,首先使用卡爾曼濾波或動態貝葉斯網絡等方法預測人與車輛的軌跡,然后計算軌跡之間的重疊概率或風險指標來估計車輛和行人之間的碰 撞 風 險,比 如 碰 撞 時 間(TTC)、車 頭 時 距(THW)、后侵入時間(PET)。在上述研究中,風險估計是通過預測行人的軌跡和對行人和車輛進行復雜動態建模來實現的。然而,這樣的方法仍存在兩個局限性:
(1)使用人工定義的函數定義人車相撞的模型,計算人車軌跡的交叉點或位置概率重合點。然而,這種計算方式難以模擬行人和車輛在真實世界中高度動態的行為交互過程;基于操作的風險估計算法通過引入車輛的行為模式進行碰撞計算,但由于這些方法大多使用路基視角的軌跡,建模運算中須對多個主體同時進行運算,將面臨較高的計算成本。
(2)通過人工設置TTC 閾值或人工劃分不同區域的危險系數來對行人的風險程度進行劃分。這種分類方式高度依賴于人工判斷,并且很可能會受不同研究者主觀認知的影響;另外,也會隨著不同路況、不同交通場景變化而變化,在模型的泛化上將會面臨很大挑戰。
為了克服上述限制,本文中提出了基于車輛視角數據的行人軌跡和風險等級評價模型。
首先,采集、研究了車輛視角行人數據。過去的研究多數使用路基視角行人數據來分別估計行人和車輛的運動,并用于估計駕駛風險。但如前面所述,這類數據通常來源于架設在道路上的靜止攝像頭,并不能直接被行駛中的車輛及時獲取和利用,即使能夠獲取,使用這類數據來計算碰撞風險,也無法避免大量的建模計算。相反,車輛視角數據是基于車載傳感器的數據,所檢測到的行人運動不僅包含行人自身的運動,還包含車輛的運動。通過在相對運動坐標系下簡化行人與車輛之間危險指標的計算,可以避免由于使用路基視角數據導致的復雜運算。
其次,通過數據驅動的方法對車輛視角行人軌跡進行學習和預測。車輛視角數據天然地模擬了人類駕駛員直接接收到的行人信息,使用車輛視角行人軌跡能夠同時對行人和車輛的行為模式進行學習和預測。近年來,遞歸神經網絡(RNN)已被證明在軌跡預測、時間序列模式學習的應用上是簡單而有效的。因此,本文中應用RNN 的變體長短期記憶神經網絡(LSTM),從車輛視角數據中挖掘的行人和車輛的行為與交互模式,實現車輛視角行人軌跡的預測。
最后,對于行人風險等級評價,利用車輛視角行人數據包含豐富行人和車輛動態信息的特點,對行人特征狀態進行了聚類分析。聚類算法作為一種典型的數據挖掘方法,能夠有效地尋找潛在的數據模式。因此,使用聚類算法從車輛視角行人數據中挖掘不同行人的風險特性,并以此為依據訓練了行人危險等級識別器,避免了人工選擇TTC 閾值方法的弊端。此外,基于聚類分析得出的數據類別,使用支持向量機(SVM)訓練風險等級識別器,可以對新觀測的車載視角行人數據進行分類,提供風險標簽,實現行人危險等級評價。
1 問題定義與模型框架
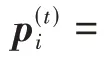

圖1 展示了本文中提出的總體框架。首先,基于車載傳感器,采集車輛視角行人軌跡數據并進行預處理。其次,使用采集的車輛視角行人軌跡訓練LSTM 神經網絡,進行行人軌跡預測。最后,應用該主成分分析-K Means 聚類法(KPCA-KMC)分析觀察到的行人特征,將其分為具有不同風險標簽的類群。利用KPCA-KMC 的標簽,訓練一個風險等級分類器。該分類器將對LSTM 預測的行人軌跡進行風險等級識別,從而實現基于車載視角行人數據的軌跡和風險等級評價。
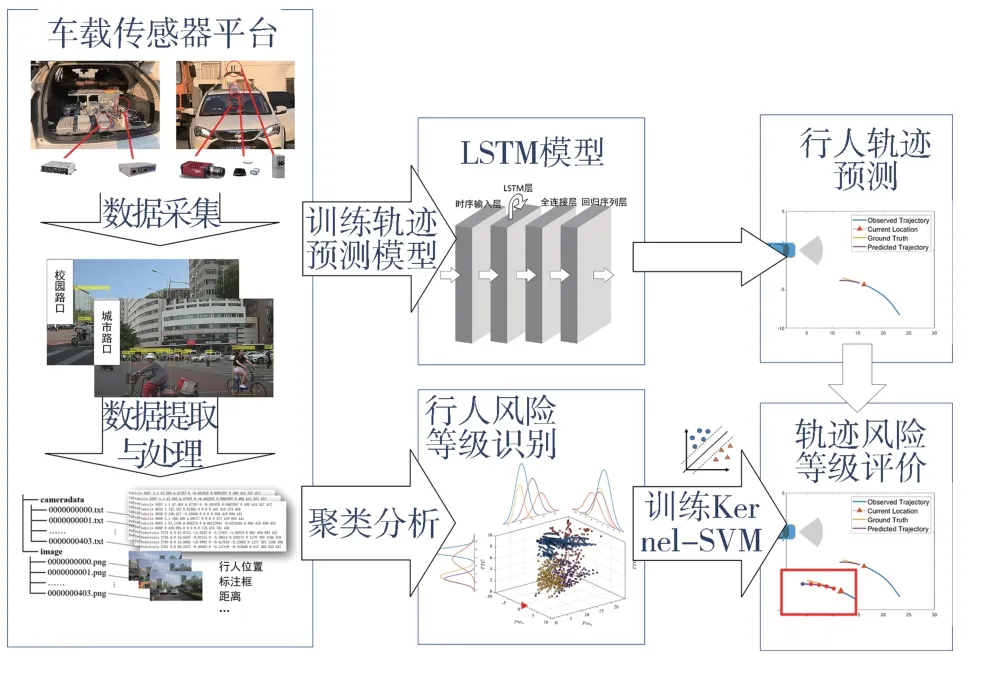
圖1 行人軌跡預測和風險等級評價總體框架
2 數據采集與模型方法
2.1 數據采集與預處理
為了獲得車輛視角下的行人數據,本文中采用車載傳感系統進行數據收集。該系統包含一個安裝在汽車頂部的Velodyne 激光雷達HDL-32E,一個OxTs慣性+GNSS/INS套件,一個安裝在車輛前窗玻璃上的Mako相機和一個車載工控機,如圖2所示。

圖2 車載傳感系統
工控機裝有行人檢測和定位程序,通過融合攝像機圖像的檢測結果和激光雷達點云的距離信息,提供行人相對車輛的坐標位置。所使用相對坐標系的原點對應于車輛后軸的中點,軸的正方向對應于車輛的前進方向。最終的視頻和軌跡數據幀率為6.5 Hz。
在城區道路的選擇上,考慮到城區交叉口作為城區路網中最繁忙的部分之一,容納了大量的人車交互場景,因此,選取北京理工大學校園內和北京西三環的4 個信號燈路口作為數據采集地點。行駛路線如圖3 所示。為了保證采集和識別效果,數據采集在白天13:00-15:00 進行,主要包含右轉和直行兩種行車場景,其中右轉場景居多。數據采集由兩名經驗豐富的駕駛員輪流駕駛完成。
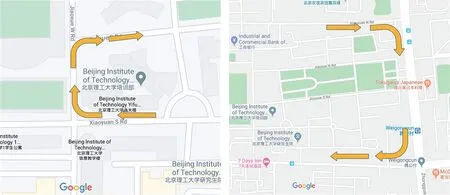
圖3 數據采集路線

2.2 行人軌跡預測

2.3 行人數據聚類


式中T代表行人的軌跡長度(幀數)。

式中μ為第個集群的中心點向量。KMC通過不斷優化聚類中心點,最小化類群內部點到中心點距離的平方和,從而將具有相似特征的點劃分為同種類群。在將行人特征數據聚類為不同的類群后,觀察不同類群在各類特征上的分布,便可確定不同類群的行人相對車輛的風險程度。
2.4 風險等級分類器
通過聚類方式,可以獲得不同行人數據對應的風險程度,因而可以此為依據,訓練一個行人風險等級識別器:首先預測行人軌跡,通過預測得到的軌跡提取相應的行人特征,并輸入到訓練好的風險等級識別器中,即可確定行人未來的風險等級。本文中,SVM 作為一種典型的分類器,通過迭代尋找能夠最好地區分不同種類數據的最佳超平面,以對新的數據點進行分類。與KPCA 類似,SVM 中同樣可以運用核技巧使非線性數據轉化為可分離的線性數據。
為了實現行人風險等級識別,本文中訓練核SVM 分類器,它將觀測值=[,,...s]及其風險標簽=[,,...l]作為輸入,最終訓練得到風險等級分類器,可用于識別新觀測值的風險等級類別。
3 實驗與分析
3.1 實驗1:行人軌跡預測
為了驗證車輛視角數據中的行人相對位置能夠有效使用LSTM 模型進行預測,同時,探索車輛視角數據中非軌跡信息對位置預測的準確性,本節根據采集的數據設計了4種模型,如表1所示。
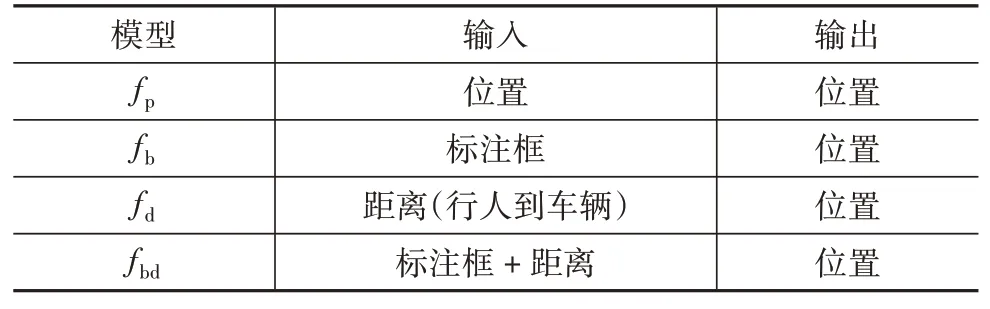
表1 模型符號與輸入輸出信息
本文中軌跡預測的觀察窗口設置為從1 幀到幀,預測窗口從+ 1 幀設置到+ 5 幀。采用5 倍交叉驗證(CV)來評估行人軌跡預測模型的性能,這有助于減少變異性并確保對小數據集的模型性能的準確估計。平均位移誤差(ADE)被用來評估模型的性能。經過10 次5 倍CV 的重復,各模型在測試集中的預測誤差平均值,如表2所示。
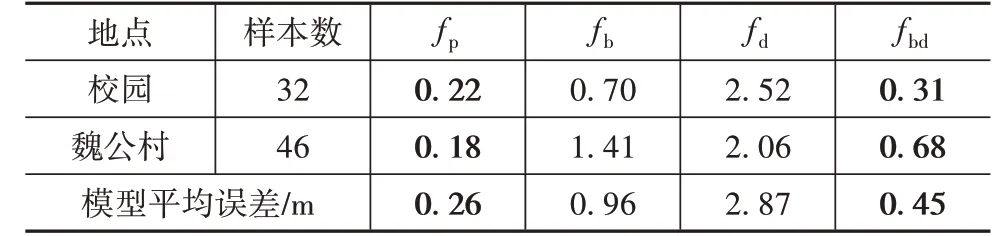
表2 測試集預測誤差
通過橫向對比,在模型平均誤差上可看出預測精度>>>。其中模型的平均偏移誤差為0.263 7 m,精度最高,次之,ADE 為0.448 7 m。目前,主流的非駕駛場景的行人軌跡預測方法中,典型的Social-LSTM 平均偏移誤差在0.27~0.53 m,引入社會注意力模型Social Attention 的平均偏移誤差在0.20~0.30 m。對比之下,本實驗結果顯示在LSTM模型建模下,使用車輛視角行人相對位置信息直接進行位置預測的模型能達到較高精度的預測效果,證明LSTM 模型能夠有效對車輛視角下的相對行人軌跡進行學習和預測,直接使用相對位置信息能夠獲得最佳的預測結果。其次是結合距離和標注框信息進行位置預測的模型,雖然誤差大于,但表明標注框和距離信息在LSTM 網絡中能夠很好地捕捉行人的空間位置變化,可以直接預測行人未來的相對位置,起到了數據融合的作用。而對于僅使用標注框進行預測的模型或僅使用距離進行預測的模型,誤差明顯偏大,表明單純的距離或標注框信息很難推測出行人的位置。因此,在后面風險預測部分,主要采用相對位置信息對行人軌跡進行預測,以保證更佳的軌跡預測效果和危險預測結果。
3.2 實驗2:行人數據聚類
本實驗分別采用KMC 和KPCA-KMC 對兩種數據集的行人數據進行聚類。聚類結果通過殘差平方和(RSS)和赤池信息準則(AIC)度量進行評價。RSS的計算公式為

式中μ是類別的中心點。AIC 指標是一個最大似然度量,AIC 曲線的最小值保證了可靠的聚類結果和相對較低的聚類復雜性。AIC的計算公式為
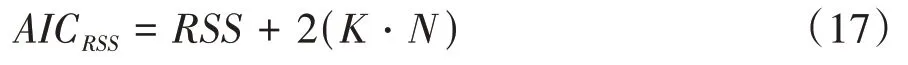
式中:是集群的總數量;是維度數量。
聚類結果如圖4 所示,可見對于城區和校園路口數據集,使用KPCA-KMC 的RSS 和AIC 誤差明顯低于KMC,表明KPCA+KMC 能獲得更佳的聚類效果。同時,采用KPCA+KMC 方法,魏公村和校園兩組數據的RSS和AIC 誤差分別在= 4和= 2附近取得最低。不過當= 2 時,雖然聚類復雜性降低,但會造成聚類結果過度依賴某單一特征(如TTC)的情況,無法辨識其他特征維度對聚類結果潛在的影響,使分類過于簡單化。因此對于魏公村和校園兩組數據均采用最佳類群數= 4。
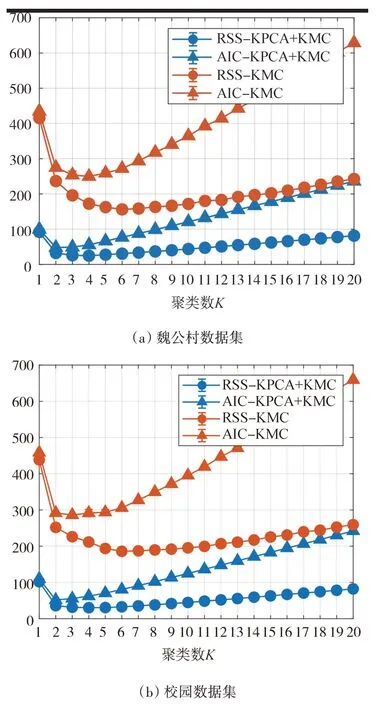
圖4 KPCA-KMC與KMC的聚類結果在RSS和AIC上的對比
在校園和城區路口數據集應用KPCA+KMC 方法的聚類結果分別如圖5 和圖6 所示。為了更好地展示聚類結果,本文中將5 個維度的數據放置于兩種特征坐標系中:Pos- Pos-坐標系和Vel-Vel-坐標系中,Pos、Pos代表、方向上行人的相對位置,Vel、Vel表示相對速度。在相對坐標系中,車輛始終靜止在原點,在圖5 和圖6 中使用紅色三角形來表示。
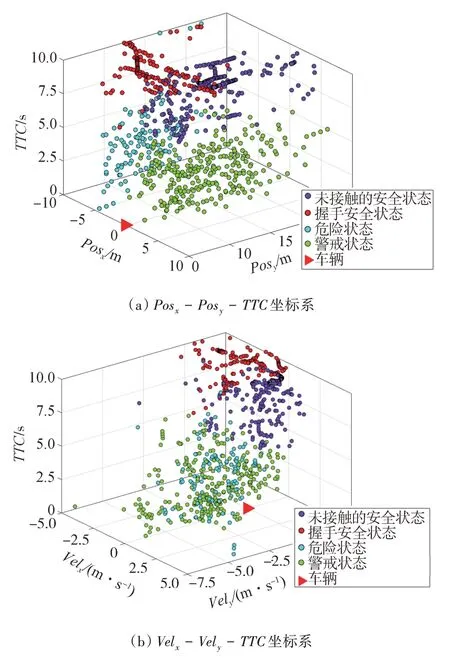
圖5 校園路口數據的特征聚類結果
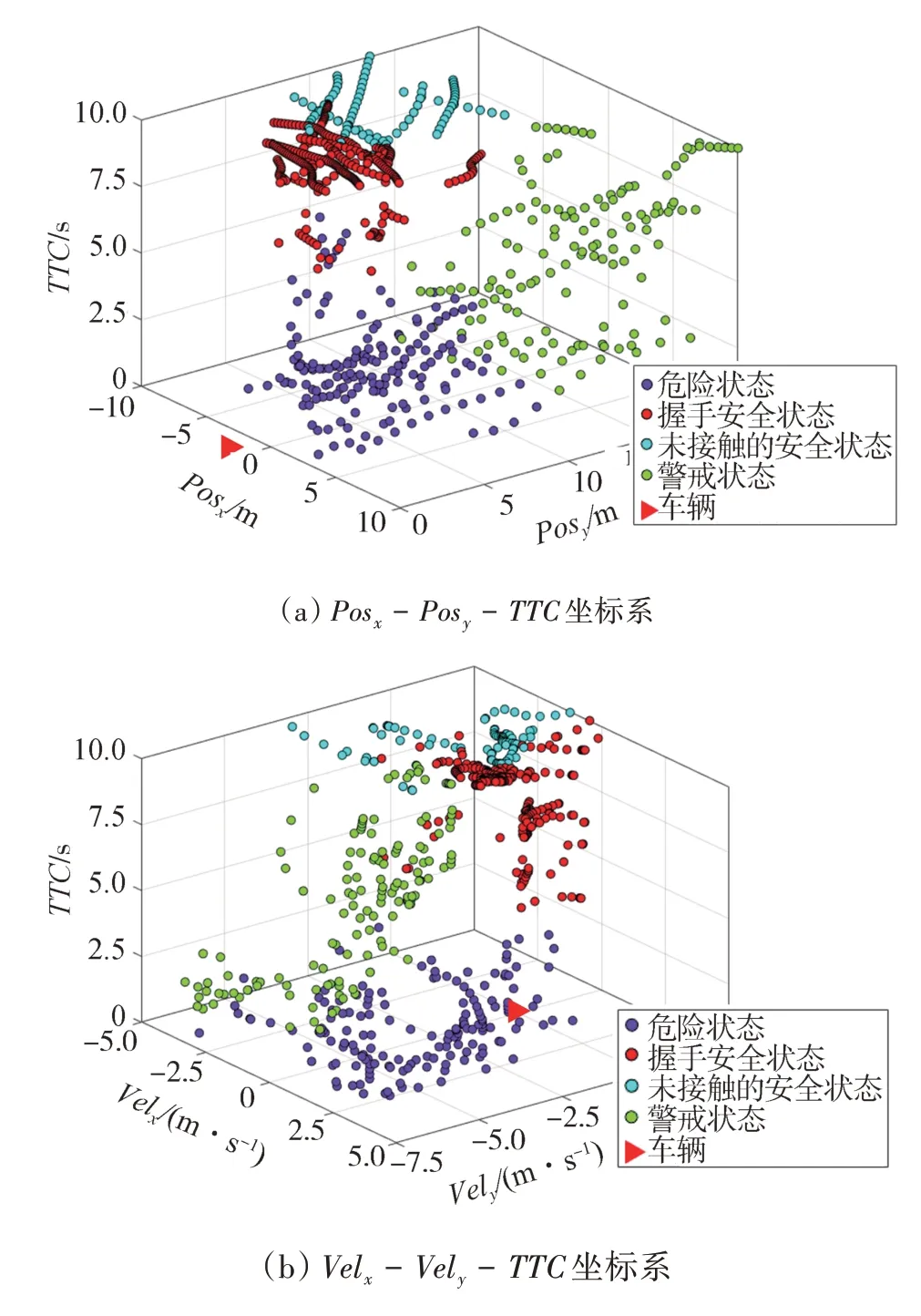
圖6 城區路口數據的特征聚類結果
校園路口數據的聚類結果如圖5 所示,將數據分為如下4類。
類別1:TTC 較大,與車輛的縱向距離相對較長,縱向速度較低;橫向位置多分布在車輛左側,整體上有繼續向左移動并與車輛漸行漸遠的趨勢,說明這類行人與車輛之間目前沒有明顯的沖突。因此,將此狀態定義為未接觸的安全狀態。
類別2:TTC 較大,縱向位置接近車輛,而橫向位置從左到右分布廣泛,縱向速度較低。此時,雖然行人離車輛較近,但行人和車輛都沒有對對方構成危險。這說明在路權分配達成了一致的情況下,行人在車輛前方安全通過。在這種情況下,車輛只需保持當前的操作即可,例如停車等待。因此,將此狀態定義為握手安全狀態。
類別3:TTC 較小,縱向距離在所有類別中距車輛最近,橫向位置分布偏左,且接近速度較高,說明有行人(多來自左側)正在向車輛接近,發生沖突可能性較高,要求車輛保持高度警惕,隨時準備向右側避讓或直接制動,以避免可能的左側碰撞。因此,將此狀態定義為危險狀態。
類別4:與類別3相似,TTC較小,與車輛縱向距離同樣較近,接近速度較高,但大部分行人位于右側,需要車輛對從右前方駛來的行人保持警惕。因此,將此狀態定義為警戒狀態。
對于城區路口的聚類結果,與校園路口數據類似,同樣將數據劃分為未接觸安全、握手安全、危險和警戒4類狀態,如圖6所示。
3.3 實驗3:行人風險等級預測
通過KPCA-KMC 獲得行人的風險等級標簽后,本實驗的目的是使用行人特征數據S 及其對應標簽L訓練風險等級識別器,即SVM 模型,并使用該模型進行行人風險等級評價。本文中訓練、對比了線性核、二次核、立方核和高斯核的SVM,使用5 倍交叉驗證法對其性能進行評估,如表3 所示。其中,分類速度單位s表示每秒能夠完成的觀測數或分類次數。由表可見,對于校園數據集,二次核分類器的SVM 在準確度和預測速度上都最好;而對于城區數據集,則是高斯核分類器SVM 的準確度和預測速度最好。因此,校園和城區數據集分別選擇二次核和高斯核的SVM模型。

表3 不同核類型的分類準確率和分類速度的對比
為了測試該分類器對行人風險等級的預測準確度,首先將所有行人軌跡進行風險等級識別,作為真實值;同時,使用LSTM 模型對行人軌跡進行預測,對預測軌跡進行風險等級識別,作為預測值;最后,對比真實值和預測值,通過對比預測值和真實值,統計預測正確和錯誤的樣本數,得出分類器的識別準確率。預測結果用4行4列的混淆矩陣來表示,如圖7 所示。矩陣的每一行的數字表示被預測為該類別的數目(上)和占比(下),而每一列數字表示真實為該類別的數目和占比。比如第2 行第3 列的數字表示被預測為第2 類,但實際是第3 類的數目和占比。表格第5 列和第5 行分別展示了不同預測類別的準確度和不同真實類別被預測的準確度。因此,矩陣對角線前4 格的數就表示被準確預測的數目和占比,而對角線的最后一個格,即右下角的數便是各類被準確預測的總占比(上),即該數據集風險等級預測的整體準確率和相應的錯誤率(下)。
由圖7 可見,校園數據集的整體準確率達到82.0%,城區數據集的準確率達到86.8%,表明在行人風險等級的準確識別方面表現良好。
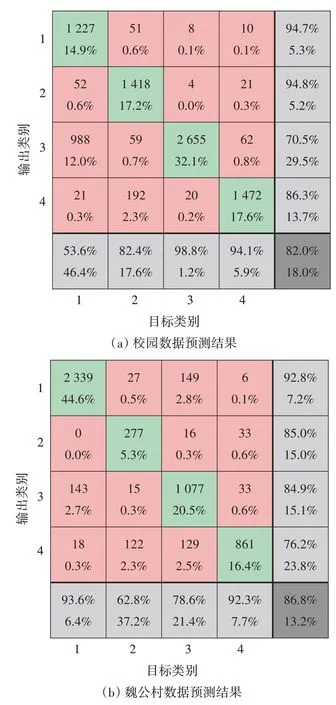
圖7 行人風險等級預測模型的混淆矩陣
圖8 顯示了一個校園數據集中風險等級預測的例子。在以車輛為原點的相對坐標系中,預測軌跡(紫色線),其風險等級用不同顏色的圓點表示,每一種不同的顏色對應不同的風險等級。如圖第3 幀到第16 幀展示了車輛右轉時,觀察行人、接近和讓行的過程。預測的軌跡顯示LSTM 模型能夠良好估計車輛視角行人相對位置,表明該模型能夠較好地在估計車輛和行人的移動趨勢。在第6 幀時,該模型預測行人在接下來的幾幀中可能會從安全狀態轉為警戒狀態。這表明在目前的情況下,車輛應該減速并優先考慮行人,否則風險等級會轉為更高。在第13 和第16 幀,由于車輛仍在向前行駛,風險等級從警戒狀態轉換為危險狀態。可以看出,本文中提出模型的結果符合車輛與行人相互作用下的實際情況,表明其具有良好的風險等級評價能力。
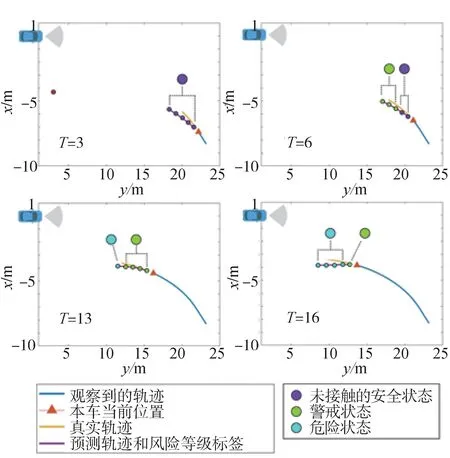
圖8 行人風險等級預測實例
4 結論
本文中為實現車輛視角下的行人軌跡及風險等級預測,提出了一個基于車載傳感系統采集數據的行人軌跡預測和風險等級評價模型,主要包含3 項工作:首先,進行了車輛視角下的行人數據實車采集與處理,獲得了城區和校園兩種交叉路口的車輛視角行人數據;其次,使用LSTM 網絡訓練了行人軌跡預測模型。實驗結果顯示,LSTM能夠有效對車輛視角行人數據進行學習并預測未來軌跡,其中,直接使用相對位置數據能夠獲得最好的預測效果,而距離信息和標注框信息次之;最后,使用KPCA+KMC 對車輛視角下的行人數據進行聚類分析,識別出不同行人的風險等級,并以此為根據,基于SVM 訓練得到了行人風險等級識別器。將該識別器應用于LSTM預測的車輛視角行人軌跡,可以獲得預測軌跡的風險等級。實驗結果顯示,該風險等級識別器在兩種不同場景下均能夠有效估計車輛和行人的移動趨勢和交互特征,顯示了良好的風險等級評價能力,對自動駕駛系統和高級輔助駕駛系統開發具有實用價值。在未來的工作中,將會考慮在提出的模型中引入更多的行人特征數據和環境信息,并將該模型擴展到更多的車輛-行人交互場景中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
