DHSSA優化的K均值互補迭代車型信息數據聚類*
2022-06-08 02:08:46李文龍王會峰
汽車工程 2022年5期
黃 鶴,李文龍,楊 瀾,王會峰,王 飚,茹 鋒
(1. 長安大學,西安 710064;2. 西安市智慧高速公路信息融合與控制重點實驗室,西安 710064)
前言
聚類分析是統計學習領域的常用方法,可以根據不同對象數據之間的內在特征,將相似度較大的數據樣本劃分到同一簇,已經應用于許多領域,諸如車輛數據、車輛檢測、車輛軌跡等等。K-means 聚類(KMC)是使用最廣泛的聚類算法之一,具有速度快、效果好、思想簡單的特點。但是在實際的車型數據聚類過程中會因為初始點選取不當而導致誤差較大。K-means++、山峰聚類等在一定程度上解決了KMC 初始化方面的缺陷,但優化路徑過于簡單,存在受異常點影響大、算法早熟的問題。近年來利用群智能優化算法來尋找聚類中心,解決早熟問題成為研究熱點,廣受研究學者的關注。文獻[11]中將人工蜂群算法與KMC 雜交迭代,解決了早熟的問題,驗證了群智能改進KMC 的有效性,但是利用改進蜂群算法來改進KMC 處理高維數據集,存在能力不足和迭代速度慢的問題;文獻[12]中利用螢火蟲算法優化KMC 的中心初始化問題,克服了初始聚類中心難選取和噪聲點的影響,但不適合處理大數據集;文獻[13]中設計了一種準確率較高的IFOA-K-means 算法,增強了橫向探索能力,但忽略了縱向的挖掘能力;文獻[14]中將改進飛蛾撲火算法與KMC 算法交叉迭代實現聚類,優化尋優結果,但飛蛾的更新機制使得算法的耗時較長。麻雀搜索算法(sparrow search algorithm,SSA)是2020 年 由Xue等提出的一種新的群智能優化算法,SSA 模擬了麻雀覓食的過程,具有收斂速度快,適應性強,模型易修改等特點,適合用于優化聚類。因此,本文設計了一種基于擾動因子-領頭雀的SSA 優化方法(DHSSA),與KMC 算法互補迭代,有效提高了車型數據的聚類精度和迭代速度。
1 KMC和SSA算法特點
1.1 KMC算法
KMC 可以按照不同類別將數據集劃分成多個子集,具體步驟如下:
(1)從個數據中隨機選取個對象作為初始聚類中心C(1≤≤);
(2)計算每個數據到各個初始聚類中心的歐式距離,根據距離最小原則重新分類數據;
(3)計算聚類簇的各個維度平均值,得到新的中心。
重復步驟(2)和(3),直到聚類中心不再發生改變或聚類中心發生偏移的距離均小于設定閾值,輸出該數據集的聚類中心。從聚類過程可以看出,初始聚類中心選擇不當,會陷入局部最優。聚類中心C的計算公式如式(1)所示:

式中n為第個聚類簇樣本個數,=1,2...,,為聚類中心個數。聚類中心C與樣本數據X的歐式距離計算式如式(2)所示:
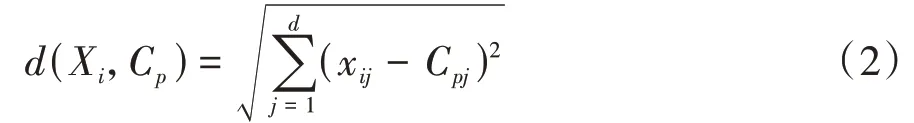
式中=1,2,…,表示數據維度。
因此,KMC 的初始化具有隨機性,每次處理車型數據聚類過程中結果相差較大,容易由于中心選擇不當而陷入局部極值,還可能會將離群值誤作為初始中心;同時,根據均值選取中心的更新過程會導致KMC易受孤立點的影響。
1.2 SSA算法
(1)初始化
SSA中麻雀種群分為覓食發現者、搶食物的加入者和作為偵察的警戒者3 種。前兩者角色可以互換,而一定比例的偵察警戒者,一有危險便飛向別處。麻雀種群在維空間內只麻雀的位置矩陣表示如下:
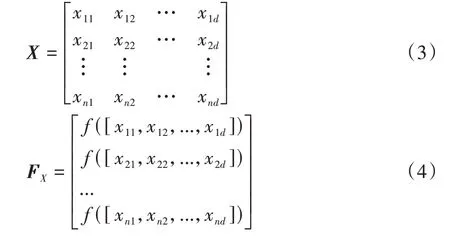
式中:x為維空間內第只麻雀的位置;矩陣F表示麻雀的適應度值。
(2)麻雀位置更新機制
更新機制主要可分為發現者的覓食過程、加入者的搶食過程和警戒者的檢測過程。
a. 覓食過程:迭代尋優過程中,麻雀種群中的發現者負責覓食和指導整個種群移動,發現者位置更新如下:
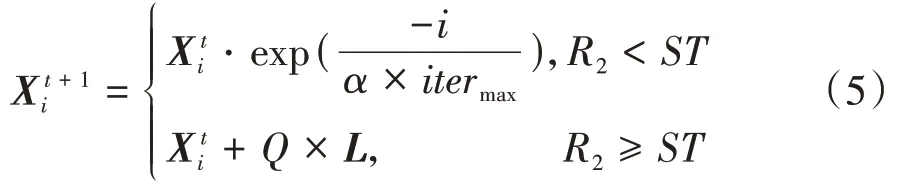
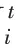
可以看出,當<時,發現者的每一維都在縮小,這對求解測試函數非常有效,但對于大多數求解非0的實際應用反而降低了搜索能力。
b. 搶食過程:加入者為除去發現者適應度較差的一些個體,設計位置更新公式為

c. 檢測過程:在麻雀種群隨機選取20%的個體作為警戒者,則這些個體對全體的影響程度用式(8)表示。

2 擾動因子-領頭雀SSA優化策略
綜合SSA 發現者、加入者和警戒者的更新方式可知,SSA 中的麻雀位置更新具有向原點收斂的趨勢,這對于求解非原點問題存在一定局限性,而聚類中心一般不取0 值。同時,由于SSA 的收斂方式是跳躍式的,容易陷入局部最優。因此,尋找聚類中心前必須對SSA作進一步改進。
2.1 自適應領頭雀引導
由更新式(5)可知,發現者的位置更新是在父代的基礎上尋優,跟隨父代更新會導致尋優速度減慢,增加聚類迭代時間。而通過作者的研究,自然界中的麻雀群在覓食中通常都會由一個最強壯、基因最優秀的個體充當領頭雀。鑒于此,設計了一種自適應領頭雀引導策略來完善SSA 算法,使得迭代更新不僅受父代的影響,還受到領頭雀的影響。加入領頭雀引導在前期會不利于種群全局探索能力的提升。為同時增加算法的前期全局探索和后期局部尋優能力,在上述最優個體(領頭雀)引導策略的基礎上添加自適應權重,這里新的發現者更新公式修改為

式中和分別為最大和最小值,取1 和0.01。系數隨著迭代次數的增加變化曲線如圖1所示。
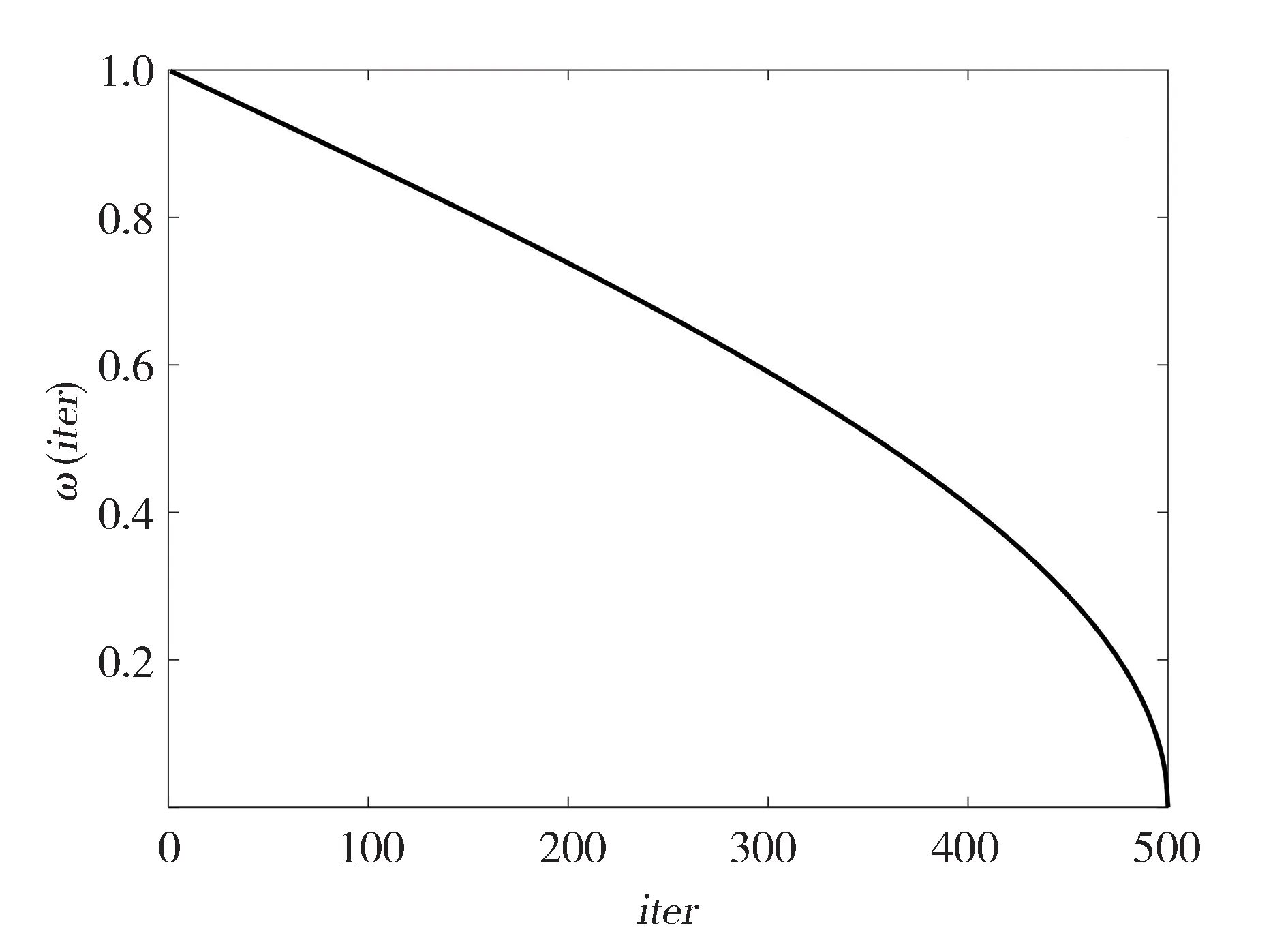
圖1 ω系數變化曲線圖
隨的變化規律在前中期設計為緩慢減小,使得發現者的更新受父代的影響較大,降低算法早熟的可能性;而后期減小迅速,受領頭雀的影響較大,由此提高算法精度,加快聚類迭代的完成。
2.2 擾動因子
麻雀發現者的位置更新存在收斂于0 的趨勢,而加入者和警戒者的收斂趨于最優解,這導致了SSA 尋找聚類中心時易收斂于0,但是聚類中心的值一般不為0。針對這一問題,一般采用變異操作加強全局搜索能力,最常用的是高斯和柯西算子。而在SSA 尋找聚類中心的過程中為增加種群多樣性,采用分布擾動因子對麻雀個體變異,根據參數自由度的大小表現不同,在自由度較小時表現為柯西分布,在自由度較大時表現為高斯分布。將分布的自由度參數設為麻雀搜索算法迭代次數,前期表現為柯西分布,隨著迭代次數的增加,后期表現高斯分布,加強局部探索能力。通過擾動得到的位置既有利于增加種群多樣性,即尋得聚類中心的可能性增加,又可以增加聚類的迭代速度。分布效果如圖2所示,隨著自由度參數的增大,的大概率取值范圍越來越小。
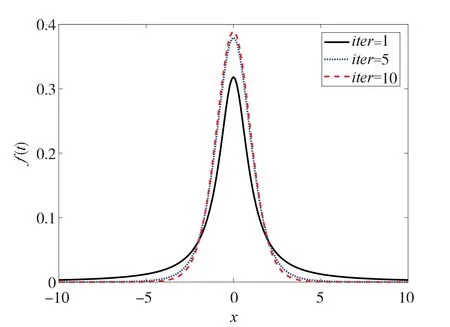
圖2 t分布概率密度圖
擾動種群的計算公式為
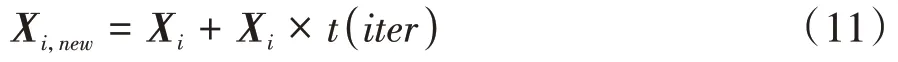
式中:為當前迭代次數;()為自由度參數為的分布。采用擾動因子求取新解之后,根據貪婪原則更新得到的新種群如式(12)所示。
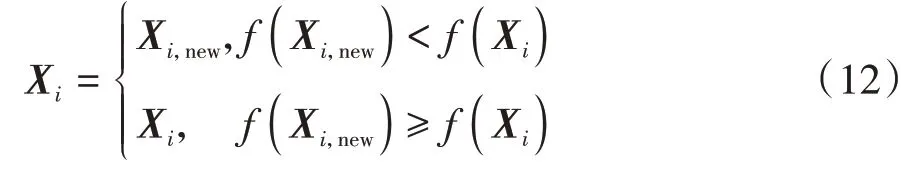
式中:(X)為X的適應度;(X)為X的適應度。
DHSSA優化策略具體流程如下:
(1)確定麻雀種群的數量以及維度,計算種群適應度并排序選出最優和最差個體;
(2)開始迭代更新;
(3)發現者根據頭雀策略更新坐標位置,加入者和警戒者利用SSA更新位置;
(4)利用擾動因子增加種群多樣性,根據貪婪原則決定是否替換原種群個體;
(5)判斷最優適應度是否小于迭代上次最優適應度,小于時就替換最優個體,否則繼續;
(6)判斷是否達到最大迭代次數,是則輸出最優個體,否則跳回(3)。
2.3 優化策略的測試
為了驗證算法的性能,DHSSA 與SSA、SOA、HHO進行比較,測試函數如表1 所示。測試中,對于各個測試函數每種算法運行30 次,得到均值和標準差如表2 所示,適應度收斂曲線如圖3 所示。設置種群的規模為50,迭代次數為500。

表1 測試函數
表2和圖3數據表明,本文算法在求解各個函數時都表現出了優異的性能。精度方面,對于函數F1,DHSSA>SSA>SOA>HHO;對于函數F2 和F4,DHSSA>SSA>HHO>SOA;對于函數F3,DHSSA>HHO>SSA>SOA;對于函數F5,DHSSA>SOA=HHO>SSA。而對于函數F6,幾種算法精度相同,收斂速度方面DHSSA>SSA>SOA>HHO。通過6 種測試函數驗證了本文算法在總體上表現出較優的性能,可以改善SSA的全局尋優能力。
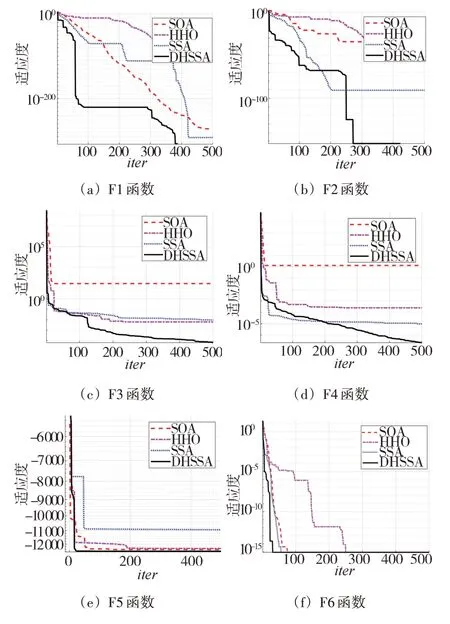
圖3 函數收斂曲線
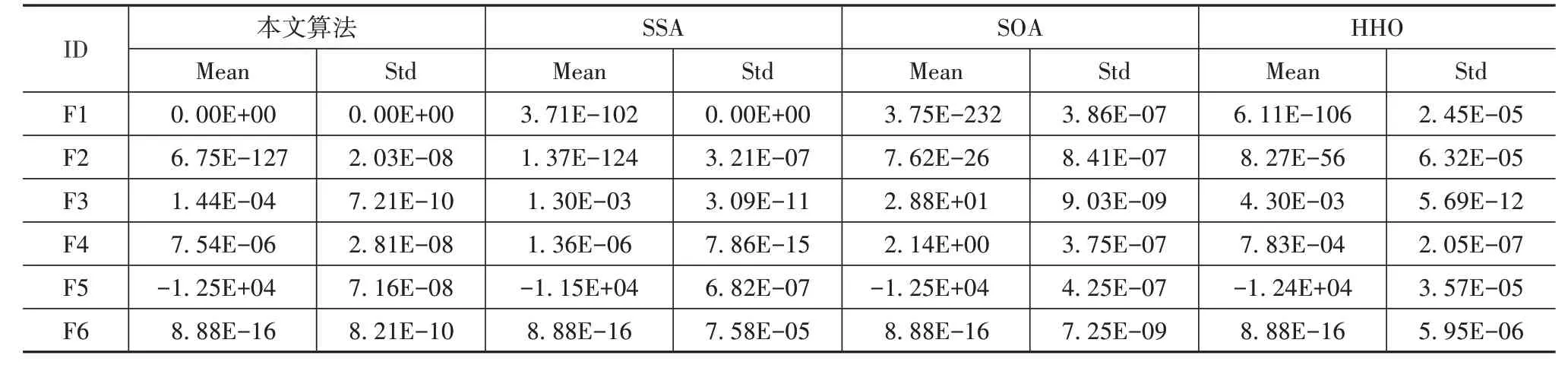
表2 算法測試結果比較
3 DHSSA與KMC的互補迭代
3.1 適應度函數選擇
適應度函數決定了優化麻雀群體進化的方向,直接影響種群算法的優化效果和解的質量,且是DHSSA 與KMC 算法的唯一接口。KMC 以每個類別中個體到中心的距離和或個體總數為適應度函數,距離或點個數相等時,會存在辨識能力不足而影響更新的問題。利用DHSSA 優化聚類中心,結合距離和個數,采用如下適應度函數:
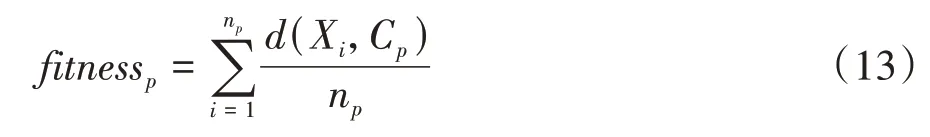
式中:腳標表示種群的類別數;(X,C)表示第類內的對象到該類的聚類中心點的距離和;n為第類中的種群數量。從適應度函數可以看出,當前聚類結果的適應度不僅與每個類別所有樣本點到該簇聚類中心的距離有關,也與該類樣本數有關,反映的是該簇所有樣本點到聚類中心歐式距離的均值大小。均值越小,適應度越小,代表樣本點距離中心更近,該簇樣本更多。
3.2 篩選最大最小距離積初始化
利用最大最小距離積方法(maximum and minimum distance product,MMP)選取KMC 的初始中心,可以使得其代價有所減小,但選擇的第一個初始中心具有隨機性,有可能會把異常點計算為中心。同時,最大最小距離積法在計算的過程中,不考慮樣本數據之間相互影響和密集程度的問題,計算出的兩個中心點或者更多點可能出現在同一個簇中,尤其對于處理車型信息數據集這樣的高維數據集,初始化聚類中心的能力明顯不足。因此,針對上述問題,本文設計了一種篩選最大最小距離積法(screening maximum and minimum distance product,SMMP),計算所有點之間的距離,建立距離矩陣,然后求出該樣本中離所有點的距離和最小的點作為第一個中心點,避免第一個中心的盲目選擇問題。每個數據集分為類,說明有個簇。為了解決多個中心出現在一個簇中的問題,建立一個數值全為-1 的標記矩陣,每選出一個中心,將距離中心的前/個點歸于對應的中心,并且在矩陣中標記出來,之后計算的中心只會在矩陣中標記為-1 的元素中得到。這樣計算得到的中心大概率不會落在同一個簇中。SMMP 初始化算法可以有效減小車型信息數據之間相互影響和密集程度。
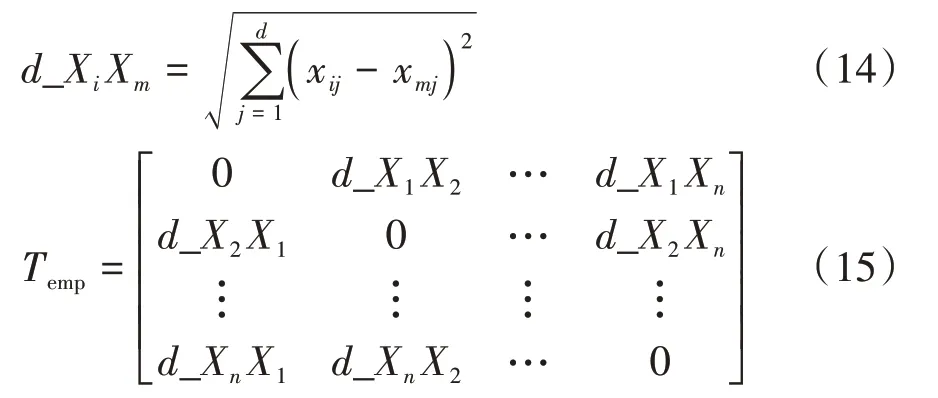
式中_XX表示第個元素到第個元素的距離,、=1,2,…,。對求取每行元素的距離和,即可得到第一個中心。
初始化步驟如下:
(1)計算數據集Data 中所有點之間的距離,建立,從中選取離所有點距離和最短的點作為第一個初始中心點,加入集合中,新建×1 的數值全為-1 的標記矩陣,在中標記周圍距離大小為前/的點為1;
(2)選取距離最大且在中標記為-1 的元素為;
(3)將加入集合中,在中標記周圍距離大小為前的點為2;
(4)分別統計Data 中標記為-1的元素到中各個元素的距離,并存入臨時距離矩陣中;
(5)找出Data中標記為-1的元素對應中的最大距離和最小距離值,求其乘積,并將最大乘積值對應的元素作為中心C(1≤≤),加入集合中,在中標記C周圍距離大小為前的點為。若中元素個數小于,轉到步驟(4);若中元素個數大于,則初始中心選取結束,輸出包含個初始點集合,得到初始中心。
通過以上步驟得到的初始聚類中心,可避免隨機初始化引起的初始誤差過大,有效減少了聚類耗時。選取Aggregation 數據集進行初始化,圖4為3種初始化方法尋找聚類中心的對比結果,圖5 為優化KMC更新曲線。
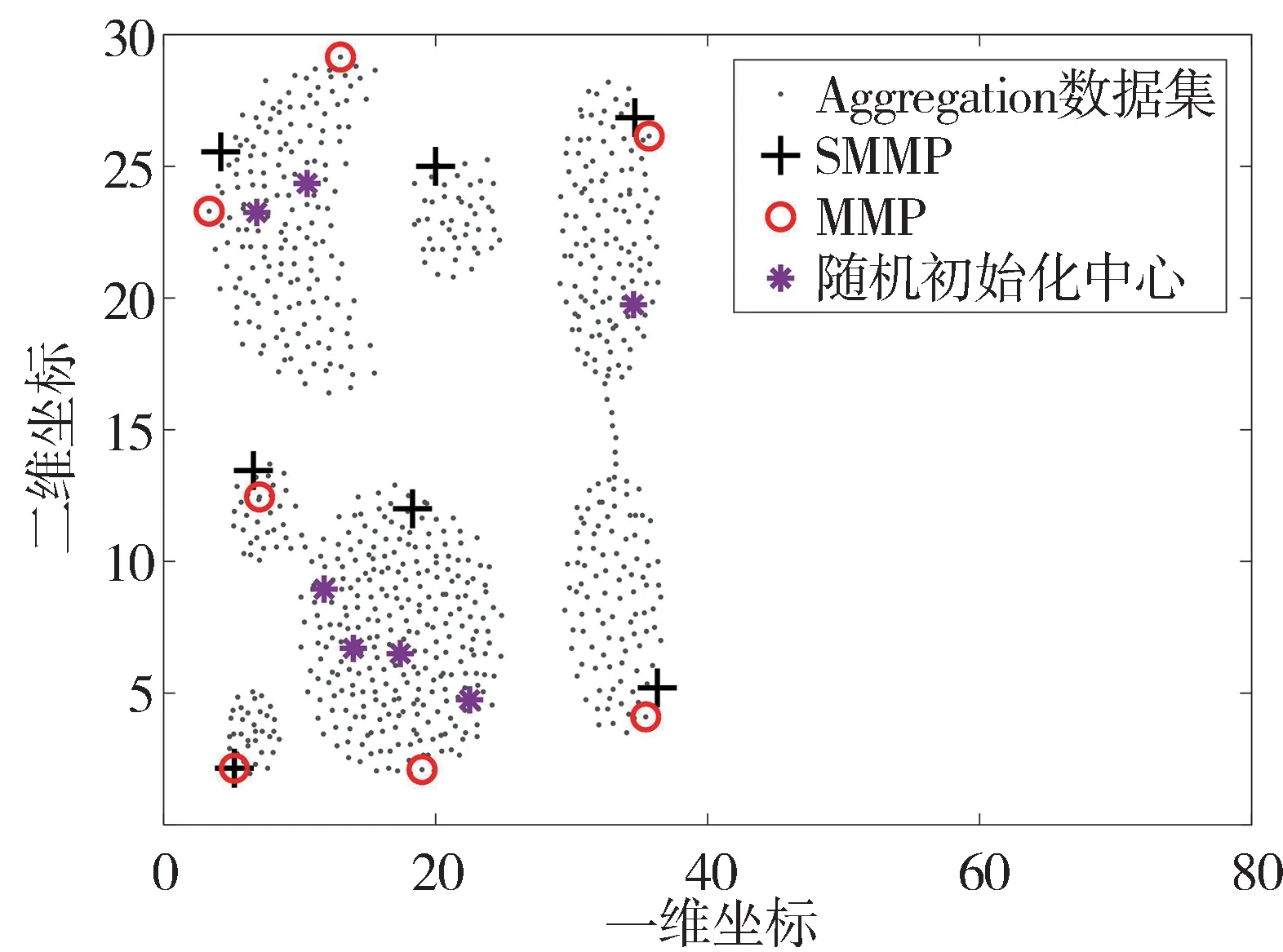
圖4 Aggregation數據集初始化對比

圖5 Aggregation數據集KMC聚類曲線
圖4 中,*為在Aggregation 數據集上隨機選取的聚類中心,初始化中心分布不規律,且大概率多中心落在同一個簇中;圓圈代表MMP 初始化得到的聚類中心,在左上角的簇中有兩個聚類中心;+代表SMMP 得到的初始化中心,每個中心均勻的分布在相應的簇中。由圖5 可以看出,SMMP 的初始化與MMP 和隨機初始化(random init)相比其迭代速度更快,最優適應度更小。
3.3 DHSSA與KMC的互補迭代
KMC 通過求各個維度均值獲得新聚類中心,更新方法過于簡單,容易受異常點影響,陷入局部最優,導致優化精度過低。本文利用DHSSA 尋找聚類中心,實現與KMC 的互補迭代,擴大尋優范圍,避免陷入局部最優的同時提高搜索精度,流程如圖6所示。
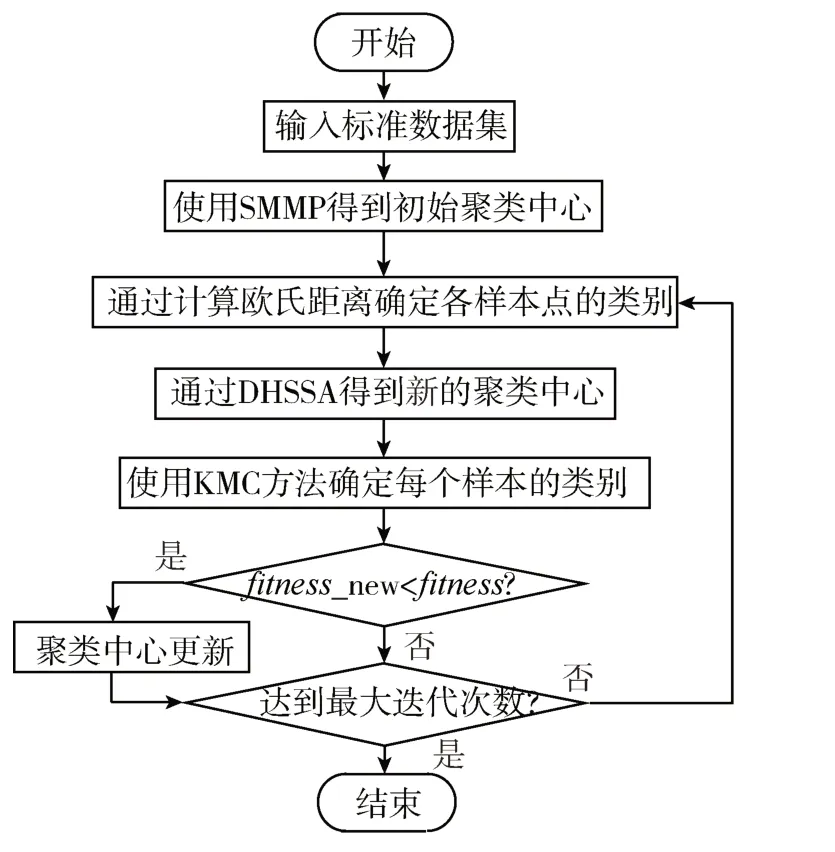
圖6 方法流程圖
基本步驟如下:
(1)輸入數據集Data,根據其類別的個數確定數據集中類的個數;
(2)利用SMMP初始化中心點;
(3)計算Data 中的每個樣本點到各個聚類中心的歐式距離,按數值大小進行排序,將樣本點所屬類別歸于最小歐式距離的聚類中心;
(4)在每個類別的麻雀種群中通過DHSSA 進行尋優操作,得到新的聚類中心;
(5)使用KMC 確定每個樣本的類別,計算由新中心聚類得到的新類別的適應度_new,若其適應度優于上次迭代的聚類中心,則用新的聚類中心取代。判斷當前迭代是否達到結束條件,若未達到結束條件則執行步驟(4),使得DHSSA 與KMC 互補迭代,否則循環結束,輸出尋優結果結束程序。
3.4 輪廓系數(silhouette index,SI)
輪廓系數具有相對較好的評價能力,被廣泛使用,它反映了聚類數據集的類內緊密程度和類間的區分程度,本文使用SI 指標驗證各聚類算法的聚類效果。
假設有一個數據集被劃分成了個類,X是其中的一個樣本數據,X的SI指標為
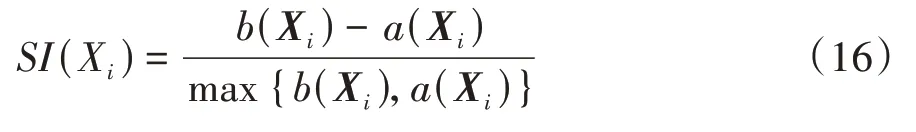
式中(X)為樣本x與其所屬中心C(1≤≤)中的其他樣本的平均相似度。令(X,C)為樣本x到其他中心C(1≤≤)的所有樣本的平均相似度,則(X)=min{(X,C)}。(X)和(X)的計算公式為
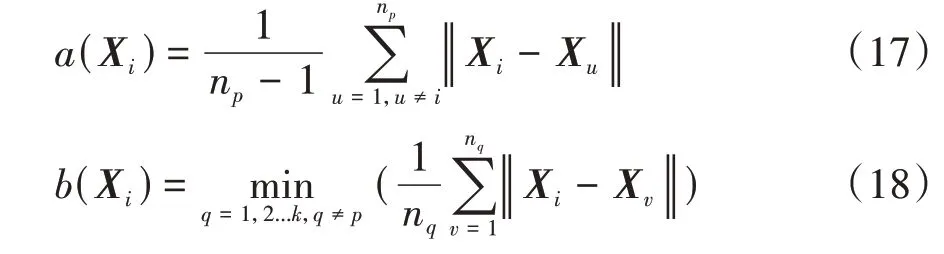
式中:n為X所屬類的數量;X為X所屬類C的其他樣本。
由(X)可以計算得到一個類C的所有樣本的平均值(C),進而計算得到一個數據集所有樣本的值,值可以反映聚類結果的好壞,指標值越大,代表類別之間分離程度越大,類內緊密程度越高。
4 實驗結果分析與應用
4.1 算法性能評價
硬件平臺為Intel Core i5-7300HQ CPU 2.60GHz、8GB 內存的計算機,計算軟件為Matlab R2017b。為了評價效果,將DHSSA-KMC 與SSA-KMC、IMFOKMC、KMC++、KMC 在公共數據集Wine、Ionosphere、Aggregation、Vowel、Glass、Ecoli 上驗證。其中,Wine、Ionosphere 為高維少分類數據集,Aggregation、Vowel為低維多分類數據集,Glass、Ecoli 為高維多分類數據集。最大迭代次數都設置為50 次,在上述5 種聚類方法中,KMC++采取算法本身初始化方法,其余算法的初始化皆使用本文的初始化算法。各數據集的主要特征如表3 所示,各聚類算法處理各數據集的適應度收斂曲線如圖7所示。
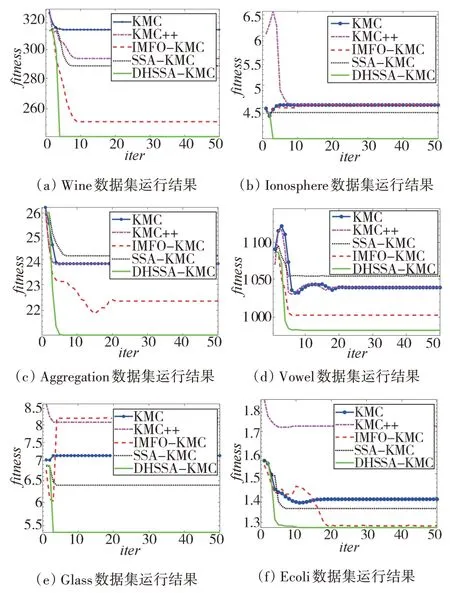
圖7 不同算法在6種數據集上的運行結果
表3 標準數據集特征
由圖7可以看出,DHSSA-KMC在聚類精度和收斂速度方面都優于其他4 種算法。在數據集Wine的測試中,DHSSA-KMC 的適應度<IMFO- KMC<SSA-KMC<KMC++<KMC;在數據集Ionosphere 的測試 中,DHSSA-KMC 的 適 應 度<SSA-KMC<IMFOKMC=KMC++=KMC;在數據集Aggregation 和Vowel測 試 中,DHSSA-KMC 的 適 應 度<IMFO-KMC<KMC++=KMC <SSA-KMC;在數據集Glass 測試上,DHSSA-KMC 的適應度<SSA-KMC<KMC <KMC++<IMFO-KMC;在數據集Ecoli測試中,DHSSA-KMC 的適應度<IMFO-KMC<SSA-KMC <KMC<KMC++。
由圖7曲線還可以看出:在Ionosphere、Aggregation、Vowel數據集上,KMC和KMC++的適應度曲線重合,證明SMMP 初始化方法和KMC++的初始化方法效果相同;在Glass、Ecoli 數據集上,KMC 在初始和聚類完成的適應度均優于KMC++,說明在處理復雜數據上SMMP初始化方法優于KMC++的初始化方法。
采用Acc、ARI、NMI 3種評價指標對不同聚類算法進行評估。其中,Acc 表示聚類準確率,ARI 衡量兩個數據分布的吻合程度,NMI 表示兩組數據之間的關聯程度。3 個指標的范圍都為[0,1],值越大表示結果越好。對Wine、Aggregation、Ecoli 數據集的實驗結果如表4所示。
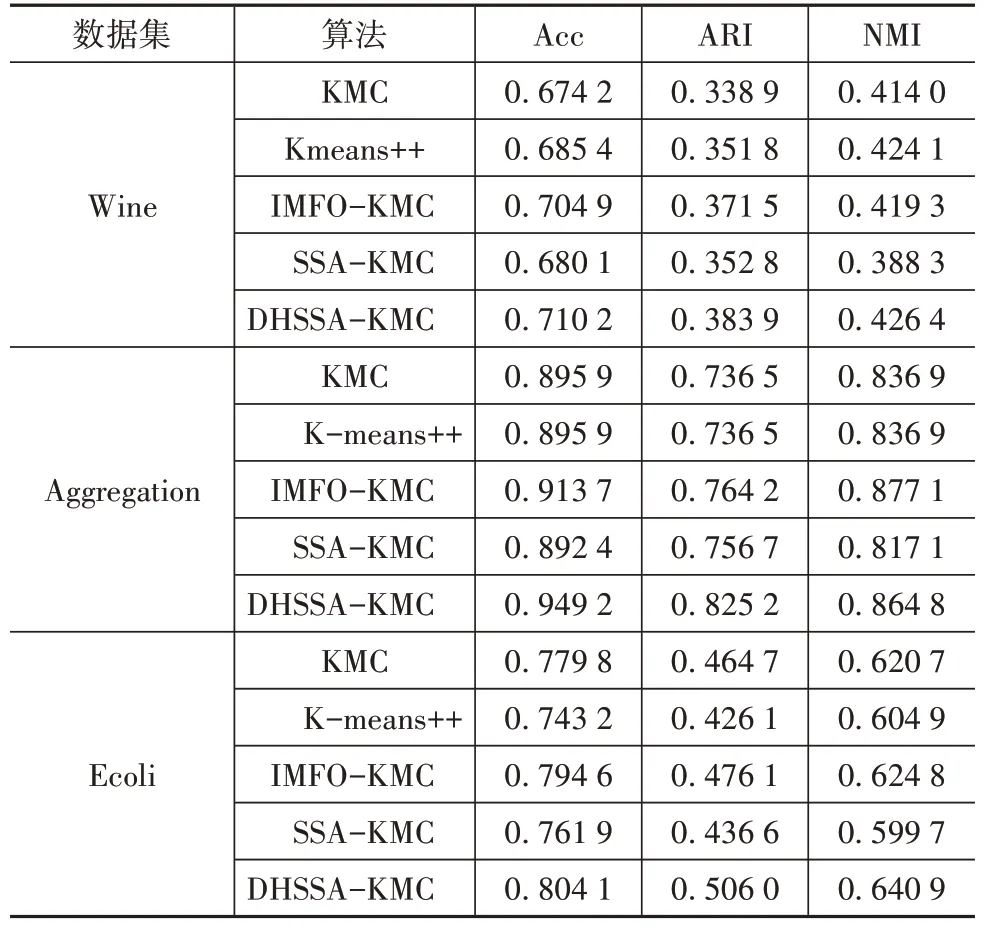
表4 不同算法對3個數據集的實驗結果
表4中的評價數據是由50次獨立實驗數據求均值得到的,在Wine 中,本文算法的Acc 與其它算法相比提高了0.53%~3.6%,ARI提高了1.24%~3.21%,NMI 提高了0.23%~3.81%;在Aggregation 中,本文算法的Acc 相對其它算法提高了3.55%~5.33%,ARI提高了6.1%~8.87%,NMI低于IMFO-KMC1.23%,與其它算法相比提高了2.79%~4.77%。在Ecoli中,本文算法的Acc 與其它算法相比提高了3.55%~5.33%,ARI提高了2.99%~7.99%,NMI提高了1.61%~4.12%。因此,DHSSA-KMC聚類效果指標更優。
表5 所示為用各聚類算法處理Wine、Aggregation、Ecoli數據集計算指標的結果。
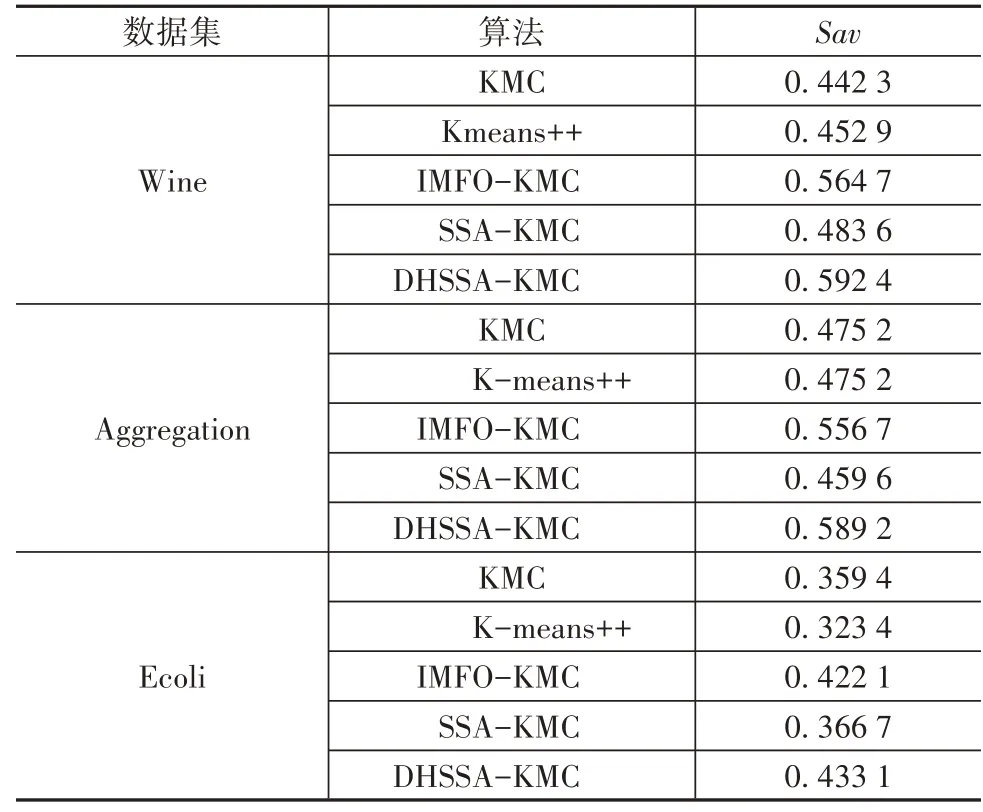
表5 3個數據集的SI指標
由表5 中指標可以看出,在Wine 上,本文算法相對其它算法提高了2.77%~15.01%,在Aggregation 上,本文算法相對其它算法提高了3.25%~12.96%,在Ecoli上,本文算法相對其它算法提高了1.1%~6.37%。在3 個數據集上,本文算法的Sav 值最大,表示類別之間分離程度最大,類內緊密程度最高。
聚類的迭代融合群體智能算法的迭代,能提高聚類精度,但會增加耗時。當最大迭代次數仍設為50時,各算法優化聚類的時間代價如表6所示。
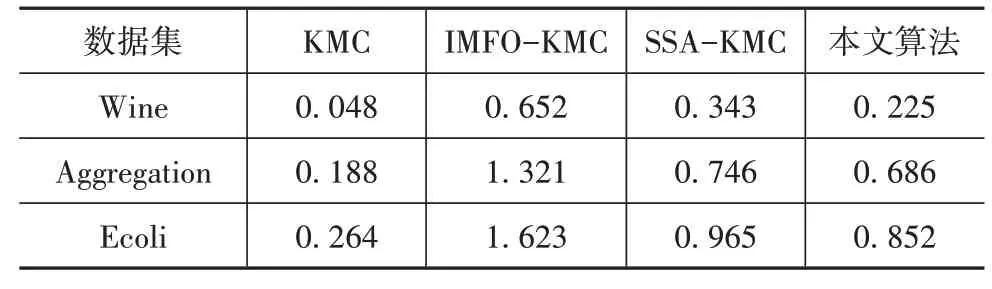
表6 不同算法對3個數據集的時間代價 s
從表6中可以看出,在Wine、Aggregation 和Ecoli中,本文算法分別比IMFO-KMC 降低了0.427、0.635 和0.771 s,比SSA-KMC 降低了0.118、0.060和0.113 s,比經典的KMC 提高了0.177、0.498 和0.588 s。綜合來看,本文算法相對于經典KMC 的迭代耗時略高,相對于IMFO-KMC 和SSA-KMC 有所減小。這是因為IMFO-KMC 受限于飛蛾的更新機制,收斂速度提高有限,而本文算法繼承了SSA 位置更新更快的優點,并且提高了全局尋優的能力,能夠在保證精度的同時減少迭代時間。
4.2 車型信息數據聚類分析
實驗選取具有代表性的阿里云公開的汽車聚類數據集,數據為205款車的26個字段,主要包括汽車 的id(car_ID)、風 險 等 級(symbolling)、車 型(CarName)、燃油(fueltype)、最大轉速(peakrpm)、城市里程(citympg)、高速里程(highwaympg)、價格(price)等參數。聚類的目的是針對指定的車型,通過數據聚類分析可以找到其同類車型即競品車型。原數據集存在非數值型數據,需要將非數值字段轉化為數值,操作方式為獨熱編碼。轉換后的數據特征前5 列如表7 所示。對于汽車數據集的分類數量可以通過肘部原則來選擇,本文選擇=5,對于汽車數據集的聚類迭代曲線如圖8 所示,對于汽車數據集的聚類Silhouette指標如表8所示。
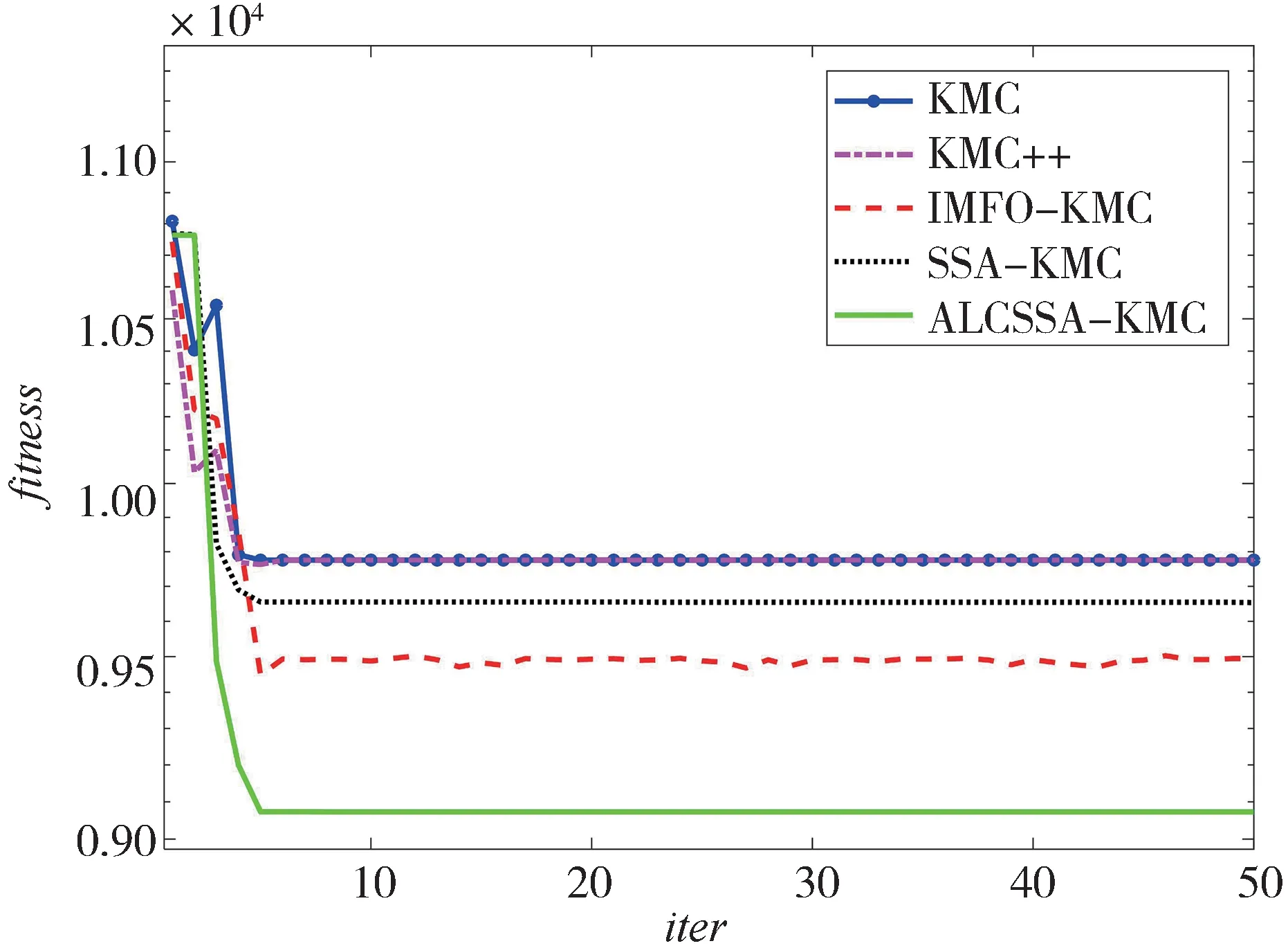
圖8 不同算法在車型信息數據集上的運行結果
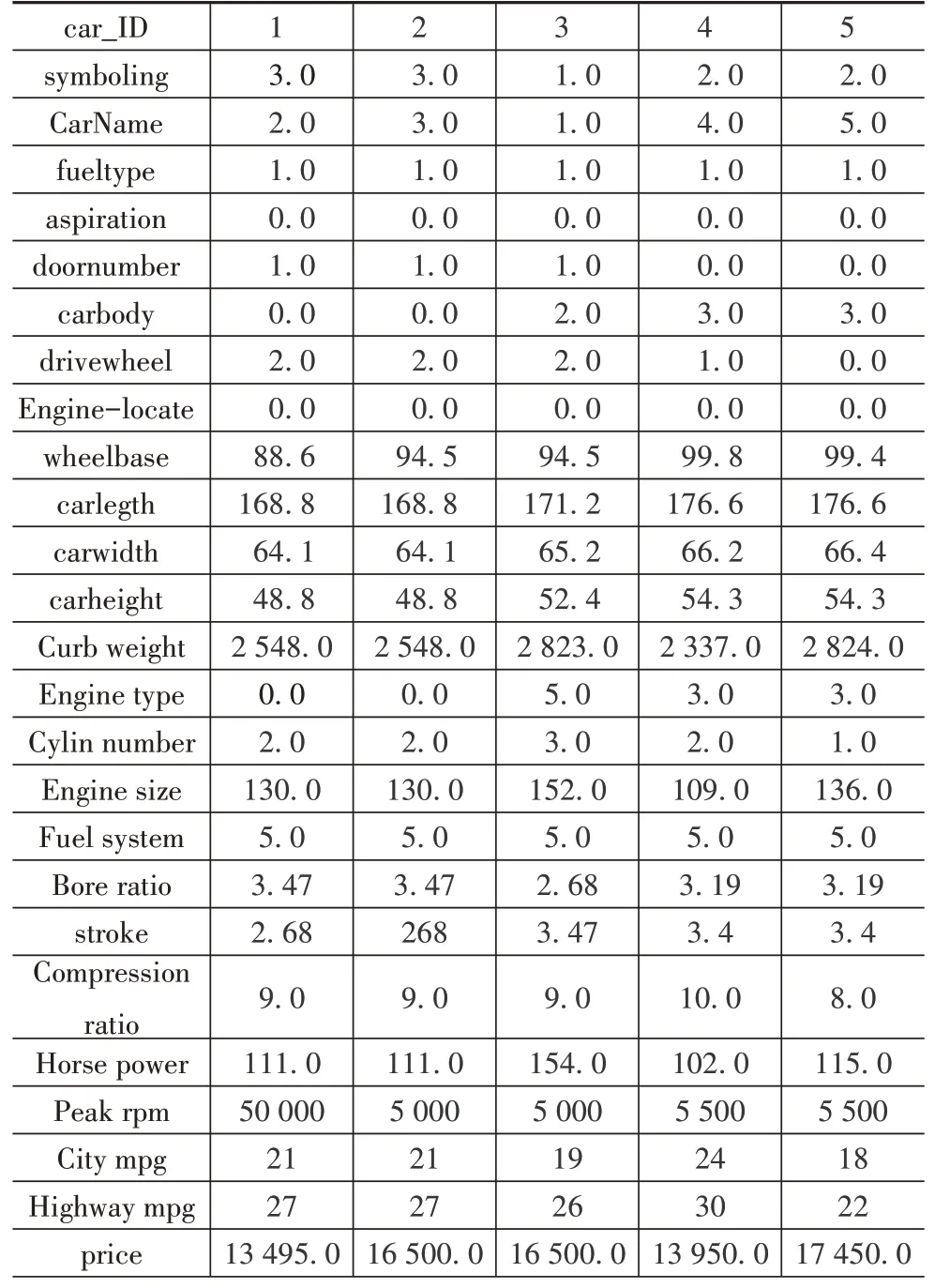
表7 編碼后的汽車聚類數據集
從表8 中可以看出,在車型信息數據集上,本文算 法 的Sav 值 為0.554 1,比IMFO-KMC 提 高 了0.116 3,比KMC 提高了0.149 6,比SSA-KMC 提高了0.194 3,本文算法在聚類車型信息數據集時使得車型同類之間距離更小,類別之間距離更大,聚類效果最佳。

表8 車型信息數據集的Silhouette指標
通過聚類可以將相似的汽車屬性聚為一類,然后利用聚類結果分析各個類的差別以及同類汽車屬性的差異。例如:某客戶中意奧迪車,可以找出audi汽車的聚類結果,如表9 所示。也可以找出audi 品牌下audi 5000 所在的類別5,并統計出類別為5 和carbody標簽為wagon 的所有車輛,然后按價格排序,供消費者選擇出最符合需求的汽車,如表10所示。
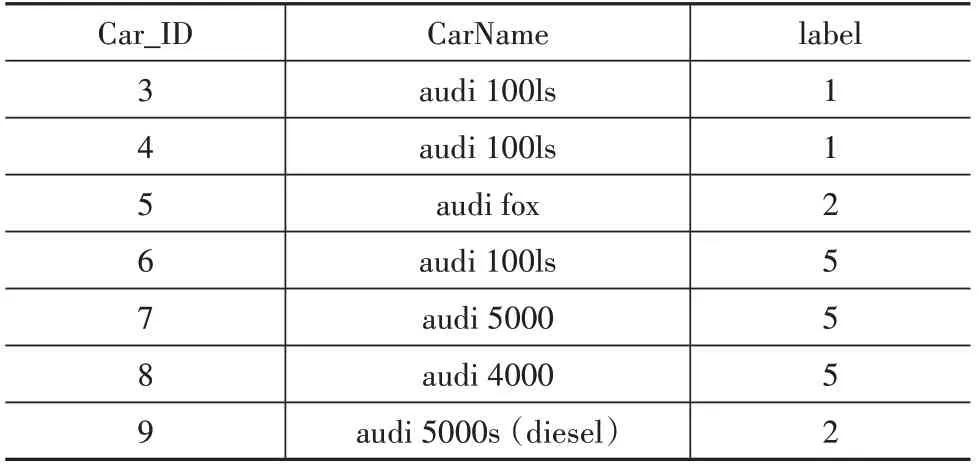
表9 audi汽車的聚類結果
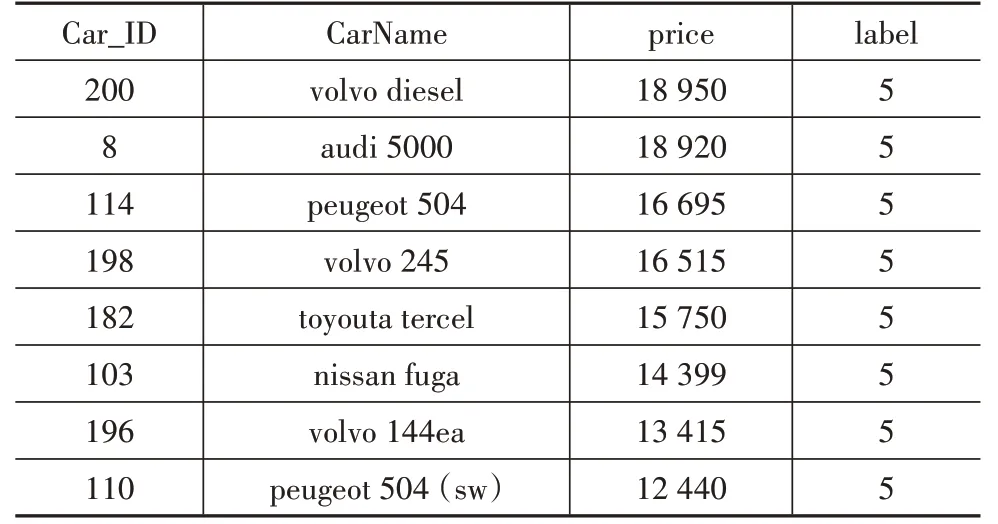
表10 按價格排序的audi 5000的競品車型
5 結論
本文提出了一種DHSSA 優化的K 均值互補迭代車型信息數據聚類方法。首先設計了一種擾動因子-領頭雀優化策略,由此提升SSA 的全局尋優能力,減小了由于SSA 易陷入局部最優造成的時間成本;然后利用篩選最大最小距離積法初始化中心,保證了各個中心最大程度地落在每個簇中;最后將DHSSA與KMC互補迭代,解決了聚類迭代過程中受離群點影響大以及路徑搜索能力不足的問題,減小了迭代次數,同時提升了搜索效率,得到較好的聚類結果。最后通過車型信息數據集聚類,驗證了本文算法的應用價值。
