基于改進YOLOX的交通標志檢測與識別
2022-06-15 15:52:45陳民?吳觀茂
現代信息科技 2022年2期
陳民?吳觀茂

摘? 要:現實中交通標志的檢測和識別具有環境多變的特點,交通標志長時間暴露在外經常會出現損壞情況,對檢測的精度和速度產生較大影響。利用最新的YOLO系列算法——YOLOX,對網絡結構的加強特征提取層進行改進,引入OPA-FPN網絡,相較于原來的PANet網絡,后者精度提升2.2%。在交通標志識別過程,對經典的卷積神經網絡模型LeNet-5進行改進,在數據集TT100K中進行實驗,相較于其他交通標志識別模型,使用改進的模型可以使識別正確率提升2.31%,識別時間減少了13.02 ms。
關鍵詞:單步路徑聚合網絡;YOLO;卷積神經網絡;FPN;LeNet-5
中圖分類號:TP273+.4? ? ? ? ? ? 文獻標識碼:A文章編號:2096-4706(2022)02-0101-04
Abstract: In reality, the detection and recognition of traffic signs have the characteristics of changeable environment. Traffic signs are often damaged after being exposed for a long time, which has a great impact on the accuracy and speed of detection. Using the latest YOLO series algorithm—YOLOX, the enhanced feature extraction layer of the network structure is improved, and the OPA-FPN network is introduced. Compared with the original PANet network, the accuracy of the latter is improved by 2.2%. In the process of traffic sign recognition, the classical convolutional neural network model LeNet-5 is improved, experiments are carried out in the data set TT100K. Compared with other traffic sign recognition models, using the improved model can improve the recognition accuracy by 2.31% and reduce the recognition time by 13.02 ms.
Keywords: single-step path aggregation network; YOLO; convolutional neural network; FPN; LeNet-5
0? 引? 言
隨著城市化的發展,人們的生活質量日益提高,道路上車輛的數量也遠超過從前,無人駕駛作為極具發展前景的技術也逐步進入百姓生活中。無人駕駛是在沒有駕駛人員的情況下由駕駛系統操控車輛,那么對于駕駛系統掌控道路交通信息就有著更加及時準確的要求。另外,道路堵塞、交通事故經常發生,交通標志檢測與識別也可以作為車載輔助系統的重要組成部分,可以防止駕駛員因疏忽大意或在惡劣環境下出現交通事故。因此,在最短時間內達到高準確率的檢測和識別極具挑戰。
交通標志都是以幾種簡單形狀中的一種構成背景,標志的顏色也是醒目的特定顏色,所以使用基于顏色和形狀的方法進行檢測[1],傳統的交通標志檢測算法有復雜度高、系統硬件要求高和需要對訓練數據進行不同的預處理等缺點。近年來,基于卷積神經網絡的目標檢測算法興起,包括一階段和二階段的算法,二階段算法是由R-CNN為代表的一系列算法[2],檢測精度較高。一階段算法是以YOLO系列為代表的,可以直接得到坐標和框的概率,YOLOv3選用Darknet-53作為主干網絡,使用了多標簽分類[3];YOLOv4輸入端采用Mosaic增強,主干網絡使用CSPDarknet-53[4];YOLOv5創新地使用了Focus的結構,將寬高信息集中到了通道信息[5]。
在交通標志檢測階段,本文使用基于端到端的目標檢測算法,對網絡中的Neck結構進行改進,使用高效的搜索架構得到最佳的特征金字塔路徑,對于破損、模糊的交通標志,在提高檢測精度的同時提升檢測速度;在標志識別階段,對經典的卷積神經網絡模型LeNet-5改進,可以在駕駛過程中實時地識別出類別繁多的交通標志。
1? 交通標志的檢測
YOLO系列算法檢測目標的速度很快,YOLOX是YOLO系列的改進版,綜合了系列網絡的優點,YOLOX是創視科技于2021年發布的新算法,創新地使用了解耦頭、Anchor-free和標簽分配策略SimOTA,YOLOX在所有模型尺寸上實現了比其他對應目標檢測算法更好的速度和準確性之間的權衡。
1.1? YOLOX算法結構
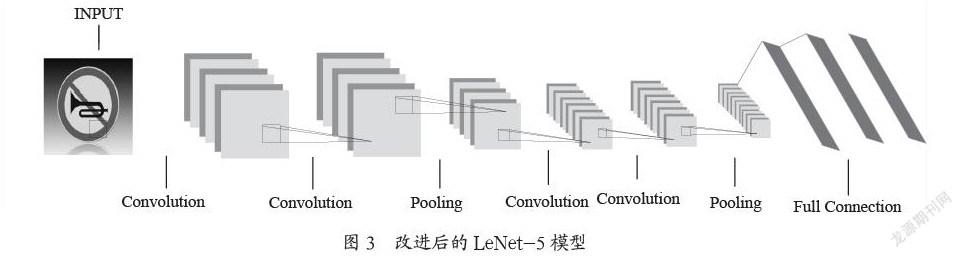
主干部分:YOLOX主干部分使用的是Darknet-53網絡結構。輸入640×640×3的圖片,首先使用Focus網絡結構,每隔一個像素拿到一個特征值,然后堆疊將寬高信息集中到通道信息,變成320×320×12的特征層;然后進行卷積標準化和SiLU激活函數,即Resblock-body操作,之后再進行四次Resblock-body的操作;特別地,在YOLOX中,SPP模塊被使用在主干特征提取網絡中,在最后一次Resblock-body的操作后,通過不同池化核大小的最大池化進行特征提取,提高網絡的感受野。
加強特征提取部分:在主干提取網絡部分獲得到三個有效特征層,分別是80×80×256、40×40×512、20×20×1 024的有效特征層,對深層特征層上采樣和淺層特征層融合,然后再將淺層特征層融合后的結果進行下采樣和深層特征層進行特征融合,即PANet結構,在經典特征金字塔網絡從上至下的過程后添加了從下至上的過程。
預測頭部分:目標位置的檢測是個回歸問題,在預測頭中,這些信息是糅合在一起的,而解耦頭就是將這些信息分成不同任務的預測頭。具體地,利用加強特征提取網絡可以獲得三個有效特征層,首先對輸入進來的特征層利用卷積標準化加激活函數進行特征整合,然后將預測分為分類和回歸兩個部分,分類部分利用兩次卷積標準化加激活函數判斷物體所屬的種類,回歸部分同樣的操作得到回歸預測的結果以及這個特征點是否有對應的物體。
1.2? 網絡結構改進
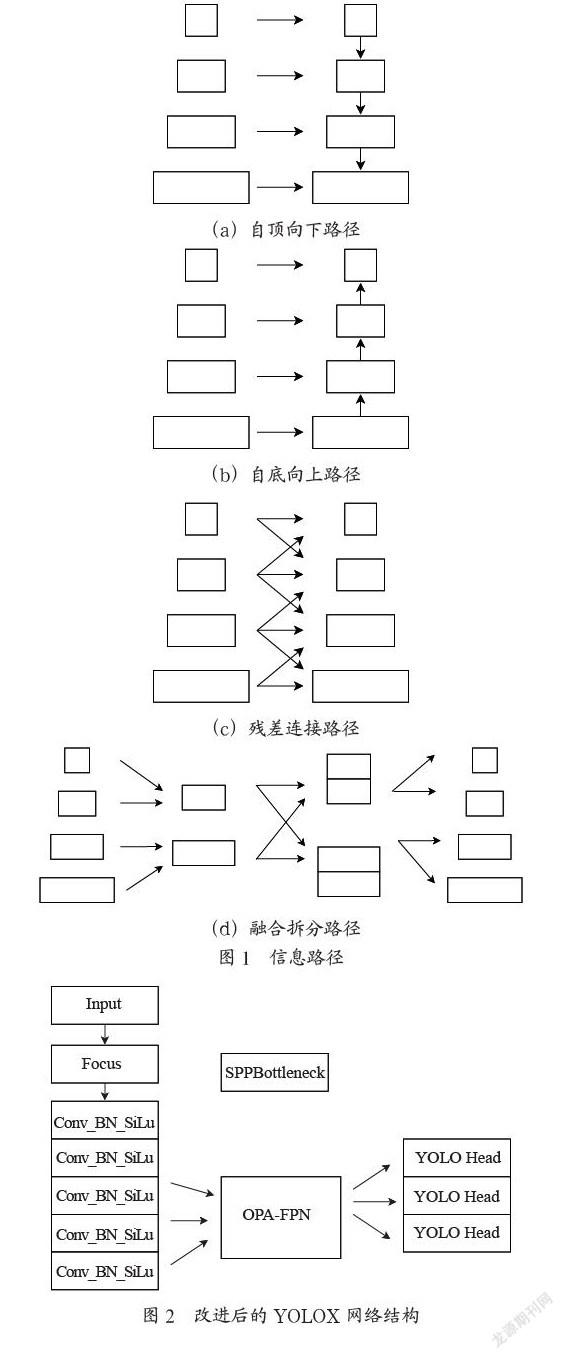
功能金字塔網絡(FPN)是最流行的目標檢測網絡的基本架構,并產生了許多重要的變體。它采用了用于圖像分類的骨干網模型,通過將骨干網特征層次中相鄰的兩層依次合并,形成自上而下的信息流。YOLOX使用的就是PANet的結構,低級功能可以被來自高級功能的語義信息所補充,盡管簡單有效,但FPN可能不是最佳架構設計。它有以下局限:第一個是效率低,由于搜索空間體積很大,搜索時間變長;第二個是適應性弱,只針對特定的檢測器。為了解決上述問題,首先提出了六種類型的信息路徑,可以捕捉多層信息,然后引入了一種新的高效搜索架構,它通過一次性搜索算法,從超級網中搜索最優子網,得到新的OPA-FPN架構。
具體的,有以下六種路徑:
如圖1(a),自頂向下路徑,這條路徑是由經典的功能金字塔網絡修改而來的,得到的特征圖都是與更高級別的特征圖迭代構建。
如圖1(b),自底向上路徑,與自頂向下的路徑相反。
如圖1(c),殘差連接路徑,通過合并鄰接層的特征,映射得到新的特征圖。
如圖1(d),融合拆分路徑,將最高的兩個特征映射到一個特征圖,將兩個最低的特征映射到另一個特征圖,然后將用連接的方式將它們融合,最后調整為多尺度特征金字塔結構。
最后兩條是殘差連接路徑、空信息路徑,這兩條路徑無參數,不參與計算,是為了降低模型復雜性實現更好的速度與復雜度平衡而設計的。
本文利用一種高效的一次性搜索方法搜索最優聚合網絡,即首先訓練一個超級網絡,然后用進化算法使用這六種路徑找到最優的路徑組合,數據證明OPA-FPN架構在訓練時間與準確度都強于目前所有的一階段和二階段檢測器,將OPA-FPN應用到YOLOX的加強特征提取網絡中,可以提高檢測性能。改進后的檢測網絡結構如圖2所示。
2? 交通標志的識別
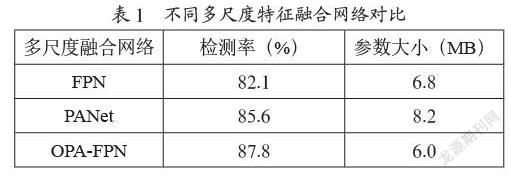
LeNet-5模型最初用于手寫體數字的識別[6],經典的卷積神經網絡模型,參數量少,結構簡單,包含輸入層、隱含層、輸出層。具體的,對于輸入的圖像,利用5×5大小的卷積核進行步長為1的特征提取,得到6個卷積后的特征圖,第二層進行池化操作,使得整體網絡參數變小,并保留特征,第三層還是卷積層,利用16個5×5大小的卷積核生成16個特征圖,繼續池化操作,再經過展平層調整為120個1×1大小的向量,最后加入有64個神經元組成的全連接層,輸出10個概率預測手寫的數字。雖然LeNet-5模型結構簡單,相較于其他模型,處理速度很快,但是對種類繁多的交通標志進行準確分類,僅僅使用LeNet-5模型進行識別,無法實現最佳的效果。為此提出兩個改進。
改進一:將5×5大小的卷積核改進成為2個3×3大小的卷積核,變成兩個卷積層,一個池化層的結構。5×5的卷積核尺寸過大,模型復雜度變高,計算量會增加,不利于網絡的加深,2個3×3的卷積核特征學習能力更強。
改進二:將sigmoid函數更換為PReLU激活函數。Sigmoid函數處處連續便于求導,是良好的閾值函數,可以與概率分布函數相聯系,但是在趨向無窮的地方,容易發生梯度爆炸的現象,不利于深層神經網絡的反饋傳播,而PReLU激活函數由于參數較小,不會發生梯度爆炸的現象。
改進后的LeNet-5模型如圖3所示。
3? 結果與分析
3.1? 實驗環境
本實驗環境的操作系統是Windows10,使用Intel Core i5處理器,YOLOX網絡的深度學習框架為Darknet-53,LeNet-5模型的深度學習框架為Pytorch,調用CUDA10.0,cuDNN7.3加速,GPU為NVIDIA GeForce GTX 1650,配置8 GB顯存,20 GB內存。將輸入的圖片裁剪為416×416的大小,學習率設置為0.001,權重衰減為0.005,最大迭代次數為20 000。
3.2? 數據集
使用中國交通標志數據集TT100K,數據集中有10 349張訓練圖像、3 073張驗證圖像和6 107張測試圖像,共有221個類別。所有的照片都是在一天的不同時間和不同的照明條件下在移動的車輛上拍攝,模擬真實駕駛情況,包含的圖片面臨模糊、傾斜、強烈光照、雨霧天氣、光線昏暗等挑戰。數據集分為訓練集、驗證集和測試集。
3.3? 實驗結果
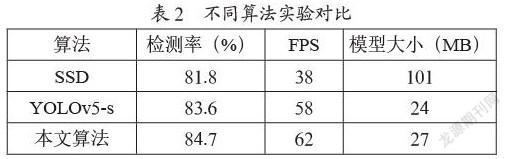
YOLOX使用的是PANet的結構,結合了自頂向下和自底向上的路徑,但是具有局限性,本文使用OPA-FPN的多尺度融合網絡,具有較高的精度和較少的參數量,如表1所示。
在交通標志檢測過程中,本文引入OPA-FPN架構改進YOLOX的Neck結構,如表2所示,本文模型在多尺度融合方法中取得較高精度的同時具有較小的參數量,改進后的YOLOX模型在滿足輕量化的條件下,與比同類型目標檢測算法相比,檢測率提升了1.1%。
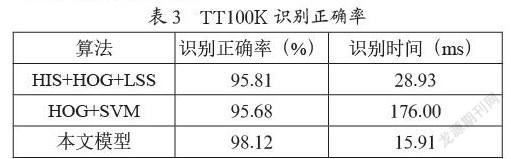
檢測過后的圖像送入LeNet-5模型識別標志種類的概率,從表3可以看出,相對于經典的交通標志識別模型HIS+HOG+LSS算法和HOG+SVM算法,在中國交通標志數據集TT100K上,本文使用改進的LeNet-5模型識別正確率和識別速度都更優。
圖4為本文模型在TT100K上檢測的效果。
4? ?結? 論
本文提出了一種改進YOLOX網絡的新算法,用于交通標志位置的檢測,然后對經典卷積神經網絡模型LeNet-5改進,用于交通標志的種類識別,旨在解決現存交通標志檢測與識別模型,處理速度慢檢測精度低,模型參數過大的問題,經實驗證明,本文改進后的模型略微提升模型大小,但使準確率和識別時間都達到更好的效果。
圖4? 實驗效果
參考文獻:
[1]陳維馨,李翠華,汪哲慎.基于顏色和形狀的道路交通標志檢測 [J].廈門大學學報(自然科學版),2007(5):635-640.
[2] REN S,HE K,GIRSHICK R,et al. Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(6):1137-1149.
[3] REDMON J,FARHADI A. YOLOv3:An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].(2018-04-08).https://arxiv.org/abs/1804.02767v1.
[4] BOCHKOVSKIY A,WANG C Y,Liao H Y M. YOLOv4:Optimal Speed and Accuracy of Object Detection [J/OL].arXiv:2004.10934 [cs.CV].(2020-04-23).https://arxiv.org/abs/2004.10934.
[5] YI Z T,WU G,PAN X L,et al. Research on Helmet Wearing Detection in Multiple Scenarios Based on YOLOv5 [EB/OL].[2021-11-16].https://mall.cnki.net/magazine/Article/IPFD/KZJC202105007096.htm.
[6] 趙志宏,楊紹普,馬增強.基于卷積神經網絡LeNet-5的車牌字符識別研究 [J].系統仿真學報,2010(3):638-641.
作者簡介:陳民(1997—),女,漢族,安徽濉溪人,碩士在讀,研究方向:目標檢測;吳觀茂(1965—),男,漢族,安徽歙縣人,副教授,博士,研究方向:深度學習。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
