中文命名實體識別的傅立葉卷積網絡
2022-06-15 15:52:45李彪
現代信息科技 2022年2期
摘? 要:針對transformer編碼器架構在中文命名實體識別任務上表現不佳的問題,提出使用無參數化的傅立葉子層替換編碼器中自注意力子層,使用卷積神經網絡替代前饋神經網絡。實驗表明,采用結合傅立葉變換和卷積神經網絡的transformer encoder架構的算法,可以在較小的字符嵌入和參數量下實現性能提升,且訓練過程更快。
關鍵詞:中文命名實體識別;編碼器;傅立葉變換;卷積神經網絡
中圖分類號:TP391;TP18? ? ? ? ? ? ? 文獻標識碼:A文章編號:2096-4706(2022)02-0104-03
Abstract: In view of the poor performance of transformer encoder architecture in the task of Chinese named entity recognition, a non-parameter Fourier sublayer is proposed to replace the self attention sublayer in the encoder, and a convolutional neural network is used to replace the feedforward neural network. Experiments show that the algorithm based on the transformer encoder architecture combining Fourier transform and convolutional neural network can improve the performance with small character embedding and parameters, and the training process is faster.
Keywords: Chinese named entity recognition; encoder; Fourier transform; convolutional neural network
0? 引? 言
命名實體識別是自然語言處理領域的重要基礎課題,旨在將文本中命名實體分類到預定義的類別,如人名、組織和公司等。自然語言處理領域的一系列下游任務都依賴于命名實體的準確識別,如問答系統和知識圖譜,甚至在推薦系統領域內NER也開始扮演著重要角色。
現有的標準NER模型將命名實體識別視作逐字符的序列標注任務,通過捕獲上下文信息預測每個命名實體的預定義標簽分類概率。該領域內的主要模型可以大致分為以條件隨機場為代表的概率統計模型和以BiLSTM-CRF[1]為代表的深度學習模型。
Transformer[2]架構在NLP領域的其他任務中快速地占據了主導地位,通過從輸入的組合中學習更高階特征的方式靈活地捕獲不同語法和語義關系。但其核心的注意力子層在方向性、相對位置、稀疏性方面不太適合NER任務。
本文引入無參數的傅立葉變換子層和卷積神經網絡單元對Transformer架構中注意力子層和前饋神經網絡單元進行完全替代,改進后的Transformer結構解決了中文命名實體識別中模型特征提取能不足和中文潛在特征表示不充分的問題。傅里葉子層和卷積神經網絡單元的參數規模和并行性能使得該架構在小規模語料、較小字符嵌入和快速訓練場景中更具實用性。模型在CLUENER2020[3]中文細粒度命名實體識別數據集上取得了較好的實驗性能。
1? 相關工作
近年來,基于深度學習的實體識別方法開始成為主流研究方向。Collobert[4]等提出使用卷積神經網絡完成命名實體識別任務。RNN模型因為能夠解決可變長度輸入和長期依賴關系等問題被引入NER領域,BiLSTM-CRF模型使用雙向長短期記憶網絡和其他語言學特征提升模型識別效果。
傅立葉變換作為神經網絡理論研究的重要方向。Chitsaz等在卷積神經網絡中部署了FFT以加快計算速度,Choromanski等利用隨機傅立葉特征將Transformer自注意力機制的復雜性線性化,而James等[5]提出的FNet網絡更是在訓練速度和模型精度上取得了成功。
本文提出了一種基于新型Transformer編碼結構的命名實體識別方法,通過引入無參數化的快速傅立葉變換彌補Transformer結構的自注意力機制在中文命名實體識別任務中方向性和相對位置上的不足,并采用更適合上下文信息交互的卷積神經網絡替換Transformer結構中密集的全連接層。新型Transformer編碼結構結合BiLSTM-CRF模型,在不引入先驗知識和預訓練信息的基礎上,采用更少的詞嵌入長度、參數量和標注數據語料即可充分捕獲文本序列的潛在特征,構建一種遷移能力更強、完全端到端的命名實體識別模型。
2? FTCN模型
FTCN模型共包含三個部分:FTCN編碼模塊,BiLSTM模塊和CRF模塊。FTCN編碼模塊支持隨機初始化并自主訓練詞向量和預訓練詞向量微調兩種詞嵌入方式。BiLSTM模塊通過引入門控機制充分提取文本的雙向語義特征。最后,CRF模塊采用動態規劃算法將BiLSTM輸出的特征向量解碼為一個最優的標記序列。
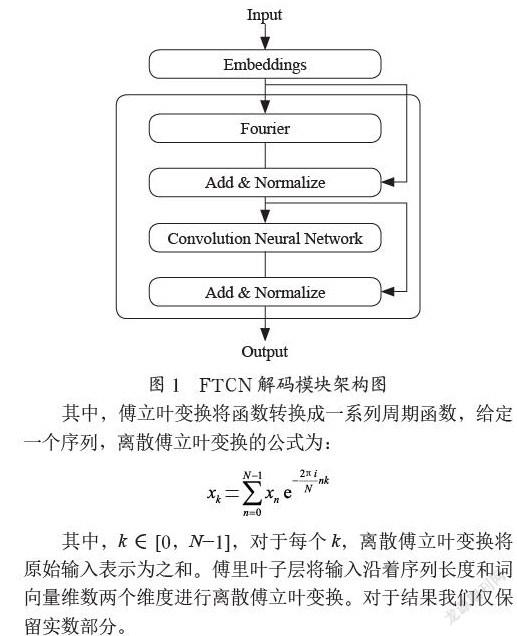
2.1? FTCN解碼模塊
FTCN-Encoder是一種無須注意力機制的Transformer架構,其中每一層由一個傅里葉子層和一個卷積神經網絡子層組成,模塊結構如圖1所示。本質上,本文是將每個Transformer架構的自注意力子層替換成一個傅里葉子層,該子層將輸入序列沿著序列長度和詞向量維數兩個維度進行離散傅立葉變換。同時,本文使用卷積神經網絡取代每個Transformer架構的前饋神經網絡,卷積神經網絡可以模擬實現類似n-gram模型的效果,充分挖掘上下文字符之間的語義特征,相較于前饋神經網絡參數量更少且更適合命名實體識別任務。
其中,傅立葉變換將函數轉換成一系列周期函數,給定一個序列,離散傅立葉變換的公式為:
其中,k∈[0,N-1],對于每個k,離散傅立葉變換將原始輸入表示為之和。傅里葉子層將輸入沿著序列長度和詞向量維數兩個維度進行離散傅立葉變換。對于結果我們僅保留實數部分。
同時,如果保留Transformer中的前饋神經網絡,則FTCN-encoder模塊將退化成無卷積神經網絡參與的FTNN-encoder模塊。FTCN-encoder模塊的特征提取能力更強,且可以通過設置各子層的連接方式,選擇ResNet連接或Concat連接。而FTNN-encoder模塊的連接方式則更適合ResNet連接,模型參數量過大且難以收斂。
2.2? BiLSTM模塊
長短期記憶網絡是一種特殊的RNN網絡,在動態捕獲序列特征和保存記憶信息的基礎上引入門控機制和記憶單元。用于緩解長序列遺忘問題的三個門控機制分別為遺忘門、輸入門和輸出門,這種門控機制通過對記憶單元的信息進行有效遺忘和記憶,能夠學習到長期依賴并解決了不同長度輸入和RNN容易產生梯度消失和爆炸的問題。BiLSTM是對長短期記憶網絡的一種優化改進,使用正向和反向長短期記憶網絡來提取隱藏的前向語義信息和后向語義信息,實現對上下文數據的充分利用。
2.3? CRF模塊
通常,基于概率統計的機器學習和深度學習都是將命名實體識別任務視作序列標注問題,所以多采用Softmax等分類器完成多分類任務。但Softmax分類器忽略了預測標簽之間的依存關系,而依存關系是命名實體識別中重要的機制。條件隨機場模型可以考慮標簽序列的全局關系,得到全局最優的標注序列。
3? 實驗與分析
本文采用控制變量的方法進行實驗設計,為了驗證傅立葉卷積網絡FTCN的性能和各個結構對性能提升的占比,將采用統一的數據處理方法、相同的運行環境和訓練參數設置。模型的差異度僅存在于不同的結構構成,共同部分確保一致。在每輪實驗中都讓模型得到充分訓練,并采用多輪測試取平均的方式作為最終的性能指標,排除隨機性和其他實驗干擾。
3.1? 實驗數據及評價指標
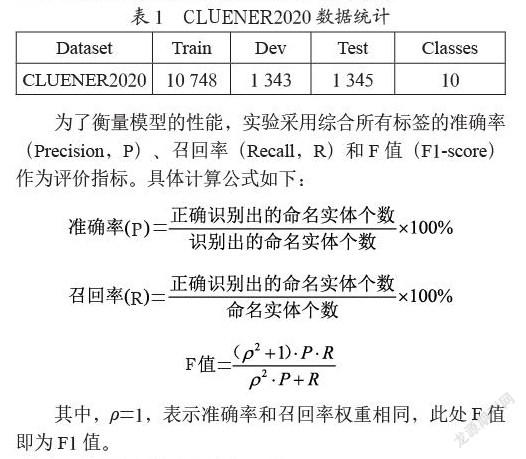
本文使用中文細粒度命名實體識別數據集CLUENER 2020,本數據是在清華大學開源的文本分類數據集THUCTC基礎上,選出部分數據進行細粒度命名實體標注。CLUENER2020采用四元標記集{B,I,O,S},標注了包括組織、姓名、地址、公司、政府、書名、游戲、電影、組織機構和景點共計10個標簽類型。其中B表示命名實體的第一個詞,I表示命名實體的其余詞,O表示非命名實體詞,S則表示命名實體為單個字符。與其他可用的中文數據集相比,CLUENER2020被標注了更多的類別和細節,具有更高的挑戰性和難度。CLUENER2020數據集的信息統計如表1所列。
為了衡量模型的性能,實驗采用綜合所有標簽的準確率(Precision,P)、召回率(Recall,R)和F值(F1-score)作為評價指標。具體計算公式如下:
其中,ρ=1,表示準確率和召回率權重相同,此處F值即為F1值。
3.2? 模型搭建和參數設置
實驗使用PyTorch搭建模型,并保證模型的數據處理和訓練、測試部分代碼的一致性。PyTorch是一個基于Torch的Python開源機器學習庫,用于自然語言處理等應用程序。實驗所涉及模型的參數設置如下:輸入維度為128,訓練集和測試集的batch_size為32,訓練學習率為0.01,dropout參數均為0.5,FTCN中卷積核kernel_size設置為3和5并保證輸出維數與輸入維數一致。
3.3? 實驗結果
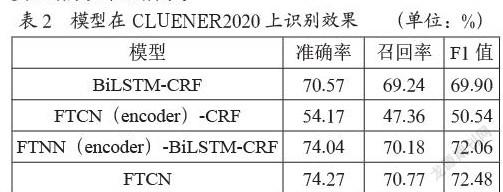
在CLUENER2020數據集上,為了有效驗證FTCN模型的性能,本文采用以下四種方法進行實驗設置:CLUENER2020數據集中的基線模型BiLSTM-CRF、采用FTCN解碼模塊的FTCN(encoder)-CRF、將FTCN解碼模塊中卷積神經網絡替換為transformer中前饋神經網絡的FTNN(encoder)-BiLSTM-CRF和本文提出的FTCN模型。實驗結果如表2所示。
從表2中可以看出,BiLSTM-CRF的F1值為69.90%相較于CLUENER2020數據集中提出的基線模型取得了相近的結果;FTCN(encoder)-CRF模型由于缺少BiLSTM模塊所以取得較差的成績;FTNN(encoder)-BiLSTM-CRF由于FNN導致編碼模塊的特征提取能力不足;本文提出的FTCN模型在準確率、召回率和F1值三項評價指標上均取得了最優,對比CLUENER2020提出的baseline即BiLSTM-CRF模型將F1值從70%提升至72.48%,提升幅度約為3.54%,并且模型訓練速度顯著提升,收斂更為迅速。
4? 結? 論
本文提出了一種全新的端到端神經網絡FTCN,并將其應用于中文命名實體識別任務中且在CLUENER2020中文細粒度命名識別數據集上驗證了模型的性能。該模型的編碼模塊使用類似Transformer編碼的架構,使用傅立葉變換子層取代了Transformer中的自注意力子層,并選擇更適合自然語言處理任務的卷積神經網絡代替前饋神經網絡。在降低模型參數量的基礎上,提升了模型的并行程度,充分挖掘上下文字符間的語義信息,提升了命名實體識別的性能。
參考文獻:
[1] HUANG Z,XU W,YU K. Bidirectional LSTM-CRF models for sequence tagging [J/OL].arXiv:1508.01991 [cs.CL].[2021-11-02].https://arxiv.org/abs/1508.01991.
[2] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is all you need [J/OL] arXiv:1706.03762 [cs.CL].[2021-11-02].https://doi.org/10.48550/arXiv.1706.03762.
[3] XU L,DONG Q,LIAO Y,et al. CLUENER2020:fine-grained named entity recognition dataset and benchmark for Chinese [J/OL].arXiv:2001.04351 [cs.CL].[2021-11-05].https://doi.org/10.48550/arXiv.2001.04351.
[4] PINHEIRO P O,COLLOBERT R. Weakly Supervised Semantic Segmentation with Convolutional Networks [J].arXiv:1411.6228 [cs.CV].[2021-11-03].https://arxiv.org/abs/1411.6228.
[5] LEE-THORP J,AINSLIE J,ECKSTEIN I,et al. FNet:Mixing Tokens with Fourier Transforms [J].arXiv:2105.03824 [cs.CL].https://doi.org/10.48550/arXiv.2105.03824.
作者簡介:李彪(1996—),男,漢族,安徽蚌埠人,碩士研究生在讀,研究方向:人工智能、自然語言處理、數據挖掘。
