基于GA改進BP神經網絡預測熱變形流變應力模型的建立
2022-06-15 05:54:14汪雅婷黎俊良袁楷峰陳廣義
材料工程 2022年6期
汪雅婷,黎俊良,袁楷峰,陳廣義*
(1 佛山科學技術學院 機電工程與自動化學院,廣東 佛山 528200;2 西安熱工研究院有限公司,西安 710054)
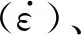
與傳統的BP神經網絡模型相比,遺傳算法(genetic algorithm,GA)的添加能在有限的訓練數據中進行數據優化,通過優化輸入層、隱含層和輸出層的初始權值、閾值,減少了收斂到局部最優的可能性[15],增強實驗數據與預測數據的相關性,避免如BP神經網絡模型在訓練學習新樣本數據時遺忘舊樣本及輸出結果可能趨于局部最優解的缺點。而與蒙特卡羅的隨機模擬相比,GA通過重組和變異的方式,使得數據信息“繁衍進化”,優化預測結果。本實驗通過分析應力-應變曲線,采用GA對BP神經網絡預測應力-應變模型進行改進優化,對比了BP神經網絡模型和改進優化后的BP神經網絡模型的準確性。GA改進型BP神經網絡模型的建立有助于預測金屬不同變形溫度下的應力-應變曲線,為實際熱加工提供優化工藝、提高產品質量的理論指導。
1 實驗材料與方法
實驗材料為結構用鋼普遍采用的Nb-Ti-V微合金鋼,其主要化學成分(質量分數/%)為:0.12 C,1.47 Mn,0.01 Ti,0.007 V,0.042 Nb,0.25 Si,0.018 P,0.009 S,0.0039 N,Fe余量。利用線切割機對鑄造樣坯切割出圓柱狀試樣(φ10 mm×15 mm),使用Gleeble-3500熱模擬機對試樣進行等溫恒應變速率壓縮實驗,壓縮變形量均為60%,變形溫度分別為1000,1050,1100,1150,1200 ℃;應變速率分別為0.01,0.1,0.5,1,3 s-1。將試樣放置熱模擬機中,以10 ℃/s的升溫速率加熱至變形溫度后保溫30 s,然后以不同的應變速率進行壓縮實驗,變形結束后立即水冷至室溫。實驗過程中,熱模擬機內需保持真空環境,試樣兩端添加金屬墊片,以減少由于端面摩擦而對測試數據產生的影響。實驗數據通過熱模擬機中自帶的數據采集系統軟件采集,從而得到不同應變量下的流動應力值。
2 應力-應變曲線分析
金屬的熱變形過程中必然存在著加工硬化、動態回復甚至動態再結晶。圖1為不同應變速率下Nb-Ti-V微合金鋼的應力-應變曲線,從圖中可以明顯看出,隨著應變量的增加,變形過程中應力急劇升高然后減緩,最后應力隨著材料的變形量增加而下降。這是由于在變形的初始階段(ε<0.1),加工硬化隨著應變量增加而增強,從而導致應力的上升;隨著應力達到峰值應力后,動態回復與動態再結晶的相“較量”會導致不同應力-應變曲線出現。當動態軟化弱于加工硬化時,應力會隨著應變的增加而持續上升并無峰值應力的出現;當動態再結晶和動態回復的軟化效果強于加工硬化時,應力會隨著應變的增加而下降并出現峰值應力,應變的持續增加,材料中的軟化效果會與加工硬化達到平衡,應力-應變曲線趨于平穩,進入穩態流變階段。圖1(e)中Nb-Ti-V微合金鋼的部分應力-應變曲線的應力值隨著應變在0.7之后的增加而呈現上升趨勢。這是由于在具有較高層錯能的Nb-Ti鋼中,動態再結晶的回復效果發生一定程度上的減弱,從而導致加工硬化再次占據主導地位,應力-應變曲線出現“上翹”[16]。Nb-Ti-V微合金鋼在同一變形溫度不同應變速率下的應力-應變曲線如圖2所示。由圖中可以看出,同一應變、同一溫度下流變應力隨著應變速率的增加而增大,應力-應變曲線中峰值應力隨著應變速率的增加而增大,其對應的應變值也增大;而在同一應變和應變速率下,流變應力隨著變形溫度的升高而降低,峰值應力隨著變形溫度的升高而降低,峰值應力對應的應變值減小。應變速率的提高意味著完成相同變形量的時間減少,位錯的湮滅速率小于增殖速率,位錯累積導致流變應力提高;變形溫度越高,原子的擴散和運動越劇烈,代表著Nb-Ti-V微合金鋼中的位錯更輕易擺脫第二相粒子的釘扎作用,致使流變應力隨著變形溫度的升高而明顯降低。
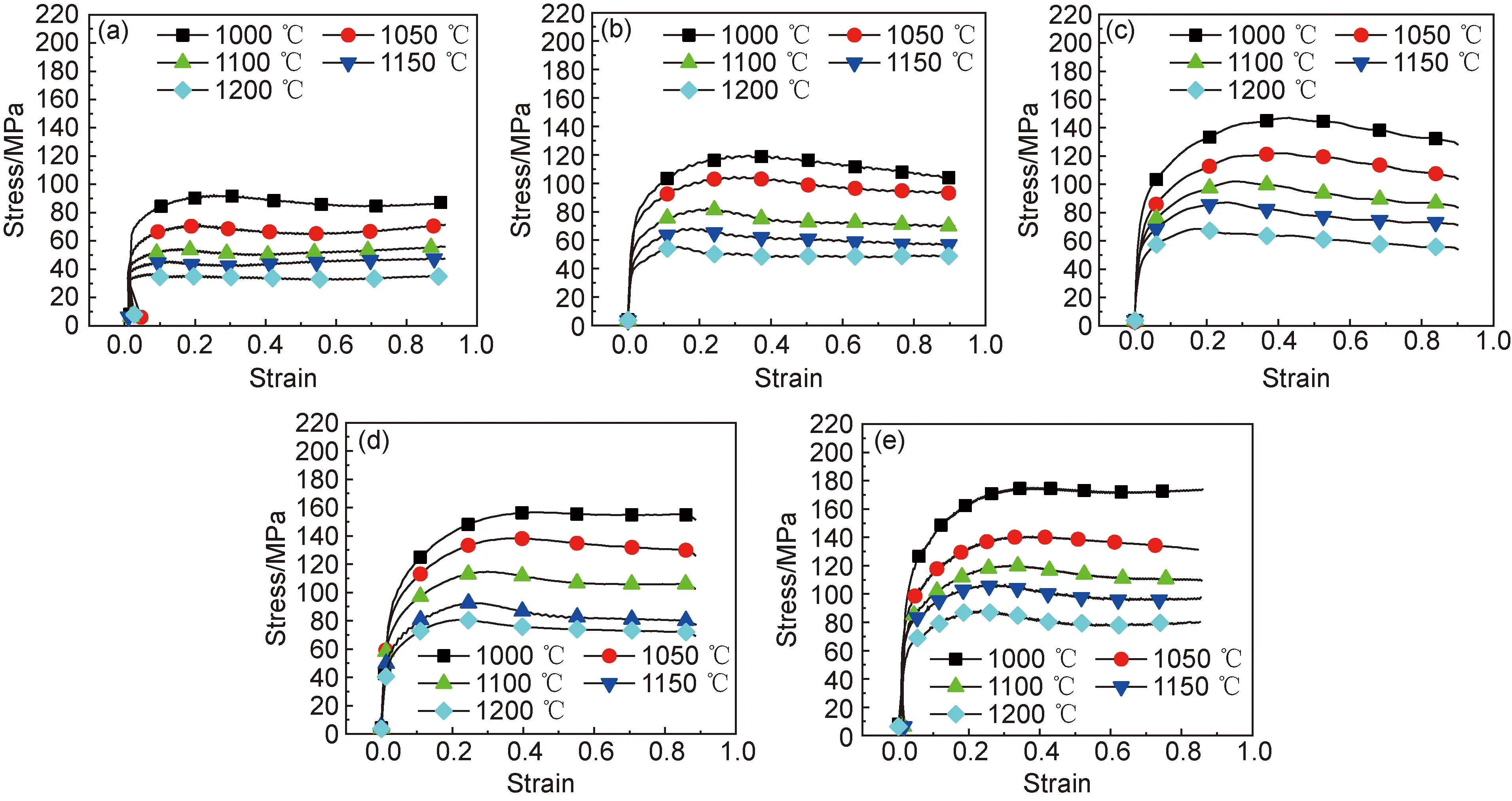
圖1 不同應變速率下不同溫度的應力-應變曲線
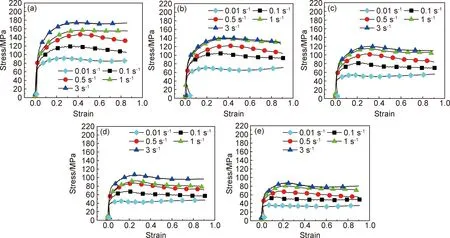
圖2 不同變形溫度下不同變形速率的應力-應變曲線
3 GA改進型BP神經網絡模型的建立
3.1 樣本的選取
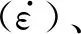
(1)
(2)
式中:Z為Zener-Hollomon參數;Qdef為熱變形激活能,J·mol-1;R為氣體常數,J·mol-1·K-1;T為絕對溫度,K;α,A,n均為材料常數。
在現有的人工神經網絡模型中,BP神經網絡是一種預測金屬高溫變形行為的有效方法。而溫度、應變速率和應變作為金屬熱變形過程中影響流變應力大小的重要參數,在神經網絡模型中需作為輸入層參數,輸出層為流變應力。GA算法在全局范圍內搜索得到訓練所需的最優權值和閾值,再輸回BP神經網絡模型中進行局部搜索從而得到誤差更小的預測值。本實驗工作所建立的GA改進型BP神經網絡模型的運行結構示意圖如圖3所示,其中隱藏層結點個數為i,輸入層到隱藏層的權重為U,隱藏層到輸出層的權重為W。
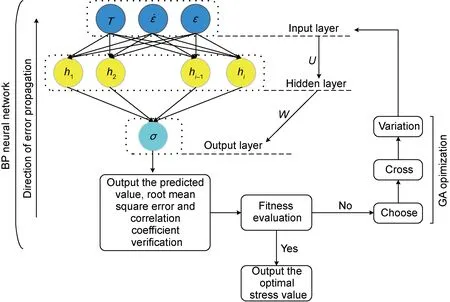
圖3 GA改進型BP神經網絡模型結構
Nb-Ti-V微合金鋼的25組熱模擬數據中,為了保證訓練數據量,選取23組數據作為模型訓練數據,2組作為測試數據。其中,訓練數據包含了應變速率0.01~3 s-1、變形溫度1000~1200 ℃,而測試數據為應變速率0.5 s-1、變形溫度1050 ℃和應變速率1 s-1、變形溫度1100 ℃的熱模擬數據,具體數據劃分如表1所示。
3.2 歸一化處理
(3)
式中:X′為歸一化得到的數據;ymin,ymax為歸一化處理中的兩邊界值,即為0和1;x為樣本數據;xmin,xmax分別為樣本數據中的最小值與最大值。而在模型輸出結果后,需要將其進行反歸一化后,結果轉換為應力值再進行誤差分析,數據反歸一化遵循:
y′=(y-ymin)(xmax-xmin)+xmin
(4)
式中:y′為反歸一化后得到的數據。
3.3 訓練參數設置
在評估模型數據的多樣性時,均方誤差(RMSE)越低,可顯示模型預測效果越好。而確定隱藏層的神經元數量是至關重要的,設置“合適”的神經元數量能提高模型的計算精度。本模型在確定隱含層神經元個數n1時,遵循的經驗公式為[20]:
(5)
式中:m為輸入層節點數目;n為輸出層節點數目;a在[1,10]范圍內取任意自然數。控制模型訓練次數為2000,學習速率為0.01,目標訓練誤差為0.0001的條件下,根據經驗公式進行窮舉運算,得出隱含層神經元個數取[3,12]之間自然數時的均方根誤差,確定最佳隱含層節點數,其中均方根誤差(RMSE)公式為:
(6)
式中:Ei為實驗值樣本;Pi為預測值樣本;N為樣本的總數。模型運行所得均方差結果如圖4所示,可以看出,隨著神經元個數的增加,訓練集均方根誤差顯著減小,當隱含層神經元個數為12時,RMSE值達到最小。因此,可確定最佳BP神經網絡模型的網絡結構為3-12-1。
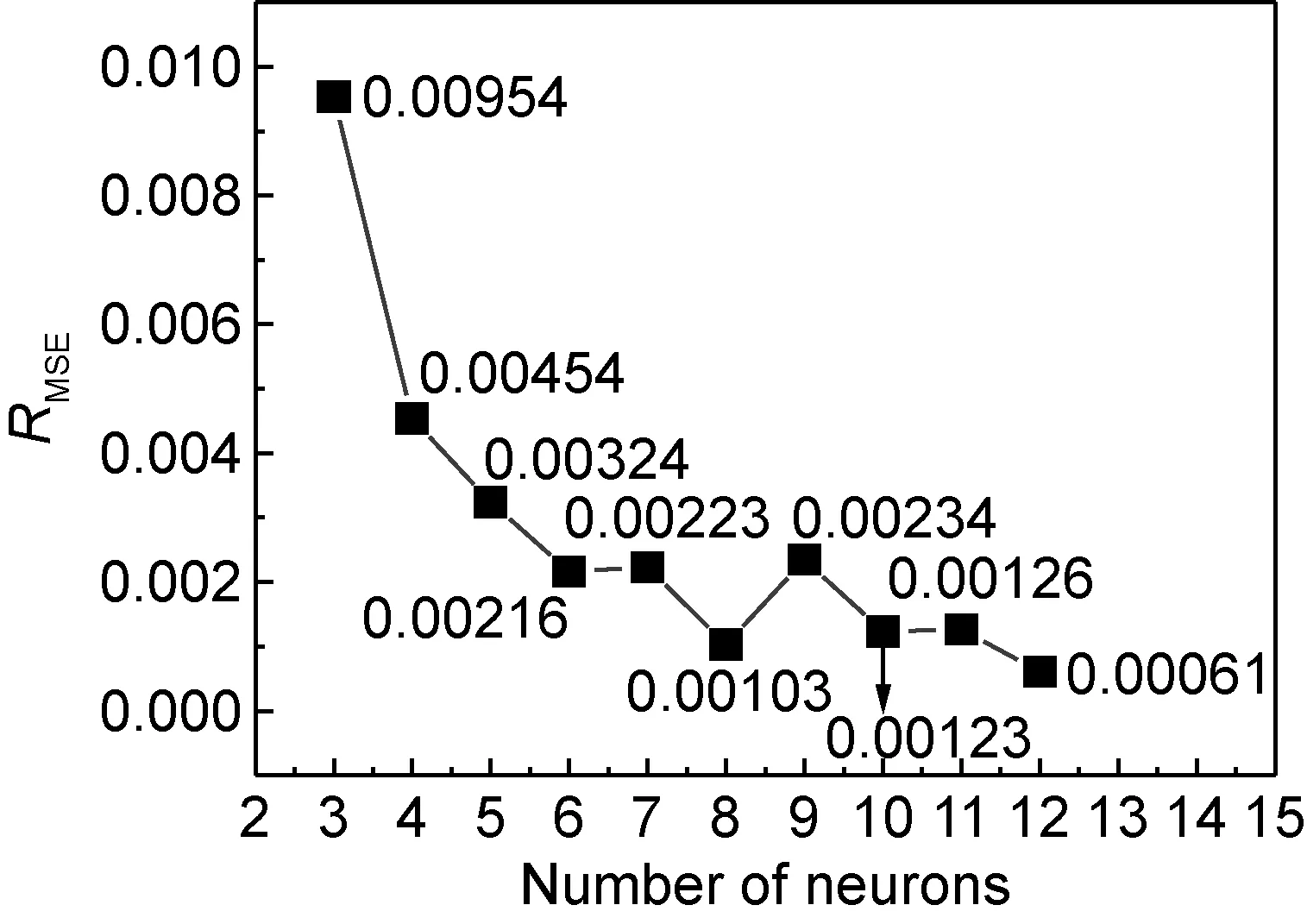
圖4 確定過程中隱含層節點數與訓練集均方根誤差的關系曲線
構建出最佳BP神經網絡模型后進行訓練,設置訓練次數為2000,學習速率為0.01,動量因子為0.01,訓練誤差設置為0.0001。
3.4 誤差反向傳播過程
各輸出層神經元的輸出誤差被計算記錄后,模型會通過誤差梯度下降法對各層的權值和各層的節點閾值進行調整,會得到較為優異的輸出值,且接近期望值。
每個輸入層的二次型誤差準則函數為[15]:
(7)
式中:p為訓練數據樣本;Ep為神經網絡在第p個樣本輸入下的偏差;L為輸入結點總數;Tk為第k個節點的實驗值;Ok為第k個節點的輸出值。
模型對p個訓練數據的總誤差準則函數為:
(8)
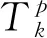
則輸出層權值的調整公式為:
(9)
式中:wni為連接輸出層的第n個神經元和穩藏層的第i個神經元的權值;Δwni為wni的變化量;η為學習速率;φ′為輸出層的激勵函數導數;netk為第k層網絡;yi為輸出層第i個神經元的值。
輸出層閾值調整公式為:
(10)
式中:ak為輸出層閾值;Δak為ak的變化值。
隱含層權值調整公式為:
φ′(netk)·wni·?′(netk)·xj
(11)
式中:wij為連接隱藏層的第i個神經元和上一個隱藏層的第j個神經元的權值;Δwij為wij的變化量;?′為隱含層的激勵函數導數;xj為隱藏層第j個神經元的值。
隱含層閾值調整公式為:
φ′(netk)wni·?′(netk)
(12)
式中:θ為隱藏層的閾值;Δθ為隱藏層閾值的變化值。
遺傳算法尋最優值閾值參數設置為:訓練次數2000,學習速率為0.01,動量因子為0.01,訓練目標誤差0.0001,種族群規模為30,進化迭代次數為50,交叉概率與變異概率分別為0.8和0.2。
4 模型對比及實驗驗證結果
測試數據根據式(3)輸入神經網絡熱變形預測模型后,應變速率為0.5 s-1、變形溫度1050 ℃和應變速率為1 s-1、變形溫度1100 ℃兩組測試數據經不同模型輸出的預測數據誤差結果如圖5所示。由圖可明顯看出,經GA算法改進型BP神經網絡模型預測的數據誤差基本以0參考線上下波動,并且波動幅度明顯小于經BP神經網絡模型預測的誤差曲線。
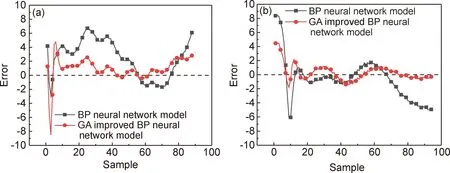
圖5 不同樣本中BP神經網絡模型和GA改進型BP神經網絡模型輸出值的訓練誤差曲線
測試數據經BP神經網絡和GA改進型BP神經網絡預測后輸出預測結果,并與實驗結果相比較,如圖6所示。由圖6可以明顯看出,經實驗驗證,GA優化改進后BP神經網絡模型預測的應力值與實驗值有較好的重合度,應力應變曲線動態趨勢一致,其重合度要明顯優于BP神經網絡模型的預測結果。證明采用GA優化改進后的BP神經網絡所預測的應力應變曲線具有更優異的精度,能為工業生產軋制工藝提供更好的理論指導,能夠大大降低重復做實驗的時間成本和材料成本。
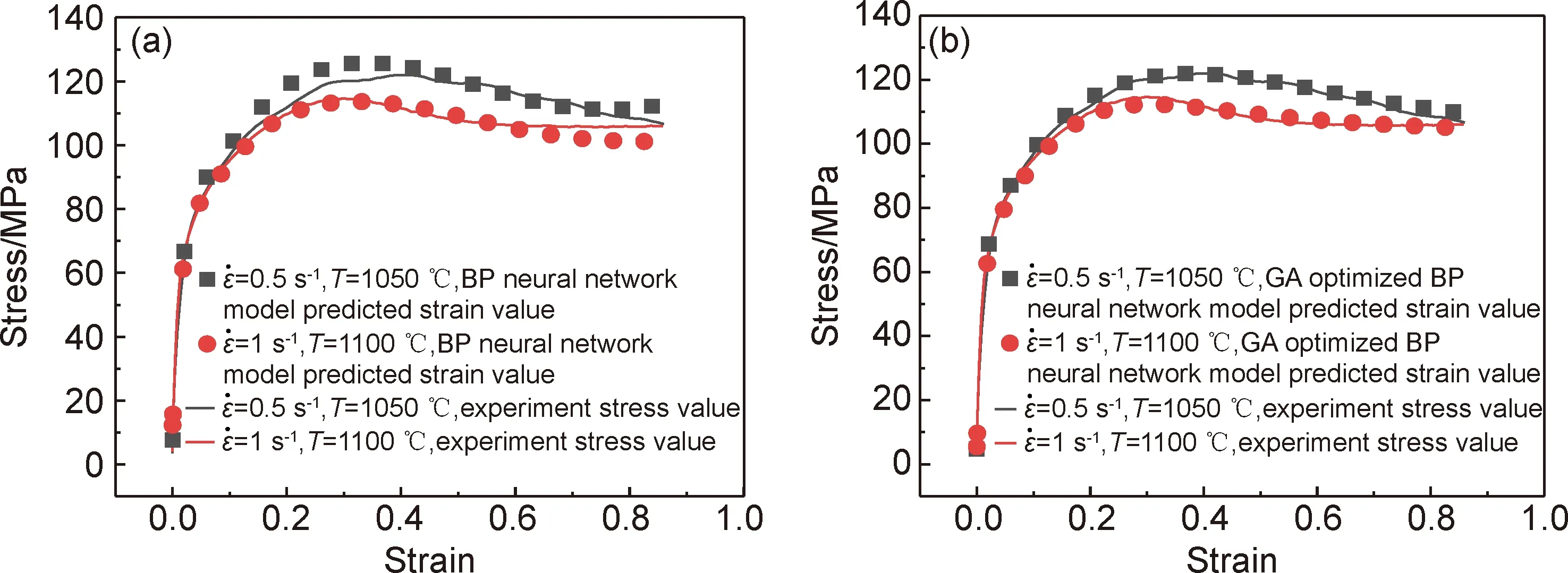
圖6 BP神經網絡(a)及GA改進型BP神經網絡(b)預測應力值與實驗數據曲線對比曲線
相關系數(R)常用于表示預測數據和實驗數據之間的線性關系。R的計算如下式所示:
(13)
式中:N為采集的分析數據點個數;σe為試樣熱壓縮實驗所得到的應力值;σp為BP神經網絡模型或GA改進型BP神經網絡模型所預測的應力值。通過式(13)對GA改進型BP神經網絡模型預測結果與BP神經網絡模型預測結果進行相關系數計算,得到結果如圖7所示,預測數據與實驗數據的相對誤差分布如圖中矩形分布圖。模型經GA優化改進后,應變速率為0.5 s-1、變形溫度1050 ℃和應變速率為1 s-1、變形溫度1100 ℃的預測應力值與實驗應力值的相關系數分別為0.99202和0.99734,較BP神經網絡模型預測結果的相關系數要更優異。在相對誤差分布上,傳統BP神經網絡所預測的兩組熱模擬數據的應力值相對誤差范圍較廣,分別在[-2,6]和[-2,4]之間;經GA優化改進后預測的兩組數據預測應力值的相對誤差主要處在[-2,2]范圍內,占70%以上,且相對誤差平均值均小于BP神經網絡模型的相對誤差平均值。
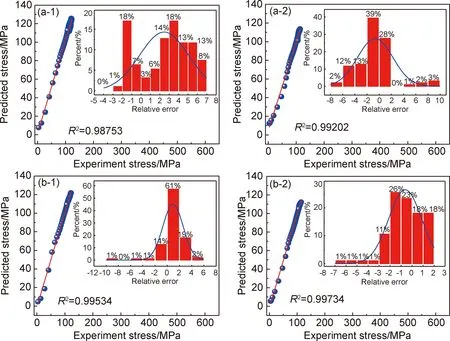
圖7 不同條件時,BP神經網絡(1)和GA改進BP神經網絡(2)預測的應力值與實驗值線性關系圖、相對誤差比值與相對誤差值分布圖
由于預測值與其實驗值相比,部分數據會出現偏高或者偏低的現象,因此需要引入平均相對誤差(δMRE)作為模型的評估條件之一,其可以被認為是用于確認模型可信度的無偏統計量,評估預測的準確性和可靠性[21-22]。平均相對誤差值(δMRE)[11,23]的計算公式為:
(14)
與預測值和實驗值的擬合相關系數相比,平均相對誤差更能體現基于GA改進BP神經網絡預測模型預測的應力值與實際實驗得到的應力值之間的偏差,也能定量評價模型的預測準確性。由式(14)計算得到由BP神經網絡模型預測兩組測試數據的平均相對誤差分別為3.5346%和11.4829%,而由GA改進型BP神經網絡預測模型所預測的平均相對誤差僅為2.7816%和2.1703%,結合上述擬合相關系數和相對誤差的分布可說明所建立的GA改進型BP神經網絡預測模型具有良好的預測能力。
5 結論
(1)從BP神經網絡模型和GA改進型BP神經網絡模型預測的數據與實驗數據對比來看,BP神經網絡模型經GA優化改進后,預測應力值與實驗應力值的相對誤差在[-2,2]區間內的數據占比達70%,相關系數分別達到0.99202和0.99734,平均相對誤差僅為2.7816%和2.17034%,說明遺傳算法(GA)對BP神經網絡模型有著良好的優化改進,大大提高了模型的預測精度。
(2)通過測試數據與實驗數據的對比分析得出,在較大應變范圍內,模型預測結果與實驗結果只有較小的誤差,經GA優化改進后的模型具有良好的穩定性和預測性,能較好地預測不同熱變形參數下的應力應變曲線。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
中華詩詞(2020年1期)2020-09-21 09:24:52
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小學生作文(中高年級適用)(2018年5期)2018-06-11 01:22:56
中學生數理化·七年級數學人教版(2017年11期)2017-04-23 07:18:00
數學大王·中高年級(2016年12期)2016-12-26 21:37:36
光學精密工程(2016年6期)2016-11-07 09:07:19
