結合價格波動策略與動態回溯機制的蟻群算法
2022-06-17 07:10:56趙家波游曉明
計算機與生活 2022年6期
關鍵詞:信息
趙家波,游曉明+,劉 升
1.上海工程技術大學 電子電氣學院,上海 201620
2.上海工程技術大學 管理學院,上海 201620
旅行商問題(traveling salesman problem,TSP)是一類經典的組合優化問題,可以描述為一位旅行商從某一城市出發,要求不重復通過所有規定的城市,最后回到最初城市的最短路徑問題。
在20 世紀90 年代,意大利學者Dorigo、Maniezzo等人受到自然界螞蟻覓食的啟發,模擬螞蟻覓食的行為,提出了蟻群算法(ant colony optimization,ACO),并應用于旅行商的問題與分布式優化問題,取得了較好的結果。之后學者們根據自身研究領域將蟻群算法應用于配電網故障定位、火力分配問題、網絡路由問題、車間調度問題等。
由于信息素的正反饋作用,螞蟻系統在后期常常因為個別路徑信息素的快速積累導致螞蟻不會選擇其他路徑,從而陷入局部最優問題。為了避免信息素的過度積累,減少陷入局部最優的概率,Dorigo在螞蟻系統(ant system,AS)算法的基礎上提出蟻群系統(ant colony system,ACS)算法,并提出了全局信息素更新方式與局部信息素更新方式,加入局部搜索算法,改善了算法陷入局部最優的情況。之后,為了避免信息素過多而導致陷入局部最優,Stutzle 等人提出了最大-最小螞蟻系統(max-min ant system,MMAS),通過分別設置信息素最大最小閾值,將信息素的濃度控制在一定范圍內,從而避免信息素的不斷堆積造成局部最優。以上是經典的蟻群算法,雖然它們具有高效的探索尋優能力,但仍存在著容易陷入局部最優、收斂速度慢等問題。針對這些問題,許多學者提出各自的改進策略。
一些學者在加快蟻群算法的收斂速度上做出一些改進,如文獻[9]結合遺傳算法,提出使用螞蟻的基因控制螞蟻選擇城市,減少算法初期探索全部路徑的時間成本,加快算法前期收斂速度。文獻[10]通過全局路徑重新設定初始信息素分布,使得算法前期路徑的探索具有一定導向性,并且通過信息素的二次揮發,加快算法后期的收斂能力,使算法能夠在較短時間內找到較優解。文獻[11]提出一種改進的信息素差異化更新策略,在所有螞蟻完成本次路徑構建后,對優于平均路徑長度的路徑進行信息素加強,對劣于平均路徑長度的路徑進行信息素削弱,從而增大較優路徑的吸引力,削弱較差路徑對螞蟻路徑選擇的干擾,加快算法整體的收斂速度。上述學者較好地解決了蟻群算法收斂速度慢的問題,但算法仍存在易陷入局部最優的問題。文獻[12]提出一種具有記憶特征的區間蟻群優化算法,將信息素濃度推廣為一定區間范圍,不再束縛于信息素為某一定值,并引入長短時記憶的信息素更新方式,對應不同的揮發系數,使得算法呈現更具層次的多樣性。文獻[13]為了解決算法陷入局部最優的問題,使用平滑信息素的方法削弱所有路徑信息素的差異性,并通過自適應改變算法的取值,增大算法接受隨機解的概率,從而實現跳出局部最優。文獻[14]根據蟻群算法與魚群算法的優勢互補,提出一種先魚群再蟻群的混合算法,通過更新率的調整,前期借助魚群算法找到更多的解,當更新率達到某一值時,轉為蟻群算法進行更好的尋優,當算法陷入局部最優時,再通過更新率的變化轉為魚群算法,從而平衡收斂速度慢、易陷入局部最優等問題。雖然以上改進的蟻群算法都從加快收斂速度與提高多樣性進行改善,但在解決中大規模的TSP 問題中仍然存在收斂速度慢且容易陷入局部最優等問題。
為了在中大規模TSP 問題中較好地平衡解的多樣性與收斂速度的關系,本文提出一種結合價格波動策略與動態回溯的蟻群算法(ant colony algorithm based on price fluctuation strategy and dynamic backtracking mechanism,PBACO)。在價格波動策略中,結合時間序列思想將蟻群算法完整迭代周期根據不同需求分為三類,并根據價格波動平衡,將影響價格波動的供求關系進行匹配,通過分析算法在各類時期的不同需求,對信息素揮發因子進行自適應動態供給,來滿足算法各階段的動態需求,較好地改善算法整體性能。當價格波動策略的供給關系無法實現平衡時,算法將面臨局部最優問題,此時引入動態回溯機制,以迭代最優螞蟻的個體相似度作為標準,將路徑信息素回溯至相似度差異顯著的時期,而非將路徑信息素清零,保證了算法收斂速度的同時能夠有效跳出局部最優。通過MATLAB 對TSP 中的不同測試集進行仿真,結果表明該算法在保證收斂速度的基礎上,有效提高了解的質量,較好地平衡了多樣性與收斂速度的關系。本文的主要工作總結如下:
(1)結合時間序列的思想,將蟻群算法完整迭代周期根據不同內在需求分為A、B、C 三類,并采用價格波動策略對三類不同時期的不同需求,自適應調整信息素揮發因子進行動態供給,使算法能夠在不同時期對多樣性差與收斂速度慢的問題做出相應的改善,優于傳統算法恒定的信息素揮發因子。
(2)通過分析三類不同時期的陷入局部最優情況,引入斐波那契數列抽樣來判定算法是否陷入局部最優,而非傳統算法逐個判斷若干代最短路徑均不變的方法。采用斐波那契數列抽樣的方式通過抽樣更少樣本數來判定陷入局部最優,節約時間成本,同時對不同時期采用不同的最大樣本數,更為合理地進行抽樣樣本數的調整,進一步加快算法收斂速度。
(3)在算法陷入局部最優后,最優路徑信息素積累較多,此時引入動態回溯機制,以迭代最優螞蟻的個體相似度作為標準,將路徑信息素回溯至相似度差異顯著的時期,可以將路徑信息素重置為若干代前的路徑信息素,這樣既增加了下代螞蟻選擇路徑的多樣性,同時未完全重置信息素,節省了螞蟻重新構建路徑信息素的時間成本,在保證收斂速度的同時能夠有效跳出局部最優。
1 相關工作
1.1 ACS 蟻群算法1.1.1 路徑構建
ACS 中每只螞蟻從城市到城市的選擇公式:
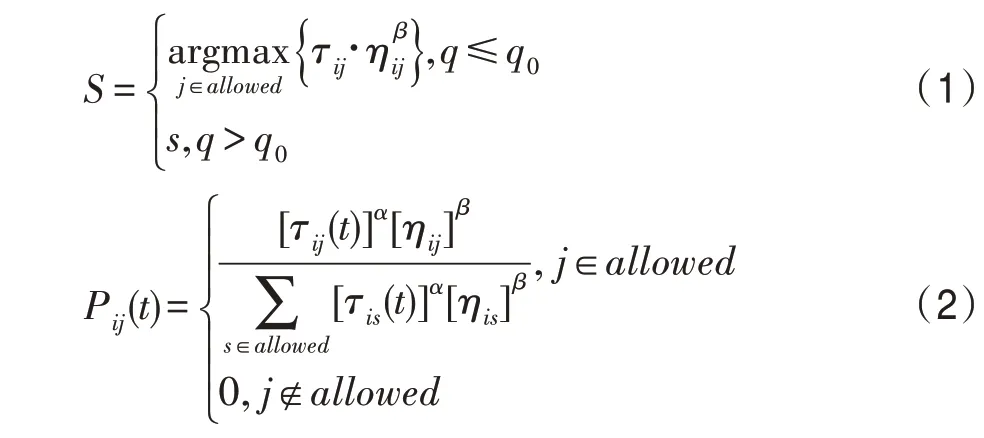
其中,τ()代表著時刻城市和城市之間的信息素的濃度大小,每條邊上的起始濃度都是相同的,記為。 η代表的是、城市之間距離d的倒數,即η=1/d。是在區間[0,1]的常數值,是在區間[0,1]的隨機數,∈表示城市屬于禁忌表外的可選城市集合。表示當≤時將要被選擇的下一個城市。是式(2)輪盤賭的選擇方式。、分別表示信息啟發式因子和期望啟發式因子,越大,表示對下一條路徑選擇受啟發式信息素的影響越大,而值越大,表示對下一條路徑選擇受城市間距離的影響越大。
式(1)、式(2)表明,當≤時,城市之間信息素高的城市和距離相對近的城市被選擇的概率更大,當不符合上述條件,采用式(2)輪盤賭進行路徑構建。
ACS 蟻群算法的更新機制分為局部信息素更新和全局信息素更新兩部分。
全局信息素更新:當所有螞蟻都完成一次迭代之后,算法只對當前最優路徑上的信息素進行更新,通過算法的正反饋作用,使得最優路徑和非最優路徑上的信息素的差距逐漸拉大,為蟻群的路徑選擇增加指向性,加快了算法的收斂速度。公式如下:
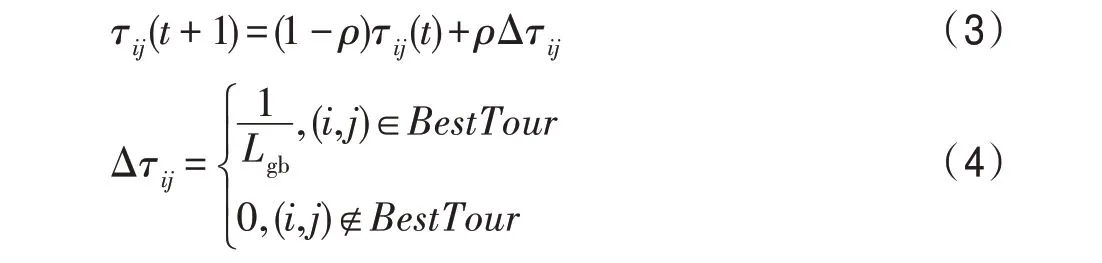
其中,是全局信息素的蒸發率;Δτ是信息素增量;是當前最優路徑長度。
局部信息素更新:當每只螞蟻完成一次周游后,算法便會對其走過的路徑進行局部信息素更新。局部信息素更新是對所有螞蟻都進行更新,其作用是為了縮短最優路徑和非最優路徑之間信息素的差距,增加算法的多樣性,提高算法全局搜索能力,避免陷入局部最優。公式如下:
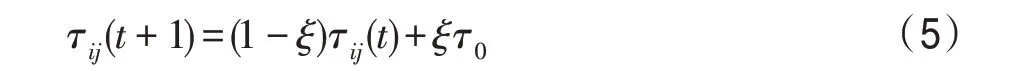
其中,Δτ是信息素增量;為每條邊上的起始濃度;是局部信息素的蒸發率。
1.2 時間序列分析法
時間序列分析法是統計學中常用于預測未來發展變化趨勢的一種方法,能夠以時間的推移預測市場需求趨勢,通過將經濟跌漲、購買力大小、價格變動等同一常數的觀察值,按照時間順序進行排列,再運用數理統計方法對市場未來趨勢的變化進行預測,來確定市場的預測值。
一個時間序列通常由四種要素組成:長期趨勢變動、季節變動、循環變動和不規則變動。長期趨勢變動是指時間序列在長時期內呈現出來的持續向上或持續向下的變動;季節變動是指時間序列在隨季節而重復出現的周期性波動,受氣候條件、節假日等各種因素的影響;循環變動是指時間序列變化為非固定時長的周期性波動,其循環周期與趨勢不同,它并非是單一方向的長時變化,而是漲落有序的交替波動;不規則變動是指時間序列中除去以上三種要素所剩余的變動,通常隨機出現在時間序列中,使時間序列產生不平穩的震蕩波動。
時間序列函數可由以上四種元素進行表示,即=(,,,),常用所構建的模型可分為兩種,加法模型=+++以及乘法模型=***。當時間序列隨時間等寬推進時,常用加法模型;當時間序列的季節變動與長期趨勢變動成正比時,常用乘法模型。
1.3 個體相似度
在相似度算法的距離度量中,距離越近則兩者差異性較小,證明其相似度越高。但是這類相似度無法直接應用于蟻群算法中,因為當蟻群算法陷入局部最優時,其最優路徑基本保持不變,前后兩次路徑的差異性較小,相似度高,但是對于需要跳出局部最優的問題并非一個好的結果。
考慮到螞蟻個體在尋找路徑時是通過城市節點的連接來進行路徑尋優,個體之間形成的閉環路徑總會有一些相同路徑,因此可用個體間的相同路徑信息來表示個體之間的相似度,路徑信息相同數越多,則代表個體間的相似度越高,而相同數越少,也表示個體間差異性較為明顯。個體相似度的計算過程如下所示。
個體相似度的計算通過相同路徑的多少來進行,設兩個個體和,其路徑信息借助連接矩陣表示,如對應連接矩陣,對應連接矩陣,則有:
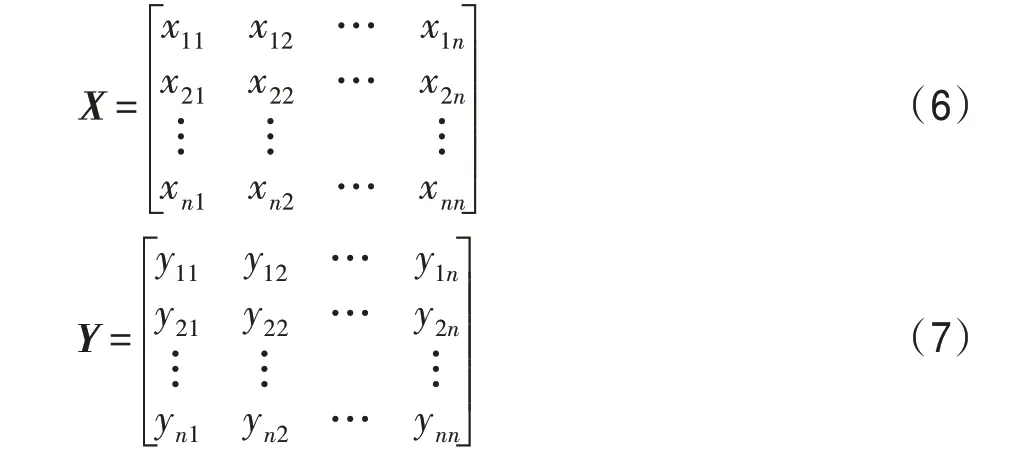
其中,代表城市數,在矩陣中,x表示城市至城市的路徑信息,如果個體的路徑信息中具有城市至城市,則使x=1,否則x=0;因為x與x均表示城市至城市的路徑信息,所以x=x,為對稱矩陣,個體的連接矩陣同理所示。
個體相似度借助連接矩陣則可以較為明顯地比較兩個個體的路徑信息。在算法運行初期,從隨機城市出發的兩個螞蟻個體可能走過完全不同的路徑,此時兩者的相似度應為0,在算法陷入局部最優或算法運行末期,因為信息素正反饋的作用,兩個螞蟻個體走過的路徑可能大體相同,此時兩者的相似度為1 或近似為1,所以可構建個體相似度函數,將兩個個體的相同路徑進行統計處理,使個體間的相似度處于0~1 的范圍。個體相似度函數的公式如下所示:
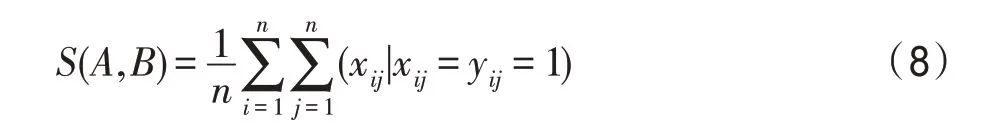
2 改進的蟻群算法
2.1 價格波動策略
價格波動策略結合了價格理論中商品的供求關系對價格的影響,在不同時期商品的價格會受供給和需求的不同而產生變化,但總體價格呈現出波動平衡的狀態。而傳統蟻群算法在進行路徑探索時,存在易陷入局部最優、收斂速度慢等問題,雖然后續提出信息素揮發因子來避免信息素過度積累,改善解的質量,但傳統蟻群算法的信息素揮發因子仍具有一定的局限性,信息素揮發因子作為蟻群算法的重要參數,設置為某一定值無法發揮其在算法各階段的不同作用,對算法整體的適應性較差,因此提出價格波動策略,使算法不同時期的供求關系處于動態平衡狀態。
時間序列分析法處理的數據通常是根據時間排列的數據,用來進行曲線的預測與內在發展趨勢的變化,本文通過將時間序列思想引入蟻群算法,對蟻群算法各時期的不同狀態進行分析分類,為2.1.2 小節價格波動策略的供求關系匹配奠定基礎。
下面將通過分析最短路徑收斂圖來對蟻群算法各時期的不同狀態進行分類,為了提高此分類方法的普適性,本文根據文獻[7]的ACS 算法,對城市集eil51、eil76、KroA100、KroB100、ch130、ch150、KroA200 和KroB200 進行15 次獨立實驗,獲取各城市集的最短路徑收斂圖。為了增強說服力,選取各城市集15 次實驗中的最優路徑收斂圖作為典型進行分析。
如圖1 所示,蟻群算法的收斂曲線是以迭代數為時間軸,對本次迭代最優螞蟻的最短距離進行統計,從而繪制成的曲線,因此曲線不會出現往上回升的變化,只存在下降與持平的情況。考慮到以上原因在蟻群算法的特殊性,蟻群算法最短路徑的變化曲線在結合時間序列思想時會對曲線的要素做出相應調整,構建符合蟻群算法邏輯的模型。
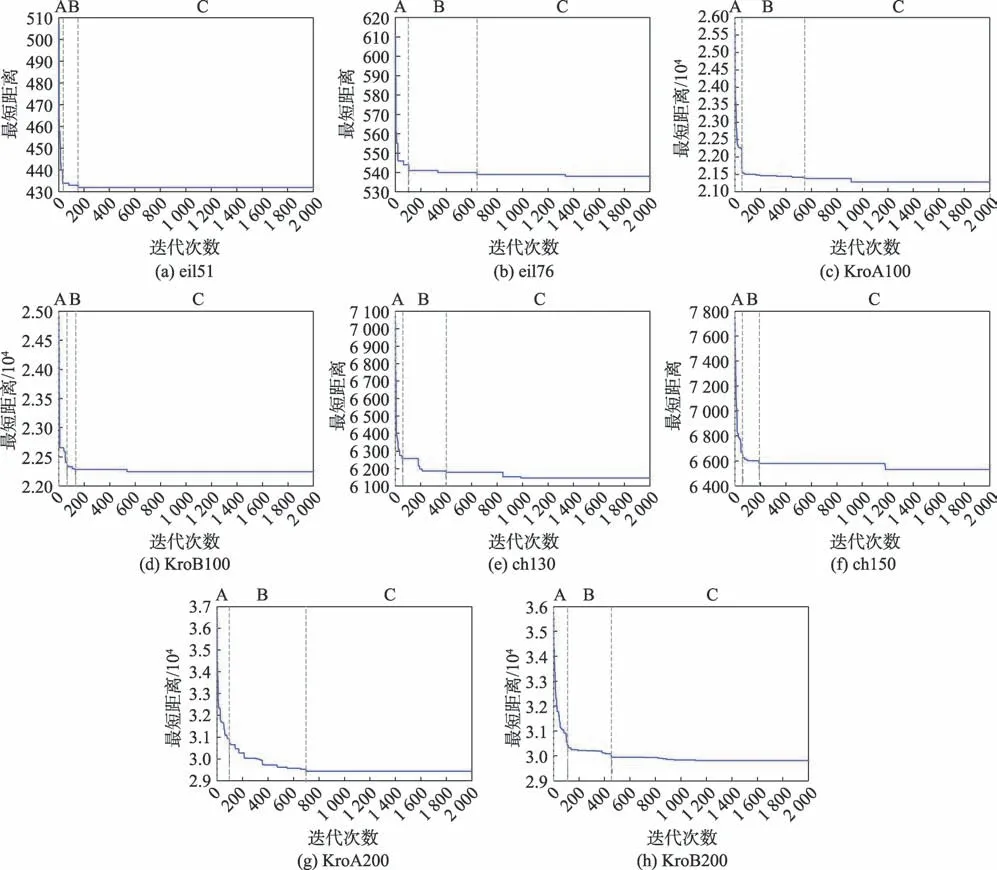
圖1 最短路徑收斂圖Fig.1 Shortest path convergence graph
圖1 將根據算法不同時期的不同變化對對應時期的曲線進行要素分類。在圖1 中,各城市集的最短路徑曲線都可分為A、B 和C 三個階段。在A 階段,各城市集曲線呈極速下降趨勢,階段特征為曲線在較少迭代數內落差明顯,此時處于算法前期,螞蟻主要受期望啟發式的影響積極探索路徑,稱之為極速下降變化;在B 階段,各城市集曲線呈階梯下降趨勢,階段特征為曲線在持平較短迭代數后發生下降變化,之后再次持平與下降,循環進行,此時處于算法前中期,路徑信息素積累至一定程度,螞蟻的路徑選擇受啟發式與信息素濃度的共同作用,波折探索更短路徑,稱之為階梯下降變化;在C 階段,各城市集曲線呈長期持平或長期持平后下降趨勢,階段特征為曲線在較長迭代數內持平,或在較長迭代數內持平后出現下降,此時處于算法中后期,信息素的正反饋積累使當前最優路徑的信息素達到較大值,陷入局部最優,算法只能通過輪盤賭的小概率來尋找更短路徑,因此曲線在較長迭代數保持持平,若能找出更短路徑,即出現下降現象,稱之為恒定兼隨機變化。
因為最優路徑曲線是以每代進行統計,以上四種分類滿足時間序列加法模型,所以可以構建價格波動策略分類模型,如式(9)所示。

其中,為最短路徑收斂曲線中的極速下降變化,為極速下降的時長,該時段算法多樣性較好,容易找出更優解;為最短路徑收斂曲線中的階梯下降變化,為階梯下降的時長,該時段信息啟發式與期望啟發式共同作用,算法多樣性逐漸降低,開始陷入局部最優,又跳出局部最優的階段;為恒定兼隨機變化,為恒定兼隨機變化的時長,該時期算法的多樣性較低,已經陷入局部最優問題,若能跳出局部最優,則為隨機變化,若未能跳出局部最優,則為長期恒定變化;為完整收斂曲線,為各階段時長的總和。
上述通過結合時間序列的思想,分析了蟻群算法最短路徑的變化曲線,將蟻群算法迭代周期分為三種階段時期,在不同時期算法具有不同的需求,而當信息素揮發算子設置為定值時,無法動態調整信息素在各個階段發揮不同的作用,對算法整體的適應性較差。因此本文提出一種價格波動策略,將影響價格波動的供求關系進行匹配,對信息素揮發因子進行動態調整,用于全局信息素更新公式中,來平衡算法各階段不同時期的需求。
在算法運行前期,即A 階段,最優路徑曲線處于極速下降變化階段,此時路徑信息素積累量較少,此時若將信息素揮發因子設定為較大值,雖然會削弱正反饋的作用,但此時算法會將期望啟發式因子作為主導地位,從而使螞蟻容易聚集在期望啟發式因子最強的路徑,變為類貪心算法,容易陷入局部最優;而將信息素揮發算子設為較小值時,有助于加快算法前期的收斂速度,因此在算法前期設置信息素揮發因子為較小值。在算法運行前中期,即B 階段,最優路徑曲線呈階梯下降階段,路徑信息素積累較為密集,易陷入局部最優,此時采用較大值的信息素揮發因子,來平衡最優路徑與其他路徑的差異性,使螞蟻選擇其他路徑的可能性增大,從而增加探索更優解的概率。在算法運行中后期,即C 階段,最優路徑曲線呈恒定兼隨機變化,算法跳出局部最優能力較弱,并在當前最優解上浪費了大量時間成本,因此此時應適當增加算法的收斂速度,應減小信息素揮發因子,以實現算法后期的快速收斂。
綜合上述分析,并結合MMAS 的范圍限制思想,本文構建一種服從高斯分布的自適應信息素揮發因子。
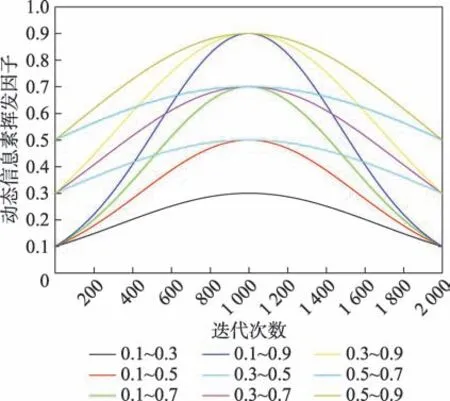
圖2 全局信息素揮發因子Fig.2 Global pheromone volatilization factor
由圖2 可知,在算法前期的A 階段,服從高斯分布的自適應信息素揮發因子將處于較小值,滿足算法前期信息素揮發因子較小的需求;當算法運行至中前期的B 階段,此時算法路徑信息素積累逐漸密集,且隨迭代數的增加與解的精度的提高,算法陷入局部最優后再跳出局部最優的能力逐漸減弱,此時需要信息素揮發因子也隨之增加,而服從高斯分布的自適應信息素揮發因子隨迭代數增加而增加,滿足此階段的需求;在算法中后期的C 階段,最優路徑信息素的積累達到較大值,隨迭代數的增加與信息素的積累,算法跳出局部最優的概率逐漸降低,此時算法會在當前最優解上浪費大量的時間成本,此時服從高斯分布的信息素揮發因子隨迭代數逐步減小,提升算法后期的收斂速度,滿足此階段的需求。
服從高斯分布的自適應信息素揮發因子公式如下所示:

全局信息素更新公式為:
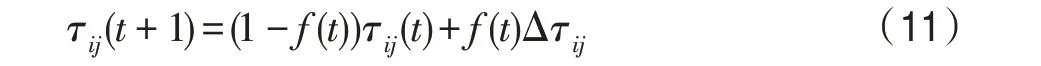
其中,是位置參數,這里設定為1 000;>0 是尺度參數;是調整倍數。通過調整和的值,使信息素揮發因子范圍保持在圖中各分布區間,對于具體參數選擇,在后續實驗中會進行分析對比,選出一組相對較好的參數。
2.2 動態回溯機制
動態回溯思想受中值法與最優化估計算法啟發,在進行優化計算時通過取區間中值來對最優解不斷逼近,當一次中值法結束,對最優解存在區間再次進行中值法,循環往復直至逼近最優解或得到最優解。而在蟻群算法中,常常會遇到陷入局部最優的問題,導致算法在較優解而非最優解浪費大量時間成本,并且解的精度提升較小,因此提出一種動態回溯機制來實現跳出局部最優,改善解的質量。信息素是蟻群算法的核心因素,螞蟻通過信息素的積累來進行下一個城市的選擇,而動態回溯機制正是通過將路徑信息素回溯至個體相似度差異顯著的時期,此時在未完全陷入局部最優的同時,保留路徑信息素的完整性,區別于將信息素初始化的大災變,節省時間成本,并能有效地跳出局部最優。
動態回溯的核心在于將信息素重置為較優迭代時刻,在判斷重置為哪些較優迭代時刻的選擇問題上,本文借助個體相似度作為標準,來判斷信息素較好的較優時刻,從而進行動態回溯。
該機制首先要對是否陷入局部最優進行判斷,傳統判斷局部最優方式為若干代的至今最短路徑是否均相等,此類判斷方法需要在每次迭代結束后將最優路徑與若干代前每一代的最優路徑進行對比,浪費了時間成本。本文借助斐波那契數列來對陷入局部最優進行判定,通過斐波那契數列的抽樣方式,結合價格波動策略不同階段時期的特殊情況,對算法是否陷入局部最優進行判定,在算法前期的A 階段,算法基本不會出現陷入局部最優的情況;在算法前中期的B 階段,算法會在陷入局部持續較短迭代數,再跳出局部,此時斐波那契數列抽樣的最大樣本數會相應減小;在算法中后期的C 階段,算法會陷入局部最優,并持續較長迭代數,此時斐波那契數列抽樣的最大樣本數會相應增加。如圖3 所示,對比傳統局部最優判定方式,假設樣本迭代數為50 代,即連續50 代的最短路徑均相等,最短路徑不發生變化時,判定算法陷入局部最優;而斐波那契數列抽樣的方式,在算法前中期設置最大樣本數為30,即可通過抽樣第1、2、3、5、8、13 和21 這7 組迭代樣本的最短路徑進行比較,從而判定算法是否陷入局部最優。在算法中后期適當提高最大樣本數,設置最大樣本數為50,抽樣方式同理。隨著斐波那契數列的遞進,樣本抽樣跨度顯著提高,可以省去檢測大量重復樣本的時間。采用斐波那契數列抽樣進行局部最優的判定,其優點在于能通過抽樣的方式快捷合理地判斷是否陷入局部最優,節約時間成本,并結合動態回溯機制實現跳出局部最優,使算法解的精度得到較好的提升。

圖3 斐波那契數列抽樣對比圖Fig.3 Comparison chart of Fibonacci sequence sampling
在算法運行時,若出現下一代最優路徑與至今最優路徑相等,則調用斐波那契數列函數進行判定,設定當前代斐波那契數為1,下一代斐波那契數為2,校驗后續滿足斐波那契數列代數的最優路徑,若經過斐波那契數列抽樣后的最優路徑都相等,則判定算法陷入局部最優。斐波那契抽樣函數公式如下:
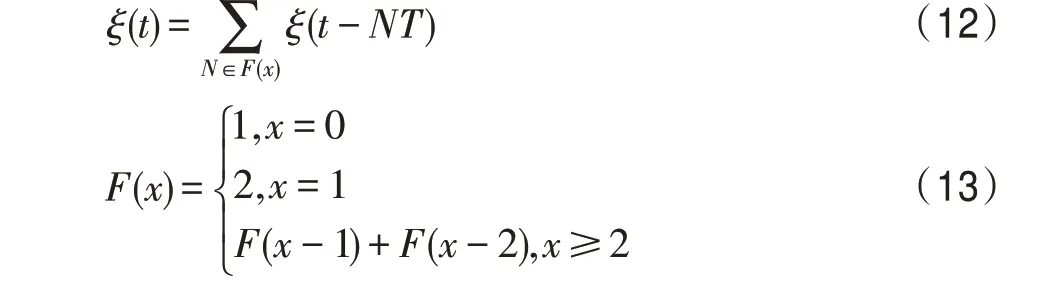
其中,為抽樣時刻;=1 為采樣周期;()為斐波那契函數;為整數。
若抽樣得到的最短路徑均相等,則判定算法陷入局部最優,此時對下一代螞蟻的路徑信息素進行回溯,通過式(14)相似度判別公式作為判定條件,回溯到滿足此條件且距離當前迭代數最近的較優代,根據式(15)重置其信息素,使其信息素回溯至若干代前個體相似度差異顯著的時期,借助此時跳出局部最優能力更強的信息素重新進行路徑尋優,迭代代,若仍未跳出局部最優則再次使用式(14),找出滿足條件的下一個較優代,再次進行信息素回溯,以此循環直至跳出局部最優或達到迭代最大代數,動態回溯示意圖與動態回溯機制流程圖如圖4、圖5 所示。

其中,為個體相似度判定算子,為0 至1 的某一常數。考慮到取1 時,等同于將信息素重置為與至今最優路徑相同的路徑信息素,并不一定能實現跳出局部最優。為滿足相似度判別公式時的迭代數。為信息素回溯后的迭代數,與成正比,當個體相似度高時,回溯的較優代與此時代數相差步長較小,陷入局部最優嚴重,需要迭代時間加長;反之當個體相似度低時,回溯的較優代與此時代數相差較大,信息素差異明顯,此時迭代時間適當縮小。

圖4 動態回溯示意圖Fig.4 Dynamic backtracking diagram
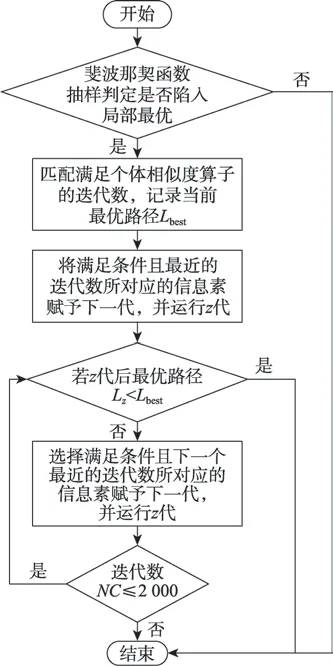
圖5 動態回溯機制流程圖Fig.5 Flow chart of dynamic backtracking mechanism
當價格波動策略難以通過自適應調整信息素揮發因子來滿足算法的需求時,算法陷入局部最優問題,此時將會啟用動態回溯機制,使跳出局部最優成為算法的首要任務,通過式(17)強制提升信息素揮發因子,使其達到最大值,來更好地解決跳出局部最優問題。
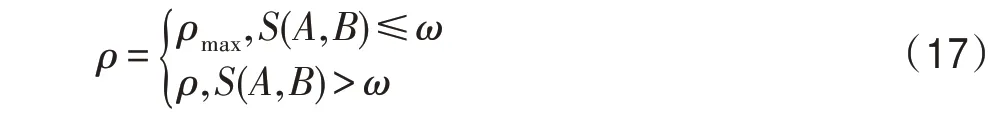
其中,為價格波動策略的最大揮發因子值,當(,)≤時,算法已經陷入局部最優,強制全局信息素揮發因子調整為最大值。
2.3 算法流程
初始化參數,=0。
將只螞蟻隨機分配到各個節點。
根據ACS 算法進行迭代,根據式(10)自適應調整信息素揮發因子,將式(11)作為全局最優更新公式進行信息素更新。
若發現相鄰兩代最優路徑的距離相同,調用斐波那契函數進行抽樣,若抽樣后的最優路徑距離不全部相同,則跳回步驟3;若抽樣后的最優路徑距離完全相同,則跳到步驟5。
當算法陷入局部最優時,根據式(14)進行動態回溯,匹配滿足個體相似度算子的迭代數,記錄至今最優路徑,根據式(15)將對應的信息素賦予下一代。
以重置后的信息素進行次迭代,若迭代數達到最大迭代時,則找到并輸出最優解;若未達到時,則對比當前最優路徑與至今最優路徑,若當前最優路徑小于至今最優路徑,則跳出局部最優,跳至步驟7;若不小于至今最優路徑,則取滿足式(14)的下一個最近迭代數時的信息素回溯,跳回步驟6。
重復上述步驟2~6,直至迭代次,找到并輸出最優解。
2.4 算法復雜度分析
雖然本文通過回溯信息素濃度的方式實現跳出局部最優,但并未對迭代總數進行改變。從上述算法流程的分析可以看出,本文算法總的迭代數為,假設算法在第1 代陷入局部最優,動態回溯機制會將若干代前滿足相似度標準的該代信息素賦予1代,并運行1 代,若無法跳出局部最優則繼續向前尋找滿足相似度標準的信息素,賦予第(1+1)代。以此循環,假設迭代數達到代也未能跳出局部最優,則運行總代數為(1+1+2+…+)代,其中=1+1+2+…+;若假設在運行代時實現跳出局部最優,則當前運行代數為(1+1+2+…+),隨后運行-(1+1+2+…+)代。綜上所述,算法迭代總數仍為,螞蟻的數量是,城市數為,在每次迭代時因為禁忌表的使用,每只螞蟻只能搜尋除自身初始城市外的城市,即-1 個城市,因此算法的時間復雜度為(××(-1))即(××),與傳統ACS 算法的時間復雜度相同。
3 實驗對比與結果分析
為檢驗PBACO 的算法性能,本文實驗使用Windows10 系統,MATLAB2016a 版本的仿真環境,選取國際標準TSP 數據庫的多組數據集進行仿真實驗。
3.1 節將進行公共參數、價格波動策略與動態回溯機制的參數設置。首先引用文獻[7]的公共參數,為了檢驗后續參數的性能,采用控制變量法,后續全部實驗將在統一的公共參數上進行。在設置價格波動策略參數中,以KroA100 作為數據集,將圖1 中動態揮發因子的九組不同區間參數,與全局信息素揮發因子為恒定值0.3 時的算法作對比,通過比較30 次獨立實驗中的最小誤差率、滿足誤差率在0.5%的比例和平均解,來分析揮發因子的動態調整所改善的性能;同時挑出幾組較優的區間參數,在A200 數據集上進行30 次獨立實驗,再次與恒值為0.3 時的算法作對比,通過分析對比更大規模數據集的結果,再次驗證算法的改善,并選出一組最佳參數。最后分析動態回溯機制的個體相似度判定因子對性能的影響,綜合分析后確定其取值。
3.2 節將進行算法的性能分析,分析不同改進方法的作用。在數據集eil76、KroA150 與tsp225 進行仿真實驗,分別對ACS、ACS+波動平衡策略、ACS+波動平衡策略+動態回溯機制進行20 次仿真實驗,通過對比實驗分析各改進方法的作用及優勢。
3.3 節將在多組數據集中對ACS、ACS+3opt 與PBACO 算法進行仿真實驗,證明本文算法性能更優,有效改善了蟻群算法解的質量,較好地平衡了解的多樣性與收斂速度的關系。
3.4 節將會與其他最新改進算法進行對比分析,再次驗證本文改進算法的性能。
3.1 實驗參數設置
本文在ACS的基礎上進行多次實驗,測試了多組參數對算法性能的敏感性作用,統計發現公共參數為表1 所示參數時效果更好。因此,在本文后續實驗中,在表1 公共參數不變的基礎上測試其他參數,進行敏感性分析。

表1 PBACO 的公共參數設置Table 1 Public parameter setting of PBACO
表1 中,為信息啟發因子,影響信息素在路徑構建的作用,越小,螞蟻探索非最優路徑的概率增加,解的多樣性變好,但容易使期望啟發因子作用加強而陷入局部最優;為期望啟發因子,越大,螞蟻選擇距離最短路徑的概率加大,收斂速度加快,但多樣性會降低;為局部信息素揮發率,揮發率過小時,會容易陷入局部最優,揮發率過大時,會影響最優路徑的探索;為螞蟻數量,螞蟻數量越大,得到的解越多,算法精度相應提升,但會增加時間成本,影響收斂速度;為式(1)的判別閾值,越大,算法探索信息素與距離更短的路徑概率越大,收斂速度加快,但多樣性降低;為總迭代數。

表2 節點分配組合表Table 2 Node allocation combination table
首先將圖2 中的9 組區間參數,與=0.3 在公共參數相同的基礎上進行實驗對比,在KroA100數據集上進行獨立實驗30 次,得到的運行結果如表3 所示。
以=0.3 作對比,觀察表3 可知,在KroA100 數據集上,各組參數均能找到最優解;在0.1~0.3 區間時,其滿足誤差率比例與平均解都最優,同時參數為0.1~0.5、0.1~0.9、0.3~0.7 與0.5~0.9 在平均解上都略優于0.3,前三組參數在滿足誤差率比例上與0.3 持平,雖然0.5~0.9 略低,但在后續仿真時也加入實驗,避免遺失潛在優質參數。通過表3 數據可知,價格波動策略在算法各時期對的動態調整,對算法性能具有一定改善作用。
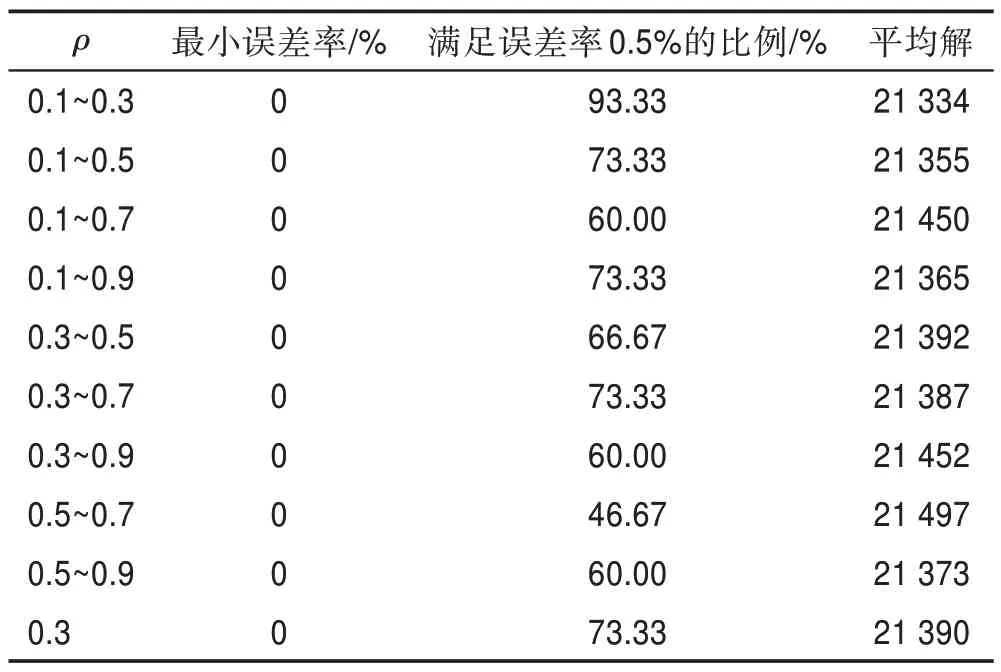
表3 不同區間ρ 在KroA100 對蟻群算法性能的影響Table 3 Effect of different interval ρ in KroA100 on performance of ant colony algorithm
為了確定最佳參數,同時驗證算法性能,將以上較優的參數在KroA200 數據集上再次進行獨立實驗30 次,得到的運行結果如表4 所示。

表4 不同區間ρ 在KroA200 對蟻群算法性能的影響Table 4 Effect of different interval ρ in KroA200 on performance of ant colony algorithm
以=0.3 作對比,觀察表4 可知,在KroA200 數據集上,參數為0.1~0.3 和0.1~0.5 在最小誤差率上最小,能找到精確解的能力優于其余參數,證明此時參數會使解的質量得到提升;在滿足誤差率比例上,參數為0.1~0.3 和0.1~0.5 均以40%比例高于其他參數,此時參數穩定性能優于其他參數;最后通過比較15組實驗最短路徑的平均解,發現參數0.1~0.5 的平均解優于參數0.1~0.3,雖然在滿足誤差率比例上兩者持平,但從平均解分析可發現參數0.1~0.5 在解的質量上會略優,因此確定波動平衡策略的參數區間為0.1~0.5,根據式(6),可計算出=577.4,=698.6。
動態回溯機制中參數設置涉及個體相似度判定因子,值越大,個體與最優螞蟻的路徑相似度越高,越難跳出局部最優,值越小,路徑差異越明顯,但此時也要花費較多的時間成本。綜合上述分析并在多組數據集上進行實驗,發現在算法陷入局部最優后,回溯至前300 代,個體相似度可降至0.95,回溯至前500 代,個體相似度可降至0.9,再往前回溯雖然個體相似度會較快下降,但其原因是已經貼近初始運行時期,類似于大災變,因此綜合考慮將值設定為0.9。
3.2 算法性能分析
為了驗證PBACO 算法各個改進策略的作用,本文將不同策略組合為三組優化方案,分別在數據集eil76、KroA150 與tsp225 進行仿真實驗,優化方案如表5 所示。每組優化方案在各數據集進行20 次獨立實驗,并統計各組方案的最優解、最優解誤差率、平均解與迭代次數,并結合收斂曲線與多樣性曲線來進行對比與分析,統計結果如表6 和圖6 所示。

表5 優化方案表Table 5 Optimization scheme table
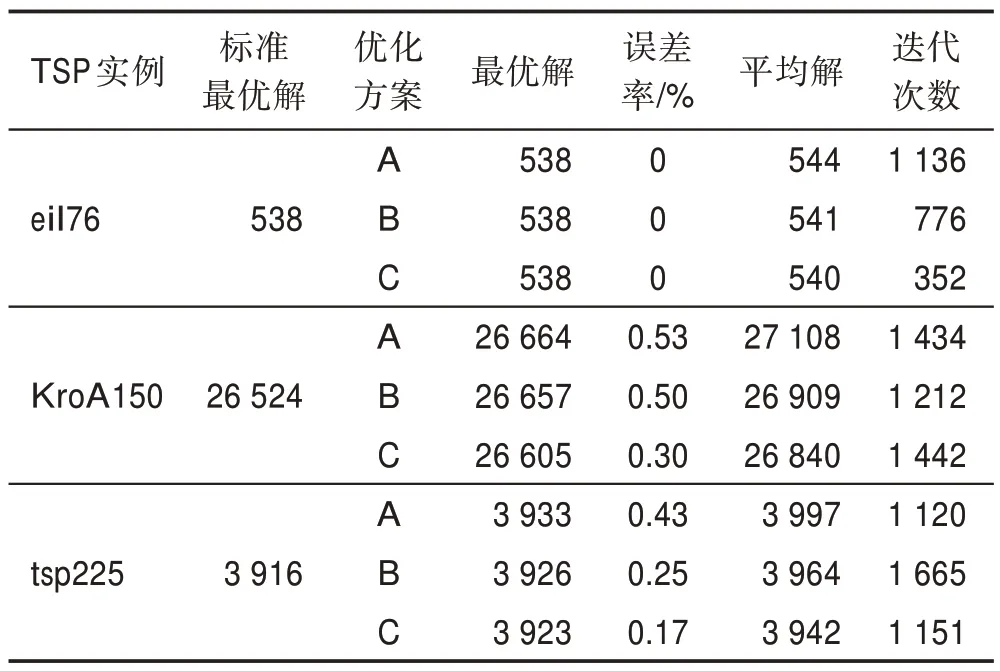
表6 優化方案性能對比表Table 6 Performance comparison table of optimization scheme
從eil76 數據集的實驗結果可以發現,A、B、C 方案都可以找到最優解,但是B、C 方案在收斂速度上明顯優于ACS 算法,并且更快速地跳出局部最優找到最優解,能夠較好地平衡算法多樣性與收斂速度,同時從平均解可以看出,改進算法的穩定性也優于ACS 算法。

圖6 各測試集收斂情況Fig.6 Convergence of each test set
從KroA150 數據集的實驗結果可以發現,在迭代前期,B 方案通過價格波動策略在短時間內就能夠找到較優解,優于A 方案,C 方案雖然因為陷入局部最優,未找到較優解,但在300 代左右仍能快速跳出,并找到優于A、B 方案的更優解。在迭代中后期陷入局部最優后,B 方案通過價格波動策略,最先使算法跳出局部最優,但解的精度不高;在此基礎上改進的C 方案通過動態回溯機制,進一步跳出局部最優,使算法整體解的精度得到較好的改善。
從tsp225 數據集的實驗結果可以發現,B、C 方案在前期收斂速度與探索較優解的能力明顯優于A 方案,在中后期的收斂曲線中,C 方案借助動態回溯策略,在更高精度的解中多次跳出局部最優,找到更優解,同時結合表6 中的最優解與平均解可以發現,C方案在解的精度上得到了有效提升,并且相比A、B方案,解的穩定性也得到了明顯改善。
3.3 與傳統蟻群算法對比分析
為了分析PBACO 算法在不同規模數據集的性能,將ACS、ACS+3opt、PBACO 算法應用于不同城市規模的TSP 實例中,其中ACS 與ACS+3opt 為傳統判定局部最優方式,PBACO 算法中的動態回溯機制為斐波那契數列抽樣方式判定是否陷入局部最優,結果如表7、圖7 和圖8 所示。
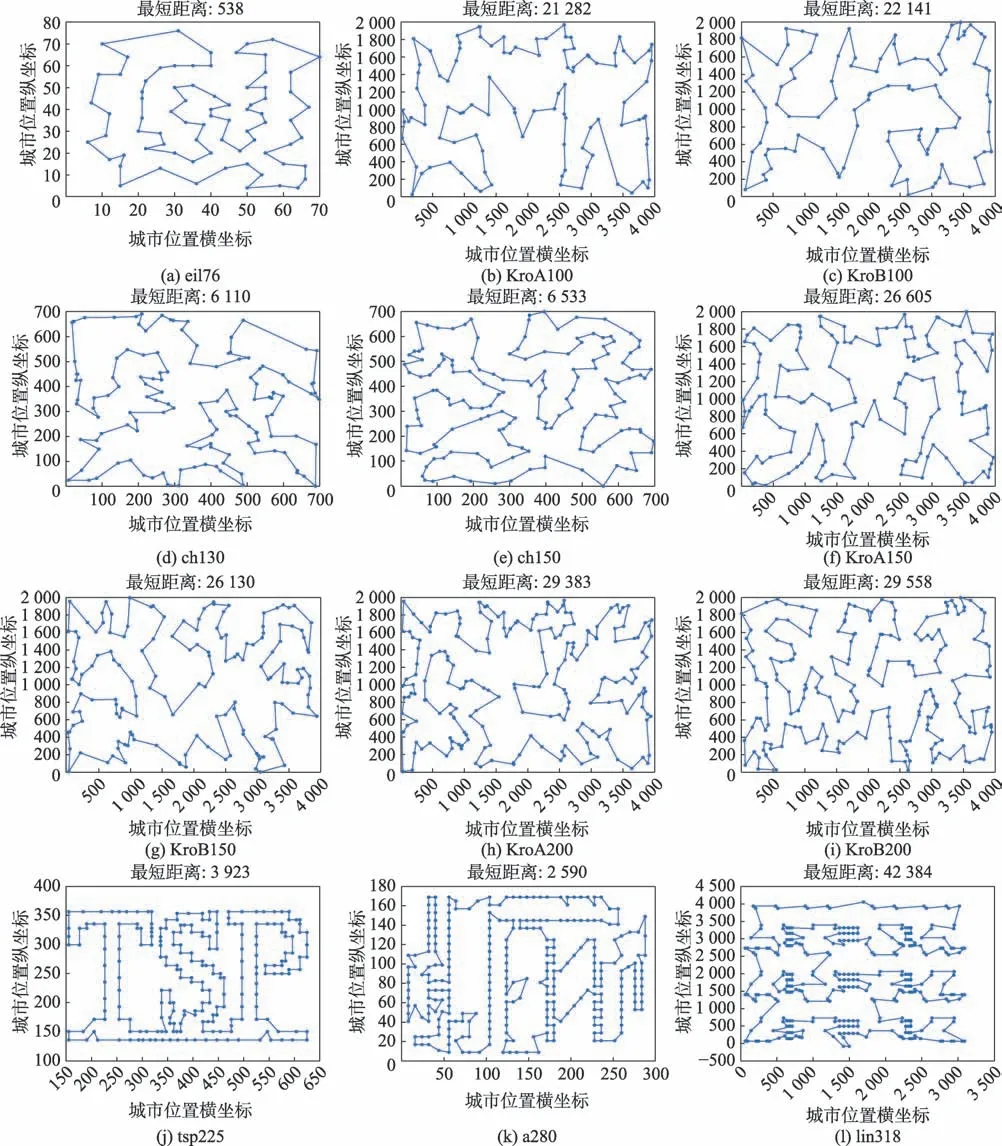
圖7 PBACO 算法在部分城市集最短路徑Fig.7 Optimal path of PBACO algorithm for part of city sets
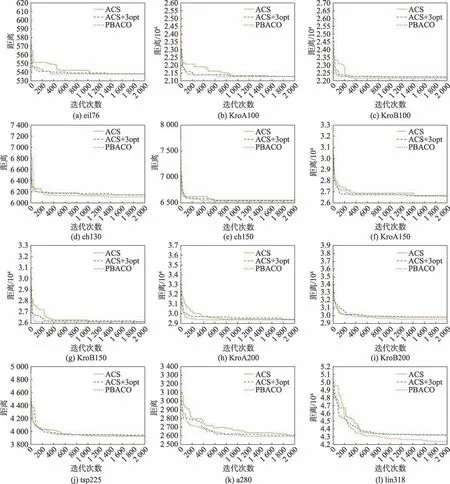
圖8 部分城市集收斂情況Fig.8 Convergence for part of city sets
圖7 和圖8 按順序分別展示了改進算法在eil76、KroA100、KroB100、ch130、ch150、KroA150、KroB150、KroA200、KroB200、tsp225、a280 和lin318 城市集中的最短路徑和收斂情況。從表7、圖7 和圖8 可以看出,在小規模城市集中,三種算法均能找到最優解,但ACS 與ACS+3opt 的收斂速度明顯慢于PBACO 算法,改進算法在前期通過價格波動策略對算法進行改善,能夠較快收斂且找到精度較高的解。城市數在100 至200 之間的中規模城市集中,傳統算法無法找到ch130 的最優解,而改進算法能通過中后期的動態回溯機制跳出局部最優,找到最優解;對于ch150、KroA150 與KroB150,PBACO 算法相比傳統算法均能有效地提高解的精度,并且在KroB150 城市集能精確找到最優解,同時找到最優解的迭代數明顯縮減。在城市數大于200 的城市集中,從表7 中可以發現,PBACO 算法在解的精度上得到了較大的改善,并且找到最優解的迭代數也有部分減少,其中KroA200找到貼近最優解的較優解,KroA200 與a280 在改善解的精度的同時將收斂速度提升,雖然在tsp225 城市集中PBACO 迭代數較大,但在動態回溯機制的作用下,多次跳出局部最優,找到更優解。在大規模城市集lin318 中,雖然在迭代前期PBACO 算法陷入短暫的局部最優,但在200 代之后算法解的精度明顯提高,在550 代相比傳統算法已經找到更優解,并在之后陷入局部最優后,通過動態回溯機制多次跳出局部最優,將解的質量明顯改善。
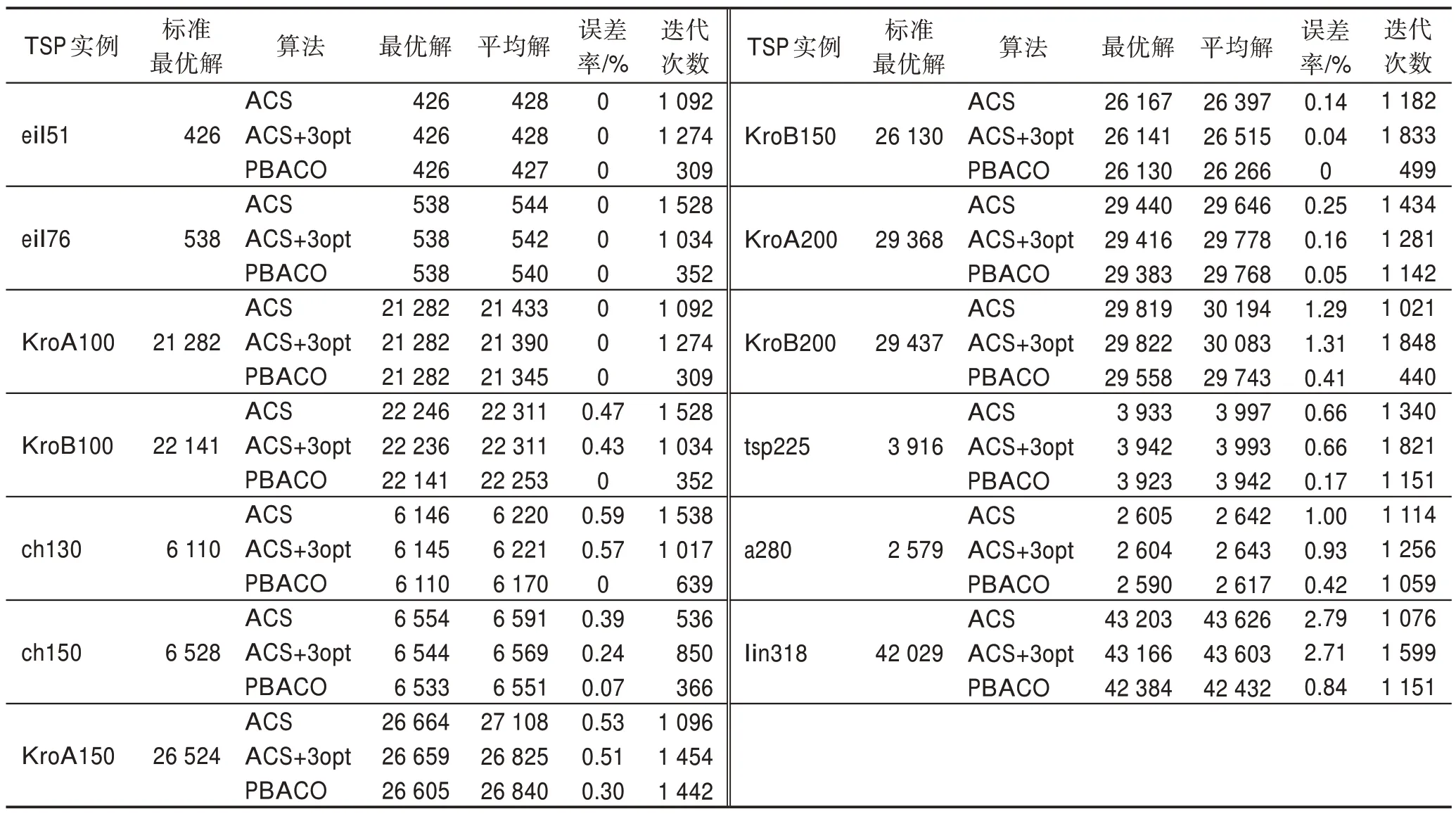
表7 不同規模城市數據集的性能對比Table 7 Performance comparison of urban datasets of different sizes
3.4 與至今最新改進算法對比分析
為了進一步驗證PBACO 算法性能,本文選用至今最新改進的融合貓群算法的動態分組蟻群算法(CACS)、考慮動態導向與鄰域交互的雙蟻型算法(TREEACS)和文獻[11]進行比對,如表8 所示。由表8 可以看出,PBACO 算法在小規模城市中與其他算法都能找到最優解,但在中規模城市與大規模城市中,PBACO 算法解的精度相比其他算法得到了較好的改善。
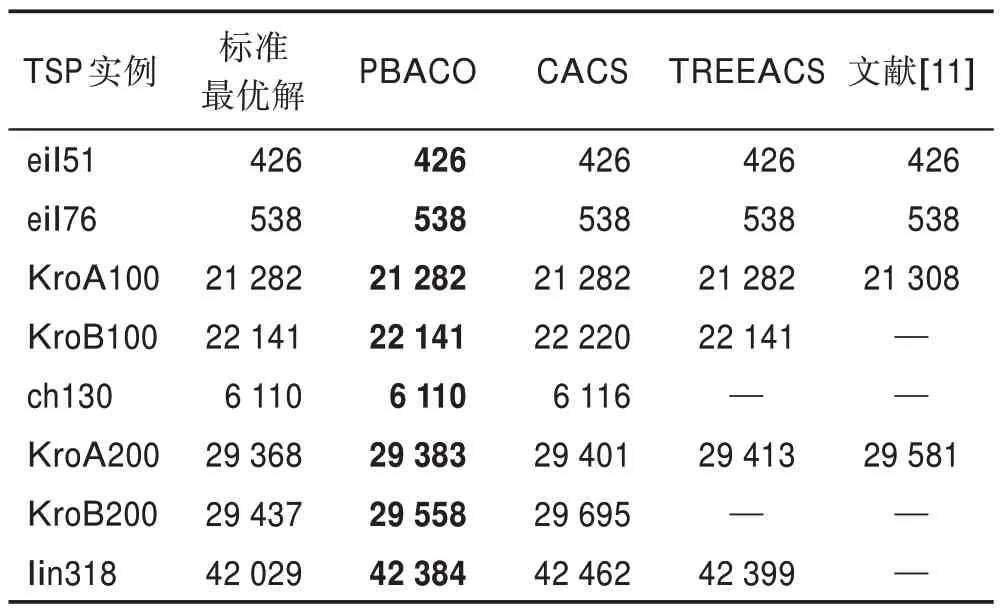
表8 PBACO 與其他最新改進算法比較Table 8 Comparison of PBACO with other newly improved algorithms
通過實驗分析與結果對比可知,本文改進后的PBACO 算法與傳統蟻群算法ACS、ACS+3opt和至今最新改進的蟻群算法相比,解的精度與收斂性都有明顯的改善。
4 結束語
針對傳統蟻群算法存在易陷入局部最優、收斂速度較慢等問題,本文提出一種結合價格波動策略與動態回溯機制的蟻群優化算法(PBACO)。通過價格波動策略,以時間序列分析的思想將算法不同需求的時期進行分類,以價格波動平衡的供求思想對信息素揮發因子進行自適應動態供給,在保證收斂速度的同時增大跳出局部最優的能力,能夠有效地改善解的質量。在算法陷入局部最優后,引入動態回溯機制,以迭代最優螞蟻的個體相似度作為標準,將路徑信息素回溯至相似度差異顯著的時期,在保證收斂速度的同時能夠有效地跳出局部最優,明顯改善解的精度,并且保證解的穩定性。雖然在實驗對比中相較其他算法解的質量得到較好的改善,但在超大規模城市集中算法解的精度還需要進一步提升,因此下一步將進行多種群合作競爭的算法研究,以提高算法在超大規模城市集中的求解能力。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
