基于知識圖譜的雙端鄰居信息融合推薦算法
2022-06-18 02:09:16王寶亮潘文采
計算機與生活 2022年6期
王寶亮,潘文采
1.天津大學 信息與網絡中心,天津 300072
2.天津大學 電氣自動化與信息工程學院,天津 300072
當今社會,隨著網絡的興起,用戶的選擇信息越來越多,為了解決用戶的個性化推薦問題,推薦系統應運而生。其中,協同過濾算法通過分析相似用戶的行為進行推薦,取得了較大的成功。然而,傳統的協同過濾算法存在冷啟動和用戶交互信息稀疏的問題,因此研究者通過加入輔助信息例如社交網絡、物品的屬性信息等來緩解該問題。由于知識圖譜包含豐富的物品信息,也被應用于推薦算法中。

將知識圖譜應用于推薦算法已成為一個熱點,例如文獻[7]將知識圖譜應用于新聞推薦系統,將上下文嵌入、知識圖譜實體嵌入和語句嵌入送入CNN網絡,從而在語義層次和知識圖譜層次學習嵌入表示。文獻[8-9]將知識圖譜網絡中與用戶交互的物品的鄰居信息聚合到用戶上,生成信息豐富的嵌入表示。文獻[10-11]將物品的鄰居信息聚合到物品上生成物品嵌入表示。
受上述算法啟發,本文提出基于知識圖譜的用戶物品鄰居信息融合推薦算法,即將用戶鄰居和物品鄰居信息分別融合,從而產生用戶和物品信息均豐富的嵌入表示。在聚合用戶信息時,首先根據用戶的點擊記錄得到與用戶交互的物品,如圖1 所示的左邊菱形節點。然后根據物品在知識圖譜網絡的位置得到一階鄰居。同理,向外傳播,得到高階鄰居。然后利用節點和節點之間的關系豐富用戶的向量表示。在聚合物品信息時,由于物品通常是知識圖譜的某個實體節點,如圖1 所示右邊的菱形節點,直接得到物品的一階和高階鄰居,根據KGCN(knowledge graph convolutional networks)模型(一種利用圖卷機神經網絡和知識圖譜的推薦模型)聚合信息生成豐富的物品嵌入表示。最后將得到的用戶和物品的向量嵌入表示送入預測環節,得到用戶和物品的交互概率。在公開的兩個數據集上進行對比實驗,驗證了本文算法的有效性。
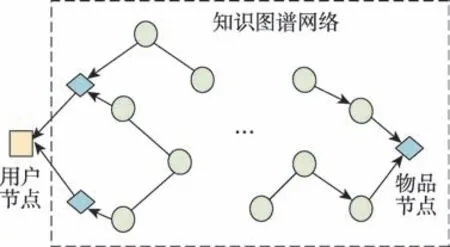
圖1 總體框架Fig.1 Overall framework
1 本文算法
1.1 總體框架
本文的總體思路如圖1 所示,其中,正方形節點表示用戶節點,圓形和菱形節點表示知識圖譜中的實體節點,左邊的菱形節點表示與用戶有交互關系的物品節點。
1.2 用戶節點鄰居信息融合
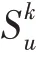
給定用戶物品交互矩陣和知識圖譜用戶的跳實體集合定義如下:
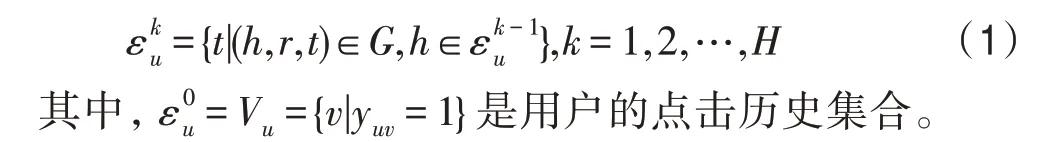
用戶的跳的鄰居集合如下:
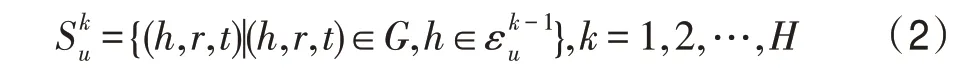
隨著跳數的增加,鄰居集合的數量會變得十分龐大,因而不會選得很大,當很大時,帶來的噪音會比有效信息更多。同時,為了降低集合的數量,每一跳采樣固定數量大小的鄰居。
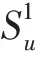

其中,R∈R,h∈R,分別表示關系R和實體head h的嵌入表示,考慮到用戶的點擊歷史是用戶的直接興趣表達,因而將加入權重表達式。
p可以表示在R空間下用戶對于h和關系R的喜好程度,也可以表征每個鄰居節點和用戶的點擊歷史物品的相似度。
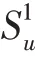

其中,t∈R,是tail t的嵌入向量的表示。
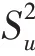
最終的用戶的向量表示為:

然而,對于[],隨著的增長,離用戶的交互歷史越來越遠,包含的噪音信息會更多,因此不同的路徑對模型的影響是不同的,式(5)無法解決該問題,選擇文獻[12]提出的累加操作,如式(6)所示。
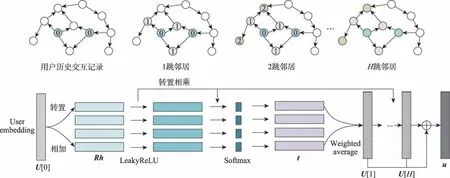
圖2 用戶節點信息融合Fig.2 User node information aggregation

其中,是參數,用來控制每一跳輸出的權重。該操作能夠區分不同跳輸出的重要性,其偏導如式(7)所示。
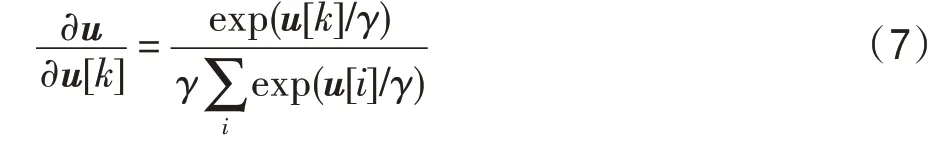
通過控制的大小可以調整每一跳輸出的比重。
1.3 物品節點鄰居信息聚合
物品鄰居節點的聚合采用KGCN模型,其基本框架如圖3 所示。
圖3 KGCN 模型Fig.3 KGCN model
KGCN 模型在知識圖譜中聚合實體特征,從而發掘物品的潛在關聯。涉及的概念如下:

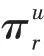

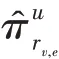

()的規模很大,選擇隨機采樣固定數量鄰居的方式降低計算復雜度。

其中,表示采樣的數目。
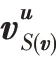
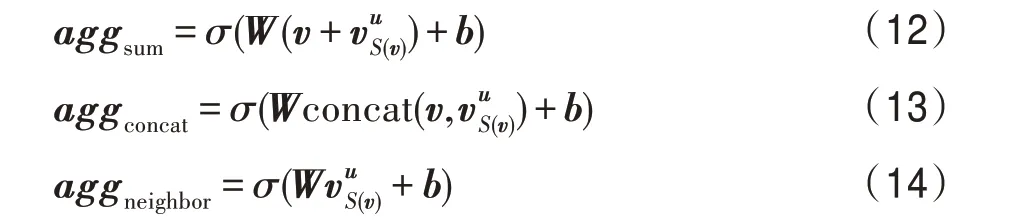
根據文獻[10]實驗結果,式(12)的聚合效果在三種聚合方式最好,本文根據文獻[13]提出的聚合方式,如式(15)所示。
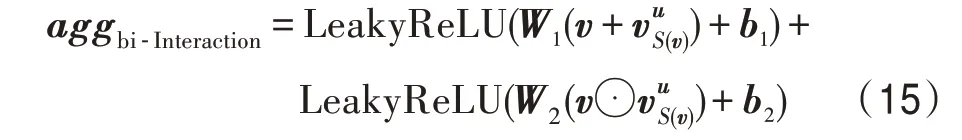
其中,⊙表示element-wise 操作。
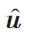

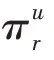

根據式(9)~(11)、(15)~(17),如圖3 所示,不斷從外向內聚合,將節點的信息聚合到物品節點。最終形成物品節點的向量表示v。
1.4 預測部分
通過1.2 和1.3 節,得到了用戶和物品的最終向量表示和v,其中用戶向量包含了用戶的歷史記錄信息和其在知識圖譜中的鄰居信息。物品向量v包含了物品本身和其在知識圖譜的鄰居信息以及用戶對鄰居信息的喜好程度。預測函數如式(18)所示。

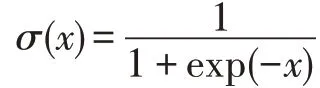
為了比較對向量的不同操作對最終結果的影響,預測函數公式可替換為式(19)。

其中,∈R。
損失函數如式(20)所示。
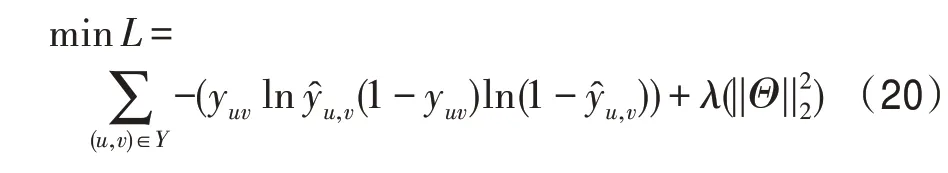
1.5 算法流程
雙端鄰居信息融合

2 實驗部分
2.1 數據集
本文采用的數據集是Book-Crossing(http://www2.informatik.uni-freiburg.de/~cziegler/BX/)和Last.FM(https://grouplens.org/datasets/hetrec-2011/)。其中Book-Crossing數據集來自Book-Crossing 市場,包含100 萬個書籍評分信息。Last.FM 數據集來自Last.FM 在線音樂系統,包含2 000 個用戶的評分信息。對應于數據集的知識圖譜數據從KGCN公開的預處理知識圖譜獲得(https://github.com/hwwang55/KGCN),該知識圖譜信息來自Microsoft Satori。兩個數據集經過預處理后的統計數據如表1 所示。
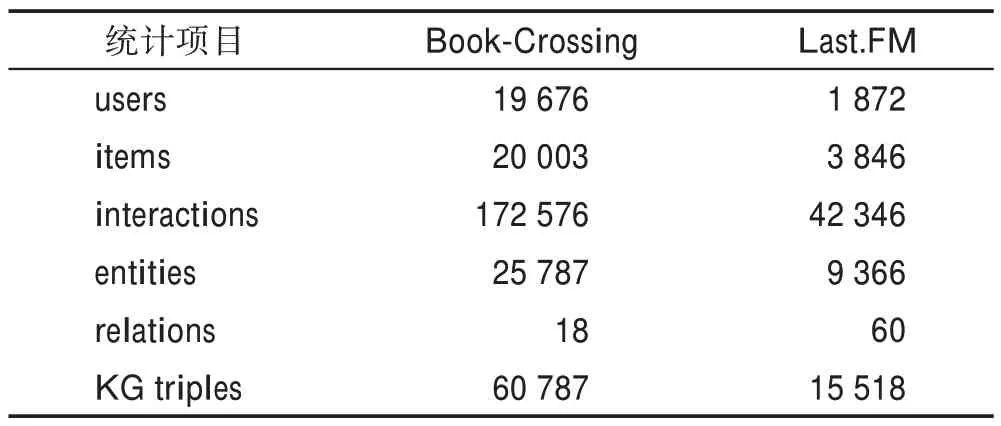
表1 兩個數據集的統計數據Table 1 Statistics for two datasets
2.2 實驗設置和參數
本文算法將與經典的推薦算法LibFM、Wide&Deep和基于知識圖譜的推薦算法RippleNet、KGCN、KGNN-LS進行比較。通過評價指標ACC(accuracy)和AUC(area under curve)來比較各個算法的性能,它們反映了算法在CTR(click-through rate)預測時的性能。
本實驗在Windows10 環境下使用python-3.6.5 進行開發,使用的第三方庫及版本:tensorFlow-1.12.0、numpy-1.15.4、sklearn-0.20.0。對于每個數據集,按照6∶2∶2 的比例隨機構成訓練集、驗證集和測試集。其他相關的參數如表2 所示。
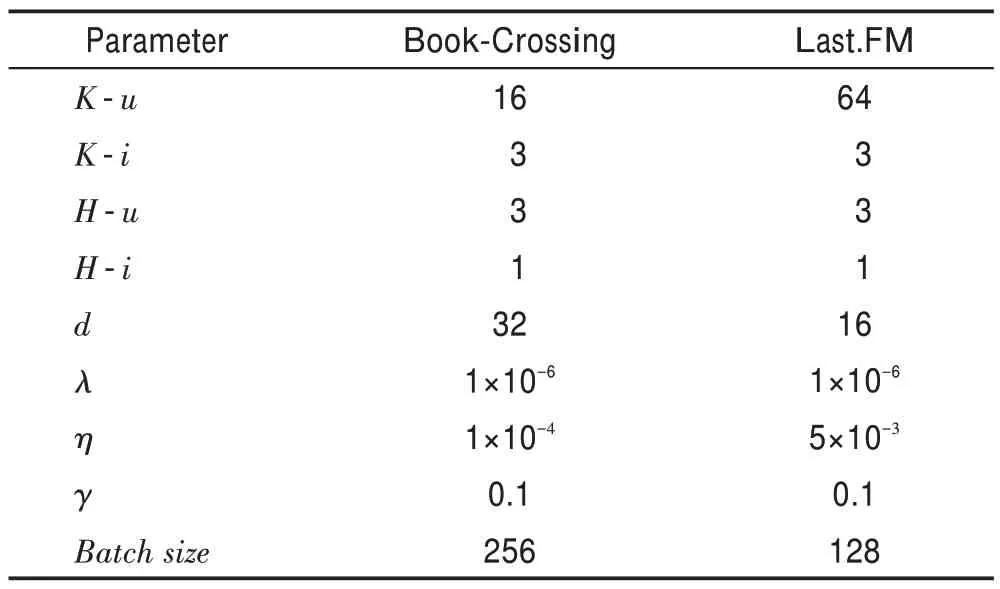
表2 參數的設置Table 2 Parameter setting
表2 中,-表示用戶端,-表示物品端。表示鄰居采樣數量,表示跳數,表示嵌入向量的維度,表示正則化參數,表示訓練速率,表示式(6)中的參數,調整每一跳的比重。
KGCN(https://github.com/hwwang55/KGCN)、KGNN-LS(https://github.com/hwwang55/KGNN-LS)的參數設置按照文獻[10-11]的設定進行設置。對于RippleNet(https://github.com/hwwang55/RippleNet),其在Last.FM數據集上的設置為=16,=3,=10,=0.02,=0.005;在Book-Crossing 數據集的設置為=4,=3,=10,=0.01,=0.001。
2.3 對比實驗結果
各個模型的CTR 預測結果如表3 所示。
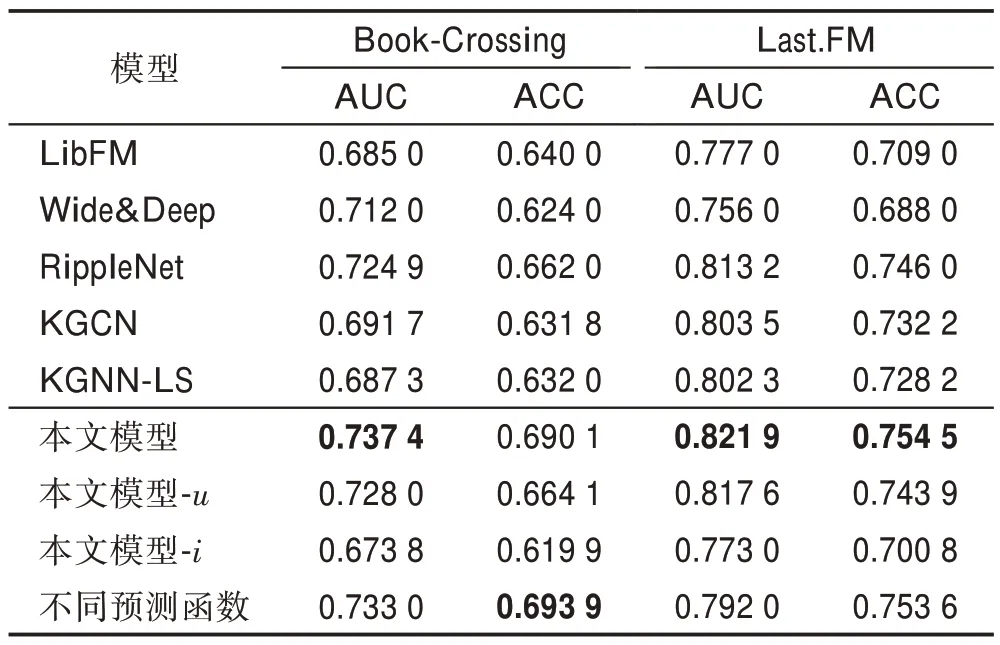
表3 CTR 預測中AUC 和ACC 的結果Table 3 Results of AUC and ACC in CTR prediction
從表3 的結果可以看出,相較于經典的推薦算法LibFM、Wide&Deep 以及在知識圖譜中僅聚合用戶鄰居信息的RippleNet算法和僅聚合物品鄰居的KGCN、KGNN-LS 算法,本文算法在兩個數據集的性能都有所提升。在Book-Crossing 數據集上,相較于最優基線,AUC和ACC提升1.72%和4.24%;在Last.FM 數據集上,AUC和ACC提升1.07%和1.14%。其中模型-表示本文算法僅聚合用戶鄰居信息的結果,模型-表示本文算法僅聚合物品鄰居信息的結果。通過對比可以看出聚合兩者的鄰居信息能夠提升算法的有效性。同時可以發現,模型-的算法性能下降較為明顯,主要原因是本文的物品鄰居采樣數太少且向外聚合的深度也僅為1 跳,因此得到的信息非常少,從而導致性能效果下降更多,這也從側面說明鄰居信息對算法的性能有較大的影響。
表3 最后一行表示用式(19)作為預測函數的結果。可以看出,式(19)引入額外的無關參數會導致大部分結果變差,因此需要恰當選擇合適的預測函數,才能提升模型性能。
2.4 參數敏感性分析
在聚合用戶鄰居信息時,得到每一跳的結果后,通過值來調整每一跳累和時的比重,當值趨于0時,會選擇最重要的一跳信息作為最終用戶向量表示,當值趨于無窮時,累和方式類似于對多跳輸出取平均值作為最終用戶向量表示。由表4 結果可以看出,對于Book-Crossing 數據集和Last.FM 數據集,值取小值時,效果要好于大值。這是由于取小值時,會更傾向于取重要一跳的信息作為最終用戶向量表示。表4 中最后一行表示直接累加所有跳的輸出的結果,可以看出,利用值調整能夠提升算法的有效性。
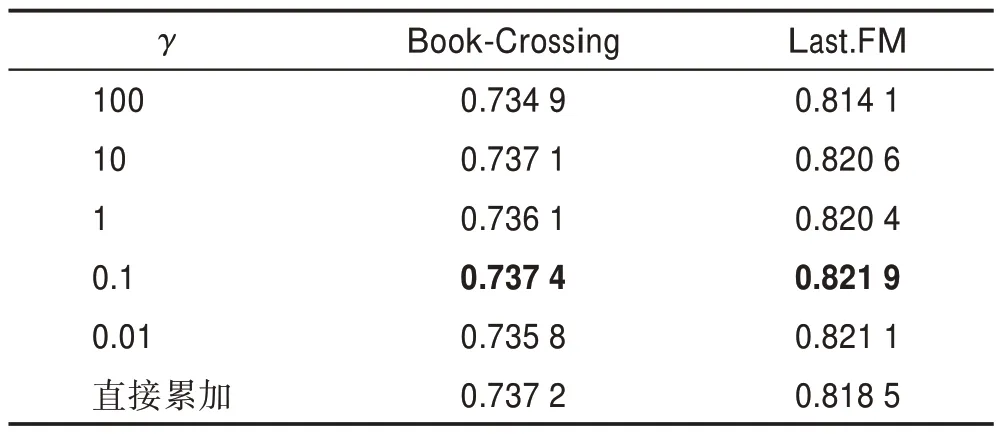
表4 參數γ 對AUC 值的影響Table 4 Influence of parameter γ on AUC value
表5 和表6 表示采樣鄰居數目對算法的影響。可以看出,當值取過低和過高時,模型的性能都會受到影響。過高時,會帶來更多的噪音,過低時無法聚合更多有效的信息。
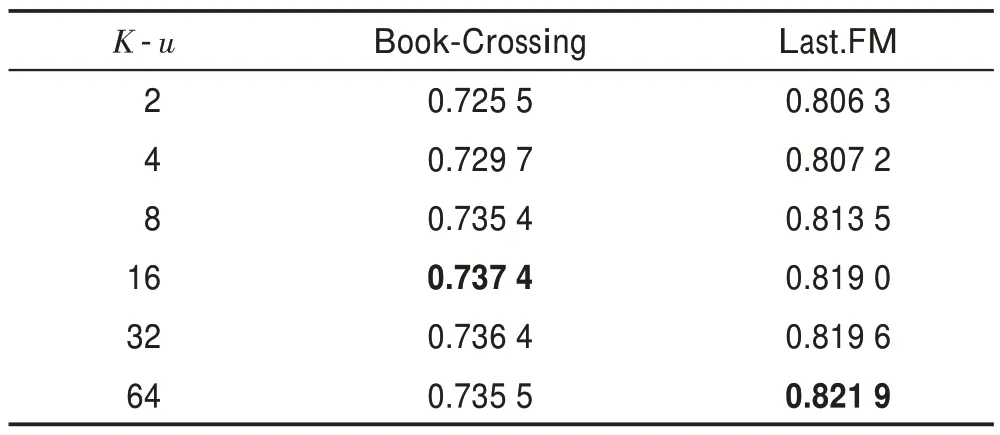
表5 用戶端每跳采樣值K-u 對AUC 值的影響Table 5 Impact of K-u sampled value per hop on AUC value at user end
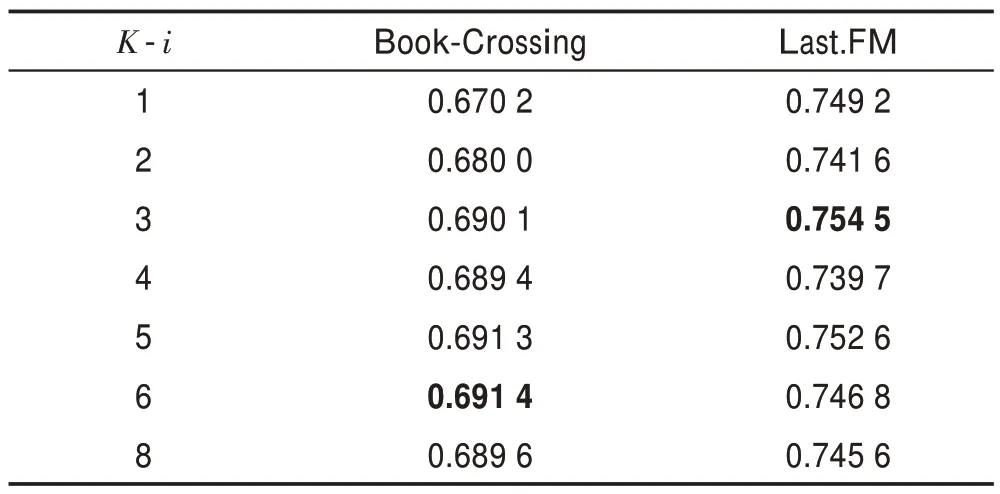
表6 物品端每跳采樣值K-i 對ACC 值的影響Table 6 Impact of K-i sampled value per hop on ACC value at item end
表7和表8 表示聚合深度對算法的影響。可以看出本文算法對聚合深度的敏感性更強,特別是對于的性能急劇惡化,說明當跳數增加時,會引入更多的不必要信息,這也符合現實情況。知識圖譜中的1 跳鄰居信息是對實體的更為直接的描述,有很強的相關性,當跳數增加時,其有效的描述信息會少很多。
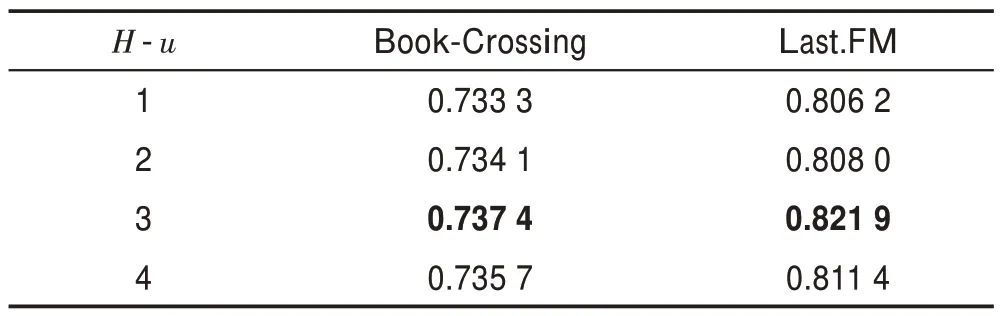
表7 用戶端聚合跳數H-u 對AUC 值的影響Table 7 Impact of user end aggregation hops H-u on AUC value
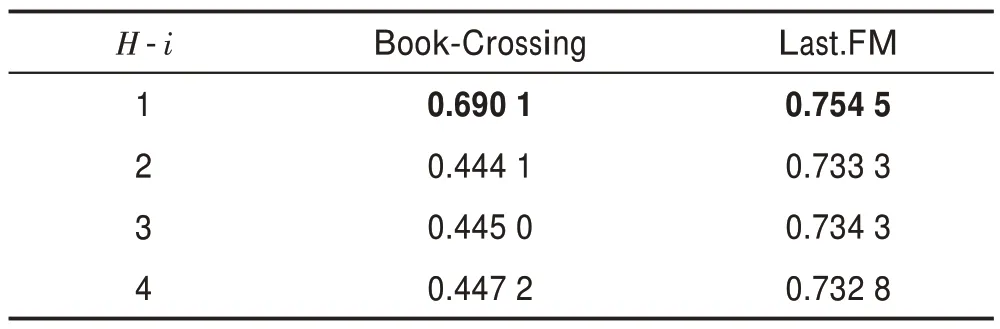
表8 物品端聚合跳數H-i 對ACC 值的影響Table 8 Impact of item end aggregation hops H-i on ACC value
表9 表示向量維度對算法性能的影響。合適的向量維度能夠編碼有效的信息而不會引入更多的噪音,也能緩解算法的過擬合現象,同時也會減小算法的訓練時間。
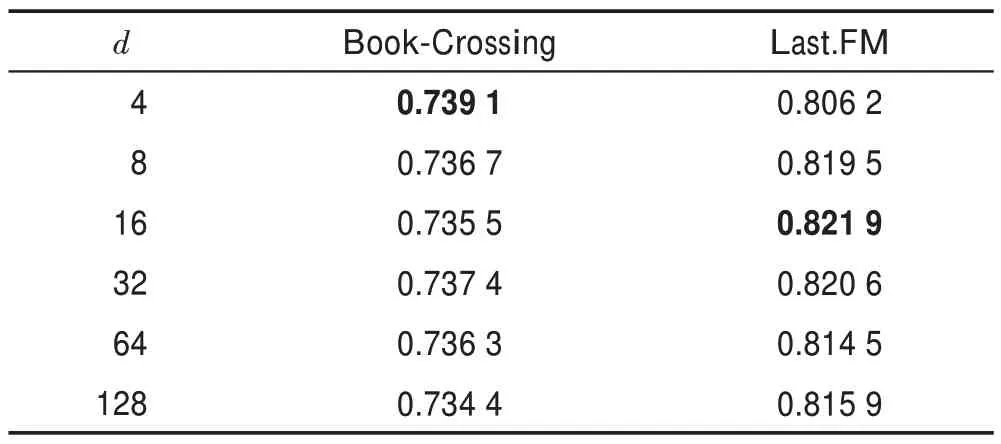
表9 向量維度值d 對AUC 值的影響Table 9 Influence of vector dimension value d on AUC value
3 結束語
針對推薦系統存在的冷啟動問題,本文提出了一種基于知識圖譜的融合用戶鄰居信息和物品鄰居信息的推薦算法。該算法將知識圖譜作為輔助信息,算法首先聚合用戶的鄰居信息,生成有個性化信息的用戶向量,然后將用戶向量送入KGCN 模型聚合物品的鄰居信息,生成有個性化的物品向量。最后將向量送入預測階段。在數據集Book-Crossing 和Last.FM 上的實驗結果證明了本文算法的有效性,提高了推薦結果的準確性,同時增加了推薦算法的可解釋性。下一步將針對知識圖譜中存在的不相關實體問題做進一步探究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
