基于佐證圖神經網絡的多跳問題生成
2022-06-21 07:47:26龐澤雄
中文信息學報 2022年5期
龐澤雄, 張 奇
(復旦大學 計算機科學技術學院,上海 200443)
0 引言
問題生成任務(Question Generation,QG)旨在對給定的一段文本生成一個合理的問題,這在自然語言理解領域中是非常具有挑戰性的一個課題。問題生成有很多潛在的應用場景,例如,在問答系統中利用QG模型提供標注數據[1],應用QG輔助教育領域中的測試和評估[2],在智能聊天機器人中實現持續對話[3]。
之前大多數問題生成相關研究關注于只需要初步推理的簡單問題生成,例如,Du等[4]在SQuAD[5]數據集上使用一個含有答案的句子作為模型的輸入就可以生成相對自然的問句。在現實應用中,多跳問題生成這一任務無疑更具挑戰性,模型需要在理解多段文本的語義的情況下,根據多個不同的信息點進行多步推理才能生成足夠復雜的高質量問題。
最近的一些研究已經在嘗試去解決多跳問題生成所面臨的一些挑戰。Pan等[6]構建了一個語義級別的圖網絡去建模文檔的表示,然后把圖表示向量融入到多步的推理過程中;Xie等[7]直接利用QG的評價指標,通過強化學習方法去提升模型效果。然而文檔中信息的重要性是不同的,只有小部分句子中包含有關鍵的信息點。以圖1的樣本為例,文檔1和文檔2中只有前兩個句子之間含有與答案相關的關鍵信息(Apple Remote,Front Row)。在給定答案“keyboard function keys”時,模型需要準確地捕捉到“The device was originally designed to interact with the Front Row”這一信息點。因此,選擇語義層次優先的句子,忽略無效的信息點,可以幫助構造一個更魯棒的問題生成系統,本文把這一類提供支持事實信息的句子統稱為佐證句(Evidence)。這種思想也十分類似于人類提問的過程,先提取出需要的知識點(what to ask),根據知識點構造自然問句(how to ask)。
本文提出了一個新的方法,基于佐證句選擇的圖神經網絡(Graph-based Evidence Selection network,GES),它將多跳問題生成劃分為兩個子任務: 佐證句選擇和問題生成,并把兩個子任務統一到序列到序列(Seq2seq)的框架中來。我們首先使用基于自注意力機制的編碼器得到不同文檔的詞嵌入表示,進一步得到各個句子的向量表示。然后我們引入圖注意力網絡(Graph Attention Network,GAT),融合不同句子間的信息,通過圖神經網絡的多步迭代來顯式建模語義理解中的多步推理過程,基于句子層級的模型結構也體現了文檔中的層次結構信息。判斷句子是否為佐證句的二值信號會作為偏置信息輸入到解碼器中輔助問題的生成。因為佐證句預測是一個離散的任務,會阻礙梯度的回傳,所以本文使用了直通估計量(straight-through estimator, STE)來處理反向傳播,使得Seq2seq模型可以端到端地訓練。
本文在HotpotQA數據集[8]上進行了充分的實驗,在BLEU等文本生成通用的自動指標上取得了顯著提升。佐證句預測的定量分析也表明GES模型可以準確地選出語義信息相對重要的句子,進而提升生成問題的質量。同時這也增強了多跳問題生成模型的可解釋性,為后續該領域的進一步研究提供了相應的理論基礎。
1 相關工作
隨著深度學習和神經網絡模型的發展,問題生成技術從基于規則的方法逐步過渡到基于序列到序列的神經網絡方法,之后的大多數工作都是在此基礎上的延伸。Zhou等[9]在編碼中加入了命名實體,詞性等語言學特征;Song等[10]在解碼器中引入拷貝機制(copy mechanism)來解決稀有詞問題(Out of vocabulary, OOV)。Tuan等[11]提出了多階段注意力機制來建模文檔中句子級別的信息交互。
近年來圖神經網絡也被應用于各種自然語言處理任務中,取得了很好的效果。Chen等[12]在編碼—解碼結構中引入了基于強化學習的圖網絡; Li等[13]在多文檔摘要生成中引入了多種圖表示學習來提升生成摘要的質量;Wang等[14]在抽取式摘要生成中引入了異質圖神經網絡來建模不同粒度的文本表示;Qiu等[15]在多跳問答中引入了一個動態融合圖神經網絡來提升模型效果。
與本文工作類似,Pan等[6]、Su等[16]也通過引入圖神經網絡的方法來輔助多跳問題生成。之前的工作大多是構建基于實體關系或者不同語義粒度的圖模型來顯式學習多段文本間的關系。而本文提出的方法是在此基礎上利用圖神經網絡來輔助佐證句的選擇,從而提升多跳問題生成的效果。
2 主要方法
2.1 問題定義
本節會對多跳問題生成給出一個準確的定義。給定不同文檔組成的原文C=(c11,c12,…,cmn),其中,cmn代表文本中第m個句子的第n個單詞,問題對應的答案A=(a1,a2,…,ak),問題生成任務的目標是生成一個連貫且符合邏輯的問句Q=(q1,q2,…,qt)。圖2顯示的是本文方法的結構圖。
2.2 序列編碼器
之前的問題生成模型大都使用了循環神經網絡(RNN)作為Seq2seq框架的基礎模型,而近年來基于自注意力機制的Transformer[17]已經在機器翻譯或摘要生成等領域中廣泛應用,并且取得了比RNN模型更好的效果。此外,在與問題生成互補的機器問答領域,基于Transformer的預訓練語言模型展現出了與人類媲美的自然語言理解能力。因此本文引入BERT[18]作為Seq2seq框架的編碼器。
在多跳問題生成中,模型需要處理多個句子的輸入,為了標識每個對立的句子,在每個句子的開頭我們加入了[SENT]標簽,編碼器最終輸出的[SENT]向量就是對應句子的特征表示。受UniLM[19]的啟發,我們將答案和原文拼接到一起輸入到編碼器中,通過分隔符[SEP]來區分不同的文本。序列編碼器的隱層向量可以表示如式(1)所示。
E,H=Transformer(C,A)
(1)
其中,E=(e1,e2,…em,ea)代表各個句子和答案的隱向量表示,ei是Transformer最頂層第i個[SENT]標簽的輸出結果。
2.3 佐證句選擇網絡
佐證句任務旨在判斷這個句子是否可以為問題生成提供支持事實,然后賦予對應的0或1二值符號。我們認為候選的佐證句含有與答案和原文最相關且最重要的信息。為了從冗長的文本中對信息點進行查找和推理,本文構建了一個句子級別的全連接圖神經網絡。
2.3.1 佐證圖神經網絡
一般地,給定編碼器輸出的句子隱向量表示作為圖網絡表示的初始值u0,佐證圖神經網絡由K層圖注意力神經網絡[20]組成,uk表示第k層圖網絡的隱層表示。首先我們通過一個多層感知機的結構來計算每個節點與相鄰節點間的注意力權重,如式(2)所示。
(2)
其中,Wa,Wq,Wk都是可以學習的參數,“||”表示連接操作,與注意力機制相同,最后使用softmax函數來歸一化權重,如式(3)所示。
(3)
然后我們通過注意力權重和相鄰節點表示的線性運算得到對應節點在第k層的特征表示,如式(4)所示。
(4)
為了避免多步迭代后出現梯度消失的情況,在每一層圖網絡后我們加入了一個殘差單元,因此第k層圖網絡的最終輸出可以表示如式(5)所示。
(5)
2.3.2 佐證句預測
在堆疊多層圖網絡后,我們通過圖模型的最終輸出來判斷這個句子是否為問題生成提供了支持事實,如式(6)、式(7)所示。
MLP是一個多層感知機,σ表示sigmoid非線性激活函數,gi是第i個句子被選為佐證句的概率,zi是一個二值控制門,決定句子是否被選為佐證句。
連同序列編碼器輸出的詞表示,我們將佐證句的位置信息反饋給模型,用于輔助問題生成。因為zi是一個二元標量,我們使用一個詞嵌入矩陣D∈R2×d得到一個和隱狀態H同維度的詞嵌入表示si。最后我們將si和對應句子的詞表示相加得到最后的隱狀態表示,如式(8)所示。
fij=LayerNorm(hij+si)
(8)
其中,hij代表第i個句子中第j個單詞的隱狀態,整個隱狀態表示矩陣定義為F。
2.4 訓練策略
模型通過最小化參數的負對數似然來訓練,如式(9)所示。
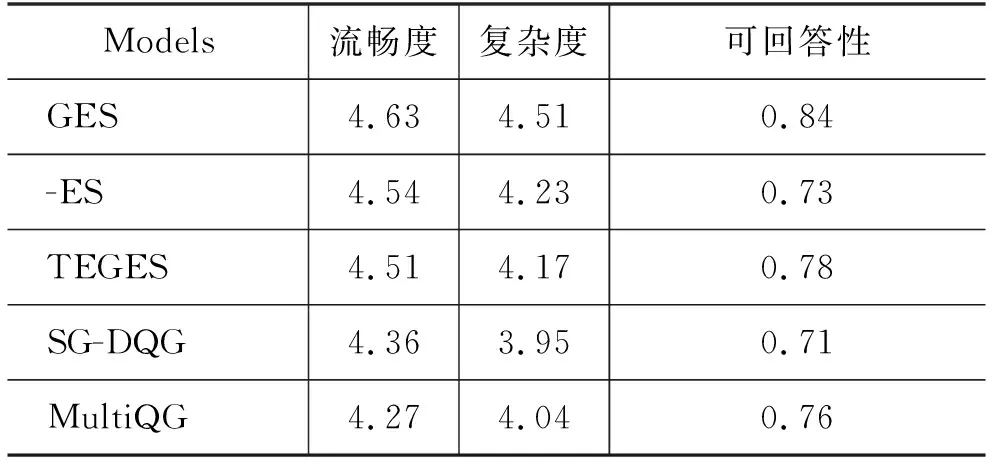
LMLE=-∑logP(qt|q (9) 2.4.1 參數共享 Seq2seq框架中的編碼器是預訓練語言模型,解碼器是淺層Transformer,因此為了緩解訓練不同步的問題,我們使用了參數共享的方法來初始化模型的詞嵌入層。解碼器中的詞嵌入層和位置嵌入層都會與訓練模型中保持一致。而解碼器輸入端標識佐證句位置信息的二元詞嵌入矩陣也通過拷貝BERT中的segment embedding的參數來初始化。 2.4.2 直通估計量 在佐證句預測中,模型會得到一個二值信號,這是一個不連續的過程,導致訓練時的梯度回傳受阻。一種常見的解決方法是強化學習,通過從語言模型中采樣一個動作,系統會利用獎勵函數計算出一個得分,以此來指導模型訓練。但是策略梯度方法會導致訓練過程中的高方差問題[21],導致模型訓練非常困難。參考之前訓練不連續神經網絡的工作[22],本文使用直通估計量去估計二值預測的梯度,對于編碼器一個特定的參數θ,估計梯度計算如式(10)所示。 (10) 如圖3所示,在正向傳播時,模型通過離散化計算得到一個不連續的獨熱向量z。而在反向傳導時,則通過一個連續而平穩的函數來估計z的梯度,所以梯度仍然可以正常回傳。盡管這是一個有偏的估計,但直通估計量依然是一個高效的計算方法。 圖3 直通估計量傳播和回傳過程 2.4.3 佐證句預測的監督學習 本文提出的方法以多篇文檔和答案文本作為輸入,預測佐證句并生成自然問句。在多跳問題生成任務中,數據集中有標注好的佐證句標簽,我們通過這個監督信號來加速模型的訓練。具體來說,對于輸入中的每一個句子,標簽fi∈{0,1}表示第i個句子是否為樣例中的問答對提供了支持事實。我們通過BCE loss(Binary Cross-Entropy loss)引入這一信息,如式(11)所示。 LBCE=-∑ifiloggi+(1-fi)log(1-gi) (11) 因此,最后的損失函數可以表示如式(12)所示。 L=LMLE+λLBCE (12) 為了驗證本文提出的方法在多跳問題生成任務中的表現,我們在HotpotQA數據集上開展了實驗。HotpotQA是一個問答數據集,涵蓋有超過113k基于維基百科的問答對。每一個數據樣例由一個具體問題和兩篇包含有支持事實的文檔組成。數據集主要有兩種類型: comparison和bridge。本文遵循原數據集的數據劃分、90 447個樣本組成的訓練集和7 405個樣本組成的測試集,同時我們從訓練集隨機選取了800個樣本作為驗證集。 在多跳問題生成中,數據處理一般有兩種范式,句級和文檔級。Pan等[6]預先從數據中提取出推理必須的佐證事實作為模型的輸入,這是相對簡化的處理,需要大量人力成本進行數據標注。本文提出的模型主要基于文檔級的范式,更貼近現實需求。 本文所有的模型和實驗都是基于PyTorch神經網絡框架開展的。我們使用BERT自帶的Wordpiece分詞器來預處理文本,原文、答案以及問句的最大截斷長度分別取512,10和40。其他參數的設置與BERT-based相同,12層網絡,注意力頭數為8,隱狀態維度為768,所有的全連接層維度為2 048。模型使用AdamW優化器進行訓練,初始學習率和權重衰退率分別設置為2e-5和0.001。 而在文本生成的推斷中,模型使用beam search來緩解錯誤累積的問題,beam size為5。 同時為了驗證本文方法的通用性,我們還在通用的Transformer上進行了實驗,模型的參數設置與Vasvani等[17]相同,6層網絡,注意力頭數為8,隱狀態維度為512。 參照之前的一些工作,本文采用三個自動評價指標來評測問題生成方法的效果,BLEU,METEOR和ROUGE-L。 本文采用的基線模型主要有: (1)NQG++[9]: 該模型在編碼器中引入了豐富的語言學特征,包含實體信息、答案位置和詞性標注等; (2)ASs2s[23]: 該模型用不同的編碼器分開處理原文和答案文本,并基于key word-net結構進行特征的交互和匹配; (3)MP-GSA[24]: 該模型提出了門控注意力機制和最大值指針來提升文檔級別的問題生成; (4)CGC-QG[25]: 該模型在Seq2seq模型前,引入了一個GCN來選擇可能出現在問句中的關鍵詞; (5)SG-DQG[6]: 該模型構建了一個語義圖神經網絡來提升多跳問題生成; (6)QG-Reward[7]: 該模型通過強化學習直接優化問題生成相對應的指標來提升模型效果; (7)MulQG[15]: 該模型在Seq2seq模型中引入了一個基于GCN的實體圖神經網絡。 表1展現了在HotpotQA數據集上的實驗結果。表格第一部分是基于句級輸入的基線模型結果,第二部分是文檔級的結果,最后是本文提出方法的實驗結果。句級范式通過移除冗余句子降低了多跳問題生成任務的難度,并且同時需要大量人力成本的投入。而GES只需要在模型訓練階段使用監督信號用于輔助訓練,在實際的推斷應用中,不需要標注的句級標簽,模型就會自動預測潛在的佐證句并據此提升后續生成問句的質量。同時基于文檔級輸入的設定更符合現實情境的需求,也更具挑戰性。 表1 HotpotQA數據集上的實驗結果 從表1的結果來看,本文提出的GES方法相比于之前的基線模型在多個指標上有了非常顯著的提升。簡化的TEGES方法都明顯優于之前的方法,在BLEU-4有1.6個點的提升。幾個評價指標的顯著提升證明了我們的方法可有效提取出不同文檔間的關鍵信息點,過濾掉不相關的信息,進而提升生成問題的質量。 4.2.1 佐證句預測的影響 為了驗證佐證句選擇對多跳問題生成的作用,本文只保留了基礎的Seq2seq框架并進行了實驗,實驗結果如表2所示。GES和TEGES的性能都有明顯的下降,其中,BLEU-4分別從22.76下降到21.46,從17.03下降到14.36。 表2 消融實驗結果 同時為了測試本文方法的理論上界,我們在解碼器輸入側加入標注的佐證句位置信息而不是GES預測出的結果。模型在BLEU-4達到了23.44,一方面驗證了本文方法思路的正確性,冗余信息的過濾確實可以有效提升問題生成系統的性能;另一方面,在一定程度上體現了GES良好的去噪能力,在預測結果帶有一定噪聲的情況下仍然能輔助提升多跳問題生成。 4.2.2 圖神經網絡的影響 從表2可以看出,當移除圖神經網絡后,模型性能有小幅下降,相對于GES,TEGES下降幅度更大。我們認為單純從BERT學到的句級表示不足以準確預測出佐證句的位置信息,加入圖神經網絡,模型可以捕捉到分離信息點之間的聯系,從而提升佐證句的預測精度。 4.2.3 預訓練語言模型的影響 無論編碼器是BERT還是基礎的Transformer,GES在多個指標上都有顯著的性能提升,這充分說明了本文提出方法的通用性和魯棒性。GES的可移植性可以歸因于以下幾點: ①佐證句選擇模塊是獨立于Seq2seq框架外的,即插即用; ②直通估計量和多任務學習的訓練策略可以指導模型更好地學習; ③佐證句選擇可以提升多跳問題生成這一客觀規律的存在。 為了更好地分析本文模型在長文本下預測佐證句的效果,本文根據每個樣例的句子數量劃分了5個區間,在圖4左圖中,我們計算了GES預測佐證句的F1值。隨著句子數量的增加,模型預測的精度略有下降,但是GES依然可以保持超過70%的F1值。同時圖神經網絡給予模型預測精度的提升幅度隨著句子數量增加而提升,這也說明了圖神經網絡在佐證句預測中的重要性。 圖4 不同句子數量對模型性能的影響左圖顯示的是有無圖神經網絡對佐證句預測精度的影響,右圖是有無佐證句預測對問題生成性能的影響。 右圖展現的是在不同文本長度下,GES給多跳問題生成帶來的提升。顯而易見,句子數量越多,BLEU-4提升的幅度越大。通過這個實驗證明,佐證句選擇可以篩選出重要的句子,從而提升多跳問題生成模型的表現。 為了更準確地評測問題生成模型的性能,我們從測試集隨機抽取了100個樣例,進行了人工評測,評測標準有以下幾點: (1)流暢度:生成的問句是否在語法語義方面自然流暢,得分從1到5。 (2)復雜度:生成的問句是否需要兩個或以上的信息點才可以推理回答,得分從1到5。 (3)可回答性:生成的問句是否可以從文檔中得到回答,與給定的答案是否相符,分數為0或1。 實驗結果表3所示。 表3 人工評測結果 基于Transformer結構的模型在流暢度上的得分明顯優于其他模型。TEGES在三個評測指標上都明顯優于baseline,進一步說明了佐證句預測對多跳問題生成性能的提升。此外,歸功于Wordpiece分詞器的作用,即使GES,TEGES沒有使用拷貝機制,生成的問句也少有出現稀有詞問題(OOV)。 本節進行用例分析,圖5展現了一個具體例子以及本文提出方法和各種基線模型的對比。GES從兩個文檔中選出兩個與答案“French and English”相關的佐證句,涵蓋了所有用于問題生成的重要信息。通過佐證句選擇來過濾噪聲,本文模型可以生成需要復雜推理且可回答的合理問句。對比沒有佐證句選擇模塊的方法可以發現,該模型會受到不相關噪聲的干擾,例如,在圖5中,生成的短語“in Clackamas County,Oregon”與該用例的問答無關,生成的問句與答案不符。顯然,GES生成的樣例也明顯優于其他baseline模型,再次說明佐證句預測對多跳問題生成任務的輔助作用。 圖5 生成問題樣例 本文針對多跳問題生成任務提出了一種基于佐證句預測的神經網絡方法。模型引入了圖注意力神經網絡來建模句子級別的語義關系,并根據圖隱狀態表示來預測出對問題生成最重要的句子,進而提升模型的性能。同時,我們使用直通估計量來端到端地訓練模型。在HotpotQA數據上的實驗結果表明,GES可以準確地捕獲長文本中的佐證事實,有效輔助復雜自然問句的生成。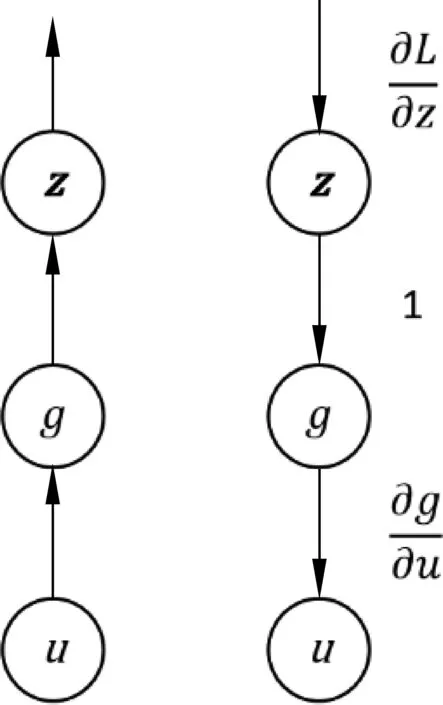
3 實驗設置
3.1 數據集
3.2 實驗細節
3.3 基線模型和評價指標
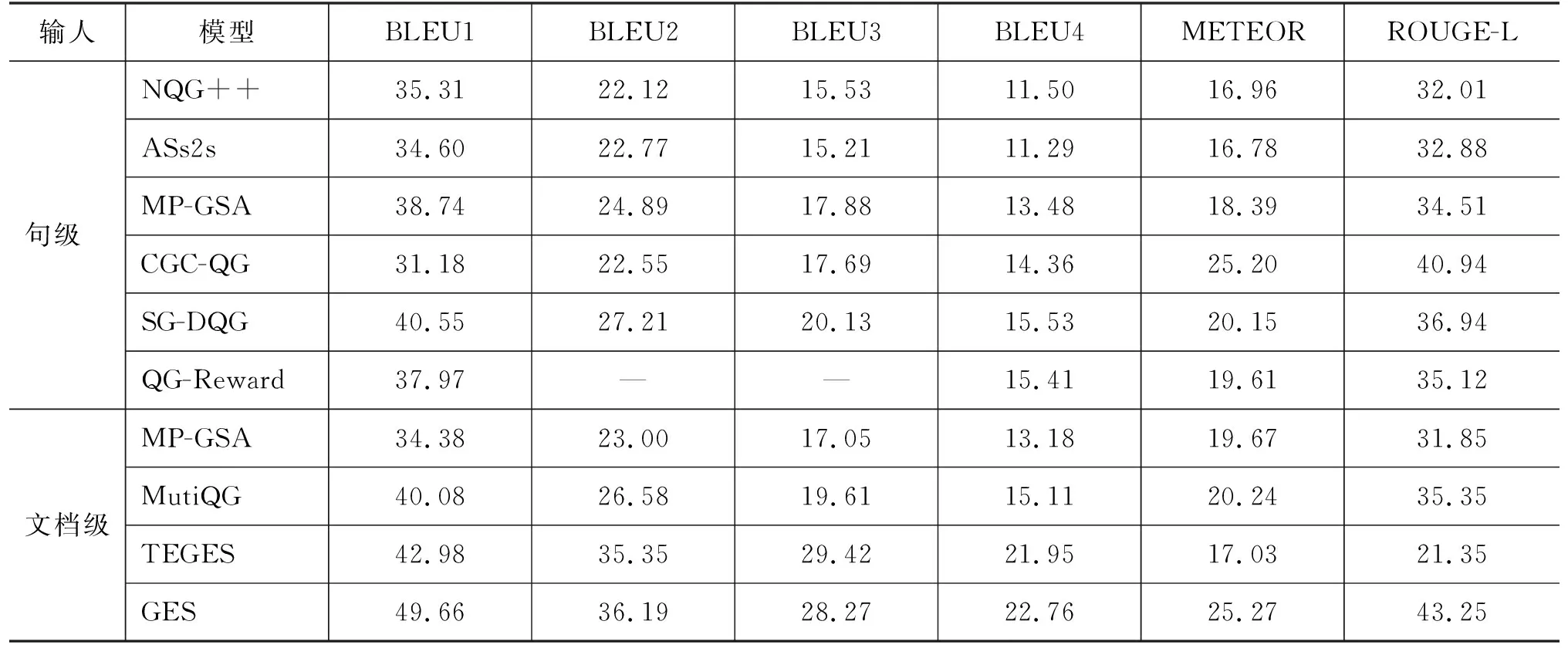
4 實驗結果和分析
4.1 方法對比
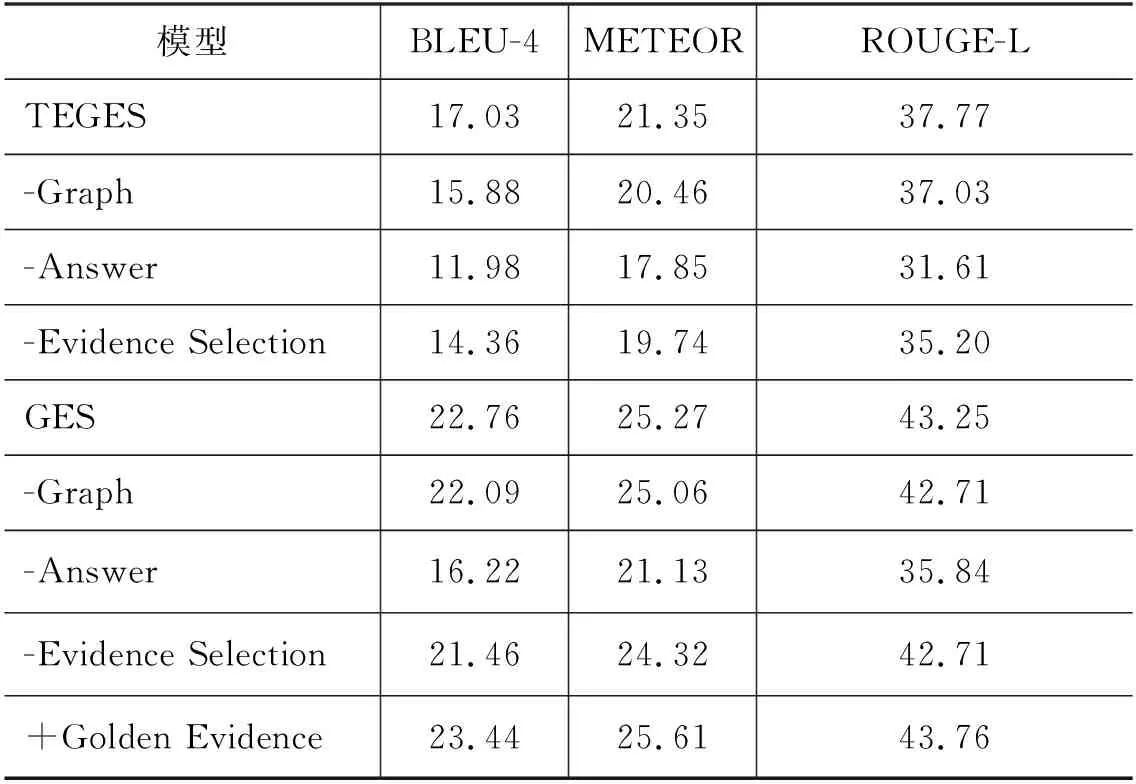
4.2 消融實驗
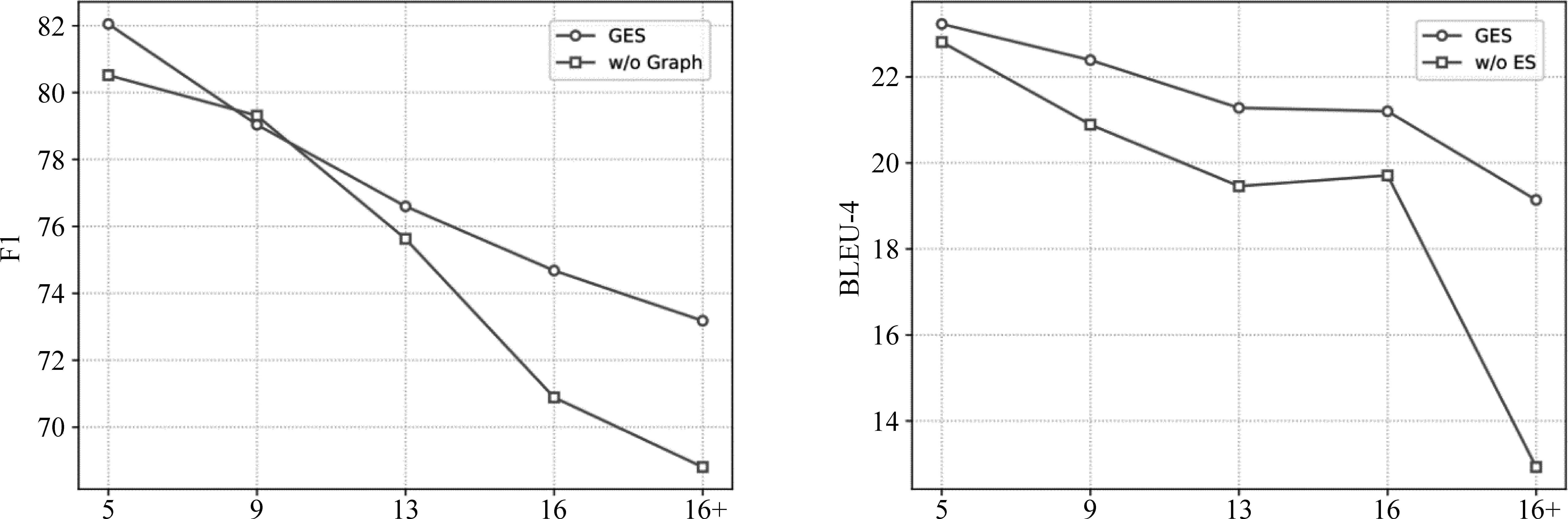
4.3 佐證句選擇的定量實驗分析
4.4 人工評測
4.5 用例分析

5 總結
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
