基于視覺Transformer的雙流目標跟蹤算法
2022-06-23 06:24:48江英杰宋曉寧
計算機工程與應(yīng)用 2022年12期
江英杰,宋曉寧
江南大學 人工智能與計算機學院,江蘇 無錫 214122
視覺目標跟蹤技術(shù)在智能安防、人機交互、無人駕駛、行為識別和人流統(tǒng)計等實際場景下具有非常廣泛的應(yīng)用[1-5],逐漸成為計算機領(lǐng)域內(nèi)的一個研究重點。根據(jù)需要跟蹤的目標對象數(shù)量的不同,可以分為單目標和多目標跟蹤。本文主要針對單目標跟蹤開展研究。近些年來,基于深度孿生網(wǎng)絡(luò)的目標跟蹤算法[6-8]由于簡潔高效的成對匹配形式和特征提取能力逐漸成為主流。其將跟蹤表示為匹配問題,使用共享參數(shù)的孿生網(wǎng)絡(luò)提取目標模板和搜索區(qū)域的特征并進行相似性衡量。在此基礎(chǔ)上,許多基于錨點(anchor-based)或無錨(anchor-free)的方法被提出,代表性的如SiamRPN++[9]和Ocean[10]。這些方法在跟蹤性能上取得了不錯的進展,但是其對模板和搜索區(qū)域特征的融合依賴于相關(guān)操作,對全局信息的利用還不夠充分。
最近隨著Transformer[11]在計算機視覺領(lǐng)域的廣泛應(yīng)用,一些前沿的研究開始發(fā)掘Transformer在改進孿生網(wǎng)絡(luò)跟蹤算法中的巨大潛力。如TrSiam[12]利用Transformer來增強和傳播深度卷積特征提高跟蹤精度。TrTr[13]使用Transformer獲得豐富的上下文信息來幫助孿生網(wǎng)絡(luò)進行相關(guān)性計算。STARK[14]通過Transformer編碼器-解碼器建模目標與搜索區(qū)域全局依賴關(guān)系。
雖然上述基于Transformer的目標跟蹤算法取得了不錯的進展,但是其主要都是為了更好地融合或者增強從深度卷積網(wǎng)絡(luò)如ResNet[15]中提取的目標和搜索區(qū)域特征,忽視了視覺Transformer本身在特征提取和解碼預(yù)測方面的能力。針對這些問題,本文提出基于視覺Transformer的雙流目標跟蹤算法。首先利用基于注意力機制的Swin Transformer[16]作為孿生主干網(wǎng)絡(luò)獲得更加魯棒的特征表示。接著通過Transformer編碼器-解碼器結(jié)構(gòu)充分融合目標和搜索區(qū)域特征,并學習目標特定的信息。最后對學習到的雙流信息分別進行預(yù)測后再進行決策層面的加權(quán)融合。通過本文這樣的設(shè)計可以有效利用雙流信息進行互補,能夠有效應(yīng)對遮擋、干擾和尺度變化等情況,實現(xiàn)準確的目標跟蹤。另外,由于本文算法是端到端進行訓練和測試的,避免了先前孿生網(wǎng)絡(luò)算法中使用的余弦窗等復(fù)雜的后處理步驟,跟蹤速度可達42 FPS(frame per second,F(xiàn)PS),具有巨大的潛力。
1 基于視覺Transformer的雙流目標跟蹤算法
本文算法整體框架如圖1所示。首先使用一個共享權(quán)重參數(shù)的Swin Transformer作為孿生主干網(wǎng)絡(luò)對第一幀目標模板(target template)圖像和當前幀搜索區(qū)域(search region)圖像分別進行特征提取。其次使用Transformer編碼器對目標模板特征和搜索區(qū)域特征進行特征融合,再使用Transformer解碼器學習目標查詢中特定的目標位置信息。然后對編解碼器輸出的雙流信息分別進行邊界框預(yù)測。最后在決策層面上進行加權(quán)融合得到目標最終跟蹤結(jié)果。

圖1 算法整體框架Fig.1 Overall framework of the algorithm
1.1 視覺Transformer孿生主干網(wǎng)絡(luò)
本文采用基于注意力機制的Swin Transformer作為孿生主干網(wǎng)絡(luò),具體結(jié)構(gòu)如圖2(a)所示。相比于經(jīng)典的卷積神經(jīng)網(wǎng)絡(luò),Transformer中的自注意力機制能夠挖掘全局依賴關(guān)系,具有全局感受野,在許多視覺任務(wù)上取得了很好的效果。Swin Transformer是由微軟在2021年提出的視覺Transformer模型,通過在不重疊的窗口進行自注意力計算和允許跨窗口連接來提高計算效率,使得其與視覺任務(wù)相兼容。

圖2 Swin Transformer孿生主干網(wǎng)絡(luò)Fig.2 Swin Transformer siamese backbone network
本文中Swin Transformer孿生主干網(wǎng)絡(luò)的輸入是一對圖像,分別是初始幀的目標模板圖像z∈RHz×Wz×3和當前幀的搜索區(qū)域圖像x∈RHx×Wx×3。輸出分別是模板特征和搜索區(qū)域特征為了降低計算成本,本文只使用Swin Transformer的前3個階段(Stage)提取特征,所以此處的步長s為16。
Swin Transformer每個階段由多個連續(xù)的Swin Transformer塊(block)組成,其中每兩個連續(xù)塊的結(jié)構(gòu)如圖2(b)所示,由層歸一化(layer norm,LN)、窗口多頭自注意力(window based multi-head self-attention,W-MSA)、移位窗口多頭自注意力(shifted window based multi-head self-attention,SW-MSA)和多層感知機(multilayer perceptron,MLP)通過殘差連接組成。具體過程可表示為:

其中,Xl和X?l分別表示第l個塊中MLP和兩種自注意力的輸出結(jié)果。當固定每個局部窗口中所包含塊的數(shù)量M×M時,W-MSA通過在不重疊的局部窗口計算多頭自注意力可以將計算復(fù)雜度從塊數(shù)量的二次方降低為線性復(fù)雜度。本文中M默認設(shè)置為7。同時SWMSA在保持非重疊窗口的有效計算的同時引入跨窗口連接,與前一層的窗口進行橋接,可以顯著增強特征建模能力。這種策略具有較低的實際延遲,并且可以逐層聚合相鄰窗口的特征表示,能夠感知全局信息,為跟蹤任務(wù)提供了更加魯棒的特征表示。
1.2 Transformer編碼器-解碼器結(jié)構(gòu)
Swin Transformer孿生主干網(wǎng)絡(luò)輸出的模板特征和搜索區(qū)域特征首先經(jīng)過一個1×1卷積層將通道數(shù)從C降低到d,與后續(xù)Transformer編碼器-解碼器結(jié)構(gòu)中的隱藏層維度保持一致。然后將兩個特征分別展平,再沿著空間維度連接起來得到長度為的總特征表示F輸入到Transformer編碼器中。
(1)編碼器。Transformer編碼器由一系列連續(xù)的編碼器層組成,每層包括多頭自注意力MSA和前饋網(wǎng)絡(luò)(feed forward network,F(xiàn)FN)。其中FFN包含一個兩層的多層感知機和GELU激活函數(shù)。每層間的計算過程如下:
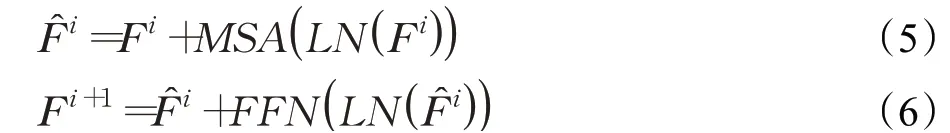
其中,F(xiàn)i和F?i分別表示第i層的輸入和中間計算結(jié)果。
由于Transformer是序列到序列模型,具有排列不變性,因此在通過拼接方式自然地融合來自模板分支和搜索分支的特征之后,本文添加了正弦位置編碼[11]到每個注意力層的輸入序列中,以確保模型在計算注意力過程中知道特征標記所處的位置和分支。通過編碼器層中的自注意力機制對總特征表示中的模板和搜索區(qū)域特征之間的依賴關(guān)系進行捕獲,利用全局信息有效融合和增強特征的判別性,幫助網(wǎng)絡(luò)更加準確地定位目標位置。
(2)解碼器。Transformer解碼器具有與編碼器類似的結(jié)構(gòu),也是由連續(xù)的解碼器層組成,每層包括多頭自注意力、編碼器-解碼器注意力和前饋網(wǎng)絡(luò)。
解碼器的輸入是編碼器輸出的增強后的總特征表示F?和目標查詢(target query)。不同于檢測任務(wù)中采用的多個對象查詢,本文只采用一個目標查詢進行預(yù)測來降低計算成本。目標查詢通過編碼器-解碼器注意力關(guān)注模板和搜索區(qū)域上的所有位置,建立全局關(guān)系,輸出得到魯棒的目標表示T用于后續(xù)邊界框預(yù)測。與編碼器類似,在解碼器的每個注意力層的輸入中也加入位置編碼來傳遞位置信息。
1.3 雙流信息預(yù)測與決策融合
總特征表示F經(jīng)過整個編碼器后輸出得到增強的總特征表示F?,然后將其按照原來的順序分離重新得到增強后的模板特征f?z和搜索區(qū)域特征f?x。解碼器輸出的目標表示T與搜索區(qū)域特征f?x一起構(gòu)成了Transformer編碼器-解碼器輸出的雙流信息。
為了充分地利用雙流信息中目標判別特征以及全局區(qū)域信息進行邊界框預(yù)測,本文對雙流信息進行融合與互補。具體地,如圖1中所示,一邊使用編碼器邊框預(yù)測頭(box head)融合雙流信息進行預(yù)測,另一邊通過多層感知機對解碼器信息進行預(yù)測。最后在決策層面進行融合進一步優(yōu)化目標跟蹤結(jié)果。
編碼器邊框預(yù)測頭的結(jié)構(gòu)如圖3所示。搜索區(qū)域特征f?x與目標表示T分別通過點積注意力機制和深度互相關(guān)(depth-wise cross correlation,DW Corr)操作進行特征增強,得到全新特征并進行拼接(concatenation)。然后重塑成方形特征圖輸入到全卷積網(wǎng)絡(luò)(fully convolutional networks,F(xiàn)CNs)中進行角點熱力圖(corner heatmap)預(yù)測。最后計算角點概率分布的期望得到編碼器流的邊界框預(yù)測結(jié)果BE。

圖3 編碼器邊框預(yù)測頭Fig.3 Encoder box prediction head
與STARK[14]不同的是,本文考慮到深度互相關(guān)操作在孿生網(wǎng)絡(luò)跟蹤算法中的廣泛應(yīng)用[9-10],能夠幫助找到搜索區(qū)域中與目標表示高度相關(guān)的位置,有利于后續(xù)的角點概率預(yù)測。因此將其與點積注意力機制進行互補,從兩個角度共同衡量目標相似性來增強重點區(qū)域得到更具判別性的全新搜索區(qū)域特征進行預(yù)測。
對于解碼器流信息使用三層的多層感知機MLP直接回歸目標邊界框坐標,得到解碼器邊界框預(yù)測結(jié)果BD。這樣的設(shè)計能夠以微量的計算成本來利用解碼器學習到的目標表示T中豐富的目標信息進行顯式的結(jié)果預(yù)測,避免了該信息只在編碼器邊框預(yù)測頭中起到相似性度量的作用的情況,減少了目標信息的浪費。
在得到雙流信息預(yù)測結(jié)果BE和BD之后,本文在決策層面使用了加權(quán)融合策略。通過兩個線性層分別學習編碼器流和解碼器流預(yù)測結(jié)果的融合權(quán)重w1和w2,然后對結(jié)果進行加權(quán)融合得到最終優(yōu)化的目標跟蹤結(jié)果BF,具體計算過程如公式(7)~(11)所示:


其中,W1和W2分別為這兩個線性層的權(quán)重矩陣,b1和b2為對應(yīng)的偏置項,w?1和w?2為歸一化之前的權(quán)重。
1.4 損失函數(shù)與多監(jiān)督策略
本文算法是通過端到端的方式進行訓練的,使用L1損失和GIoU(Generalized IoU)損失[17]對邊界框預(yù)測結(jié)果進行監(jiān)督。整個框體損失函數(shù)LBBox的計算公式如下:
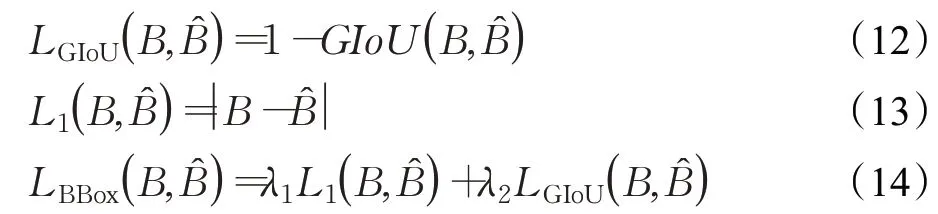
其中,B?和B分別表示邊界框真實標簽和預(yù)測結(jié)果,λ1和λ2是每項的損失權(quán)重系數(shù),在本文中分別設(shè)置為5和2。
考慮到恰當?shù)谋O(jiān)督策略對整體網(wǎng)絡(luò)的收斂與性能起到了非常重要的作用,本文針對提出的雙流信息預(yù)測與決策融合結(jié)構(gòu)使用了多監(jiān)督策略。即對雙流信息預(yù)測結(jié)果和最終跟蹤結(jié)果共同進行監(jiān)督以保證充分的收斂性及性能提升。最終的損失函數(shù)如公式(15)所示:
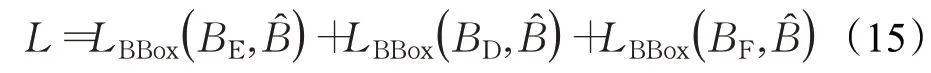
其中,BE、BD和BF分別代表編碼器預(yù)測框、解碼器預(yù)測框和最終預(yù)測框。
2 實驗結(jié)果與分析
2.1 實驗設(shè)置
本文算法是使用Python 3.6和Pytorch 1.5.1框架實現(xiàn)的。在具有兩塊RTX 2080Ti GPU的64 GB物理內(nèi)存的服務(wù)器上進行實驗。本文使用Swin-T[16]作為孿生主干網(wǎng)絡(luò),主干網(wǎng)絡(luò)輸出特征維度C為384,訓練過程中使用在ImageNet[18]上預(yù)訓練的參數(shù)進行初始化。Transformer編碼器-解碼器均為6層,其中多頭注意力的隱藏層維度d和頭數(shù)分別設(shè)置為256和8,前饋網(wǎng)絡(luò)的隱藏層維度為2 048。Dropout[19]設(shè)置為0.1來減少過擬合。編碼器邊框預(yù)測中的全卷積網(wǎng)絡(luò)由5層卷積塊組成,解碼器邊框預(yù)測使用的三層MLP的隱藏層維度為256。
訓練數(shù)據(jù)由LaSOT[20]、GOT-10k[21]和TrackingNet[22]數(shù)據(jù)集的訓練部分以及COCO[23]數(shù)據(jù)集組成。目標模板圖像及搜索區(qū)域圖像分別被裁剪成128×128和320×320的大小送到主干網(wǎng)絡(luò)中。數(shù)據(jù)增強采用了水平翻轉(zhuǎn)和亮度抖動等策略。整體訓練過程為500個周期(epoch),每個周期有60 000個樣本,使用AdamW[24]優(yōu)化器進行優(yōu)化。整體網(wǎng)絡(luò)的初始學習率為5E-5,權(quán)重衰減為1E-4。為了穩(wěn)定訓練保證收斂,采用梯度裁剪和學習率衰減策略,在400個周期后將學習率縮為原來的1/10。主干網(wǎng)絡(luò)以其他部分1/10的學習率進行微調(diào)。
2.2 數(shù)據(jù)集及評價指標
本文在LaSOT[20]、TrackingNet[22]、UAV123[25]和NFS[26]四個通用目標跟蹤數(shù)據(jù)集上驗證算法的有效性。其中LaSOT數(shù)據(jù)集有1 400個視頻序列,平均有2 512幀,共包含70個目標類別,每類有20個序列,涉及野外場景下的各種挑戰(zhàn)。該數(shù)據(jù)集每幀都是手工標注并經(jīng)過嚴格檢查,提供了一個高質(zhì)量的大規(guī)模目標跟蹤基準。其中劃分20%作為測試集,共包括280個視頻序列。
TrackingNet是從大規(guī)模目標檢測數(shù)據(jù)集中精挑細選出專門針對目標跟蹤的視頻片段并進行重新標注。總共30 643個視頻片段,平均時長16.6 s。其中測試集包括511個視頻和70個目標類別,并且沒有給出真實標注,只能通過在線服務(wù)器進行評估以確保公平比較。
UAV123數(shù)據(jù)集中包括低空無人機平臺采集的123個航拍視頻,平均915幀。隨著無人機的運動相機視角也在不斷發(fā)生變化,因此目標長寬比的變化比較明顯,對跟蹤算法的狀態(tài)估計能力提出了巨大的挑戰(zhàn)。NFS數(shù)據(jù)集包括100個視頻序列,使用高幀率攝像機從真實世界場景捕獲并手動標注,為實際跟蹤應(yīng)用提供測試基準。
LaSOT和TrackingNet兩個數(shù)據(jù)集均采用一次性評估(one-pass evaluation,OPE)策略,評價指標為精度(precision,P)、歸一化精度(normalized precision,NP)和成功率(success,S)。UAV123和NFS數(shù)據(jù)集只包括精度和成功率兩個指標。其中精度是通過比較預(yù)測結(jié)果跟真實結(jié)果之間的距離來計算,成功率是通過衡量兩者之間的交并比來計算。由于精度指標對目標大小和圖像分辨率非常敏感,因此歸一化精度是根據(jù)真實目標框大小對精度進行歸一化計算。最終跟蹤算法通常根據(jù)成功率圖的曲線下面積(area under curve,AUC)進行排名。
2.3 消融實驗
為了降低訓練成本,消融實驗中比較的算法模型均統(tǒng)一訓練250個周期,其余策略與實驗設(shè)置中完全訓練的模型保持一致。本文在LaSOT數(shù)據(jù)集上進行了消融實驗,報告了各種算法的成功率結(jié)果以及模型的參數(shù)量(Parameters,Params)、浮點運算數(shù)(floating point operations,F(xiàn)LOPs)和跟蹤速度(frames per second,F(xiàn)PS)。具體消融結(jié)果如表1所示。

表1 LaSOT數(shù)據(jù)集上的消融實驗Table 1 Ablation study on LaSOT dataset
其中,基線(Baseline)為STARK-S50模型。模型一(Model1)表示移除解碼器結(jié)構(gòu),直接使用編碼器信息進行邊框預(yù)測的模型。從模型一和基線的對比來看,基線中編碼器學習到的信息由于只起到了空間注意力的作用,因此移除整個解碼器對整體效果也不會帶來明顯的影響,反而節(jié)約了參數(shù)和計算量帶來了速度的提升。從側(cè)面反映出來基線結(jié)構(gòu)中對解碼器信息利用不夠充分,這也啟發(fā)了本文的改進。
模型二(Model2)表示使用本文改進的編碼器邊框預(yù)測頭的模型。通過額外引入深度互相關(guān)操作幫助找到搜索區(qū)域中與目標高度相關(guān)的位置來得到更具判別性的搜索區(qū)域特征,在大規(guī)模跟蹤數(shù)據(jù)集LaSOT上獲得一定的性能提升,證明了這種模型結(jié)構(gòu)改進的有效性。此外,該改進帶來的額外參數(shù)和計算量僅約為1.2×106和4×108,跟蹤速度達50 FPS,不影響算法實時性。
模型三(Model3)表示在模型二的基礎(chǔ)上加入雙流信息預(yù)測與決策層面融合的模型。與模型二相比,由于只增加了一個MLP和兩個線性層,因此只增加了1.0×105參數(shù)和1.0×108計算量。這樣的改動取得了0.5個百分點的成功率提升,說明融合后預(yù)測邊界框與真實邊界框的交并比獲得提升,證明該方法能提高邊界框預(yù)測的準確性,同時也反映出融合雙流信息的必要性。相比只使用編碼器的單信息進行預(yù)測,雙流信息預(yù)測可以融合解碼器中目標特定的判別信息,減輕干擾物的影響,進一步提高模型魯棒性。從實時性來看,算法的跟蹤速度保持在48 FPS,還是超過實時性要求(>20 FPS),并不影響其實際應(yīng)用。
模型四(Model4)表示只把基線模型中主干網(wǎng)絡(luò)ResNet50替換成Swin-T的模型。可以發(fā)現(xiàn)獲得了1.4個百分點的成功率結(jié)果提升,證明基于注意力機制的視覺Transformer作為主干網(wǎng)絡(luò)能夠為目標跟蹤提供更加魯棒的特征表示。這一改進由于只影響了主干網(wǎng)絡(luò)提取特征部分,因此對跟蹤速度的影響也比較小。
模型五(Model5)表示同時使用Swin-T主干網(wǎng)絡(luò)、改進的編碼器邊框預(yù)測頭和雙流信息預(yù)測與決策融合的最終模型。總體來說,通過4.7×106參數(shù)和1.3×109計算量獲得了在大規(guī)模跟蹤數(shù)據(jù)集LaSOT上2.2%的絕對性能提升。通過端到端的跟蹤,整體跟蹤速度仍能達到42 FPS,能夠滿足實時性的要求。
2.4 不同融合方法比較
對于編碼器和解碼器的雙流信息預(yù)測結(jié)果,本文在決策層面使用了決策層面的自適應(yīng)加權(quán)融合方法。為了進一步證明本文方法的有效性,本文在上述模型二的基礎(chǔ)上,將幾種融合方法進行實驗比較,在LaSOT數(shù)據(jù)集上的成功率結(jié)果如圖4所示。

圖4 不同融合方法比較結(jié)果Fig.4 Comparing results of different fusion methods
其中,方法一為ATOM[27]算法中對多個邊界框結(jié)果取平均的融合方式,即分別用0.5的固定權(quán)重對雙流信息預(yù)測結(jié)果進行融合。方法二在方法一基礎(chǔ)上參考目標檢測領(lǐng)域的方法,先計算兩個邊界框的交并比,大于閾值0.8的情況下再取平均,否則采用編碼器的預(yù)測結(jié)果。此舉通過人工設(shè)計避免雙流信息中低質(zhì)量框?qū)θ诤辖Y(jié)果的影響。方法三與方法二不同的是,否則采用解碼器的預(yù)測結(jié)果。
從圖中結(jié)果可以看出,直接取平均這種固定權(quán)重的融合方式效果相比未融合的上述模型二提升0.2%,說明直接融合雙流信息能夠帶來一定提升但是因為不同的跟蹤環(huán)境下兩者預(yù)測結(jié)果會有不同的表現(xiàn),固定權(quán)重難以適應(yīng)這種變化。
相比之下,方法二有所提升,這是由于通過交并比約束避免了一些較低質(zhì)量的預(yù)測結(jié)果的干擾。方法三效果比方法一略高,但是比方法二略差,說明編碼器流信息在一定程度上比解碼器流信息更具有判別力,也反映出雙流信息需要分配不同的融合權(quán)重。
本文方法取得了最好的結(jié)果,這是因為本文方法的融合權(quán)重是通過線性層自適應(yīng)學習得到的,在不同跟蹤場景下會根據(jù)雙流信息的重要性和預(yù)測質(zhì)量為其賦予不同的融合權(quán)重。當需要依賴編碼器的全局信息獲得更加準確的預(yù)測結(jié)果時,會為其分配更高的權(quán)重;當需要依賴解碼器的判別信息時,則為解碼器預(yù)測結(jié)果分配更高的權(quán)重。這樣的融合方式可以使得最終融合結(jié)果更適應(yīng)具體情況的變化,相比固定權(quán)重的方式更加合理,也更具有魯棒性。
2.5 不同算法的結(jié)果比較
為了驗證本文所提出算法的有效性,在LaSOT和TrackingNet兩個大型數(shù)據(jù)集上與當前主流的多種目標跟蹤算法進行實驗結(jié)果比較。涉及的算法有SiamFC[7]、SiamRPN++[9]、Ocean[10]、TrSiam[12]、TrDiMP[12]、TrTr[13]、STARK[14]、ATOM[27]、MDNet[28]、SiamFC++[29]和DiMP[30]。LaSOT數(shù)據(jù)集上的結(jié)果如圖5所示。

圖5 LaSOT數(shù)據(jù)集上的結(jié)果Fig.5 Results on LaSOT dataset
可以看到本文算法(Ours)達到了最佳的67.4%的成功率和72.4%的精度,相比STARK-S50分別取得了1.6和2.7個百分點的提升,也超越了TrSiam和TrDiMP等基于Transformer的跟蹤算法。除圖中給出的結(jié)果外,本文算法在LaSOT上的歸一化精度NP可以達到77.4%。證明本文提出的雙流信息預(yù)測和決策融合能夠有效利用來自Transformer編碼器-解碼器的雙流信息并進行融合互補,使得算法具有很好的目標尺度估計能力。在目標旋轉(zhuǎn)、形變和遮擋等各種困難場景下仍然能夠獲得較為準確的邊界框預(yù)測結(jié)果,跟蹤精度相比STARK-S50具有明顯的提升。也證明視覺Transformer作為孿生主干網(wǎng)絡(luò)能夠通過注意力機制建模全局依賴關(guān)系,為跟蹤任務(wù)提供優(yōu)秀的特征表示。
表2給出了在TrackingNet數(shù)據(jù)集上的實驗結(jié)果,其中“—”表示原始論文中未給出相關(guān)結(jié)果。從表中可以發(fā)現(xiàn),本文算法分別取得了80.9%、77.8%和85.6%的成功率、精度和歸一化精度結(jié)果。與STARK-S50相比,在各項指標上均有一定程度的提升,并且優(yōu)于SiamRPN++、Ocean和DiMP等主流跟蹤算法。得益于特征層面的主干網(wǎng)絡(luò)改進,信息層面的充分利用和決策層面的有效融合,在如此大規(guī)模野外跟蹤數(shù)據(jù)集上取得了優(yōu)秀的成果,證明了具有強大的跟蹤性能及泛化性。

表2 TrackingNet數(shù)據(jù)集上的比較實驗Table 2 Comparative experiments on TrackingNet dataset
表3中給出了在UAV123和NFS數(shù)據(jù)集上不同算法的成功率曲線下面積AUC的比較結(jié)果。可以看出,本文算法分別取得了68.6%和66.0%的結(jié)果,均比基線STARK-S50取得提升。在UAV123上取得了最好的結(jié)果,證明了算法的有效性。在NFS上僅次于TrDiMP,相比基線已經(jīng)獲得了1.7%的提升。不過本文算法的跟蹤速度可達42 FPS,超過TrDiMP的26 FPS,具有足夠的實際應(yīng)用潛力。

表3 UAV123和NFS數(shù)據(jù)集上的成功率Table 3 Success rate on UAV123 and NFS dataset%
2.6 跟蹤結(jié)果可視化
為了進一步展示出不同算法在目標發(fā)生遮擋、干擾、形變和旋轉(zhuǎn)等復(fù)雜情況下的實際跟蹤效果。本文從大型真實場景跟蹤數(shù)據(jù)集LaSOT上選取視頻序列(飛機、鳥和自行車)進行跟蹤結(jié)果的可視化,具體對比結(jié)果如圖6所示。其中紅色表示本文算法的跟蹤結(jié)果,綠色和藍色則分別表示DiMP和STARK算法的跟蹤結(jié)果。

圖6 跟蹤結(jié)果對比Fig.6 Comparison of tracking results
從圖6中可以看到在尺度變化、干擾、形變和遮擋等復(fù)雜跟蹤場景下,本文算法依然能夠獲得準確的目標狀態(tài)估計,得到高質(zhì)量的跟蹤結(jié)果,而DiMP和STARK算法則容易丟失目標或者尺度估計不夠準確。
具體來看,在第一行飛機視頻序列中目標的尺度發(fā)生了較大變化,DiMP算法依靠判別信息能夠定位到目標,但是尺度估計還不夠準確。STARK算法忽視了解碼器流信息,預(yù)測結(jié)果偏大。而本文算法通過雙流信息預(yù)測和決策融合,準確估計目標整體尺度,獲得更優(yōu)的跟蹤結(jié)果。
在第二行鳥視頻序列中,由于干擾物的存在導致DiMP和STARK算法將干擾物的部分也當作目標,產(chǎn)生誤判。即使DiMP算法采用了在線更新策略,但是在其更新的間隔仍然容易被干擾而導致跟蹤漂移。而本文算法通過自注意力機制有效捕獲目標全局依賴關(guān)系,精確定位目標,避免了干擾物的影響。
在第三行自行車視頻序列中,目標發(fā)生形變和遮擋的情況下本文算法依然能夠準確跟蹤,進一步體現(xiàn)出本文所提方法的有效性。
2.7 收斂性分析
為了進一步體現(xiàn)出本文使用的多監(jiān)督策略的有效性,本文對所提跟蹤算法的收斂性進行了分析。算法在訓練過程中的L1損失和GIoU損失結(jié)果如圖7所示,截取了其中300至500個周期部分。
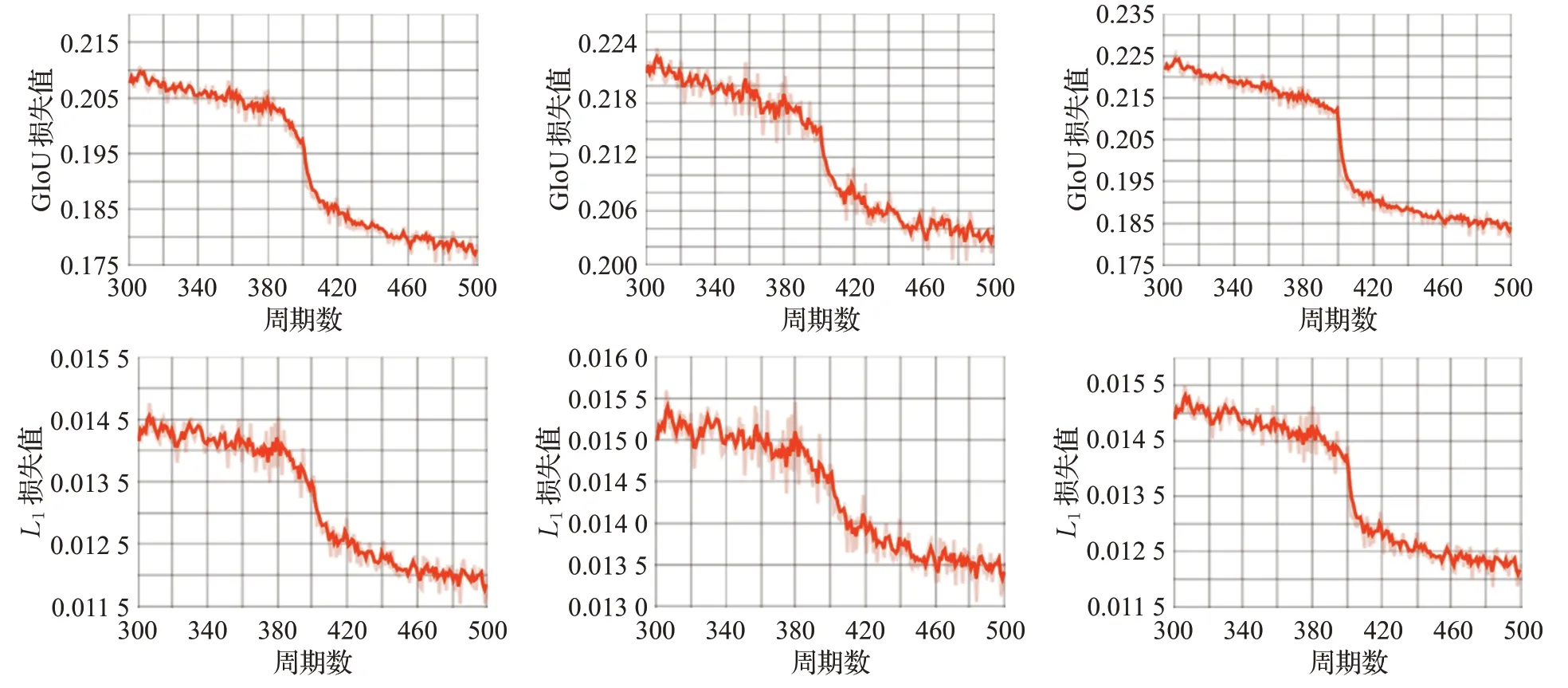
圖7 損失函數(shù)曲線Fig.7 Loss function curve
其中第一行分別為最終融合后的邊界框BF、編碼器預(yù)測框BE和解碼器預(yù)測框BD的GIoU損失,第二行分別為三者的L1損失。可以看到最終融合后的邊界框,無論是從衡量交并比的GIoU損失還是衡量中心位置誤差的L1損失來看,都成功收斂,并且取得了比融合前兩部分更小的損失值。這主要得益于本文使用的多監(jiān)督策略,將三個預(yù)測框共同進行監(jiān)督訓練,保證三者均成功收斂,并且獲得了更優(yōu)的融合結(jié)果。此舉可以避免只對最終融合結(jié)果進行約束而導致編碼器和解碼器預(yù)測框不夠準確的問題,具有明顯的優(yōu)勢。
3 結(jié)論
本文提出一種基于視覺Transformer的雙流目標跟蹤算法。對現(xiàn)有基于Transformer跟蹤算法進行改進,通過引入基于注意力機制的視覺Transformer作為孿生主干網(wǎng)絡(luò)提高特征抽取能力。設(shè)計雙流信息預(yù)測和決策層面的加權(quán)融合策略,簡單有效地利用編碼器-解碼器結(jié)構(gòu)的雙流信息,以少量的計算成本獲得了具有競爭力的大規(guī)模跟蹤性能提升。并且在端到端的跟蹤情況下,能夠達到42 FPS的跟蹤速度,具有巨大的潛力。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數(shù)理化(高中版.高考數(shù)學)(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
