基于SSD的輕量級車輛檢測網絡改進
2022-06-23 06:24:52楊德剛蔣倩倩何林晉
計算機工程與應用 2022年12期
徐 浩,楊德剛,蔣倩倩,何林晉
重慶師范大學 計算機與信息科學學院,重慶 401331
車輛檢測是近年來目標檢測領域中一個熱門的研究方向,其廣泛應用于智能交通、車流統計、擁堵監控系統之中。傳統方式的目標檢測算法一般采用梯度直方圖(histogram of oriented gradient,HOG)[1]或尺度不變特征(scale-invariant feature transform,SIFT)[2]等作為特征提取方法,再使用支持向量機(support vector machine,SVM)[3]或Gadient Boosting[4]和Adaboost[5]等自適應分類器對特征進行分類,整個檢測流程較為復雜且基于人工設計的特征提取方法難以提取出魯棒性強的特征。近年來,隨著深度學習算法的不斷發展[6-7],檢測的精確率不斷提升,并逐漸取代了傳統的目標檢測方式,但在面對實際應用時,基于深度卷積神經網絡的檢測模型還存在著占用硬件內存空間、計算耗時、檢測效率不高等方面的問題。終端攝像設備由于成本低廉,便于部署,維護簡單等特性被廣泛安裝于各個城市的交通干道之上,隨著萬物互聯時代的到來,各種終端設備不斷接入互聯網,將檢測任務從云端卸載到邊緣端有利于緩解網絡傳輸壓力、降低數據傳輸風險、保護數據隱私安全,輸入設備采集到的數據直接在本地進行處理,能夠避免網絡波動帶來的延時,使任務響應更加迅速,但目前大部分嵌入式設備上的算力很難支撐深度卷積神經網絡模型的實時運行,并且由于車輛具有快速移動的特性導致算力緊張的嵌入式的設備并不能準確、及時地捕捉移動中的車輛并返回檢測結果。
針對這一問題,本文結合殘差網絡(residual networkv2)[8]以及通道注意力網絡(squeeze-and-excitation networks,SENet)[9]提出一種改進的輕量級特征提取網絡,并根據輸入圖像大小及特征圖感受野簡化特征融合層數量,針對實際應用中特定角度下的車輛檢測任務重新設計默認框(default boxes)生成比例,在降低計算量的同時提升模型檢測效率,使得算力較低、存儲空間有限的嵌入式攝像設備也能部署基于深度學習的目標檢測模型進行車輛檢測任務并及時返回檢測結果,為以后的移動和嵌入式的智能監控設備提供一套輕量級的類實時車輛檢測參考系統。
1 傳統的SSD檢測模型
SSD(single shot multibox detector)目標檢測模型[10]是一種單階段(one-stage)目標檢測方法,該模型由兩部分構成,前半部分由深度卷積神經網絡來提取圖像特征得到多個不同尺度的特征圖(feature map),后半部分采用類似于特征金字塔網絡(feature pyramid networks,FPN)[11]結合多個不同尺度的卷積層輸出進行特征融合,對大小不同的目標進行定位和分類。SSD論文中使用VGG-16[12]作為特征提取網絡并將后兩層全連接層替換為卷積層(如圖1中的Conv6和Conv7),之后分別在38×38、19×19、10×10、5×5、3×3和1×1的卷積層上做特征提取得到不同尺度特征圖,如圖1所示。最后將6層不同尺度的特征圖依次送入分類網絡和回歸網絡中對不同大小目標的位置和類別進行回歸預測。
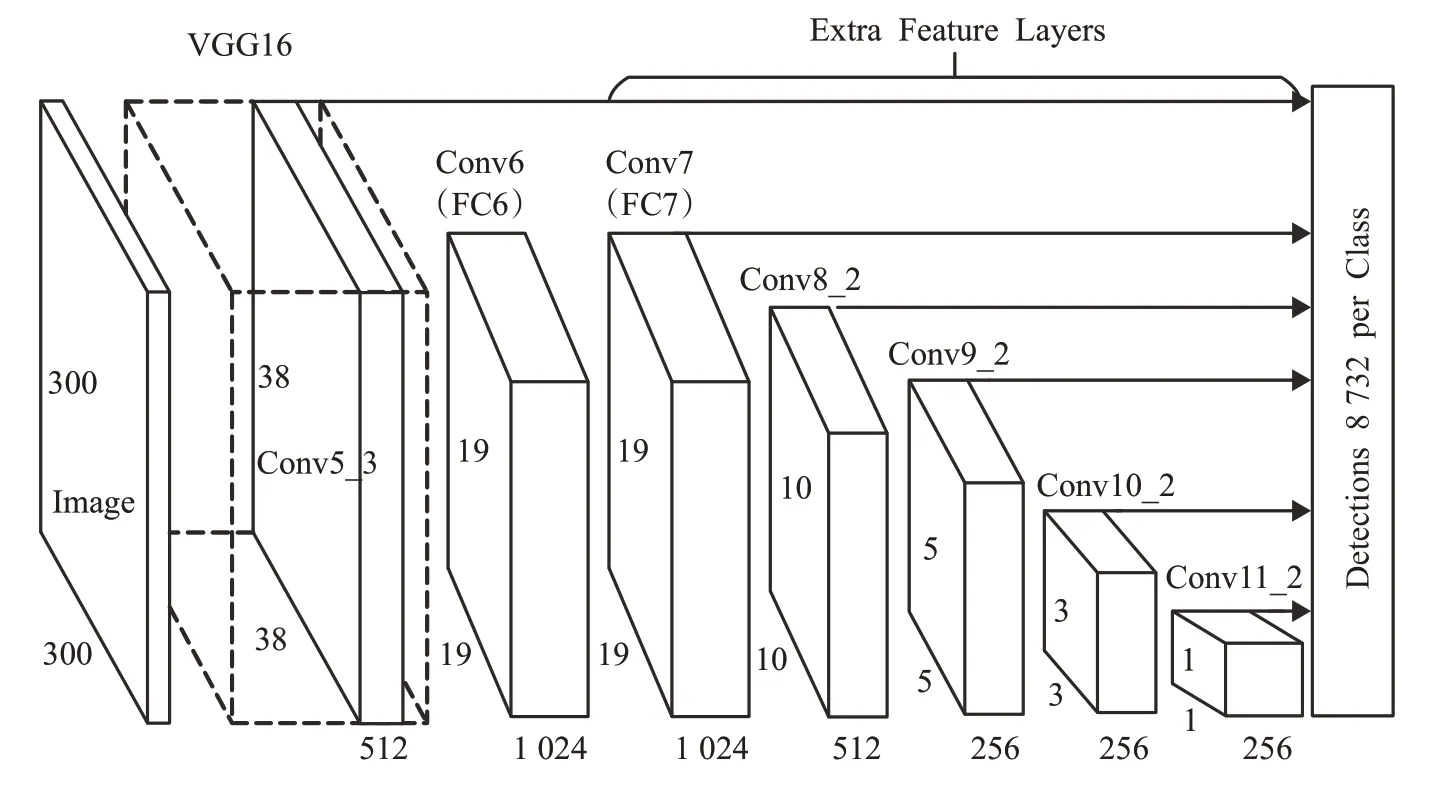
圖1 SSD檢測模型Fig.1 SSD object detection model
SSD檢測算法的損失函數由位置損失Lloc和置信度損失Lconf兩部分加權求和取得,計算公式如式(1):

其中,x為默認框與真實框的匹配結果,c為每個類別置信度,l為檢測網絡預測框,g為真實目標標注框,N為匹配正樣本總數,α為位置損失的權重,該損失函數的詳細定義可參考文獻[10]。
2 改進的SSD目標檢測模型
經典的SSD檢測模型采用VGG-16網絡導致網絡參數量龐大、運行時占用內存多等問題,為了在有限的計算資源平臺上實現目標檢測任務并做出及時的檢測結果反饋,需對原始SSD檢測模型的特征提取網絡及多尺度特征層進行精簡優化。本文使用改進后的通道注意力模塊(squeeze-and-excitation block,SE block)結合改進后的殘差連接塊(residual blockv2)作為SSD檢測模型的前端特征提取網絡,以及根據實際應用中在特定拍攝角度下車輛外形的長寬比特征重新設計SSD檢測模型的默認框生成比例并結合特征圖感受野范圍簡化特征圖融合層,降低算法運算復雜度,適應未來嵌入式攝像設備實時檢測移動車輛的應用需求。
2.1 通道注意力模塊
SE block主要根據每個通道對于目標的重要程度進行學習,強化對當前檢測任務有正向作用的通道特征并抑制對當前檢測任務作用較小的通道特征,在不影響現有網絡模型的基礎上通過壓縮(squeeze)和激勵(excitation)操作來重新標定之前的卷積結果U,得到新的卷積結果X?,SEblock工作原理如圖2所示。
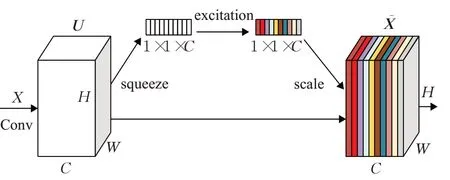
圖2 注意力模塊Fig.2 SEblock
圖2中U∈RH×W×C,X?∈RH×W×C。首先在原始卷積結果U上執行Squeeze操作,使用全局平均池化(global average pooling)[13]對每一個通道上的所有特征點計算一個平均值,使得每一個通道都壓縮為一個具有全局感受野實數,其計算公式如式(2):
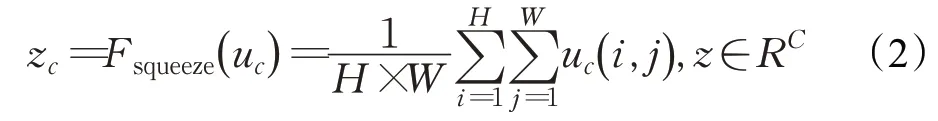
接著進行Excitation操作,對每個通道的重要性進行預測,其中第一個全聯接層(fully connected layers,FC)層先對數據進行降維,并使用ReLU激活函數對輸出結果進行非線性變換增強數據的表達能力,第二個FC層用來還原數據初始的維度,其計算公式如式(3):
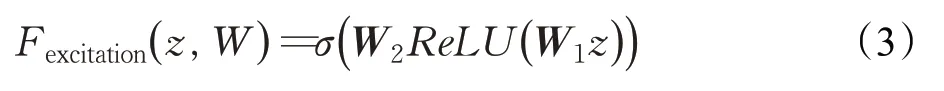
對于原始的SE block模塊,本文將Excitation操作最后一層的sigmoid激活函數如式(4),替換為用ReLU[14]函數表示的分段線性函數h-sigmoid如式(5):

以降低部分計算成本,其函數圖像對比如圖3所示。由于ReLU函數計算簡單并且在量化模式下可以消除由于編程實現方式不同帶來的數值精度損失[15],而sigmoid激活函數中的指數運算在反向傳播更新梯度時求導存在除法運算較為消耗計算資源,為了縮短模型訓練時間以及在算力有限的嵌入式設備中加速推理速度,使用h-sigmoid激活函數將更符合車輛檢測任務中快速檢測的需求,改進后的注意力模塊如圖4所示。
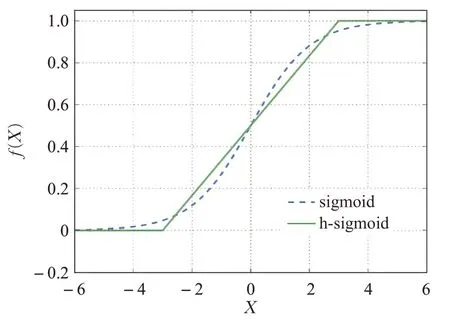
圖3 sigmoid對比h-sigmoid激活函數Fig.3 sigmoid vs h-sigmoid

圖4 改進后的注意力模塊Fig.4 Improved SE block
2.2 殘差連接塊
理論上神經網絡層數越深,擬合復雜數據模型的能力就越強,但實際在訓練深層卷積神經網絡時存在著梯度消失或梯度爆炸的問題,導致深層的卷積神經網絡難以訓練,針對這一情況He等人[7]提出的殘差神經網絡,在卷積塊之間加入恒等映射(identity mapping)的方式使淺層信息可以傳達到深層網絡,反向傳播更新權重時深層網絡的梯度信息也可以通過捷徑連接(shortcut connections)傳回淺層網絡從而訓練出更加魯棒的網絡權重,在殘差塊中的激活函數是深度學習的核心單元也是深度卷積神經網絡成功的原因之一,更為有效的激活函數雖然在每層中只有少量的擬合能力提升,但會因為在整個模型中的大量使用而獲得更強的數據擬合能力,本文將SSD檢測模型的特征提取網絡從VGG-16替換為了結合注意力機制的殘差網絡,并將殘差塊中的ReLU激活函數替換為h-swish激活函數,h-swish是Howard等人[15]提出用于逼近swish的硬性分段函數,計算公式如式(6),swish激活函數是Google Brain團隊在2017年提出的一種新的激活函數,計算公式如式(7),swish與h-swish函數圖像對比如圖5所示。

圖5 swish與h-swish激活函數Fig.5 swish vs h-swish

swish激活函數相較于ReLU激活函數能夠有效提高網絡模型檢測的精度[16],但swish激活函數中存在著指數運算計算成本較高,在算力較低的設備上計算耗時較長,在實際車輛檢測任務的應用場景中需要及時返回結果,本文使用計算更為簡單的h-swish激活函數替換殘差塊中的ReLU激活函數,用來模擬swish激活函數所達到的非線性激活效果,并在改進的殘差塊中加入注意力模塊得到改進后的注意力殘差模塊(SE-residual block)如圖6(b)所示,與傳統的Residual block對比如圖6所示。

圖6 殘差塊對比Fig.6 Residual block comparison
相較于傳統的Residual block,Residual blockv2中把批標準化(batch normalization,BN)[17]層和激活函數層提到卷積層之前,在執行卷積操作之前先把數據進行規范化以提升訓練效率,傳統的Residual block中在addition操作之后使用了ReLU函數進行非線性激活,由于ReLU激活函數非負的特性,導致數據在殘差塊間前向傳播時只能單調遞增,限制了特征的表達能力,Residual blockv2中把addition操作后的ReLU激活函數移動到addition操作前,文獻[8]表明卷積前激活(pre-activation)能夠達到更好的訓練效果。
2.3 默認框選擇
SSD檢測模型中采用了類似Faster-RCNN[18]中的錨框(anchor boxes)機制,對于同一特征層上的默認框使用不同的寬高比,設默認框的寬高比為ar,默認框的寬為,默認框高為,且當ar=1邊長為min-size時添加一個邊長縮放為的默認框,如圖7所示。

圖7 默認框生成原理圖Fig.7 Generate default box
默認框尺寸計算公式如式(8):

其中,m為模型檢測中采用的特征圖層數,Smin為設計好的最小歸一化尺寸,取值為0.2,Smax為設計好的最大歸一化尺寸,取值為0.9,Sk為第k個特征圖的min-size為參數,Sk+1為第k層的max-size參數,Feature map上每個點生成默認框的中心為,其中|fk|為第k個正方形特征圖大小i,j∈[0,|fk|)。
在模型訓練階段,多數情況下正樣本數量占比相對較少,存在著正負樣本不均衡的問題,而傳統的SSD算法中只對負樣本數量進行了篩選,為了保證訓練效果更加高效,采用Focal Loss[19]替換分類網絡中的Softmax損失函數,以減小易分樣本損失對總損失的影響。在模型部署階段,由于嵌入式攝像設備一般安裝于車輛行駛路面的正上方,檢測車輛時為正面俯視角度,根據攝像頭實際應用中安放位置和訓練所用數據集得到的固定拍攝角度的車輛特性對默認框比例進行重新設計,利用先驗知識判定特定在正面俯視角度下的完整車輛寬高比參數ar≤1,但由于捕獲延遲和拍攝時刻不同的問題,存在部分車輛的頂部或底部未包括在圖像中或只包含車輛的頂部或底部,區域候選框寬高比ar取值設定為{1,2,1/2,2/3,2/5}。
2.4 改進后的SSD網絡結構
改進后的SSD特征提取網絡主要在ResNet18殘差網絡結構的基礎上結合和通道注意力模塊將Residual block替換為改進后的SE-Residual block,并在全局平均池化之前新增加了一個注意力殘差塊用于增強模型的數據表達能力及提升特征圖的感受野,最終得到SE-ResNet20特征提取網絡,其主要由9個SE-Residual block組成,每個塊中包含了兩組完整的卷積模塊,在卷積模塊中首先進行批標準化處理(batchnorm)規范化數據,然后采用h-swish激活函數進行非線性變換,最后使用3×3的卷積核對特征圖進行卷積操作,在輸入圖像大小為512×512時每層卷積具體參數如表1所示。

表1 SE-ResNet20網絡結構Table 1 SE-ResNet20 network structure
改進后的SE-ResNet20由19個卷積層加上1個全連接層組成,在殘差塊中,當輸入和輸出維度相同時則直接將輸入通過跳躍連接加到輸出中,當輸入輸出維度不同時則通過步長進行下采樣,在Conv3_1、Conv4_1、Conv5_1、Conv6的第一層卷積中使用stride=2進行下采樣并進行通道升維使通道數量翻倍,接著使用全局平均池化得到一個1×1大小的具有全局感受野的特征向量,最后根據數據集中車輛的類別加上背景類共分為7類,得到1 024×7的特征輸出,改進后的SSD檢測模型如圖8所示。

圖8 改進后的SSD目標檢測模型Fig.8 Improved SSD object detection model
設特征圖大小為n×n,第n次下采樣后的特征圖為Cn,在特征圖的每個點上都設置k個不同比例的默認框,則單層特征圖生成默認框的數量為n×n×k。傳統的SSD目標檢測模型選取6個特征圖的k值分別為4、6、6、6、4、4,在使用512×512大小的輸入圖像下計算得到24 528個默認框。本文在訓練數據集中采用Kmeans聚類算法并設置K=7,通過標注的位置信息得到7類不同的先驗框,其相對百分比范圍為0.118 4~0.514 2,若采用512×512的大小輸入圖像,其真實框大小為60.6~263.2。通過感受野(effective receptive field)計算公式(9):
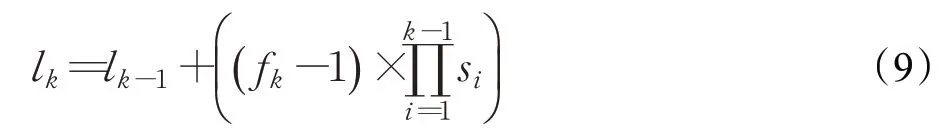
C4的感受野為64,C5的感受野為128,C6的感受野為256,結合感受野范圍大小改進后的模型在C4層使用ar為{2}的默認框,在C5層使用ar為{1,2,1/2,2/3,2/5}的默認框,在C6層使用ar為{1,1/2,2/3}的默認框,在采用同為512×512大小的輸入圖像中,改進后的SSD目標檢測模型默認框為2 496個,相較于傳統的SSD目標檢測模型默認框總數僅為其1/10,具體計算量如表2所示,更少的默認框匹配量可能導致在目標位置回歸精度上存在部分損失,但能夠減少大量計算提升檢測速度。

表2 默認框生成數Table 2 Default box number
3 實驗對比及分析
實驗所采用的軟件環境為Ubuntu18.04操作系統,Python版本為3.7.4,深度學習開發框架MXNet1.6.0版本,深度學習加速庫為NVIDIACUDA10.0和cuDNN7.6.5版本,優化工具套件OpenVINO為2021.1版本;訓練及測試硬件平臺為Intel Corei9-9900K處理器,NVIDIAGeforce 1080Ti11G顯卡,32 GB運行內存的主機;部署硬件平臺為Raspberry PI 3B+,Intel神經計算棒(NCS2)。
其中樹莓派Raspberry PI 3B+是Raspberry PI基金會開發的一款基于ARM處理器架構的卡片式低功耗電腦主板,搭載博通BCM2837B0處理器,1GB LPDDR2 SDRAM板載內存以及USB、RJ45、HDMI、CSI、音頻等豐富的外置擴展接口,通過Micro-SD卡槽可擴展存儲空間容量。IntelNCS2是Intel公司推出的低功耗AI協處理器設備,是一款基于USB模式的深度學習推理工具,被廣泛應用于邊緣計算場景中提供專用的深度神經網絡處理性能,通過USB接口可以連接在Raspberry PI 3B+上提供神經網絡推理加速功能,實驗設備如圖9所示。

圖9 實驗部署設備Fig.9 Experimental deployment equipment
實驗設置每批次(batch size)訓練樣本圖片為32張,優化器使用SGD(stochastic gradient descent)[1]算法,動量(momentum)設置為0.9,權重衰減系數(weight decay)設置為0.000 1,學習率(learning rate)初始值設置為0.001,迭代到100個Epochs之后每50個Epochs學習率減少為之前的0.2倍,迭代300個Epoch后結束訓練得到權重文件。改進后的SSD檢測模型與傳統SSD檢測模型的損失函數下降如圖10所示。

圖10 損失函數下降圖Fig.10 Loss function
模型訓練完成后將在主機上訓練好的MXNet模型文件.params和.json文件通過OpenVION工具套件對其進行優化,得到Intel NCS2能夠識別并加速的IR文件并進一步將IR文件的數據類型從Float32量化到INT8數據類型,由于模型訓練時正反向傳播中每次梯度更新的數值比較小,因此需要較高的數據存儲精度來表示,在模型訓練完成后的推理階段中權重數值精度對整個推理結果影響較小,不會對整個檢測模型的結果精度造成較大損失,通過模型量化可以減少推理階段的計算量以提升推理速度。最后將量化后的模型文件及權重部署到通過USB接口連接NCS2的樹莓派3B+上,部署實驗參考文獻[20]作出部分調整,實驗流程如圖11所示。

圖11 實驗流程圖Fig.11 Experimental procedure
3.1 實驗評價指標
BIT-Vehicle Dataset[21]是北京理工大學制作提供的車輛檢測公開數據集,采集的圖像均為路面車輛正面俯視圖,車輛類型總共包含六類車輛共9 850張,分別為公交車(bus)、小型客車(microbus)、小型貨車(minivan)、轎車(sedan)、運動型多用途汽車(SUV)和卡車(truck),每類對應數量分別為558、883、476、5 922、1 392和822。實驗按照8∶2的比例把數據集分為訓練數據集和測試數據集,并且為了增強訓練所得到模型的魯棒性,在訓練集中采用了水平翻轉、隨機擴展、剪裁等數據增強策略共得到15 760張帶有標簽的訓練數據集,部分訓練數據集圖片如圖12所示。

圖12 數據增強后的部分訓練集圖片Fig.12 Enhance dataset
實驗使用平均精度均值(mean average precision,mAP)、平均檢測速度、模型參數量大小、運行時占用內存大小作為模型的評價標準。
其中mAP計算公式如式(10):

其中,Q為類別總數,AveP(q)為第q類物體的平均精度(AP)。AP由準確率(precision,P)與召回率(recall,R)計算得到,其計算公式如式(11)、(12):

其中,TP表示被正確識別為正樣本的數量,FP代表被錯誤識別為正樣本的數量,FN表示被錯誤識別為負樣本的數量。
模型檢測速度:采用在測試數據集中檢測每張圖片平均耗費的時間,單位為毫秒(ms)。
模型參數量大小:訓練完成后的整個網絡模型及網絡模型參數的大小,單位為兆字節(MB)。
運行時占用內存:檢測模型運行過程中所占用運行內存(RAM)的空間總大小,單位為兆字節(MB)。
在要求及時反饋檢測結果的目標檢測任務中,模型檢測速度直接影響檢測結果是否能穩定可靠,在算力及存儲空間有限的終端設備上檢測模型參數量大小和運行時占用內存大小則直接影響終端硬件成本。
3.2 實驗結果對比
實驗統一采用縮放至512×512大小的圖像作為車輛檢測模型的輸入尺寸進行實驗,改進后的SSD目標檢測模型在數據集BIT-Vehicle上的mAP可以達到94.87%,實驗數據如表3所示。在保持其余外部條件不變的情況下,實驗對比了改進后的SE-ResNet20網絡與SSD原論文中采用的VGG-16網絡以及ResNet18 v2網絡和Howard等人于2019年提出的輕量級網絡MobileNetv3作為特征提取網絡時SSD目標檢測算法性能對比,實驗數據如表4所示。

表3 BIT-Vehicle Dataset檢測精度Table 3 BIT-Vehicle Dataset detection precision %

表4 不同網絡模型性能對比Table 4 Performance comparison of different detection models
由于在數據維度不一致時MobileNet和ResNet采用的兩種不同的策略,MoibleNet中使用增加1×1的卷積核用來達到數據的升維和降維,更多的卷積核會導致模型參數量及內存占用量較大,而在ResNet中則是采用步長進行下采樣,不會增加額外的參數。參數量越多代表著訪問內存的時間及次數也將更多,對于每一層卷積,設備都需要從內存中讀取特征值,進行卷積運算時也需要從內存中讀取每層的權重,在計算完成之后還需將新的特征值寫回內存,由于計算機內存讀寫存在耗時,內存中數據讀寫量越大所消耗時間就越多,通常情況下模型的權重文件越小,模型在實際運行時的檢測速度就越快。相較于ResNet18v2網絡,加入通道注意力模塊和替換激活函數后的SE-ResNet20增加了約10%的參數量以及約1 ms的推理時間,但在mAP上提升了0.85個百分點。
模型訓練完得到固定的權重之后,實驗將同一張圖片分別輸入傳統SSD采用的VGG-16網絡與改進后的SE-ResNet20網絡進行特征可視化,特征可視化結果如圖13、14所示,VGG-16網絡中采用第2、4、7、10、13層卷積層的結果,SE-ResNet20網絡采用C2、C3、C4、C5、C6的卷積層結果,從特征可視化結果可以較為直觀地看出,改進后的SE-ResNet20網絡相較于VGG-16網絡有更好的特征提取能力。

圖13 VGG-16特征可視化Fig.13 VGG-16 feature visualization
SSD目標檢測模型改進前后檢測效果如圖15所示,圖15(a)為經典的SSD檢測模型識別效果,圖15(b)為改進后的SSD檢測模型識別效果。

圖15 檢測效果對比Fig.15 Comparison of detection effect

圖14 SE-ResNet20特征可視化Fig.14 SE-ResNet20 feature visualization
從檢測效果來看,改進后的SSD檢測模型對位于圖像中心部分的完整車輛信息有更好的檢測效果,但對位于圖像邊緣的殘缺車輛信息檢測準確率及位置回歸精度較低,畫面邊緣小目標檢測效果不佳的原因可能在于C4特征圖的有效感受野僅為64,且為了提升檢測效率在C4特征圖上的默認框寬高比只使用了ar=2的比例,在圖像邊緣的小物體檢測上原SSD檢測算法融合了感受野更小的特征圖以及更多默認框比例,可以得到更精確的位置信息,由于在車輛快速行駛過程中攝像頭捕捉到的車輛圖像只有短暫時間位于畫面邊緣部分,對整體的車輛檢測任務影響較小。
從實驗得到的檢測結果數據可以發現,經過本文改進的SSD目標檢測模型較傳統的SSD目標檢測模型在檢測速度和檢測平均精度均值上均有所改進,改進后檢測模型的平均檢測時間下降了54.26 ms,模型參數文件減少了457.6 MB。在檢測模型實驗部署階段通過OpenVINO工具套件把32 bit的浮點型權重值量化為8 bit的整數型權重,進一步減少檢測模型的權重文件所占用的存儲空間,完成量化后的模型權重文件大小從39.7 MB壓縮到了11.6 MB。
4 結束語
針對目前的嵌入式攝像設備難以運行基于深度學習的目標檢測任務的問題,提出了基于殘差連接和通道注意力機制的輕量級SSD車輛檢測模型,改進后的SSD檢測模型參數量僅為傳統SSD檢測模型的1/12。實驗在BIT-Vehicle Dataset上對道路車輛檢測mAP達到94.87%,與原SSD模型mAP相比提升了0.83個百分點,平均檢測時間下降了54.26 ms,最終在實驗選定的邊緣設備上可以達到平均16 frame/s的檢測速度,對于嵌入式設備識別快速移動車輛效率不高的問題得到改進,為以后的智能交通場景中實時的車輛跟蹤、車流統計、擁堵檢測等應用提供了參考。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
