城市軌道交通橋隧結構巡檢平臺研究與開發(fā)
2012-07-05 02:58:16楊玉泉趙曉燕楊元偉
城市軌道交通研究 2012年5期
楊玉泉 趙曉燕 楊元偉
(1.上海市政工程設計研究總院(集團)有限公司,200092,上海;2.上海市政工程檢測中心有限公司,201114,上海∥第一作者,高級工程師)
近年來,隨著城市軌道交通線路里程數(shù)的不斷增加,城市日益增長的交通大大緩解,方便居民的出行。但是,在基礎建設飛速前進的背后,仍有部分技術、材料、設備以及規(guī)劃等各方面的不足與缺陷,以致使軌道交通事故時有發(fā)生,無論對人民生命安全、精神方面還是對社會財產(chǎn)來說,都造成嚴重的負面影響。從而,提升軌道交通施工及運營安全的意義重大。
在電子信息產(chǎn)業(yè)日益發(fā)達的當今,個人數(shù)字助理(Personal Digital Assistant,簡為PDA)以及智能手機由于具有便攜、操作簡便、通訊快捷等多項優(yōu)點,而在眾多行業(yè)中得到應用,如電力設備巡檢[1]、公路狀況巡檢[2]、野外測量[3]、物流管理等均有PDA的應用實例。物流行業(yè)采用PDA對貨物信息進行鑒別和查詢,并能夠與管理總部進行實時在線聯(lián)系,野外測量中將PDA作為數(shù)據(jù)自動采集終端,減輕工作人員的勞動強度,廠房設備以及電力設備巡檢中,PDA替代并改進了傳統(tǒng)的紙張記錄模式,將現(xiàn)場檢查信息實時記錄,在查詢出異常情況時,根據(jù)事情的嚴重程度,將信息實時傳送到管理中心,以備及時采取措施,避免重大事故的發(fā)生。
軌道交通橋隧結構線路長,全線結構形式除特殊的節(jié)點外較為單一,完全進行在線監(jiān)測既不經(jīng)濟,也不現(xiàn)實,應采用巡檢系統(tǒng)與在線監(jiān)測相結合的方法對全線結構的安全性進行把握,即對全線建立巡檢系統(tǒng)并在線路重要節(jié)點建立在線監(jiān)測系統(tǒng)。針對軌道交通橋隧結構的特點以及其當前的人工巡檢現(xiàn)狀,借鑒其他領域PDA應用的成功經(jīng)驗,設計開發(fā)具有針對性的電子化PDA巡檢系統(tǒng)平臺。
1 軌道交通橋隧結構人工巡檢軟件平臺設計
根據(jù)軌道交通橋隧結構的特點,將整個巡檢平臺劃分為兩大部分,即具有射頻識別功能的巡檢PDA和后臺巡檢管理平臺,各部分的組成及架構如圖1所示。其中巡檢PDA軟件能夠通過對布設于結構上電子標簽的識別,自動地調出相應巡檢點處的巡檢內容,并由巡檢人員現(xiàn)場對病害進行打分評價,繼而由軟件本身對構件進行狀態(tài)初評價。現(xiàn)場巡檢工作完成后的信息存儲于PDA中,巡檢人員根據(jù)PDA給出的評價結果,酌情將信息以USB(通用串行總線)或GPRS(通用分組無線網(wǎng)絡)方式傳送到后臺管理軟件,以備管理人員對信息進行存儲和及時反饋,并采取相應的養(yǎng)護維修措施。
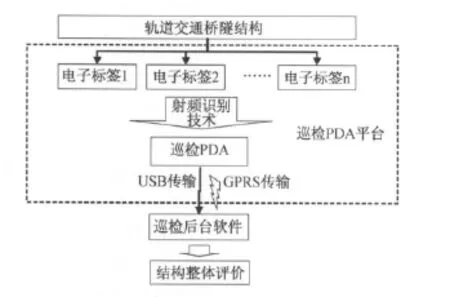
圖1 軌道交通橋隧結構人工巡檢平臺架構
2 人工巡檢PDA軟件的實現(xiàn)
根據(jù)本巡檢系統(tǒng)的功能并兼顧其與其他軟件的方便對接,采用微軟的Visual Studio 2008.Net平臺進行軟件開發(fā),該平臺支持多種高級程序設計語言,軟件開發(fā)更加便捷,同時,.net平臺中提供有智能設備的開發(fā)框架,簡化開發(fā)過程。本軟件即是以.Net平臺中的VB語言為基礎,在智能設備開發(fā)框架上進行的一系列開發(fā)。
2.1 程序開發(fā)流程
根據(jù)前述軌道交通橋隧結構人工巡檢平臺的架構,擬對現(xiàn)場采集PDA軟件依圖2所示流程分巡檢規(guī)劃、射頻識別、現(xiàn)場巡檢、數(shù)據(jù)存儲、狀態(tài)初評估等5個模塊進行開發(fā)。相應地,各模塊分別實現(xiàn)巡檢工作規(guī)劃、射頻識別、現(xiàn)場巡檢數(shù)據(jù)采集、狀態(tài)評估以及數(shù)據(jù)存儲等五大主要功能。
2.2 程序中類的劃分
Visual Studio.Net軟件平臺是真正面向對象的編程技術,將對象按照不同的性質進行劃分得到類,同類對象在數(shù)據(jù)和操作性質方面具有公共屬性,增強了程序的健壯性和可復用性。軌道交通橋隧結構包含的節(jié)點較多,橋梁結構中多以鋼筋混凝土或鋼結構簡支梁橋、連續(xù)梁橋為主,少數(shù)節(jié)點較特殊,如上海市軌道交通3號線中的剛構橋、系桿拱橋等,隧道結構則是以盾構形式為主。根據(jù)這些結構的類型特點,在巡檢軟件開發(fā)初始,構建軟件編程中所需相應的類以及各個類包含的子類(見圖3)。考慮程序編制的整體性,將沿線敷設的軌道以及巡檢的基本信息等作為與橋梁、隧道結構并列的類,并同時定義類與子類間的相互關系,以備程序編寫時調用方便。
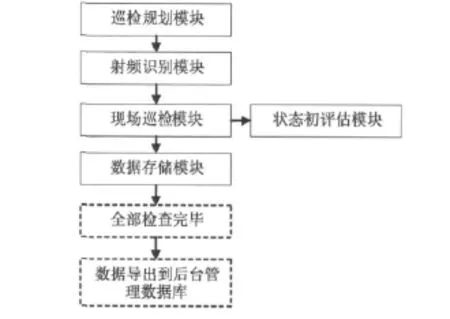
圖2 程序開發(fā)流程圖
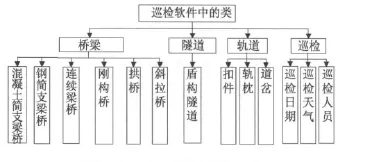
圖3 PDA巡檢軟件中類的劃分
2.3 人工巡檢PDA軟件的功能
為完成基于本系統(tǒng)架構的巡檢工作,將PDA軟件的主要功能歸納為用戶登錄、巡檢工作選取、巡檢工作規(guī)劃、基本信息、現(xiàn)場巡檢、數(shù)據(jù)存儲、構件級的評估以及養(yǎng)護維修決策等8大主要功能。軟件的主要界面如圖4~圖6所示。

圖4 巡檢設置界面

圖5 現(xiàn)場巡檢界面(1)

圖6 現(xiàn)場巡檢界面(2)
(1)用戶登錄:在巡檢開始時,確定巡檢人員,密碼功能嚴禁了非系統(tǒng)內用戶的進入。
(2)巡檢工作選取:該功能是進入本巡檢平臺中其他巡檢工作的窗口,同時亦是其他巡檢工作之間進行切換的中轉站。
(3)巡檢工作規(guī)劃:該功能包含了完成每次巡檢工作的基本信息,即巡檢日期記錄、巡檢天氣、巡檢人員登陸的密碼設置以及巡檢線路的選取等。其中,巡檢線路的選取主要是從軟件中已經(jīng)存儲的現(xiàn)有線路中選取當前需要巡檢的線路。
(4)基本信息:該功能主要由巡檢人員根據(jù)巡檢需求,選取已選中線路上的巡檢區(qū)間,選定后,相應待巡檢結構的基本特性以及巡檢點的布置位置將出現(xiàn)在相應文本框中,以備巡檢人員查看。
(5)現(xiàn)場巡檢:在巡檢工作規(guī)劃設置完成保存之后,由巡檢人員從“工作選取”功能進入到“巡檢”功能,開始現(xiàn)場巡檢工作。此時,巡檢人員首先用射頻識別儀掃描巡檢點處的電子標簽,反饋出巡檢點編號,并調出相應的巡檢內容,由巡檢人員逐一對各巡檢項進行評價。
(6)數(shù)據(jù)存儲:該功能將現(xiàn)場巡檢采集數(shù)據(jù)以及巡檢人員信息等以二進制的形式存儲于PDA中,使本軟件以外的其他軟件不能對數(shù)據(jù)進行任何操作。
(7)構件級別評估:在巡檢人員完成某一測點的各項巡檢內容后,系統(tǒng)將以分值的形式給出該座橋梁構件級別的評估。
(8)數(shù)據(jù)傳輸:該功能主要是由巡檢人員根據(jù)現(xiàn)場情況或者由PDA對采集數(shù)據(jù)作出的判斷,將現(xiàn)場情況通過無線網(wǎng)絡反饋到管理中心。
(9)養(yǎng)護維修決策:在對每座橋梁構件評價完成后,系統(tǒng)將給出相應的養(yǎng)護維修策略,以供巡檢人員參考。
3 結語
根據(jù)軌道交通橋隧結構的運營特點,設計并開發(fā)了具有射頻識別功能的電子化人工巡檢PDA軟件平臺。該平臺以PDA設備為支撐,替代了傳統(tǒng)的紙張式的現(xiàn)場巡檢工作,使巡檢人員的工作更加規(guī)范,減少現(xiàn)場設備的數(shù)量,避免人工錄入數(shù)據(jù),對軌道交通橋隧結構的巡檢以及日常養(yǎng)護維修工作具有一定的現(xiàn)實意義。
[1]胡春雄,布春明,李海峰.智能巡檢系統(tǒng)在線路運行中的應用[J].山西電力,2006(135):29.
[2]陳松林.基于PDA的公路養(yǎng)護巡檢數(shù)據(jù)采集系統(tǒng)的研制[J].電子工程師,2008(8):68.
[3]楊海明,李春燕.基于Windows Mobile的水準測量記簿系統(tǒng)的設計與開發(fā)[J].地理信息空間,2010(4):97.
[4]張琴,孫更新,賓晟.Visual Basic.Net 2008從基礎到項目實踐[M].北京:化學工業(yè)出版社,2010.
[5]賀農(nóng)農(nóng).西安地鐵工程施工安全監(jiān)督管理新模式[J].城市軌道交通研究,2011,14(7):102.
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
中國科技論壇(2017年7期)2017-07-25 08:49:53
媽媽寶寶(2017年2期)2017-02-21 01:21:24
國際漢語學報(2016年1期)2017-01-20 08:21:20
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現(xiàn)代企業(yè)(2015年9期)2015-02-28 18:56:50
中國中醫(yī)藥現(xiàn)代遠程教育(2014年22期)2014-03-01 04:32:55
