一種面向問答系統(tǒng)的多標簽答案檢索模型
2022-06-24 07:38:24李珊如周巖喬曉輝楊丹青王志剛
電子制作 2022年10期
李珊如,周巖,喬曉輝,楊丹青,王志剛
(1.河北漢光重工有限責任公司,河北邯鄲,056017;2.河北省雙介質動力技術重點實驗室,河北邯鄲,056017)
0 引言
智能聊天機器人模仿人類的交流能力,使用對話系統(tǒng)技術[1-2]使機器與人類互動。基于不同行業(yè)的不同需求,聊天機器人的使用框架也不盡相同。一般來說,聊天機器人必須了解人類的意圖,然后預測人類的行為,并做出相應的反應。
聊天機器人的日益普及也導致了這個研究方向在自然語言處理社區(qū)中成為熱門課題。例如Facebook人工智能發(fā)布了他們最大的開放領域聊天機器人BlenderBot,并將其開源,它包含了更像人類的對話技能,如個性、同理心和常識識別等能力[3]。此外,像XiaoIce、Mitsuku和MILABOT這樣的聊天機器人基于規(guī)則[1-2]、基于知識的[3-4]或基于檢索的系統(tǒng)[5-6]的對話管理器來執(zhí)行類人的屬性。盡管這種對話機器人在過去幾年中取得了顯著的進步,但在對話系統(tǒng)中,距離人類水平的智能還有很長的路要走。在實際應用中,局限于特定知識庫的面向任務的對話系統(tǒng)更為常用。通過與開放域代理集成,構建具有更自然和域外響應的面向任務的聊天機器人更有意義且更合理。除此之外,問答系統(tǒng)[4,10,2]是聊天機器人的核心部件,它需要自動地從檢索到的文檔中獲取用戶詢問的答案。
在本文中,我們提出的模型包括一個了基于注意力的五層編碼器和一個基于標簽的解碼器。具體來說,我們首先將上下文和用戶查詢數(shù)據分別提供給字符級和詞級的嵌入層。雙向長短時記憶網絡(BiLSTM)將應用于嵌入層的頂部,這是對循環(huán)神經網絡(RNN)的一種改進。BiLSTM的優(yōu)點是可以在存儲單元中獲取過去的信息。具體來說,我們使用sigmoid函數(shù)來確定保留信息的比例,以及需要忘記信息的比例,并使用它來決定RNN的輸出。在第四層,雙向注意力層將上下文向量和用戶查詢向量連接起來,產生查詢感知的表示向量。雙向注意機制是指我們使用context2query和query2context的注意力機制來最小化訓練過程中的語義信息損失。建模層再次利用了BiLSTM對輸入文本進行語義和位置信息建模。為了獲得更高的預測精度,輸出層采用了基于標記的解碼器。
同時,受到文獻[9]的啟發(fā),我們將文檔中的每個詞標記為二進制分類,以確定答案的起始和結束位置。在我們的模型中,我們使用指針網絡[10],根據輸入數(shù)據計算輸出的條件概率。我們的任務是僅從給定的上下文查找標記,并從原始上下文使用標記生成答案,在這種情況下,將指針網絡用于我們的任務是一個潛在的理想方案。
1 相關工作
Amrita Saha等人[1]引入了復雜順序問答(CSQA)系統(tǒng),該系統(tǒng)將問答和對話結合在一起,因此,它可以學習在大規(guī)模知識圖的基礎上通過一系列連貫的問題進行聊天。但這個系統(tǒng)在復雜問題上有局限性。為了解決這一問題,作者探索了推理聚合或邏輯函數(shù)以及能夠解析復雜問題的更有效的編碼器。在處理間接問題時,可以利用顯性的監(jiān)督注意力機制。
Sen Hu等人[2]提出了一種狀態(tài)轉換框架,將復雜的自然語言問題轉換為語義查詢圖,并通過知識圖將問題的答案與查詢圖匹配,以解決目前在回答復雜問題時存在的局限性。具體來說,首先,作者從問題中識別出實體和變量等節(jié)點作為初始狀態(tài)。其次,他們提出了連接、合并、擴展和折疊原語操作的條件,以促進狀態(tài)轉換過程。再次,利用所提出的MCCNN模型提取實體和關系。最后,利用支持向量機排序的獎勵函數(shù)進行狀態(tài)轉換,選擇下一個狀態(tài)。實驗結果表明,他們的框架比現(xiàn)有的方法在復雜問題上表現(xiàn)更好。但是,在使用折疊操作時,有時會出現(xiàn)一些結構失效、實體鏈接失效、關系提取失效、復雜聚合問題性能低下等問題。
Anusri Pampari等人[3]提出了一種在特定領域和大規(guī)模生成問答數(shù)據集的方法。該方法將專家現(xiàn)有的注釋用于其他NLP任務。它們?yōu)榈谝粋€具有大規(guī)模的問答對和問題-邏輯形式對的患者特定電子醫(yī)療記錄(EMR) 問答數(shù)據集做出了貢獻,允許用相應的邏輯形式驗證答案。研究表明,具有符號表示的邏輯形式有助于語料庫的生成。未來的工作可能是使用原始實體的詞匯變體來生成問題-邏輯形式,更多的多重句子推理問題和生成沒有內容相關實體的問題。
Lisa Bauer等人[4]提出了一個問答系統(tǒng)框架,該框架可以有效地執(zhí)行多跳推理,并使用雙向注意和指針發(fā)生器解碼器產生準確和一致的答案。他們還提出了一種算法,可以利用常識知識填補問答系統(tǒng)推理的空白。
Xinya Du和Claire Cardie[6]研究了一種利用共指信息訓練問題生成系統(tǒng)的方法。為了更好地編碼用于段落級問題生成的語言知識,他們提出了用于神經問題生成的門控關聯(lián)知識(CorefNQG)。對于問題生成,該生成器將文本輸入作為位置特征嵌入、答案特征嵌入和詞嵌入的連接。

圖1 模型結構與流程
2 模型與方法
■ 2.1 總覽
我們的模型是一個分層的多階段結構,其中包括了基于注意力機制的編碼器和基于標簽的解碼器。作為一種層次結構,我們的注意力編碼器首先將輸入上下文和用戶問題用字符級卷積神經網絡映射每個字符到一個字符向量。然后,我們通過預先訓練的詞嵌入模型將每個單詞映射到一個詞向量。在上下文嵌入層,我們通過BiLSTM網絡獲取每個給定單詞的上下文表示。之后,在注意力流層,模型可以同時獲取上下文和用戶提問向量,并將它們轉換為每個單詞的問題感知特征向量。在模型編碼器部分,首先是建模層,該層部署了一個BiLSTM來進一步提取高級語義特征,并將相應的輸出作為基于標簽的解碼器的輸入,用于我們答案范圍的預測。
■ 2.2 基于注意力機制的編碼器
(1)字符嵌入層。利用神經網絡將每個單詞的字符嵌入到高維向量空間中。其中輸入文本是一維的,輸出是固定大小的向量。輸入上下文的表示形式是{c1,c2,… ,cT}和{q1,q2,… ,qJ}用于輸入用戶問題。

(2) 詞嵌入層。使用預先訓練好的向量進行詞級嵌入。
(3) 上下文嵌入層。取C表示上下文的d維向量序列,Q表示查詢的d維向量序列作為該層的輸入,是以前兩層公路網的輸出。由于我們生成上下文詞向量F和查詢詞向量來服務于下一個雙向注意層,所以在它們的頂部使用了兩個LSTM。
(4) 雙向注意力層。通過將C和S作為輸入上下文標記和輸出上下文標記作為查詢感知向量W來實現(xiàn)雙向注意力機制。這種注意力機制使用Softmax計算權重 w =softmax ((maxcol(S) )∈RT,從而確定用戶問題和上下文之間的最高概率的單詞,生成新的用戶問題向量和上下文向量。
(5) 建模層。使用W作為輸入。使用雙向LSTM,輸出發(fā)送到解碼器進行最終的答案預測。
■ 2.3 基于標簽的解碼器
基于標簽的解碼器旨在提取上下文中的文本跨度作為我們的預測答案。傳統(tǒng)上,以往的工作[5]主要把這個問題看作是整個上下文范圍內的多分類任務,模型需要預測上下文概率分布上的開始和結束索引。在我們的工作中,我們提出了一種新穎的方法,將該問題重新建模為多個二元分類任務,并對給定上下文的每個單詞施加一個分類器。
為了實現(xiàn)這一點,給定上下文中的一個單詞,我們使用一個指針網絡[10]來預測當前令牌是否屬于開始索引。類似地,我們建立了一個相同的二進制分類器來預測當前標記是否屬于結束索引。具體來說,給定基于注意的編碼器建模層的輸M,我們通過以下公式計算每個單詞的概率:

其中pi
start和piend表示上下文中預測第i個單詞的概率作為答案文本的開始和結束位置。如果概率超過某個閾值,則將相應的標記賦值為標記1,同樣,如果沒有,則將標記賦值為0。通常,我們將閾值設置為0.5。im是來自建模層的第i個單詞的上下文表示。W為可訓練權矩陣,b為偏置矩陣。
如上所述,不難推測我們的模型是通過交叉熵損失函數(shù)進行訓練優(yōu)化的。具體來說,該模型優(yōu)化下方的似然函數(shù)來識別給定上下文表示C和查詢表示Q的預測答案S的范圍。
3 實驗
■ 3.1 數(shù)據集
我們在SQuAD數(shù)據集[9]上評估我們的模型,SQUAD是閱讀理解和問答系統(tǒng)的常用研究性數(shù)據集,由超過10萬對問題和答案組成,這些問題和答案是通過在500多篇維基百科文章上的眾包手工創(chuàng)建的。每個問題的答案都在相應的文章中,以一段文本[9]的形式出現(xiàn)。創(chuàng)建這個數(shù)據集的目的是讓機器能夠讀取上下文并相應地回答問題。
■ 3.2 模型細節(jié)
我們的模型的參數(shù)設置基本上與基線模型[9]一致,這樣保證了效果對比的公平性。如表1所示,我們將CNN LSTM的隱層大小設為100。詞嵌入維度為100。訓練集以0.5學習率進行學習,并訓練64個輪次。我們使用AdaDelta[2]進行優(yōu)化。在訓練過程中,保持模型各權重的移動平均,并設定指數(shù)衰減率為0.999。在環(huán)境配置方面,我們使用一個特斯拉P100 GPU對模型進行了大約8小時的訓練。另外,我們的操作系統(tǒng)是Linux Ubuntu 16.04, Python版本是3.6。

表1 模型細節(jié)與實驗設置
■ 3.3 實驗結果
值得注意的是,在我們的實驗中,所有的基線都是單一模型,而不是集成模型。由表2所示,由于缺乏處理高維語義特征的能力,樸素機器學習方法,即邏輯回歸獲得了最低的性能。其他基線模型在EM和F1-score指標方面實現(xiàn)了差不多的實驗結果。先前的最先進的基線模型BiDAF,獲得了68.0 EM和77.3 F1-score。我們的模型分別優(yōu)于BiDAF的0.5 EM和0.5 F1-score,這有力地證明了我們的模型的有效性。我們的模型取得較好性能的原因是多個二進制分類器能夠在更細粒度的層次上區(qū)分特征多樣性。

表2 在SQUAD數(shù)據上的實驗結果

BiDAF 68.0 77.3我們的模型 68.9 78.0
4 分析與驗證
■ 4.1 不同的閾值設置
我們在0.3~0.7的范圍內選擇閾值。從表3可以看出,當閾值設置為0.5時,模型的效果最好。說明訓練樣本相對均衡。
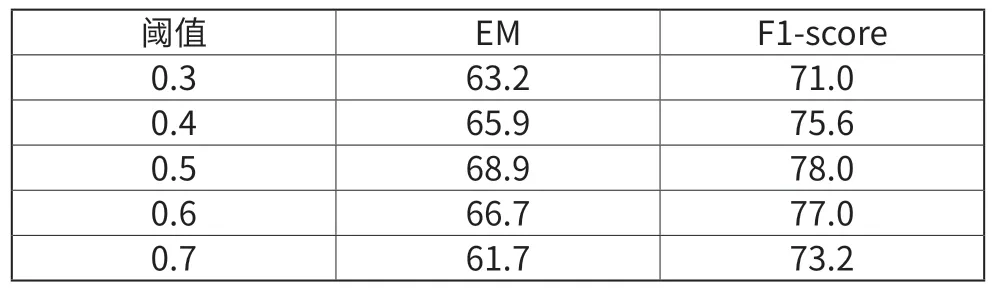
表3 不同閾值設定下模型結果
■ 4.2 超參數(shù)微調
我們選取了幾個超參數(shù)用于模型微調。具體地,我們選擇了不同的LSTM隱層大小和學習率進行參數(shù)優(yōu)化。如表4所示,當LSTM隱層大小為256,學習率為0.5時,模型得到了最先進的結果,這與基線模型的結果一致。

表4 超參數(shù)微調
5 結語
本文旨在通過對現(xiàn)有方法的探索和改進來提供問答系統(tǒng)的性能。本文首先從現(xiàn)有文獻中列舉了一些基線框架作為相關工作。之后我們提出了一個多標簽解碼器,這是我們的框架的基本結構。基于編碼器-解碼器模型的改進可能是未來研究中提高性能的一個有前景的方向。在SQUAD數(shù)據上的實驗結果驗證了我們模型的有效性。
猜你喜歡
閱讀(快樂英語中年級)(2024年9期)2024-10-23 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
意林(繪英語)(2017年5期)2017-05-15 02:17:23
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
