一種改進的多分類孿生支持向量機
2022-06-24 10:02:36周開偉錢雪忠周世兵
計算機應用與軟件 2022年4期
周開偉 錢雪忠 周世兵
(江南大學物聯網工程學院 江蘇 無錫 214122)
0 引 言
支持向量機(Support Vector Machine,SVM)是Vapnik等在統計學習理論的基礎上提出的一種用于二分類的機器學習算法[1]。該算法在解決小規模樣本的分類問題上比一些其他算法有更好的性能,故對SVM的相關研究受到了極大的重視。為了進一步提高SVM的性能,2007年Jayadeva等在廣義特征值近似支持向量機的基礎上提出了求解二分類問題的孿生支持向量機(Twin Support Vector Machine,TWSVM)[2-3]。TWSVM通過求解一組二次規劃(Quadratic Programming Problem,QPP)產生一對非平行的超平面,分別對應于兩類相應的樣本,使得某一類樣本盡可能距離相對應的超平面近,同時盡可能遠離另一類的超平面。理論上TWSVM每次求解一個QPP問題的規模是傳統SVM問題的一半,所以TWSVM求解問題的速度是SVM的四倍[4]。為了提高TWSVM的性能,國內外眾多學者對其進行改進,進而提出了不少改進算法。例如,投影孿生支持向量機(Projection TWSVM)[5]和基于Chen-Harker-Kanzow-Smale(CHKS)函數的光滑孿生支持向量機(CHKS TWSVM)[6]。
現實中,多分類問題是普遍存在的,所以研究多分類具有重要意義。構建多分類支持向量機使用最多的方法是間接構建法,即通過不同的策略將多個二分類器組合成一個多分類器,該方法計算復雜度低,實現簡單,且容易理解。目前,已經有許多學者在多分類孿生支持向量機的研究上做出了一定貢獻。Xie等[7]結合一對多(one-versus-all,OVA)策略和TWSVM構造出基于一對多策略的多分類孿生支持向量機(OVA-MTWSVM),該算法將TWSVM運算速度快與OVA策略原理簡單且易實現等優點相結合,從而提高了解決多分類問題的效率和速度。Shao等[8]將Knerr提出的一對一(one-versus-all,OVO)策略和TWSVM相結合得到基于一對一策略的多分類孿生支持向量機(OVO-MTWSVM),此算法因為使用OVO策略,每個子分類器只需兩類樣本參與訓練,訓練的速度較快,而且能很好地解決樣本不平衡問題。Gu等[9-10]結合TWSVM與圖論中的有向無環圖(directed acyclic graph,DAG)得到基于有向無環圖的多分類孿生支持向量機(DAG-MTWSVM),該算法與其他策略相比在分類時需要的分類器數量較少,分類速度較快。Yang等[11]將多對一策略(all-versus-one,AVO)與TWSVM相結合得到基于多對一策略的多分類孿生支持向量機(AVO-MTWSVM),又被稱為多生支持向量機(MBSVM),此算法和OVA-MTWSVM一樣具有較低的算法復雜度,因此受到眾多學者的關注。除了這四種常用方法外,Xu等[12]將TWSVM與1-versus-1-versus-rest(1-1-R)策略相結合得到一種全新的多分類孿生支持向量機(Twin KSVC)[12],此算法的每個子分類器既考慮到了待分類的兩類樣本,同時也將其他類樣本考慮在內,具有更好的算法魯棒性。
本文在多對一的多分類組合策略的基礎上提出一種改進的多分類算法。所謂多對一策略就是將訓練樣本中某一類樣本設為負類樣本并與設為正類樣本的其余所有類樣本組合構建多個二分類器。根據測試樣本與超平面的距離,若測試樣本距離某一類的超平面最遠則判定測試樣本屬于該類。另外,此算法設定每個二分類器的參數都是相同的,以此來解決多分類問題。本文在此基礎上通過添加正則項[13]來貫徹SVM的最小結構風險原則[14],并結合最小二乘思想得到一種改進的最小二乘多分類孿生支持向量機(Improved multiclass least squares TWSVM,IM AVO MLSTSVM)。
1 相關理論
1.1 孿生支持向量機
假設X1∈Rl1×n和X2∈Rl2×n分別表示n維空間Rn中的兩類樣本,其中X1為+1類樣本,樣本數為l1,X2為-1類樣本,樣本數為l2。TWSVM算法主要是在Rn中尋找到以下兩個非平行的超平面:
XTW1+b1=0和XTW2+b2=0
(1)
式中:W1和W2是兩個超平面的法向量;b1和b2是兩個超平面的偏移量。它們是通過求解下面兩個QPP得出:
(2)
s.t. -(X2W1+e2b1)+ξ≥e2,ξ≥0
(3)
s.t. (X1W2+e1b2)+η≥e2,η≥0
式中:c1和c2是兩個懲罰因子;e1和e2是兩個全為1的向量;ξ∈Rl1和η∈Rl2是兩個松弛變量。最后決策函數式(4)通過計算測試樣本與超平面之間的距離,比較測試樣本與各個超平面的距離,與測試樣本最近的超平面所對應的那一類為該測試樣本所屬類別。
(4)
如圖1所示,對于兩個非平行的超平面,Class1所對應的超平面盡可能與Class1所對應的樣本點近而距離Class2所對應的樣本盡可能遠,同樣Class2所對應的超平面距離Class2對應的樣本盡可能近,而距離Class1的樣本盡可能遠。

圖1 孿生支持向量機
1.2 基于多對一策略的最小二乘多分類孿生支持向量機
TWSVM最初是為了解決二分類問題而提出來的,但現實中大多數問題為多分類問題,這就需要結合TWSVM和多分類的組合策略構成多分類孿生支持向量機來解決多分類問題。
多對一組合策略是構建多分類器方法最常用方法之一,其原理就是將K類樣本中取某一類作為負類,其余K-1類作為正類,構建一個分類器并得到該K-1類樣本的超平面,以此類推最后得到K個超平面。AVO策略在每次訓練時需要所有的訓練樣本參與訓練,這就需要訓練出K個分類器。本文所用算法是基于多對一策略的最小二乘多分類孿生支持向量機(AVO MLSTSVM)[15],該算法在基于AVO策略的MTWSVM的基礎上引入最小二乘思想[16],用等式約束代替原先QPP問題中的不等式約束,極大地降低了算法求解的復雜性。
基于多對一策略的最小二乘多分類孿生支持向量機(AVO MLSTSVM)算法需要求解以下QPP問題:
(5)
s.t. (XiWi+ei1bi)+ξi=ei1
式中:ci為懲罰因子;ei1∈Rli,ei2∈Rl-li是兩個全為1的向量;ξi是松弛變量。式(5)的目標函數的第一項使得超平面盡可能遠離第i類樣本;第二項為松弛變量,用來最小化來自其他樣本點的分類誤差。這樣使得超平面盡可能遠離相應的樣本點,而盡可能接近其他樣本點。求解式(5)一般使用拉格朗日乘子法[17],則其對應的拉格朗日函數為:
αi((XiWi+ei1bi)+ξi-ei1)
(6)
根據Karush-Kuhn-Tucker(KKT)條件,分別對Wi、bi、ξi、αi求其梯度并令其為0:
(7)
(8)

(9)
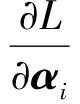
(10)
求解式(7)-式(10)得到分類超平面的法向量Wi和偏移量bi為:
(11)

(12)
最后通過計算測試樣本與各個超平面的距離,比較各個距離的大小,與測試樣本距離最遠的超平面所對應的樣本類別為該測試樣本所屬類。
圖2為AVO MLSTSVM在三類樣本中的分類示意圖,可以看出Plane 1為Class1類樣本所對應的超平面,Plane 1盡可能遠離Class1樣本,并離Class2和Class3樣本近,同理Plane 2和Plane 3與Plane 1一樣都是距離所對應的樣本盡可能遠,而距離其他樣本盡可能近。

圖2 線性AVO MLSTSVM示意圖
2 基于多對一策略的改進的最小二乘多分類孿生支持向量機
結構風險最小化原則是通過最大化各類樣本之間的邊界來實現的。傳統多對一策略的最小二乘多分類孿生支持向量機只考慮了經驗風險的最小化,卻沒有將結構風險最小化原則考慮在內。本文在多對一策略的最小二乘多分類孿生支持向量機的基礎上引入正則項式[13]來實現最小結構風險原則[14]。
本文對基于一對多策略的改進的最小二乘多分類孿生支持向量機從線性情況與非線性情況分析。在待分類的數據中能夠直接找到超平面將待分類的數據分開,稱為該情況為線性可分的,即為線性情況。在待分類的數據中無法直接找到相應的超平面將待分類的數據分開,稱該情況為非線性情況。這種情況往往通過核函數將待分類的數據映射到高維空間,從而可以解決在低維空間無法直接分類的問題。
2.1 線性情況
假設2維空間R有L個樣本,這些訓練樣本可以被分為K類。其中令Xi表示第i類樣本,Yi表示除第i類樣本之外其余的樣本。那么在線性情況下算法所需要解決的最優化問題可以表示為:
(13)
s.t. (XiWi+ei1bi)+ξi=ei1
式中:Wi是第i類樣本的超平面的法向量,bi為偏移量,ci為懲罰因子,ξi為松弛變量,ei1、ei2是兩個全為1的向量,θi為添入的正則項式的權重。
用拉格朗日乘子法求解式(13)得:
(14)
最后得到超平面的參數為:
(15)

(16)
算法1線性情況下改進的基于多對一策略的最小二乘多分類孿生支持向量機(IM AVO MLSTSVM)的步驟如下:
Step1初始化:訓練數據的類數K,Xi為第i類樣本,Yi為其他類樣本,i為第i類樣本的類標。
Step2fori=1:K
(1) 定義兩個矩陣Ai和Bi,其中Hi=[Xiei1],Gi=[Yiei2]。
(2) 選擇合適的懲罰因子ci和正則化參數θi。
(3) 根據式(15)確定第i類樣本所對應的分類超平面的參數,從而確定第i類樣本所對應的超平面。
end
Step3根據式(16)計算測試樣本與超平面的距離,測試樣本與哪個超平面最遠則判斷該樣本屬于哪一類。
2.2 非線性情況
現實情況下大多數需要解決的問題都是非線性的,所使用的算法必須在能解決線性問題的同時也能解決非線性問題。對于非線性的樣本需要使用核函數對樣本進行處理,首先把樣本映射到高維空間中去,然后再利用分類器進行分類。則樣本對應的超平面可以表示為:
Ker(Y,DT)μi+γi=0i=1,2,…,K
(17)
式中:D=[XiYi]T,Ker表示選用的適合的核函數。則改進的基于多對一策略的最小二乘多分類孿生支持向量機(IM AVO MLSTSVM)可以表示為:
(18)
s.t. (Ker(Xi,DT)μi+ei1γi)+ξi=ei1
用拉格朗日乘子法求解式(18):

(19)
求解得到超平面:
(20)

(21)
與線性情況下一樣,通過計算測試樣本與各個超平面的距離,比較各個距離的大小,測試樣本與哪個超平面的距離大,則判定該樣本屬于該超平面所對應的那一類。
非線性情況下改進的基于多對一策略的最小二乘多分類孿生支持向量機(IM AVO MLSTSVM)步驟如下:
Step1初始化:訓練數據的類數K,Xi為第i類樣本,Yi為其他類樣本,i為第i類樣本的類標。
Step2fori=1:K
(1) 定義兩個矩陣Hi和Gi,其中Hi=[Ker(Xi,DT)ei1],Gi=[Ker(Yi,DT)ei2]。
(2) 選擇合適的懲罰因子ci和正則化參數θi。
(3) 根據式(20)確定第i類樣本所對應的分類超平面的參數,從而確定第i類樣本所對應的超平面。
end
Step3根據式(21)計算測試樣本與超平面的距離,測試樣本與哪個超平面最遠則判斷該樣本屬于哪一類。
2.3 復雜度分析

3 實驗與結果分析
本節通過實驗對本文所提出的算法進行驗證。所選用的數據均來自UCI數據庫,所有實驗均用十次交叉驗證。運行環境為4 GB內存,CPU為Intel CORE i3- 4170,3.7 GHz的主頻,Windows 10操作系統。所有實驗室均在MATLAB R2016a環境上實現。實驗所用的數據集具體信息如表1所示。

表1 實驗所用數據集信息
在實驗設置中,本文選取一對多策略多分類支持向量機(OVA SVM),多對一策略最小二乘多分類孿生支持向量機(AVO MLSTSVM)和一對多策略最小二乘多分類孿生支持向量機(OVA MLSTWSVM)作為對比實驗。并且分別對不同算法選用線性核時算法的表現和選用高斯核時算法的表現作出分析,實驗結果均為10次交叉驗證所得到的平均精度。實驗中對比算法都只有一個懲罰參數c和一個核函數參數σ,本文提出的算法包含三個參數,懲罰參數c、核函數參數σ和一個正則化參數θ,懲罰參數和正則化參數均使用網格搜索選取參數,參數均初始化為之間,同時為了減少運算的復雜度,默認高斯核的核參數σ為2。各種算法在不同數據集上的性能如表2和表3所示。

表2 線性情況下各類算法的分類性能對比(%)

表3 非線性情況下各類算法的分類性能對比(%)
由表2可以看出新提出的算法在使用線性核情況下,在數據集glass、wine、thyroid、cmc和ecoli上面表現的結果較其他三個算法是性能更好。由表3可以得出,IM AVO MLSTSVM算法在非線性情況下使用rbf核函數并且核參數默認為2的情況下在數據glass、wine、thyroid、cmc和ecoli上表現較其他三種算法分類性能更好。由此可看出在大多數情況下提出的算法在較其他三種算法在分類性能上是有改進的。
從表4的分類時間上可以看出本文所提出的算法在線性核情況下時與算法AVO MLSTSVM和OVA MLSTSVM相差較小,同時比OVA SVM的分類時間更好。由表5可以看出在非線性核情況下本文所提出的算法與其他三個算法在數據集glass、wine、thyroid和ecoli上分類時間相差不大,在數據集cmc上與算法AVO MLSTSVM和算法OVA MLSTSVM相差不大,同OVA AVM相比較低。綜上所述本文的算法在分類時間上在大多數情況下是有改進的。

表4 線性情況下各類算法的分類時間對比 單位:s

表5 非線性情況下各類算法的分類時間對比 單位:s
本文對比實驗采用十次交叉驗證,最后結果為十次的平均值,圖3-圖8為在線性核情況下數據集wine、cmc和ecoli以及在非線性使用RBF核函數的情況下在數據集glass、thyroid和wine上各算法在十次交叉驗證中的對比情況。由圖3可以看出,本文的算法在線性核情況下在數據集wine上的有著更好的表現,而且總的來說對比其他三種算法都有著更好的表現。由圖6可以看出非線性情況下在數據集glass上本文所提出的算法更優于其他三種算法。另外,由圖4、圖5、圖7和圖8也可以看出與其他三種算法相比本文算法在分類性能上有較好的改進。

圖3 線性情況下各算法在wine上的表現

圖4 線性情況下各算法在cmc上的表現
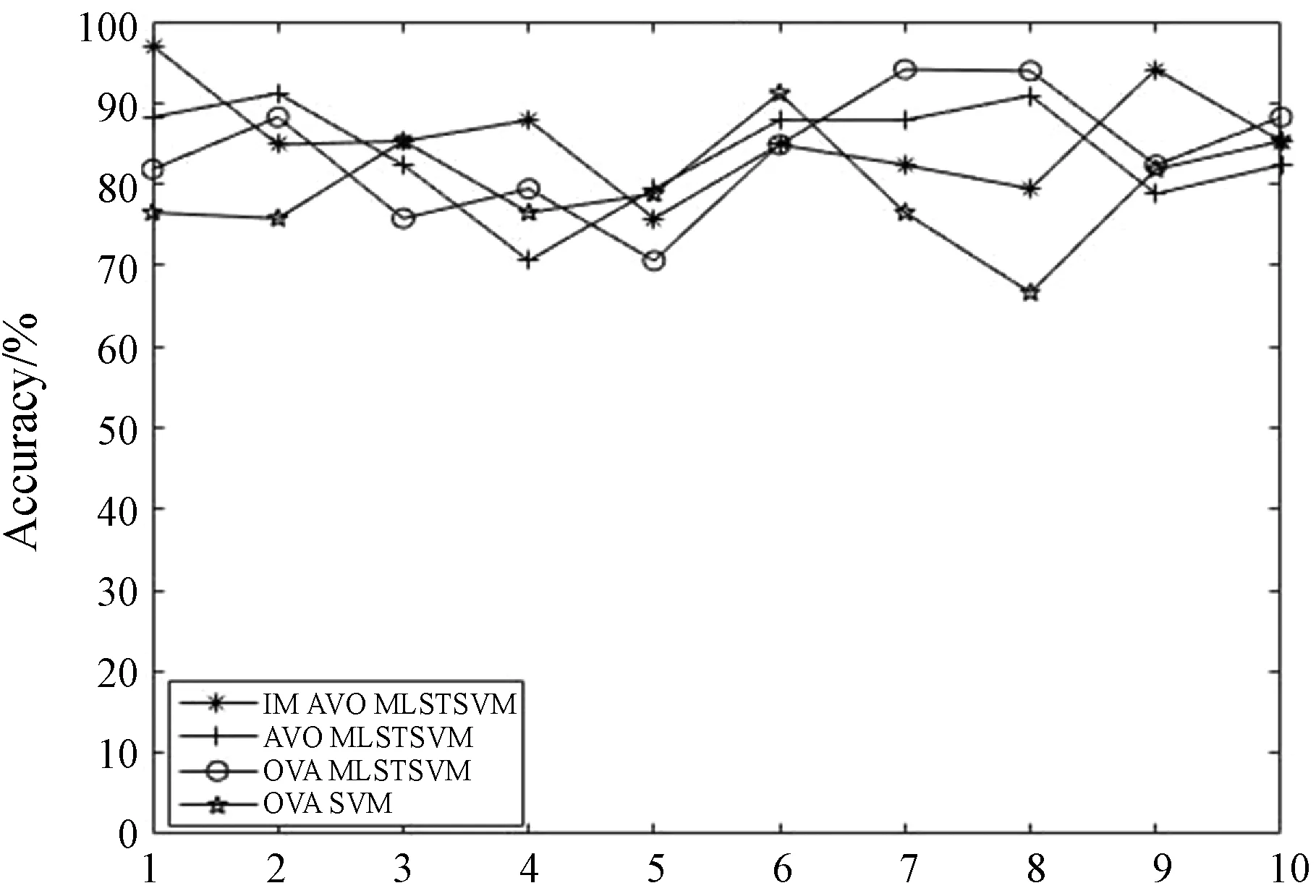
圖5 線性情況下各算法在ecoli上的表現

圖6 非線性情況下各算法在glass上的表現

圖7 非線性情況下各算法在thyroid上的表現

圖8 非線性核情況下各算法在wine上的表現
4 結 語
本文算法是在多對一策略的最小二乘多分類孿生支持向量機的基礎上引入正則項式來實現結構風險最小化原則,從而提高分類器的性能。和AVO MLSTSVM類似,本文算法也是將訓練數據按照多對一的策略劃分。然而AVO MLSTSVM只考慮到算法的經驗風險,卻沒有考慮算法的結構風險。本文提出的算法考慮到算法的經驗風險,而且通過引入正則項式來貫徹結構風險最小化原則,能夠極大地提高分類算法的性能。通過在UCI數據集上的實驗驗證,引入的正則化對提高分類器性能是有效的。另外,在面對數據不平衡時,各類樣本數相差較大時如何提升算法性能,解決數據不平衡問題還需進一步研究。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
數學大世界(2018年1期)2018-04-12 05:39:14
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
