基于遷移學習的癲癇發作預測方法
2022-06-29 06:08:24樊軻
電子設計工程 2022年12期
關鍵詞:癲癇
樊軻
(西安工程大學計算機科學學院,陜西西安 710600)
截止于2020 年,我國有超過了1 000 萬人群遭受癲癇疾病的困擾,而且每一年都會有50~60 萬新增病例[1]。臨床治療中常常使用抗癲癇藥物以抑制患者癲癇發作,但是藥物治療并不適合所有癲癇患者[2]。
腦電圖(Electroencephalogram,EEG)信號具有捕捉癲癇發作信號和決定癲癇發作狀態的能力[3]。腦電圖中蘊含有豐富的生理和疾病信息,臨床醫生通過分析病人的腦電圖不僅可以判斷該病人在某段時間內是否處于癲癇發作時期,還可以迅速而精確的定位到癲癇的致病腦區,可以幫助醫生以手術的方法切除致癇腦區[4]。
相關文獻表明,癲癇發作并不是突然性的,是存在一個時間過程,因此對癲癇發作的預測是可行的[5]。
2018 年,周夢妮等[6]使用非線性動力學中的排列熵提取腦電信號的特征,然后使用支持向量機識別癲癇發作時期的腦電信號,并使用投票機制完成癲癇發作的實時預測。
2020 年,Usman 等[7]提出一種基于深度學習算法中卷積神經網絡的癲癇發作預警系統。該方法已應用于波士頓兒童醫院頭皮腦電圖數據集的24 名受試者,成功地獲得了92.7%和90.8%的平均敏感性和特異性。
2016 年,Zhang[8]等提出了一種預測癲癇發作的具備良好特異性的算法。該算法使用SVM 作為分類器完成腦電信號的識別。由其實驗結果可知,該方法具有很好的準確率以及靈敏度。
然而,由于腦電信號在個體之間差異較大,傳統的機器學習很難適用于處理每一個患者的腦電記錄。而且深度學習自動提取數據特征的前提是數據規模足夠大,因為深度學習方法的學習能力是由可用于訓練和測試的標注數據的數目決定的,所以深度學習算法常常存在一個弊端,即數據不足的問題。
為了解決上述問題,文中使用遷移學習方法完成了癲癇預測。與深度學習方法相比,遷移學習的一個顯著優點是不需要足夠多的標注樣本也可以學習到可靠的分類模型。解決了癲癇信號因人而異的問題,極大地提高了模型處理腦電信號的效率。
1 數據集介紹
文中使用了波士頓兒童醫院(Children Hospital Boston,CHB)[9]公開的數據集。該數據集包含22 名患者的23 組腦電記錄。每組腦電數據包含23 個通道的腦電記錄,采樣頻率為256 Hz。文中使用編號為1~18 的患者的腦電記錄作為實驗數據。每組腦電記錄中至少包含5 次癲癇發作時期的腦電信號。
圖1 對比了癲癇發作間期和癲癇發作時期的腦電信號。

圖1 癲癇發作間期和癲癇發作期腦電信號對比
2 基于遷移學習的癲癇發作預測算法
2.1 數據預處理
為了實現癲癇發作預測,文中將腦電信號分為兩類,即癲癇發作期腦電信號和癲癇發作間期腦電信號。由于癲癇發作時間很短,因此,文中把每次癲癇發作前30 s 的腦電信號也標記為癲癇發作期。
腦電信號采集過程中容易受到干擾,如眼電信號干擾、肌電信號干擾、工頻干擾等。因此,腦電信號處理的第一步通常是數據預處理。數據預處理的作用主要是過濾其他干擾信號,并根據實際情況選擇頻率區間的腦電信號。
文中使用6組不同頻率區間的帶通濾波器對腦電信號作預處理。其頻率區間分別為0.5~4 Hz、4~8 Hz、8~13 Hz、13~30 Hz、30~80 Hz 和80~150 Hz。
2.2 特征提取
為了更好地識別發作期和發作間期的腦電信號,文中使用樣本熵作為分類特征。
樣本熵是通過計算在目標信號序列中生成新碼型的可能性來測量目標時間序列的復雜度[10]。并且其復雜度與生成新碼型的概率成反比。具體而言,樣本熵越小,時間序列越穩定,生成新模式的可能性越小,時間序列的復雜度也越低。相反,樣本熵越大,生成新模型的可能性就越大,時間序列的復雜性和易變性也就越大[11]。
計算N維時間序列x(1),x(2),…,x(N)樣本熵的方法如下:
1)按序號將時間序列組成m維向量,即:
序列:Xm(1),Xm(2),Xm(3),…,Xm(N-m+1)。
2)定義向量Xm(i)和Xm(j)之間的距離D為兩者對應元素差值最大值的絕對值,即:
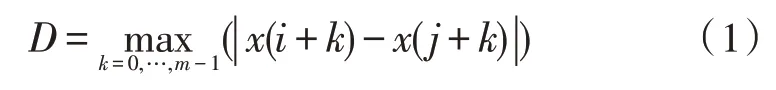
3)對于給定的閾值,統計Xm(i)和Xm(j)之間距離小于或等于閾值的數目,記為Bi,定義:

4)求(r)對所有i值的平均值:

5)將維數增加到m+1,重復步驟2)~4),得到Am(r)。則樣本熵定義為:
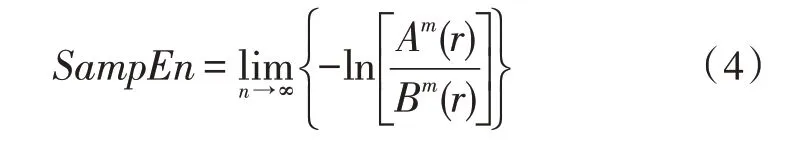
當N為有限值時,樣本熵可估計為:

2.3 遷移學習
腦電信號的一個特點就是因人而異,個體和個體之間差別很大,傳統的機器學習或者深度學習算法不能適用于每一個患者的實際情況。在實際臨床治療中,腦電信號是否處于實際癲癇發作時期都是依賴于臨床醫務人員或者專家的人工標注。而且由于腦電數據采集成本高、信噪比較差,并且每次癲癇發作的持續時間都很短。所以在實際臨床應用中,對每一位患者建立足夠且帶標注的腦電信號數據比較困難。
因此,使用遷移學習處理和分析腦電信號越來越受到國內外研究學者的關注。
源領域和目標領域是遷移學習中的兩個基本概念[12]。通常情況下,目標領域存在的問題是可用于訓練的數據太少或數據標注太困難,而源領域則有足夠數量的訓練數據用于模型學習。因此,為了能在目標領域構建一個效果可靠的分類器,通常需要把在源領域學到的知識應用在目標領域中,這種知識的轉移就是遷移學習[13]。相比于經典的機器學習方法,遷移學習的優點是學習到的分類模型的好壞不再由可利用的訓練樣本來決定;用來學習的源領域的訓練數據與新測試數據的關系也不必屬于獨立且同分布的關系[14]。
文中使用基于模型的遷移學習[15]。實驗中使用VGG19 網絡訓練和測試所選的數據。VGG19 網絡是Oxford 組在AlexNet 的基礎上改進后而得到的[16]。與AlexNet 中卷積核尺寸都比較大不同的是,VGG19網絡中使用的是尺寸小但連續的卷積核。在VGG19中卷積核的大小和最大池化的大小都是固定的。并且相比于AlexNet 中較大的卷積核,VGG19 中連續小卷積核的組合濾波效果更加明顯,這也證明了可以通過一直加深網絡層數來提升網絡的性能。由于腦電信號的特殊性,所以將該網絡中卷積核的尺寸設置為3×1。其結構如圖2 所示。
提升初中歷史課堂教學,應當增加學生對歷史學習的興趣,將學生的感情與歷史聯系在一起。巧妙設計課前導學,激起學生探索歷史的興趣,利用情境創設引導學生講感情帶入學習之中,同時通過多媒體使學生更加直觀地了解歷史,拓寬自己的歷史知識。使學生在輕松自主的課堂氛圍中掌握知識點,將被動學習變成主動記憶,促進學生歷史學習體系的建立。我希望通過本次的研究,可以為一線歷史教師提供一些幫助,有助于營造師生互動、自主探究的歷史課堂學習氛圍,提高歷史課堂教學效率,培養學生的綜合素質。

圖2 1維卷積神經網絡結構圖
2.4 癲癇發作預測模型
在經過VGG19 網絡分類之后,需要用6 min 的非重疊時間窗來統計這段時間內發作期信號的數量,以識別其是發作期還是發作間期。
具體做法:在經過VGG19 網絡分類后,得到測試數據集的標簽,根據每一個病人的實際情況設置一個閾值,如果該段時間內發作期信號大于該閾值,則判定該段時間處于發作期,反之則認為該段時間處于發作間期。
假設該病人實際癲癇發作時間點為T1,而模型預測病人癲癇發作的時間點為T2,則發作預測時間T的計算公式為:

2.5 癲癇發作預測算法
基于遷移學習的癲癇發作預測算法的具體步驟為:
1)為了解決因實驗數據維度太多而造成算法時間復雜度過高的問題,使用PCA 方法將原始23 導聯的腦電數據降維至3 導聯數據;
2)為了濾除其他干擾信號數據,便于分析研究不同頻率波段的腦電信號,使用6 組不同頻率波段的ButterWorth 帶通濾波器對降維處理之后的腦電信號數據進行分段處理;
3)為了避免多維度特征造成時間復雜度太高,而使用樣本熵作為唯一的分類特征;
4)使用遷移學習得到的VGG19 網絡學習預先劃分好的訓練數據集中的知識,并在測試數據集中進行驗證;
5)統計規定時間段內處于癲癇發作時期的腦電信號數量,并將其與預先設置的閾值進行比較。如果該段時間內處于發作時期的腦電信號大于閾值,則判定該段時間處于發作期,反之則認為該段時間處于發作間期。
3 實驗結果與分析
文中使用Matlab 的2020a 作為實驗平臺,運行環境為單GPU。實驗中為了VGG19 網絡具有更好的學習能力,將數據集的80%作為訓練數據,20%作為測試數據,最大迭代次數為525 次。
3.1 評價指標
為了更好地評估算法的預測能力,文中使用發作預測時間和誤報率作為算法的評價指標。
1)發作預測時間
發作預測時間是指從模型預測病人癲癇發作的時間點到病人實際癲癇發作的時間點。
2)誤報率
如果一個時間窗內的發作期信號超過預先設定的閾值,則認為該段時間處于癲癇發作期。如果該時間段處于病人實際發作之前,則判定這次預測為正確預測,如果該時間段處于病人實際發作期內或實際發作之后,則判定這次預測為誤報。
3.2 實驗結果
表1 給出了18 個參與實驗患者的評估結果。
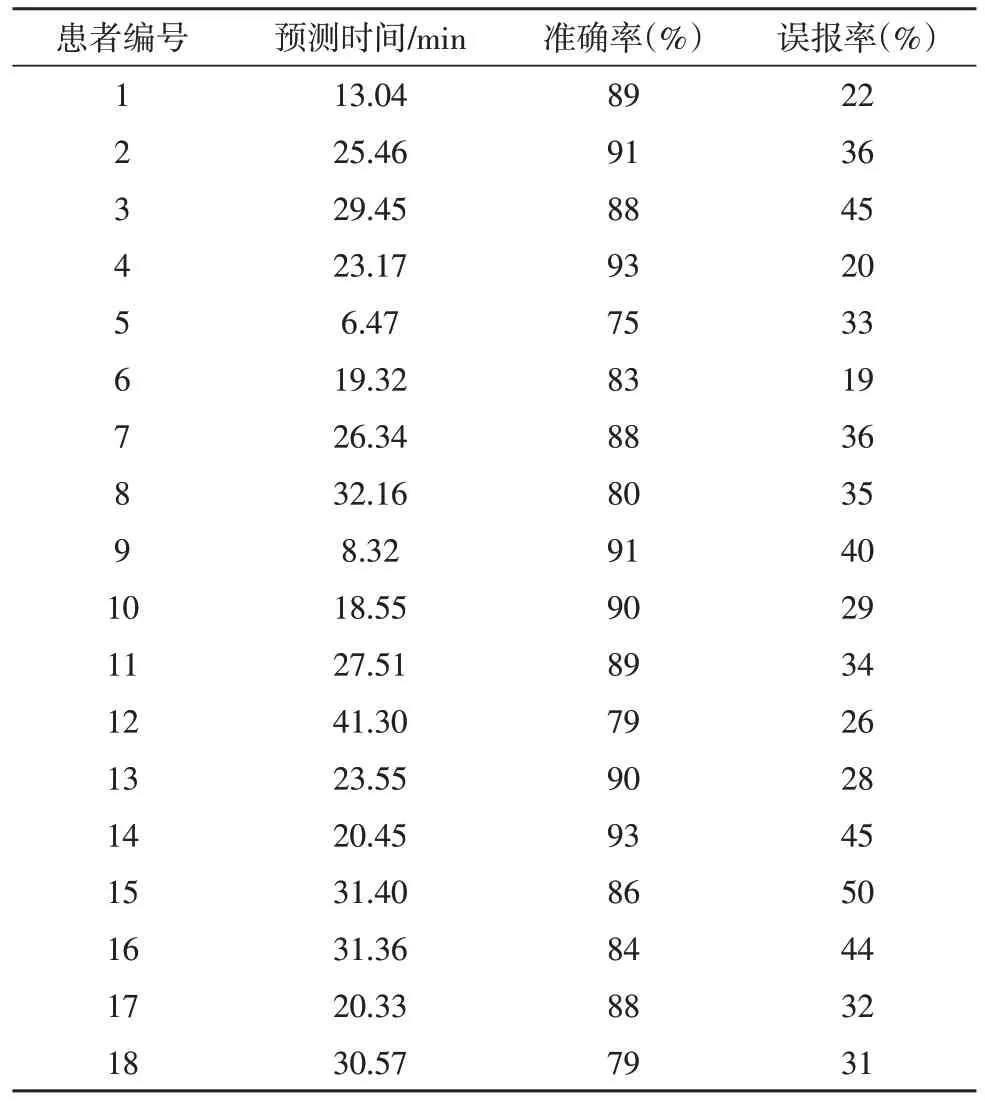
表1 18個參與實驗患者的評估結果
從表1 可以看出,所有患者中最長的預測時間達到41.30 min(12號患者),最短的預測時間為6.47 min(5 號患者)。所有患者的平均預測時間為23.82 min。所有患者中最高的預測準確率為93%,最低的預測準確率為75%,而所有患者的平均預測準確率為86.4%。所有患者中最高誤報率為50%(15 號病人),最低誤報率為19%(6 號病人),而平均誤報率為34%。
4 結論
文中提出一種基于遷移學習的癲癇發作預測方法,具體做法是以18 例癲癇患者的腦電信號記錄作為實驗數據,根據巴特沃斯帶通濾波器將原始數據劃分為6 組不同頻率區間的數據,用樣本熵作為分類特征。最后使用遷移學習后的VGG19 網絡作為分類器來識別發作期的癲癇腦電信號。該方法的最長預測時間為41.30 min,平均預測時間為23.82 min。最高預測準確率為93%,平均預測準確率為86.4%。最低誤報率為19%,平均誤報率為34%。實驗結果表明,該方法可很好地用于癲癇發作的預測。
文中方法的不足之處:使用單一特征提取方法不足以反映腦電信號的特點,導致發作預測準確率較低。為了解決這一問題,建議使用更多的特征提取方法。然而,在臨床治療中,預測的實時性是必須關注的問題。因此,如何解決特征提取維度和實時性預測是后期要解決的問題。
猜你喜歡
中國民間療法(2021年5期)2021-06-09 09:21:04
中華養生保健(2020年2期)2020-11-16 00:49:00
解放軍醫學院學報(2020年12期)2020-03-29 05:11:46
中成藥(2017年6期)2017-06-13 07:30:35
飲食科學(2017年5期)2017-05-20 17:11:53
臨床醫藥文獻雜志(電子版)(2017年11期)2017-05-17 04:48:10
安徽醫科大學學報(2015年9期)2015-12-16 11:09:44
中國當代醫藥(2015年7期)2015-03-01 02:01:13
西南軍醫(2015年4期)2015-01-23 01:19:30
西部中醫藥(2014年6期)2014-03-11 16:07:47
