基于DPRI的單行為強化聚類算法
2022-06-29 06:08:26張龍李鳳蓮張雪英史凱岳
電子設計工程 2022年12期
張龍,李鳳蓮,張雪英,史凱岳
(太原理工大學信息與計算機學院,山西榆次 030600)
K-means 算法是一種簡單高效易于實現的基于劃分的聚類算法,該算法的計算復雜度接近線性,但初始聚類中心的選擇和樣本的劃分方式均會對聚類性能產生較大的影響[1],因此,一些改進算法相繼被提出。K-means++算法使用最大最小距離法選取初始聚類中心,盡可能選取相對距離較遠的樣本作為初始聚類中心,一定程度上減小了隨機選取初始聚類中心對聚類性能的影響[2]。文獻[3]將K-means 與關系對稱矩陣和社會網絡分析中的度中心性相結合,并對K-means 算法初始聚類中心的選擇進行了優化,提高了聚類算法的性能。文獻[4]提出基于特征關聯度的K-means 初始聚類中心優化算法,可得到更優的聚類結果。上述改進主要是針對初始聚類中心選取開展的研究,對聚類算法樣本劃分方式未進行改進。
模糊聚類[5](Fuzzy C-Means,FCM)算法將樣本的硬劃分轉化為一種柔性的模糊劃分,以此更科學地度量樣本相似度。文獻[6]在FCM基礎上,提出了一種密度加權FCM 算法,文獻[7]提出了基于迭代信息熵權的改進LFCM 聚類算法。上述FCM 及其改進算法主要以樣本的劃分方式為切入點進行改進,提高了聚類性能,但處理中規模和大規模數據時的復雜度較高。
近年來,隨著強化學習在AlphaGo上的成功應用,將強化學習和聚類算法相結合也成為一個新的研究方向。學習自動機[8]作為一種強化學習算法,使用該算法對聚類算法進行改進是近年來的一個熱點。文獻[9]提出了學習自動機聚類算法(Learning Automata Clustering,LAC)。受該文獻啟發,文中提出了一種基于DPRI(Discretized Pursuit Reward Inaction)的單行為強化聚類算法,在聚類過程中引入DPRI算法中的離散更新技術,去除了算法中智能體(Agent)行為概率之和必須為1 的約束,把行為概率轉換為累積獎勵,并引入ε貪婪策略,提升了Agent 選擇行為的速度,有效降低了時間復雜度。
1 基礎理論
1.1 強化學習
強化學習[10](Reinforcement Learning,RL)又稱增強學習,通過模擬人類學習過程中的“探索”和“利用”機制,把待分析問題抽象為馬爾科夫決策過程[11](Markov Decision Process,MDP)。該過程中,如果Agent 的某個行為得到系統的正向反饋,那么Agent選擇該行為的趨勢就會增大;如果Agent 所選行為得到系統的負向反饋,那么Agent 選擇該行為的趨勢就會下降。強化學習的目的就是在學習過程中使得到的獎勵最大化。
1.2 馬爾科夫決策過程
馬爾科夫決策過程(MDP)是一個四元組<S,A,T,R>。其中,S={s1,s2,…,sn}表示包含該過程中所有狀態的有限集合;A={a1,a2,…,aK}表示一個有限的行為集合,其中K≥2;T=p{si+1|si,ai}是一組狀態轉移函數,表征了Agent 在狀態si下,選擇行為ai后轉換到狀態si+1的過程;R={r1,r2,…,rT},ri=r(si,ai,si+1)表示關于當前狀態、行為和下一個狀態的標量函數,即Agent 在狀態si下選擇行為ai轉移到狀態si+1后環境給予的獎勵。MDP 狀態轉移過程如圖1 所示。

圖1 MDP狀態轉移過程
1.3 離散學習自動機DPRI算法
DPRI算法是強化學習中的一種經典離散學習自動機算法,算法將估計器技術和離散化技術進行了結合[12]。該算法的整體特點是行為選擇概率向量的更新取決于環境的反饋和歷史經驗。算法引入了行為被選擇的次數Zi和被獎勵的次數Wi,通過求解獎勵概率的估計值,追溯獎勵概率值最大的行為;行為的累積獎勵在區間[0,1]上是跳步更新的,變化量用表示,其中r表示行為的個數,N表示行為概率的更新分辨率。若概率更新后大于1 則強制為1,若更新后的概率值小于0,則強制為0。文中結合強化學習算法的特點,并融合DPRI算法中離散化獎勵更新技術,提出了一種基于DPRI的單行為強化聚類算法(Single Behaviour Reinforcement Clustering algorithm based on DPRI,SBRC)。
1.4 ε 貪婪策略
貪婪策略[13]是強化學習中對貪心算法的別稱,使用貪婪策略求解問題時,每個階段達到局部最優解,以實現最終全局最優的目的[14]。文中使用貪婪策略選擇行為具體是指,當Agent 選擇行為時,選取Q表中累積獎勵值最大的行為。ε貪婪策略(0 ≤ε≤1)是基于概率對強化學習任務中的“探索”和“利用”相結合的方法,Agent 每次選擇行為時,以ε的概率對Q表進行“利用”,即選擇累積獎勵值最大的行為,以1-ε的概率進行“探索”,即在行為集中隨機選擇一個行為。依據3.2 節的實驗結果,SBRC 算法中ε取值為0.9。
2 算法實現
文中提出的SBRC算法將ε貪婪策略和DPRI算法的離散化獎勵更新技術與聚類算法相結合,把聚類任務轉化為強化學習任務。算法初始化時,建立一個大小為N×K的Q表,其中N表示輸入樣本的數量,對應N個Agent,K表示Agent 可選擇的行為數量,對應聚類任務中的聚類數目,Q表中的每一行數據與一個Agent 相關聯,算法在迭代過程中不斷更新Q表直至趨于穩定。停止迭代時,每個Agent 最大累積獎勵所對應的類簇即為該樣本的所屬類簇。
2.1 強化信號的構建
強化學習中強化信號是環境給與Agent 的反饋信號[15]。傳統的K-means 等聚類算法根據聚類中心的變化是否小于給定的閾值作為算法停止迭代的條件,但聚類中心只能反映該類簇在樣本空間的位置,無法對類簇中樣本的聚集程度進行描述。平均類內距離反映了類簇中樣本的聚集程度,若一次迭代結束后平均類內距離增大,則說明該類簇中的樣本更加分散,反之則更加緊密。因此,SBRC 算法使用平均類內距離變化趨勢作為發送強化信號的依據,平均類內距離的計算方法如式(1)所示:

式(1)中,Adis(cj)表示第j個類簇的平均類內距離,|cj|表示第j個類簇中樣本的數量,M表示樣本的屬性個數,xim表示第i個樣本的第m個屬性,cjm表示第j個聚類中心的第m個屬性,其中1≤m≤M。
2.2 Q表的構建
SBRC 算法運行前建立大小為N×K的Q表,如表1 所示,其中rik表示第i個Agent 行為k的累計獎勵。該算法無需滿足條件,1 ≤i≤N,即去除了Agent 累積獎勵和為1 的約束。Q表在算法迭代過程中不斷更新,最終達到穩定狀態。

表1 輸入樣本所對應的Q表
2.3 Q表的更新過程
SBRC 算法運行過程中,Agent 根據ε貪婪策略選擇行為。每次迭代結束后,計算各類簇的平均類內距離,并與該類簇上一次得到的平均類內距離比較。如果距離減小,則表明此次迭代選擇該行為的所有Agent 組成的類簇更加緊密,該類簇中所有Agent 會得到一個獎勵信號,使得該行為的累積獎勵值增大,反之使得該行為的累積獎勵值減小,Q表的更新過程如圖2 所示。算法迭代過程中,每個Agent有ε的概率去選擇最大累積獎勵值所對應的行為,有1-ε的概率在行為集中隨機選擇一個行為,圖2中假設了聚類數K=3 的情況。該更新過程是針對一個Agent 而言的,圖中與聚類數對應的行為數為3,分別代表3 個類簇。狀態Siter表示該Agent 正處于第iter次迭代,Q1、Q2、Q3分別表示3 種行為的累積獎勵,Adis(iter)表示該Agent 所在類簇第iter次迭代結束后的平均類內距離。Q1↑表示行為1 的累積獎勵增大,Q1↓表示行為1 的累積獎勵值減小,Q1_ 表示行為1 的累積獎勵值不變。算法中設置累積獎勵上下限分別為1 和-1,如果更新后的累積獎勵值大于1或者小于-1,則將其強制為1 或-1。累積獎勵的更新方法如式(2)和式(3)所示:

圖2 SBRC算法Q表更新過程
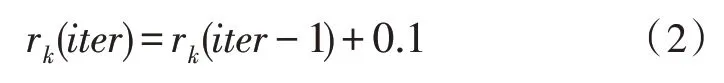
式(2)表示Agent 選擇了行為k后,相較于上次迭代,平均類內距離減小時累積獎勵的更新方式。行為k的累積獎勵增大,其余行為的累積獎勵不變。

式(3)表示Agent 選擇了行為k后,相較于上次迭代,平均類內距離增大時的累積獎勵的更新方式。此時行為k的累積獎勵減小,其余行為的累積獎勵不變。
2.4 算法初始化及偽代碼
算法運行前需要輸入參數,并對相關變量進行初始化:輸入聚類數K,最大迭代數為maxiter,平均類內距離變化閾值為stop;創建大小為N×1 的行為向量,用于存儲Agent 選擇的行為,初值設置為0;創建大小為N×K的Q表,用于存儲累積獎勵,初始值設為0;創建大小為N×1 的強化信號向量,用于存儲環境反饋的信號,初始值設為0;創建大小為2×K的向量,用于存放平均類內距離,初始值為0。SBRC 算法的偽代碼如下:


SBRC 算法第一次迭代時,所有Agent 隨機選擇一個行為,計算各個類簇的平均類內距離。從第二次迭代開始,每個Agent 依據ε貪婪策略選擇行為,并計算新的平均類內距離,與上一次迭代得到的平均類內距離作比較。若距離減小,則給予該類簇中所有Agent 獎勵信號,否則給予懲罰信號,每個Agent根據收到的信號類型更新Q表,當平均類內距離的變化小于閾值stop或達到最大迭代次數maxiter,則停止迭代并輸出聚類結果。
3 實驗及結果分析
3.1 實驗數據及評價指標
實驗采用準確率、DB 指數以及輪廓系數對聚類性能進行評價。準確率的計算方法如式(4)所示:
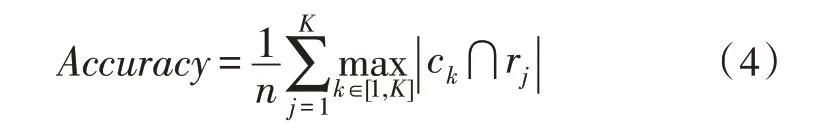
式(4)中,n表示樣本的數量,ck表示Q表中樣本標簽為k的所有樣本集合,rj表示真實標簽為j的樣本集合。表示兩者交集中樣本的數量。
Davies-Bouldin(DB)指數[16]是聚類算法的一種內部評價指標,該值越小表明聚類效果越好,計算方法如式(5)所示:

式(5)中,K為聚類數目,Adisi為類簇Ci的平均類內距離,Cij為類簇Ci和類簇Cj聚類中心之間的距離。
輪廓系數結合了內聚度和分散度兩種因素[17],可以對同一數據集在不同算法中的聚類結果進行評價。輪廓系數的計算方法如式(6)所示:
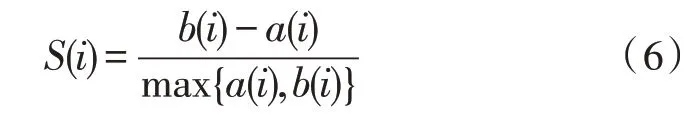
式(6)中,a(i)為第i個樣本與它所屬類簇中其他樣本的距離均值,b(i)為第i個樣本到與之距離最近的另一個類簇中所有樣本的距離均值。輪廓系數介于-1 和1 之間,且越接近1,該點的內聚度與分散度越好。
實驗數據及Q表初始化值如表2 所示。其中D1~D7 為小規模數據集,D8~D10 為中規模和大規模數據集。

表2 數據集信息及Q表初始化值
3.2 貪婪系數的選取
文中以iris 數據集為例說明貪婪系數的選取過程。使用不同的貪婪系數進行SBRC 聚類,分別取值0.5、0.6、0.7、0.8 和0.9,選取同一樣本觀察不同貪婪系數下最大累積獎勵的收斂情況,實驗結果如圖3 所示。由圖3 可知,貪婪系數為0.5 時Q值的收斂速度最慢,為0.9 時收斂速度最快,對其他數據集進行分析可得到相同結論,因此,將貪婪系數設置為0.9。

圖3 貪婪系數對算法收斂性能的影響
3.3 實驗結果及分析
為說明SBRC 算法的有效性,文中選用經典聚類算法K-means(簡稱KM)、K-means++(簡稱KM++)、FCM 以及文獻[9]提出的LAC 算法作對比,進行聚類性能分析。
圖4給出了5種算法平均準確率的對比情況。由圖4 可知,相比于其他3 種聚類算法,LAC 和SBRC 算法結果整體最優。10個數據集中有6個數據集SBRC算法的準確率最高,其中D3、D6、D8 數據集的準確率相比于LAC 算法分別提高了1.8%、3.8%和2.6%。

圖4 SBRC算法準確率對比結果
圖5 給出了5 種聚類算法DB 指數的對比情況。由圖5 可知,相對于3 種經典聚類算法,LAC 和SBRC算法結果整體依然較優,且SBRC 算法稍優于LAC。10 個數據集中有6 個數據集SBRC 算法的DB 指數均最優,其余數據集結果也接近最優,這表明SBRC 聚類算法具有較好的類內緊湊度和類間分散度[18]。
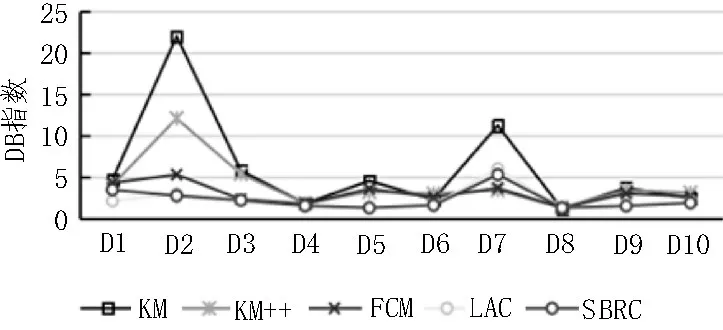
圖5 SBRC算法DB指數對比結果
圖6 給出了5 種算法輪廓系數的對比情況。由圖6 可知,10 個數據集中有5 個數據集SBRC 算法的輪廓系數最高,其中D5、D6、D8 和D10 數據集相比于LAC 算法分別提高了0.018、0.053、0.068 以及0.048。
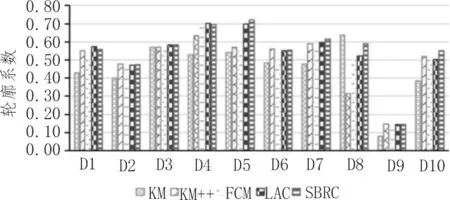
圖6 SBRC算法輪廓系數對比結果
表3 給出了5 種聚類算法運行時間的對比情況。由表3 可知,7 個小規模數據集中,4 個數據集SBRC算法運行時間最短。3 個中規模和大規模數據集相較于其他幾種對比算法,LAC 和SBRC 算法的運行時間至少降低了一個數量級,SBRC 算法比LAC 算法降低效果顯著。其原因一方面與強化學習的行為選擇機制有關;另一方面,由于SBRC 算法采用了單行為獎勵方式,其他未選擇行為的累計獎勵不需要更新,所以相對于LAC 算法,SBRC 算法時間復雜度更低。

表3 SBRC與已有聚類算法運行時間對比情況
綜上可知,與3 種經典算法相比,LAC 和SBRC算法在準確率、內聚度和分散度方面,皆具有更優的聚類性能。在算法運行復雜度方面,SBRC 算法使用的單行為獎勵更新機制使之具有更低的時間復雜度;對大規模數據集而言,SBRC 算法則具有更強的時間優勢。
3.4 實驗過程分析
為說明SBRC 算法有效性,對算法迭代過程中單個Agent 累積獎勵進行跟蹤,說明Q表的更新及收斂情況。圖7 給出了iris 數據集中單個樣本Q值的更新及收斂情況。其中,圖7(a)、(b)、(c)分別取自3 個不同標簽中的樣本,圖中a1、a2及a3分別表示行為1、行為2 和行為3。通過分析可知,圖7(a)和圖7(c)的收斂速度較快,但是圖7(b)中的Q值在算法運行前期經歷了一段時間的震蕩,這是由強化學習本身“探索”和“利用”的特性以及樣本本身的分布情況造成的。

圖7 iris數據集每類中單個樣本Q值更新及收斂情況
4 結論
針對聚類結果對初始聚類中較為敏感的缺陷以及樣本的劃分方式對聚類性能的影響,文中提出了一種基于DPRI算法的SBRC 聚類算法。實驗結果表明,相比3 種經典聚類算法,文中提出的SBRC 算法及LAC 算法在大多數數據集上具有更高的準確率、更優的DB 指數以及更高的輪廓系數,說明了兩種基于強化學習聚類算法的有效性。時間復雜度方面,相比于LAC 算法,SBRC 算法處理各種規模的數據集時,都具有較大優勢,這對下一步繼續采用SBRC 算法分析大規模數據集,提供了前期研究基礎。但是,SBRC 算法通過建立Q表存儲各行為的累積獎勵,是一種用空間換時間的做法,下一步就如何減小算法的空間復雜度方面進行研究。
