基于TextCNN 的政策文本分類
2022-06-29 06:08:26李悅,湯鯤
電子設計工程 2022年12期
李 悅,湯 鯤
(1.武漢郵電科學研究院,湖北武漢 430070;2.南京烽火天地通信科技有限公司,江蘇 南京 210019)
在當今的大數據時代,政府進行宏觀決策時,常常需要參考各地市出臺的政策文件,然而現在各地市的政策文件分布雜亂,且類別不統一,目前市面上也并沒有把各地市的政策全部綜合起來的政策文本類數據集,而此類數據集為政府在宏觀決策時提供參考,基于此,文中構建了一個大型綜合的全國各地市政策文本類數據集。其次,針對政策文本分類,目前市面上大都只進行了單標簽分類,而單標簽分類顯然并不適用于政策文本的分類,用一個標簽來概括整篇文本太籠統,因此,文中對政策文本數據集進行多標簽分類。此外,在政策文本分類中,當前普遍的思路是采用TF-IDF+SVM 分類算法[1]來構建分類模型,或者使用BERT 進行分類[2],效果都不佳。文中經過實驗驗證了采用神經網絡TextCNN 更適合進行政策類長文本的多標簽分類。
1 TextCNN原理介紹
TextCNN 模型可以并行處理,且自帶n-gram 屬性,訓練速度和預測精度都比較理想,是一種非常優秀的文本分類模型[3]。對于500 字以上長度的長文本,即使是LSTM 在這么長的序列長度上也難免梯度消失,而CNN 就不存在該問題,TextCNN 不僅適合處理短文本,同樣也適合處理長文本,該文待處理的政策文本即為長文本。下面介紹了TextCNN 模型的原理。
1)Word Embedding
如圖1 所示,在TextCNN 中,首先將“這個青團不錯,你嘗嘗”分詞成“這個/青團/不錯/,/你/嘗嘗”,通過Embedding 將每個詞映射成一個5 維詞向量(維度可任意)[4-5]。

圖1 Word Embedding
這步主要是為了將自然語言數值化,從而方便后續的處理。可以看出,映射方式不同,最后結果不同。構建完詞向量后,將所有的詞向量拼接成一個6×5 的二維矩陣,將其作為最初的輸入。
2)Convolution 卷積
這一步驟是將輸入詞向量矩陣與卷積核進行卷積運算操作,將“這個”/“青團”/“不錯”/“,”4 個詞語構成的矩陣與卷積核分別對應相乘再相加,可得到最終的Feature Map,這個步驟即為卷積[6],具體操作如圖2 所示。卷積操作后,輸入的6×5 的詞向量矩陣就被映射成了一個3×1 的矩陣,即Feature Map。

圖2 卷積
3)Pooling 池化
在得到Feature Map=[1,1,2]后,從中選取最大值‘2’作為輸出,便是max-pooling[7]。如果選擇平均池化(mean-pooling)[8],就是求平均值作為輸出。由此,最大池化在保持主要特征的情況下,極大地減少了參數的數目,加速了運算,并降低了Feature Map的維度,同時,也降低了過擬合的風險。

圖3 max-pooling
4)使用Softmax k 分類
接下來是將max-pooling的結果合并到一起,再送入Softmax 中,可以得到各個類別[9],如label 為1 和-1的概率,如圖4 所示。

圖4 Softmax
在做模型預測時,使用TextCNN,此時要根據預測標簽以及實際標簽來計算損失函數,分別計算出卷積核、max-pooling、Softmax 函數、激活函數,這4 個函數中的各個參數需要更新的梯度,再依次更新這些參數,即可完成一輪訓練。
2 數據集的構建
由于該文研究任務的特殊性,沒有現成的語料可以使用,所以需要構建相應的語料庫。其數據集來源于全國各個地市的政府政策公告文本信息的爬蟲爬取,然后再對爬取的結果利用正則以及結合人工清洗的方式進行數據的清洗,構建數據庫,將爬取并清洗后的數據入庫,構建政府政策文本語料庫。
2.1 爬取數據及數據處理
文中所采用的數據均為網絡爬蟲所得,先挑選出幾個所需字段,再對各個地市政府官網公開的政策文本數據分別進行采集,經過簡單清洗后整理入庫。
為了豐富數據庫的數據內容,文中挑選的字段涵蓋了標題、文本、適用對象、原文鏈接等。全部字段有:title 標題、themeList 主題、styleName文體、levelName 層級、dispatchList_commonName 發文單位、targetList 適用對象、original_url 原文鏈接、publishTime 發文時間、industryList 適用行業、scaleList 適用規模、qx_content 內容、classify_tag_list分類標簽。
共爬取數據100 000 條,經去重、去空,以及刪除過短文本后數據量為96 640 條。對數據進行如下操作:
1)增加標簽、篩掉無關類別的數據(和分類沒關系的字段)。
2)繁簡轉換、清洗無意義字符。
3)人工打標,主要是對“其他”這個類別的數據進行打標。
4)構建訓練集和測試集,按照6∶2∶2 進行劃分。
2.2 數據集的介紹
2.2.1 類別的構建
由于爬取的數據集中,內容的類別雜亂不統一,不利于后續進一步利用該數據集,因此,對自建數據集中的“qx_content 內容”字段進行文本分類操作。
在類別的設定上,首先參考了國務院政策信息網的類別設定;另外,文中對數據集進行TF-IDF+LDA 聚類[10],通過聚類得到了一些政策重點詞,針對這些政策重點詞,進行類別的設定。最終,共擬定了47 種類別。全部類別為:產業發展、營商環境、政務公開、學校教育、人才引進和能力培育、創新研發、復工復產、資質認定、稅收優惠、節能環保、信息化建設、轉型升級、互聯網+、市場拓展、工程報建、企業創辦、穩企穩崗、醫療健康、金融財稅、平臺基地建設、知識產權、電子政務、成果轉化、數字政府、不動產登記、科研課題、融資幫扶、三農發展、租金減免、孵化器及基地建設、市場監管、疫情扶持、緩繳社保、大數據、水電氣減免、招商引資、法律法規、數字經濟、電子商務、品牌建設、數據治理、智慧城市、改制上市、并購重組、一帶一路、區塊鏈、其他。
2.2.2 數據集示例
針對上文中的自建數據集,想要實現對每條數據進行清洗、分詞后,對該條數據打上相應分類標簽的目的。樣本和標簽的情況如下:
樣本是政策的文本內容,標簽是政策文本涉及到的類別,而每條政策涉及到的類別可能為多個,所以需要進行政策文本的多標簽分類。所以訓練模型的目的,是希望輸入政策文本數據,輸出該政策涉及到的類別。數據集示例如圖5 所示。

圖5 數據集示例圖
3 TextCNN模型的構建
3.1 搭建TextCNN模型
1)定義Embedding 層
加載預訓練詞向量,在自定義Embedding 層時,將把詞向量矩陣加入其中。采用這種方法,可使詞向量矩陣在模型初始化時就加載好了。可以選擇詞向量在訓練過程中凍結還是微調。如果選擇微調,即freeze=False,能夠一定程度上提升效果,盡管訓練速度會變慢[11]。
2)定義卷積層和池化層
如果卷積層的層數太淺,會無法捕捉長距離的語義信息,從而不足以提取文本的特征,但是如果卷積層數太深,就會陷入梯度消失的境地[12]。為了便于提取長文本中的句子特征,文中增加了卷積層數、更改了池化方式。
采用的池化為1/2 池化,在卷積之后,每經過一個大小為3,步長為2 的池化層,序列的長度就被壓縮成了原來的一半。即同樣是size=3 的卷積核,每經過一個1/2 池化層后,其能感知到的文本片段就比之前長了一倍,解決了原TextCNN 模型中無法捕獲長距離語義信息的問題。
3)全連接層
該文對模型在全連接層處也進行了修改,TextCNN 的原論文中,網絡結構只有一個全連接層作為輸出層,且無激活函數。它是把卷積池化的結果拼接,然后進行dropout 操作,再接輸出層。而該文在輸出層之前,又加了一個全連接層(激活函數為ReLU),將卷積池化的結果拼接,進行dropout,加全連接層,再接上輸出層。這樣做的原因主要是網絡加深后,便于提取更豐富的特征。而且如果輸出的類別較少,那么輸出的維度劇烈降維的情況下,如直接從幾百維降到幾維,可能對分類的效果產生不好的影響。因此需要加一個全連接層來過渡。
4)輸出層
輸出層是線性層,不需要使用激活函數。后面的loss 函數,將sigmoid 和計算binary loss 兩步同時進行,這樣計算更有效率,也更穩定,故不必加sigmoid函數得到概率。
文中經改進后的TextCNN 模型與原TextCNN 模型相比,有如下優勢:
基于傳統的TextCNN 模型,為了解決模型中無法捕捉長距離語義信息的缺點,該文加深了卷積深度,同時提出了等長卷積和1/2 池化方式,使得卷積范圍增加。
另外,增加一個全連接層作為過渡,防止在輸出維度劇烈降維情況下,對分類效果產生的不利影響。
3.2 多標簽分類的評估函數
該文選擇采用海明損失[13](Hamming loss)和F1值[14](宏平均和微平均)作為主要指標來評估模型的性能。關于宏平均和微平均:如果每個class 的樣本數量相差不大,那么宏平均和微平均差異也不大。如果每個class 的樣本數量相差較大并且想更注重樣本量多的class,就使用微平均;更注重樣本量少的class,就使用宏平均。如果微平均遠低于宏平均,則應該去檢查樣本量多的class。如果宏平均遠低于微平均,則應該去檢查樣本量少的class[15]。這里可直接用sklearn 函數來計算。對于每一個預測樣本,需要47 個類別的每一個類別都預測正確,才能算該樣本預測正確,其難度太大,并不適合用于評價模型的效果,該文需要分類的共有47 個類別,如果部分類別可以預測正確的話,模型也是可以用的。在模型的訓練過程中,如果監控到驗證集上的F1 值有提升,那么會在測試集上做一次評估,同時保存模型。
多標簽分類的損失函數不再是多分類的crossentropy loss,而是binary cross-entropy loss。具體實現的函數為:criterion=nn.BCEWithLogitsLoss (pos_weight=config.class_weights)[16]
該函數將模型的輸出做sigmoid,然后計算損失。pos_weights 這個關鍵字參數,用于傳入類別的權重,引入該參數緩解類別不平衡的問題,這里只在訓練時傳入,驗證和測試時不用。
4 實驗結果及對比分析
4.1 配置環境及實驗參數
1)實驗環境
該實驗的運行環境為:tensorflow-gpu=1.12.0、keras=2.2.4、python3.6、Scikit-learn=0.21.3、Torch=1.1.0。
2)實驗參數
在config 類中,配置好相關的參數,如文件路徑、模型的各個參數等。其他一些需要通過計算得到的模型參數,在數據處理過程中添加,如輸入的最大長度、類別數、詞表的尺寸等。該文設置的部分參數如下:
①batch size=128;
②學習率=1e-3;
③百度百科詞向量維度=300;
④卷積核尺寸=[2,3,4,5];
⑤卷積核數量=128;
4.2 文本預處理
首先數值化樣本及標簽,在配置參數初始化后,依次完成文本的清洗和分詞,確定輸入的最大長度,對樣本進行zero pad,轉化為id,對標簽進行數值化,以及構建詞表等操作。數值化后的標簽每一位是0或1,類別數是列數,標簽的類別數為47,也就是TextCNN 的輸出維度為47。在數值化樣本及標簽后,加載百度百科詞向量。針對類別不平衡問題,該文的數據集多標簽類別有47 個,經過統計分析,每個類別之間數量差別巨大,存在比較嚴重的類別不平衡問題。通過計算各個類別的權重,來計算加權的loss。對于數量較多的類別,給予較小的權重,數量較少的類別,權重較大,以期能緩解多標簽的類別不平衡問題。
4.3 對比實驗結果
該節測試基本的多標簽貝葉斯分類算法MLNB、多標簽分類KNN 算法ML-KNN,以及RoBERTa算法與文中改進過的TextCNN 模型之間的性能對比。該選擇將以上各個算法在該文的自建數據集上進行測試運行對比,結果如表1 所示。
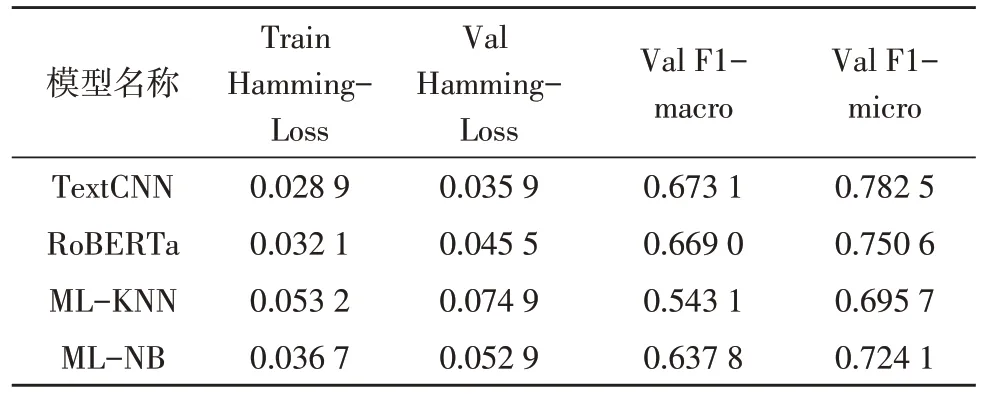
表1 實驗結果對比
在該文的自建數據集上,TextCNN 模型在主要的性能指標上超過了所有其他模型,達到了較好的效果。F1-micro 的值分別比RoBERTa、ML-KNN、ML-NB 高出了3.19,8.68,5.84 個百分點。
5 結束語
該文首先介紹并構建了一個全新的全國政策文本類的數據集,通過爬蟲來獲取全國各個地市的政策文本數據,對數據進行預處理后,構建訓練集、驗證集和測試集。后在自建數據集上進行基于TextCNN 的多標簽分類任務。最后通過改進過的TextCNN 神經網絡來訓練模型對數據進行多標簽分類,經過實驗對比測試,經過改進后的TextCNN 結合百度百科詞向量在自建數據集上達到了較好的分類效果。
當然,該文在研究過程中仍然有不足之處,比如文中自建數據集里的政策數據是多標簽文本,存在一定程度上的標簽類別不平衡的問題,雖然使用權重在一定程度上緩解了類別不平衡的問題,但權重應用的效果并不是很好,這部分內容待優化。未來將在該方面繼續進行研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
