圖像異常檢測研究現狀綜述
2022-07-03 02:10:52呂承侃張正濤
自動化學報 2022年6期
呂承侃 沈 飛 , 張正濤 , 張 峰 ,
異常檢測是機器學習領域中一項重要的研究內容.它是一種利用無標注樣本或者正常樣本構建檢測模型[1],檢測與期望模式存在差異的異常樣本的方法.異常檢測在各種領域中都有廣泛的應用,如網絡入侵檢測、信號處理、工業大數據分析、異常行為檢測和圖像與視頻處理等.
早期的異常檢測算法大多應用于數據挖掘領域,而近年來隨著計算機視覺和深度學習等相關技術的發展,許多相關工作將異常檢測引入到圖像處理領域來解決樣本匱乏情況下的目標檢測問題.
傳統的目標檢測算法中很大一部分方法屬于監督學習的范疇,即需要收集足夠的目標類別樣本并進行精確的標注,比如圖像的類別、圖像中目標的位置以及每一個像素點的類別信息等[2-3].然而,在許多應用場景下,很難收集到足夠數量的樣本.例如,在表面缺陷檢測任務當中,實際收集到的圖像大部分屬于正常的無缺陷樣本,僅有少部分屬于缺陷樣本,而需要檢測的缺陷類型又十分多樣,這就使得可供訓練的缺陷樣本的數量十分有限[4].又比如在安檢任務當中,不斷會有新的異常物品出現[5].而對于醫學圖像中病變區域的識別任務,不僅帶有病變區域的樣本十分稀少,對樣本進行手工標注也十分耗時[6].在這些情況下,由于目標類別樣本的缺乏,傳統的目標檢測和圖像分割的方法已不再適用.
而異常檢測無需任何標注樣本就能構建檢測模型的特點,使得其十分適用于上述幾種情況[7].在圖像異常檢測當中,收集正常圖像的難度要遠低于收集異常圖像的難度,能顯著減少檢測算法在實際應用中的時間和人力成本.而且,在異常檢測中模型是通過分析與正常樣本之間的差異來檢測異常樣本,這使得異常檢測算法對各種類型甚至是全新的異常樣本都具有檢測能力.雖然標注樣本的缺失給圖像異常檢測帶來了許多問題和挑戰,不過由于上述各種優點,如表1 所示,已經有許多方法將圖像異常檢測應用在各種領域中.因此,圖像異常檢測問題具有較高的研究價值和實際應用價值.

表1 圖像異常檢測的應用領域Table 1 Applications of image anomaly detection
隨著對異常檢測研究的深入,大量研究成果不斷涌現,也有許多學者開展了一些綜述性工作.如Ehret 等[20]根據不同的圖像背景,對大量圖像異常檢測方法進行了綜述,不過對基于深度學習的方法還缺乏一定的梳理.Pang 等[21]和Chalapathy 等[22]則是從更為廣闊的角度對基于深度學習的異常檢測方法進行了梳理,不過由于數據類型的多樣性,這些工作對異常檢測在圖像中的應用還缺乏針對性.陶顯等[23]對異常檢測在工業外觀缺陷檢測中的應用進行了一些總結,不過重心落在有監督的檢測任務上,對無監督的異常檢測方法欠缺一定的整理和歸納.而本文則針對無監督的圖像異常檢測任務,以工業、醫學和高光譜圖像作為具體應用領域,對傳統和基于深度學習的兩大類方法進行梳理.上述3 種應用領域都有相同的特點即可使用的帶標注異常樣本數量稀少,因此有許多工作針對這幾個領域內的異常目標檢測問題開展了研究.本文整體結構安排如下:第1 節將介紹異常的定義以及常見的形態.第2 節根據模型構建過程中有無神經網絡的參與,將現有的圖像異常檢測算法分為傳統方法和基于深度學習兩大類并分別進行綜述與分析.第3 節將介紹圖像異常檢測中常用的數據集.第4 節將介紹在圖像異常檢測當中面臨的主要挑戰.第5 節將綜合圖像異常檢測的研究現狀對未來可能的發展方向進行展望.最后第6 節將對本文內容進行總結.
1 異常檢測的定義
1.1 異常的定義及類型
異常,又被稱為離群值,是一個在數據挖掘領域中常見的概念[24],已經有不少的工作嘗試對異常數據進行定義[25-26].Hawkins 等[25]將異常定義為與其余觀測結果完全不同,以至于懷疑其是由不同機制產生的觀測值.一般情況下,會將常見的異常樣本分為3 個類別[1]:點異常、上下文異常和集群異常.
點異常一般表現為某些嚴重偏離正常數據分布范圍的觀測值,如圖1(a)所示的二維數據點,其中偏離了正常樣本點的分布區域(N1,N2)的點(O1,O2和O3)即為異常點.
上下文異常則表現為該次觀測值雖然在正常數據分布范圍內,但聯合周圍數據一起分析就會表現出顯著的異常.如圖1(b)所示,t2點處的溫度值雖然依然在正常范圍內,但聯合前后兩個月的數據就能發現該點屬于異常數據.
而集群異常,又稱為模式異常,是由一系列觀測結果聚合而成并且與正常數據存在差異的異常類型.該類異常中,可能單獨看其中任意一個點都不屬于異常,但是當一系列點一起出現時就屬于異常,如圖1(c)箭頭所指區域內單獨看每一個點的值都在正常范圍內,但這些點聚合在一起就形成了與正常信號模式完全不同的結構.
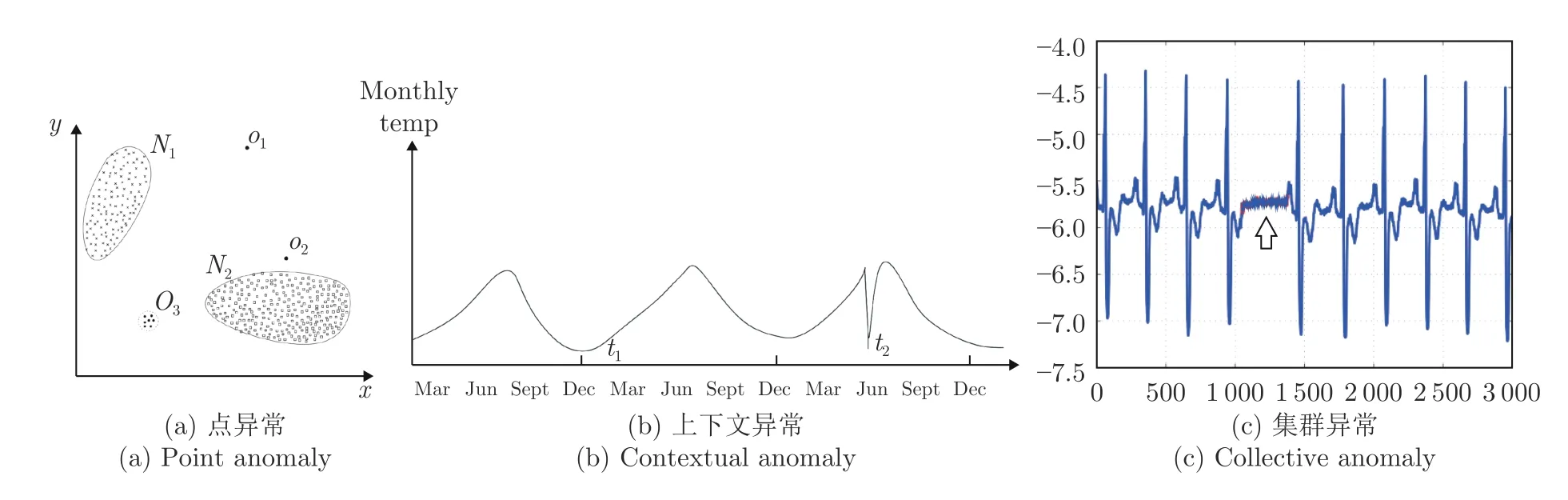
圖1 異常的類型[1]Fig.1 The type of anomaly[1]
1.2 圖像數據中的異常
圖像數據中每一個像素點上的像素值就對應著一個觀測結果.由于圖像內像素值的多樣性,僅僅分析某一個點的像素值很難判斷其是否屬于異常.所以在大部分圖像異常檢測任務中,需要聯合分析圖像背景以及周圍像素信息來進行分類,檢測的異常也大多屬于上下文或者模式異常.當然,這3 種異常類型之間并沒有非常嚴格的界限.例如,有一部分方法就提取圖像的各類特征[27],并將其與正常圖像的特征進行比較以判斷是否屬于異常,這就將原始圖像空間內模式異常的檢測轉換到了特征空間內點異常的檢測.
圖像異常檢測任務根據異常的形態可以分為定性異常的分類和定量異常的定位兩個類別.
定性異常的分類,類似于傳統圖像識別任務中的圖像分類任務,即整體地給出是否異常的判斷,無需準確定位異常的位置.如圖2 左上圖所示,左側代表正常圖像,右側代表異常圖像,在第1 行中,模型僅使用服飾數據集(Fashion mixed national institute of standards and technology database,Fashion-MNIST)[28]中衣服類型的樣本進行訓練,則其他類別的樣本圖像(鞋子等)對模型來說都是需要檢測的異常樣本,因為他們在紋理、結構和語義信息等方面都不相同.又或者如第2 行所示,異常圖像中的三極管與正常圖像之間只是出現了整體的偏移,而三極管表面并不存在任何局部的異常區域,難以準確地定義出現異常的位置,更適合整體地進行異常與否的分類.
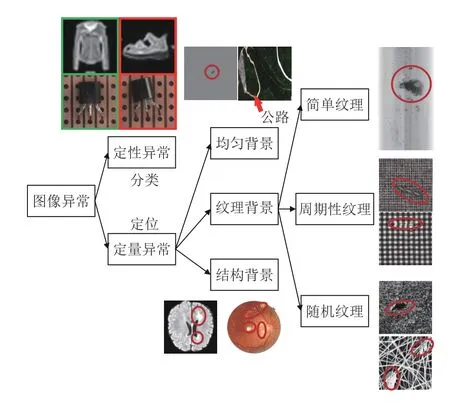
圖2 圖像異常分類圖Fig.2 The classification of image anomalies
而定量異常的定位則類似于目標檢測或者圖像分割任務,需要得到異常區域的位置信息.在這種類型的圖像異常檢測中,測試圖像中只有一小部分區域出現了異常模式.而異常定位任務根據具體的圖像背景又可分為以下幾類,如圖2 所示,其中被圈出部分為異常區域.
1) 均勻背景
均勻背景代指一些內容較為單一的場景,如圖2中上圖所示磨砂玻璃表面對局部缺陷的定位,或者深色山區圖像中對盤山公路的定位.這一類背景下的異常檢測屬于相對簡單的檢測任務.
2) 紋理背景
紋理背景主要出現在工業生產領域中,根據紋理形態又可以分為簡單紋理、周期性紋理和隨機紋理3 種.其中,簡單紋理代指因光照和材質反光等因素影響,在原本均勻的物體表面產生的一些非均勻的紋理背景,如圖2 右上所示的鋼板表面圖像.而周期性紋理則代指各類由大量重復單元組成的具有顯著周期性的圖像,最具代表性的就是圖2 所示的各類布匹圖像.而隨機紋理則代指一些由無規則結構組成的圖像背景,如圖2 右下圖所示的聲吶和納米材料圖像.
3) 結構背景
結構背景則是一類更為廣泛的圖像背景,一般具有結構復雜、個體差異大和語義信息豐富等特點,需要整體進行分析而無法僅依靠局部信息進行異常檢測,如圖2 左下圖所示的各種醫學圖像.這類圖像背景下的異常檢測問題是相對較難的一類檢測任務.
2 圖像異常檢測技術研究現狀
一般情況下圖像異常檢測的目標是通過無監督或者半監督學習的方式,檢測與正常圖像不同的異常圖像或者局部異常區域.近年來傳統機器學習方法已經在圖像異常檢測領域有了較多的應用,而隨著深度學習技術的發展,越來越多的方法嘗試結合神經網絡來實現圖像異常檢測.根據在模型構建階段有無神經網絡的參與,現有的圖像異常檢測方法可以分為基于傳統方法和基于深度學習的方法兩大類別.如圖3 所示,基于傳統方法的異常檢測技術大致包含6 個類別:基于模板匹配、基于統計模型、基于圖像分解、基于頻域分析、基于稀疏編碼重構和基于分類面構建的異常檢測方法.而基于深度學習的方法大致包含4 個類別:基于距離度量、基于分類面構建、基于圖像重構和結合傳統方法的異常檢測方法.
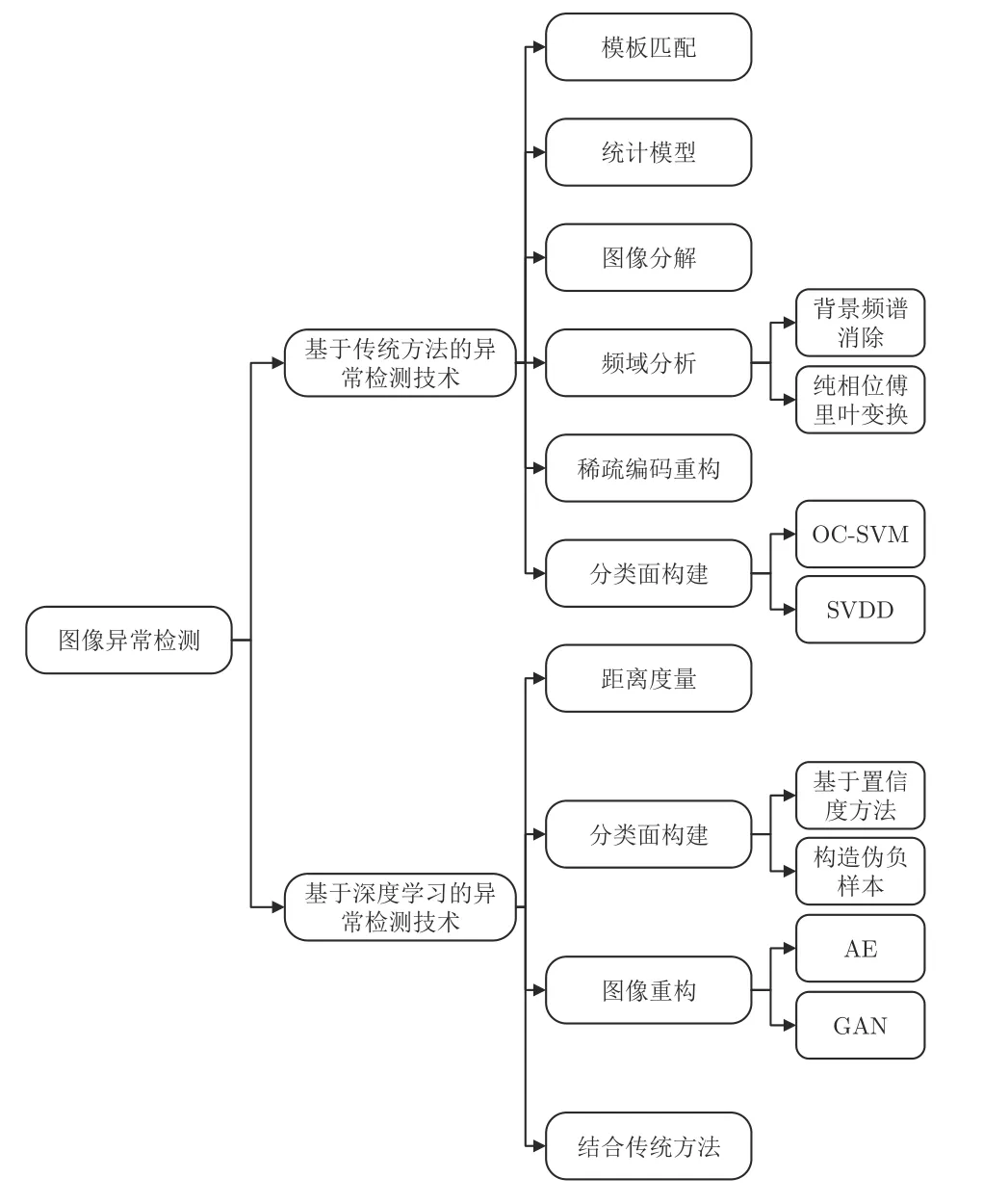
圖3 圖像異常檢測技術的分類圖Fig.3 The classification of image anomaly detection methods
2.1 基于傳統方法的異常檢測技術
本文根據檢測原理將傳統圖像異常檢測方法分類為以下類別:基于模板匹配、基于統計模型、基于圖像分解、基于頻域分析、基于稀疏編碼重構和基于分類面構建的異常檢測方法.傳統的圖像異常檢測算法大多會學習一個模型來描述正常圖像,隨后在檢測階段根據待檢圖像與現有模型之間的匹配程度來進行異常檢測.
2.1.1 基于模板匹配的異常檢測方法
在圖像異常檢測任務中,最理想的情況是所有的正常圖像都高度相似,且異常圖像與正常圖像之間只會在小部分區域出現區別.此時,模板匹配是非常有效的一類異常檢測方法.得到待測圖像和模板圖像之間的對應關系后,比較兩者之間的差異即可實現異常檢測.
圖像匹配作為一種計算機視覺中的常見任務,已經得到了充分的發展,根據相關文獻的整理[29],現有的方法可以大致分為點特征匹配、線匹配和區域匹配3 大類別.點特征匹配中,常用有諸如Harris 特征[30]、尺度不變特征變換(Scale invariant feature transform,SIFT)[31]和仿射尺度不變特征變換(Affine scale invariant feature transform,ASIFT)[32]等人工設計的特征提取方法,也有結合機器學習進行特征點提取的改良的加速分割測試特征(Features from accelerated segment test-enhanced repeatability,FAST-ER)[33]和時間不變學習檢測器(Temporally invariant learned detector,TILDE)[34]等算法.不過由于點特征提取過程中往往存在大量的外點,為了估計準確的幾何參數還需要額外的篩選流程去除外點.線匹配中,常用的有均值-標準差線描述符(Mean-standard deviation line descriptor,MSLD)[35]和條帶描述符(Line band descriptor,LBD)[36]等通過提取直線特征進行匹配的方法,也有Xia 等[37]和Wolfson 等[38]采用的曲線匹配方法.線特征相比于點特征包含更多的場景信息和結構信息,但是也會面臨邊緣特征不明顯和線段斷裂等問題.而第3 類區域匹配的方法包含最為完整的圖像信息,相比于另外兩種方法具有更好的魯棒性.早期的方法包括歸一化積相關[39]和平均絕對差[40]等算法,近期較為常用的還包括Korman 等[41]提出的快速匹配算法(Fast affine template matching,FAST-Match)和Jia 等[42]提出的適用于彩色圖像匹配的彩色快速匹配算法(Fast affine template matching for colour images,CFAST-Match).而近年來有一些方法利用深度學習進行區域匹配.如Han 等[43]通過對圖像區域進行特征提取和相似性度量以實現圖像匹配.也有方法不進行相似性度量,如Balntas 等[44]利用三元損失對網絡進行特征提取的訓練,相比于傳統的特征描述符有更高的提取效率和匹配效果.
而在圖像異常檢測領域,有許多相關方法利用圖像匹配技術進行異常檢測.如Chen 等[45]提取了待測圖像和模板圖像的Hu 矩作為特征對三維打印零件進行異常與否的分類.Vaikundam 等[46]先提取了圖像的SIFT 特征,利用聚類算法進行描述符篩選之后,找到最為匹配的正常圖像作為模板來進行異常區域的定位.Herwig 等[47]則是通過中值濾波創建模板圖像來檢測鋼材表面的異常區域.考慮到空域模板匹配方法容易受到諸如光照變化和正常圖像間微小差異的影響,Tsai 等[48]將模板匹配過程遷移到了頻域,通過比較待檢圖像和模板圖像經傅里葉變換后的頻域分量來定位印制電路板(Printed circuit board,PCB)上細微的缺陷.
但模板匹配的方法一般適用于圖像采集環境穩定且可控的場景,如圖4 所示的PCB 板表面的異常檢測,雖然結構復雜但內容基本保持不變.而更多的情況下,即便是正常圖像之間都會存在著較多的差異,難以通過模板匹配實現異常檢測.

圖4 模板匹配的適用場景[48]Fig.4 Applicable scenes of template matching[48]
2.1.2 基于統計模型的異常檢測方法
這一類方法通常是利用統計模型來描述正常圖像中像素值或者特征向量的分布情況,而對于一些遠離該分布的圖像區域則認定為存在異常.
其中較為常見的方式是利用高斯模型進行描述,比如Reed 等[49]提出的RX (Reed-xiao)算法就利用高斯分布函數來描述高光譜圖像中像素點內信息的分布情況[50].然而一個高斯分布模型很難描述更為復雜多變的場景,為了進一步地提升建模效果,Veracini 等[51]通過高斯混合模型對高光譜圖像的背景像素進行描述,并通過期望最大化算法來自適應地確定高斯混合模型中子分布模型的數量.Zhang等[52]則是利用馬爾科夫隨機場提升了高斯混合模型的魯棒性,在鋼板表面獲得了較好的異常定位效果.
上述方法大多僅對像素點內的信息進行了建模而忽略了區域信息,為了讓模型對于孤立的噪聲像素點有足夠的魯棒性,有方法同時考慮了像素點的鄰域信息來進行背景建模.Goldman 等[27]首先對局部圖像片提取特征,然后再通過構造高斯模型的方式檢測異常區域.
此類方法為了估計模型的參數需要一定數量的正常樣本,而且這些方法都預先對圖像數據的分布做了假設,這在一定程度上降低了該方法的通用性.基于統計模型的方法較為適合圖5(a)所示的高光譜圖像這種一個像素點包含大量信息的特殊圖像類型,因此在高光譜圖像中的異常檢測問題上衍生出了許多基于RX 算法的改進方法,如子空間RX 算法(Subspace RX,SSRX)[53]和局部RX 算法(Local RX,LRX)[54]等.而對于普通圖像類型而言,統計模型的方法在一些背景較為簡單的圖像中有較好的檢測效果,如圖5(b)所示的鋼板表面圖像,而結合特征提取算法也能應用在一些具有一定紋理背景的圖像中,如圖5(c)所示的聲吶圖像.但是結構更為復雜的圖像往往難以預先假設其數據分布,在模型參數的估計上也有較高的難度,無法保證檢測效果[55].

圖5 統計模型的適用場景[27,51-52]Fig.5 Applicable scenes of statistical model[27,51-52]
2.1.3 基于圖像分解的異常檢測方法
基于圖像分解的方法大多針對的是周期性紋理表面小面積異常區域的檢測任務.由于異常區域一般是隨機出現的,其周期性較弱,這一特點使其可以與周期性的背景紋理進行區分.
較為常用的方法主要利用了周期性背景紋理低秩性的特點,采用低秩分解將原始待檢測圖像分解成為代表背景的低秩矩陣和代表著異常區域的稀疏矩陣[8]:
其中,F代表原始圖像矩陣,L和S分別代表著低秩矩陣和稀疏矩陣.‖·‖*代表著矩陣的秩,||·||1代表L1 范數來近似描述矩陣的稀疏度,λ是一個人工變量.不過,直接對原始圖像進行低秩分解容易受到正常背景變化的影響,導致其定位精度較低.因此,一般會先對原始圖像進行特征提取,然后在特征向量構成的矩陣上進行低秩分解以區分正常和異常區域.
其大致流程如圖6 所示,圖中分解得到的稀疏矩陣Si就對應著可能存在異常的區域.Li 等[8]將原始圖像切分成不同圖像區域,并利用Gabor 變換與方向梯度直方圖(Histogram of oriented gradient,HOG)提取圖像區域的特征,再利用低秩分解來尋找對應著異常區域的圖像塊.楊恩君等[56]則結合布匹圖像的基元特征和HOG 特征作為輔助信息來進一步優化低秩分解的效果.Li 等[57]聯合多通道特征提取和低秩分解算法來進行布匹表面缺陷的檢測.Wang 等[10]在多特征融合的基礎上,結合背景先驗知識挖掘和超像素分割的方法,在鋼材表面缺陷分割任務中獲得了更為細致的分割結果.

圖6 基于低秩分解的圖像異常檢測示意圖[57]Fig.6 Illustration of anomaly detection based on low-rank decomposition[57]
但是,原始的低秩分解方法只是將原始圖像分解成為了低秩矩陣和稀疏矩陣兩部分,這一過程沒有考慮可能出現的加性噪聲,這些噪聲同樣被保留在了分解出的稀疏矩陣中,影響后續的異常定位過程.因此,Zhou 等[58]提出的分解算法(Go decomposition,GoDec)將原始矩陣分解成低秩矩陣、稀疏矩陣和噪聲矩陣3 個部分,相比于原始的低秩分解方法有更強的魯棒性.Zhang 等[59]在GoDec 的基礎上,充分利用了背景區域的先驗知識,結合馬氏距離來檢測高光譜圖像中的異常區域.Wang 等[60]在分解布匹圖像的過程中考慮了異常區域的局部連續性以保證缺陷形態的完整,還提出了一種積分機制來進一步提升稀疏矩陣中缺陷的完整性并減少噪聲的殘留.然而,在稀疏矩陣中也存在著部分背景區域,同樣也會影響檢測的過程.針對這一問題,Yang 等[61]結合正交子空間投影和自適應權重選取算法來抑制稀疏矩陣中的背景噪聲.
基于低秩分解的異常檢測算法,其優點在于完全不需要任何訓練樣本,直接可以在待檢圖像上進行異常區域的檢測.不過這一類方法由于涉及到優化過程,計算量較大,其檢測速度相對較慢,難以進行實時檢測.由于其對背景圖像的低秩性假設,這一類方法適用于如圖7(a)所示的布匹[8]等各種規則紋理表面的缺陷檢測問題,同時,低秩分解在圖7(b)所示的更為復雜的高光譜圖像的異常檢測中也有應用[59,61],不過需要將原始h×w×b的三維圖像數據重新排列成(h×w)×b的二維矩陣再進行后續的分析,其中b代指頻段數.但此類方法對于無周期性或者紋理更加復雜的普通圖像并不適用.

圖7 圖像分解的適用場景Fig.7 Applicable scenes of image decomposition
2.1.4 基于頻域分析的異常檢測方法
基于頻域分析的方法主要針對的也是規則紋理表面異常區域的檢測.不過這一類方法主要是對圖像的頻譜信息進行編輯,嘗試消除周期性背景紋理以凸顯異常區域.其中常用的方法包含背景頻譜消除和純相位傅里葉變換法(Phase only fourier transform,POFT)[62]兩類,前者通過消除背景的頻譜信息來凸顯異常區域,而后者則嘗試在逆傅里葉變換時僅利用相位譜以消除重復背景.
1)早期的方法如圖8 所示,在檢測過程中首先利用傅里葉變換(Fourier transform,FT)[63]將原始圖像轉換到頻域空間,在幅度譜中將對應著周期性背景紋理的頻譜分量去除之后,通過逆傅里葉變換(Inverse fourier transform,IFT)來得到異常區域的位置信息.可以看到,圖8(a)中的斜向紋理在經過傅里葉變換之后會在圖8(b)中被圈出的部分得到較高的頻譜分量,按照圖8(c)的方式將這些區域消除后再進行逆變換,從圖8(d)中可以看到原始的紋理背景已經被消除,而屬于缺陷的黑色圓點依舊被保留了下來.

圖8 通過背景頻譜消除來進行異常檢測[66]Fig.8 Anomaly detection based on subtraction of background spectral[66]
Liu 等[64]將待檢圖像與正常圖像的頻譜作差來進行異常檢測,不過該方法更適合背景較為固定的場景,當目標出現旋轉等變換時其性能就會受到嚴重的影響.Tsai 等[65-66]通過刪除幅度譜中某些特定的信息來進行紋理圖像表面的異常檢測.不過該方法只適合于一些均勻或者有方向性的紋理圖像,因為這類圖像其背景對應的頻譜分量比較容易確定.但對于較為復雜的圖像,背景區域頻譜分量的分布更為復雜,無法直接利用濾波[65]等操作來去除.后續的方法嘗試用更加自適應的方式來進行異常檢測,比如Zhang 等[63]就結合譜減法來嘗試檢測玻璃表面的缺陷.譜減法[67]首先使用特定的濾波器處理幅度譜,隨后計算其與原始幅度譜之間的差值,并以該差值進行逆傅里葉變換來得到圖像中異常區域.Li 等[68]在譜減法的基礎上,利用重構后圖像的熵來自適應地選擇最優濾波器,以此來實現對不同大小目標的檢測.不過,譜減法的檢測性能與使用的濾波器核有較強的相關性[68],需要在模型設計階段投入大量的精力來設計合適的濾波器核.
2) 第二類比較常用的方法,則是采用POFT來消除背景區域.POFT 在對圖像進行傅里葉變換之后,拋棄了幅度譜的信息而僅采用其相位譜信息來進行逆傅里葉變換[69]:
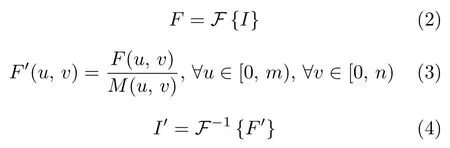
其中,I代表著二維圖像矩陣,F和F-1分別代表著傅里葉變換和逆傅里葉變換,F(u,v)代表著傅里葉變換后的結果F在坐標(u,v)處的值,而M(u,v)代表著該點處的幅度值.m和n則分別代表著圖像矩陣的行數和列數.處理后的F′中僅保留了相位譜的信息,I′則代表著逆變換后得到的圖像.在此過程中能夠去除原始圖像中全部的周期性紋理部分而保留異常區域,這一點已經由Bai 等[12]進行了數學證明.Aiger 等[69]在POFT 的基礎上結合自適應閾值的方式自動在逆變換后的圖像中分割異常區域.POFT 比背景頻譜消除的方法更為便捷,但對于長線條或劃痕這種面積較大且具有周期性的缺陷卻無法進行檢測.
上述這兩種方法由于其本身的特點導致其無法應用在集成電路等無周期性的圖像,有一種解決思路是人工地構造周期性.如圖9(a)所示,Bai 等[12]將一系列待測樣本以矩陣的形式進行排列,人工構造出了正常圖像的周期性,由于異常一般不會在一個區域反復出現,因此不會呈現周期性,在逆變換后依然能被保留下來.除了在二維空間中排列圖像來構建周期性的方法,也有Tsai 等[70]通過將多張圖像進行堆疊,使得正常背景在創建出的圖像軸上能夠體現出周期性,如圖9(b)所示.
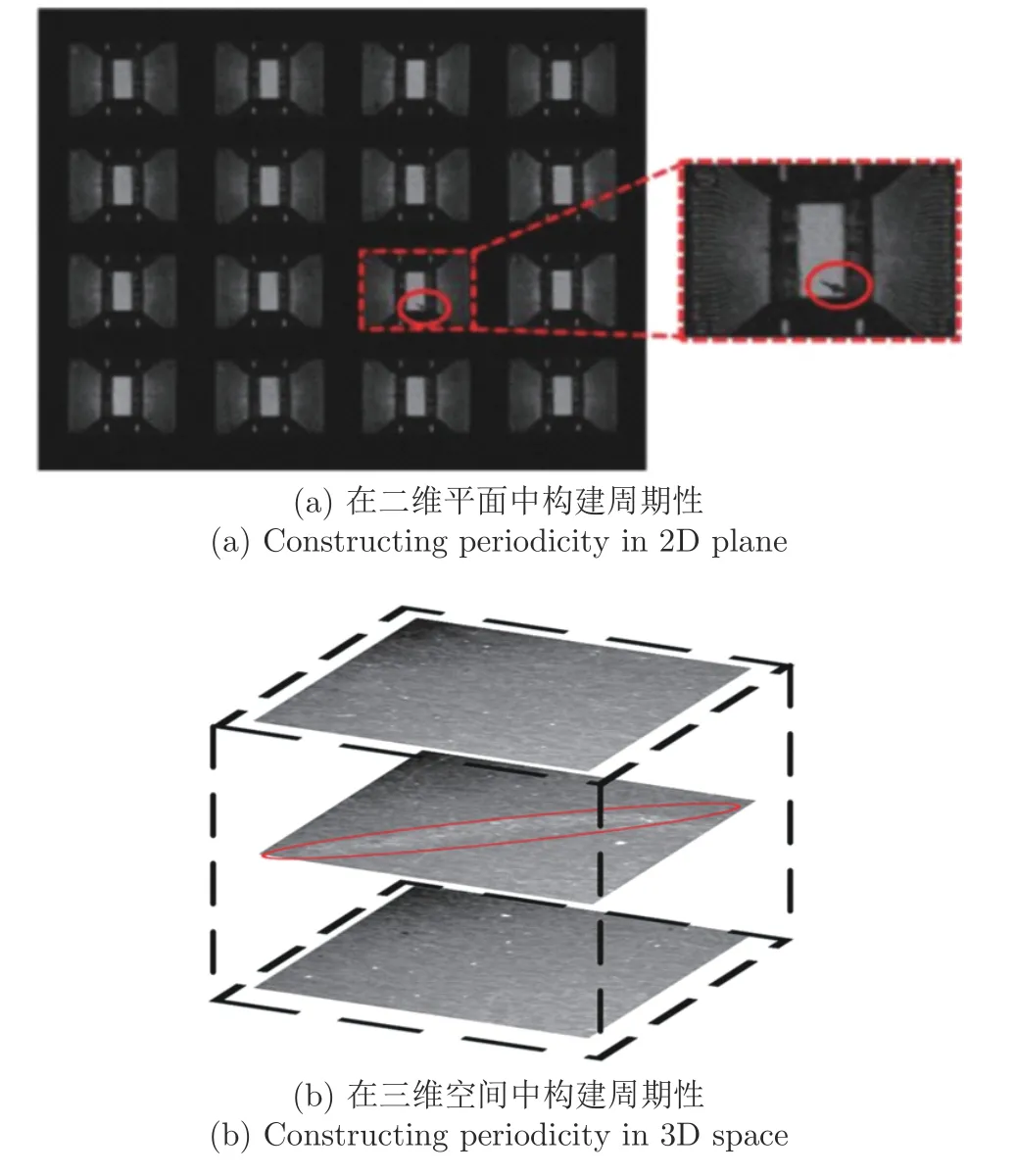
圖9 人工構造周期性示意圖Fig.9 Illustration of artificial periodicity
相比于別的方法,基于頻域分析的異常檢測方法其優點在于計算速度快,而且不需要事先構建模型,直接可以在待測圖像上進行檢測.這使得該方法非常適合實時性要求較高的場景.這一類方法對有周期性且紋理較為簡單的圖像有較好的檢測效果,比如磨砂玻璃表面[63]以及圖7 中展示過的布匹圖像等,但依然對圖像背景有一定的限制.雖然有一些方法嘗試利用人工構造周期性的策略來檢測不規則圖像,但是其泛化性能并不好,僅適用于圖像采集環境嚴格可控的一些工業生產環境中.當樣本出現光照變化或者圖像內目標出現平移和旋轉等變化導致周期性較弱時,這些方法往往表現不佳,在正常目標附近也會出現許多干擾,如圖10 所示.

圖10 周期性較弱時的檢測效果[62]Fig.10 Detection result in weakly periodic scene[62]
2.1.5 基于稀疏編碼重構的異常檢測方法
這一類方法通常是借助稀疏編碼[71-73]的方式對圖像進行重構,并在此過程中學習一個字典來表示正常圖像,然后在測試階段從重構差異和稀疏度等角度進行異常檢測.
稀疏編碼在模型訓練階段需要學習一個過完備的字典來存儲有代表性的特征,并通過線性組合字典中存儲的元素來重構輸入圖像.其特點在于,需要盡可能地選擇少的元素的線性組合來表示正常樣本,即:
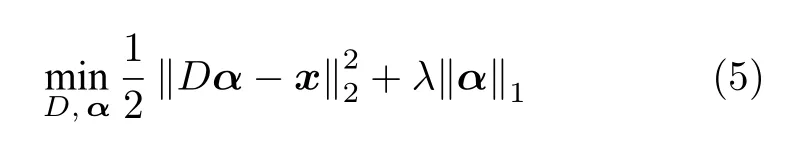
其中,D為字典,α是線性組合中的系數向量,x代表訓練集中的正常樣本,||Dα-x||2描述了字典對樣本的重構誤差,||α||1近似描述了系數向量α的稀疏度.這種約束使得字典需要去不斷精煉學習到的特征來提升編碼過程的稀疏度.字典學習的過程一般會先將原始問題轉換成凸優化問題,然后采用Boyd 等[74]提出的交替方向乘子法來求解.圖11展示了在納米材料上進行字典訓練和稀疏編碼的過程,對于具有線狀結構的納米材料,字典中存儲了各種用來描述邊緣區域的元素以有效地對正常樣本進行重構.而在測試階段,用學習到的字典對異常樣本進行重構時,由于字典僅學習了正常圖像的表示方法,對于異常樣本就會體現出較大的重構差異,編碼向量的稀疏性也較弱.

圖11 稀疏編碼中的字典[71]Fig.11 The dictionary learned in sparse encoding[71]
Liang 等[72]依據編碼向量的稀疏度來進行觸摸屏表面的異常檢測.Boracchi 等[71]在稀疏度的基礎上聯合考慮重構誤差來進行納米材料表面的異常檢測.Carrera 等[75]則在傳統的稀疏編碼中結合了多尺度的策略,對于原始圖像進行不同比例的縮放并分別構建字典,通過這種方式來提升對不同大小異常區域的檢測性能.Chen 等[76]在考慮稀疏度和重構精度的同時,對圖像局部區域的平滑性同樣進行了約束以得到更高質量的字典和重構過程.與稀疏編碼比較接近的還有獨立成分分析(Independent component analysis,ICA)[77].Sezer 等[78]借助ICA尋找構成正常樣本的獨立元素作為字典,在測試階段計算待檢圖像的編碼向量到正常圖像的編碼向量之間的距離來進行異常檢測.
基于稀疏編碼的方法相比于前3 種方法而言,不需要預先對數據的分布做假設,僅使用足夠的樣本就能很好地學習到正常圖像的表示方法,這使得稀疏編碼比之前的方法擁有更為廣泛的應用場景.在檢測各類周期性圖像的同時,也能處理具有隨機結構的圖像,特別是在如圖12 所示的納米材料表面異常檢測中有許多應用.

圖12 納米材料圖像[71]Fig.12 Image of nanofibres[71]
不過這類方法依然存在一些不足之處.
首先,稀疏編碼的效率較為低下.在測試階段由于需要通過迭代優化的方式尋找最優的編碼向量,在Carrera 等[71]的實驗中,對于一張1 024×696 像素的圖像,迭代求解編碼向量的過程需要約50 秒的時間,這使得這類方法很難直接應用到生產線上進行在線檢測.不過也有一些方法嘗試結合目標的特點來進行優化,Zhou 等[13]針對瓶蓋表面異常檢測的問題建立了可能出現的異常區域的字典來加速迭代尋優的過程.
其次,稀疏編碼需要較多的空間來保存字典.為了獲得稀疏的編碼向量,一般字典都是過完備的,即字典中元素的數量要超過樣本的維度.但對于圖像數據而言,無論是局部圖像區域還是特征向量其維度都比較高,過大的字典不僅會占用較多的存儲空間,也會降低算法的運行速度.
2.1.6 基于分類面構建的異常檢測方法
基于分類面構建的方法大多是希望能夠在正常圖像分布區域外構建一個足夠緊致的分類面以區分正常樣本和潛在的異常樣本.較為常用的兩類方法為單類支持向量機方法(One-class support vector machines,OC-SVM)[79-80]和支持向量數據描述方法(Support vector data description,SVDD)[81].OC-SVM 通過在高維空間創建超平面來分割正常樣本和潛在異常樣本,而SVDD 則創建超球面來包裹絕大部分正常樣本以實現異常檢測.
圖13 分別展示了OC-SVM 和SVDD 構建分類面的示意圖,其中實心與空心的點分別代表已知的正常樣本和潛在的異常樣本.如圖13(a) 所示,OC-SVM 采用的策略是將原始數據映射到核函數對應的特征空間之后,在創建分類超平面時最大化超平面到原點的距離并確保大部分正常樣本都落在超平面的另一側.而在檢測階段,落在超平面靠近原點一側的圖像就對應著異常樣本.其訓練階段的目標函數可表示為[82]:
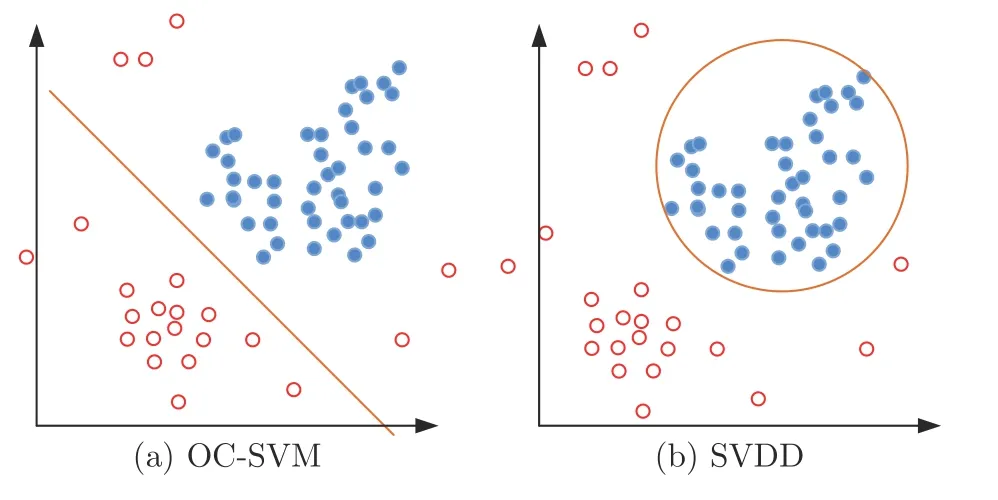
圖13 OC-SVM 和SVDD 的示意圖[82]Fig.13 Illustration of OC-SVM and SVDD[82]

其中,w和b分別代表了超平面的法向量和截距,ξi是松弛變量,n代表訓練樣本的數量,c則是對應的懲罰因子,Φ代表投影函數,xi代表正常樣本.OC-SVM 模型簡單而且有較為成熟的優化算法,不過隨著樣本維度的上升,其效果會受到顯著的影響,因此現有方法大多都會先對圖像進行特征提取并對得到的特征向量進行異常檢測.Amraee 等[80]提取圖像中每一個區域的HOG 和局部二值模式(Local binary pattern,LBP)等特征,然后借助OCSVM 對圖像中每一個區域進行異常與否的分析.Azami 等[83]對腦部核磁共振圖像提取多種特征之后,結合OC-SVM 進行異常區域的檢測.
不過OC-SVM 僅考慮構建一個超平面來進行異常檢測,這樣一個半開放的決策邊界并沒有很好地包圍正常樣本的分布區域,這限制了OC-SVM對于異常樣本的檢出能力.如圖13(a)所示,對于落在與正常樣本同一側的異常樣本就無法進行良好的檢測.因此另外一類常用方法,SVDD 在分類面的構建過程中進行了更強的約束.SVDD 的基本思想為,利用一個超球面來包裹住全部或者絕大部分的正常樣本,并且希望該超球面的半徑越小越好,對應的目標函數可表示為:
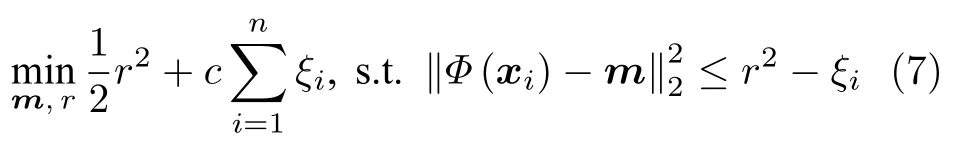
其中m為聚類中心,r為超球面的半徑,對應的超球面就是區分正常與異常樣本的決策邊界,如圖13(b)所示.相比于OC-SVM,SVDD 使用的超球面進一步提升了分類面的緊致性,獲得了相比于OC-SVM更加良好的異常檢測效果.Zhang[84]等和Gurram 等[85]都將SVDD 引入到了高光譜圖像的異常檢測任務中,Liu 等[86]提出了加速SVDD 以實現液晶屏表面細微缺陷的實時檢測.
不過,SVDD 對數據的分布又做了一個假設,即所有正常樣本都滿足一個單峰的分布模式,可以用一個超球面良好地進行表示.這是一個比較強的假設,雖然也可以通過引入核方法來提升對不同形態分布的擬合能力,但是對于許多圖像而言,不同區域的像素值或者特征向量的分布模式完全不同,導致原始數據表現為多分布融合的結果,很難用一個超球面來進行描述.如圖13(b)中的樣本點,在超球面的內部還是存在著許多代表著未知樣本的空區域.如果異常圖像落在這些區域內就很有可能會被判定為正常圖像.為了解決這一問題,Liu 等[87]嘗試集成多個SVDD 模型來描述這種樣本分布更為復雜的情況,并利用模糊c 均值聚類的方式確定子SVDD 模型的數量及對應的參數.
基于分類面構建的方法,其優點在于對待測圖像類型沒有如圖像分解或頻譜分析那樣較高的限制,能夠適用于各種類型的圖像,而且計算復雜度的問題也有相關的文獻工作給出了解決思路.不過也存在一些問題,在處理復雜圖像時,核函數的選擇可能會成為一個問題.如果選擇使用如Liu 等[87]提出的多超球面的方法,其各項參數的選擇也需要較為精心的設計.而且本質上本類方法屬于圖像分類算法,無法直接實現異常區域的定位,更適合于一些識別定性異常的場景,面對定量異常,大多需要通過區域劃分的方式進行定位,反而降低了算法的處理效率.
表2 總結了上述各類基于傳統方法的圖像異常檢測方法的設計思路和優缺點.其中,基于模板匹配的方法十分適合工業生產這類環境可控且目標高度一致的場景,實現了較高的檢測精度,但不適用于采集環境多變或者正常圖像間存在較大差異的場景.基于統計模型的方法雖然速度很快,但需要一定的訓練樣本來評估背景模型的參數.基于圖像分解的方法則適合訓練樣本稀缺的場合,可以直接在待測樣本上檢測異常區域,不過該方法速度較慢.而基于頻域分析的方法則兼顧了檢測速度和對訓練樣本的低依賴性,但是由于對背景圖像有一定的限制,因此通用性較差,這也是前3 類方法的一個通病.而后兩類基于稀疏編碼和分類面構建的方法適用于各種類型的圖像,具有更高的通用性.但稀疏編碼方法在重構階段非常耗時,而分類面構建的方法也面臨著參數選擇困難和定位精度的問題.

表2 基于傳統方法的圖像異常檢測技術的分類和特點Table 2 The classification and characteristic of traditional image anomaly detection methods
2.2 基于深度學習的異常檢測技術
近年來,深度學習在計算機視覺中的各個領域內都得到了長足的發展.相比于傳統的方法,深度學習由于其無需人工設計特征,算法通用性更高等優點,已經被廣泛引入到了圖像異常檢測任務當中.現有的方法大致可以分為以下幾類:基于距離度量的方法、基于分類面構建的方法、基于圖像重構的方法和與傳統方法相結合的方法.
2.2.1 基于距離度量的異常檢測方法
基于距離度量的方法,其核心思想在于訓練一個深度神經網絡作為特征提取器,讓正常圖像所提取到的特征向量的分布盡量緊湊,即盡可能地減小樣本的類內距離.而在測試階段,大多數方法計算待測樣本的特征與正常特征之間的距離作為度量來進行異常檢測.
Ruff 等[88]提出的深度支持向量數據描述(Deep support vector data description,Deep SVDD)是這一類型中較為常用的一種方法.作者首先在特征空間中人為指定了一個點作為特征中心,然后以正常樣本到該點的距離之和作為損失函數的主體來進行特征提取網絡的訓練.如圖14 所示,經過訓練網絡能夠將原始圖像空間中的正常樣本都映射到特征中心點附近,而異常樣本其對應的特征就可能會遠離該中心點,因此根據距離就能判斷待測樣本是否屬于異常樣本.

圖14 Deep SVDD 的原理示意圖[88]Fig.14 Illustration of Deep SVDD[88]
但這種方式存在著較多的限制.首先,該方法假設正常樣本在特征空間中屬于一個單峰分布,即都落在指定的中心點附近.這一假設在一些較為復雜多變的數據集上可能并不成立.這一點從Ruff 等的實驗結果中也能看出,Deep SVDD 對于手寫數字數據集(Mixed national institute of standards and technology database,MNIST)[89]的效果十分優秀,但是對于加拿大高等研究院(Canadian institute for advanced research,CIFAR)構建的CI-FAR-10[90]這種更為復雜的自然圖像數據集其性能較為有限.此外,該方法容易出現模型退化的問題,即學習到的模型會把所有圖像都映射到同一點上,因此該方法在訓練過程中還有許多限制,比如網絡結構中不能有偏置項,特征中心點需要人工指定并且不可修改,而且在檢測階段還涉及到了對特征向量的編輯過程,這些都限制了Deep SVDD 的應用場景.
不過可以通過額外的訓練目標來優化特征提取過程以避免Deep SVDD 遇到的各種限制[91].Perera 等[92]并沒有人工地指定特征中心,而只是以減小正常樣本特征之間的距離為訓練目標.不過作者在正常樣本的基礎上,引入了ImageNet 數據集中的樣本來構建一個分類的子任務.網絡不僅需要減小正常樣本特征的類內離散度,還需要有一定的類間離散度來保證分類性能,網絡需要有較強的語義信息提取能力而不僅僅是將樣本映射到某一區域內,這使得該方法對于復雜的自然圖像數據也有較好的性能.而Wu 等[93]增加了解碼模塊將特征解碼成與輸入樣本近似的圖像,以此來保證所提取到的特征向量有足夠的語義信息,避免出現Deep SVDD 中的模型退化問題.Bergman 等[94]在Deep SVDD 的基礎之上,利用多種幾何變換方法將原本僅有一類的正常圖像數據擴增成了多類數據集,并且為每種變換對應的類別都指定了一個特征中心.作者在訓練過程中采用了三元損失(Triplet loss)[95]來強調不同變換方式對應的特征向量之間的可分性.這種方式既避免了模型退化的問題還構建出了多個特征中心點作為分類參考,相比于原始的Deep SVDD 方法有了顯著的性能提升.不過依然需要更加通用的幾何變換方式來適應具有周期性或者紋理類的圖像[94].近期,Liznerski 等[96]提出的全卷積數據描述(Fully convolutional data description,FCDD)利用神經網絡中的偏置項替代Deep SVDD 中的聚類中心,并且利用全卷積網絡提取圖像的特征圖來直接定位異常區域,如圖15所示.

圖15 FCDD 的原理示意圖[96]Fig.15 Illustration of FCDD[96]
除了用待測樣本的特征與正常特征之間的距離來衡量樣本的異常程度,還有方式嘗試結合距離的方差來進行異常檢測.Bergmann 等[97]同時訓練多個結構相同的特征提取網絡.而在檢測階段,由于訓練過程的隨機性,不同的網絡會得到不同的特征,根據特征分布的方差來實現對異常樣本的檢測.此外還有方式嘗試利用半監督的方式提升檢測性能,因為在實際檢測任務中標注少量的異常樣本是可行的.Ruff 等[98]就將少量經過標注的異常樣本加入到訓練過程中,并且以盡量增大異常樣本特征向量分布的熵作為目標來訓練特征提取網絡.實驗表明這種基于熵的損失函數要優于傳統的基于距離的損失函數.
上述這些方法的優點在于簡單高效,不過這種方法大多需要事先人工指定特征中心,而且為了避免模型退化需要在訓練階段設計額外的任務.僅設定一個全局特征中心點的方式在一定程度上對圖像背景產生了一些約束,在醫學圖像或者自然圖像這些較為多變的場景中,可能難以在保證泛化能力的情況下將全部的圖像映射到同一目標點附近.Wu等[93]采用的為每種圖像區域分別設置中心點的方式并不適合所有圖像,而FCDD[96]以偏置項作為中心點的方式或許也不適用于待測目標經常出現平移和旋轉等變化的場景下的異常定位任務,如圖16所示.

圖16 在旋轉目標上的檢測效果[96]Fig.16 Detection results on targets with rotation[96]
2.2.2 基于分類面構建的異常檢測方法
基于分類面構建的方法,其核心思想在于將單類正常樣本轉換成多類別樣本以訓練分類器,通過這種方式來在圖像空間中構建分類面,實現對正常樣本和潛在的異常樣本的分類.常用的基于分類面構建的方法大致包含以下兩個類別:
1)第一類方法將原始單類樣本通過幾何變換得到多類別樣本,并結合在分布外檢測(Out-of-distribution,OOD)[99]任務當中比較常見的基于置信度的方法來進行異常檢測.
OOD 檢測任務與異常檢測任務目標非常相似,同樣也需要模型對訓練過程中未出現過的樣本有檢測能力,但OOD 的特點在于訓練樣本中包含了多個類別,所以可以直接在訓練樣本上進行多分類的訓練.Hendrycks 等[100]指出,由于異常樣本落在正常樣本的分布之外,分類器對異常樣本輸出的最大softmax 值往往會低于正常樣本的最大softmax 值,所以可以通過設定閾值的方式區分正常樣本和異常樣本.由于異常檢測中訓練集僅包含了一類樣本,所以相關工作就嘗試通過對正常樣本進行變換的方式來構建多類別的訓練集.
如圖17 所示,Golan 等[101]采用了以翻轉、平移和旋轉為基礎的一共72 種幾何變換方式來處理原始圖像,每一種變換方式下得到的圖像即為一類樣本,以此構建了一個72 類的分類數據集來訓練一個分類網絡.在檢測階段,對待檢樣本進行全部的72 種變換并分別進行分類,異常樣本經過變換之后,網絡會無法確定其對應的變換類別,使得分類時輸出的最大softmax 值降低,以此來進行異常圖像的檢測.Hendrycks 等[102]對該方法進行了改進,將原本直接的72 分類任務轉換成了一個多任務(Multi-task)模型,在提取到的特征圖上進行額外的角度和平移量的分類任務,以此來提升網絡特征提取和分類的能力.

圖17 將單類樣本轉換成多類樣本[101]Fig.17 Transforming one-class samples into multi-class samples[101]
第一類方法雖然在CIFAR-10 等自然圖像數據集上取得了優異的成績,不過存在著一些限制,如圖18 所示,當檢測目標為斑馬時,網絡能夠識別圖像之間存在旋轉的關系.但如果檢測目標為具有對稱結構或者沒有方向信息的紋理圖像,比如圖18第二行所示斑馬表面的黑白紋理,網絡無法直接從紋理圖像中感知到足夠大的差異實現旋轉角的預測,此時強迫網絡輸出相應的角度反而會影響網絡的訓練過程[101].類似地,當檢測目標本身存在角度上的顯著變化時也難以應用上述方法.因此這類方法還需要設計更為通用的變換方式以擴展其應用領域,充分發揮其高精度的優勢.此外,也有相關的研究指出,在OOD 檢測任務中,分類模型對異常樣本也有可能會產生很高的概率值,影響異常檢測的過程[103],這同樣是一個值得進一步研究和改進的內容.

圖18 不同圖像上旋轉效果對比[102]Fig.18 Comparison of rotation on different images[102]
2)第二類方法則考慮結合傳統方法中OC-SVM或者SVDD 的思路,構建盡可能貼合正常樣本分布的分類面來進行異常檢測.這類方法大多將正常樣本當作正樣本,并采用額外的輔助樣本作為負樣本,以此在圖像空間中構建正常和異常圖像間的分類面.
Oza 等[104]利用預訓練好的神經網絡提取正常圖像的特征作為正樣本,同時在特征空間中使用以原點為中心的隨機高斯噪聲向量作為負樣本,以此來訓練一個分類網絡.不過這種方法僅使用高斯噪聲作為負樣本,負樣本比較單一且容易分類,很容易出現過擬合的問題導致網絡無法檢測新的異常樣本.Hendrycks 等[105]注意到了隨機生成的簡單噪聲樣本的不足,因此從別的圖像數據集中選取圖像作為負樣本來訓練分類模型.
然而上述方法在選取負樣本時沒有考慮到正常樣本的分布情況,在這種情況下訓練得到的分類效果就無法保證.當選擇的負樣本距離正常樣本較遠時,網絡容易出現過擬合的現象,導致其無法對真正的異常樣本進行分類.而如果選擇的樣本與正常樣本的分布過于相似,也可能出現網絡無法訓練的問題.
因此,許多方法嘗試在正常樣本分布區域附近通過生成式模型創建負樣本.而生成式對抗網絡(Generative adversarial network,GAN)[106]是近年來備受關注的生成式模型,有許多方法就結合GAN 來進行分類器的訓練.GAN 的結構如圖19所示,在GAN 的訓練過程中,目標函數一般可以表示為:
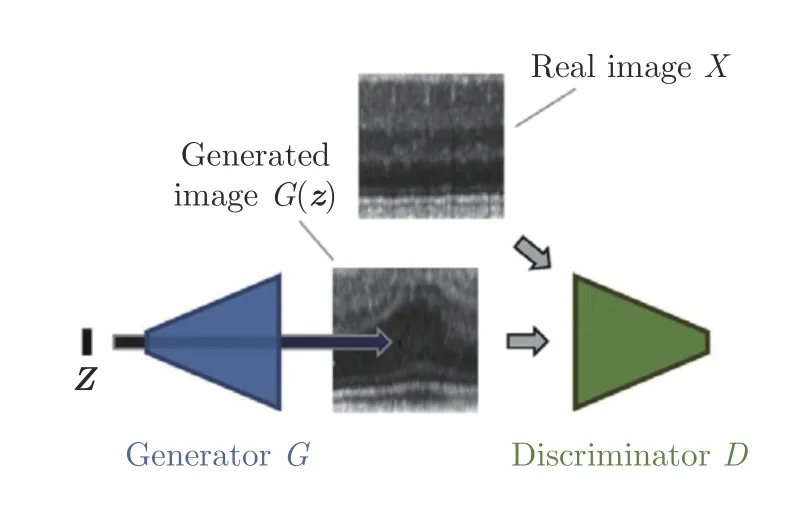
圖19 GAN 結構示意圖[15]Fig.19 The structure of GAN[15]
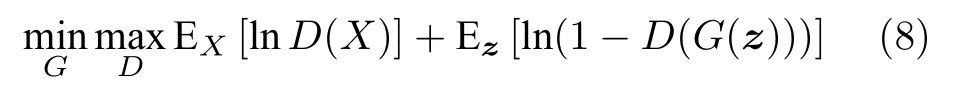
其中,G和D分別代表生成器和判別器,X是真實樣本,z是隨機的噪聲向量,G(z)即為生成的樣本.
為了對抗不斷優化的判別器,生成器所生成的圖像質量會不斷提升,最終能生成清晰且真實的樣本圖像,而Sabokrou 等[107-108]注意到在GAN 訓練的中期,生成的依然是低質量的圖像,鑒于其與正常圖像之間存在一定的相似性,此時的判別器正好可以作為一個分類器進行圖像異常檢測.作者將自編碼器作為生成器,并且附加了一個分類網絡作為判別器.在自編碼器訓練過程中作者采用了Earlystop[109]的策略,即當重構誤差小于特定閾值時就停止自編碼器的訓練避免生成過于真實的樣本,如果過度訓練反而會影響判別器對真實異常樣本的分類性能[110].利用此時的自編碼器處理正常樣本就能得到大量接近正常樣本的合成圖像.而判別器為了區分這些樣本和正常樣本,就需要在正常樣本周圍構建分類面,足夠貼合的分類面為該方法提供了良好的異常檢測性能.Yang 等[110]和Chatillon 等[111]也采取了相似的策略,不同的是,Yang 等是通過分析損失函數曲線的方式人工設定Early-stop 的節點.Chatillon 等是在GAN 訓練完畢之后,選擇一部分訓練中期的生成器權重,用來生成低質量樣本作為分類時使用的負樣本,并且還給出了一部分數學上的證明以表達該方法的有效性.Zaheer 等[112]同樣將原始GAN 中的生成器換成了自編碼器,并且將判別器的任務從區分真實圖像和生成圖像轉換成了區分正常圖像和異常圖像,其中在訓練階段使用的異常圖像同樣是借助未充分訓練的生成器得到的.
這類方法都采用了Early-stop 來避免生成器過度優化,為此還需要進行反復的實驗來確定最優的超參數,這使得這些方法在應用到新的圖像類型中時需要較長的調參過程.為了讓模型能夠生成低質量樣本又避免反復調參,部分方法開始主動探索對應著低質量樣本的區域來生成負樣本.Lim 等[113]嘗試在特征空間中生成低質量樣本,作者在GAN的基礎上,對隱變量的分布進行了約束,迫使其分布在原點周圍.訓練完畢后,距離原點越遠的特征向量,其解碼后的圖像質量就越差.因此,可以通過在該區域內進行采樣和插值等方式得到低質量樣本以進行分類器的訓練.而Liu 等[114]則通過修改生成器訓練目標來直接生成低質量樣本,該方法用一些正常樣本中最容易被判定為異常圖像的低質量樣本來訓練生成器,在這種情況下生成器的性能就會被限制,導致其只能生成低質量的樣本.不過由于并不是每一批訓練樣本中都包含低質量樣本,所以可能會存在訓練不穩定的問題.針對這一點,Ngo 等[115]改進了生成器訓練階段使用的損失函數,對于判別器能以較高置信度判別正常與否的樣本都進行懲罰,迫使生成器生成與正常樣本盡量相似又有所區別的低質量樣本.Schlachter 等[116]也采用了類似的思路,不過Schlachter 并沒有利用GAN,而是通過分析正常樣本特征之間的距離將訓練樣本分成了典型和非典型兩類,典型樣本特征之間的距離較小而非典型樣本特征之間的距離較大.隨后在兩種樣本之間構建分類面,以區分位于非典型樣本區域之外的異常樣本.
Goyal 等[117]提出的魯棒單類別分類(Deep robust one-class classification,DROCC)是這一類方法的最新工作,作者僅采用了一個分類器進行異常檢測,并通過梯度上升自動生成最適合現有數據的異常樣本作為負樣本.在分類器訓練的初期,僅使用正常樣本進行訓練并希望分類器對全部樣本輸出相同的結果.而在后續的訓練過程中,對于每一個正常樣本,都通過梯度上升的方式,在以正常樣本為中心半徑為r的圖像空間中尋找潛在的負樣本并進行二分類的訓練.該方法在各種類型的數據集上都表現出優異的性能.不過該方法依然存在一個需要調節的超參數r,而且從實驗結果來看不同的半徑r會對分類器的檢測性能產生較大的影響,因此同樣需要反復實驗來得到最合適的半徑.
圖20 展示了上述幾種需要構建負樣本來訓練分類網絡的方法示意圖.其中(a)~(d)分別展示了利用隨機噪聲[104]、利用隨機圖像[105]、利用GAN[110-115]以及利用梯度上升[117]來創建負樣本的方法.其中實心與空心的圓點分別代表了正常樣本與生成的負樣本.實線與虛線則分別代表了分類器對正常樣本和異常樣本的決策邊界.而點劃線代表著兩者之間的不確定區域.曲線上的數字代指分類器的輸出值,越高表示分類器越肯定該圖像為正常圖像,反之亦然.對于(a)和(b)方法,由于隨機的噪聲或者圖像與正常樣本之間并沒有關聯,所以構建出的分類面中存在大量的不確定區域,分類器無法很好地鑒別位于這些區域內的圖像進而影響檢測性能.而后兩種方法都主動在正常圖像周圍生成低質量圖像作為負樣本,而且梯度上升的方法更是顯式地約束了生成圖像到正常圖像的距離,這些方法由于采用的負樣本更加貼近正常圖像,因此訓練得到的分類器能夠產生更加緊密的決策邊界和更小的不確定區域,異常檢測精度更高.

圖20 需要構建負樣本的幾種方法的示意圖Fig.20 The graphical illustration of the methods based on creating fake-negative samples
然而,這些利用負樣本構建分類面的方法存在較多的假設和隨機性,大多難以直觀地控制所生成負樣本的圖像質量和分布,雖然DROCC 嘗試通過梯度上升的方式生成負樣本,但調參過程較為繁瑣.而且這些方法所生成樣本的分布特性大多只是在二維或三維空間進行了可視化驗證,在更高維的復雜圖像或者特征空間中,或許就無法得到理想的緊致分類面,這或許就是第二種方法在精度上略低于第一種幾何變換類的方法的原因[102,117].所以,如何更直觀有效地設計負樣本生成算法使其緊密分布在正常樣本周圍依然是一個需要解決的問題.
2.2.3 基于圖像重構的異常檢測方法
基于圖像重構的方法,其核心思想在于對輸入的正常圖像進行編解碼,并以重構輸入為目標訓練神經網絡,以此來學習正常圖像的分布模式.然后在檢測階段通過分析重構前后圖像之間的差異來進行異常檢測.根據采取的訓練模式,常用的基于圖像重構的方法大致包含基于自編碼器和基于生成式對抗網絡(Generative adversarial networks,GAN)兩種類型.
1)在基于圖像重構的方法中,最為常用的網絡結構為自編碼器(Autoencoder,AE)[118-119].僅利用正常樣本訓練得到的自編碼器,在測試階段能夠良好地重構正常圖像.而對于存在異常的圖像,在圖像編碼以及后續的重構過程中都會與正常圖像產生較大的差異,而差異的大小即為衡量待測樣本異常程度的指標.
自編碼器的結構如圖21 所示,其一般由一個編碼器和一個解碼器組成,且兩者的網絡結構一般是對稱的.其中,編碼器在網絡前向傳播過程中不斷縮小特征圖的尺寸,以此來刪除冗余的信息.而解碼器負責對特征進行解碼,得到與輸入圖像相同大小的圖像,通過計算重構前后圖像之間的差異來訓練網絡.而在此過程中最為常用的損失函數就是均方誤差(Mean square error,MSE)[120].MSE 用重構前后圖像中所有像素點上的像素值之差的平方均值來衡量圖像重構的質量.訓練結束后,由于瓶頸結構的存在,對于一些異常區域面積較小的樣本,自編碼器能夠在圖像編解碼的過程中消除異常區域的影響,重構出一張正常圖像作為參考,隨后可以通過逐像素比較的方式得到異常區域.
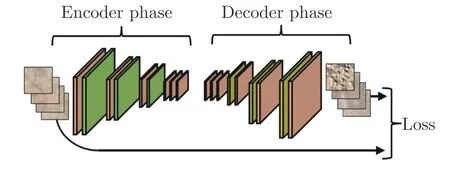
圖21 自編碼器的結構[119]Fig.21 The structure of autoencoder[119]
很多方法利用自編碼器來進行異常檢測[121-123].Mei 等[119]利用降噪自編碼器來進行紋理圖像的異常區域定位,作者將樣本切分成一系列小的圖像片并分別進行重構.此外,Mei 等還表明結合多尺度的策略[124],即在多個不同尺度下對圖像進行重構可以有效地提升異常的定位精度.
除了重構誤差,近期有一些方法開始利用圖像重構中得到的梯度信息來進行異常檢測.Kwon 等[125]指出,重構誤差一般僅衡量了在中間層特征空間以及最后的圖像空間內的差異.但如果分析梯度差異,則可以從重構網絡的任意一層處獲取并進行比較,這使得基于梯度的方法能從更全面的角度衡量待測圖像的異常程度.此外,Zimmerer 等[126]表明在異常樣本上計算得到的梯度還提供了額外的方向信息輔助分類.對于圖像而言,異常圖像上計算得到的梯度其實就代表著朝向正常樣本的優化方向.這些優點使得梯度向量相比于簡單的重構損失能提供更加完備的信息.Zimmerer 等[126]首先將梯度信息引入到了異常檢測任務中,通過計算變分自編碼器(Variational autoencoder,VAE) 中證據下界(Evidence lower bound,ELBO)相對于輸入圖像的梯度來進行異常檢測.Kwon 等[125]利用余弦相似度來計算正常樣本梯度向量之間的角度,以此來構建正常樣本梯度向量的方向一致性約束.在測試階段出現不滿足該一致性約束的梯度向量時,則認為該圖像為異常圖像.Chu 等[127]則從一個全新的角度進行異常圖像檢測,作者們發現自編碼器在以正常樣本為主的訓練集上訓練時,正常圖像的重構誤差會穩步下降,但異常圖像的重構誤差則會出現波動.因此,作者通過分析損失函數的變化曲線(Loss profile)以實現未標記樣本中異常圖像的檢測.
不過,這種基于傳統自編碼器的圖像重構方法存在重構后圖像比較模糊的問題.自編碼器常用的MSE 統計了每一個像素點上的重構差異,但由于瓶頸結構的存在,在編解碼的過程中會有信息的丟失,導致從理論上來說自編碼器無法保證每一個像素點上的像素值都不變.如果迫使MSE 接近于0,則會得到一個大致而平均的結果,這就使得重構后的圖像容易模糊,在邊緣區域會出現較多的差異從而影響后續的異常定位過程.
對于自編碼器重構較為模糊的問題,早期方法會嘗試采用VAE 并結合編碼后的特征輔助異常檢測[128],或者修改重構階段的損失函數[120]來進行改進,不過效果都比較有限.Abati 等[129]則是在圖像重構的基礎上,引入了自回歸過程以學習潛在表示的概率分布,并通過最小化隱變量分布的微分熵來訓練網絡.相比于VAE,這種更加靈活的隱變量分布提升了圖像重構的質量和異常檢測的能力.
此外有方法嘗試通過修改網絡結構的方式優化重構的質量,Zhou 等[16]通過額外增加一條用來提取圖像結構的支路來盡可能地保留輸入樣本的信息.作者采用預先訓練好的網絡提取輸入樣本的結構特征,并且將此特征融合到圖像重構的訓練過程中.此外,還通過比較重構前后圖像結構信息的方式來確保重構圖像的質量.
除了重構模糊的問題,基于自編碼器的方法還存在著無法保證完全消除輸入圖像中的異常區域的問題[11].當訓練樣本比較多樣化時,自編碼器會體現出強大的學習能力并對潛在的異常樣本產生過強的適應能力.如圖22 所示,自編碼器僅使用了數字8 進行訓練.在編碼異常圖像數字1 時,雖然1 對應的特征向量在特征空間中會遠離正常特征向量的分布區域,但重構網絡依然重構出了與輸入接近的圖像,導致其重構前后的差異反而較小,使得一些異常樣本被誤判成正常樣本.針對這一問題,大多方法采用對隱變量進行編輯的方式來解決.Tian 等[131]嘗試利用一個全連接層優化待測圖像的隱變量,迫使其接近于正常樣本的特征向量,以此來保證重構后的圖像中不存在異常區域.此外,如圖23 所示,Gong 等[132]提出的記憶強化自編碼器(Memoryaugmented deep autoencoder,MemAE)在自編碼器的基礎上,增加了一個記憶模塊,用來存儲最具有代表性的特征向量以提升圖像重構的穩定度.

圖22 異常樣本的重構示意圖[130]Fig.22 The reconstruction of anomalous images[130]

圖23 隱變量編輯示意圖[132]Fig.23 The editing of latent vector[132]
不過該方法存在一個問題就是需要大量的空間存儲訓練得到的記憶模塊,文章中一共采用了1 000個記憶向量來保證特征重構的效果.針對這一問題,Park 等[133]在MemAE 的基礎上,嘗試提升記憶向量學習的有效性.在記憶向量的訓練階段,結合聚類中類內緊致類間可分的思想,最小化歸屬于同一記憶向量的特征的類內距離,同時提升不同記憶向量之間的可分度.通過增加這兩項損失函數,作者將記憶模塊的容量從原先的1 000 個降到了10 個,顯著提升了算法的效率.除了編輯隱變量,Dehaene等[134]采用直接在圖像空間內進行迭代優化的方式來消除重構圖像中的異常結構,相比于優化隱變量再解碼的方式,這種直接在圖像空間內優化的方式能更好的保留圖像的細節.不過,上述幾種方法在檢測階段的優化過程較為煩瑣且耗時.而Yang 等[11]在隱變量層增加了基于聚類損失的正則項來避免重構出異常區域,在紋理圖像上的效果較好,但缺乏理論上的保證.
2)基于GAN 的異常檢測方法大多是利用GAN能生成逼真圖像的特點[106],采用GAN 來重構出比自編碼器更加清晰的圖像.而根據其具體重構方式,又可分為直接利用GAN 重構以及結合AE 與GAN重構兩個類型.
直接利用GAN 重構的方法考慮到原始的GAN僅創建了從隱空間到圖像空間的映射關系,因此采用迭代優化的方式獲得重構圖像.Schlegl 等[15]提出的基于GAN 的異常檢測模型(Anomaly detection with generative adversarial network,AnoGAN)從某個隨機變量開始,計算該變量生成的圖像和待測圖像之間的差異,通過梯度下降的方式迭代優化該隨機變量,使得生成的圖像逐漸接近待測圖像.由于生成器僅使用正常樣本進行訓練,所以理論上僅能生成正常樣本.當待測圖像中存在異常區域時,生成器會生成與其盡量接近但屬于正常類別的圖像作為參考,通過計算待測圖像和生成圖像之間的差異來進行異常檢測.Deecke 等[135]則在此基礎上進行了改進,從多個點開始嘗試對待測圖像進行重構,而且在迭代優化過程中,同時優化隱變量和生成器內部參數,以此來提升圖像重構的質量.AnoGAN已經在實際檢測任務中有了相關的應用[136],不過其存在算法效率上的不足.AnoGAN 在檢測階段需要進行多次的迭代優化來生成合適的正常圖像作為參考,迭代優化的過程會顯著增加算法的執行時間,在一些需要實時檢測的任務當中就無法應用.
而更多的方法會將GAN 與AE 結合,將GAN中對抗訓練的思想引入到傳統AE 的訓練框架中,以此來提升自編碼器的重構質量.
在異常檢測領域,常見的結合AE 與GAN 的方法如圖24 所示,在自編碼器的基礎上增加一個判別器,用來區分重構后的圖像和輸入的真實圖像,通過判別器和重構網絡的對抗訓練來提升重構圖像的質量[137-139].Baur 等[140]在VAE 的基礎上,增加了對抗損失來對醫學圖像進行更為真實的重構.Akcay 等[141]在傳統重構誤差的基礎上,還統計了重構前后圖像經編碼器和判別器提取到的特征之間的差異,通過多角度的約束迫使重構后的圖像在特征空間和圖像空間中都能盡量地與原始圖像接近.Schlegl 等[142]直接用GAN 中訓練好的生成器替換了原始AE 中的解碼器,以一種更為直接的方式利用GAN 強大的圖像生成能力來進行圖像重構.Tang 等[143]將原本僅用來對圖像進行二分類的判別器替換成了一個輔助的圖像重構網絡,原本判別器執行的二分類任務也轉換成了一個重構任務,通過這種更為直觀的約束來提升自編碼器的重構質量.Venkataramanan 等[144]表示,人們會需要觀察整張圖像來覺察到哪里是有異常的部分,意味著圖像中所有的區域都有助于進行異常檢測.因此,作者在結合了VAE 與GAN 進行圖像重構的基礎上,計算出了重構過程中的注意力圖[145],并期望注意力圖對于所有正常圖像區域都能輸出高值.而在檢測階段,當圖像中出現沒有訓練過的異常圖像模式時,就會表現出低注意力的情況.
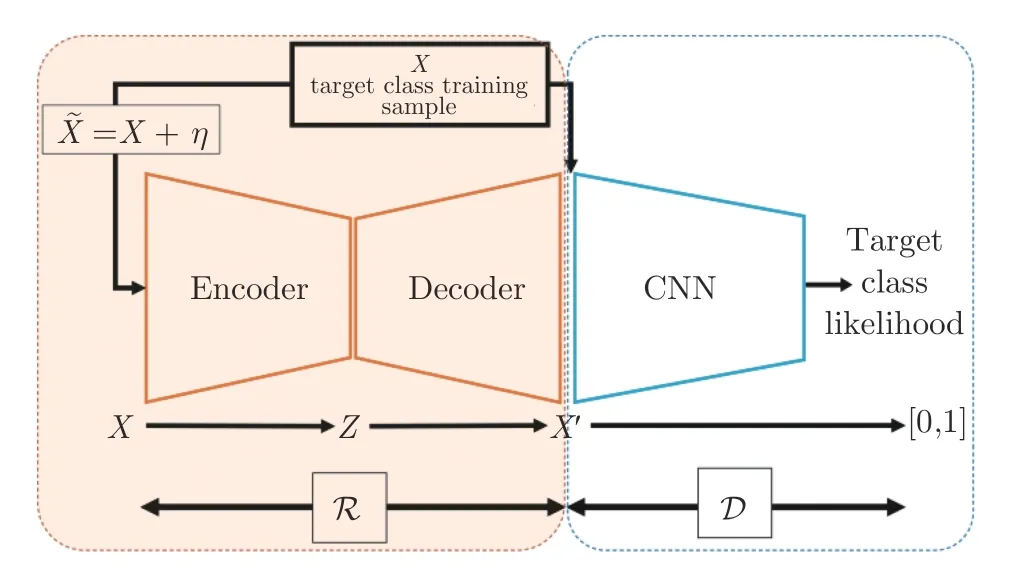
圖24 結合自編碼器和GAN 進行圖像重構[107]Fig.24 Image reconstruction based on autoencoder and GAN[107]
不過在實驗過程中,即便是使用正常樣本訓練得到的GAN,同樣也會生成一些低質量的圖像[146],導致在重構圖像中可能會殘留異常區域.雖然其概率相比于基于自編碼器的方法要小,但依然不容忽視.Perara 等[130]發現,自編碼器的這一問題主要是由于中間層對應的特征空間中,還存在著能解碼出其他類型圖像的區域.所以,作者們提出的單類GAN(One-class GAN,OCGAN)通過一種梯度上升的方法,主動地探索并消除中間層特征空間內能解碼成其他圖像的區域.但畢竟中間層特征向量的空間維度較高,通過這種探索式的策略很難全部覆蓋到,這種利用梯度上升的方法可能僅能優化原始特征向量分布區域附近的空間.而且OCGAN 在CIFAR-10 數據集上的實驗表明該方法在較為復雜的圖像異常檢測任務中優勢并不明顯.
此外,在某些正常樣本數量也極少的情況下,經典的重構網絡可能會出現過擬合等問題.而GAN也可能無法獲得生成多樣化數據的能力,因為GAN本身就是一個需要大量數據進行訓練的模型,當數據量不足時會嚴重影響其圖像生成的能力.因此,Lu 等[147]借助了小樣本學習中元學習[148]的思想來進行異常圖像幀的檢測.作者預先在多個數據集上進行元訓練,來得到一組有良好通用性的重構網絡權重.而對于新的異常檢測環境,僅需要少量正常圖像進行幾次梯度下降優化就能得到最適合目標場景的檢測模型.
圖像重構類方法借助重構后的圖像,無需采用滑窗或者逐區域分析的方法就可以高效地實現異常區域的定位.
不過,圖像重構類方法也有許多值得進一步研究的內容,如正常區域重構誤差的問題.由于瓶頸結構的存在,在重構過程中很容易丟失圖像細節,導致在重構前后圖像比較過程中在正常圖像區域出現較大的差異,現有方法往往難以解決這一問題,這一點在結構復雜多樣的醫學圖像中尤為顯著,如圖25 所示虹膜和眼底圖像,矩形框代表著存在異常的區域.可以看到重構前后的圖像在正常區域內也存在較大的差異,特別是在具有細致紋理的區域.因此也有方法不直接從像素級別的重構誤差進行分析,Xia 等[149]針對的是圖像語義分割中的異常檢測任務,在利用GAN 將分割結果重構成正常圖像后,通過比較重構前后圖像特征間的余弦距離來定位異常目標.
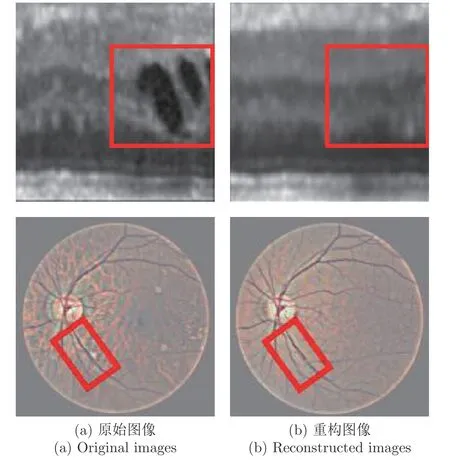
圖25 醫學圖像的重構[16,142]Fig.25 Reconstruction of medical images[16,142]
此外還有如何進行大尺度下精細重構的問題.上述許多方法在處理大分辨率圖像時大多都會將原圖縮放至較小的分辨率,此時對于異常較為明顯的自然圖像而言影響不大,但對于如圖26 所示面積占比極小的異常而言,縮放后不僅在原圖中難以觀測,而且定位過程容易受到正常區域重構差異的影響.而這種小面積異常區域的檢測在工業領域內又有較高的需求,因此如何實現大尺度下圖像的精細重構或許是值得進一步研究的內容.

圖26 工業圖像中的微小異常[146]Fig.26 Tiny anomaly in industrial image[146]
2.2.4 結合傳統方法的異常檢測方法
結合傳統方法和深度學習來進行異常檢測的方法,大部分是借助神經網絡來實現特征提取,然后通過傳統方法對圖像特征進行快速分類以實現圖像異常檢測.Gupta 等[150]借助用ImageNet 預訓練的網絡作為特征提取器,然后借助OC-SVM 實現對異常圖像的分類.Napoletano 等[151]對網絡提取到的特征利用主成分分析[152]和聚類算法構建特征向量的字典來進行異常檢測.Wang 等[82]在利用預訓練網絡進行特征提取的基礎上,使用多個超平面和子空間以獲得比OC-SVM 更加貼合正常樣本分布的決策邊界.
上述這些方法相比于人工設計特征具有更好的效果,不過在自然圖像數據集上預訓練的網絡或許并不適合其他類型比如工業圖像和醫學圖像,在這種情況下就需要利用目標類型的數據集對網絡進行特征提取的訓練.常用的方式是先利用自編碼器進行特征提取,然后計算與正常樣本特征向量之間的歐氏距離[153]以進行異常檢測.Sun 等[154]利用稀疏編碼來學習變分自編碼器隱藏層特征向量的表示方法,通過特征向量的重構誤差來進行異常檢測.Alaverdyan 等[155]在自編碼器的基礎上結合暹羅網絡的思想進行訓練,在重構輸入圖像的同時減小隱變量之間的距離,隨后在特征圖上構建OC-SVM以實現異常區域的定位.Burlina 等[156]提出了一種更為通用的檢測框架,除了使用預訓練的網絡,還結合GAN 作為生成式特征提取器,而對于得到的圖像特征,則采用OC-SVM 或者孤立森林[157]等傳統方法進行異常圖像檢測.Kozerawski 等[158]則是利用遷移學習的方法學習了從圖像特征向量到支持向量機(Support vector machine,SVM)決策面的映射,然后僅使用一張正常圖像就可以得到SVM的分類面實現異常檢測.
大部分上述方法在決策階段采用了傳統的方式,在檢測速度上會優于深度學習的方法,相比于傳統異常檢測方法則有更高的精度和更好的通用性.然而,這類方法在檢測精度上要遜于最新的深度學習方法,所以有一種方式是在現有深度學習方法的基礎上,在模型訓練過程中結合傳統方法來進一步提升檢測的精度[159],如Nie 等[160]采用高斯混合模型對自編碼器隱變量的分布進行建模,在并不顯著影響算法效率的同時提升了模型對全局異常的檢測能力.
表3 總結了各類基于深度學習的圖像異常檢測方法的設計思路和優缺點.整體來看,這些方法得益于神經網絡強大的學習能力,可以適用于各種紋理和結構下圖像的異常檢測,因此在檢測精度和通用性上要明顯優于傳統方法.不過相對應的,這些方法也更為復雜,需要設計各種策略來保證網絡的順利訓練.

表3 基于深度學習的圖像異常檢測技術的分類和特點Table 3 The classification and characteristic of deep learning based image anomaly detection
3 圖像異常檢測數據集
圖像異常檢測相關的研究方興未艾,目前有許多識別定性異常的相關文章是在傳統圖像分類數據集上開展的,諸如MNIST[89]、Fashion-MNIST[28]、CIFAR-10[90]等等.而對于定量異常的檢測任務,所使用的數據集就與具體的應用領域相關,如表4所示.

表4 圖像異常檢測常用數據集Table 4 Common datasets for image anomaly detection
在工業外觀檢測領域,對于織布檢測,常用的有TILDA (Textile texture database)[161]和PFID(Patterned fabric image database)[162]等數據集.TILDA 是最為常用的織布圖像數據集之一,包含8 種代表性的紋理圖像總計3 200 張,每種圖像提供了正常圖像和7 種缺陷圖像,不過沒有提供像素級的標注.PFID 則是由香港大學提供的一個包含3種花紋織布的圖像數據集,每種圖像都提供了數十張正常和異常圖像,并且進行了像素級的標注.對于金屬表面檢測,有MT (Magnetic tile defect datasets)[163]、RSDDs (Rail surface discrete defects datasets)[164]和NEU (Northeastern university surface defect database)[165]等.MT 數據集包含5 類從不同光照條件下采集到的磁瓦表面缺陷圖像,每類包含數十張缺陷圖像并且提供了像素級的標注,同時提供了大量的正常圖像作為參考.RSDD 則是一個鋼軌表面缺陷數據集,包含兩類圖像共計195 張并且提供了像素級標注.NEU 包含了6 類圖像,每類有300 張熱軋帶鋼表面缺陷圖像,不過僅以邊界框(bounding box)的形式提供標注,Zhou 等[166]則是為其提供了像素級的標注.而NanoTWICE (Nanocomposite nanofibres for treatment of air and water by an industrial conception of electrospinning)[71]是一個常用的納米材料圖像數據集,包含45 張利用掃描電子顯微鏡得到的納米材料圖像,其中5 張為正常圖像,其余40 張則帶有各種缺陷并且提供了像素級的標注.MVTec AD (MVTec anomaly detection dataset)[146]是一個綜合了工業生產中各種常見材質的圖像異常檢測數據集,包含了5 種紋理圖像和10 種物體圖像,每種圖像包含60 至320 張正常圖像以及幾十張帶有異常區域的測試圖像,并且提供了像素級的人工標注,常用于異常定位方法的驗證.而在醫學領域,有BraTS (Brain tumor image segmentation benchmark)[167]和AMD (Age-related macular degeneration)[168]等.BraTS 包含一共65 張低級別和高級別神經膠質瘤的多模態核磁共振圖像,并且提供了精細的人工標注.AMD 是杜克大學整理的一個針對老年性黃斑病變的大型圖像數據集,包含來自115 個正常眼部和269 個患者眼部的總計38 400張譜域光學相干層析掃描圖像(Spectral domain optical coherence tomography,SD-OCT),并且提供了精細的像素級標注.而對于高光譜圖像則有AVIRIS (Airborne visible infrared imaging spectrometer)[169]、ABU (Airport-beach-urban)[170]等常用數據,囊括了海岸、城市和機場等各種場景的高光譜圖像.
除了上述這些數據集,還有很多相關的數據集,但限于篇幅等原因此處不再展示.而MVTec AD雖然剛剛于CVPR2019 上提出但已經有許多相關方法在其上進行了實驗,如表5 所示.
表中受試者工作特性曲線下面積(Area under receiver operating characteristic curve,AUROC)和區域重疊分數(Per-region-overlap score,PROscore)是常用的兩個衡量異常定位效果的指標[171].AUROC 中的ROC(Receiver operating characteristic curve,ROC)是模型在不同分類閾值下真陽性率和假陽性率的變化曲線,而AUROC 是一個整體的評價指標,越高說明其模型分類效果越好.不過有文獻[97]指出AUROC 對于一些面積較大的缺陷會比較寬容,因此提出了PRO-score.PRO-score同樣也是在一系列閾值下構建性能曲線,并以曲線下面積作為綜合評估指標.不同的是,PRO-score統計的是不同閾值下的區域重疊率(Per-regionoverlap,PRO),PRO 是以二值化后連通域和真值圖之間的相對重疊率作為每一個閾值下的模型分類性能.從表5 中可以看到,許多方法采用圖像重構或者距離度量的方式進行異常區域的定位.雖然前者在速度上更有優勢,但精度上往往不如距離度量類的方法,這可能是源于圖像重構對圖像細節的丟失,也有可能是自編碼器容易殘留異常區域的問題所導致的.而基于距離度量類的方法則沒有上述這些潛在的問題,特別是Defard 等[171]所提出的方法在兩個指標上都實現了最高的性能.但從實際的檢測結果來看,該方法速度較慢,而且會更傾向于提高召回率,在精準率上的優勢并不明顯,特別是在一些微小缺陷的檢測上往往因為異常區域的響應值較低而導致較多的誤檢現象,這也表明基于距離度量的方法對于一些微弱異常的檢測效果還有待提升.

表5 各圖像異常定位方法在MVTec AD 上的性能Table 5 Performance of image anomaly localization methods on MVTec AD
4 圖像異常檢測問題面臨的挑戰
異常檢測一般是在沒有真實異常樣本的情況下進行模型訓練,這種特點使得異常檢測任務面臨著不小的挑戰.
1)異常樣本的未知性.在異常檢測當中,一般僅有正常樣本可供使用,由于異常樣本的未知性,傳統的基于監督學習的目標識別算法難以直接應用到異常檢測領域當中.這使得研究人員需要設計新的模型建立方法或者網絡訓練方法來進行異常檢測.而且僅利用正常樣本訓練得到的異常檢測模型對實際異常樣本的檢測還存在一定的風險,依然可能會遺漏一些人眼認為較為顯著的異常目標.
2)異常定義的不清晰.由于僅擁有正常樣本,對于異常的定義存在一定的難度,比如異常程度到多少為異常,如果設定太過嚴苛,可能會導致很多因噪聲而產生的誤檢出現,而如果太過寬松又會使得一些較微弱的異常項被判定成正常.但又缺乏足夠的真實異常樣本來輔助這一決策過程,使得現階段檢測方法往往較為嚴苛,容易出現較多的誤檢區域.
3)微弱異常的定位.如第2 節所說,圖像異常檢測一般有分類和定位兩個類型.對于異常圖像分類任務來說,異常樣本和正常樣本之間存在明顯差異.利用人工設計的特征或者預訓練好的神經網絡進行特征提取就有望將兩者的特征向量區分開.但是對于異常定位任務而言,圖像中一般只有一部分區域出現了異常,而且經常會出現面積較小的目標,比如在工業外觀檢測過程中可能會出現寬度僅有7個像素的細微異常區域,也可能會出現一些對比度較弱的異常區域[146].在高光譜圖像異常檢測或者醫學圖像中病變區域的定位中,目標區域的面積一般都只占整張圖像很小的比例,使得異常區域的定位較為困難.
4)維數災難.異常檢測是一個從數據挖掘領域中發展而來的概念,因此早期的方法也大多是針對低維數據設計的[79,81],而這些方法在面臨高維數據時其檢測性能會受到嚴重影響.而圖像數據是一個典型的高維數據,即便是最為基礎的Mnist 數據集,如果僅僅是直接地將其轉換成向量也會形成長達784 維的向量,這使得一些在數據挖掘中常用的異常檢測算法很難直接用于圖像數據.
5)算法的通用性.不同類型的圖像數據差別很大,其實際檢測的目標也不盡相同,導致現階段許多異常檢測算法是針對某一類圖像而開發的.較低的通用性使得現有算法難以應用到新的圖像類型當中.
5 展望
本文對近年來圖像異常檢測方法的發展狀況進行了回顧,可以看到針對這一問題已經有了一定數量的研究.關于未來可能的研究方向,我們認為可以從以下幾個角度進行考慮:
1)構建更為高效的異常檢測算法.對于異常檢測而言,不僅僅需要對待檢圖像進行正常與否的判斷,往往還需要對異常區域進行定位.比如工業圖像表面的缺陷檢測,醫學圖像中病變區域的定位等等.然而,由于在訓練階段沒有任何關于異常區域的標注信息,傳統的目標檢測或者圖像分割的方法無法直接應用到異常檢測任務中.因此,現有的方法大多采用的是將待檢圖像切分成一系列的圖像塊,然后分塊進行異常與否的二分類來進行異常區域的定位.而且,為了獲得異常區域的準確輪廓,這種切分的步長一般較小,會顯著影響算法的效率.現有的一些方法比如頻譜分析雖然能夠同時處理整張圖像以實現高效的定位,但該方法對于圖像有一定的要求.而基于深度學習的圖像重構方法雖然沒有上述約束,但重構圖像中殘留的異常區域會影響后續的檢測.因此,如何兼顧檢測精度和實時性仍需進一步的探索.
2)小樣本/半監督學習.現階段的異常檢測方法大部分僅利用正常樣本來訓練模型.但是在實際檢測任務中,并不是完全無法獲取真實的異常樣本.比如在工業外觀檢測任務中,少量的缺陷樣本是可以獲取的.而且對幾張缺陷圖像進行標注并不會顯著地增加訓練成本.而且相關文獻[96]初步嘗試了在訓練過程中引入一張真實異常圖像并且獲得了一定的效果提升.因此可以考慮結合小樣本學習的方法,利用大量正常樣本和幾張真實的異常樣本來進行模型訓練以提高性能.而有些異常檢測任務面臨的是嚴格無監督的環境[98],連所用樣本是否屬于正常樣本也不可預知,此時訓練樣本中存在的少量異常樣本就會對模型的訓練產生性能上的影響,如果采用半監督的訓練方式,對少量正常和異常樣本進行標注,可以有效提升模型對潛在異常樣本的檢測能力.但是這種方法還是會面臨一些問題,比如采集到的異常樣本顯然不可能囊括所有類別,如何讓模型兼顧對已知類型和未知類型異常樣本的檢測能力,也是一個待研究的任務.
3)更自適應的樣本合成方法.在許多相關的文獻中[105,108,110]都已經證明了在模型訓練階段,引入各種人工構造的異常圖像能有效地提升檢測性能.即便構造的異常圖像與真實的異常圖像并不相同,額外增加的異常圖像可以提升分類面的貼合度或者背景重構的穩定度,這都可以增加模型對潛在異常圖像的檢測能力.但相關文獻表明這些額外的異常樣本越接近與正常樣本模型的性能越好[105].然而,相關方法中額外使用的異常圖像大多是采集自別的數據集,這些圖像一般與正常樣本的分布之間存在較為明顯的差異.雖然有方法嘗試采用梯度上升的方式合成異常圖像,但該方法在更為復雜的圖像上的結果還有待論證.因此,如何針對各種正常圖像自適應地合成異常樣本也是一個有待解決的問題.
4)輕量化網絡設計.基于深度學習的異常檢測方法得益于神經網絡強大的學習能力往往能得到比傳統方法更優秀的性能,但代價是需要更多的計算量和更長的處理時間.對于一張待測圖像,需要利用深層神經網絡提取特征向量以區分正常和異常樣本,而且重構類的方法還需要再次經過第二個深層神經網絡來重構輸入圖像.因此,更為輕量化的網絡設計能夠減少方法的運行時間.此外,大多數方法在驗證時硬件條件較好,而實際生產現場要部署同等算力的設備會需要較高的成本,因此,輕量化的網絡設計在減少計算量的同時,還能降低對硬件設備的需求,降低在實際應用中的成本.針對這一問題,現階段常用的有兩類方法:a)輕量模型設計,設計更為高效的網絡計算方法以實現減小模型體積的同時保持性能不變,例如MobileNet[175]等.也可以采用知識蒸餾的方式,用復雜網絡的輸出作為目標來訓練一個更為簡單的網絡;b)模型壓縮,有通過剪枝的方式剔除冗余的權重以減小模型大小,也有通過網絡量化的方式,以犧牲一定精度為代價減小網絡參數所占空間,其中二值化模型具有突出的壓縮性能,更利于模型部署.
5)更高精度的異常定位方法.對于異常定位任務,現有的方法大多會采用滑窗的方式將原始圖像分解成一系列小的圖像區域,然后再利用異常分類的方式對每一個區域進行異常與否的分析.這種分塊分析的方式無法精準地定位異常區域,處于異常紋理與正常紋理的交界處的圖像區域也很有可能被誤判為異常.而對于能直接定位異常的圖像重構類方法,又會因自身重構精度的限制,在正常紋理區域也會出現差異,這也會影響對一些微弱異常區域的定位效果.在醫學和工業等領域內異常目標的檢測中,不僅要關注召回率,異常檢測的精準率也十分重要.但從現有方法的效果看,許多方法主要在召回率方面性能優異,因為在實際應用領域中漏檢的危害性遠高于誤檢.但如果能夠在保證召回率的同時提高精準率,盡可能減少后續人工或者算法的二次處理,異常檢測方法將能更廣泛地應用在相關領域中.因此,如何精準定位異常區域并減少對正常圖像區域的誤判情況,同樣也是一個值得研究的問題.
6 結論
圖像異常檢測的目標是在真實異常樣本難以獲取的情況下,構建分類模型對潛在的異常圖像進行檢測.本文首先介紹了異常的定義和常見的類型.然后按照具體的檢測思路,分別對傳統的和基于深度學習的圖像異常檢測方法的發展現狀進行了綜述和分析,并且給出了未來可行的研究方向.現階段對于圖像異常檢測方法已經有了較多的研究,但依然可以在算法的檢測效率、小樣本/半監督學習以及更自適應的樣本合成方法等方面有進一步的發展.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
