基于文本內容的敏感數據識別方法研究與實現
2022-07-04 08:45:45郭玲玲
科學與財富 2022年5期

摘 要:為防止敏感數據泄密事件問題,為對敏感數據的有效訪問和管理工作建立基礎,發明并完成了基于文本內容的敏感數據識別技術。經過對敏感數據庫系統和已知秘密文件數據庫系統的深入研究,實現了通過設定文本內容的敏感數據辨識閾值,進而確定未知文本內容是否存在有敏感數據。并介紹了文字預處理、文本辨識和閾值評估等工作的細節設計與完成流程等。而通過識別數據庫中的一些相關文檔,可確保該方法的敏感數據的處理過程簡單、實用、準確。
關鍵詞:文本內容; 敏感數據 ;識別方法
目前,防范數據泄漏的方式主要可以分成三種:安全審計、安全控制和文件加密【1】。其中,敏感數據辨識技術在防范信息泄漏的安全管理中起了關鍵作用。一旦可以智能地辨識并保存從內部互聯網發送到外部網絡上的加密信息,則能夠大大簡化自動辨識或訪問控制規則的復雜度,從而有效地避免了敏感數據出現風險的概率。
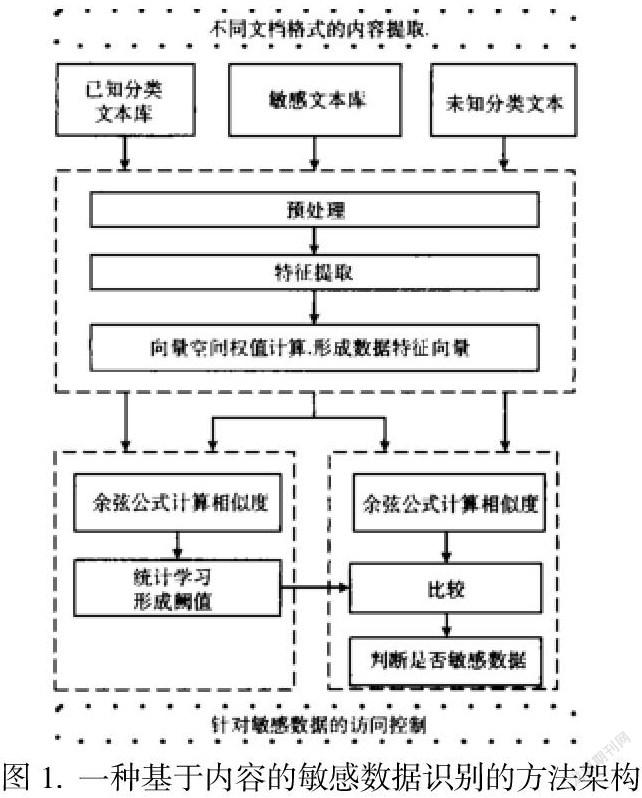
一、體系結構
文字類型可包括如下過程:首先,創建數據集合,包含培訓集和測試集。接著創建文字表示模式,確定文字類型。然后學習訓練集,并構建分類器。最后,進行試驗與性能評價。
本文的資源收集項目主要涵蓋了培訓集和測試集,也涉及了敏感文本庫和已有的文本庫。敏感的數據庫系統中,通常包括了大量的敏感數據文件,主要用于機器學習。而目前已知的分類數據庫系統通常由2種小詞庫構成,一類是加密數據,另一類則不是加密數據,主要用來生成在統計學習時是否產生了敏感數據的閾值。
主要實現過程如下:
主要實現流程如下:
1.通過對敏感數據空間的文本數據庫進行預處理和特征提取,TFIDF算法能夠預測向量空間的權重,進而產生數據特征向量。
2.用敏感數據形成的特征向量計算余弦,并根據閾值確定方法確定閾值。
二、功能組成
21預處理方法
在識別文本敏感數據的過程中,第一步是通過中國科學院中文方法分析系統預處理階段ICTCLAS,將文本分為單獨的短語,并標注詞性、詞長和詞頻,以促進特征的提取效率。
通過ICTCLAS分詞界面,分詞文件,統計單詞長度,標記詞性,如名詞(n)、動詞(v)、形容詞(a)等。
2特征提取
在文本學習與分析的過程中,若以所有詞性分詞為關鍵詞,由于計算工作量大,且冗余數據太多,后期的計算誤差也較大。
(1)詞性選擇
在文本中,可以按照詞性選取最能代表文章內容的關鍵字,也可以用于后期特征提取,可以減少信息冗余,縮短運算步驟。因此,可以提取分析文本短語中的名詞短語,并剔除其他單詞,進行詞性選擇。
(2)詞頻統計
統計關鍵詞的頻率,形成分詞三元組,包括短語、短語在本文中的頻率和詞性。T加上一個詞頻項,進行進一步表示。
(3)選擇單詞長度
在文字中,漢字往往比詞匯更有表現力。計算每個關鍵詞的長度,并刪除一個單詞的所有關鍵詞。
(4)詞頻選擇
在文本中,只出現一次的單詞都是偶然的,并不具備代表性,所以可以從統計后的文本分割三元組中,刪去只出現一次的短語。
2.3計算特征向量
2.3.1計算敏感數據的特征向量
計算單詞權重也是度量特征值的有效方式。目前,基于統計方法的TF-IDF公式已經獲得了廣泛的運用,并且已經在大量的現實應用中被證實是合理和高效的。核心思想是一個詞語如果在其他文獻中出現的數量越少,含有的信息就越多,越能代表文獻的類型。反之,一旦在其他文獻中大量出現,這個詞語就不具備代表性。
2.5閾值確定方法
通過對比計算結果與閾值,并分析余弦的相似性,將有助于確定文檔是否對數據敏感。因此本文將通過研究現有的分析文獻來判斷閾值。先得到安全文檔和敏感文件的詞庫,接著再處理和統計敏感詞集的余留部分。然后,再經過定義相同范圍的閾值,才能確定對數據的最敏感,并由此定義失敗率最并且最能保證未知秘密文件閾值的方式。
三、具體的應用
(1)建立數據庫
該系統還能夠通過改變數據集中訓練庫的文本數據類型,來辨識在不同環境下的敏感數據。
(2)預處理和特征選擇
數據說明,在特征選擇過程中,詞類選取后滿足關鍵詞要求的比率約為百分之三十,而字長法選取后滿足關鍵詞要求的比率約為27%,而字頻分析法選取后滿足關鍵詞要求的比率約為10%。冗余分詞比率將逐步減小,而后續的運算過程也將越來越簡化【2】。
(3)計算特征向量
根據獲得的關鍵字,通過TFIDF算法計算,用向量表示敏感數據,獲得敏感數據的特征向量V。
(4)計算已知分類和敏感數據的余弦值
已知分類文檔的特征向量計算的相同量的敏感數據,和無敏感數據或敏感數據的特征向量V余弦之間的最大相似度值。獲得余弦相似度值,就必須找尋出它們之間的排列順序。
(5)確定閾值
以長度范圍為單位,從值的底部開始,每次添加一個范圍單位,將每個值設置為一個閾值,并計算在該閾值環境中判斷的錯誤率。計算后,將最低錯誤率作為實際閾值。
(6)閾值用于識別敏感文檔
根據上述定義的閾值,對所有在未知文件庫中的文件都進行了預處理和分析,并獲取了基于敏感數據的特征向量。使用了對敏感數據的特征矢量運算后,就能夠使用余音運算得到相應的結果。余弦運算基本原理主要包括:根據結果可確定的錯誤閾值為0.7,并統計未知文檔庫的錯誤識別情況和60.45%的錯誤率。
(7)性能測試
提升對文本內容的敏感數據的識別率,提升識別的效率,簡化識別的過程,節約識別的時間,促進文本敏感數據識別技術的發展。
結語:
綜上所述,本文主要研究了一個基于詞性、詞頻和詞長的簡便有效的文本特征提取方式,利用智能技術來自動設定閾值,來確定對文本中是否存在有的數據敏感。該方式較以往自動設定閾值的方式,更為實用、精確、靈活。該方法既可有效地避免數據泄漏的問題,同時也可以更高效地實現對敏感數據的甄別與訪問控制。在文件識別處理過程中,由于機器學習數據庫大小和待處理文件長度的提高,處理效能也將大大提高,但是要求也會同時提高,因此唯有通過對技術加以持續地提高與發展,并同時持續地加以完善與優化,才可以緊跟新時代的發展腳步,從而有效地識別處文本內容中的敏感數據,為后續的工作打下一個堅實的基礎,促進我國文本識別技術的發展【3】。
參考文獻:
[1]林臻彪.基于數據流分析的防文件網絡泄露關鍵技術研究[D].鄭州:解放軍信息工程大學,2009.
[2]李曉紅.中文文本分類中的特征詞抽取方法[J].計算機工程與設計,2009,30 ( 17>:4127-4129.
[3]劉蔚琴.網絡敏感信息監控系統研究[D].廣州:廣東工業大學,2008.
作者簡介:郭玲玲,出生年月:1987.2,性別:女,籍貫(精確到市):安徽省宿州市,民族:漢,學歷 :本科,職稱職務:工程師,研究方向:敏感信息檢測。
