基于注意力機制的多任務(wù)漢語關(guān)鍵詞識別
2022-07-06 08:56:01何振華胡恒博金鑫安達李靜濤
現(xiàn)代信息科技 2022年6期
何振華?胡恒博?金鑫?安達?李靜濤


摘? 要:為了提高語音關(guān)鍵詞識別的性能,在無自動語音識別的端到端關(guān)鍵詞識別模型的基礎(chǔ)上,使用了軟注意力機制并結(jié)合多任務(wù)訓(xùn)練的方式對其進行了改進。改進后的基于注意力機制的關(guān)鍵詞識別模型由四部分構(gòu)成,關(guān)鍵詞嵌入模塊和聲學(xué)模塊使用軟注意力來得到特征向量,判別器模塊和分類器模塊輸入特征向量來進行關(guān)鍵詞識別。實驗結(jié)果表明,改進后模型的準(zhǔn)確率分別比基線模型和傳統(tǒng)的關(guān)鍵詞檢索方法高出37.3%和3.1%。
關(guān)鍵詞:關(guān)鍵詞識別;注意力機制;多任務(wù)訓(xùn)練
中圖分類號:TP183? ? ? ? 文獻標(biāo)識碼:A文章編號:2096-4706(2022)06-0082-05
Keyword Recognition of Multi-Task Chinese Based on Attention Mechanism
HE Zhenhua1, HU Hengbo1, JIN Xin2, AN Da2, LI Jingtao1
(1.Zhengzhou Xinda Institute of Advanced Technology, Zhengzhou? 450000, China; 2.China Railway Beijing Group Co., Ltd., Beijing? 100036, China)
Abstract: In order to improve the performance of speech sounds keyword recognition, this paper uses the method of soft-attention mechanism and combines multi-task training method to improve it based on the end-to-end keyword recognition model without automatic speech sounds recognition. The improved keyword recognition model based on attention mechanism consists of four parts. Keyword embedded modules and acoustic modules use soft attention to obtain the feature vectors, and the discriminator modules and classifier modules input the feature vectors for keyword recognition. Experimental results show that the accuracy of the improved model is 37.3% and 3.1% higher than the baseline model and the traditional keyword retrieval methods respectively.
Keywords: keyword recognition; attention mechanism; multi-task training
0? 引? 言
關(guān)鍵詞識別(Keywordspotting)指在從連續(xù)的音頻流中檢查出是否有預(yù)定義的關(guān)鍵詞[1]。根據(jù)是否使用了傳統(tǒng)的關(guān)鍵詞識別方法,可分為兩類:第一類為傳統(tǒng)的關(guān)鍵詞識別方法,即基于大詞匯量連續(xù)語音識別的關(guān)鍵詞檢索[2],第二類方法為基于神經(jīng)網(wǎng)絡(luò)的關(guān)鍵詞識別方法。傳統(tǒng)的方法通常先將待檢測的音頻通過自動語音識別識別來生成一種特殊的詞格,然后在詞格上面進行關(guān)鍵詞搜索以檢測是否有預(yù)定義的關(guān)鍵詞。基于神經(jīng)網(wǎng)絡(luò)的關(guān)鍵詞識別方法則是直接使用由神經(jīng)網(wǎng)絡(luò)構(gòu)成的關(guān)鍵詞識別模型進行關(guān)鍵詞識別,例如[3-6]。此外,文獻[1]中使用了卷積循環(huán)神經(jīng)網(wǎng)絡(luò)(Convolutional Recurrent Neural Network, CRNN)模塊加上連接時序分類(Connectionist Temporal Classification, CTC)[7]訓(xùn)練損失對不同組合方式的普通話輸入進行了關(guān)鍵詞識別,其中的四種CTC標(biāo)簽分別為:關(guān)鍵詞標(biāo)簽、非關(guān)鍵詞標(biāo)簽、句子中每個字的間隔標(biāo)簽、CTC的blank標(biāo)簽。關(guān)鍵詞標(biāo)簽中使用了字和音調(diào)的組合以獲得最好的結(jié)果,關(guān)鍵詞以外的全部字則被設(shè)為非關(guān)鍵詞標(biāo)簽。模型訓(xùn)練結(jié)束后,對模型輸出的結(jié)果去重后即可進行關(guān)鍵詞識別。另外,Audhkhasi等人[8]提出了一種使用較少監(jiān)督進行關(guān)鍵詞識別的方法,模型中分別用聲學(xué)模型和字符級語言模型得到輸入音頻和關(guān)鍵詞的嵌入向量表示,然后送入前饋網(wǎng)絡(luò)中預(yù)測關(guān)鍵詞是否出現(xiàn)在輸入音頻中,模型中的聲學(xué)模塊和字符級語言模型模塊都采用無監(jiān)督的方式進行訓(xùn)練,模型的標(biāo)簽也只有1/0分別表示所需檢測關(guān)鍵詞是否出現(xiàn)在需要檢測的句子中,整個模型的訓(xùn)練用到較少的監(jiān)督標(biāo)簽,并沒有對音頻進行標(biāo)注。本文以此模型對應(yīng)的方法作為基線系統(tǒng)并對其進行進一步的改進。
在文獻[8]中,其聲學(xué)模塊是由聲學(xué)自動編碼器組成。聲學(xué)自動編碼器[9]中的編碼器將輸入的音頻特征進行信息壓縮得到代表整個輸入音頻的嵌入向量表示,然后再將此嵌入向量送入聲學(xué)自動編碼器中的解碼器中,以輸出重建的輸入音頻,聲學(xué)模塊使用最小均方誤差損失來進行訓(xùn)練。由于在對輸入音頻特征進行信息壓縮的過程中會有信息損失,而且對于關(guān)鍵詞識別,并不需要輸入音頻中所有的信息,而只需要包含有關(guān)鍵詞信息的那部分信息。故只需要關(guān)注整個輸入中對關(guān)鍵詞識別有用的信息,而不再需要對整個輸入音頻特征進行信息壓縮。注意力機制是一種聚焦于局部信息的機制,可以被用來從眾多信息中選擇出對當(dāng)前任務(wù)目標(biāo)更關(guān)鍵的信息,受此啟發(fā),可以使用注意力機制對輸入音頻進行處理以得到關(guān)鍵詞識別中所需的信息。B86FCB7B-49CA-44AB-8AD0-41E3BF54ADD1
本文改進了一種基于注意力機制的關(guān)鍵詞識別方法。使用注意力機制得到融合了關(guān)鍵詞和輸入音頻特征的嵌入向量,然后再將嵌入向量送入前饋神經(jīng)網(wǎng)絡(luò)進行關(guān)鍵詞識別。
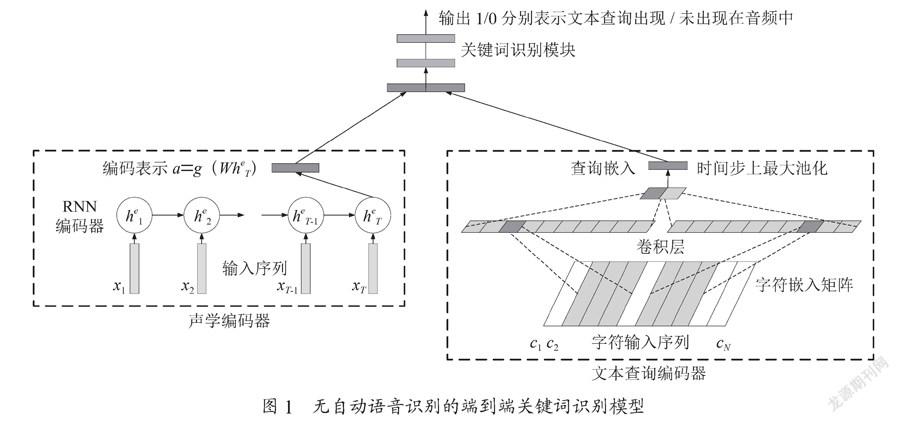
1? 無自動語音識別的端到端關(guān)鍵詞識別
該模型的輸入為待檢測的文本格式關(guān)鍵詞和待檢測音頻的特征,輸出為1/0表示關(guān)鍵詞是否出現(xiàn)在音頻中。模型結(jié)構(gòu)如圖1所示,該模型由三部分構(gòu)成。聲學(xué)編碼器將音頻特征進行壓縮以得到代表輸入音頻的編碼表示向量,文本查詢編碼其將輸入的文本格式關(guān)鍵詞進行嵌入、卷積和池化操作得到對應(yīng)的查詢嵌入,最后對這兩個向量進行拼接并送入到前饋神經(jīng)網(wǎng)絡(luò)中輸出識別結(jié)果。
聲學(xué)編碼器是訓(xùn)練過后的聲學(xué)自動編碼器的編碼器部分。聲學(xué)自動編碼器輸入音頻特征,然后輸出重建后的輸入音頻特征。其實由兩個循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network, RNN)組成:一個編碼器、一個解碼器。RNN編碼器逐步輸入音頻特征(x1,x2,…,xT)并更新對應(yīng)的RNN內(nèi)部單元狀態(tài),直接輸入xT更新對應(yīng)的狀態(tài)后將隱含層狀態(tài)作為整個輸入特征的表示,然后對進行非線性轉(zhuǎn)換以使得聲學(xué)向量表示和文本向量表示在相同的嵌入空間中,并將此向量作為輸入特征。最后,將送入RNN解碼器的每個時間步上,并依次輸出對應(yīng)時間步上的重建特征。聲學(xué)自動編碼器在使用最小均方誤差損失進行訓(xùn)練之后去除解碼器之后便得到了聲學(xué)編碼器[10]。
文本查詢編碼器是由字符級語言模型[11]經(jīng)過訓(xùn)練后得到的。字符級語言模型輸入字符序列,然后輸出下一個預(yù)測的字符。其由三部分構(gòu)成:嵌入向量矩陣,一維卷積神經(jīng)網(wǎng)絡(luò),RNN語言模型。給定n個字符c=(c1,c2,…,cn),每個字符經(jīng)過d×N的嵌入向量矩陣的嵌入后得到n個嵌入向量d=(d1,d2,…,dn),然后使用M個d×w的卷積核對向量d進行一維卷積得到M個對應(yīng)的一維卷積向量,對這M個向量進行最大池化后得到一個維度為M的嵌入向量q,最后將q送入到RNN語言模型中以輸出待預(yù)測的下一個字符。由于RNN語言模型只輸入向量q來預(yù)測下一個字符,因此可以用向量q作為文本輸入序列的表示。字符級語言模型使用交叉熵損失進行訓(xùn)練,訓(xùn)練完之后去除掉RNN語言模型便得到了文本查詢編碼器。
前饋神經(jīng)網(wǎng)絡(luò)是由兩層神經(jīng)網(wǎng)絡(luò)構(gòu)成的。在得到了輸入音頻特征表示a和文本向量表示q之后,首先對這兩個向量進行拼接,然后再將拼接后的向量送入到前饋神經(jīng)網(wǎng)絡(luò)中進行預(yù)測,結(jié)果輸出1/0分別表示關(guān)鍵詞是否出現(xiàn)在音頻中。
軟注意力機制是一種根據(jù)某些額外的query信息中從向量表達集合values中提取特定的向量進行加權(quán)組合的方法。軟注意力值可以分為兩步得到,先根據(jù)query信息在所有的向量表達集合values上計算注意力分布,然后根據(jù)注意力分布來計算向量表達集合values的加權(quán)平均。
具體來說,對于第一步,給定query向量q和values向量X=(x1,x2,…,xn),可以使用兩個向量之間的點積運算結(jié)果來得到注意力打分分數(shù):s =(s1,…,si,…,sn),其中,然后使用softmax函數(shù)來得到注意力分布:a=(a1,…,ai,…,an),其中ai表示向量q和xi的相關(guān)聯(lián)程度:
(1)
對于第二步,則是將第一步得到的注意力分布a中的每個注意力得分ai分別乘上對應(yīng)的xi,然后將相乘加權(quán)后的向量全部相加得到注意力值:
(2)
在無自動語音識別的端到端關(guān)鍵詞識別模型中,為了更有效地得到輸入音頻中與關(guān)鍵詞識別相關(guān)的信息,我們可以使用軟注意力機制將文本向量表示q作為query向量,將輸入音頻的特征作為values向量,經(jīng)過運算操作后得到注意力值然后送入到前饋神經(jīng)網(wǎng)絡(luò)中進行關(guān)鍵詞識別。
2? 基于注意力機制的多任務(wù)關(guān)鍵詞識別模型
該模型有兩個輸入X1,X2和兩個輸出Y1,Y2,X1為文本格式的關(guān)鍵詞,X2為音頻話語,Y1輸出1/0表示關(guān)鍵詞輸入是否出現(xiàn)在輸入的音頻話語中,Y2輸出被檢測關(guān)鍵詞的分類概率。模型在推理時則只需輸出Y1來得到最終的識別結(jié)果。
模型由四部分組成:(1)關(guān)鍵詞嵌入模塊,用來得到關(guān)鍵詞嵌入向量。(2)聲學(xué)模塊,使用注意力機制融合關(guān)鍵詞嵌入向量和音頻特征序列來得到特征向量。(3)判別器模塊,輸入特征向量進行關(guān)鍵詞識別。(4)分類器模塊,輸入特征向量進行關(guān)鍵詞分類。模型結(jié)構(gòu)如圖2所示。
2.1? 關(guān)鍵詞嵌入模塊
為了更有效地得到注意力機制中的關(guān)鍵詞query向量,與文本查詢編碼器不同的是,沒有訓(xùn)練字符級語言模型的環(huán)節(jié),我們直接將每個關(guān)鍵詞進行嵌入操作得到關(guān)鍵詞query向量。關(guān)鍵詞嵌入模塊中的關(guān)鍵詞輸入經(jīng)過兩個步驟得到嵌入向量:首先,N個關(guān)鍵詞k1,k2,…,kN-1,kN經(jīng)過嵌入矩陣E后得到對應(yīng)的嵌入向量e1,e2,…,eN-1,eN,為了使關(guān)鍵詞的嵌入向量和音頻特征序列向量在同一模態(tài)空間中以更好的進行后續(xù)的注意力運算,關(guān)鍵詞嵌入模塊使用線性變化q=g(We)來得到處理后的關(guān)鍵詞嵌入向量,其中g(shù)為LeakyRelu(LeakyRectifiedLinearUnit)函數(shù),W為線性層。
2.2? 聲學(xué)模塊
聲學(xué)模塊由CRNN模塊和注意力模塊兩部分構(gòu)成。CRNN模塊從輸入音頻特征中提取出輸入音頻的高層特征,Attention模塊則使用注意力機制將關(guān)鍵詞嵌入向量和音頻輸入高層特征進行融合。
2.2.1? CRNN模塊
CRNN模塊由m個卷積神經(jīng)網(wǎng)絡(luò)(ConvolutionalNeural Network, CNN)層和n個循環(huán)神經(jīng)網(wǎng)絡(luò)(RecurrentNeural Network, RNN)層組成。CNN層中的CNN有權(quán)重共享和局部感受野的特點,可以用來捕獲局部相關(guān)性,且在最后一層使用了最大池化(MaxPooling)用來減少后續(xù)的計算量,使得所需提取的特征更加突出明顯。RNN層只包含用來獲得上下文相關(guān)性的雙向RNN網(wǎng)絡(luò)。CRNN模塊使用了批歸一化(BatchNormalization)層用來加速訓(xùn)練,激活函數(shù)則使用了LeakyRelu。模塊的最后使用線性層來對雙向RNN網(wǎng)絡(luò)的隱含層輸出做變換,以使得CRNN模塊輸出的音頻高層特征和關(guān)鍵詞嵌入向量在同一嵌入空間中。B86FCB7B-49CA-44AB-8AD0-41E3BF54ADD1
2.2.2? 注意力模塊
注意力模塊使用注意力機制從高層聲學(xué)特征中提取與關(guān)鍵詞相關(guān)的信息。注意力模塊的計算過程如下:關(guān)鍵詞嵌入向量為qi,i∈(1,2,…,N-1,N),音頻輸入特征X=x1,x2,…,xT進入CRNN模塊后得到的高層特征為V=v1,v2,…,,用qi對V中的每一個特征向量做內(nèi)積得到權(quán)重向量d=(d1,d2…),其中:
(3)
d中的每個常數(shù)表示關(guān)鍵詞嵌入向量qi與每個高層特征v的關(guān)聯(lián)性大小。d經(jīng)過softmax處理得到對應(yīng)的權(quán)重向量s=s1,s2…:
(4)
然后將s中的每一個權(quán)重乘上對應(yīng)的高層特征v得到加權(quán)后的C其中,最后將C中每列的特征向量進行相加得到融合了關(guān)鍵詞嵌入向量和高層特征向量的向量a,即:
(5)
2.3? 判別器模塊
因向量a融合了關(guān)鍵詞嵌入向量信息和音頻特征信息,判別器模塊直接將向量a作為輸入以進行關(guān)鍵詞識別,輸出范圍為0-1的置信度得分以表示關(guān)鍵詞是否出現(xiàn)在音頻句子中。判別器模塊是由兩個線性層后接LeakyRelu激活函數(shù)后再加上了sigmoid激活函數(shù)組成。
2.4? 分類器模塊
為了更好地利用模型輸入的關(guān)鍵詞信息以輔助進行關(guān)鍵詞識別,我們可以將融合了關(guān)鍵詞嵌入向量信息和音頻特征信息的a送入分類器模塊中輸出關(guān)鍵詞分類結(jié)果。分類器模塊是由兩個線性層后接LeakyRelu激活函數(shù)后再加上softmax激活函數(shù)組成。基于注意力機制的多任務(wù)關(guān)鍵詞識別模型如圖2所示。
3? 實驗
3.1? 實驗設(shè)置
3.1.1? 數(shù)據(jù)準(zhǔn)備
實驗使用了AISHELL數(shù)據(jù)集,AISHELL包含各種類型的共計178個小時的干凈普通話話語,采樣頻率為16 kHz。我們按照詞頻遞減的方法在數(shù)據(jù)集中選出了至少出現(xiàn)5次的共計15個關(guān)鍵詞。訓(xùn)練集和評估集中的每個句子至少包含有一個關(guān)鍵詞,測試集中一半的句子不止包含有一個關(guān)鍵詞,另外一半句子完全不包含有關(guān)鍵詞。
為了使模型不會受數(shù)據(jù)標(biāo)簽比例偏向性的影響,需要對判別器模塊和分類器模塊的標(biāo)簽數(shù)據(jù)進行處理。對于判別器的標(biāo)簽,需使數(shù)據(jù)中的正樣本和負樣本保持1:1的比例。具體來說,對于訓(xùn)練集和評估集,假設(shè)句子si中含有n個關(guān)鍵詞k1,k2…kn,則句子si分別與k1,k2…kn共構(gòu)成n對標(biāo)簽為1的實驗數(shù)據(jù)集S1:(si,k1),(si,k2)…(si,kn),對應(yīng)標(biāo)簽全為1。S1作為正面樣本,表示關(guān)鍵詞k1,k2…kn出現(xiàn)在句子si中。未出現(xiàn)在句子si中的剩余(15-n)個關(guān)鍵詞被隨機地選出相同數(shù)量的n個關(guān)鍵詞,同樣的,句子si分別與共構(gòu)成n對標(biāo)簽為0的實驗數(shù)據(jù)集S0:,對應(yīng)標(biāo)簽全為0。S0作為負面樣本,表示關(guān)鍵詞未出現(xiàn)在句子si中。測試集中正樣本的選取方式和訓(xùn)練與評估集相同,負面樣本則采取類似的方式由任意的關(guān)鍵詞與任意的完全不包含有關(guān)鍵詞的句子組成。對于分類器的標(biāo)簽,當(dāng)判別器的標(biāo)簽為0時,分類器的標(biāo)簽也為0,當(dāng)判別器的標(biāo)簽為1時,分類器的標(biāo)簽為對應(yīng)的關(guān)鍵詞分類標(biāo)簽。
3.1.2? 參數(shù)設(shè)置
關(guān)鍵詞嵌入模塊中嵌入矩陣E的維度為256,線性層W含有256個單元。對于聲學(xué)模型模塊,給定音頻后先對其進行幀長為25 ms,幀移為10 ms的分幀,然后對每幀取40維梅爾濾波器組特征(filterbank,fbank)并進行一階和二階差分后得到每幀120維的fbank特征。CRNN模塊中的m/n分別為2/2,CNN層中的卷積核大小都為3×4且步長都為1,而輸出通道數(shù)依次為16和32,最大池化層的池化大小都為2×2且步長都為2,RNN層中的雙向LSTM中的隱含層大小都為256,緊跟其后的線性層含有256個單元。判別器模塊中隱含層單元個數(shù)依次為256,128,1。分類器模塊中隱含層單元個數(shù)依次為256,128,16。
模型使用了Adam優(yōu)化算法,采用了多任務(wù)訓(xùn)練的方式對其進行了訓(xùn)練:記判別器輸出和對應(yīng)標(biāo)簽yk的二分類損失為,分類器輸出和對應(yīng)標(biāo)簽yc的交叉熵損失為,則總損失為。Batchsize為512,初始學(xué)習(xí)速率為0.000 1,實驗每5個epoch進行一次評估,當(dāng)評估集損失無明顯下降時,便將學(xué)習(xí)速率下降至原來的0.9,當(dāng)評估集的損失不再下降時,模型被停止訓(xùn)練以防止過擬合。該模型使用Pytorch進行實現(xiàn)。
我們用Kaldi工具完成了傳統(tǒng)方法的關(guān)鍵詞識別實驗作為對比。在實驗中,我們使用了TDNN-HMM模型,共有5層DNN,每層含有850個隱含層,其含有2 984個發(fā)射狀態(tài)。
3.2? 評估準(zhǔn)則
在本文的關(guān)鍵詞識別任務(wù)中,準(zhǔn)確率和召回率被用來衡量關(guān)鍵詞識別任務(wù)的好壞。首先定義如下統(tǒng)計量:
Nfa:虛警(FalseAlarm, FA)數(shù),即將非關(guān)鍵詞樣本檢測為關(guān)鍵詞的個數(shù)。
Nfr:拒識(FalseReject, FR)數(shù),即將關(guān)鍵詞樣本檢測為非關(guān)鍵詞的個數(shù)。
Ntt:關(guān)鍵詞樣本被檢測為關(guān)鍵詞的個數(shù)。
Nff:非關(guān)鍵詞樣本被檢測為非關(guān)鍵詞的個數(shù)。
召回率(Recall)是指識別結(jié)果中關(guān)鍵詞樣本中被正確地檢測為關(guān)鍵詞結(jié)果所占所有關(guān)鍵詞樣本的比例,其定義為:
(6)
準(zhǔn)確率(Accuracy)是指識別結(jié)果中被正確檢測的關(guān)鍵詞樣本占所有檢測樣本的比例,其定義為:
(7)
3.3? 實驗結(jié)果及分析
我們分別探究了α、β取不同值時其對結(jié)果的影響,實驗結(jié)果如表1所示。
表中的Attention-KWS表示本文所改進的方法,ASR-free-KWS表示本文中第2章所提到的基線系統(tǒng),ASR-KWS則表示傳統(tǒng)的關(guān)鍵詞識別方法。從表中可以看出,當(dāng)α和β分別取0.7和0.3時,準(zhǔn)確率最高,效果最好。相比較于未使用注意力機制的ASR-free-KWS,Attention-KWS與其相比提升了37.3%,這說明了注意力機制在關(guān)鍵詞識別中提取所需信息的重要性,而且Attention-KWS相比較于傳統(tǒng)方法ASR-KWS也提升了3.1%。B86FCB7B-49CA-44AB-8AD0-41E3BF54ADD1
4? 結(jié)? 論
本文針對ASR-free-KWS聲學(xué)模塊中存在的信息利用問題,使用了軟注意力機制并利用多任務(wù)訓(xùn)練的方式,使得關(guān)鍵詞嵌入向量高效地使用了輸入音頻特征的信息,使系統(tǒng)的性能得到了較大的提升。在下一步的工作中,為了能夠識別任意的漢語關(guān)鍵詞,我們將試著探究漢語中的開集關(guān)鍵詞識別。
參考文獻:
[1] YANH K,HEQ H,XIEW.Crnn-CtcBased Mandarin Keywords Spotting [C]//ICASSP2020-2020IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Barcelona:IEEE,2020:7489-7493.
[2] MANDAL A,KUMAR K R P,MITRA P. Recentdevelopmentsinspokentermdetection:asurvey [J].InternationalJournalofSpeechTechnology,2014,17:183-198.
[3] CHENGG,PARADAC,HEIGOLDG.Small-footprintkeywordspottingusingdeepneuralnetworks [C]//2014IEEEInternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP).Florence:IEEE,2014:4087-4091.
[4] DEANDRADEDC,LEOS,VIANAMLDS,et al.Aneuralattentionmodelforspeechcommandrecognition [J/OL].arXiv:1808.08929 [eess.AS].[2021-12-24].https://arxiv.org/abs/1808.08929.
[5] SAINATHT N,PARADAC. Convolutionalneuralnetworksforsmall-footprintkeywordspotting [EB/OL].[2021-12-24].https://download.csdn.net/download/weixin_42601421/10691683?utm_source=iteye_new.
[6] ARIKS?,KLIEGL M,CHILD R,etal. ConvolutionalRecurrentNeuralNetworksforSmall-FootprintKeywordSpotting [EB/OL].[2021-12-24].https://www.isca-speech.org/archive/interspeech_2017/ark17_interspeech.html.
[7] GRAVES A,F(xiàn)ERN?NDEZ S,GOMEZ F,etal. ConnectionistTemporalClassification:LabellingUnsegmentedSequenceDataWithRecurrentNeuralNetworks [C]//Proceedingsofthe23rdinternationalconferenceonMachinelearning. Pittsburgh:[s.n.],2006:369-376.
[8] AUDHKHASI K,ROSENBERG A,SETHY A,etal. End-to-End ASR-Free Keyword Search From Speech [J/OL].IEEEJournalofSelectedTopicsinSignalProcessing,2017,11(8):1351-1359.
[9] BALDIP. Autoencoders,unsupervisedlearning,anddeeparchitectures [C].Proceedings of the 2011 International Conference on Unsupervised and Transfer Learning workshop.Washington:JMLR.org,2011,27:37-50.
[10] CHUNGY A,WUCC,SHENC H,et al.AudioWord2Vec:UnsupervisedLearningofAudioSegmentRepresentationsusingSequence-to-sequenceAutoencoder [J/OL].arXiv:1603.00982[cs.SD].[2021-12-24].https://doi.org/10.48550/arXiv.1603.00982.
[11] KIMY,JERNITEY,SONTAGD,et al. Character-AwareNeuralLanguageModels [J/OL].arXiv:1508.06615 [cs.CL].[2021-12-24].https://arxiv.org/abs/1508.06615.
作者簡介:何振華(1983—),男,漢族,河南鄭州人,中級工程師,本科,研究方向:語音識別、機器翻譯;胡恒博(1994—),男,漢族,河南鄭州人,碩士研究生在讀,研究方向:語音識別、語音關(guān)鍵詞識別。
收稿日期:2022-02-09
課題項目:中國鐵路北京局集團有限公司科技研究開發(fā)計劃課題(2021AY02)B86FCB7B-49CA-44AB-8AD0-41E3BF54ADD1
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
