知識圖譜:一種系統性構建因果圖的方法
2022-07-14 05:48:16白永梅孫華鴿
首都醫科大學學報 2022年4期
白永梅 孫華鴿 杜 建
(1.北京大學醫學部醫學技術研究院,北京 100191;2.北京大學健康醫療大數據國家研究院,北京 100191;3. 北京大學醫學部公共衛生學院,北京 100191;4.墨爾本大學數學與統計學院,澳大利亞墨爾本 3010)
隨機對照試驗(randomized controlled trial,RCT)是流行病學研究中進行因果推斷的金標準,但由于時間效率、設計/實施難度、倫理等問題,在無法實施RCT的情況下,需要使用觀察性數據(如電子健康檔案、隊列或生物樣本庫)進行因果建模[1]。基于觀察性研究揭示暴露-結局之間因果關系的重要前提是,識別與暴露-結局相關的所有協變量(包括混雜變量、中介變量、對撞變量、工具變量)以及變量之間的復雜路徑關系,以在因果建模中更科學地進行變量調整。目前指導因果建模的主要工具是有向無環圖(directed acyclic graphs,DAG,也稱因果圖)[2]。DAG可以使研究假設更加明確,最大限度識別混雜因素[3]。DAG側重于確定因果推斷中主要的偏倚來源——混雜偏倚[4]。科學的因果關系推斷策略制定必須建立在對所研究問題涉及的先驗知識體系的整體認識和把握基礎之上,但目前DAG的繪制主要依賴研究者的文獻檢索結果和專家經驗,對于同一研究問題要么不交代所基于的因果圖,要么研究者各自繪制因果圖,具有局部性,在不同的研究者之間存在異質性和非標準化,在一定程度上影響了因果推斷的科學性以及干預措施的真實效果。流行病學研究領域也在呼吁要構建系統性、標準化、可共享的混雜因素全球知識庫,并在觀察性研究中報告所采用的因果圖,以提高研究質量、透明性和可重復性[5]。使全球范圍內分散的研究整合起來,為制定有效的健康干預策略提供高質量科學證據。為解決目前DAG繪制的局部性、異質性和非標準化問題,本文從跨學科角度,將因果圖定義為研究問題涉及概念(頭概念和尾概念)及其所有第三方變量之間的復雜知識圖譜。科技文獻是先驗知識最直接的體現,由科技文獻生成的知識圖譜本身就是對知識之間復雜關系的可視化表示,其中包含大量已經被證實的科學機制。從科技文獻中識別這些機制,將其轉換成可計算的形式,可以為構造復雜問題的解決模型提供支撐。利用科學文獻中的知識主張抽取并整合成因果圖,可為系統性生成因果圖提供新的思路。本文嘗試綜述流行病學、計算機科學、生物醫學信息學領域對該問題的研究進展,以期引入跨學科視角,提高因果圖的產生效率和使用價值,推動因果圖在觀察性研究因果建模和機制解釋中的應用。
1 因果圖的基本結構
因果推斷屬于一整套推理框架,可以與統計學、心理學、機器學習等研究模型相銜接。因果推斷的方法主要分為兩大流派:一種是基于估計方程的統計學方法,一種是基于圖網絡的計算機方法;第二種方法是通過圖網絡將不同研究之間進行連接,從而實現RCT研究的再利用[6]。1999年,Greenland等[7]提出了應用于流行病學研究的因果圖方法,主要用于區分混雜因素。后期該理論衍生出DAG。
以疫苗(暴露)和不良反應事件(結局)為例,當“暴露”和“結局”之間的關系未經過控制該因素的RCT研究時,該因素與“暴露”和“結局”之間有以下3種關系[8]:(1)當該因素同時影響“暴露”和“結局”時,該因素可能是“暴露”和“結局”之間的混雜因素。(2)當“暴露”通過該因素影響“結局”時,該因素可能是中介變量。(3)當“暴露”和“結局”同時作用于該因素時,該因素可能是對撞因子(圖1)。
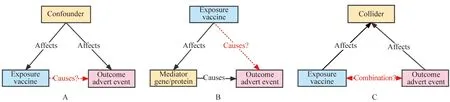
圖1 因果圖中的基本結構Fig.1 Basic structures in causal graphsA:confounder;B:mediator;C: collider.
1.1 混雜變量
來自電子健康病歷(electronic health records,EHR)和公開數據庫的臨床和治療數據為臨床和流行病學研究帶來了新的機會,但由于數據庫存在的局限性,使其研究容易產生偏倚,混雜偏倚是最常見的偏倚類別(63.2%)[9]。在醫學研究當中,混淆變量在很大程度上威脅著結論的可靠性,在DAG構建后,通過后門準則來判斷explore和outcome之間的關系,其中“explore→outcome”為前門路徑,“explore←confounder→outcome”為后門路徑,常采用協變量校正、分層、匹配等方法來控制混雜,在阻斷所有后門路徑后,前門路徑不成立,則證明confounder存在[10]。傳統統計模型分析時,常通過自變量之間的共線性來進行變量相關性篩選,但往往根據自變量對結果變量的影響程度來確定自變量納入排除的情況,整個判斷過程是無向的。而DAG中可以清晰地看到所有潛在的混雜變量、通過關系的指向排除collider變量,為模型調整提供清晰的指引。
2021年Malec等[11]的研究通過從文獻中提取的結構化的醫學知識——三元組構建知識圖譜,以發現潛在的“混雜因素”,將“候選”混雜因素合并到統計和因果圖模型當中,利用已有的知識衍生發現“因果關系”,根據發現的新增混雜因素調整原有的Logistic回歸模型中的變量,比較變量調整前后的模型可解釋性,即通過相關研究中的數據假設檢驗和已經報道的效應值來進行驗證。
1.2 中介變量
中介變量往往反映了作用機制。例如“藥物對心臟病發作的預防作用是由它對血壓水平的調節來介導的”。“介導”一詞往往是中間變量的提示詞和觸發詞。這句話其實編碼了一個簡單的因果模型:“藥物→血壓→心臟病發作”。在這個例子中,藥物降低了血壓水平,進而降低了心臟病發作的風險。所以,可以從醫學文本中抽取因果主張。鏈式結構(圖1B所表示的結構)中可能存在工具變量(instrumental variable,IV),IV指在鏈式結構中與隨機擾動項不相關、與結局變量不相關,但可以通過影響explore來影響outcome的變量[12]。
1.3 封閉式發型和開放式發現
在因果主張的抽取過程中,基于文獻的知識發現(literature-based discovery, LBD)將獨立在文獻中的知識通過邏輯關系進行連接,最后達到發現“未被發現的已知知識”的目的,如一組文獻報告了A和B的關系,另一組完全不同的文獻報告了B和C的關系,則提示A和C可能存在相關關系,這樣的發現是有待驗證的新知識[13-14],在判斷A和C的關系是否獨立于條件B的時候,通常采用D-分離來檢驗A和C關系的獨立性。在“斯旺森雷諾氏病-魚油”關系抽取示例中,雷諾氏病是起始術語,血液黏度、血小板聚集和血管反應性是連接術語,魚油是目標術語[14]。
LBD通過統一醫學語言系統(Unified Medical Language System, UMLS)來實現,有兩種主要模式:封閉式發現和開放式發現,也分別稱為雙節點搜索和單節點搜索[13]。在封閉式發現中,LBD 的目標是幫助解釋起始詞和目標詞之間的假設聯系。最終結果是一組連接術語,描述了起始術語和目標術語如何相關(例如血液黏度、血小板聚集和血管反應性)。在開放式發現中,LBD 有助于找到與起始術語隱含關聯的新概念[15]。這些新的聯系可以提供新的見解,例如治療疾病或緩解癥狀的物質(例如魚油),如圖2所示。這兩種范式不是排他性的,使用開放發現生成的假設可以使用封閉發現生成的假設來解釋。此外,無論哪種情況,LBD 的最終目標都是相同的——從文獻中隱含的知識中產生假設。Knowledge discovery是數據驅動的,是計算科學家的主要工作;Scientific discovery是實驗驅動的,是實驗科學家的主要工作。正如基于LBD得到的“斯旺森雷諾氏病-魚油”的推斷在臨床研究中得到了驗證。
在大規模LBD研究中,2019年Nordon等[16]提出通過自動構建醫療數據之間的圖譜來進行間接因果關系的發現,其數據來源于2 700萬篇PubMed的醫學摘要和150萬條電子病歷記錄(electronic medical record, EMR)數據分別構建網絡圖,通過EMR中每位患者的主要診斷根據國際疾病分類(International Classification of Diseases, ICD)生成的疾病“相關性”圖譜,用來自文獻(先驗知識)的疾病共病因果圖對EMR文本生成的圖譜進行修剪,專家對兩個圖合并結果打分來判斷其制作的圖譜精度,研究者稱該方法較其他研究而言精度顯著提高。該團隊的另一項研究[17]則通過因果圖路徑來進行候選藥物的生成和優先排序,使用醫療記錄和生物醫學文獻中的因果線索來確定潛在藥物的新用途。
單節點搜索旨在幫助正在尋找新假設的研究者,雙節點搜索能夠幫助確定現有假設中最有可能的那個假設(圖2)。
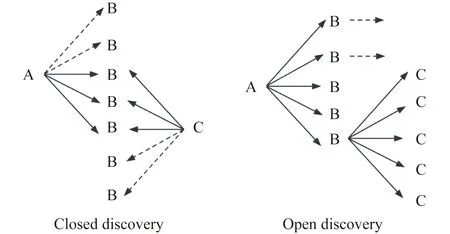
圖2 封閉式發現和開放式發現Fig.2 Closed discovery and open discovery
雙節點搜索策略的重要性體現在:(1)已經有了將A和C關聯起來的假設(或初步實驗發現),但沒有任何已發表的文章對其進行了明確介紹,通過雙節點搜索來探索兩個實體之間的作用機制。
(2)在討論A的文章集和討論C的文章集之間進行雙節點搜索,并尋找共有的B詞,此時B詞可能為A和C的中介變量。
(3)目的是對B詞列表進行排序以找出最相關和最可能的鏈接,并研究A與C相關聯的可能機制。
2 因果圖的構建技術
2.1 NLP技術作為基礎技術
自然語言處理(natural language processing, NLP)技術是基于以往研究[18]構建因果圖必不可少的基礎技術,核心在于從醫學文本中生成結構化三元組。SemRep、集成網絡和動態推理匯編器(integrated network and dynamical reasoning assembler, INDRA)等工具為醫學文本關系的抽取提供了基礎。SemRep使用語言學原理和UMLS的知識基礎處理 PubMed 文章的摘要和題目,并從中提取語義關系。INDRA作為本文描述的方法和軟件工具,描述了生物機制之間的關系,包含特定基因的所有已知信息,其類別遵循繼承層次結構,所有語句類型都繼承于父類語句[19]。
筆者團隊基于美國國立衛生研究院SemMedDB數據庫研發了結構化醫學知識體系平臺,實現從文獻內提取結構化醫學知識,包含超過9 400萬條三元組及超過2億條支持語句等元數據。相比其他平臺,能夠實現:(1)實體中英文映射;(2)中間變量的查詢;(3)響應速度快,查詢用時較少;(4)可直接下載逗號分隔值(comma-separated values,CSV)格式的三元組。結構化醫學知識體系平臺當前可以實現4個方面的應用:(1)三元組檢索,在搜索框中輸入關鍵詞,可返回與該關鍵詞相關的所有結構化醫學知識三元組(圖3A);(2)三元組路徑推斷,依據輸入的關鍵詞X和Y,從結構化醫學知識數據庫中檢索X作用于Y的路徑中的中間元素Z,返回X-Z-Y這一醫學知識路徑相關的所有醫學知識三元組(圖3B);(3)依據輸入的PubMed文章ID,返回從該篇文章標題和摘要中提取的所有結構化醫學知識三元組(圖3C);(4)三元組及相關句檢索,依據輸入關鍵詞,返回包含該關鍵詞的所有相關句以及結構化醫學知識三元組(圖3D)。
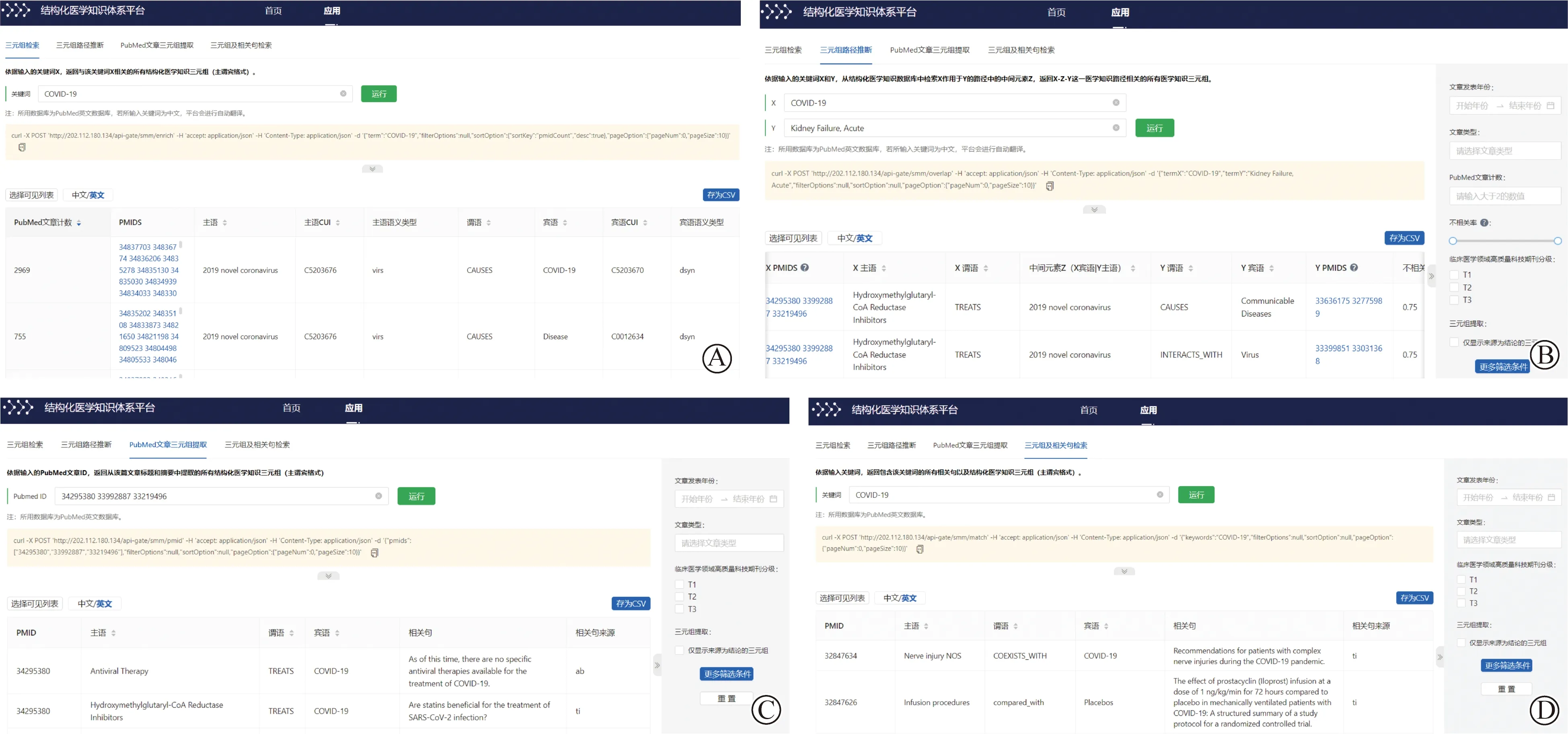
圖3 結構化平臺應用示例Fig.3 Examples of structured platform applications
2.2 將知識圖譜轉化為因果圖
目前,因果推斷(相對于相關性分析)是基于大數據的觀察性研究的主要方法,因果圖常通過DAG整合大量先驗知識將復雜的因果關系可視化,已成為合理制定因果推斷策略的重要工具。然而目前針對具體研究問題的因果圖的構建主要依賴專家知識和經驗,存在兩個問題:一是僅從研究問題涉及的關鍵詞出發的文獻檢索策略不同導致先驗知識獲取的召回率和準確率在不同的研究者之間存在異質性,無法反映從整個醫學知識體系出發的系統性,無法實現標準化;二是目前構建的DAG多為淺層的變量之間的直接路徑關系,無法反映變量之間復雜的間接路徑關系。這引發了對系統化構建DAG的呼吁[20]。本文嘗試從跨學科角度,將因果圖定義為研究問題涉及概念(頭概念和尾概念)及其所有第三方變量之間的復雜網絡(圖1),為系統化構建DAG提供新策略。
系統構建因果圖的方法有兩種:一是將知識圖譜修剪為因果圖。首先從醫學文本中利用自然語言處理技術抽取“概念-關系-概念”三元組,然后將不同的醫學文本生成的三元組整合起來,充分利用基于LBD進展,首先構建圍繞特定問題的概念知識圖譜,進而利用圖算法(路徑發現算法、D-分離等)將知識圖譜修剪為因果圖。二是將基于人群-干預/暴露-對照-結果(population-interventions/exposure-comparisons-outcomes,PI/ECO)框架的證據結論合成為因果圖。通過文獻檢索和判讀,將證據的結論轉化為DAG,然后將多個證據的結論綜合為集成的DAG,以系統構建根據已有證據確定納入的變量以及變量之間的關系。
在醫學研究[21]中,系統構建DAG分為以下幾個步驟:(1)將每個研究的結論“映射”到DAG中;(2)利用若干因果推理原則,系統地評估這些DAG中的因果結構,并予以相應糾正;(3)生成的DAG將被合成為一個或多個“綜合DAG”。當前可以進行知識可視化的工具非常多,通過這些工具可以將現有知識轉化為知識圖譜或圖數據庫,用于知識的查詢、推理和可視化。如Neo4j、GraphDB、protégé、NetworkX包等。
基于國內外相關研究[22-24],本研究發現計算機科學的知識圖譜和因果推斷中的DAG結合起來的研究逐步興起,通過分解因果圖來消除混淆變量。在此基礎上,通過統計學計算來進行因果推斷,如傾向性評分(propensity score, PS)分配來均衡組間“混雜因素”的影響[22],差分法(difference in difference,DID)來比較暴露前后的差異[23],邊際結構模型(marginal structural models,MSMs)允許在存在時間依賴性混雜的情況下估計時變暴露對結果的因果影響[24],2021年的研究[25]表明在連續性變量可以通過生成對抗去混雜(generative adversarial de-confounding, GAD)的算法來消除連續效果估計中的混雜因素。
3 因果圖構建示例
EpiGraphDB(https://epigraphdb.org/)是一個由英國布里斯托大學綜合流行病學研究所開發的圖數據庫,其中包含了眾多生物醫學和流行病學關系,與可被應用在健康數據科學中的分析平臺[26]。當今,關于人類表型、風險因素、分子特征和治療干預的豐富數據資源為健康科學提供了新的發展機遇,而如何更好地利用這些資源則需要不同數據集間的協調與整合。作為一個數據平臺,EpiGraphDB中集成了因果、觀察或遺傳特征關系、文獻挖掘獲得的關系、生物學途徑、蛋白質互作、藥物靶標等資源,以支持風險因素、疾病關系等的數據挖掘。EpiGraphDB中包含了由文獻證據構建的圖譜常被應用在健康數據科學研究中。文獻圖譜的底層數據來源于美國國立衛生研究院的標準化語義數據庫SemMedDB[27],該數據庫中包含有PubMed中所有語句轉化、映射出的語義三元組,即將自然語言標準化為主語-謂語-賓語的形式,并與UMLS標準詞表對應,形成了可被應用于基于文獻發現等方向的大型知識資源庫。而EpiGraphDB中的文獻圖譜使用三元組作為節點,連接三元組所屬的PubMed文獻節點。查詢時可通過直接搜索三元組中的主語或賓語,獲得所有相關的三元組及有三元組出現過的PubMed文獻,同時還可以限制謂語類型,獲得更精確的查詢結果。除了在網頁上直接檢索各個圖譜中的數據,EpiGraphDB還提供API、R語言包、Cypher等檢索方法。通過獲取到的三元組,可以構建更有指向性的知識因果圖等,用來輔助健康數據科學的研究。
因果圖在醫學研究[28-30]中主要以DAG為主,通過證據綜合的方法來構建DAG可以將每個研究的結論都映射到DAG當中,通過網絡圖中基本結構的因果推斷原則系統評價DAG中的結論,并予以適當糾正。如當前研究[31]通過DAG識別殘疾和心電圖結果之間的混雜變量,通過Logistic回歸模型調整證明了統計學相關的因素為“混雜變量”。2021年的研究[32]發現,來自Scopus、Medline和Embase等數據庫在1999-2017年間發表的出版物中,提及DAG和DAGitty的文獻中有62%提供了DAG,48%報告了他們所提供的DAG的調整集。近些年來多項研究基于“知識圖譜”批量構建不同文獻中得到的結論之間的聯系。Riseberg等[30]將暴露為“金屬混合物”、結局為“心臟代謝”的系統綜述結果進行匯總,構建DAG來確定潛在的混雜因素,并通過統計學模型來進行調整。基于該研究進展,筆者團隊通過SemRep工具進行了新型冠狀病毒肺炎(COVID-19)相關三元組的提取,并導入Neo4j進行知識圖譜構建,將不同文獻的結論連接起來。通過查詢“疫苗→不良反應事件”的路徑,其中三元組源于“托珠單抗→抑制→C反應蛋白”來源于PMID號為32531257的出版物(圖4),三元組“C反應蛋白→更易于發生→呼吸衰竭”源于PMID號為34102804、32628003的出版物,從而構成完整的托珠單抗和呼吸衰竭之間的路徑,使托珠單抗、呼吸衰竭、停止生命三個實體之間形成包含中介因子的完整路徑。
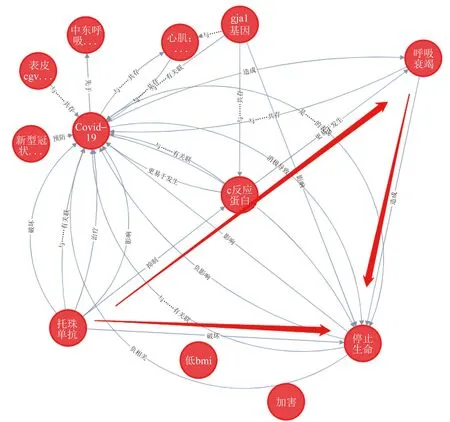
圖4 因果圖構建示例Fig.4 Example of causal graph construction
4 總結與展望
通過基于醫學知識構建知識圖譜的方法,極大提高了臨床研究的二次利用率,相對于傳統DAG構建或循證醫學研究,因果圖的構建極大提高了效率和信息召回率,且能夠實現作用機制的建立和查詢。
目前,LBD 是一個成熟的領域,具有不同的范式和系統設計,尋求自動化或半自動化的方式從現有文獻中發現新的知識,可以在孤立的文獻之間建立聯系,增加跨學科信息共享。科學出版物的海量劇增凸顯了LBD的重要性,它對加速知識獲取和研究發展進程非常有益。
綜上所述,與專家根據已有知識和經驗構建DAG相比,通過信息學/數據科學系統基于LBD構建DAG主要分為以下幾個步驟:(1)通過NLP技術來處理醫學文本中已經存在的醫學知識,將其結構化,在這個過程中可以使用超級敘詞表來進行醫學實體標準化映射;(2)通過計算機技術將結構化的醫學知識轉化為可視化、可查詢的知識圖譜和圖數據庫;(3)根據EMR、現有研究中的檢驗結果、設計RCT研究、專家審核、統計分析等方法來對知識圖譜中的“路徑查詢”結果進行驗證。
用圖模型來高度概括因果關系可以實現既往研究的二次利用,建立研究之間的間接聯系[4]。基于知識圖譜構建因果圖的相關研究仍然存在數據來源單一、多數據庫融合性不足等問題。當構建圖譜的數據來源局限于文獻、EMR、數據庫或臨床試驗時,所得到的醫學實體之間的因果關系會存在召回率低、準確率低、僅表達相關性、可解釋性差等缺點。數據庫來源單一的情況則難以實現“基因-藥物-臨床研究-人群”多層面、可解釋性強的因果推斷路徑構建。在今后的研究當中,可以考慮將不同層面的數據庫作為信息來源,如“基因數據庫”“臨床試驗數據庫”“EMR”“出版物”等,通過自然語言處理技術構建醫學實體之間的三元組,增強數據重復利用的價值,通過“基因-藥物-臨床研究-人群”等多層面的數據連接,來提高醫學知識的可解釋性。
利益沖突所有作者聲明無利益沖突。
作者貢獻聲明白永梅:論文撰寫、數據分析;孫華鴿:數據收集和抽取;杜建:研究設計和論文指導。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
