基于輕量級(jí)網(wǎng)絡(luò)自適應(yīng)特征提取的番茄病害識(shí)別
2022-07-16 08:11:04胡玲艷周婷劉艷許巍蓋榮麗李曉梅裴悅琨汪祖民
江蘇農(nóng)業(yè)學(xué)報(bào) 2022年3期
關(guān)鍵詞:特征提取
胡玲艷 周婷 劉艷 許巍 蓋榮麗 李曉梅 裴悅琨 汪祖民




摘要: 為了實(shí)現(xiàn)番茄病害的精準(zhǔn)識(shí)別,本研究提出一種輕量級(jí)網(wǎng)絡(luò)自適應(yīng)特征提取方法。該方法首先對(duì)圖片進(jìn)行正形處理,然后基于SqueezeNet模型構(gòu)建輕量級(jí)網(wǎng)絡(luò)模型GKFENet。GKFENet模型包含全局特征提取和關(guān)鍵特征提取2個(gè)模塊,其中全局特征提取模塊逐層提取番茄病害葉片的全局特征,關(guān)鍵特征提取模塊通過學(xué)習(xí)評(píng)估出特征圖各通道的重要程度,計(jì)算出權(quán)重值,最后將該值加權(quán)到原特征圖上,從而實(shí)現(xiàn)病害關(guān)鍵特征的自適應(yīng)提取。結(jié)果顯示,正形機(jī)制有助于神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)特征,本研究構(gòu)建的GKFENet模型的平均識(shí)別準(zhǔn)確率為97.90%,模型大小僅為2.64 MB,且在強(qiáng)噪聲環(huán)境下,其識(shí)別準(zhǔn)確率仍能保持在78.00%以上。GKFENet模型在訓(xùn)練過程中相對(duì)穩(wěn)定,對(duì)8種番茄病害的識(shí)別準(zhǔn)確率均超過96.00%。相比Bayes、KNN、LeNet、SqueezeNet、MobileNet模型,本研究構(gòu)建的GKFENet模型的識(shí)別精度高,穩(wěn)定性強(qiáng)且占用內(nèi)存小,對(duì)于移動(dòng)端未來的應(yīng)用具有較高的實(shí)際價(jià)值。
關(guān)鍵詞: 輕量級(jí)網(wǎng)絡(luò); 正形機(jī)制; 特征提取; 番茄; 病害識(shí)別
中圖分類號(hào):? TP391;S641.2? ?文獻(xiàn)標(biāo)識(shí)碼: A?? 文章編號(hào): 1000-4440(2022)03-0696-10
Tomato disease recognition based on lightweight network auto-adaptive feature extraction
HU Ling-yan, ZHOU Ting, LIU Yan, XU Wei , GAI Rong-li, LI Xiao-mei, PEI Yue-kun, WANG Zu-min
(School of Information Engineering, Dalian University, Dalian 116622, China)
Abstract: To realize accurate recognition of tomato diseases, a lightweight network auto-adaptive feature extraction method was proposed. This method firstly performed a correction processing on the image. Then, based on the SqueezeNet model, a lightweight network model named global and key feature extraction network (GKFENet) was built. The GKFENet model included global feature extraction and key feature extraction modules. The global feature extraction module extracted the global features of tomato diseased leaves layer by layer. The key feature extraction module evaluated the importance of each channel in the feature images through learning, and calculated the weight value. Finally, the value was weighted on the original feature images to realize the adaptive extraction of the key features of the diseases. The results showed that the correction mechanism helped the neural network to learn features, the average identification accuracy of GKFENet model constructed in this research was 97.90%, and the model size was only 2.64 MB. In an environment with strong noise, the recognition accuracy of the model was still above 78.00%. GKFENet model was relatively stable during the training process, and the recognition accuracies of eight types of tomato diseases were all over 96.00%. Compared with Bayes, k-nearest neighbor (KNN), LeNet, SqueezeNet and MobileNet models, the GKFENet model constructed in this research has higher recognition accuracy, stronger stability and less memory. It has strong practical value in future mobile applications.
Key words: light weight network; correction mechanism; feature extraction; tomato; disease recognition
番茄富含維生素和礦物質(zhì),兼具特殊藥理作用,被人們廣為食用,已經(jīng)被世界糧農(nóng)組織列為第六大蔬菜 [1-2] 。種植過程中的病蟲害嚴(yán)重制約著番茄的產(chǎn)量和收益,一旦對(duì)疾病判斷有誤或者診斷不及時(shí),將給農(nóng)戶帶來巨大的經(jīng)濟(jì)損失。因此,快速、精準(zhǔn)地識(shí)別番茄病害類型,及時(shí)進(jìn)行干預(yù),有助于農(nóng)戶番茄種植的提質(zhì)增效。
隨著計(jì)算機(jī)技術(shù)和人工智能的快速發(fā)展,利用這些信息技術(shù)對(duì)植物病害類別進(jìn)行診斷、識(shí)別,逐漸成為一種新趨勢(shì)。目前,國(guó)內(nèi)外針對(duì)番茄病害識(shí)別方面的研究取得了較大進(jìn)展,基于傳統(tǒng)的機(jī)器學(xué)習(xí)算法,通過手工提取特征和分類器進(jìn)行分類 [3-4] ,可以初步滿足病害識(shí)別的要求,但復(fù)雜的特征提取工程極大地影響了工作效率,且人工提取的特征是主觀的、有限的、粗糙的。深度學(xué)習(xí)浪潮的興起,為上述問題提供了解決辦法。其中,卷積神經(jīng)網(wǎng)絡(luò)具備強(qiáng)大的“自學(xué)”能力,能夠在最大程度上獲取所有與輸入、輸出相關(guān)聯(lián)的信息,避免了繁重的特征提取工作,備受研究者們青睞。Jiang等 [5] 和Rangarajan等 [6] 采用不同的深度卷積神經(jīng)網(wǎng)絡(luò)識(shí)別番茄病害,每個(gè)模型的預(yù)測(cè)精度均在97%以上。王艷玲等 [7] 和Jia等 [8] 將遷移學(xué)習(xí)與神經(jīng)網(wǎng)絡(luò)模型相結(jié)合,通過“固定低層,微調(diào)高層”的訓(xùn)練策略,建立的模型能快速、準(zhǔn)確識(shí)別10種番茄病害。Wu等 [9] 利用DCGN網(wǎng)絡(luò)模型增強(qiáng)數(shù)據(jù),并分別采用AlexNet、GoogLeNet、VGG16、ResNet網(wǎng)絡(luò)模型對(duì)番茄葉片病害進(jìn)行識(shí)別。上述研究均采用經(jīng)典的深層網(wǎng)絡(luò)模型,隨著研究的推進(jìn),這些模型的層數(shù)逐漸增多。增加網(wǎng)絡(luò)模型深度可以有效提升準(zhǔn)確率,但同時(shí)需要耗費(fèi)巨大的存儲(chǔ)空間和運(yùn)算時(shí)間。在識(shí)別番茄葉片圖像的過程中,神經(jīng)網(wǎng)絡(luò)模型會(huì)提取整個(gè)圖片的信息,然而真正需要提取的有用特征僅存在于目標(biāo)對(duì)象所在的局部區(qū)域。因此,人們從增加網(wǎng)絡(luò)模型深度轉(zhuǎn)而開始研究如何實(shí)現(xiàn)對(duì)病害關(guān)鍵特征的提取。胡志偉等 [10] 、李曉振等 [11] 以及Meeradevi等 [12] 提出將注意力機(jī)制與多種深層網(wǎng)絡(luò)模塊相結(jié)合的方法,利用注意力機(jī)制有效抽取番茄病害不同層次的特征信息,加強(qiáng)關(guān)鍵特征的表達(dá),同時(shí)抑制無關(guān)特征的表達(dá),最終構(gòu)建的模型均有較高的準(zhǔn)確率。這種方法通過對(duì)目標(biāo)特征的精準(zhǔn)提取,實(shí)現(xiàn)計(jì)算資源的合理分配,進(jìn)而提升模型的識(shí)別性能,但網(wǎng)絡(luò)模型巨型化的問題仍未得到有效解決,因此這些模型難以應(yīng)用到移動(dòng)端。
隨著物聯(lián)網(wǎng)技術(shù)在各行各業(yè)的廣泛應(yīng)用、移動(dòng)設(shè)備的日趨普及,人們開始研究可以應(yīng)用在移動(dòng)端的病害識(shí)別算法。方晨晨等 [13] 和郭小清等 [14] 在深層網(wǎng)絡(luò)架構(gòu)的基礎(chǔ)上,采用多尺度卷積核、深度可分離卷積等操作對(duì)傳統(tǒng)網(wǎng)絡(luò)模型進(jìn)行改進(jìn),縮小了模型大小,實(shí)現(xiàn)了準(zhǔn)確率和存儲(chǔ)空間的平衡,其中改進(jìn)的AlexNet模型識(shí)別田間番茄病害的準(zhǔn)確率達(dá)到89.2%。Elhassouny等 [15] 基于現(xiàn)有的輕量級(jí)網(wǎng)絡(luò)模型MobileNet構(gòu)建一種應(yīng)用程序,識(shí)別10種常見的番茄葉部病害。Agarwal等 [16] 搭建了1個(gè)8層的簡(jiǎn)化卷積神經(jīng)網(wǎng)絡(luò)(CNN)模型,在Plant Village數(shù)據(jù)庫上的測(cè)試效果均優(yōu)于K最近鄰算法和深層網(wǎng)絡(luò)模型VGG16。上述算法在簡(jiǎn)化模型大小方面取得了一定進(jìn)展,同時(shí)保持著較高的準(zhǔn)確率,但神經(jīng)網(wǎng)絡(luò)模型在縮小模型以及提高準(zhǔn)確率方面仍有很大的提升空間。此外,大多數(shù)的研究結(jié)果來源于理想的圖片和環(huán)境,未考慮模型在復(fù)雜環(huán)境下的性能,其魯棒性難以保證,也有部分研究在實(shí)際環(huán)境下對(duì)模型進(jìn)行檢測(cè),但準(zhǔn)確率較低。因此,要想在實(shí)際生產(chǎn)中使用,上述研究還存在一定距離。
綜上所述,在近期識(shí)別番茄病害的研究工作中,人們考慮了準(zhǔn)確率、模型大小以及魯棒性等特性,但沒有實(shí)現(xiàn)這些性能的綜合平衡。本研究擬采用正形機(jī)制對(duì)病害圖片進(jìn)行處理,結(jié)合Fire模塊的優(yōu)點(diǎn)和注意力機(jī)制 [17] 的特性構(gòu)建輕量級(jí)網(wǎng)絡(luò)模型GKFENet,識(shí)別常見的番茄病害類別,以期實(shí)現(xiàn)準(zhǔn)確率、模型大小、識(shí)別速度以及魯棒性的綜合平衡,可以更好地在實(shí)際環(huán)境中指導(dǎo)農(nóng)業(yè)生產(chǎn)。
1 材料與方法
1.1 數(shù)據(jù)集
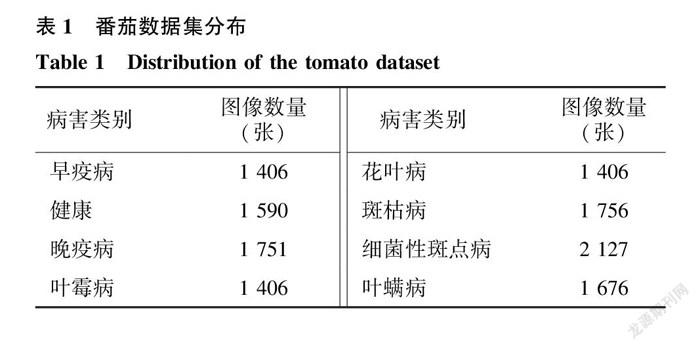
本研究模型采用的數(shù)據(jù)集來自大型公開數(shù)據(jù)庫Plant Village [18] ,該數(shù)據(jù)庫共收集了18 160 張感染病害的番茄葉片圖片。綜合考慮番茄種植過程中病害的發(fā)病率以及研究適用性等因素,從Plant Village數(shù)據(jù)庫中選取感染早疫病、晚疫病、葉霉病、花葉病、斑枯病、細(xì)菌性斑點(diǎn)病、葉螨病的葉片與健康葉片共8種番茄葉片作為本次研究的數(shù)據(jù)集。下面對(duì)這8種番茄葉片的紋理特征圖像以及病害特征進(jìn)行描述 [19-20] 。
早疫病:感病初期葉片出現(xiàn)水漬狀暗褐色病斑,呈離散狀分布,擴(kuò)大后近圓形,有同心輪紋,邊緣多具淺綠色或黃色暈環(huán)。嚴(yán)重時(shí),多個(gè)病斑連成不規(guī)則形大斑,導(dǎo)致葉片枯萎,當(dāng)環(huán)境潮濕時(shí),病斑處還會(huì)長(zhǎng)出黑霉。
健康:番茄葉片顏色質(zhì)地均勻,為深綠色或者淺綠色,無大小病斑,無殘缺,無孔洞,無扭曲,無枯萎,無生理性卷葉,無子葉上舉等異常癥狀。
晚疫病:葉片發(fā)病初期出現(xiàn)暗綠色水漬狀不規(guī)則病斑,病健交界處不明顯,擴(kuò)大后變?yōu)楹稚稍飼r(shí)呈綠褐色,后變暗褐色直至枯萎。濕度大時(shí)葉片背面出現(xiàn)白色霉層,多從植株下部葉尖或葉緣開始發(fā)病,然后逐漸向上部葉片蔓延。
葉霉病:葉片染病后出現(xiàn)橢圓形或不規(guī)則淡黃色病斑,葉片背面長(zhǎng)出灰褐色至黑褐色的絨狀霉層,條件適宜時(shí),染病葉片正面也長(zhǎng)出霉層,一般中、下部葉片先發(fā)病,然后逐漸向上部葉片蔓延,病害嚴(yán)重時(shí)病斑連片,葉片逐漸卷曲、干枯。
花葉病:葉片染病后會(huì)出現(xiàn)黃綠相間或濃綠與淡綠相間斑駁,亦或是顏色深淺分布不均勻的綠色病斑,葉片外形變得細(xì)長(zhǎng)且小,葉片增厚,且略有皺縮扭曲。
斑枯病:染病后,葉片正面、背面均出現(xiàn)圓形或近圓形的病斑,呈現(xiàn)大量凸起的小黑點(diǎn),病斑周圍區(qū)域泛黃,葉片邊緣的發(fā)病部位會(huì)發(fā)生微卷曲,嚴(yán)重時(shí)形成大的枯斑,病部組織壞死穿孔,導(dǎo)致葉片干枯脫落。
細(xì)菌性斑點(diǎn)病:染病后,葉片出現(xiàn)大量褐色病斑,呈聚集狀態(tài),病斑周圍的過渡區(qū)呈現(xiàn)黃褐色,發(fā)病后期病斑枯萎,形成孔洞。
葉螨病:葉螨即紅蜘蛛,受損害的葉片部位會(huì)由于水分缺失而變?yōu)榘咨~片表面呈現(xiàn)大量白色病斑,葉片卷曲。
1.2 圖片的正形處理
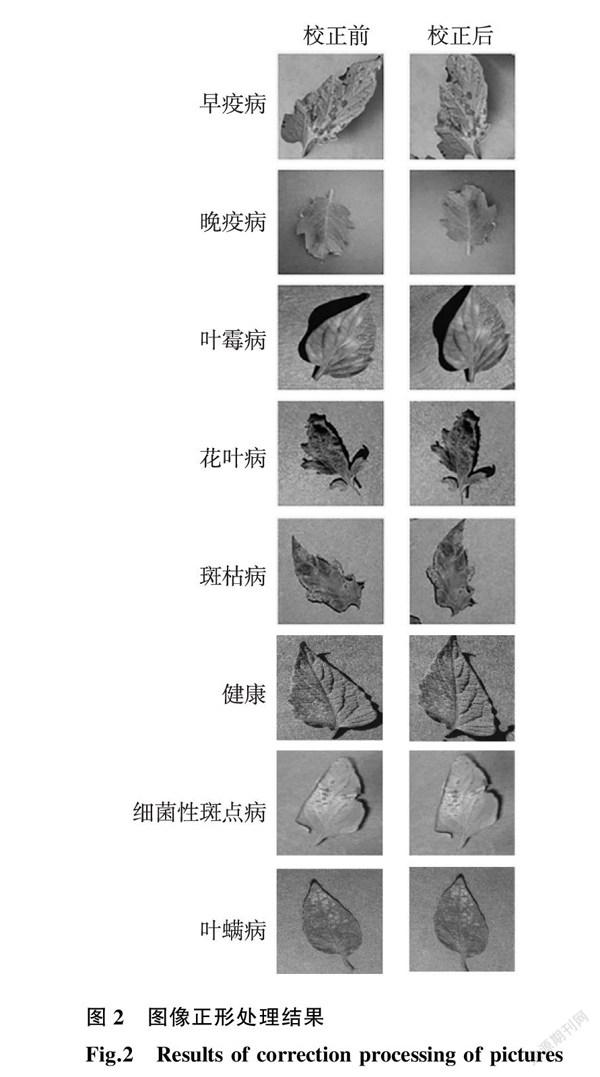
Plant Village數(shù)據(jù)庫中每張番茄圖像只有一張葉片,每張葉片只患一種疾病,圖像背景簡(jiǎn)單,但葉片在圖像中的位置不固定,且葉片的朝向是任意的。為了使葉片朝向統(tǒng)一,本研究提出了正形機(jī)制,該機(jī)制旨在將所有葉片的方向統(tǒng)一為葉尖朝上,葉柄朝下,使得葉片盡可能處于圖片的正中位置,保證葉片與圖片中線的偏離角度范圍為-5°~ 5°。通過正形機(jī)制對(duì)圖像進(jìn)行處理,有利于卷積神經(jīng)網(wǎng)絡(luò)提取到更多、更細(xì)致的病害特征,進(jìn)而提高神經(jīng)網(wǎng)絡(luò)模型的學(xué)習(xí)效率,增強(qiáng)穩(wěn)定性。其工作流程如圖1所示,具體步驟為:第一,獲取病害圖片;第二,對(duì)圖片進(jìn)行灰度化處理;第三,利用高斯濾波降低圖片噪聲;第四,利用多級(jí)邊緣檢測(cè)算法-Canny邊緣檢測(cè)算子 [21] 提取葉片的邊緣特征;第五,繪制最小外接多邊形,獲得圖片旋轉(zhuǎn)角度( θ );第六,利用旋轉(zhuǎn)角度( θ )對(duì)圖片進(jìn)行仿射校正。
本研究選取11 250 張圖像,篩除朝向正確的圖片,剩下需要進(jìn)行正形機(jī)制處理的圖像共有7 568 張,圖2為部分葉片經(jīng)過正形處理后的結(jié)果。此外,數(shù)據(jù)集中各類圖像數(shù)量分布的不均衡,往往會(huì)對(duì)模型訓(xùn)練產(chǎn)生極大影響,甚至產(chǎn)生過擬合的現(xiàn)象。為了緩解圖片數(shù)量不均衡的問題,以8種番茄葉片樣本的平均值為基準(zhǔn),采用隨機(jī)復(fù)制的方式對(duì)數(shù)據(jù)量較少的早疫病、葉霉病和花葉病進(jìn)行數(shù)據(jù)擴(kuò)充 [22] ,最終得到的圖像樣本共13 118 張,數(shù)據(jù)集具體信息如表1所示。
1.3 病害識(shí)別模型設(shè)計(jì)
1.3.1 模型的構(gòu)建 本研究構(gòu)建的輕量級(jí)網(wǎng)絡(luò)模型GKFENet的結(jié)構(gòu)如圖3顯示,該模型包括全局特征提取子網(wǎng)絡(luò)GFE-Net和關(guān)鍵特征提取子模塊KFE-Block 2個(gè)部分,GFE-Net通過一系列卷積池化操作,對(duì)輸入圖片的顏色、紋理和形狀等全局特征進(jìn)行提取,獲取圖片的整體屬性,輸出多個(gè)特征圖。KFE-Block將這些包含全局特征的特征圖進(jìn)行池化壓縮,得到通道維度的信息描述符,捕獲該通道描述符之間的非線性相互作用關(guān)系,根據(jù)關(guān)鍵程度為每個(gè)特征通道分配權(quán)重,最后將該權(quán)重作用在輸入的特征圖上,從而提升關(guān)鍵特征的表達(dá)并抑制不相關(guān)特征,實(shí)現(xiàn)對(duì)關(guān)鍵特征的精準(zhǔn)提取。
1.3.2 組成模塊
1.3.2.1 全局特征提取子網(wǎng)絡(luò)GFE-Net 原SqueezeNet [23] 網(wǎng)絡(luò)模型中包含8個(gè)Fire模塊,網(wǎng)絡(luò)層數(shù)和參數(shù)量均較多,運(yùn)算時(shí)間長(zhǎng)。綜合考慮8種番茄病害圖片數(shù)量的適合度,同時(shí)避免過擬合,將SqueezeNet中的Fire3、Fire6、Fire8和Fire9這4個(gè)模塊刪除,利用剩余的模塊構(gòu)建GFE-Net子網(wǎng)絡(luò)。GFE-Net子網(wǎng)絡(luò)由4個(gè)Fire模塊、2個(gè)卷積層、3個(gè)池化層、1個(gè)全局平均池化層、1個(gè)Dropout層和1個(gè)Softmax層組成,表2為構(gòu)建的GFE-Net子網(wǎng)絡(luò)的具體參數(shù),其中Fire模塊重新排序命名。每個(gè)Fire模塊包括Squeeze層和Expand層,每層僅由1× 1或3× 3大小的卷積核組成,與傳統(tǒng)的卷積層相比,該方法將網(wǎng)絡(luò)模型的參數(shù)量減少了90%,其結(jié)構(gòu)如圖4顯示。2個(gè)卷積層分別處在GFE-Net子網(wǎng)絡(luò)的前端和后端,能夠有效提取到圖像基本特征和高層語義信息。3個(gè)最大池化層能夠提取出低分辨率、強(qiáng)語義信息的特征圖。用全局平均池化層代替全連接層,可以有效減少網(wǎng)絡(luò)模型的計(jì)算復(fù)雜度和參數(shù)量,從而提高模型訓(xùn)練速度。Dropout層的引入能夠有效防止過擬合。利用Softmax函數(shù)計(jì)算出每個(gè)類別的概率,輸出預(yù)測(cè)結(jié)果。
1.3.2.2 關(guān)鍵特征提取子模塊KFE-Block 本研究引入關(guān)鍵特征提取子模塊,實(shí)現(xiàn)與全局網(wǎng)絡(luò)模塊的有效結(jié)合,同時(shí)能夠?qū)μ卣鞯闹匾潭冗M(jìn)行評(píng)估,獲取權(quán)重值,強(qiáng)化病害關(guān)鍵特征的表達(dá)。結(jié)合注意力機(jī)制的KFE-Block包括1個(gè)全局平均池化層、2個(gè)全連接層、2個(gè)激活函數(shù)和1個(gè)矩陣乘法操作,該模塊提取關(guān)鍵特征的過程如下:
步驟1:獲取通道描述符。從GFE-Net子網(wǎng)絡(luò)卷積層輸出的特征圖維度為[ H , W , C ], H、W、C 表示特征圖的長(zhǎng)、寬、通道數(shù),將其輸入到KFE-Block中,首先經(jīng)過全局平均池化層,對(duì)大小為 H ×? W 的特征圖上的所有值進(jìn)行求和取平均值,每個(gè)通道的輸出值用 gc 表示,運(yùn)算公式如下:
gc= 1 H×W ?Hi=1 ?Wj=1? uc(i,j) (1)
其中, H、W、C 表示特征圖的長(zhǎng)、寬、通道數(shù); i 、 j 表示特征圖上像素的位置索引; uc(i,j) 表示特征圖上的值; gc 為每個(gè)通道的輸出值。 C 個(gè)通道的總輸出值為 G ,則 G =[ g1 , g2 ,…, gc ]。
步驟2:降維,獲取通道間非線性關(guān)系。將前面獲得的總輸出值 G 先經(jīng)過全連接層1,該層通過縮放因子 r 將通道數(shù)從 C 降低到 C/r ,減少計(jì)算量。然后再利用激活函數(shù)ReLU獲取通道之間的非線性關(guān)系。運(yùn)算公式如下:
R =max(WT1× G ,0)(2)
其中,W1表示全連接層1的權(quán)重參數(shù)矩陣,維度為( C / r )× C ;T表示轉(zhuǎn)置; G 為特征圖經(jīng)過全局平均池化的結(jié)果,維度為[1,1, C ]; R 為輸出值,維度為[1,1, C/r ]; C 為通道數(shù); r 為縮放因子。
步驟3:升維,獲取關(guān)鍵值。將上一步獲得的輸出 R 經(jīng)過全連接層2,此操作將通道數(shù)恢復(fù)到原始數(shù)量。然后通過Sigmoid函數(shù)進(jìn)一步捕獲通道間的非線性關(guān)系后進(jìn)行評(píng)估,輸出各通道的關(guān)鍵度值,其值記為 K_V ,運(yùn)算公式如下:
K_V =11+exp(-WT2× R )(3)
其中,W2表示全連接層2的權(quán)重參數(shù)矩陣,維度為 C ×( C / r );T表示轉(zhuǎn)置; R 為步驟2的輸出值; K_V? 表示關(guān)鍵度值,為包含 C 個(gè)數(shù)值的標(biāo)量,且[ k_v1 , k_v2 ,..., k_vc ]的數(shù)值大小代表對(duì)應(yīng)通道關(guān)鍵程度的高低。
步驟4:關(guān)鍵特征提取。將獲取的關(guān)鍵值逐通道加權(quán)到先前的特征圖上,即將每個(gè)特征圖[ H , W ,1],[ H , W ,2],...,[ H , W , C ]分別與[ k_v1 , k_v2 ,..., k_vc? ]相乘,運(yùn)算公式如下:
xc = k_vc×uc (4)
其中, uc 為特征圖上的值; k_vc 為 C 通道對(duì)應(yīng)的關(guān)鍵度值; xc 為每個(gè)通道的輸出值。 X 為 C 個(gè)通道輸出的總特征圖,與輸入維度一致,但此時(shí)特征圖上的值都已被重新標(biāo)定,即關(guān)鍵特征的特征值變得更大,無關(guān)的特征變得更小甚至被抑制,從而實(shí)現(xiàn)關(guān)鍵特征的提取。圖5為KFE-Block子模塊的結(jié)構(gòu)。
1.4 模型訓(xùn)練
1.4.1 試驗(yàn)參數(shù)設(shè)置 本研究在服務(wù)器上的試驗(yàn)配置環(huán)境如下:計(jì)算機(jī)操作系統(tǒng)Window10,搭載處理器Intel Xeon E5-2620,內(nèi)存64 G,顯卡NVIDIA GTX 1080Ti,顯存11 G。采用Tensorflow2.0深度學(xué)習(xí)框架,將Python3.6作為編程語言。
將預(yù)處理后的數(shù)據(jù)集隨機(jī)劃分為訓(xùn)練集、驗(yàn)證集和測(cè)試集,這3部分的圖像數(shù)量比例為8∶ 1∶ 1,最終形成10 500 張訓(xùn)練集圖像,1 300 張驗(yàn)證集圖像,1 318 張測(cè)試集圖像。用隨機(jī)劃分后的樣本數(shù)據(jù)集對(duì)不同分類模型進(jìn)行訓(xùn)練,得到各模型的性能評(píng)估結(jié)果。
在番茄葉片病害識(shí)別模型的訓(xùn)練過程中,輸入圖像大小設(shè)定為256× 256,選用優(yōu)化速度較快的自適應(yīng)矩陣估計(jì)算法(Adam)優(yōu)化網(wǎng)絡(luò)模型,其初始學(xué)習(xí)率設(shè)置為0.000 5 ,并采用多分類對(duì)數(shù)函數(shù)作為損失函數(shù)。每組試驗(yàn)反復(fù)進(jìn)行10次,每次迭代100次,試驗(yàn)中訓(xùn)練集和驗(yàn)證集的批次大小均設(shè)置為64,測(cè)試集的批次大小為128,關(guān)鍵特征提取子模塊中的縮放因子 r 設(shè)置為8。同時(shí),為了防止過擬合,設(shè)置正則化系數(shù)為0.000 5 。
試驗(yàn)選用的評(píng)價(jià)指標(biāo)有3個(gè),分別為準(zhǔn)確率、模型大小和識(shí)別速度。準(zhǔn)確率定義為被正確分類的病害圖像數(shù)量與總病害圖像數(shù)量之比。模型大小與參數(shù)量有關(guān),在訓(xùn)練過程中使用Summary函數(shù)記錄網(wǎng)絡(luò)模型的參數(shù)量。識(shí)別速度為進(jìn)行單張圖片測(cè)試時(shí)所需的時(shí)間。
1.4.2 試驗(yàn)方案設(shè)計(jì) 為了更全面地驗(yàn)證正形機(jī)制的作用以及GKFENet模型的性能,選取Bayes、KNN、LeNet、MobileNet、SqueezeNet模型作為對(duì)比模型。其中,MobileNet模型直接從Keras官方應(yīng)用網(wǎng)站(Keras Applications)下載,其他分類模型均在本研究搭建的試驗(yàn)環(huán)境中進(jìn)行代碼編寫。試驗(yàn)方案設(shè)計(jì)如下:
步驟1:準(zhǔn)備2個(gè)數(shù)據(jù)集,將包含任意朝向葉片的原始數(shù)據(jù)集標(biāo)志為Data1,經(jīng)過正形機(jī)制處理后的數(shù)據(jù)集標(biāo)志為Data2,比較4種神經(jīng)網(wǎng)絡(luò)模型(LeNet、MobileNet、SqueezeNet、GKFENet)在2種數(shù)據(jù)集上的準(zhǔn)確率和魯棒性,驗(yàn)證正形機(jī)制操作處理后的數(shù)據(jù)集對(duì)模型性能的影響。
步驟2:確定模型中所包含的Fire模塊數(shù)量,并對(duì)比模型加入關(guān)鍵特征提取模塊前后各性能指標(biāo)的變化情況,驗(yàn)證該模塊加入的必要性。
步驟3:將GKFENet模型與其他模型進(jìn)行對(duì)比,從準(zhǔn)確率、模型大小、識(shí)別速度、魯棒性以及穩(wěn)定性等多個(gè)維度進(jìn)行試驗(yàn),驗(yàn)證所提出模型的綜合性能。
2 結(jié)果與分析
2.1 正形機(jī)制對(duì)不同模型識(shí)別性能的影響
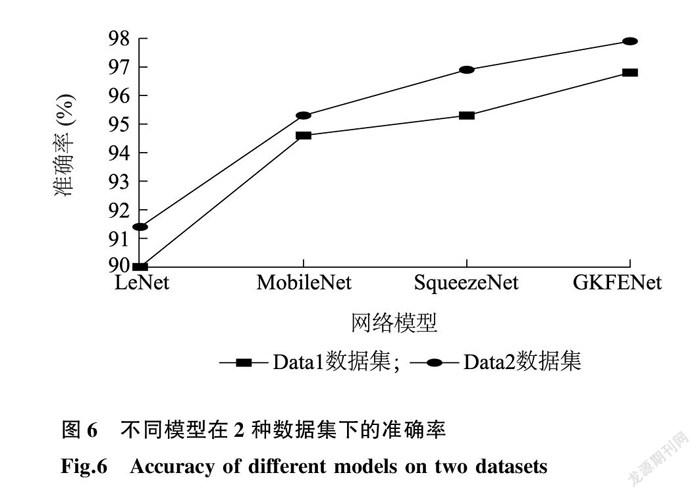
圖6展示了不同分類模型在2種數(shù)據(jù)集上得到的試驗(yàn)結(jié)果,可以看出,與Data1數(shù)據(jù)集相比,LeNet、MobileNet、SqueezeNet、GKFENet模型在Data2數(shù)據(jù)集上表現(xiàn)出更優(yōu)的性能,且各模型的準(zhǔn)確率均提升了1%左右。這可能是因?yàn)榫矸e神經(jīng)網(wǎng)絡(luò)具備學(xué)習(xí)能力,在訓(xùn)練的過程中可以根據(jù)損失函數(shù)不斷更新參數(shù),而朝向統(tǒng)一的圖片能夠進(jìn)一步加深網(wǎng)絡(luò)模型的“理解和記憶”,有助于模型快速、細(xì)致地學(xué)習(xí)到目標(biāo)特征,得到更優(yōu)的一組權(quán)重參數(shù),從而使模型獲得更高的準(zhǔn)確率。
為了進(jìn)一步探究正形機(jī)制對(duì)模型魯棒性的影響,分別在Data1、Data2數(shù)據(jù)集上添加同等的高斯噪聲。圖7顯示,在2個(gè)數(shù)據(jù)集中添加高斯噪聲后,各個(gè)模型的準(zhǔn)確率均出現(xiàn)不同程度的下降,每個(gè)模型在Data1數(shù)據(jù)集上的準(zhǔn)確率下降幅度均高于在Data2數(shù)據(jù)集上的下降幅度。不難分析出,由于數(shù)據(jù)集經(jīng)過正形機(jī)制處理,幾乎所有葉片都位于圖片的中心位置,而病害特征也會(huì)局限在這個(gè)區(qū)域內(nèi),因此根據(jù)這些同向的葉片,神經(jīng)網(wǎng)絡(luò)模型將提取到更多相關(guān)的、重疊的特征,可以在一定程度上緩解噪聲環(huán)境的干擾。綜上可以得出,對(duì)數(shù)據(jù)進(jìn)行正形機(jī)制處理,有助于提高模型的準(zhǔn)確率和魯棒性。因此,后續(xù)研究均采用Data2數(shù)據(jù)集進(jìn)行試驗(yàn)。
2.2 GKFENet模型的綜合性能
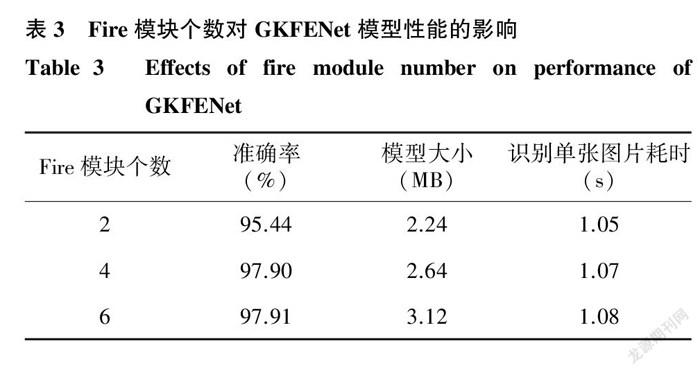
2.2.1 Fire模塊個(gè)數(shù)對(duì)模型的影響 結(jié)合本研究所采用數(shù)據(jù)集中的圖片數(shù)量,為了防止過擬合,相應(yīng)刪減了原SqueezeNet網(wǎng)絡(luò)模型中的Fire模塊。為了確定最佳的Fire模塊數(shù)量,分別將含有2個(gè)、4個(gè)和6個(gè)Fire模塊所對(duì)應(yīng)的GKFENet模型在Data2數(shù)據(jù)集上進(jìn)行試驗(yàn)。表3顯示,3種模型識(shí)別單張圖片所用的時(shí)間差距極其微小,說明三者檢測(cè)速度相當(dāng)。當(dāng)模型中的Fire模塊個(gè)數(shù)為2時(shí),此時(shí)占用內(nèi)存最少,準(zhǔn)確率也最低。與Fire模塊個(gè)數(shù)為2時(shí)的模型相比,F(xiàn)ire模塊個(gè)數(shù)為4時(shí),模型大小僅增加0.40 MB,同時(shí)準(zhǔn)確率增加2個(gè)百分點(diǎn)以上。與Fire模塊個(gè)數(shù)為4時(shí)的模型相比,F(xiàn)ire模塊個(gè)數(shù)為6時(shí),模型準(zhǔn)確率幾乎沒有增大,但模型大小卻增加了0.48 MB。通過上述結(jié)果不難分析出,F(xiàn)ire模塊個(gè)數(shù)過多不僅沒有明顯提升準(zhǔn)確率,還可能增加存儲(chǔ)負(fù)擔(dān);若數(shù)量過少,雖占用內(nèi)存較少,但不利于對(duì)特征進(jìn)行完全、細(xì)致的提取,從而使得準(zhǔn)確率較低。因此,為了保證設(shè)計(jì)的模型在準(zhǔn)確率、占用內(nèi)存方面均具備較好的表現(xiàn),最終在模型中保留4個(gè)Fire模塊,此時(shí)GKFENet模型的綜合性能更佳。
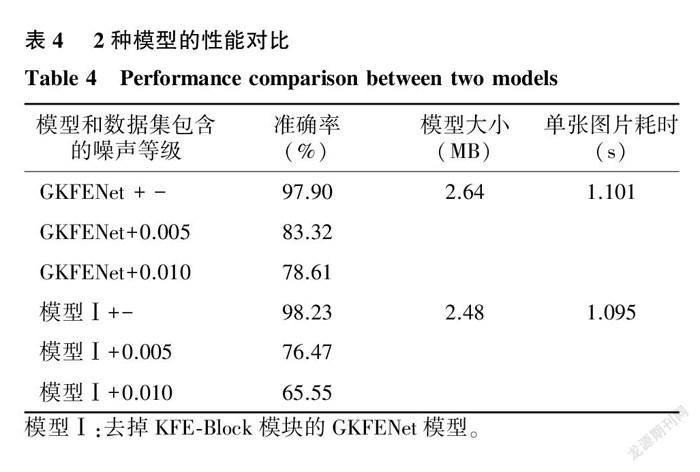
2.2.2 關(guān)鍵特征提取模塊對(duì)模型的影響 為了驗(yàn)證關(guān)鍵特征提取模塊對(duì)網(wǎng)絡(luò)模型性能的影響,在Data2數(shù)據(jù)集上對(duì)GKFENet模型和去掉KFE-Block模塊的GKFENet模型進(jìn)行訓(xùn)練,將后者命名為模型Ⅰ。結(jié)果(表4)表明,與GKFENet模型相比,模型Ⅰ準(zhǔn)確率略高,模型略小,識(shí)別速度略快,但二者均處于同一數(shù)量級(jí),差別甚微,因此都能滿足小型化、快速、精準(zhǔn)識(shí)別的要求。然而,當(dāng)在Data2的測(cè)試集中添加不同級(jí)別的高斯噪聲時(shí),模型Ⅰ的準(zhǔn)確率驟降,且下降的幅度分別高達(dá)21.76個(gè)百分點(diǎn)、32.68個(gè)百分點(diǎn),幾乎很難精準(zhǔn)地識(shí)別病害,而GKFENet模型的準(zhǔn)確率降低幅度均不超過20.00%,仍能保持78.00%以上的識(shí)別準(zhǔn)確率。這是因?yàn)槟P椭邪年P(guān)鍵特征提取模塊能夠抓住主要的、關(guān)鍵的特征,忽略其他不重要的特征或者干擾源,從而具有較好的魯棒性。在評(píng)估模型性能時(shí),準(zhǔn)確率、模型大小固然重要,但魯棒性同樣必不可少,否則模型僅僅是在實(shí)驗(yàn)室中的識(shí)別效果好,一旦應(yīng)用到復(fù)雜的實(shí)際農(nóng)業(yè)環(huán)境中,性能將大打折扣,無法滿足現(xiàn)實(shí)需求。因此,從準(zhǔn)確率、模型大小和魯棒性3個(gè)維度綜合考慮,在本研究提出的GKFENet模型中加入KFE-Block模塊是很有必要的。
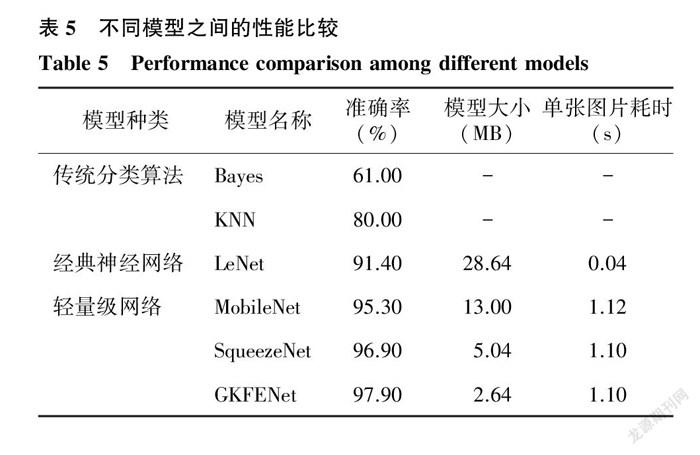
2.2.3 模型的準(zhǔn)確率和模型大小 本研究基于數(shù)據(jù)集Data2,比較3種分類模型對(duì)番茄8種病害圖像識(shí)別的準(zhǔn)確率、模型大小和識(shí)別單張圖片所用時(shí)間。表5顯示,GKFENet模型的準(zhǔn)確率為97.90%,遠(yuǎn)遠(yuǎn)高于傳統(tǒng)分類算法模型Bayes和KNN;與經(jīng)典神經(jīng)網(wǎng)絡(luò)模型LeNet相比,雖然單張圖片識(shí)別耗時(shí)略久,但在準(zhǔn)確率和模型大小2個(gè)方面表現(xiàn)較好。GKFENet模型與2種常見的輕量級(jí)網(wǎng)絡(luò)模型MobileNet、SqueezeNet相比,單張圖片識(shí)別耗時(shí)相當(dāng),但GKFENet模型僅占2.64 MB,內(nèi)存需求更小,且準(zhǔn)確率更高,識(shí)別性能更好。在番茄識(shí)別的實(shí)際應(yīng)用中,準(zhǔn)確率和模型大小是更為重要的性能指標(biāo),因此,綜合考慮模型的性能和可移植性,GKFENet網(wǎng)絡(luò)模型具有一定的應(yīng)用優(yōu)勢(shì)。
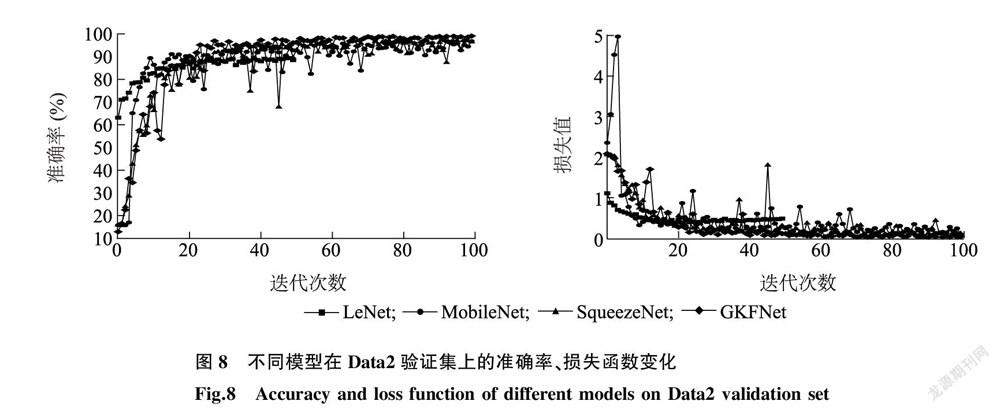
2.2.4 模型的穩(wěn)定性和魯棒性 本研究分析了LeNet、MobileNet、SqueezeNet、GKFENet這4種神經(jīng)網(wǎng)絡(luò)模型在100輪迭代過程中的準(zhǔn)確率、損失函數(shù)變化情況,其中LeNet模型只迭代了50輪,因?yàn)?0輪以后出現(xiàn)驗(yàn)證集準(zhǔn)確率上升,而損失值不降反增的現(xiàn)象,模型發(fā)生過擬合。圖8顯示,MobileNet模型和SqueezeNet模型在訓(xùn)練初期,均能快速達(dá)到較高的準(zhǔn)確率,但在迭代過程中發(fā)生明顯抖動(dòng),且抖動(dòng)持續(xù)時(shí)間較長(zhǎng),模型穩(wěn)定性較低。LeNet模型雖然上升比較平穩(wěn),但準(zhǔn)確率明顯低于其他3種模型。對(duì)于GKFENet模型,雖然初始迭代時(shí)準(zhǔn)確率上升相對(duì)緩慢,也有幾次抖動(dòng),但隨著迭代次數(shù)的增加,模型準(zhǔn)確率呈平穩(wěn)上升趨勢(shì),在整個(gè)后期訓(xùn)練中只有微小的浮動(dòng),且最終的準(zhǔn)確率高于其他3種模型,損失值最小,因此GKFENet模型具有較好的穩(wěn)定性。
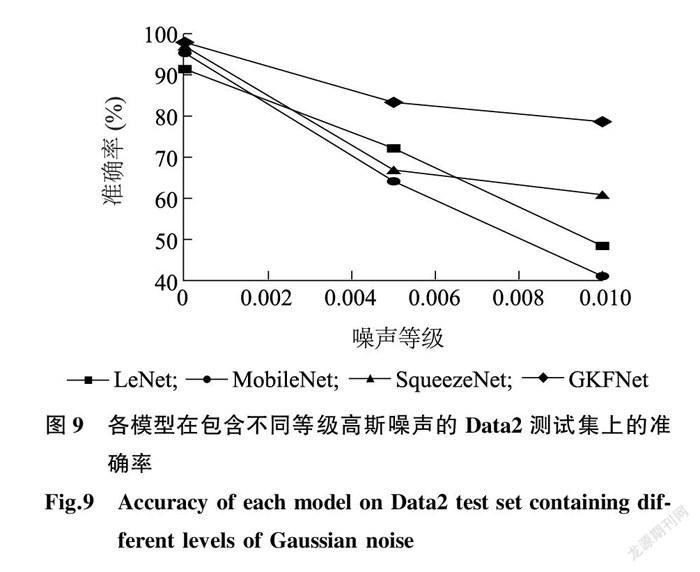
圖9顯示,隨著高斯噪聲等級(jí)的增加,各個(gè)模型的準(zhǔn)確率都有所降低,除GKFENet模型外,LeNet模型、MobileNet模型、SqueezeNet模型的準(zhǔn)確率均出現(xiàn)大幅驟降,當(dāng)噪聲等級(jí)增加到0.01時(shí),這3個(gè)模型的準(zhǔn)確率均低于61.00%,此時(shí)這些模型無法正常完成病害識(shí)別任務(wù)。而對(duì)于GKFENet模型,在同樣的強(qiáng)噪聲干擾下,準(zhǔn)確率仍能達(dá)到78.61%,可以準(zhǔn)確識(shí)別出番茄病害數(shù)據(jù)集約3/4的圖片。說明,GKFENet模型在噪聲干擾的環(huán)境中,仍然具備良好的識(shí)別性能,準(zhǔn)確率雖有降低但在可接受范圍內(nèi),具有較好的魯棒性。
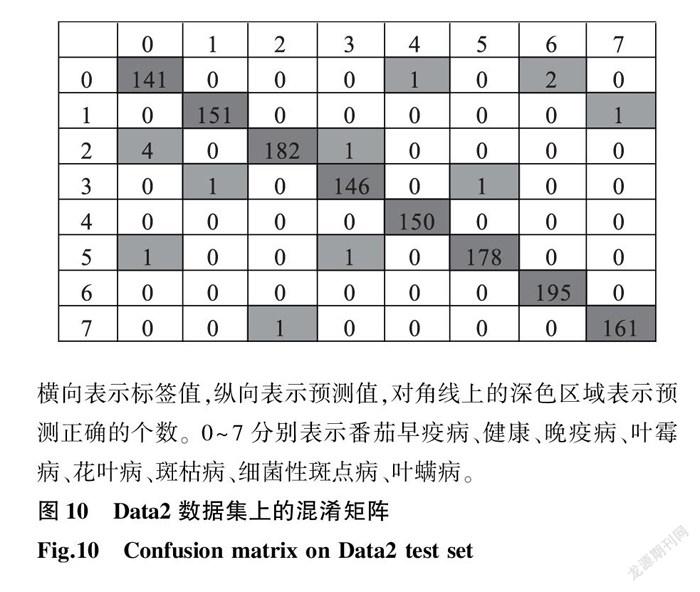
分析GKFENet模型在數(shù)據(jù)集Data2測(cè)試集上的混淆矩陣,圖10橫向數(shù)據(jù)表示標(biāo)簽值,縱向數(shù)據(jù)表示預(yù)測(cè)值,對(duì)角線上的深色區(qū)域內(nèi)數(shù)據(jù)表示預(yù)測(cè)正確的個(gè)數(shù)。0~ 7分別表示番茄早疫病、健康、晚疫病、葉霉病、花葉病、斑枯病、細(xì)菌性斑點(diǎn)病、葉螨病,對(duì)應(yīng)的預(yù)測(cè)準(zhǔn)確率分別為96.58%、99.34%、99.45%、98.65%、99.34%、99.44%、98.98%、99.38%。本研究構(gòu)建模型對(duì)早疫病的識(shí)別能力稍弱,對(duì)其他7類病害的識(shí)別準(zhǔn)確率均在98.00%以上。這是因?yàn)樵缫卟D片本身數(shù)量少,并且圖片中展現(xiàn)的病害嚴(yán)重程度不同,不利于網(wǎng)絡(luò)學(xué)習(xí),所以準(zhǔn)確率略低。
3 結(jié) 論
為了滿足精準(zhǔn)農(nóng)業(yè)的發(fā)展需求 [24-26] ,本研究基于番茄病害的現(xiàn)有研究成果,提出一種自適應(yīng)特征提取的番茄病害識(shí)別方法。根據(jù)2種數(shù)據(jù)集以及GKFENet、Bayes、KNN、LeNet、SqueezeNet、MobileNet這6個(gè)模型設(shè)計(jì)對(duì)比試驗(yàn),分析試驗(yàn)結(jié)果,得出以下結(jié)論:
第一,經(jīng)過正形處理后,4種網(wǎng)絡(luò)模型的準(zhǔn)確率提高1%左右,且魯棒性增強(qiáng),說明正形機(jī)制與神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)能力相配合,能起到正向增強(qiáng)作用。
第二,GKFENet將全局特征提取和關(guān)鍵特征提取2個(gè)模塊有效結(jié)合,在獲取基礎(chǔ)語義信息的基礎(chǔ)上進(jìn)一步篩選出重要的特征,并弱化不相關(guān)的特征。這種自適應(yīng)提取病害特征的方式能夠更精準(zhǔn)地提取到關(guān)鍵特征,實(shí)現(xiàn)了對(duì)8種番茄葉片病害的精確識(shí)別,與現(xiàn)有的一些識(shí)別方法相比,該方法具有明顯優(yōu)勢(shì)。
在前期工作的基礎(chǔ)上,結(jié)合精準(zhǔn)農(nóng)業(yè)的發(fā)展藍(lán)圖以及現(xiàn)有的技術(shù)背景,本研究構(gòu)建的模型在計(jì)算復(fù)雜度和參數(shù)量方面還可進(jìn)一步優(yōu)化、提升,使其能夠在移動(dòng)端上快速精準(zhǔn)地識(shí)別出病害類別,從而實(shí)現(xiàn)病害的早期評(píng)估和預(yù)警,減少作物損失。
參考文獻(xiàn):
[1] TM P, PRANATHI A, SAIASHRITHA K, et al. Tomato leaf disease detection using convolutional neural networks: 2018 International conference on contemporary computing (IC3) [C]. Piscataway: IEEE Press, 2018.
[2] MIM T, SHEIKH M H, SHAMPA R A, et al. Leaves diseases detection of tomato using image processing: 2019 International conference on system modeling and advancement in research trends (SMART) [C]. Piscataway: IEEE Press, 2019.
[3] MOKHTAR U, ALI M A S, HASSANIEN A E, et al. Identifying two of tomatoes leaf viruses using support vector machine[M]. New Delhi: Springer Press, 2015:771-782.
[4] 柴 洋,王向東. 基于圖像處理的溫室大棚中番茄的病害識(shí)別[J]. 自動(dòng)化技術(shù)與應(yīng)用, 2013, 32(9): 83-89.
[5] JIANG D, LI F, YANG Y, et al. A tomato leaf diseases classification method based on deep learning: 2020 Chinese control and decision conference (CCDC) [C].? Piscataway: IEEE Press, 2020.
[6] RANGARAJAN A K, PURUSHOTHAMAN R, RAMESH A. Tomato crop disease classification using pre-trained deep learning algorithm[J]. Procedia Computer Science, 2018, 133: 1040-1047.
[7] 王艷玲,張宏立,劉慶飛,等. 基于遷移學(xué)習(xí)的番茄葉片病害圖像分類[J]. 中國(guó)農(nóng)業(yè)大學(xué)學(xué)報(bào), 2019, 24(6): 124-130.
[8] JIA S, JIA P, HU S, et al. Automatic detection of tomato diseases and pests based on leaf images: 2017 Chinese automation congress (CAC) [C].? Piscataway: IEEE Press, 2017.
[9] WU Q, CHEN Y, MENG J. DCGAN based data augmentation for tomato leaf disease identification[J]. IEEE Access, 2020,8: 98716-98728.
[10] 胡志偉,楊 華,黃濟(jì)民,等. 基于注意力殘差機(jī)制的細(xì)粒度番茄病害識(shí)別[J]. 華南農(nóng)業(yè)大學(xué)學(xué)報(bào), 2019, 40(6): 124-132.
[11] 李曉振,徐 巖,吳作宏,等. 基于注意力神經(jīng)網(wǎng)絡(luò)的番茄葉部病害識(shí)別系統(tǒng)[J]. 江蘇農(nóng)業(yè)學(xué)報(bào), 2020, 36(3): 561-568.
[12] MEERADEVI A K, RANJANA V, MUNDADA M R, et al. Design and development of efficient techniques for leaf disease detection using deep convolutional neural networks: 2020 IEEE international conference on distributed computing vlsi electrical circuits and robotics (DISCOVER) [C].? Piscataway: IEEE Press, 2020.
[13] 方晨晨,石繁槐. 基于改進(jìn)深度殘差網(wǎng)絡(luò)的番茄病害圖像識(shí)別[J]. 計(jì)算機(jī)應(yīng)用, 2020, 40(增刊1): 203-208.
[14] 郭小清,范濤杰,舒 欣. 基于改進(jìn)Multi-Scale AlexNet的番茄葉部病害圖像識(shí)別[J]. 農(nóng)業(yè)工程學(xué)報(bào), 2019, 35(13): 162-169.
[15] ELHASSOUNY A, SMARANDACHE F. Smart mobile application to recognize tomato leaf diseases using convolutional neural networks: 2019 International conference of computer science and renewable energies (ICCSRE) [C]. Piscataway: IEEE Press, 2019.
[16] AGARWAL M, GUPTA S K, BISWAS K K. Development of efficient CNN model for tomato crop disease identification [J]. Sustainable Computing: Informatics and Systems, 2020, 28(1):100407.
[17] HU J, SHEN L, SUN G, et al. Squeeze-and-excitation networks: IEEE conference on computer vision and pattern recognition[C]. Piscataway: IEEE Press, 2017.
[18] HUGHES D P, SALATHE M. An open access repository of images on plant health to enable the development of mobile disease diagnostics[EB/OL]. (2016-04-04)[2021-09-20]. https://arxiv.53yu.com/ftp/arxiv/papers/1511/1511.08060.
[19] 劉子記,杜公福,牛 玉,等. 番茄主要病害的發(fā)生與防治技術(shù)[J]. 長(zhǎng)江蔬菜, 2019(19): 59-62.
[20] 劉鵬鵬. 基于深度學(xué)習(xí)的番茄葉面型病蟲害識(shí)別研究[D]. 南昌:南昌大學(xué), 2020.
[21] CANNY J. A computational approach to edge detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1986, 8(6): 679-698.
[22] 宋余慶,謝 熹,劉 哲,等. 基于多層EESP深度學(xué)習(xí)模型的農(nóng)作物病蟲害識(shí)別方法[J]. 農(nóng)業(yè)機(jī)械學(xué)報(bào), 2020, 51(8): 196-202.
[23] IANDOLA F N, HAN S, MOSKEWICZ M W, et al. SqueezeNet:Alexnet-level accuracy with 50× fewer parameters and <0.5 MB model size[EB/OL]. (2016-11-04)[2021-09-20].https://arxiv.org/abs/1602.07360v4.
[24] 宋永嘉,劉 賓,魏暄云,等. 大數(shù)據(jù)時(shí)代無線傳感技術(shù)在精準(zhǔn)農(nóng)業(yè)中的應(yīng)用進(jìn)展[J].江蘇農(nóng)業(yè)科學(xué),2021,49(8):31-37.
[25] 李仁路,萬書勤,康躍虎,等. 基于微灌工程設(shè)計(jì)成果數(shù)據(jù)的農(nóng)田電子地圖構(gòu)建方法[J].排灌機(jī)械工程學(xué)報(bào),2020,38(9):939-944.
[26] 林 娜,陳 宏,趙 健,等. 輕小型無人機(jī)遙感在精準(zhǔn)農(nóng)業(yè)中的應(yīng)用及展望[J].江蘇農(nóng)業(yè)科學(xué),2020,48(20):43-48.
(責(zé)任編輯:王 妮)
收稿日期:2021-09-20
基金項(xiàng)目:國(guó)家自然科學(xué)基金青年基金項(xiàng)目(61601076);大連市科技創(chuàng)新基金項(xiàng)目(2020JJ26SN058)
作者簡(jiǎn)介:胡玲艷(1978-),女,河北滄州人,博士,副教授,主要從事智慧農(nóng)業(yè)、作物動(dòng)態(tài)生長(zhǎng)監(jiān)測(cè)研究。(E-mail)hulingyan@dlu.edu.cn
通訊作者:汪祖民,(E-mail)wangzumin@dlu.edu.cn
猜你喜歡
艦船科學(xué)技術(shù)(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動(dòng)化學(xué)報(bào)(2017年7期)2017-04-18 13:41:09
自動(dòng)化學(xué)報(bào)(2017年11期)2017-04-04 02:52:58
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
廣西科技大學(xué)學(xué)報(bào)(2016年1期)2016-06-22 13:10:38
計(jì)算機(jī)工程(2015年4期)2015-07-05 08:28:02
機(jī)電信息(2015年3期)2015-02-27 15:54:46
機(jī)械工程師(2015年10期)2015-02-02 01:13:49
