基于非對(duì)稱(chēng)卷積的大規(guī)模天線信道狀態(tài)信息反饋算法
2022-07-18 09:10:44李婷婷辛雨桐
無(wú)線電通信技術(shù) 2022年4期
關(guān)鍵詞:模型
李婷婷,辛雨桐,冉 鵬,曹 彪,楊 陽(yáng)
(北京郵電大學(xué) 人工智能學(xué)院,北京 100876)
0 引言
大規(guī)模天線技術(shù)是未來(lái)無(wú)線通信系統(tǒng)中的關(guān)鍵技術(shù)之一,具有高頻譜效率以及大容量鏈路等優(yōu)勢(shì)[1]。獲得這些優(yōu)勢(shì)的前提是具有向基站(BS)反饋較高的信道狀態(tài)信息(CSI)質(zhì)量。然而,大規(guī)模天線系統(tǒng)中由于天線數(shù)量很多,形成了龐大的CSI矩陣,導(dǎo)致無(wú)法在信道容量受限的條件下完整反饋CSI。
為了突破CSI反饋中的這一技術(shù)瓶頸,近年來(lái)基于深度學(xué)習(xí)的自編碼器獲得了廣泛關(guān)注[2-12]。東南大學(xué)金石教授團(tuán)隊(duì)[2]最先提出CsiNet,驗(yàn)證了其與傳統(tǒng)壓縮感知(Compress Sensing,CS)方案之間的巨大優(yōu)勢(shì)。以此為基礎(chǔ),該團(tuán)隊(duì)又提出了CsiNet+并加入了信道傳輸量化的考量[3]。基于CsiNet[2],大多數(shù)基于深度學(xué)習(xí)的后續(xù)方法利用更強(qiáng)大的深度學(xué)習(xí)塊構(gòu)建,以犧牲計(jì)算開(kāi)銷(xiāo)來(lái)獲得更好的性能。CsiNet-LSTM[4]和Attention-CSI[5]引入了LSTM[6],顯著增加了計(jì)算開(kāi)銷(xiāo);DS-NLCsiNet[7]采用非本地阻塞提高其捕獲長(zhǎng)程相關(guān)性的效率;CsiNet+[3]和DS-NLCsiNet[7]的計(jì)算開(kāi)銷(xiāo)約比CsiNet[2]分別高6和2.5倍。近年來(lái),一些降低復(fù)雜度的方法開(kāi)始出現(xiàn),如JCNet[8]和BcsiNet[9],但它們的性能也有所下降。文獻(xiàn)[10]利用深度循環(huán)網(wǎng)絡(luò)來(lái)開(kāi)發(fā)通道相關(guān)性。之后,CRNet[11]在網(wǎng)絡(luò)中使用了多分辨率架構(gòu),并強(qiáng)調(diào)了訓(xùn)練方案的重要性。此外,文獻(xiàn)[12]提出了ConvCsiNet,其中網(wǎng)絡(luò)基于卷積,同時(shí)也提出了ShuffleCsiNet,以使編碼器部分輕量化。然而,上述模型的性能還可以進(jìn)一步提高,尤其是在戶(hù)外場(chǎng)景中。此外,在實(shí)際部署中,還需要考慮模型的參數(shù)量和泛化能力。
本文設(shè)計(jì)了一個(gè)名為Asy-CSINet的自編碼器網(wǎng)絡(luò),深入研究了解碼器的部分,并使用非對(duì)稱(chēng)卷積塊[13]來(lái)進(jìn)一步提高網(wǎng)絡(luò)性能。此外,使用深度可分離卷積來(lái)減輕編碼器端,從而保留網(wǎng)絡(luò)的基本結(jié)構(gòu)。在實(shí)際部署中,不同的壓縮比和不同的場(chǎng)景對(duì)應(yīng)不同的神經(jīng)網(wǎng)絡(luò)。還探索了多模型綜合集成的可能性,以進(jìn)一步減少需要存儲(chǔ)在用戶(hù)設(shè)備中的參數(shù)數(shù)量。
本文的主要貢獻(xiàn)包括三方面:首先,提出了自編碼器框架Asy-CSINet。由于更深的解碼器端和非對(duì)稱(chēng)卷積模塊的使用,戶(hù)外場(chǎng)景的性能得到了極大的提升。其次,在Asy-CSINet的基礎(chǔ)上,引入了一個(gè)算法裁剪模型Asy-CSINet-l,其性能雖然略有下降,但更適合用戶(hù)端。第三,討論了多速率融合方案和多場(chǎng)景融合方案,大大提高了網(wǎng)絡(luò)的泛化能力。
1 大規(guī)模天線CSI反饋架構(gòu)

(1)

(2)
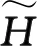
(3)

通過(guò)上述方法,雖然矩陣H的規(guī)模大大減小,但其傳輸開(kāi)銷(xiāo)仍然很大,可以進(jìn)一步壓縮。傳統(tǒng)的基于CS的方法在H是稀疏的假設(shè)下壓縮H。然而,該假設(shè)僅在發(fā)射天線數(shù)Nt→∞時(shí)成立,這在實(shí)際系統(tǒng)中是不可實(shí)現(xiàn)的。假設(shè)與實(shí)際系統(tǒng)之間的差距導(dǎo)致了性能問(wèn)題。如果沒(méi)有這樣的假設(shè),基于深度學(xué)習(xí)的框架可以更好地工作。
本文忽略了CSI估計(jì)的過(guò)程,假設(shè)可以得到完美的CSI矩陣。一旦在用戶(hù)估計(jì)CSI矩陣H編碼器將H壓縮為長(zhǎng)度為M的碼字,然后壓縮比可以表示為:
2 自編碼器網(wǎng)絡(luò)
本節(jié)提出了一個(gè)名為Asy-CSINet的自動(dòng)編碼器框架。此外,還提出了一種簡(jiǎn)單的算法剪裁解決方案。最后介紹了多速率多模型集成策略。
2.1 基于非對(duì)稱(chēng)卷積的CSI反饋網(wǎng)絡(luò)(Asy-CSINet)
深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)任務(wù)中顯示出巨大潛力。幸運(yùn)的是,CSI矩陣可以看作是具有實(shí)部和虛部的兩通道圖像。基于此,提出的Asy-CSINet如圖1所示。所有方形卷積核的大小為3×3。在每個(gè)卷積層之后使用LeakyRelu和批量歸一化。與現(xiàn)有的基于深度學(xué)習(xí)的網(wǎng)絡(luò)相比,Asy-CSINet有兩個(gè)主要特點(diǎn),如下所述。
2.1.1 非對(duì)稱(chēng)卷積模塊的使用
Asy-CSINet的基本結(jié)構(gòu)由編碼器端和解碼器端的多個(gè)卷積層組成,同時(shí)避免使用全連接層。最直觀的想法是,如果可以加強(qiáng)卷積層的性能,整個(gè)網(wǎng)絡(luò)的性能就會(huì)得到相應(yīng)的提升。因此,提出了編碼非對(duì)稱(chēng)卷積模塊(Encoding Asymmetric Convolution Block,EACB)和解碼非對(duì)稱(chēng)卷積模塊(Decoding Asymmetric Convolution Block ,DACB)。每個(gè)EACB由一個(gè)非對(duì)稱(chēng)卷積模塊和隨后的平均池化層組成,而每個(gè)DACB由一個(gè)上采樣層和一個(gè)隨后的非對(duì)稱(chēng)卷積模塊組成。非對(duì)稱(chēng)卷積模塊的主要思想是通過(guò)添加兩個(gè)條紋卷積來(lái)增強(qiáng)方形卷積核。如圖1所示,非對(duì)稱(chēng)卷積模塊層的輸出是3個(gè)路徑的總和。在功能上,非對(duì)稱(chēng)卷積模塊中的條帶卷積是為了加強(qiáng)整體網(wǎng)絡(luò)框架,一些實(shí)驗(yàn)已經(jīng)驗(yàn)證了其在計(jì)算機(jī)視覺(jué)任務(wù)中的優(yōu)越性[13],此處在無(wú)線通信領(lǐng)域使用EACB。
非對(duì)稱(chēng)卷積模塊的另一個(gè)優(yōu)點(diǎn)是它只增加了訓(xùn)練階段的參數(shù)數(shù)量,在部署階段,它可以等效地轉(zhuǎn)換為標(biāo)準(zhǔn)的卷積結(jié)構(gòu),這意味著可以使用非對(duì)稱(chēng)卷積模塊而不需要額外的開(kāi)銷(xiāo)。從非對(duì)稱(chēng)卷積模塊到標(biāo)準(zhǔn)卷積的轉(zhuǎn)換依賴(lài)于卷積的可加性。對(duì)于以I∈RU×V×C作為輸入和O∈RR×T×D作為輸出的卷積運(yùn)算,需要D個(gè)卷積核F∈RH×W×C。那么O的第j個(gè)通道是:
(4)
(5)
式中,X表示對(duì)應(yīng)位置的滑動(dòng)窗口。式(5)說(shuō)明了卷積的一個(gè)重要性質(zhì):如果多個(gè)卷積核共享同一個(gè)滑動(dòng)窗口X,當(dāng)它們以相同的步幅應(yīng)用于相同的輸入以生成具有相同分辨率的輸出時(shí),它們的輸出之和等于單個(gè)卷積算子使用內(nèi)核的總和,即便使用的內(nèi)核大小不同,如等式所示:
I*F(1)+I*F(2)=I*[F(1)⊕F(2)]。
(6)
非對(duì)稱(chēng)卷積模塊中的3個(gè)并行卷積核共享同一個(gè)滑動(dòng)窗口,這意味著它可以通過(guò)式(6)進(jìn)行轉(zhuǎn)換。更多的轉(zhuǎn)換細(xì)節(jié)可以在文獻(xiàn)[13]中找到。
2.1.2 加深的網(wǎng)絡(luò)編碼器結(jié)構(gòu)
在室內(nèi)場(chǎng)景中,CSI矩陣的非零點(diǎn)很少,而在室外場(chǎng)景中,由于非零點(diǎn)變得分散和模糊,CSI矩陣更加復(fù)雜。一般來(lái)說(shuō),更多的特征總是需要更大的網(wǎng)絡(luò)來(lái)豐富計(jì)算機(jī)視覺(jué)領(lǐng)域的表達(dá)能力。但是在編碼器端,參數(shù)太多是不可接受的,難以部署;解碼端存儲(chǔ)在具有足夠計(jì)算能力的基站中。遷移計(jì)算機(jī)視覺(jué)領(lǐng)域的經(jīng)驗(yàn),增加了ConvCsiNet解碼端的深度。本文使用了5個(gè)DACB,輸出通道分別為512、512、256、128、8。值得注意的是,DACB中包含的上采樣操作會(huì)使特征圖的大小增大一倍,因此在第4個(gè)DACB之后運(yùn)行了一個(gè)額外的平均池化層。此外,還將Refine-Block中卷積層的輸出通道更改為8、16、16、8,以便將更多有用的信息傳遞給后續(xù)層。
2.2 Asy-CSINet的算法裁剪
雖然本文提出的Asy-CSINet可以處理CSI壓縮和解壓縮問(wèn)題,但實(shí)際部署必須考慮參數(shù)的量。在無(wú)線通信系統(tǒng)中,移動(dòng)通信得到了廣泛的應(yīng)用,這意味著編碼器不能包含太多的參數(shù)。本文采用了一種簡(jiǎn)潔的算法裁剪方法Asy-CSINet-l,受 MobileNet[14]的啟發(fā),使用深度可分離卷積來(lái)使編碼器更加輕量化。通過(guò)將EACB的非對(duì)稱(chēng)卷積模塊替換為深度可分離卷積,編碼器端的參數(shù)數(shù)量顯著減少,同時(shí)保留了原始結(jié)構(gòu)。
本文也嘗試直接使用MobileNet來(lái)裁剪ACCsiNet的編碼器結(jié)構(gòu),即形成MobileNet-en。Asy-CSINet-l使用平均池化層來(lái)減小特征圖的大小,而對(duì)于MobileNet-en,使用步長(zhǎng)為2的深度可分離卷積來(lái)達(dá)到相同的效果。
2.3 多速率集成和多場(chǎng)景集成
在實(shí)際的通信系統(tǒng)中,壓縮率可能會(huì)隨著環(huán)境的變化而變化。實(shí)驗(yàn)中使用的壓縮率是16、32、64,這意味著用戶(hù)端需要為3個(gè)不同的壓縮率存儲(chǔ)3個(gè)不同的編碼器網(wǎng)絡(luò),導(dǎo)致實(shí)際中難以實(shí)現(xiàn)。為了處理這樣的問(wèn)題,本文提出了一個(gè)名為Asy-CSINet-mr的多速率網(wǎng)絡(luò)。Asy-CSINet-l僅包含卷積層,前一個(gè)卷積將特征提取到高維通道,而最后一個(gè)卷積層根據(jù)壓縮率減少輸出維度。所以本文讓不同壓縮率的編碼器網(wǎng)絡(luò)共享前面卷積層的參數(shù),只有最后一個(gè)卷積層是分開(kāi)的。該模型如圖2所示,3個(gè)并行輸出卷積層對(duì)應(yīng)3個(gè)壓縮率(16,32,64)。經(jīng)過(guò)網(wǎng)絡(luò)的公共部分后,進(jìn)行壓縮率選擇,選擇某個(gè)輸出層。在基站端,由于其存儲(chǔ)空間大,不同的壓縮率對(duì)應(yīng)不同的解碼器網(wǎng)絡(luò),因此基站中可以存儲(chǔ)3個(gè)解碼器。
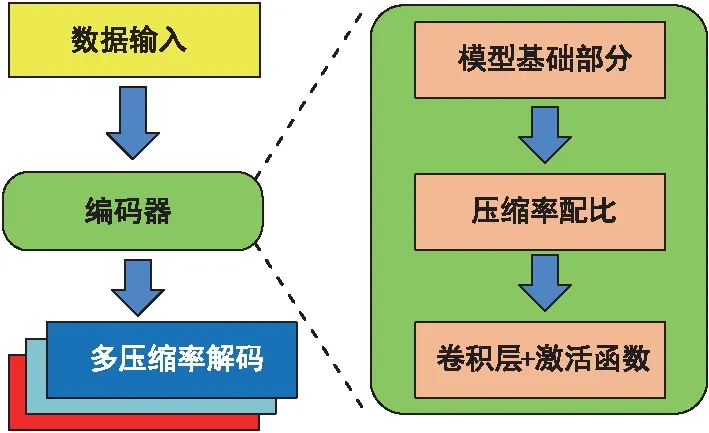
圖2 多速率集成模型架構(gòu)
在許多計(jì)算機(jī)視覺(jué)的任務(wù)中,一個(gè)深度神經(jīng)網(wǎng)絡(luò)可以同時(shí)處理多個(gè)數(shù)據(jù)。同樣,CSI矩陣在實(shí)際應(yīng)用中會(huì)隨著環(huán)境不斷變化,因此需要不斷切換壓縮和重構(gòu)模型,進(jìn)一步地,探索了多場(chǎng)景集成的可能性。
3 實(shí)驗(yàn)結(jié)果及分析
3.1 實(shí)驗(yàn)設(shè)置
為了公平地比較實(shí)驗(yàn)結(jié)果,本文使用與CsiNet相同的數(shù)據(jù)集。所有通道矩陣均由COST 2100[15]生成。考慮2種典型場(chǎng)景,包括5.3 GHz的室內(nèi)場(chǎng)景和300 MHz的室外場(chǎng)景。在基站端,采用了Nt=32和Nc=1 024的均勻線性陣列模型。轉(zhuǎn)換為角延遲域后,僅保留前Nc=32行。實(shí)驗(yàn)中使用的壓縮率為16、32和64。總共150 000個(gè)生成的CSI矩陣被分為訓(xùn)練、驗(yàn)證和測(cè)試數(shù)據(jù)集,分別由100 000、30 000和20 000個(gè)樣本組成。
在訓(xùn)練階段,使用自適應(yīng)矩陣估計(jì)優(yōu)化器來(lái)更新可訓(xùn)練參數(shù)。均方誤差(Mean Squared Error,MSE)被計(jì)算為損失函數(shù)。總訓(xùn)練輪次和每次的批次大小分別設(shè)置為500和200。受CRNet[5]啟發(fā),使用余弦退火學(xué)習(xí)率(Learning Rate,LR)和預(yù)熱來(lái)加速參數(shù)收斂。不同的是每批次而不是每個(gè)時(shí)期都改變LR,那么LR可以表示為:
(7)
其中,ηmax,ηmin分別代表初始的LR和最終的LR;i、Nw和Ns分別是當(dāng)前步數(shù)、預(yù)熱步數(shù)和總步數(shù)。在預(yù)熱階段,根據(jù)余弦退火函數(shù),LR線性增加到ηmax,然后LR非線性減小到ηmin。在訓(xùn)練階段之后,學(xué)習(xí)到的超參數(shù)可以集成到方核卷積中,從而消除非對(duì)稱(chēng)卷積模塊帶來(lái)的開(kāi)銷(xiāo)。
對(duì)于評(píng)估指標(biāo),使用歸一化均方誤差(Normalized Mean Squared Error,NMSE)和余弦相似度ρ來(lái)表示重建誤差。
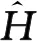
(8)
為了與之前的模型進(jìn)行比較,還計(jì)算了余弦相似度ρ:
(9)

3.2 Asy-CSINet性能評(píng)估
將Asy-CSINet與一些基于深度學(xué)習(xí)的方法進(jìn)行比較,例如CsiNet[2]等。為了探索影響模型性能的因素,將Asy-CSINet中的非對(duì)稱(chēng)卷積模塊替換為卷積層,其N(xiāo)MSE性能對(duì)比結(jié)果顯示如圖3和圖4。
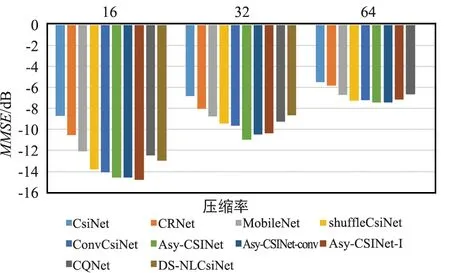
圖3 不同壓縮率下NMSE性能對(duì)比(室內(nèi))

圖4 不同壓縮率下NMSE性能對(duì)比(室外)
對(duì)于戶(hù)外場(chǎng)景,與之前的研究相比,性能提升相當(dāng)可觀。Asy-CSINet-conv和ConvCsiNet的區(qū)別在于解碼器端的更深層。室內(nèi)場(chǎng)景的CSI矩陣比較簡(jiǎn)單,因此較大的模型并不能大大提高性能。對(duì)于室外CSI矩陣,特征點(diǎn)更加復(fù)雜和分散,使用更深的網(wǎng)絡(luò)可以豐富表達(dá)能力,從而獲得更高的性能。此外,還使用了帶有不同濾波器的DACB層,添加更多濾波器時(shí)性能會(huì)提高,但解碼器端的參數(shù)數(shù)量也會(huì)大大增加。在實(shí)驗(yàn)中,選擇添加一個(gè)具有512層輸出的額外DACB,以平衡性能和參數(shù)數(shù)量。
使用非對(duì)稱(chēng)卷積模塊后的結(jié)果顯示在“Asy-CSINet”中,這表明使用非對(duì)稱(chēng)卷積模塊可以進(jìn)一步提高性能。非對(duì)稱(chēng)卷積模塊通過(guò)添加2個(gè)帶狀卷積更好地關(guān)注水平和垂直特征。正如文獻(xiàn)[13]所解釋的,卷積核的骨架是核心部分,2個(gè)額外的帶狀卷積顯著增強(qiáng)了骨架,從而在訓(xùn)練階段豐富了特征空間。值得注意的是,Asy-CSINet對(duì)Asy-CSINet-conv的性能提升在室內(nèi)場(chǎng)景下較小。實(shí)驗(yàn)現(xiàn)象表明,改進(jìn)還取決于CSI矩陣的復(fù)雜性。室內(nèi)性能主要受壓縮率限制,而室外性能可以通過(guò)使用更強(qiáng)大的工作模塊來(lái)提高。
此外,Asy-CSINet的余弦相似度對(duì)比結(jié)果如圖5所示,可以看出,同圖3和圖4類(lèi)似,模型在戶(hù)外場(chǎng)景中的性能提升比較大。值得注意的是,在傳統(tǒng)的CRNet中,一般通過(guò)使用不同的核大小來(lái)提供多分辨率的能力,而在Asy-CSINet-conv中,為了發(fā)現(xiàn)各種尺度的特征,特征圖的大小逐漸改變并使用固定大小的核進(jìn)行提取。可以看出,漸進(jìn)式特征提取使Asy-CSINet-conv的性能優(yōu)于CRNet。
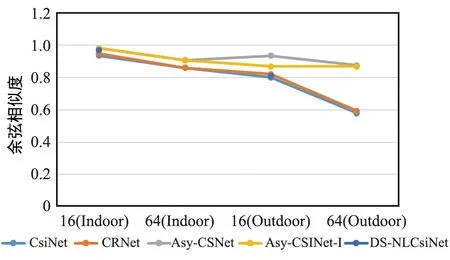
圖5 不同模型的余弦相似度對(duì)比
3.3 Asy-CSINet-l性能評(píng)估
ShuffleCsiNet[6]使用Shuffle Network (SN)來(lái)減少ConvCsiNet的參數(shù),本文使用一種更簡(jiǎn)潔的方法來(lái)裁剪編碼器網(wǎng)絡(luò)。為了保留原始神經(jīng)網(wǎng)絡(luò)的優(yōu)越性,利用深度可分離卷積來(lái)替換EACB中的非對(duì)稱(chēng)卷積模塊,即Asy-CSINet-l。結(jié)果如圖6和圖7所示。
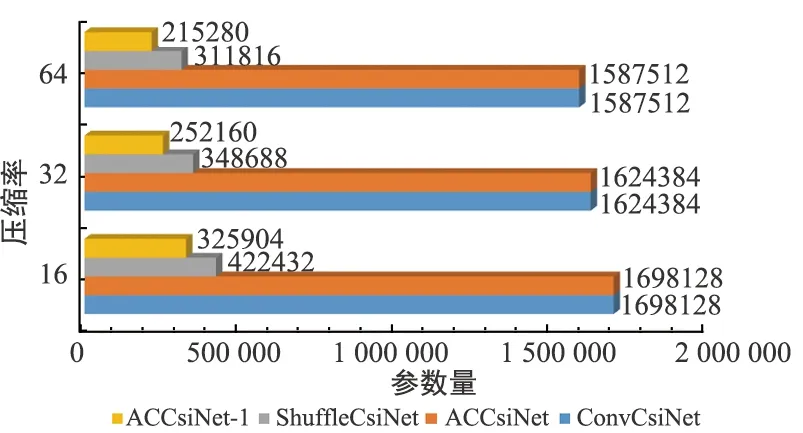
圖6 不同編碼器的參數(shù)量對(duì)比
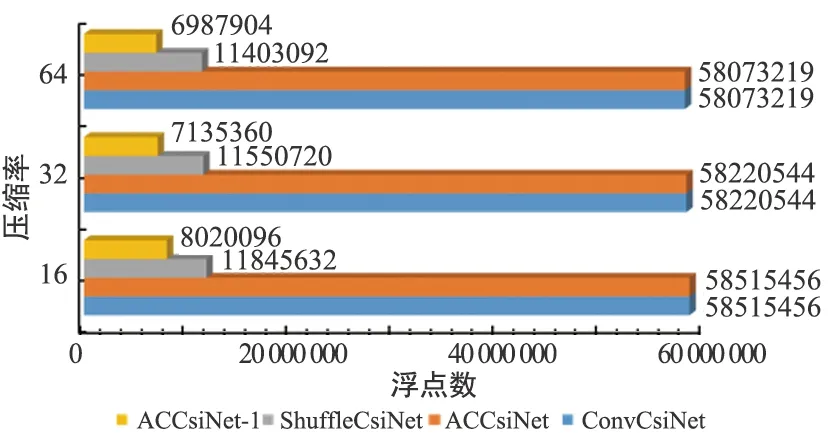
圖7 不同編碼器的浮點(diǎn)數(shù)對(duì)比
由于保留了原始網(wǎng)絡(luò)結(jié)構(gòu),Asy-CSINet-l 的性能在室內(nèi)和室外場(chǎng)景中都只略有下降。但是,部署階段的參數(shù)和浮點(diǎn)運(yùn)算(FLOPs)的數(shù)量大幅減少,這對(duì)UE的存儲(chǔ)非常有利。MobileNet-en的實(shí)驗(yàn)結(jié)果也如圖3所示,這表明用深度可分離卷積替換非對(duì)稱(chēng)卷積模塊優(yōu)于用MobileNet替換整個(gè)編碼器,原因是深度可分離卷積更適合替代固定網(wǎng)絡(luò)結(jié)構(gòu)中的標(biāo)準(zhǔn)卷積層。
3.4多模型綜合集成的性能評(píng)估
為了提高泛化能力,本文在Asy-CSINet-l的基礎(chǔ)上提出了Asy-CSINet-mr,其編碼器的最后一個(gè)卷積層是獨(dú)立的,前面的所有層都是通用的,從而大大減少了多速率下的參數(shù)數(shù)量。在訓(xùn)練階段,編碼器的輸出是3個(gè)壓縮率的組合,解碼器端的3個(gè)唯一網(wǎng)絡(luò)對(duì)應(yīng)3個(gè)壓縮率。以端到端的方式訓(xùn)練網(wǎng)絡(luò),總損失是3個(gè)壓縮率的總和。很明顯,高壓縮率的網(wǎng)絡(luò)損失更大,為了平衡影響,在每個(gè)損失前面乘以一個(gè)加權(quán)項(xiàng),可以表示為:
LT(θ)=c16L16(θ16)+c32L32(θ32)+c64L64(θ64),
(10)
其中,LN和θN是壓縮率為N的均方誤差損失和網(wǎng)絡(luò)參數(shù),cN是乘法權(quán)重。在實(shí)驗(yàn)中,設(shè)置c16=5.5、c32=2和c64=1。歸一化均方誤差性能結(jié)果如表1所示。

表1 不同模型的性能對(duì)比
此外,通過(guò)融合不同室內(nèi)外場(chǎng)景的模型,Asy-CSINet-ms被提出。可以看到Asy-CSINet-ms 仍然與Asy-CSINet保持接近最優(yōu),而存儲(chǔ)在編碼器和解碼器端的參數(shù)量顯著下降到原始的一半。在壓縮率較低的室內(nèi)場(chǎng)景中,Asy-CSINet-ms的性能損失更為明顯。但是,整體性能損失并不是很大。
進(jìn)一步將Asy-CSINet-mr和Asy-CSINet-ms集成到一個(gè)模型中,即Asy-CSINet-mrs。Asy-CSINet-mrs的結(jié)果與Asy-CSINet-ms的結(jié)果非常接近。可以得出結(jié)論,影響Asy-CSINet-mrs性能的主要原因是多個(gè)場(chǎng)景的集成。
考慮3個(gè)壓縮率不同的室內(nèi)外場(chǎng)景,用戶(hù)端需要存儲(chǔ)的參數(shù)總數(shù)如圖8所示。通過(guò)使用深度可分離卷積,Asy-CSINet-l的參數(shù)數(shù)量比ACCsiNet減少了83%。對(duì)于 Asy-CSINet和Asy-CSINet-l,總共需要集成6個(gè)編碼器模型。對(duì)于 Asy-CSINet-mr,集成了多速率模型,因此只需要2個(gè)編碼器模型即可處理2種場(chǎng)景,因此與Asy-CSINet-l和Asy-CSINet相比,參數(shù)數(shù)量分別減少了約45%和90%。最后,Asy-CSINet-mrs集成了多場(chǎng)景模型,使用Asy-CSINet-mrs時(shí)只需要一個(gè)模型。
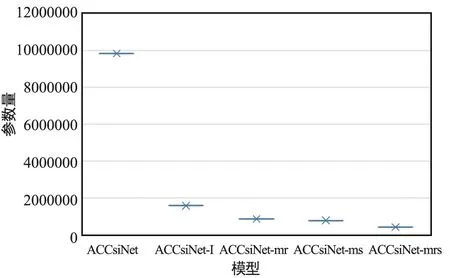
圖8 各模型參數(shù)量對(duì)比
該實(shí)驗(yàn)為實(shí)際部署提供了指導(dǎo),多速率集成方案可以大大減少參數(shù),同時(shí)幾乎沒(méi)有性能損失。如果存儲(chǔ)空間需要進(jìn)一步壓縮,可以考慮多場(chǎng)景集成方案。
4 結(jié)論
本文提出了使用Asy-CSINet來(lái)處理 CSI 反饋問(wèn)題,通過(guò)使用非對(duì)稱(chēng)卷積模塊和深度可分離卷積,不僅增強(qiáng)了網(wǎng)絡(luò)的特征提取能力,而且大大減輕了編碼器端的重量。然后,進(jìn)一步提出多模型綜合集成方案,以增強(qiáng)網(wǎng)絡(luò)的泛化能力。實(shí)驗(yàn)結(jié)果表明,所提出的Asy-CSINet極大地提高了歸一化均方誤差和ρ性能,特別是對(duì)于戶(hù)外場(chǎng)景。最后,結(jié)果驗(yàn)證了算法剪裁和多模型綜合集成方案都可以達(dá)到所提出Asy-CSINet的最優(yōu)性能,同時(shí)減少了83%和90%以上的參數(shù)量。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(bào)(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(bào)(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
