基于無監督學習的無線網絡性能異常檢測方法
2022-07-18 08:58:00吳艷芹胡華偉
無線電通信技術 2022年4期
關鍵詞:檢測
張 樂,吳艷芹,楊 昊,張 平,胡華偉
(1.中國電信股份有限公司研究院,北京 102209;2.中國電信股份有限公司福建分公司,福建 福州 350001)
0 引言
無線網絡作為運營商網絡中重要的一部分,一旦發生性能劣化,會對用戶體驗帶來較大影響,實時監控網絡運行的狀況,電信運營需要發現潛在的問題并對已發生問題的區域和設備進行準確、及時的定位分析。由于人工篩查性能異常具有滯后性,難以早期發現,且已有的案例和經驗難以復用和擴展,因此規則高度依賴于運營專家的經驗,而且維護難度大。
鑒于以上問題,本文利用無監督學習及統計分析技術對性能指標數據進行診斷識別,對性能異常實現早期快速識別,進一步提升用戶體驗以及網絡質量。
1 問題描述
性能異常問題主要包含如何定義性能劣化、性能雪崩,以及如何根據不同場景、不同時段、不同指標合理設定閾值。如圖1所示,性能劣化和性能雪崩的定義并無明確的界限,主要在于性能指標異常程度的不同,通常情況下性能雪崩相對于性能劣化的異常程度更嚴重,而如何合理設定閾值則是本文希望解決的問題。

圖1 性能劣化與性能雪崩
現今對于性能劣化的判斷規則,無一例外均高度依賴于運營專家的經驗,需要長年累月的積累,形成過程耗時耗力,且并不一定完全合理。而且規則中告警/預警準確度比較高的同時伴有一定滯后性,無法做到提前發現和提前預警,且各地運營規則不同,不易形成一套具有普適性的規則閾值生成方法。
2 性能異常檢測算法
相對于現有性能異常問題診斷方法,智能算法通過對小區的關鍵性能指標的數據進行分析,采用統計學方法、聚類算法等獲取更加合理的性能異常門限[1]。本文提出的算法大體上可以分為三類:一類為基于統計學特征(如3-sigma檢測、同比/環比檢測等);第二類為基于密度(如異常點/離群點檢測算法、孤立森林算法等);第三類為基于聚類(如K均值算法+異常點/離群點檢測算法等)。
2.1 基于統計特征的異常檢測
(1) 3-sigma檢測
基于3-sigma的異常檢測算法(Anomaly Detection Algorithm),其算法的核心思想是[2-4]:假定數據集滿足正態分布,計算數據集的數學期望μ和方差σ2,并且利用少量的Cross Validation集來確定一個閾值ε;當給出一個新的點時,定義異常值的方法為,若該值與平均值的偏差超過ε,則判斷為異常點。
(2) 同比/環比檢測
通過設置規則和閾值[5-7],可以對指標同比突降、指標環比下降等進行監控,增加指標檢測手段。
2.2 基于密度的異常檢測
2.2.1 LOF檢測法
LOF(Local Outlier Factor)算法主要涉及的概念[8-9]:
①d(p,o):兩點p和o之間的距離。
②k-distance:第k距離。
對于點p的第k距離dk(p)定義如下:dk(p)=d(p,o),并且滿足:
a.在數據集中至少有不包括p在內的k個點o′∈C{x≠p},滿足d(p,o′)≤d(p,o);
b.在數據集中最多存在不包含p點在內的k-1個點o′∈C{x≠p},滿足d(p,o′) 其中點p的第k距離,即距離p點第k遠的點的距離值,不包含p,如下圖2(a)。 (a) 第k距離 ③ 第k距離鄰域,點p的第k距離鄰域Nk(p),就是點p的第k距離半徑內的所有的點,包括第k距離所對應的點,因此,p的第k鄰域點的個數|Nk(p)|≥k。 ④ 可達距離,點o到點p的第k可達距離定義為: k(p,o)=max{k-distance(o),d(p,o)}, 其中,k(p,o)表示o點到p點的第k可達距離,至少是o的第k距離,或者為o、p間的真實距離。如圖2(b),o1到p的第5可達距離為d5(p,o1),o2到p的第5可達距離為d5(p,o2)。 ⑤ 局部可達密度,點p的局部可達密度表示為: 其中,點p的局部可達密度越高,點p越有可能與當前的領域內其他的點屬于同一簇,密度越低,點p越可能是離群點。 ⑥ 局部離群因子,點p的局部離群因子表示為: 局部離群因子的值約接近1,標識點p的與鄰域內的其他點越有可能是同一簇;局部離群因子的值越大,則表明點p的密度值越小,與p的鄰域內其他點的密度越不一致,則點p越可能是異常點[10-12]。 2.2.2 孤立森林算法(Ifortst) 以二維數據為例,如圖3所示,圖中A點和B點為離群點,希望將點A和點B單獨切分出來[13]。先隨機指定一個維度,當前維度的取值區間捏隨機選擇一個切割點p,按照該切割點將數據集進行左右切割,切割為兩個子集,將小于p點的節點放在左子集,大于等于p點的節點放在右子集。然后,在左右兩組子集中,重復上述步驟,不斷指定維度對數據集進行切分,構造新的子集,直到每個數據子集僅剩一個數據點,無法再繼續分割,或者剩下的數據全部相同為止。 圖3 孤立森林算法異常點切割 由圖3可知,點B處在較為稀疏的位置,與其他的點距離較遠,通過少量的分割就可以將點B分割出來,點A處在較為稀疏的位置,需要的分割次數更多一些。孤立森林算法采用二叉樹去對數據集進行分割,被分割的數據點在二叉樹中所處的深度反應了該條數據的“疏離”程度。整個算法大致可以分為兩步: 步驟1訓練:在總數據集中,隨機抽取多個樣本,作為構建多棵二叉樹的訓練集。 構建一棵二叉樹時,先從總數據集中抽取樣本容量為n的樣本集,然后隨機選擇一個特征維度作為該樣本集的根節點,并隨機在特征的取值區間選擇一個值,將樣本集劃分為左右子集,然后分別在左右子集中,重復上述步驟,直到滿足如下條件: ① 數據不可再分,即只包含一條數據,或者全部數據相同。 ② 二叉樹達到限定的最大深度。 步驟2預測:根據多棵二叉樹的結果,計算每個數據點的異常分值。 數據x的異常分值計算:先要估算x在每棵二叉樹中的深度,即從根節點到葉子節點經過的邊的個數。設二叉樹的訓練樣本中落在x所在葉子節點的樣本數為T.size,則數據x在這棵二叉樹上的路徑長度h(x),可以用這個公式計算: h(x)=e+C(T.size), 其中,e為數據x在二叉樹深度,C(T.size)為一個修正值,它表示該二叉樹的平均路徑長度。一般的,C(n)的計算公式如下: 其中,H(n-1)可用ln(n-1)+0.5772156649估算,此處的常數是歐拉常數。結合多棵二叉樹,數據x最終的異常分值如下: 其中,E(h(x))表示數據x在多棵二叉樹的深度的平均值,需對多棵樹的結果進行歸一化。 從上述對異常分值的計算可以看出,如果數據x在每棵樹中的平均深度越短,得分越接近1,則數據點x越異常;如果平均深度越短,得分越接近0,則x越可能是個正常點。 KMeans算法原理簡單,容易實現,可解釋度較強,故此采用KMeans算法做聚類分析。 KMeans聚類算法:選擇初始化的k個樣本作為聚類中心,其中k為聚類的類別數。計算數據集中每個樣本到k個聚類中心的距離,將樣本歸類到距離最近的類中,然后重新計算每個類的質心,重復以上步驟,直到迭代次數,或者最小誤差小于特定閾值為止。這樣最終確定每個樣本所屬的類及每個類的質心。 實驗中所用的性能數據為選定市區2021年6月-8月的數據,包括RRC連接成功率、E-RAB連接成功率、eNodeB內切換成功率、X2接口切換成功率及S1接口切換成功率等性能指標。 基于統計特征的性能異常檢測方法利用各異常指標的質量信息的均值和標準差來劃定閾值,將“質量信息小于百分比均值-(a*標準差)”劃定為異常(a為系數,此處等于3),與原始標定的結果(小時粒度達到門限)做比較。 其部分結果和案例如表1所示,通過表1不難發現盡管各異常指標質量信息分布有所不同,但通過調整樣本的分布,可以使得劃定的閾值滿足各異常指標的檢測結果,均可達到較好效果。 表1 基于統計特征的性能異常檢測結果和案例 3.3.1 基于LOF算法 (1) 原始數據異常檢測 采集某市區兩個月運行的現網數據中字段列表1的38種性能數據作為樣本集,隨機選取70%作為訓練集,剩余30%作為測試集,利用LOF算法進行建模,調整參數使得模型盡可能學習到更多有效特征。 為了方便評價模型的好壞,樣本集需要進行標注,相當于半監督學習。在參數n_neighbors= 3 000時效果最好,AUC值為0.580 3。 (2) 歸一化數據后異常檢測 此處只將數值型特征進行歸一化處理,百分比型特征不做處理,構成新的數據集用于訓練模型,分別嘗試了3種不同的歸一化方法:分位數歸一、正則歸一和10為底的log函數歸一化處理。 經過歸一化處理以后,數據的分布更加合理,模型的泛化能力更強,分位數歸一在參數n_neighbors= 40時,AUC最大值達到了0.946 5;正則化歸一在參數n_neighbors= 180時,AUC最大值達到了0.930 4;10為底的log函數歸一化處理在參數n_neighbors= 22時,AUC最大值達到了0.905 7,歸一化效果明顯。 3.3.2 基于IForest算法 訓練集與測試集LOF算法所用訓練集與測試集歸一化前一樣,利用LOF算法進行建模,調整參數使得模型盡可能學習到更多有效特征。 在參數n_estimators=200,contamination= 0.15時效果最好,AUC為0.620 7。 基于密度的算法中用量信息數值往往很大,對密度結果影響也很大,鑒于此,先對各異常指標的用量信息處理歸一化后做KMeans聚類分析[14-15],將聚得的類再進行LOF異常值檢測。 其中聚類類別分為8類時效果最好,AUC值為0.970 6,準確率為0.994 1,相對于基于密度的方法有了較大提高。 以效果最好的基于聚類的異常檢測方法為例,分別統計了RRC連接成功率、ERAB連接成功率、eNodeB站內切換成功率、X2內切換成功率和S1內切換成功率5類指標的異常檢測結果,具體如圖4所示。 由圖4可知,基于聚類的異常檢測算法對各項指標的異常判斷較為均衡,同時準確率高,達到了對于性能異常檢測的預期。 圖4 聚類異常檢測部分指標結果 本文針對無線網絡性能異常檢測問題,提出了3種無監督異常檢測方法,分別為基于統計特征的異常檢測、基于密度的異常檢測、基于聚類的異常檢測,并采用實際性能數據對各種異常檢測方法進行測試。實驗結果表明,異常檢測算法中基于聚類的算法效果最好,AUC值為0.970 6,準確率為0.994 1。本文通過將AI 技術應用于無線網絡性能預測,幫助運維人員及時掌握無線網絡的運行狀況與趨勢,實現性能劣化預測預判,增強主動運維能力,防患于未然,有效提升客戶體驗。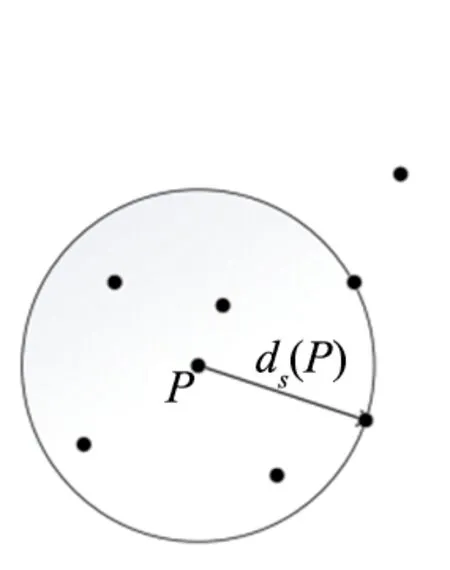

2.3 基于聚類的異常檢測
3 算法實驗及結果分析
3.1 數據準備
3.2 基于統計特征實驗分析

3.3 基于密度的實驗分析
3.4 基于聚類的實驗分析
3.5 結果分析

4 結論
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
