智能中醫舌脈診斷手環
2022-07-23 07:41:34毛曉波路宜寧
電子設計工程 2022年14期
沈 睿,毛曉波,周 熙,路宜寧
(鄭州大學電氣工程學院,河南鄭州 450001)
脈象診斷和舌象診斷是中醫極具價值的臨床診斷方法,但是傳統中醫診斷主要依靠醫生的肉眼和經驗,難以量化描述和精確診斷。目前舌脈診客觀化已有一些研究成果。脈象方面,大量中醫學者的研究表明,不同疾病病癥在脈圖參數方面有顯著的相關性[1],使脈圖能夠有效運用于中醫診斷。通過時域方法可以直觀提取脈圖參數,但脈象的識別準確率較低。舌象方面,也有中醫學者驗證了某些病癥與色彩空間的值具有相關性[2-5],但針對舌象色彩空間參數進行舌象判別鮮有研究。
市場上已經研制出多種脈診儀和舌診儀,但體積龐大,操作復雜,很難推廣給大眾。中醫辨證體系要求四診合診才能全面了解病情[6],而市場上的舌診儀、脈診儀往往是分開的,只能局限性地展示疾病狀況。
該文以構建小型化舌診脈診儀為目的,設計一款智能中醫舌脈診斷手環,建立舌脈象的判別模型,提高判別準確率,對推動中醫舌診客觀化、規范化提供一種模型方法。
1 總體結構與實施方案
該智能舌脈診斷手環包括采集單元和診斷單元,系統總體結構圖如圖1 所示。采集單元即為智能手環,內置脈搏傳感器、舌象拍攝模塊和通信模塊。診斷單元為上位機,進行脈象和舌象的處理分析。

圖1 系統總體結構圖
具體實施方案流程圖如圖2 所示,脈象處理方面:先用脈搏傳感器模塊采集脈象,使用光電容積法對淺部微動脈進行信息提取分析;利用通信模塊傳輸到上位機保存脈搏數據,同時繪制能顯示出脈搏的波形;再進行判別模型判斷,對脈象的分析利用隨機森林bagging 決策樹算法,得出模型后回代評估模型,最終得到脈象分析結果。舌象處理方面:先用舌象拍照模塊拍照,利用通信模塊傳輸到上位機;之后進行識別定位,應用卷積神經網絡中的YOLOv3 算法檢測出人臉和舌頭的位置,定位位置后標記,提取出坐標。然后是舌象色素提取:定位后再對舌象重要部分進行剪切,得到舌頭數據圖片,對其進行像素點分析,提取RGB 數據后轉化為Lab 數據;最后判別模型進行判斷,對Lab 數據等舌象信息進行Fisher 線性判別,構造二次模型并將樣本代入到模型中,計算其混淆矩陣和判對率,得到舌象判別結果。其中舌象采用Fisher 二次模型,苔色采用一次模型。

圖2 實施方案流程圖
2 系統設計
2.1 脈象設計技術關鍵
2.1.1 光電容積法
使用光電容積法利用560 nm 波長左右的光對淺部微動脈進行信息提取分析,其原理流程如圖3所示。在目前的智能穿戴設備上,應用最多的就是PPG 光電容積法[7],其基本原理如下:人體的皮膚等對于光的反射是固定值,而毛細血管和動脈、靜脈對光的反射值是波動值,隨著脈搏容積不斷變化,這個波動值正好與心率一致,所以通過這個波動值就可以確定使用者的心率數據。

圖3 光電容積法原理示意圖
2.1.2 隨機森林bagging
從生物力學的角度考慮,脈象形成是橈動脈在心臟、血液、血管相互作用下的一種運動,通過研究參與這一運動的作用力,可以闡明脈象形成的機理。當患有某種疾病時,會引起某些生理參數的變化,從而改變了與此參數有關的作用力,影響了橈動脈的正常運動,出現病脈。所以一切脈象的形成都可以歸結到參數的變化[8-9]。因此,建立模型進行參數分析,以得到脈象的客觀指標,就可以判別脈象。
建立模型前要測得不同脈象的有關參數,以確定出各相應的相似準數的正常范圍及陽性指標。這樣便可以定量區別各種不同的脈象并探討其機理。考慮到與脈形信息相關的參數較多,若將其全部引入會造成模型計算困難以及變量信息重疊度高進而導致模型不顯著等,所以剔除與脈形信息關系不大的參數會提高模型精度:首先對所有自變量逐個建立判別模型,由于有些脈形樣本數較少故采用Fisher線性判別分析,以各模型判對率的上四分位點為閾值,選取對脈象信息有較大相關性的自變量引入模型。圖4 是隨機森林引入變量數目的選擇,當縱軸表示的錯誤情況達到最低時為最佳選擇,所以選擇引入4 個變量。

圖4 隨機森林引入變量數目的選擇
隨機森林就是以集成學習的思想將多棵決策樹集成的一種算法,它的基本單元是決策樹,每棵決策樹作為一個分類器,則對于一個輸入的樣本集成了所有分類投票的結果,N棵樹就會有N個分類結果,而隨機森林根據投票制指定最多的類別為最終輸出,隨機森林bagging的思想是指將若干個弱分類器組成一個強分類器。隨機森林算法實質是基于決策樹的分類器集成算法,其中每棵樹都依賴于一個隨機向量。隨機森林會隨機地來生成多個分類樹,最終將分類樹結果進行匯總。所以不僅要確定引入的變量,還要確定隨機森林所包含決策樹的數目。圖5 給出了指定隨機森林所包含決策樹數目的決策,決策樹數目為500 時,模型內誤差基本穩定,故取數目為500。
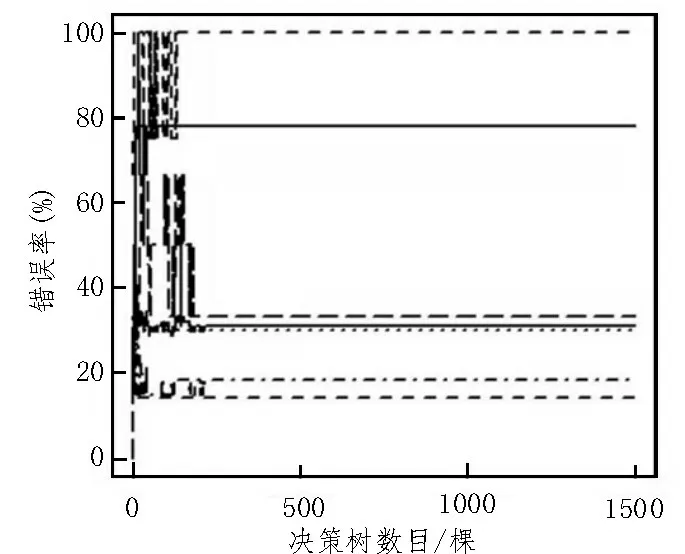
圖5 隨機森林模型的建立
針對脈象參數眾多的特點,隨機森林與神經網絡等其他算法相比,降低了運算量,提高了預測精度,而且該算法對多元共線性不敏感以及對缺失數據和非平衡數據都比較穩健,所以適合于脈象數據集。在bagging 方法里,從數據里抽取出自舉樣本,由每個樣本建立一個決策樹模型,最終的模型是所有單個決策樹結果的一個平均。bagging 決策樹算法以降低方差得到穩定的最終模型,這種方法提高了精度,最終得到判別準確率為91.07%,并且不容易過擬合。在得出模型后進行交叉驗證來評估模型的準確率。
2.2 舌象設計技術關鍵
2.2.1 YOLOv3算法
傳統的舌象及面象提取多用專業儀器,需要有專業人員操作,在固定攝像頭、固定位置下進行圖像采樣以確保準確性。而該產品為使得用戶能夠自主簡便操作,真正地實現全自動化健康檢測,采用了基于Darknet-53 網絡結構的YOLOv3 算法,通過卷積神經網絡對用戶拍攝的面部位置和舌頭位置不確定的圖片進行自動識別并定位,高效準確地確定坐標以供后續分析處理。
Yolov3 與R-CNN、Fast R-CNN、SSD 相比,識別速度上有明顯的優勢,能夠迅速得到識別結果,以供后續分析處理。YOLOv3 在實現相同準確度下要顯著地比其他檢測方法快。時間都是在采用M40 或Titan X 等相同GPU 下測量的。
數據集采用VOC 數據集,其中圖片采集于鄭州大學第五附屬醫院及網絡數據庫。使用Python 標注程序進行標注,并使用縮放比例、裁剪、移位等方式來進行數據增強,擴充數據集,提高各種情況下識別的準確率。并確保數據集的測試集和訓練集具有有效的區分性以保證訓練精度。
YOLOv3 輸出了3 個不同尺度的feature map,采用了predictions across scales 改進方法,多尺度地來對不同size 的目標進行檢測,以確保對于不同比例尺圖像中人臉和舌頭檢測的精準性。在對b-box 進行預測時,采用了logistic regression,即網絡每次對b-box 進行預測時,都輸出一組(tx,ty,tω,th,t0),最后通過式(1)計算出最優的bx、by、bω、bh和置信度。

logistic 回歸用于對anchor 包圍的部分進行一個目標性評分(objectness score),即這塊位置是目標的可能性有多大。因為用戶使用時,一張照片只有一個舌象位置和面部位置,故選擇輸出目標可能性得分最高的目標框作為實際識別坐標。
經對測試集檢驗,準確率達到了95.8%(207/216),其中目標在圖片中的絕對位置偏移量與其所占數量百分比坐標圖如圖6,在確保后續處理檢驗準確性的前提下選取容忍范圍為5 mm。

圖6 YOLOv3算法目標絕對位置偏移量與其所占數量百分比坐標圖
故文中采用的YOLOv3 算法能夠有效地達到在定位不明確的圖片中準確快速定位舌象和面象位置并提取坐標,以供后續分析處理的功能。
2.2.2 提取LAB數據
舌診是中醫診斷學的重要方法,通過辨別舌色,可診斷病癥。舌色需要借助顏色空間進行提取和分析,目前在計算機視覺領域存在著較多類型的顏色空間。LAB 模型色域寬闊,對顏色的描述更接近中醫舌色診斷的實際過程,所以對舌色特征的分析均是基于該色彩模型進行的。
RGB無法直接轉換成LAB[10-11],需要徑過RGB——XYZ——LAB,也就是先轉換成XYZ 再轉換成LAB,因此轉換公式如下:

2.2.3 Fisher線性判別
對舌象色彩空間參數進行Fisher 線性判別,因為自變量屬于三維空間,故可做出三維散點圖用于初步判斷不同類別的大致分布狀態(以不同顏色區分),為了更加清晰地觀測分布,采用交互繪圖方式,發現類間基本線性可分,故采用線性判別分析。
舌象三維散點圖如圖7 所示,不同顏色代表數據點所屬類別不同。

圖7 舌象三維散點圖
Fisher 判別即給定訓練樣本集,設法將訓練樣本投影到一條直線上,使每一類之內的投影值所形成的類內距離盡可能小,而不同類之間間距離差盡可能大。建模后進行交叉驗證,計算其混淆矩陣和判對率。若發現效果不明顯,則可以考慮增加一個緯度,即投影到二維空間并重新建模和檢驗。最終可知,在苔判別中,線性模型的分類效果優于二次模型的分類效果,而在舌的判別中,二次模型的分類效果優于線性模型的分類效果。
3 實驗結果
用戶戴上智能舌脈診手環,找到脈搏最為明顯的取脈點,將手環上的光電反射式傳感器對準采樣點,可將采集到的模擬信號利用通信模塊傳輸給上位機[12-16],此外還可以在電腦上繪制出脈搏波形。手環自動將數據導入,分析得到脈象診斷報告;其次打開舌象拍攝模塊,對面部伸舌進行拍攝,將圖片導入上位機進行舌象分析;最后得到最終的中醫舌診脈診檢測結果。
4 結論
該文針對中醫舌診脈診儀小型化、標準化、客觀化的需求,設計了一款智能舌脈診斷手環,作為移動醫療可穿戴設備,該系統將脈搏傳感器和攝像頭都集成到手環,集成度高。人工智能自動識別舌像,改變傳統定位識別的固定模式,便于用戶使用,其具備便攜、診斷方便快捷等優點。在算法上,建立舌脈象判別模型。針對脈象參數過多可能存在信息重疊進而產生多重貢獻的情況,采用隨機森林方法,結果表明,與一般脈象分析方法相比,其對于多重貢獻更加不敏感,使模型較穩健,提高了判別精度。為了更直觀地描述舌色分布情況及各舌色之間的差異性,選取Lab 模型得到舌象參數,利用Fisher 線性判別建立了舌象與色彩空間參數的模型關系。以上為進一步研究中醫舌脈診智能化標準化提供了新的思路。但由于數據量有限,該模型只能在特定情況下具有較高的判別概率,對比較稀少的脈象和舌象不能進行判別,因此擴大數據庫容量,獲取更多信息納入訓練集是未來的改進方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
世界科學技術-中醫藥現代化(2021年9期)2021-12-31 03:30:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國臨床醫學影像雜志(2019年2期)2019-04-25 06:15:42
光學精密工程(2016年6期)2016-11-07 09:07:19
中國繼續醫學教育(2016年14期)2016-02-15 06:39:48
湖南中醫藥大學學報(2015年1期)2016-01-06 01:06:43
核科學與工程(2015年4期)2015-09-26 11:59:03
中國中醫基礎醫學雜志(2010年5期)2010-02-11 13:44:28
