學術論斷句標注與識別方法探索
2022-07-30 01:20:02郭語凡喻雪寒黃雨馨楊婷婷王唯一
情報學報 2022年7期
徐 健,郭語凡,喻雪寒,黃雨馨,楊婷婷,王唯一,劉 政
(1. 南京農業大學信息管理學院,南京 210095;2. 南京農業大學經濟管理學院農林經濟管理博士后流動站,南京 210095)
1 引 言
隨著數字學術出版物數量的爆發式增長,信息爆炸與知識匱乏的矛盾日益突出。在學術大數據的背景下,如何利用機器學習、自然語言處理等技術對學術文獻中的文本進行自動化、細粒度地組織,挖掘其中蘊藏的理論與知識,是擺在科技情報領域學者面前的一個重要且富有挑戰性的科學問題。學術觀點,或稱學者觀點(論點),是指學者對于研究問題的看法、發現、見解或主張,是學者開展學術研究對學界形成的主要貢獻,也是學術信息交流的主要內容和形式。1644 年,約翰·彌爾頓在其著作《論出版自由》中,首次提出觀點的自由市場理論,認為真理是通過各種意見的自由辯論和競爭獲得的,并非權力賜予。以“太陽與地球運動關系”這一問題為例,不同歷史時期學者提出、豐富和發展了地心說、日心說和宇宙大爆炸等學術論斷,如圖1 所示。可以看出,新學術論斷對原有論斷的質疑、證偽、修正或推翻可視為科學研究進步的表現。同時,不同學派、學者學術觀點或論斷的交鋒、爭辯、相互補充和借鑒形成了學術研究進步的內在動力。與知識被廣泛接受不同,學術論斷(或觀點)具有主觀性的特點,主要是由于不同學者在研究視角、立場、知識結構、價值觀等方面存在差異。同時,學術論斷的正確性還需在實踐中經過同行學者和專家的進一步檢驗。

圖1 學術論斷在推動知識更新與科學進步中作用示意圖
學術觀點(或論點)通常以學術文本中的論斷性句子(claim sentences)的形式出現。目前,對領域學術觀點的梳理和歸納通常通過人工閱讀和整理,繁重的閱讀任務擠占了學者思考和實驗的時間,降低了其研究效率。基于此,本文探索學術論斷句的自動識別方法,選擇信息資源管理領域499篇論文摘要和249 篇論文全文作為研究樣本,標注其中論斷句和非論斷句,利用傳統機器學習和深度方法對此類句子進行識別。本文關注的研究問題包括:①學術論斷句的判定標準有哪些?②何種分類器對學術論斷句的識別效果較好?③學術論斷句和非學術論斷句在長度、位置、TextRank 權重等方面的特征存在什么差異,能否被用于識別學術論斷句?通過探究上述問題,在明確學術論斷句概念基礎上,通過非結構化的外在語言表現形式將學術觀點句與非學術觀點句區分開來,形成初具規模的標注語料和標注平臺,為其他功能類型語句標注、識別提供思路與工具上的參考。同時,通過對比不同類型特征對于學術論斷句識別的有用性和各類識別方法的準確性,為后續學術論斷句的進一步分類、組織與語義關聯奠定基礎。同時,本文的研究內容還可以進一步豐富觀點挖掘研究場景,完善學術文本處理方法,通過對學術文本中的論斷進行識別可以提高讀者閱讀效率。相關過程對學術信息資源利用效率、知識服務水平和知識交流效率的提高具有重要價值。
本文組織結構如下:第2 節從論辯挖掘、學術文本處理兩個角度梳理相關研究,指出現有研究不足;第3 節介紹數據集和標注過程,明確標注標準,對標注結果進行描述;第4 節介紹了所使用模型與基準模型原理、評價指標,開展識別實驗,分析實驗結果,對比論斷句和非論斷句文本特征,探索各類特征對識別效果的影響;最后,總結本文的研究結論,討論研究的局限性和創新性,并對未來研究進行展望。
2 相關工作
2.1 論辯挖掘
論辯挖掘(argument minging)研究可視為觀點挖掘(opinion mining)的延續,所分析的文本類型涵蓋新聞、政治演講、學術論文、法院判例等內容。相關研究旨在對非結構化文本進行分析,抽取其中的論辯結構,其理論來源于哲學中的邏輯學。早在20 世紀50 年代,圖爾敏模型[1](Toulmin model)就已被提出,包括主張、依據、正當理由、支援、模態限定詞、反駁等元素。弗里曼(J. B. Freeman)將反駁分為消解反駁(undercutting defeater)和直接反駁(rebutting defeater),進一步豐富了圖爾敏模型[2]。
現有論辯挖掘研究在方法層面重點關注論辯部件(argument component)和論辯結構(argument structure)的識別與抽取。其中,論辯部件可視為論辯結構的基本元素,也稱為argumentative discourse unit(ADU)或argument unit,具有判斷性(declar‐ative)、可證偽性(falsifiability)的特征。Walton[3]將論辯結構定義為若干前提與結論間組成的支持或攻擊關系。論辯關系中的前件(premise) 和結論(conclusion)均可被稱為論辯部件。目前,對論辯部件的識別包括非監督學習和監督學習兩種方法:①在非監督學習方法方面,Petasis 等[4]在帖子和議論文數據上驗證了基于TextRank 的抽取式摘要算法有助于論辯部件的識別。Levy 等[5]通過觀察提出一種在語料庫層面的查詢表達式,并據此進行論斷句識別。②在監督學習方法方面,Mochales-Palau等[6]、Palau 等[7]、Moens 等[8]在Araucaria 數據集上使用二元分類的方法進行論辯性句子的識別,并對各類特征與分類器效果進行了對比。此外,Habernal等[9]發現論辯部件與句子并非一一對應,還可能存在一句內包含多個論辯部件或者一個論辯部件由多句組成的現象。針對一句對應多個論辯部件的情況,目前多數研究通過序列標注的方式對句內詞匯角色進行標注,通過識別論辯部件邊界詞進行論辯部件的抽取,代表性研究如Park 等[10]、Sardianos等[11]、Petasis[12]等。
論辯結構主要是指論辯部件間關系,包括微觀和宏觀兩個層面:①微觀關系旨在分析論辯部件(argumentative components)間的推理關系,主要應用在獨白型文本或篇幅較短的評論信息中。Trevisan等[13]通過詞性標注的方式歸納了英文中表示論點和結論間推理關系的提示詞(conclusiva)。Carstens等[14]通過對句子對之間的關系進行分類,實現了論辯性句子的識別。Stab 等[15]在使用多類分類器對論辯部件類別進行判定的基礎上,進一步采用分類的算法對論辯部件二元對是否存在支持關系進行分類。Lawrence 等[16]從語料庫中抽取關聯陳述,使用矩陣表示主題不同方面間的關聯與推理關系。②論辯性文本間宏觀關系多出現在對白型文本或多文檔分析中。例如,Palau 等[7]使用語法分析的方法對法律文本中論斷間的關系進行判斷,Boltu?i? 等[17]采用文本蘊含分析(text entailment analysis)的方法對論壇中不同帖子之間的語義關系進行判定。受ACL、EMNLP 等國際會議推動,目前該領域方法已經在教育、法律、社交媒體、辯論等類型文本上開展了廣泛的實驗,涌現出了較多的領域語料庫。
論辯挖掘在學術場景下主要有如下三個方面的應用:①對學生撰寫的議論文論辯結構進行識別并對其質量進行評估。例如,Ong 等[18]使用基于規則的方法對來自匹茲堡心理學本科生撰寫的議論文中的句子類型進行識別并對文章質量進行評分,發現其與專家對文章的評分存在相關性;Song 等[19]對學生撰寫論文的論證策略(argument schema)進行標注,并分析其與專家評分之間的相關關系;Beig‐man Klebanov 等[20]研究發現論證結構可以比文章內容本身更準確地預測文章質量。②學術文本中論辯結構表示方法。Green[21]研究了醫學診斷報告中的論辯修辭結構的表示方法。Accuosto 等[22]以計算機語言學(computational linguistics,CL)和生物醫學(biomedicine,BIO)領域為例,提出一種摘要層面論辯單元和關系的標注方案,并利用轉移學習方法預測文本論辯結構[23]。③論斷句識別方法方面。Graves 等[24]發現實驗性論文標題中的動詞出現頻次隨時間增長,這有助于知識的傳播。Park 等[25]探索了利用語義、句法等特征識別學術論文中的比較型論斷句。從整體上來看,學術場景的論辯挖掘研究相對較少;而且,國外相關研究熱度較大,國內開展的研究還比較少,以中文為對象的論辯挖掘則更加少見。相關研究還存在判斷標準缺失、語料標注不規范的問題。本文著重關注中文學術文本中論斷句的標注與抽取工作,形成標注語料,并探索其自動化識別方法。未來還將就學術論斷的進一步分類、關聯和組織開展研究。
2.2 學術文本信息分類
學術文本是學者發表自己觀點與思想、研究發現的一種重要手段,通過閱讀學術文本可以與同領域學者進行跨時間和空間地信息交流,對學者增長見識、把握前沿、獲得啟發等具有重要作用。學術文本數量的增長促進了各類學術文本分析與處理工具的產生與發展。相關研究涉及計算機語言學、自然語言處理和語義出版等學科領域。其中,對學術文本按照一定的方式進行分類可以滿足用戶更細粒度的檢索需求,學術文本分類主要關注論文中各個片段功能的識別,按照粒度可以分為句子層面和篇章層面。
句子層面主要關注定義句[26]、創新句[27]、未來工作句[28]、研究方法句[29]等類型句子的識別方法,其潛在應用主要在于為用戶提供更細粒度的檢索結果。在此基礎上,部分學者對特定類型的句子進行了更細粒度的劃分。例如,張穎怡等[29]將研究方法句進一步分為使用研究方法和引用研究方法,并對其分布情況做了對比。溫浩[30]將創新句分為問題、方法、結果等6 種類型,并研究其自動識別的方法。學術文本中的句子功能在語法、語義和語用各個層面均有不同的分類標準和方式,各個類別之間的重合和覆蓋關系也需要進一步探討。同時,在漢語和學術環境下句子往往比較長,可以視為復句,還需要進一步拆分為具有單一功能類型的子句才可以開展學術評價、知識挖掘等類型的應用。
學術文本結構主要關注學術論文中各篇章的功能,目前各學者主要關注功能的識別。Ma 等[31]構建了一個數據標注平臺,旨在解決語料標注過程中的數據管理與規范問題。在識別方法上,Ma 等[32]、陸偉等[33]、黃永等[34]探索了利用章節內容、位置、標題及段落內容識別學術文本結構功能的方法。在應用上,方龍等[35]提出將學術文本結構功能特征應用于關鍵詞抽取,在ScienceDirect 數據庫上取得了較好的效果。本文的研究內容可以視為論辯挖掘和學術文本信息分類的交叉領域,其概念的界定和相關理論主要來自前者,而所用的方法與技術則更多地借鑒了學術文本信息分類方面的方法。在研究中,重點關注學術文本中的論斷句的判斷標準,并探索現有學術文本處理技術在論斷句識別過程中的效果,為后續論斷句結構化知識建模和關系判斷奠定基礎。
3 學術論斷句標注過程
本文立足圖書情報領域,從摘要和全文兩個層面研究學術文本論斷句標注過程和自動化識別方法。本文選擇信息資源管理領域部分學術文本文獻,搜集和處理文獻題錄信息,尋找全文內容,構建數據集。在此基礎上組建數據標注小組,在標注過程中探討標注論斷句的判斷標準,對論斷句和非論斷句進行標注,形成語料集,為下文探索學術論文句識別方法提供訓練與測試數據集(圖2)。

圖2 學術文本中論斷句標注過程
3.1 數據處理過程
本研究選擇《中文社會科學引文索引》(Chi‐nese Social Sciences Citation Index,CSSCI) 作 為 數據源,以“關鍵詞=信息資源管理”為檢索式,共獲得1998—2018 年這21 年發表的499 篇文獻,檢索日期為2019 年5 月31 日。之所以將語料限定在該主題內,主要是基于標注團隊的學科和專業背景,且數據規模適中。下載這些題錄數據,并使用Java程序對這些數據進行解析,存儲在MySQL 數據庫中。在中國知網中對這些數據進行逐一查詢,發現部分文獻由于數據庫記錄錯誤,或者由于文獻較早并未找到數據來源。在這499 篇文獻中,有463 篇找到了摘要,249篇有HTML 格式正文。對摘要中數據按照正則表達式[!?。!?]進行分句;對于全文數據,先按照正則表達式[0123346789 零一二三四五六七八九][^.)](.)*[^.,?!。,?!]識別一級標題,然后按照摘要分句的方式對一級標題下的各個段落進行分句,對句子文內和段內位置順序進行記錄。對句子中出現的亂碼進行識別,對句子錯分和非正文短句進行剔除。
最終,從摘要和全文中分別得到853 個和24401個句子,形成本文的研究數據。在摘要層面,平均每篇文獻包含1.85 個摘要句,句均長度為65.1 個字;在全文層面,平均每篇文獻包含98.0 個全文句,句均長度為60.6 個字。招募5 名標注人員,以文檔為單元分配標注任務,任務分配過程要確保各摘要和全文被3 位人員標注,以便對爭議性標注結果進行最終決策。
3.2 學術文本中論斷句數據標注標準
在預標注階段,針對標注過程中存在的分歧進行討論,形成論斷句的6 個判定標準,包括3 個必要條件和3 個充分條件。必要條件可從反面排除非論斷句,充分條件可從正面確定論斷句。具體而言,必要條件是指論斷句一定具有的特征,若不符合則為非論斷句,包括:①信念感。主要排除那些作者尚未形成確定判斷的語句,包括疑問句和假設階段的判斷句;②對象和判斷完備。主要對未形成完整命題的短文本,包括短標題、不完整的句子進行剔除。③可證偽。這個判斷標準主要是指存在與該論斷相對立或者競爭關系的其他論斷,此處主要排除對事實的描述和對現有方法、工具的介紹,此類句子在句前添加“我認為”后,句子會變得不通順。充分條件是指滿足此類條件的一定是論斷句,但論斷句并不一定滿足該標準,包括:①預測性。對未來發展進行預測,預測結果需要未來發展進行驗證。②個人理解。對一些抽象概念的定義和理解,學術應允許存在對同一概念的不同理解。③包含一定價值判斷和主張傾向的句子。建立在價值觀基礎上,是一種應然性判斷。需要說明的是,本研究并未區分作者本人的論斷和引用他人的論斷,也未區分個人觀點和公認的觀點;同時,在標注過程中并未考慮論斷句間的論辯關系。因此,本研究識別的論斷句既包括論點句,也可能包括論斷性的論據句,相關例句如表1所示。

表1 論斷句標注標準和反面例句
3.3 數據標注界面
本節對學術觀點句的標注可以分為摘要層面和全文層面。標注人員采用如圖3 所示的界面對文獻摘要中的句子進行標注。單擊句子,可將該句標注為論斷句(句子底線變為黑色實線),再次點擊后可以標記為非論斷句(句子底線變為黑色虛線),第三次點擊刪除其論斷句標注結果(刪除底線)。在左上角分別有標注完成和清除標注結果兩個按鈕,分別可以提交標注任務和取消標注結果。文獻《重視發展二級學科,科學定名一級學科——再論本學科建設問題》的摘要共包含3 句話。第一句話是對圖書館學教育萎縮的原因進行解讀,第二句話介紹了該研究的任務,最后一句話表達了作者的建議。將第一句和第三句標注為論斷句,通過異步的方式完成存儲。

圖3 摘要層面論斷句/非論斷句標注
在全文層面,本研究選擇了與論文整體研究主題契合程度比較高的句子進行標注。學術論文的關鍵詞、摘要、標題等集中反映了學術論文的研究主題與研究對象,因此,主要從這三個部分中識別論文的研究主題詞。遍歷整個文檔庫,計算各個詞匯的逆文檔頻率和重要性。考慮各個詞匯的位置與數量,計算各詞匯對其所在論文主題的揭示程度,其計算過程為
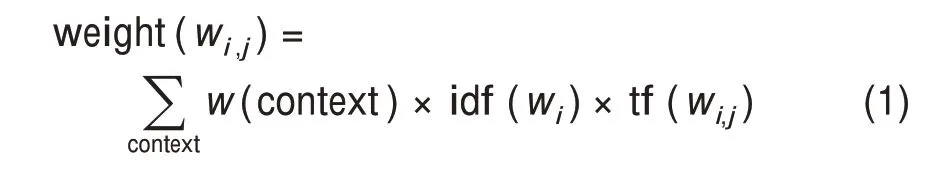
其中,wi,j表示第j篇文獻中的詞匯wi的重要性;context 可以取值為關鍵詞、標題與摘要,本研究分別設置其權重分別為1、0.5 和0.1,對于未出現在三個主題區的詞匯,其權重設定為0.01。對于每一個句子,其重要性記為各個詞匯形成的向量與論文重要性詞匯形成的向量之間的余弦夾角。計算完成后,從中抽取出主題相似性排在前20%的句子。圖4 給出了全文標注的樣例界面,背景為灰色的句子是被選出的主題相似性比較高的句子,其余標注過程與摘要相同。

圖4 全文層面論斷句和非論斷句標注
3.4 標注一致性分析
由于標注過程中有多位標注人員參與,本研究選擇kappa 指標[36]來評估標注人員之間的一致性程度,該指標取值為[0,1.0]。通常情況下,該指標小于0.2,說明一致性程度較低;該指標位于[0.2,0.4),說明標注的一致性程度一般;該指標位于[0.4,0.6),說明一致性程度中等;該指標位于[0.6,0.8),說明兩者標注一致性程度較強;該指標位于[0.8,1.0],說明一致性程度很強。例如,Ai和Aj是不同的兩個標注者,計算標注者Ai和Aj對于共同待標注句子的標注矩陣Mi,k和Mj,k,通過計算Mi,k的轉置和Mj,k矩陣相乘的乘積形成混淆矩陣,最后計算該混淆矩陣的kappa 值。此外,本研究將所有可標注文獻隨機分給5 位標注者(分別記作A1~A5),確保每篇文獻的摘要和全文至少分配給3 名標注者。將學術文獻摘要和全文賦予5 位標注者進行標注,形成20 個kappa 數值,任務分配與標注一致性如表2 所示。

表2 學術觀點句識別標注一致性結果
從表2 可以看出,標注者A1和A2一致性高達93.95%,可認為其標注近乎完全一致。剩余各標注二元組的一致性也都大于70%,可認為是高度一致。對于每一篇論文的摘要和全文的標注結果進行合并。為保障數據的準確性,對標注者標注存在不一致的句子召集標注者進行最終決策,采取多數裁定原則。最終,共形成2884 句論斷句,2479 句非論斷句,具體標注數據如表3 所示。

表3 論斷句標注結果
4 學術文本中論斷句識別方法探索
在生成論斷句標注數據的基礎上,本文將學術文本中論斷句的識別轉化為論斷句與非論斷句的二元分類問題。選擇部分文本用傳統機器學習方法與深度學習方法進行訓練,評估各算法識別效果。在此基礎上,對比論斷句和非論斷句在長度、位置、TextRank 特征上分布的差異,分析不同特征對識別算法效果是否存在提升作用。
4.1 模型選擇與參數設置
本文使用WEKA 和PyTorch 中提供的分類器模型進行論斷句識別實驗,前者主要包含傳統機器學習算法,后者則主要提供一些深度學習算法的實現。
本文選擇傳統的機器學習算法包括:方法①k近鄰(k-nearest neighbor,kNN)[37]:該方法是最簡單的文本分類方法之一,尋找與待分類節點最相近的k個節點,然后將其類別設定為這k個節點中數目最多的類別;方法②樸素貝葉斯(naive Bayesian,NB)[38]:該方法采用貝葉斯推理過程將文本類別判定轉化為詞匯類別判定問題,假設文本中的詞匯特征之間相互獨立;方法③決策樹算法:對待分類數據特征進行分析構建決策樹,可視為一系列分類特征,本文選擇C4.5 算法[39]進行模型訓練;方法④支持向量機(support vector machine,SVM)[40]:該方法使用代數運算的方法計算分類的邊界,核心技術包括最大間隔、對偶、核技巧,比較適合二元分類問題;方法⑤最小序列優化(sequential minimal optimization,SMO)[41]:該方法是一種解決支持向量機訓練過程中所產生優化問題的算法。
BERT (bidirectional encoder representation from transformers)[42]由谷歌提出,近年來在文本挖掘領域獲得了廣泛的應用。本文選擇的深度學習方法包括:方法⑥BERT+FC、方法⑦BERT+BiLSTM(bi‐directional long short-term memory)兩個模型。前者使用BERT 對句子進行表示,使用全連接層(fully connection layer)進行分類學習;后者在BERT 層對句子進行表示的基礎上,加入雙向長短時記憶網絡,輸出預測結果。在模型運行過程中,隱藏層設置為768,開啟BERT 的fine-turning 微調模式,Epoch設置為10,Batch 為32,學習率設置為2e-5。
4.2 論斷句識別評價指標
本文將學術文本中論斷句的識別轉化為一個句子二元分類問題。嘗試使用傳統機器學習分類和深度學習算法對學術論斷句進行識別。表4 為識別方法結果鄰接表。

表4 識別方法的結果鄰接表
使用準確率(p)與召回率(r)、F_1 值三種指標對模型識別的效果進行評價。計算公式為

4.3 識別效果分析
為避免過適應性,使用10 折交叉檢驗的方式進行模型效果的評估。也就是將數據集盡可能平均地分為10 份,訓練10 次,每輪選擇1 份數據作為測試集,其中,方法①~方法⑤使用剩余9 份作為訓練集,方法⑥和方法⑦則將這9 份中的8 份作為訓練集,1 份作為驗證集。各分類方法在論斷句識別任務中的效果如表5 所示。
從表5 可以看出,深度學習方法整體上要顯著優于傳統機器學習算法的識別效果。其中,BERT+BiLSTM 在摘要和全文層面均取得論斷句識別效果最優的效果。SVM 方法在摘要層面表現最差,訓練出的模型將所有數據都預測為非論斷句,導致論斷句識別的準確率和召回率均為0。結合上文訓練數據判斷,該方法在預測時會更多地將未知數據標注為多數類別。此外,各類方法在摘要層面的識別綜合效果F_1 值均不如在全文層面,說明在摘要識別方面還存在比較大的提升空間,數據規模、正負例比例是影響模型識別效果的主要原因。同時,本文是對整句進行標注的,那些既包含論斷性子句又包含非論斷性子句的長句,加大了論斷句的識別難度。

表5 各分類方法識別效果對比分析 %
4.4 論斷句文本特征分析
為進一步改善識別效果,本文對標注的摘要和全文中的論斷句和非論斷句的文本特征進行對比,包括長度、位置、TextRank 等,并將其融入識別模型中,以期提升傳統機器學習方法識別論斷句的效果。
1)長度特征對比分析
在摘要層面,共有463 篇858 個句子,其中390句被標注為論斷句,468 句被標注為非論斷句。摘要層面,論斷句長度平均為184.2 個字,非論斷句平均長度為187.5 個字,圖5 為摘要中論斷句/非論斷句長度頻率分布折線圖。將句子長度以10 為組距分組,計算各組句子數目及頻次占比,將多于300 個字的句子作為最后一組單獨呈現。
從圖5 可以看出,論斷句在50~190 個字長度區間的頻次要顯著高于非論斷句。在全文層面,標注全文中的論斷句長度平均為191.6 個字,非論斷句長度平均為139.2個字,其長度頻率分布折線如圖6所示。

圖5 摘要中論斷句與非論斷句長度頻率分布折線圖
從圖6 可以看出,論斷句與非論斷句長度的頻率分布存在顯著差異。在低于80 個字的句子中,非論斷句占比較高,論斷句占比較低,說明長度特征可能有助于學術文本中論斷句的識別。這可能是由于在標注過程中,一些較短的句子如標題、過渡句等并未包含完整的命題信息,更多地被標注為非論斷句。

圖6 全文中論斷句與非論斷句長度頻率分布折線圖
2)位置特征對比分析
為揭示摘要中論斷句和非論斷句位置分布差異,本文對不同句數摘要中論斷句出現位置頻次進行統計。在標注的463 篇摘要中,數量最多的為9句,大部分文獻(97.2%) 摘要句數在5 句以內。為分析摘要中各位置論斷句占比,本文繪制了5 句內摘要各位置論斷句概率圖,每列表示相應句數摘要的情況,括號內數字表示對應該摘要句數的文獻數目,黑色部分面積表示該位置論斷句占比,如圖7 所示。

圖7 摘要中論斷句出現位置頻次分布
從圖7 可以看出,在僅包含1 個句子的摘要(223篇)中,包含論斷句的情況比較少(20.1%),大多是對研究過程的客觀論述。在包含2 個句子的摘要中(150 篇)中,首句為論斷句的占比要大于第2 句為論斷句的占比。在包含2~5 個句子的摘要中,位置越靠前,論斷句出現概率就越高。在全文層面,本文從段內位置和文內位置兩個方面對論斷句出現位置進行分析。共有249 篇文獻擁有全文數據,共標記出論斷句2513 句,非論斷句1992 句。僅有1 句的段落中,僅20.2%的句子被標注為論斷句,這要遠低于整體上55.8%的論斷句占比。單句段落通常為過渡句,多被標注為非論斷句。在包含2 個句子的段落(69.5%)中,首句標注為論斷句的概率要高于第2 句(56.5%)。在3句及3句以上段落中,統計段首句、段中句和段尾句標注為論斷句的概率分布如圖8所示。

圖8 3句及3句以上段落中論斷句出現位置概率分布
從圖8 可以看出,在3 句及3 句以上的段落中,段落首尾處被標注為論斷句的概率要比段中句高,且段首句要略低于段尾句。這符合寫作過程中,在首句或尾句給出論斷的習慣。本文使用文內相對位置來表示論斷句與非論斷句在全文中的位置,即對論文中各個句子按照出現次序進行編號,句子文內相對位置定義為其編號與全文句子數目的比值。將句子文內相對位置按照0.05 的組距分為20 組(左開右閉),論斷句在文內相對位置的概率分布折線如圖9 所示。
從圖9 可以看出,論斷句在論文開頭和結尾兩處出現的概率較大,整體呈U 形分布。具體來說,論斷句在文內相對位置前5%和后15%出現的概率要高于非論斷句,其他位置非論斷句出現的概率要高于論斷句。這可能是因為在寫作過程中,多數學者會在論文最前面直接拋出論點或者在論文末尾總結性地給出結論。

圖9 論斷句和非論斷句在文內相對位置的概率分布折線圖
3)TextRank 特征對比分析
在文摘研究領域,TextRank 算法[43]常被用于抽取文本中比較重要的詞與句子,其核心思想是用隨機游走的方式對句子權重進行計算。使用HanLP 工具[44]計算各文獻句子初始TextRank 權重,并對該數值采用均值歸一化的方式形成最終取值介于0~1 的文內相對權重。對歸一化后的TextRank 數值按0.05的組距進行分組操作,共得到20 組(左開右閉),圖10 給出了全文層面標注論斷句、非論斷句和所有句子的頻率分布對比。

圖10 論斷句和非論斷句TextRank權重頻率分布折線圖
整體來看,所有句子的文內相對TextRank 權重呈現倒U 形分布,而本文標注的論斷句和非論斷句分布頻率卻隨著TextRank 數值的升高呈上升趨勢,這是由于本文在選擇標注數據時就選擇了和全文主題比較契合的句子。從標注結果來看,非論斷句和論斷句頻率分布曲線在TextRank 取值為0.55 處存在交點,在大于該值的組內,論斷句分布頻率要略高于非論斷句。非論斷句TextRank 均值為0.520,而論斷句TextRank 均值略高,為0.538。
4.5 特征擴充識別實驗
根據上文論斷句和非論斷句文本特征對比分析的結果,考慮在摘要和全文層面將部分特征融入識別模型以提升效果。這些特征包括:
(1)長度特征集。包括31 個特征。將句子長度以10 為組距,分成31 組,多于300 個字的歸為第31 組,將句長所屬組對應特征賦值為1,其余賦值為0。
(2)段內句數與位置。共包括6 個特征:獨段句和兩句段落分別將para_single 和para_dual 特征賦值為1,其余特征賦值為0。三句(含)以上段落將para_multi 特征賦值為1,para_first、para_middle和para_last 分別表示是否為段首、段中和段尾句。
(3)文內相對位置。包括20 個特征項。將句子文內相對位置以0.05 為組距,分成20 組,將句子文內相對位置所屬組對應特征賦值為1,其余賦值為0。
(4)TextRank。將句子TextRank 值以0.05 為組距分成20 組,所屬組對應特征項賦值為1,其余賦值為0。
上述特征中,(1)和(2)是摘要和全文層面共有的特征,而(3)和(4)則是全文層面數據所獨有的特征。按照4.3 節的分析結果,在摘要和全文層面分別選擇傳統機器學習模型中表現最優的SMO 和SVM 進行特征擴充實驗。表6 列出了加入這些特征后,模型識別效果變化情況。

表6 特征擴充識別效果分析
從表6 可以看出,在摘要數據上,僅加入長度特征后模型識別效果有較小提升,而段內位置特征加入后,識別效果幾乎沒有變化;結果顯示,將長度特征加入綜合特征后,準確率、召回率、F_1 值均小幅度提升0.5%。在全文數據上,長度、段內位置和文內相對位置特征有助于識別效果的提升;TextRank 特征加入后,論斷句識別效果幾乎沒有變化;最終,將有助于提升識別效果的三個特征全部加入特征集,識別準確率提升2.9%,召回率提升0.1%,F_1 值提升2.0%。
5 結 語
在現代科學研究中,系統地掌握、及時地了解各領域、學派、學者最新的研究發現和學術主張對學者開展研究工作起著越來越重要的作用。本文在對前人研究進行歸納的基礎上,提出學術論斷句的6 個判定標準,必要性標準可用于排除非論斷句,包括信念感、完備性、可證偽,充分性標準包括預測、個人理解和價值判斷三個標準。選擇信息資源管理領域部分論文數據開展摘要和全文層面的標注實驗,在此基礎上實現論斷句自動化識別。對論斷句和非論斷句文本特征進行分析,研究發現:①使用本文提出的判斷標準,標注者在摘要和全文層面對學術文本中論斷句和非論斷句標注的一致性較高。②基于BERT+BiLSTM 論斷句識別方法取得了最優的性能。③論斷句和非論斷句的長度在全文中的分布差異要大于在摘要中的差異;論斷句出現在文內開頭和結尾的概率要高于非論斷句,段首和段尾句被標注為論斷句的概率高于段中句;學術論文中論斷句TextRank 特征取值顯著高于非論斷句。在摘要層面,加入長度特征后,論斷句識別效果在F_1值上提升了0.5%。在全文層面,加入長度、段內相對位置、文內相對位置特征后,分類器識別效果在F_1 值上取得了2%的提升效果。
本文不足之處在于:①僅選取了信息資源管理領域的部分數據,數據量較少,范圍局限于人文社科領域,對自然科學領域的數據并未涉及,相關識別方法和結論的普適性還需進一步驗證,未來應在此方面加以補充;②在論斷句語料標注過程中,雖然不同標注人員在一定判定原則的前提下取得了較高的一致性,但數據規模較小,未來應對提出的判斷標準進行進一步完善;同時,論文不同區域的論斷句重要性并不相同,未來應考慮論斷句權重計算問題;③當前學術文本中論斷句識別已經取得較好的效果,但使用的方法、選擇的特征相對有限,準確率與召回率仍然存在一定提升空間,未來應著重挖掘文本的功能結構和推理結構,探索詞匯特征、句法特征、位置和長度特征的融合,提高論斷句或學術觀點句的識別效果。
此外,在本文的研究基礎上未來還應開展如下方向的研究:①本文從整句層面對論斷句進行了識別,未區分整句中的論斷性和非論斷性成分;未來,應從詞匯層面精確地識別邊界,從主題、研究對象和判斷類型等多維視角構建學術論斷的分類體系,并使用知識抽取的方式對各類論斷句進行細粒度地結構化表示;②論斷句僅是學術觀點或論點的必要條件,未來應從論斷句與上下文的修辭、邏輯關系入手對學術文本中的核心學術論點進行識別;同時,應從歸納和演繹的視角對各個論斷的論證方式和論據進行識別、匹配和分析,在此基礎上對論點進行權重評估,從論點間關系間角度識別文獻核心論點及其之間的語義關系,全面揭示學術論文論證結構;③在對單篇學術論文論證結構進行識別的基礎上,對同主題多文檔論證結構進行聚類、對齊、比較和歸納,發現研究者在觀點上的分歧,綜合不同研究視角的觀點對研究對象和問題形成整體性和更全面的認知。相關技術與方法在學術觀點的查重、創新性評估、自動識別學派上有著廣泛的應用前景。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
語文知識(2014年1期)2014-02-28 21:59:13
