學術文本詞匯功能識別
——在論文新穎性度量上的應用
2022-07-30 01:20:02羅卓然程齊凱
情報學報 2022年7期
羅卓然,陸 偉,蔡 樂,程齊凱
(1. 武漢大學信息管理學院,武漢 430072;2. 武漢大學信息檢索與知識挖掘研究所,武漢 430072)
1 引 言
從科學的發展來看,科學研究開始于問題發現[1],美國著名科學哲學家L?勞丹曾在其著作《進步及其問題——一種新的科學增長理論》中強調,科學研究的目的是解決問題;問題和方法是科研工作的重要組成內容,其中問題和方法的描述是科學話語的重要組成部分[2],它以特定的形式和程度表現在論文中,固化為論文中的某些詞匯或詞匯組合[3]。在創新學研究中,組合往往被看作創新產生的一個重要來源。創新理論的鼻祖約瑟夫·熊彼特(Joseph Alois Schumpeter) 在其著作《經濟發展理論》中提出創新(innovation)是已有生產要素和生產條件的組合[4],該觀點后來得到了國際上許多有影響力學者的支持[5-6]。目前,學術界對于學術文本中的“創新”這一概念還未形成統一定義,常見的指代詞如新穎性、創新力、顛覆性、innovation、novelty、creativity、fresh ideas、disruptive innovation等從創新的內容、時間、價值、影響等層面描述了創新的特征。學術研究成果的新穎性(novelty)能夠在某種程度上反映其創新性或前沿性[7],由于成果的價值一般需要較長的時間才能體現出來,在科研評價研究中常用新穎性描述研究成果的創新特質。通過文獻調研與分析,本文發現學術論文的新穎性主要源于研究問題、研究方法、研究結論等元素的重組與結合,其中研究問題與研究方法的組合是形成創新的重要方式[2]。
在科學研究領域,研究人員發現影響最大的科學研究成果主要基于以往工作的組合,尤其那些非典型的組合[8-11],并提出新穎性的主要來源是已有元素的重組或既有元素與新概念的組合[12-13]。此外,組合新穎性的內容和形式也不拘一格,國內外學者從參考文獻組合[14]、參考文獻的期刊組合[8-9,15]、詞匯組合共現[12,16-17]等內容的組合對科學創新進行了研究。上述研究從組合創新的視角研究了科研論文的創新范式,為學術論文新穎性度量和創新性評價提供了理論和方法基礎。然而,這種從期刊組合或參考文獻組合的角度度量新穎性的方法,在脫離論文內容的情況下測度論文新穎性,對新穎性的解釋力度還有所欠缺。值得注意的是,部分研究從論文詞匯組合的角度開展了新穎性研究,這類研究的對象更接近創新本體的內容層面,但是僅從詞匯組合頻率的角度計算新穎性[18-19],而缺少考慮詞匯之間的語義差異,這種情況下可能會忽略新穎性的重要特征。例如,對生物醫學詞匯之間的組合和生物醫學與計算機科學詞匯的組合而言,后者是一種跨學科詞匯的組合,這種組合能為新穎性來源和創新擴散的研究提供重要線索。挖掘組合詞匯的語義內涵,可以揭示不同跨領域研究背后的知識交叉與融合情況[20],有助于從詞匯功能的角度揭示論文新穎性的語義內涵[21]。
學術文本的詞匯功能是根據文本所在的語義環境對其承擔的語義角色和功能的認知和理解[22]。學術論文作為科研成果載體,其核心問題和核心方法解釋了論文待研究的問題和解決途徑[23],是體現論文新穎性和價值的重要功能元素。目前,國內外關于學術論文中的研究問題或研究方法的研究,主要集中在領域研究主題識別[24]、研究方法庫構建[25]、跨學科研究問題[26]與研究方法分析[27-28]等方面,而將問題與方法的組合應用在論文新穎性測度上的研究相對較少。
為進一步探索面向文本內容層面的新穎性度量方法,本文以組合新穎性理論為基礎,以學術論文細粒度詞匯功能語義差異為切入點,利用深度學習預訓練模型獲取蘊含語義信息的詞向量,提出面向CS(computer science)領域進一步預訓練的詞匯新穎性計算方法,通過模型對比實驗證明本文的預訓練模型表現效果更好。最后,將提出的語義新穎性計算方法與已有的共現率新穎性計算方法進行比較,結果表明,本文提出的方法能夠捕獲詞匯及詞匯組合之間更細粒度的新穎性差異。
2 相關研究
2.1 學術文本詞匯功能研究
術語抽取是海量文獻內容分析研究的基礎,其中不同術語的功能識別是分析術語語義功能的重要環節。伴隨著細粒度文本挖掘和實體抽取研究的深入,文本詞匯功能識別研究引起了越來越多的關注,學者們從內容元素、概念類型、詞匯功能和知識元等角度開展了詞匯功能相關研究。Kondo 等[29]將標題中的內容元素分為head、method、goal 和other 四類,并通過構建特定領域的方法/技術演化路徑構建了技術趨勢圖生成系統。Gupta 等[30]將學術文獻的詞匯功能分為話題、技術和領域三類并實現其自動識別。Tsai 等[31]將收錄于ACL(Associa‐tion for Computational Linguistics) 數據庫中的科學文獻中的概念分為技術(technique)和應用(appli‐cation)兩個功能類別,并提出了用于識別、歸納和聚類這兩類概念的算法,研究結果可為深入了解ACL 社區的研究進展、變化和趨勢提供有用的見解。Tuomaala 等[32]對LIS (library and information science)領域1965—2005 年發表的研究論文進行了內容分析,分析了研究論文主題分布與采用的方法和策略,解釋了研究問題和研究方法之間的聯系。Heffernan 等[2]認為科學研究是問題提出和解決的過程,將科學文獻中的詞匯功能分為研究問題和解決方法,并訓練分類模型對短語是否為問題或方法進行二值判斷。近年來,國內學者也對學術文本術語及詞匯功能識別展開了一些探索和研究。趙洪等[33]構建了面向理論術語的深度學習模型,研究了該模型中理論術語的特征構造和標注方法,并通過實驗對比驗證了該模型的有效性。王昊等[34]對情報學理論方法進行研究,利用深度學習模型開展了訓練與測試,發現術語實體的長度、訓練語料量、實體的類型和數量等因素也與識別結果直接相關。李賀等[35]構建了學術論文的研究問題、理論、方法、結論4 個知識元本體,提出了基于知識元的學術論文創新性判斷方法。章成志等[36]將研究方法分為論文使用研究方法和論文引用研究方法,以《情報學報》10 年的論文全文為數據對象,利用神經網絡模型抽取了研究方法實體并分析了其使用情況,發現情報學學科領域中使用頻次和引用頻次最高的均是與實驗相關的研究方法。化柏林[28]通過對文獻中研究方法內容描述的分析,將學術論文中的方法知識元總結為方法定義知識元、方法關系知識元、方法特點知識元、方法流程知識元和方法功能知識元5種類型。程齊凱等[37]提出了一種基于深度學習和標題生成策略的學術文本詞匯功能識別模型,基于seq2seq 模型和attention 機制的方式捕獲詞匯的多層語義信息,實現了學術文本中問題詞和方法詞的生成。陸偉等[38]構造了一種基于規則標題的數據標注方法對數據進行標注,并利用BERT(bidirectional encoder representation from transformers)預訓練模型對輸入的文本進行向量化表征,利用LSTM(long short-term memory)對關鍵詞進行自動判別以實現論文關鍵詞的問題或方法的識別。
2.2 組合新穎性度量研究
在學術論文新穎性度量與評價研究領域,不少學者試圖將基于人工甄別的傳統新穎性度量方式轉化為自動識別的新型評價方式。作為創新模式研究的重要范式之一,組合目的是對創新發展和創新擴散過程進行理論化與建模[39-40]。從組合內容和方式來看,代表性研究為參考文獻的期刊組合。Uzzi等[8]率先提出了基于重組的論文創新性度量,他們分析了來自Web of Science 中1950—2000 年發表的近1790 萬篇文獻,發現論文新穎性與先前工作的非常規組合有較大相關性。Boyack 等[15]基于Uzzi 等[8]的方法,以Scopus 中收錄的期刊為數據對象,利用基于期望標準差的K50 指標替代了Z-score 指標,結果顯示,該方法可以在文獻發表后的更早期得出同樣的結論。Wang 等[9]將科學研究視為一個組合過程,通過檢查已發表的論文是否首次對參考期刊進行組合來衡量科學的新穎性。除了參考文獻的期刊組合之外,有研究者直接利用參考文獻的組合來度量文獻的新穎性。Mukherjee 等[14]基于參考文獻的共被引網絡建立了“常規性-新穎性”的二維坐標系,將論文劃分為4 個創新類型。Ponomarev 等[41]認為,開創性成果是基于對已有研究的回顧與總結,提出了基于出版物引用動態檢測方法,并建立了論文創新性預測模型。Tahamtan 等[10]認為一篇論文中參考文獻的不尋常組合可以揭示其新穎性潛質,通過分析論文引文網絡中不同類型、不同主題的組合,歸納出了創新性論文常見的主題組合模式。此外,部分學者從與論文直接相關的詞匯角度度量了論文的新穎性。Azoulay 等[12]通過檢查論文中的MeSH 主題詞對,計算未出現在PubMed 上所有先前文獻中的詞對所占的比例,來衡量出版物的重組特征與新穎性,發現論文的重組程度與引文量之間存在負相關關系。Yan 等[40]定義了論文的新組合和新組件,提出了一種利用論文的關鍵字測度組合新穎性的方法。從問題詞和方法詞的角度,王艷艷等[18]利用人工的方法抽取科技文獻中的問題和方法,將問題、方法作為兩個維度構建了新穎性評估方法模型。錢佳佳等[19]根據詞頻和詞組合的頻次,提出了一種基于問題-方法組合的科技論文新穎性度量方法。Luo 等[42]考慮了詞匯的年齡和語義差異,提出了從詞匯生命指數和語義相似度兩個角度計算論文新穎性的方法。綜上,相關研究從期刊組合、引文組合、主題詞組合等角度開展了組合新穎性研究,也有從問題詞和方法詞的不同功能角度探索了論文新穎性測度,為本文的研究提供了良好借鑒的同時也存在研究數據不足、方法受限等情況。在此現狀下,本文發現從語義層面度量論文新穎性仍有進一步探索的空間。
學術論文的研究問題與研究方法是表達學術文本新穎性的主要功能詞匯,這種具有特殊語義功能詞匯的組合為新穎性研究提供了新思路。因此,本文在前期學術文本詞匯功能研究的基礎上開展詞匯功能在論文新穎性度量上的研究。
3 基于語義相似度的“問題-方法”新穎性度量方法
3.1 數據選擇
在程齊凱等[37]、陸偉等[38]前期關于詞匯功能的研究基礎上,本文利用論文研究問題、研究方法及其組合來測度論文的新穎性。為此,需要在論文中預先提取表征研究問題與研究方法的詞匯。由于論文的研究問題或研究方法可能不只一個,本文僅抽取了每篇論文中主要的問題詞和方法詞,即將論文認為是某一問題與某一方法的組合。本文中的主要問題詞是指能夠代表論文核心研究問題的詞或詞組,主要方法詞是指用于表征論文為研究解決問題所采用的方法、模型、工具或途徑的詞或詞組。實際中存在部分論文涉及多個研究問題或方法的情況,對于本文研究的組合新穎性而言,測度主要問題和主要方法的組合已能夠達到本文的研究目的,而多問題與多方法的自動抽取研究是下一步待解決的問題。
本 文 將ACM (Association for Computing Ma‐chinery)Digital Library(下稱ACM 數據庫)作為數據來源,該數據庫收錄了計算機領域權威和前瞻性的出版物,提供了解計算機和信息技術領域資源的窗口。陸偉等[38]提出的問題方法識別模型整體準確率、召回率和F1 值分別達到0.83、0.87 和0.85,優于傳統模型的效果。本文利用該模型提取了ACM數據庫中1968—2018 年的200182 篇文獻的研究問題詞和研究方法詞,并比較了模型識別效果與人工判斷的差異,在隨機篩選的100 條數據中主要問題方法詞識別一致性為82%。然后,抽取了每篇論文的DOI 號、題目、摘要、關鍵詞、發表時間等題錄信息,統計截止到2021 年2 月論文在ACM 數據庫中顯示的被引量。數據清洗操作中刪除了字段為空的數據記錄,保留了200103 條包含題錄信息和被引量在內的“問題-方法”記錄數據,并將其保存在數據庫中,實驗數據隨時間的數量分布如圖1 所示。統計每組“問題-方法”對出現頻數,再按照字母升序的方式為每一個問題詞和方法詞構建索引。最后,在數據庫中對所有的記錄數據進行條件查詢,并為每條記錄的論文設置索引ID,從實驗數據中隨機抽取2018 年的200 條記錄作為分析數據,剩余的199903 條數據作為歷史對照數據。
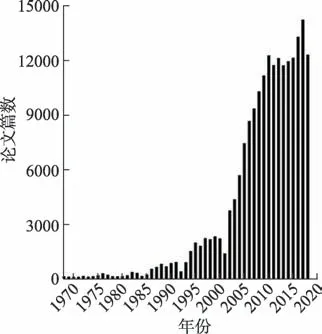
圖1 論文數量分布
3.2 技術基礎
為從語義層面計算問題詞與方法詞的新穎性差異,本文采用深度學習預訓練模型,在大規模科學文本數據集上訓練問題方法詞和方法詞的詞向量模型。詞向量是一種將詞表示成向量的無監督學習技術,代表性的詞向量訓練模型有word2vec[43]、GloVe[44]、BERT[45]等。2018 年,谷歌提出的BERT模型刷新了自然語言處理領域的11 個方向的最佳指標,是繼word2vec 之后深度學習方法在自然語言處理中的又一突破。BERT 模型利用Transformer[46]構造多層雙向編碼,該模型訓練的詞向量可用于文本相似度相關任務中。Su[47]于2020 年提出的Sim‐BERT 模型是經過微調的BERT 模型,在文本相似度任務上效果提升顯著,可見BERT 模型在語義相似度判斷上仍具有較好的表現。此外,SciBERT 是Beltagy 等[48]提出的一種基于BERT 的預訓練語言模型,該模型在BERT 的基礎上進一步在大型多領域的科學出版物語料庫上進行了無監督預訓練,提高了模型處理下游自然語言處理任務的性能,該模型能用于解決缺乏高質量、大規模標注科學數據的問題。
鑒于科學語料在詞匯功能與內容含義層面具有高度的專業性和領域區分度,直接使用SciBERT 的問題在于對所有的輸入向量都傾向于編碼到一個較小的空間區域內,導致大多數的問題方法詞對都具有較高的相似度分數,不利于語義新穎性差異化度量。為此,本文參考文本表示領域的常規做法[49-50],再次引入ACM 語料做進一步預訓練,在獲取更好語言模型的同時得到更能表征問題詞和方法詞真實差異的向量表示。語言模型效果的常用評價指標是困惑度(perplexity),在一個測試集上得到的困惑度越低,說明建模的效果越好[51]。本文選擇困惑度作為模型評價指標。
3.3 模型訓練與詞匯新穎性計算
為從語義層面度量學術論文中研究問題詞匯與研究方法詞匯的新穎性差異,本文基于BERT 模型將詞匯表示成詞向量的形式,將利用這些詞向量表示輔助計算“問題-方法”組合的新穎性。進一步地,本文提出一個面向CS 領域進一步預訓練(fur‐ther pretrain)的詞匯新穎性計算方法,如圖2 所示。本文在SciBERT 的基礎上引入ACM 數據庫中200182 篇論文中的標題及摘要信息,通過無監督訓練任務根據句子上下文來預測的概率分布,實現對SciBERT 的進一步預訓練,通過對模型調參和訓練,生成面向ACM 論文語料的詞向量表征模型SciBERT-further。
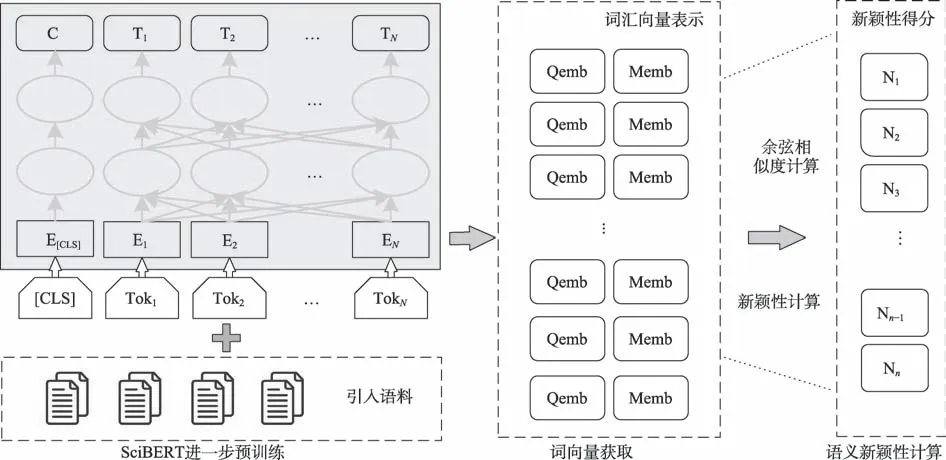
圖2 面向CS領域進一步預訓練的詞匯新穎性計算方法
進一步預訓練模型效果驗證。首先,對收集到的ACM 語料進行分句并統計句子信息,結果表明,25%的句子是短句,在15 詞以內,75%的句子在27詞以內,最大句長76 詞。為盡可能完全覆蓋語料中的句子,再訓練時設置模型最大句長為72。在打亂句子順序后,按照9∶1 的方式劃分訓練集和測試集。然后,針對本文相似的問題-方法在編碼后的表示空間中應當相近,不同的問題-方法應相距較遠的需求,為獲取更好的詞匯級詞向量表示,對同一樣本利用打亂詞序、特征裁剪兩種方式進行數據增強,同時利用模型的第一層詞匯編碼和最后一層句子編碼實現信息融合。最后,在測試時選擇了模型困惑度作為評測指標,對于測試集,將其測試樣本全部融合計算,取平均值計算該指標。訓練集的模型損失和測試集的困惑度分別如圖3a 和圖3b所示。
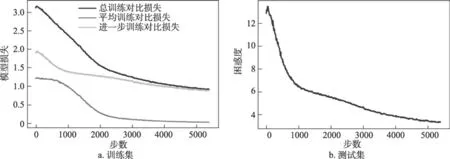
圖3 進一步預訓練中模型損失和困惑度變化圖
此外,本文在文本語義匹配任務(semantic tex‐tual similarity, STS) 的STS12、 STS13、 STS14、STS15、STS16 這5 個數據集上進行了實驗,并對比了Avg.GloVe、BERT、SciBERT 和SciBERT-further模型在無標注的STS 數據上的訓練效果,具體得分如表1 所示。結果顯示,在完全一致的設置下,本文提出的SciBERT-further 模型相對于Avg.GloVe 模型平均提升了3%,相對于BERT 提升了10.5%,相對于SciBERT 平均提升了17%,表明本文提出的SciBERT-further 模型能較好地表征詞匯真實特征,且比在類似任務上采用BERT 模型的表現更好[42]。

表1 SciBERT-further與其他方法在無監督情況下的性能比較
問題詞和方法詞新穎性計算。提取學術論文“問題-方法”數據集中的問題詞和方法詞,在Sci‐BERT-further 模型中計算并獲取上述詞的詞向量。然后計算當前問題詞和方法詞與已有詞匯空間中所有詞匯的余弦相似度,取最大值,計算詞匯的新穎性,問題詞和方法詞的新穎性計算方式分別為
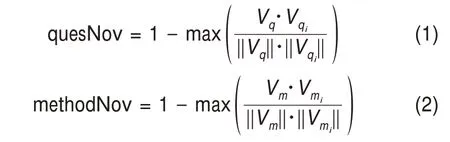
其中,quesNov 表示問題詞新穎性,Vq表示當前問題詞的詞向量,Vqi表示問題詞域的第i個問題詞的向量表示,計算Vq和Vqi的余弦相似度,用1 減去最大的向量余弦相似度,得到quesNov 的值,若Vq與Vqi越相似,則表示Vq的新穎性越小;methodNov表示方法詞新穎性,Vm表示當前方法詞的詞向量表示,Vmi表示方法詞域中第i個方法詞的向量表示,用1 減去最大的向量余弦相似度,得到methodNov的值。
3.4 “問題-方法”組合新穎性計算
對于論文中的“問題-方法”組合,在學術論文“問題-方法”數據集中查找當前問題詞或當前方法詞是否存在。若存在,則表明是舊的研究問題或研究方法;若不存在,則表示當前詞在已有的問題詞域或方法詞域中不存在,屬于新的研究問題或研究方法。組合新穎性計算的是相對新穎性,即當前組合詞相對于組合對象的所有歷史組合詞的新穎性。這里對問題方法詞是否存在進行了精確查找,只要之前在數據集中未出現過即為新詞。語義相似度用在計算組合對象的新穎性上,即對舊的問題詞或方法詞,計算它的當前組合詞與歷史組合詞序列之間的相似度。在錢佳佳等[19]對“問題-方法“組合劃分的基礎上,本文從詞匯組合方式上將“問題-方法”組合進一步分為5 種類型:“新問題+新方法”組合、“新問題+舊方法”組合、“舊問題+新方法”組合、“舊方法+舊問題”舊組合和“舊方法+舊問題”新組合。
對于“舊問題+新方法”和“新問題+舊方法”的組合而言,在已有的問題空間中分別提取與其組合過的詞,形成舊問題的方法序列和舊方法的問題序列。由于本文主要從詞匯功能組合的角度研究“問題-方法”組合,因此計算的是當前組合詞與已有組合序列的相似度。因此,對于“舊問題+新方法”組合,“新方法”不是相對于全部方法詞域來說的,而是相對于舊問題的方法序列而言,即只要當前方法詞沒有與當前問題的方法詞序列組合過,對于當前的組合來說該方法即為新方法。然后,計算當前方法詞的組合新穎性,分別計算當前方法詞與舊問題的組合序列中各個方法詞的相似度。最后,將當前組合詞的新穎性得分賦值給“問題-方法”組合,得出最終組合新穎性。基于語義相似度的“問題-方法”組合新穎性計算流程如圖4 所示。
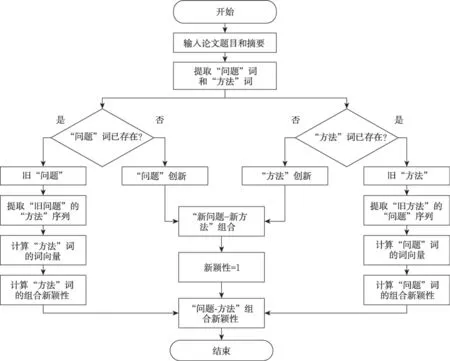
圖4 基于語義相似度的"問題-方法"組合新穎度計算流程
對于舊問題或舊方法的組合而言,本文將“舊問題”和“舊方法”稱作當前詞,與其組合的對象稱作組合詞。對于“問題-方法”組合中的當前詞t,要測度其組合的新穎性,則需要判斷其組合詞p的相對新穎性。例如,對于現有研究中已存在的舊問題t,首先枚舉與該問題組合過的所有方法,形成t的歷史組合序列P(p1,p2,…,pn)。利用SciBERTfurther 模型計算當前組合詞p的向量表征Vp與P中各個歷史組合詞的詞向量的余弦相似度,計算方式為
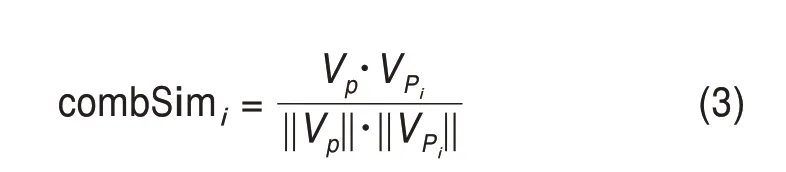
其中,VPi表示序列P中的第i個元素的詞向量表征;combSimi表示Vp與VPi的余弦相似度。
“問題-方法”組合的相似度取當前組合詞p與當前詞t的歷史組合序列P中各個元素的最大相似度值,“問題-方法”組合的相似性越高,表示該組合的新穎性越低,將“問題-方法”的新穎性得分定義為combNov(t,p),計算方法為

本文將論文的新穎性Novelty(D)定義為問題詞新穎性、方法詞新穎性以及問題-方法組合新穎性三項的算數平均值,即
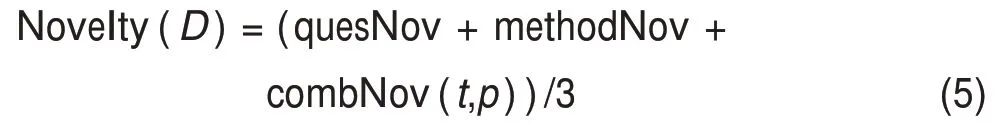
若一篇論文存在多個問題與方法,則逐個計算問題詞、方法詞以及所有的問題-方法組合的新穎性,對這些新穎性得分取算數平均值就得到論文新穎性。
4 “問題-方法”新穎性測度實驗
4.1 基于語義相似度的“問題-方法”新穎性計算
采用訓練得到的詞向量模型SciBERT-further 計算得到所選問題詞和方法詞的詞向量,并根據公式(1)~公式(4)計算詞和組合的新穎性。由于計算出的新穎性得分均較小,不能顯著體現不同組合之間的差異性,為便于數據可視化分析,本文對數值小于1的新穎性得分進行了分值歸一化處理,計算方式為
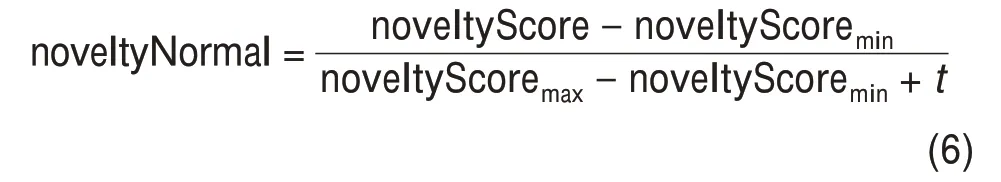
其中,noveltyNormal 表示歸一化后的新穎性得分,取值范圍為[0,1);noveltyScore 表示計算出的詞和組合的新穎性得分,noveltyScoremin表示測試集數據中新穎性得分的最小值,noveltyScoremax表示測試集數據中新穎性得分最大值;為避免分母為0,在分母中加上常數t,這里取t=0.001。
通過上文的模型訓練與新穎性計算,得到了測試集中200 篇論文的“問題-方法”新穎性得分,其中“問題”詞、“方法”詞和“問題-方法”組合的新穎性得分取值范圍均為[0,1],具體分布如圖5 所示。圖中綠色的圓點表示“問題-方法”組合新穎性得分,圓點左邊藍色和右邊黃色的柱狀線分別表示論文研究問題和研究方法的新穎性得分。由統計數據和圖6 可知,2018 年發表的200 篇論文中,“舊問題+舊方法”的論文有1 篇,占所有測試論文的0.5%,說明對于ACM 數據庫中收錄的計算機領域的論文而言,同一個研究問題采用與已有研究完全相同的方法進行研究的論文占極少數,而多數研究屬于“新問題+舊方法”或者“舊問題+新方法”的組合。此外,“新問題+新方法”的論文有95 篇,占所有測試論文的47.5%,由此可見,近半數的研究具有問題和方法兩個層面的創新。

圖5 基于語義相似度的“問題-方法”新穎性得分(彩圖請見https://qbxb.istic.ac.cn/CN/volumn/home.shtml)
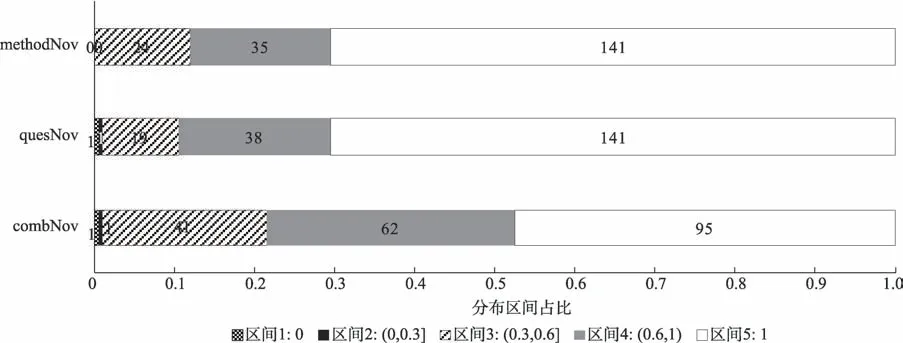
圖6 “問題-方法”新穎性取值分布區間
此外,本文對三類新穎性得分進行了區間分布統計,按區間將新穎性取值分為5 個部分:區間1,新穎性得分為0;區間2,新穎性得分取值范圍(0,0.3];區間3,新穎性得分取值范圍(0.3,0.6];區間4,新穎性得分取值范圍(0.6,1);區間5,新穎性得分取值為1。本文將詞匯新穎性的閾值設置為同類型所有詞新穎性得分的中位數,統計結果表明,本實驗中問題詞和方法詞新穎性閾值均為1。
由圖6 可見,測試集中的問題詞和方法詞的新穎性值的數量分布在5 個區間的呈現一致性,即位于區間1 的新穎性為0 的最少,而新穎性為1 的最多,說明在ACM 收錄的論文中無論是研究問題還是研究方法,與已有的主題完全重合的占比非常小,只占到所有分析數據的0.5%,而70.5%的問題詞和方法詞的新穎性為1,即在已有的主題詞空間中均未出現過。從“問題-方法”組合的角度看,組合新穎性值要整體小于單個問題詞或單個方法詞的新穎性值的分布,新穎性為1 的組合占所有測試數據的47.5%,組合新穎性值位于區間3 和區間4 的數據占所有數據的51.5%,表明“問題-方法”組合中有一半是具有中度新穎性的。整體而言,通過詞向量語義相似度計算的不同新穎性區間的數值差異明顯,問題詞和方法詞在不同新穎性區間的數量分布呈現相同的分布特征,亦表明不同功能的詞匯在語義相似度上具有一致性,說明本文提出的基于詞向量語義距離計算的“問題-方法”組合新穎性能夠測度不同詞匯之間的新穎性差異。
4.2 結果分析與討論
采用以上方式計算出論文的“問題-方法”組合新穎性的得分后,為進一步解釋該方法的度量效果,本文分別從高新穎性的高被引和高頻詞兩個角度對結果進行實例分析。
從高新穎性和高被引角度來看,本文結合論文的被引量指標,從高新穎性得分(問題、方法、組合新穎性得分均為1)的論文中,列舉了排名前五的論文,如表2 所示。由表2 可知,新穎的研究主題包括用戶和項目關系學習、Ad-Hoc 搜索、上下文感知計算系統、網絡型數據挖掘、個性化檢索等,與主題相對應的新穎的研究方法包括潛在關系度量學習、語法軟匹配、將語境利用在遞歸推薦系統中、基于相似度的多功能圖嵌入和隨機點擊模型。由此可見,對計算機領域近些年的研究而言,若以論文的被引量代表論文的影響力,從問題和方法組合新穎性的角度來看,ACM 數據庫中收錄的新穎性和影響較強的論文研究主題與信息檢索、用戶信息行為、推薦系統密切相關,問題的解決方法則采用深度學習、人機協同、圖網絡等衍生方法,與用戶行為、情境感知、決策匹配等情景的相關性更高。

表2 ACM數據庫2018年高新穎性論文示例
從詞頻角度來看,詞的出現次數能夠反映該話題的熱度和關注度。本文統計了測試集中問題詞和方法詞的頻次,并分別選取了2 個高頻問題詞和2個高頻方法詞,獲取與其相關的論文信息,如表3所示。高頻問題詞“人機交互(human-robot interac‐tion)”和“無線網絡(wireless network)”是計算機領域經典的研究問題。示例論文Q1-1 和Q1-2 圍繞經典研究問題“人機交互”開展了研究,Q1-1 討論了如何進一步探索不同的反饋方法,并研究它們對信任、控制分配和工作負載的影響,屬于采用新方法解決舊問題的研究。論文Q1-2 開發了一個基于任務對話和聊天機器人的人機交互多通道系統,并證明了該系統中應用強化學習是有益的,是舊問題+舊方法新組合類的研究。這兩篇論文研究了同樣的舊研究問題,Q1-2 采用了熱門的深度學習模型強化學習(reinforce learning),在發表后獲得了比Q1-1 更高的被引量,表明用舊方法+舊問題組合在新穎性上可能比新方法+舊問題弱一點,但是影響力不一定比新方法低,因為舊方法可能在某階段引起了大量的研究興趣,例如,Q1-2 中的“強化學習”一詞雖然在1998 年就已出現,但隨著近些年智能計算和深度學習的發展,強化學習再度受到了較多的關注。示例論文Q2-1 和Q2-2 研究了計算機工程領域無線網絡(wireless network)的問題。Q2-1提出了一個處理器支持的超低延遲調度實現PULS(propellant utilization loading system),用于測試無限網絡下行調度協議的超低延遲需求。Q2-2 提出了無線網絡拓撲選擇和組件規模調整的設計空間探索方法,其新穎性類別為舊問題+舊方法的新組合,研究方法是舊方法且受到的關注較少,發表后獲得的被引量較低。
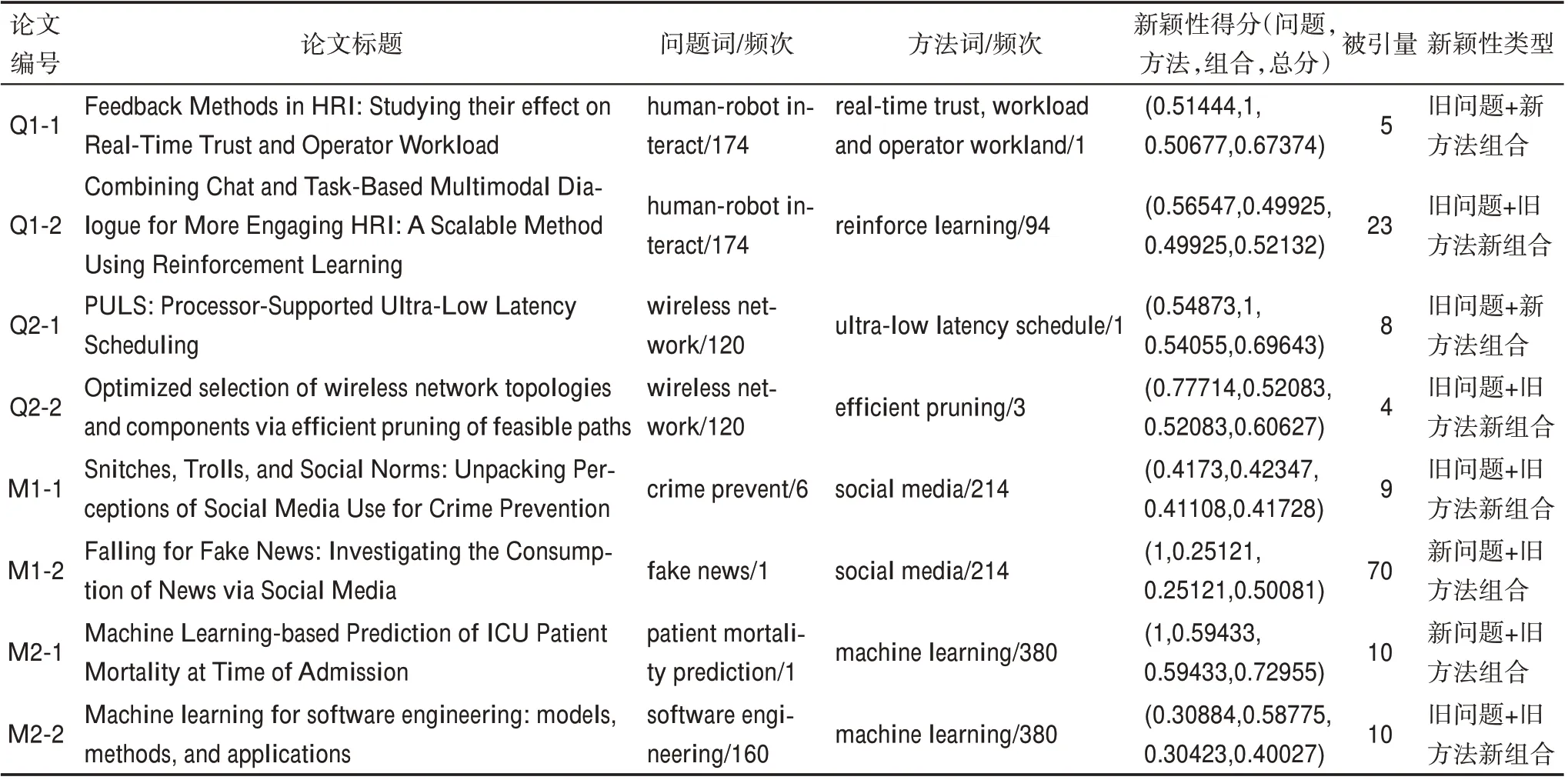
表3 高頻問題詞和方法詞組合論文示例
高頻方法詞社交媒體(social media)和機器學習(machine learning)是近年來人工智能方向的熱點詞,示例論文M1-1 和M1-2 研究了“社交媒體”作為研究方法時的應用。M1-1 研究了人們如何看待社交媒體在其社區中支持預防犯罪的使用,屬于常規舊問題+舊方法的新組合,新穎性較低且發表后獲得的引文量較少。M1-2 研究了人們對社交媒體新聞的態度,研究結果突出了打擊假新聞傳播的困難,該研究是將舊的研究方法應用在新的熱門研究問題“虛假新聞檢測”上的案例,問題的新穎性使論文獲得了較大的關注。示例論文M2-1 和M2-2是將機器學習作為研究方法的應用案例。M2-1 開展了將機器學習技術應用于預測醫院重癥監護室病人死亡率的研究,是用舊方法解決新問題的案例。M2-2 圍繞機器學習在軟件工程中所面臨的挑戰,以及機器學習如何從軟件工程方法中受益開展了研究,是舊問題與舊方法的新組合的案例。這兩篇論文是機器學習技術應用于不同領域的案例,均獲得了10 次引用,表明機器學習技術具有較強的推廣應用性。整體而言,無論是對于高頻問題詞還是方法詞而言,新穎性僅是從詞的新舊層面測量新穎性,而論文發表后的被引量不僅取決于研究問題或研究方法的新穎程度,還受到研究問題本身的適用性的影響。
由上述分析可知,論文研究問題或方法的新穎性與發表后一定時期內能獲得的被引量有一定聯系,但計算組合新穎性得分與被引量之間的相關性發現,其未達到顯著程度,將其可能的原因總結為兩點。其一,對于某些研究問題,方法的創新可能獲得更大的影響,這是由于有的經典問題本身就帶著“光環效應”,它可能是一個還未攻克的難題或瓶頸,也可能本就屬于熱點問題。其二,論文發表后的被引量或許可以反映一定的新穎性,但卻不能完全揭示新穎性或創新性的特征內涵。一方面,對于經典的理論或方法,新穎性的研究會面臨一些來自外部的阻力,包括來自現有科學范式的抵制[52];另一方面,由于受限于研究問題范圍的影響,也許在該問題上某方法的新穎性較高,但是這個問題還沒有受到相應的關注,或許需要更長的時間才能發現其新穎性并將其納入后續的研究中。
4.3 新穎性計算方法對比分析
本文提出的基于語義相似度的“問題-方法”組合新穎性計算方法是深度學習模型在詞匯新穎性度量上的應用。為進一步比較本文提出的方法與已有方法的差異,利用錢佳佳等[19]提出的基于問題-方法組合共現率的科技論文新穎性計算公式,計算了200 條分析數據的共現率新穎性,將該方法計算的問題新穎性、方法新穎性、組合新穎性和論文新穎性的結果與本文提出的語義新穎性計算結果進行了比較,如圖7a~圖7d 所示。其中quesNov、meth‐odNov、combNov 和paperVov 分別表示問題詞、方法詞、組合和論文的語義新穎性計算結果,nov_Q、nov_M、nov_Q2M 和nov_D 分別表示問題詞、方法詞、組合和論文的詞頻共現率新穎性計算結果。圖7 中三角形表示本文語義新穎性計算結果,圓點表示共現率新穎性的計算結果。對于單個詞的新穎性,由圖7a 和圖7b 可知,共現率新穎性的計算結果呈現明顯的兩極分化,集中在新穎性為1 和新穎性小于0.6。相較而言,語義新穎性的分布更為均勻,表明基于詞匯語義方法捕捉到的新穎性更為精準,這一現象在圖7c 中得到了更為顯著的驗證。由圖7c 可知,共現率新穎性的計算結果幾乎全部集中在新穎性為1 的區域,表明用該方法計算的組合新穎得分幾乎全部是1,象征著問題-方法組合都是一樣的新穎性,然而實際情況中的組合并不都是新穎的,受限于基于詞頻共現率的新穎性計算的局限性,該方法不能區分更為細微的新穎性差異;而基于語義的新穎性計算方法彌補了該方法的這一局限,能夠捕獲細微的差異。例如,語義新穎性計算方法計算的augment reality 和augment reality game 之間的差異就比augment reality 和blockchain 之間的差異要小,前兩者在向量空間中更為接近,相似度更高且相對新穎性不如后兩者;而基于詞頻共現率的新穎性計算認為這兩組詞的相對新穎性是一樣的,這將會在較大程度上損失新穎性測度精度。共現率新穎性計算方法中的實驗將論文新穎性計算公式中的問題、方法和問題-方法對的權重分別設為0.25、0.25 和0.5,即給問題-方法組合更大的權重,該做法在組合新穎性的理論層面是有意義的,然而受限于基于詞頻共現的新穎性計算方法,論文新穎性結果的整體分布更為緊密(聚集在0.8 附近),導致新穎性結果的差異更小,如圖7d 所示。總的來說,對比實驗的結果表明,基于語義相似度的問題-方法組合新穎性計算方法要優于基于詞頻共現的新穎性計算方法,前者利用詞向量的空間語義捕捉優勢能計算出更為精細的新穎性。
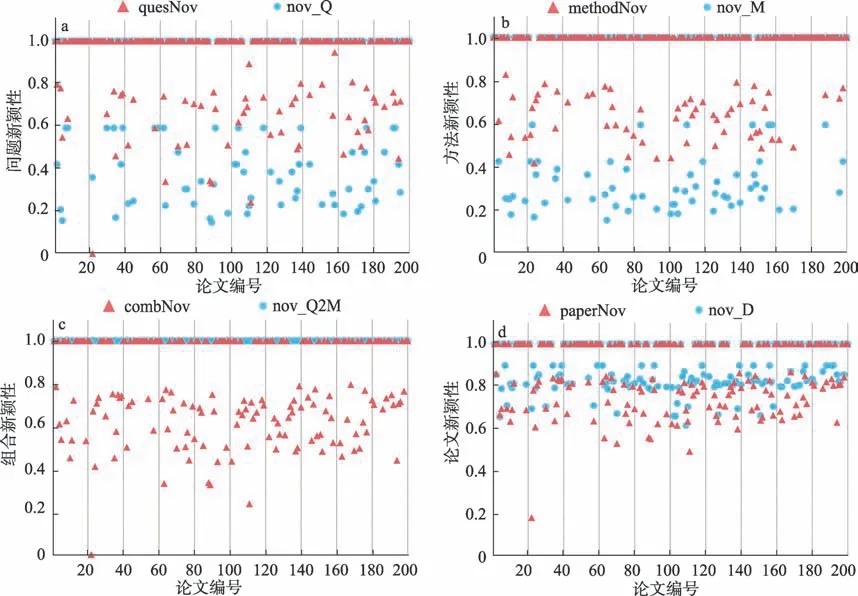
圖7 兩種新穎性計算方法對比
5 總結與展望
科學問題作為科學研究的邏輯起點,其解決方法是促進科學研究深入與發展的助推器。科學研究問題和研究方法的識別對科技前沿追蹤和創新研究發現具有重要研究意義。近年來隨著內容分析研究的流行,從學術文本內容視角對學術論文進行細粒度挖掘,是圖書情報學領域的一個新視角,其中學術論文詞匯語義功能的識別能夠幫助學者快速了解學術論文的核心內容,有助于厘清研究問題、研究方法的演化過程和發展模式,輔助于論文創新識別和新穎性度量研究。
本文以組合創新理論為基礎,以具備詞匯語義功能的學術論文問題詞和方法詞為數據,從問題與方法組合的語義層面研究了論文新穎性度量方法。與已有新穎性計算方法進行比較,發現本文提出的方法能捕獲問題詞、方法詞和問題-方法組合之間更為精細的新穎性差異。本文的不足之處是問題詞和方法詞的識別效果在某種程度上會影響論文新穎性計算結果。本文提出的計算方法更類似于計算機領域新穎性追蹤(novelty track)的方法,該方法是獨立于問題詞和方法詞本身的,但結果的解釋卻依賴于詞匯識別結果,更為準確的詞匯識別結果將會使本文的研究結果更具有可解釋性和延伸價值,如用于新穎性和影響力之間的關系分析、創新擴散的規律分析等研究上。此外,問題新穎性、方法新穎性及組合新穎性與論文影響力之間的聯系也是值得進一步探索的方向。
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
開放教育研究(2020年2期)2020-03-31 01:54:14
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中華胰腺病雜志(2012年3期)2012-11-07 05:18:45
