傾向性評分匹配應用條件及SPSS軟件實現
2022-07-30 07:07:30王瑞平
上海醫藥 2022年13期
王瑞平
(上海市皮膚病醫院臨床研究與創新轉化中心 上海 200443)
近年來,隨著網絡信息技術的發展和國內外臨床研究的持續升溫,越來越多的研究者開始關注大型人群隊列的建立和應用。盡管隨機對照臨床試驗(randomized clinical trial, RCT)可以提供高級別的循證醫學證據,但其往往耗費較多的人力、物力和財力,同時有些研究中干預措施的隨機分組還存在倫理學問題。因此,如何基于觀察性臨床研究開展等效于RCT 研究的數據處理越來越受到臨床研究工作者的關注。1983 年,由Paul Rosenbaum 和Donald Rubin 提出的傾向性評分匹配(propensity score matching,PSM)分析可以減少研究中的偏差和混雜變量影響,以便對觀察組和對照組進行更合理的比較,較為完美地解決了上述問題[1]。本文將介紹PSM 的概念和應用條件,以及如何應用SPSS 軟件實現PSM的過程,以期為研究人員開展PSM分析提供參考。
1 PSM 的概念
PSM 是一種統計學方法,主要用于處理觀察性臨床研究或臨床試驗研究數據亞組分析,可有效降低混雜偏倚,并在整個研究設計階段,得到類似隨機對照研究的效果。在觀察性臨床研究和RCT 研究亞組分析中,由于種種原因,導致偏倚和混雜變量較多,PSM 可以有效減少這些偏差和混雜變量的影響,以便對觀察組和對照組進行更合理的比較。目前,PSM 分析在醫學、公共衛生、經濟學等領域應用廣泛。
例如,某研究者想開展吸煙對于大眾健康影響的研究,這時候往往會采用觀察性研究設計,而不是隨機對照研究設計。因為如果要開展隨機對照試驗,須要把研究對象隨機分為吸煙組和不吸煙組,這種臨床試驗不符合科研倫理,無法實施。但面對容易獲得的觀察研究數據,如果不加調整,很容易獲得錯誤的結論,比如拿吸煙組健康狀況最好的一些人和不吸煙組健康狀況最不好的一些人作對比,可能會得出吸煙對于健康并無負面影響的結論。從統計學角度分析,這是因為觀察研究并未采用隨機分組,無法基于大數定理的作用,在觀察組和對照組之間削弱混雜變量的影響,很容易產生系統性的偏差。而PSM 可以解決這個問題,消除組別之間的干擾因素。
2 PSM 的應用條件
如前所述,PSM 是一種統計分析方法,主要用于處理研究組之間的不匹配或不可比的問題。PSM 分析的核心思想是控制偏倚,提高研究組之間的可比性。相比于常規的偏倚控制方法,如限制研究對象、隨機化分組、匹配、分層分析、多因素分析等,PSM 能考慮更多匹配因素,提高研究效率。
PSM 的應用基于臨床研究設計類型,目前主要用于描述性臨床研究、分析性臨床研究和RCT 臨床試驗研究亞組分析。PSM 的應用條件主要考慮如下兩種情形:①在觀察性研究和RCT 臨床試驗研究亞組分析中,分組間的樣本量比超過1 ∶4 范圍,非暴露組與暴露組直接比較的個體數量差異較大。在這種情形下,根據一定條件,選出非暴露組與暴露組交集,將這2 個可比性好的子集進行比較,可減少Ⅰ類錯誤增加,使研究結論更可靠。②盡管分組間在樣本量比例接近1 ∶1,但衡量個體特征的參數很多,若組間存在不均衡和不可比情況,從暴露組中選出1 個跟非暴露組在各項參數上都相同或相近的子集作對比則更為可取。
3 PSM 在SPSS 軟件中的實現
在應用SPSS 軟件開展PSM 分析之前,研究者應提前做好如下3 個方面內容的準備:首先,研究者須安裝SPSS 23.0 及以上的軟件版本,較低版本的SPSS 軟件無PSM 功能;其次,研究者應根據研究目的,確定暴露因素和結局變量,并確認后續分析的研究類型,如病例對照研究、隊列研究或RCT 研究亞組分析;最后,在確定的研究設計類型、暴露因素和結局變量的基礎上,先開展單因素分析,結合因果判定原則及有向無環圖(directed acyclic graph, DAG)判定方法,找出須要匹配控制的變量。為更好地解釋PSM 在SPSS 軟件中的實現,本文引用項目團隊前期開展的“母親孕期二手煙暴露對新生兒低出生體重影響的隊列研究”[2]舉例說明。
如圖1 所示,“母親孕期二手煙暴露對新生兒低出生體重影響的隊列研究”數據庫主要包括9 個變量,其中暴露因素為母親孕期二手煙暴露,結局變量為低出生體重(<2 500 g),潛在須控制的協變量包括嬰兒性別、母親年齡、母親文化程度、家庭收入、妊娠期糖尿病史、孕前BMⅠ指數和嬰兒分娩孕周。通過單因素分析(協變量分別與暴露因素、結局變量之間的分析),結合因果判定原則及DAG 判定方法,最終確定本研究應進行匹配的變量包括:母親年齡、孕前BMⅠ、孕期妊娠糖尿病病史、母親文化程度。
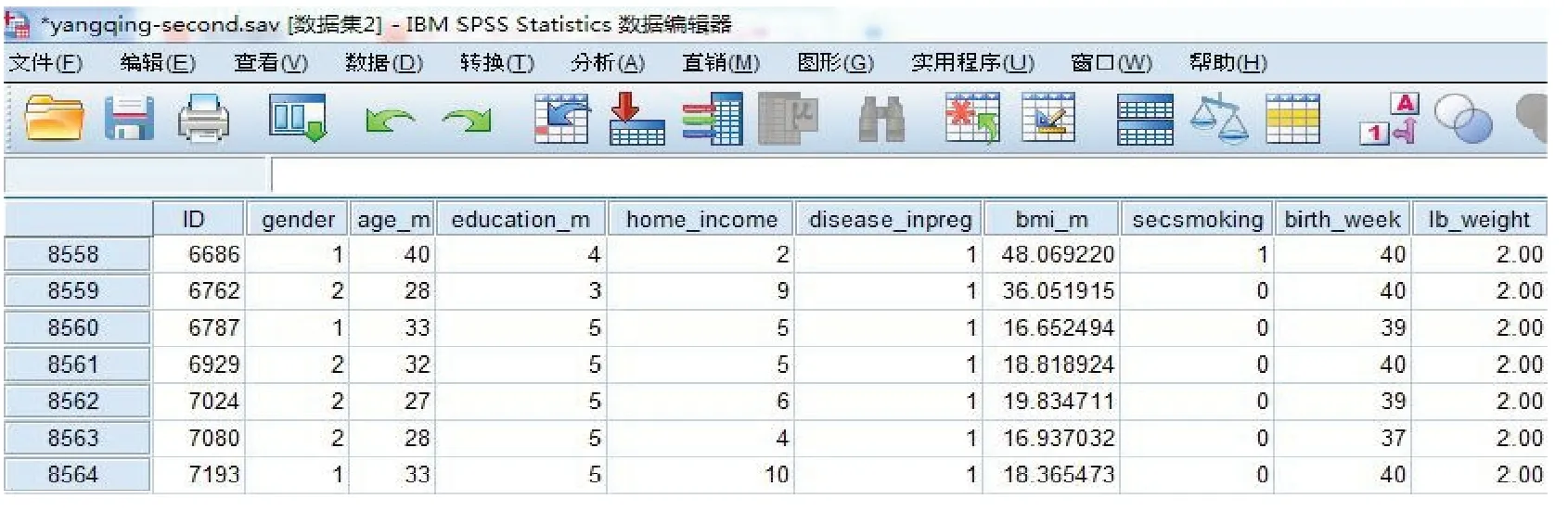
圖1 母親孕期二手煙暴露對新生兒低出生體重影響的隊列研究數據庫
在確定暴露因素、結局變量和須匹配的變量后,打開SPSS 23.0 軟件。如圖2 所示,選擇“數據菜單→傾向得分匹配”后打開對話框,在“組指示符”框放入暴露因素變量,在“預測變量”框放入待匹配的變量;然后,在“傾向變量名”框定義新的“傾向性評分變量”,在“匹配容差”框中設置匹配精度條件,取值范圍為[0, 1],數值越小,匹配的精度越高,但難度也相應越大;隨后,在“個案ⅠD”框放入原始數據庫的個案編號,在“匹配ⅠD 變量名”中定義新數據庫中匹配成功對象的編號,在“輸出數據集名稱”中定義匹配后數據庫的名稱;最后,在完成上述操作后點擊“選項”按鈕,打開新的對話框。
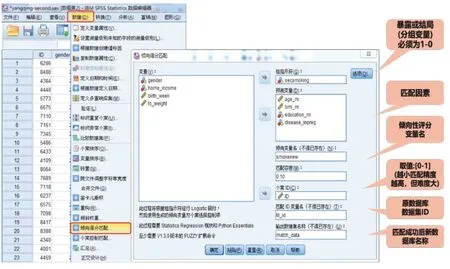
圖2 PSM分析在SPSS軟件中的操作步驟(一)
如圖3 所示,在“合格個案變量”框中定義變量名,用于展示匹配成功的個數;同時,在“抽樣”中選擇“不放回”,勾選“最優化執行性能”和“抽取匹配項時隨機排列個案順序”;最后,在“隨機數種子”中填入數字,以保證PSM 過程的可重現性。完成上述操作后,點擊“繼續→確定”按鈕,即完成PSM 分析。須注意的是,第一次打開運行PSM 時可能不成功,可先運行其它功能,如使用數據菜單中PSM 下方的“個案控制匹配”,填寫并運行,隨后再打開PSM 即可成功。
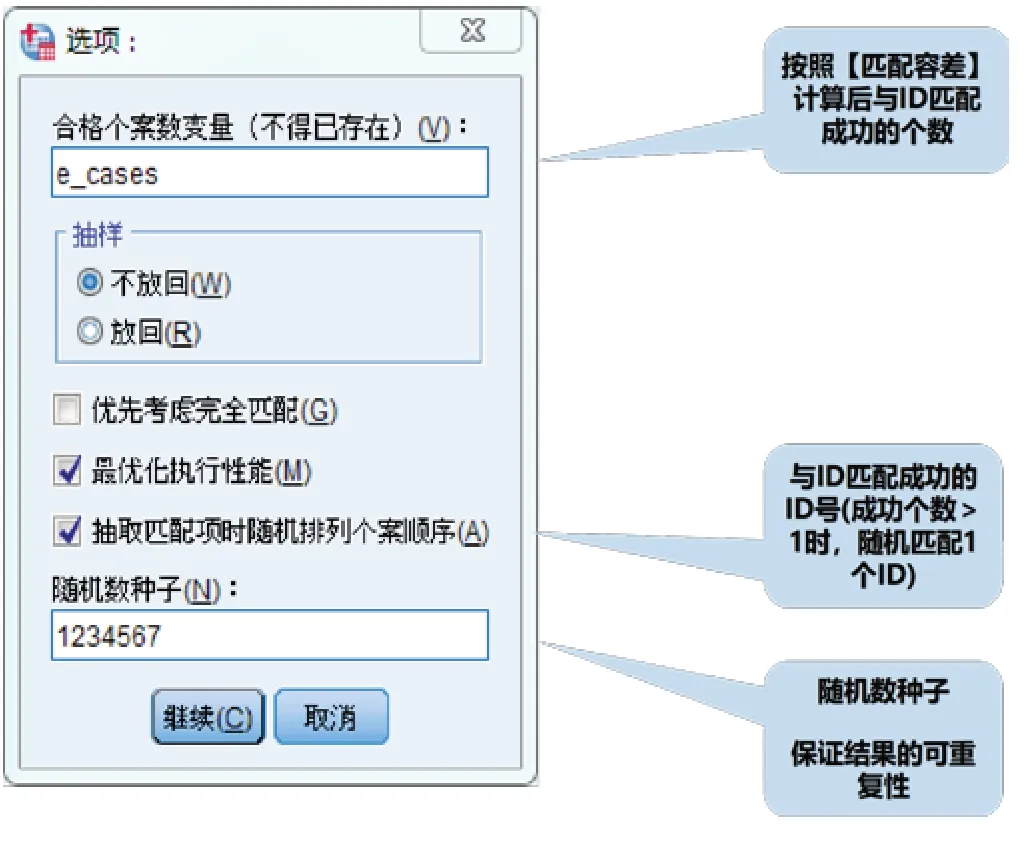
圖3 PSM分析在SPSS軟件中的操作步驟(二)
如圖4 所示,匹配成功的“match data”數據庫新增3 列數據:第1 列為基于匹配因素計算的傾向性得分情況;第2 列為按照匹配容差與原始ⅠD 匹配成功的個數;第3列為匹配成功后變量的新編號。
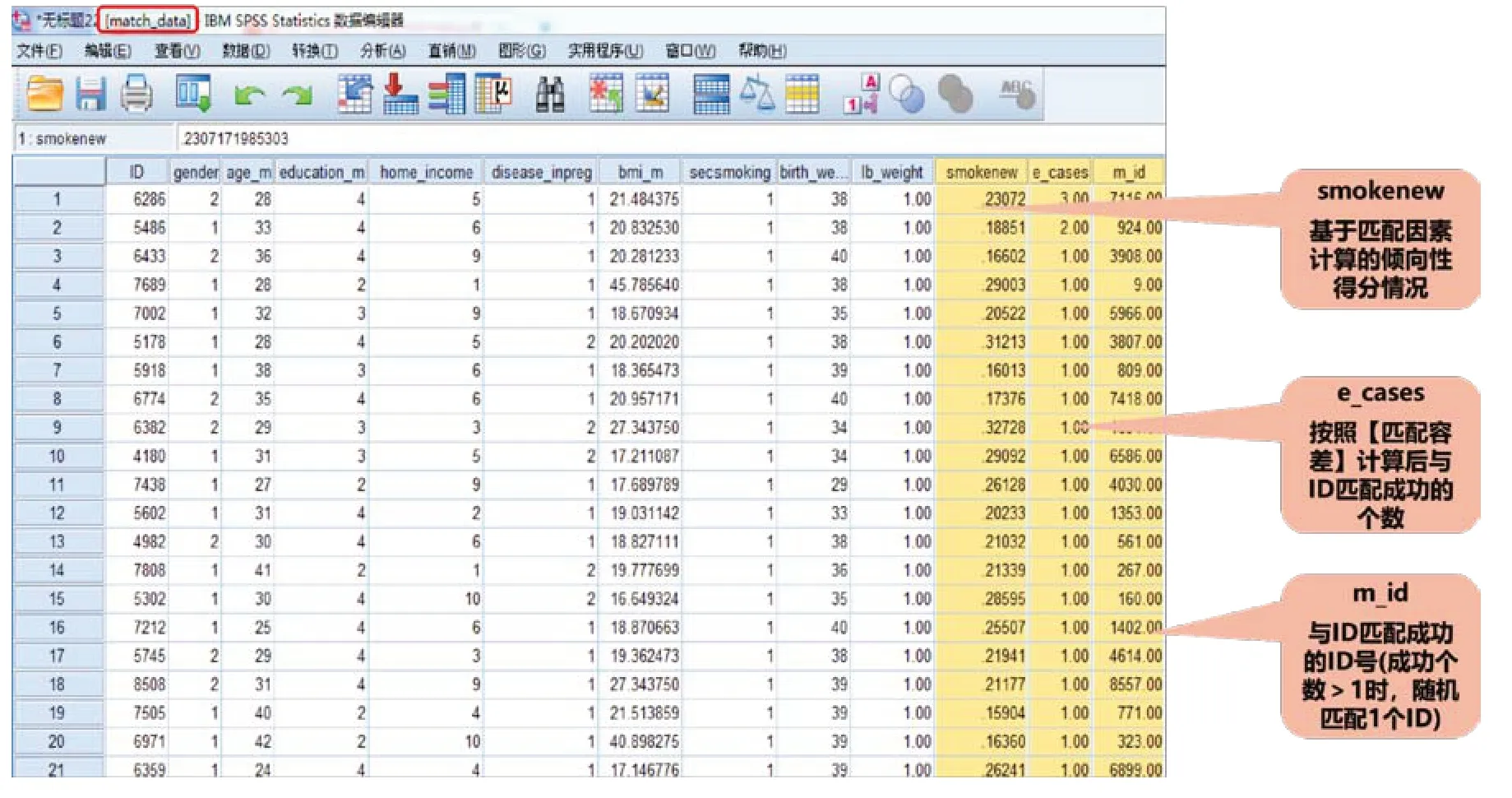
圖4 PSM分析后輸出的數據庫
如圖5 所示,經PSM 分析后,共計成功匹配1 785對個案。其中,依據前面設定的匹配容差完成“完全匹配”的有1 對,“模糊匹配”的有1 784 對。須特別指出的是,研究者在開展PSM 分析時,須對“匹配容差”進行調整測試,在保證匹配成功對數的情況下,盡可能選擇“完全匹配”占比較高的數據庫納入最后的統計分析。
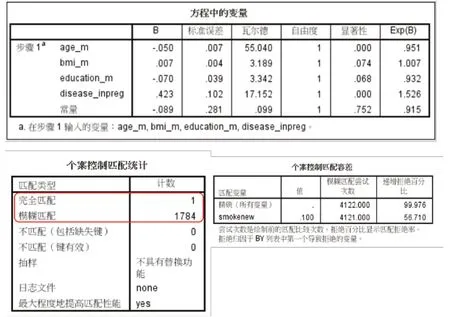
圖5 PSM分析結果
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:24
財經(2017年2期)2017-03-10 14:35:35
山東工業技術(2016年15期)2016-12-01 05:31:22
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
