基于局部特征位置編碼的小樣本分類網(wǎng)絡(luò)
2022-08-01 04:00:40劉成君譚守標(biāo)唐志偉
現(xiàn)代計(jì)算機(jī) 2022年11期
劉成君,譚守標(biāo),唐志偉,樊 進(jìn)
(1.安徽大學(xué),合肥 230039;2.中國(guó)科學(xué)技術(shù)大學(xué),合肥 230026)
關(guān)鍵字:小樣本;分類;位置編碼;注意力
0 引言
近年來深度學(xué)習(xí)在計(jì)算機(jī)視覺的諸多領(lǐng)域取得了巨大的進(jìn)步,一方面得益于科技的發(fā)展使得計(jì)算能力變強(qiáng),另一方面則是由于大數(shù)據(jù)的驅(qū)動(dòng)。但是在計(jì)算機(jī)視覺的某些領(lǐng)域,數(shù)據(jù)的獲取和標(biāo)注是十分困難的,例如醫(yī)學(xué)影像分割,瀕危動(dòng)物分類等任務(wù)。人類能夠在僅有幾張圖片作為依據(jù)的情況下完成對(duì)新樣本的識(shí)別任務(wù),受到這一行為的啟發(fā),人們提出了小樣本學(xué)習(xí)的概念,即在給定大量與目的任務(wù)無關(guān)的數(shù)據(jù)中學(xué)習(xí)一個(gè)分類器,使得該分類器在面對(duì)新的任務(wù)時(shí),也能夠有很好的表現(xiàn)。
為了解決這個(gè)問題,大量基于度量學(xué)習(xí)的方法被提了出來。這些方法通常是使用一個(gè)映射函數(shù)將輸入圖片映射到特征空間生成其特征表示,再使用合適的度量函數(shù)預(yù)測(cè)其類別。映射函數(shù)通常采用卷積神經(jīng)網(wǎng)絡(luò),提取圖片特征之后經(jīng)過全局池化得到特征向量。但是該方法將特征信息直接壓縮成一個(gè)緊湊的圖片級(jí)別的表示,往往會(huì)丟失許多判別信息。這些信息在新的類別上可能至關(guān)重要,而且這個(gè)過程往往是不可逆的。一個(gè)直接的方法是取消池化層,生成一個(gè)稀疏的特征表示,之后再使用度量函數(shù)對(duì)其分類。這些方法在計(jì)算距離的時(shí)候,通常都是兩張圖片對(duì)應(yīng)的位置直接計(jì)算距離,并未考慮二者之間局部區(qū)域的語義信息是否相同或者是否具有可比較性。如圖1 所示,位置相同的區(qū)域所表達(dá)的信息可能是不同的,甚至是截然相反的,直接計(jì)算可能會(huì)導(dǎo)致原本類別相同的兩張圖片在特征空間中的距離很遠(yuǎn)。

圖1 位置相同處的特征之間表達(dá)的信息可能不同
針對(duì)上述問題,本文提出了一種基于局部特征描述的位置編碼模塊,該模塊以卷積神經(jīng)網(wǎng)絡(luò)提取的三維特征圖作為輸入,能夠?qū)⒃揪哂泄潭臻g結(jié)構(gòu)的特征表示重新編碼,使得新生成的特征表示在相同位置處具有相同的語義信息,在最后度量?jī)蓮垐D片的距離時(shí),能夠使具有相同語義的區(qū)域之間相互比較,不至于造成特征信息之間的混亂。
為了更好地突出具有判別性的局部特征,我們提出了一種空間注意力機(jī)制,用于處理送入位置編碼模塊的特征圖。該注意力模塊將卷積神經(jīng)網(wǎng)絡(luò)提取的特征作為輸入,通過卷積操作融合周圍位置的特征,輸出每個(gè)位置的重要程度,再通過殘差的方法添加到原本的特征圖中,使得具有判別性的區(qū)域得以加強(qiáng),能夠更好地幫助位置編碼模塊完成分類任務(wù)。
為了驗(yàn)證本文方法的有效性,我們分別在miniImagenet 和CUB-200-2011 上進(jìn)行了實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果表明該方法有效地提高了小樣本分類的準(zhǔn)確度。本文的主要貢獻(xiàn)有以下三點(diǎn):①創(chuàng)新性地提出了一種可學(xué)習(xí)位置編碼模塊,能夠有效地完成位置映射,避免最終度量時(shí)可能會(huì)出現(xiàn)的語義混亂的問題;②將位置注意力與小樣本學(xué)習(xí)相結(jié)合,突出具有判別行的區(qū)域,有效地提高了分類精度;③提出了一種全新的基于局部特征分類的方法。
1 本文方法
1.1 問題描述
不同于傳統(tǒng)的分類方法,小樣本分類任務(wù)通常在訓(xùn)練集中生成一系列的任務(wù)對(duì)模型進(jìn)行更新。每個(gè)任務(wù)包含兩部分,分別是類別標(biāo)簽已知的支持集和類別標(biāo)簽未知的查詢集,即:=( ),,且和是互斥的。其中支持集包含了個(gè)類別,每個(gè)類別有個(gè)樣本,即N-way K-shot 方法。同樣地,查詢集也包含了個(gè)類別,每個(gè)類別包含了個(gè)樣本。支持集和查詢集分別表示為:
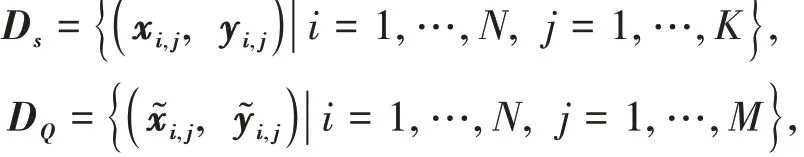
1.2 網(wǎng)絡(luò)結(jié)構(gòu)
本文方法大致整體結(jié)構(gòu)如圖2所示,共可以分成四個(gè)模塊:①特征提取網(wǎng)絡(luò)負(fù)責(zé)將樣本從輸入空間映射到特征空間,生成輸入圖片在特征空間的特征表示;②空間注意力模塊利用特征間的空間關(guān)系生成各個(gè)局部特征的權(quán)重,突出具有判別性的區(qū)域;③位置編碼模塊用于重新排列各個(gè)區(qū)域,由于梯度下降算法會(huì)使損失最小化,所以隨著訓(xùn)練的進(jìn)行,同類別的樣本會(huì)被映射成相同的空間分布;④分類器模塊則用于為查詢集中的樣本分配合適的類別標(biāo)簽。
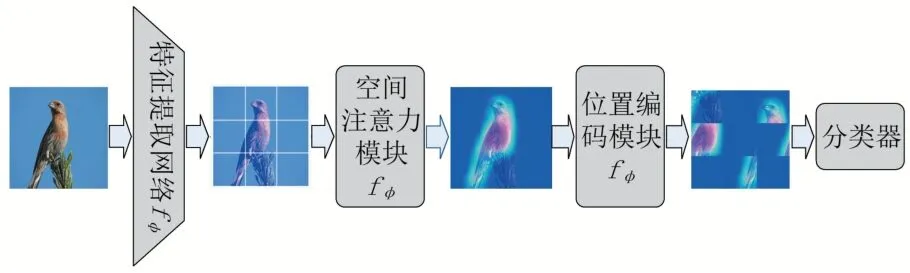
圖2 網(wǎng)絡(luò)結(jié)構(gòu)圖
1.3 特征提取網(wǎng)絡(luò)
理論上特征提取網(wǎng)絡(luò)可以是任意的,但是由于小樣本分類任務(wù)中的訓(xùn)練樣本有限,網(wǎng)絡(luò)過于復(fù)雜會(huì)導(dǎo)致過擬合。本文使用的是傳統(tǒng)的Conv-64F 網(wǎng)絡(luò),該網(wǎng)絡(luò)包含了4 個(gè)輸出通道為64 的卷積模塊,每個(gè)卷積模塊包含了卷積層、批歸一化層和ReLU 激活層,并且在每個(gè)卷積模塊之后連接2 × 2 的最大值池化層對(duì)特征圖進(jìn)行降采樣。與其他方法不同的是,本文的Conv-64F 網(wǎng)絡(luò)移除了最后的全局池化層,生成的是一個(gè)三維的特征f( )∈R ,其中f表示特征提取網(wǎng)絡(luò),、、分別表示特征圖的維度、高度和寬度。
1.4 空間注意力模塊
分類任務(wù)的本質(zhì)是提取具有判別性的特征,抑制無關(guān)信息。不同于其他的分類任務(wù),小樣本分類任務(wù)中訓(xùn)練集和測(cè)試集的樣本空間是不相交的,所以二者樣本之間的差異性更大,在訓(xùn)練過程中所抑制的信息對(duì)于測(cè)試樣本而言可能是十分重要的,過于強(qiáng)調(diào)已知樣本上的信息可能會(huì)導(dǎo)致過擬合。基于上述的考慮,本文所使用的注意力模塊不同于傳統(tǒng)的方法,并不是在卷積的過程中使用注意力機(jī)制加強(qiáng)具有判別性的區(qū)域,而是在卷積網(wǎng)絡(luò)提取特征之后強(qiáng)化局部特征。同時(shí),這種方法所引入的參數(shù)也更少。方法如圖3所示。
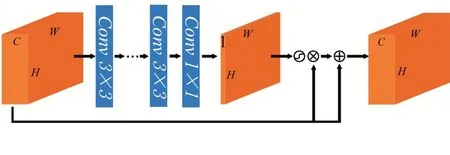
圖3 空間注意力模塊結(jié)構(gòu)圖
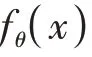
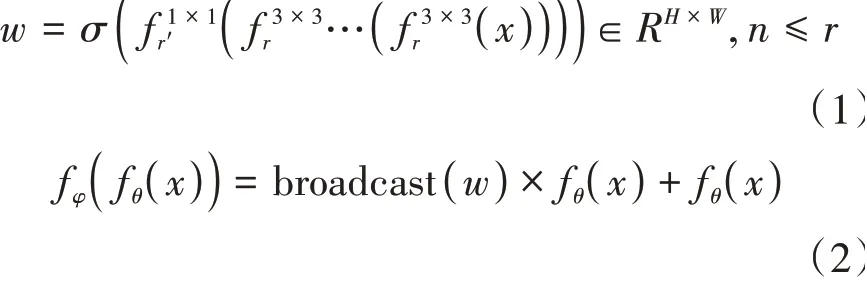
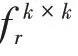
1.5 位置編碼模塊
在度量?jī)蓮垐D片級(jí)特征時(shí),傳統(tǒng)的方法通常是直接計(jì)算兩張圖像相對(duì)應(yīng)的位置的局部特征之間的距離,這樣可能會(huì)造成語義信息完全不同的區(qū)域進(jìn)行比較。Li 等提出的DN4 直接度量每張圖片局部特征之間的距離,并通過比個(gè)最相似的區(qū)域來為查詢集樣本分配類別,該方法雖在一定程度上解決了語義混亂的問題,但是引入了大量的計(jì)算量。Tang 等曾在CUB數(shù)據(jù)集上利用姿態(tài)估計(jì)進(jìn)行語義對(duì)齊并取得了一定的成果,但是現(xiàn)實(shí)中大部分?jǐn)?shù)據(jù)并沒有現(xiàn)成的姿態(tài)信息可以使用,所以該方法并不具有普適性。由于無法事先知道特征所處的位置,所以我們?cè)O(shè)計(jì)了一種自動(dòng)對(duì)齊語義信息的方案,通過可學(xué)習(xí)的參數(shù)自動(dòng)對(duì)齊局部特征,如圖4所示。
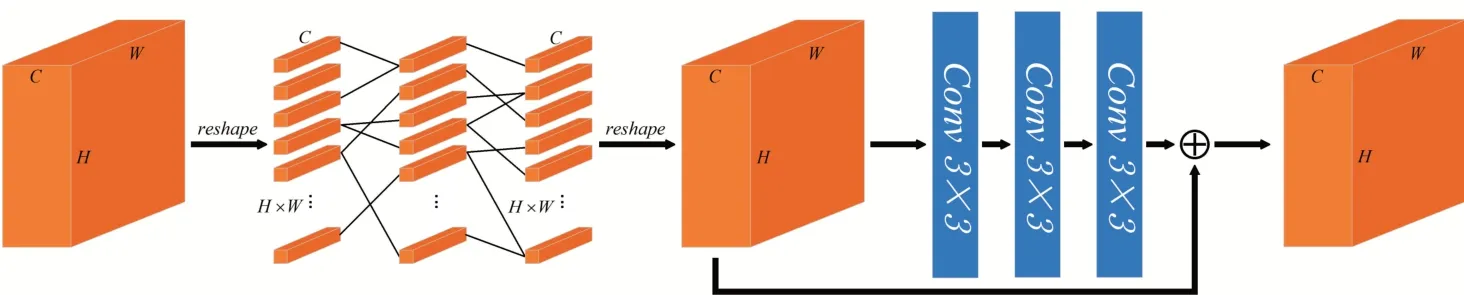
圖4 位置編碼模塊結(jié)構(gòu)圖

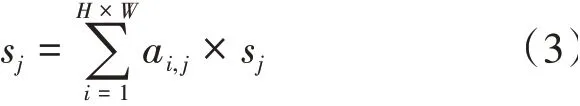
將×個(gè)一維向量s重新組成新的三維特征圖',即可獲得對(duì)齊之后的特征,上述過程可以描述為:
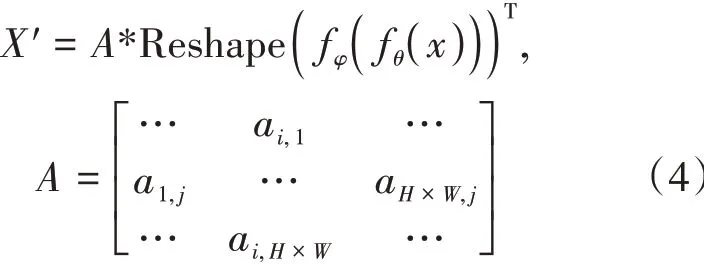
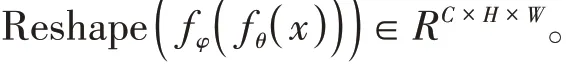
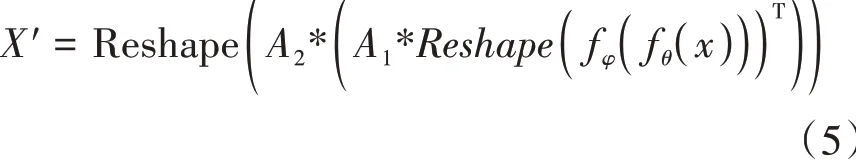
將對(duì)齊的特征通過卷積層進(jìn)行調(diào)整,最終得到位置編碼之后的特征圖:
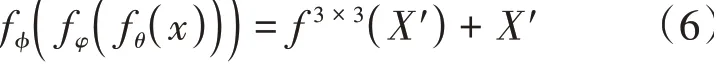
其中f表示位置編碼模塊。
由于初始的位置編碼模塊的參數(shù)是隨機(jī)生成的,編碼后的位置具有不確定性,但是由于損失函數(shù)的約束和梯度下降算法的原理,在經(jīng)過一系列的任務(wù)訓(xùn)練之后,為了使損失達(dá)到最小,距離相近的模塊會(huì)被映射到相同的區(qū)域,即特征圖在經(jīng)過位置編碼模塊之后,能夠使得具有相同語義特征的區(qū)域相互比較。
1.6 分類器
為了能夠更好地約束位置編碼模塊中的參數(shù),度量函數(shù)和損失函數(shù)的選擇至關(guān)重要,本文分別嘗試了歐氏距離加交叉熵?fù)p失,余弦距離加交叉熵?fù)p失和KL 散度損失,使用本文方法在miniImagenet 數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),最終選擇了歐式距離加交叉熵?fù)p失作為損失函數(shù)(實(shí)驗(yàn)結(jié)果見表1)。具體方式如下:
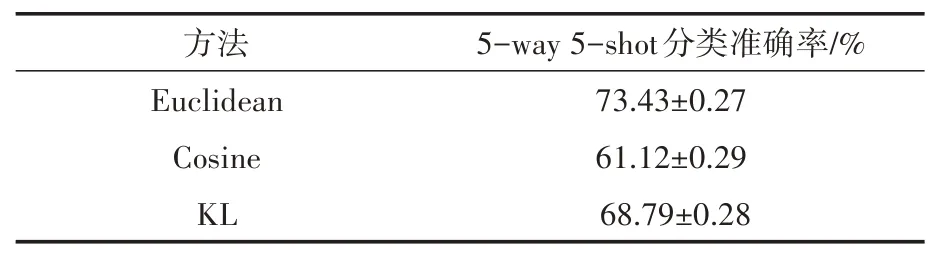
表1 不同損失函數(shù)對(duì)實(shí)驗(yàn)結(jié)果的影響
在經(jīng)過Flatten 函數(shù)之后類別的第個(gè)樣本在特征空間的表示u∈R,且不同樣本之間一維向量在相同位置處的語義信息是相同的。同大多數(shù)方法相同,將類別的所有樣本的特征向量求均值作為該類別的類別中心c:
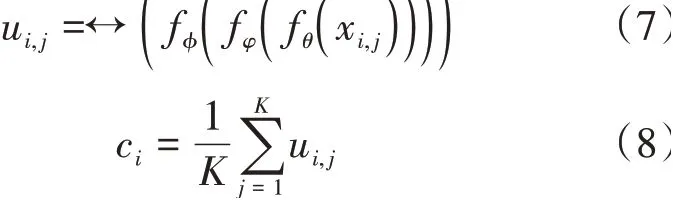
對(duì)于查詢樣本?的特征表示?,根據(jù)預(yù)先設(shè)定的度量函數(shù)(本文采用歐式距離)可以得到其類別標(biāo)簽?為:
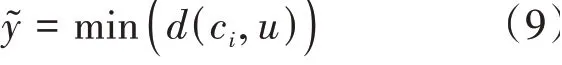
2 實(shí)驗(yàn)結(jié)果與分析
2.1 實(shí)驗(yàn)細(xì)節(jié)
本文實(shí)驗(yàn)均是在Ubuntu18.04 操作系統(tǒng)上基于PyTorch 框架完成。在訓(xùn)練集上隨機(jī)生成200000 個(gè)任務(wù)對(duì)模型進(jìn)行迭代,間隔2000 個(gè)任務(wù)對(duì)模型進(jìn)行測(cè)試,在600個(gè)任務(wù)取得準(zhǔn)確率的平均值作為測(cè)試的準(zhǔn)確率。在訓(xùn)練過程中,使用SGD 作為優(yōu)化器,設(shè)置初始學(xué)習(xí)率為0.1,當(dāng)準(zhǔn)確率不再上升時(shí)學(xué)習(xí)率衰減為原來的0.1。送入模型的圖像大小均為84×84,訓(xùn)練時(shí)對(duì)樣本隨機(jī)進(jìn)行顏色增強(qiáng)和翻轉(zhuǎn),測(cè)試時(shí)不做處理。
2.2 在miniImagenet數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果
作為Imagenet 的子集,miniImagenet包含了100 個(gè)類別,每個(gè)類別包含了600 張84 × 84的圖片,共60000張圖片。其中用作訓(xùn)練、驗(yàn)證和測(cè)試的類別數(shù)目分別為64,16,20。本文在設(shè)定每個(gè)類別查詢樣本= 15 的基礎(chǔ)上,分別從5-way 5-shot 和5-way 1-shot 兩種實(shí)驗(yàn)設(shè)定與其他方法進(jìn)行比較,實(shí)驗(yàn)結(jié)果見表2。
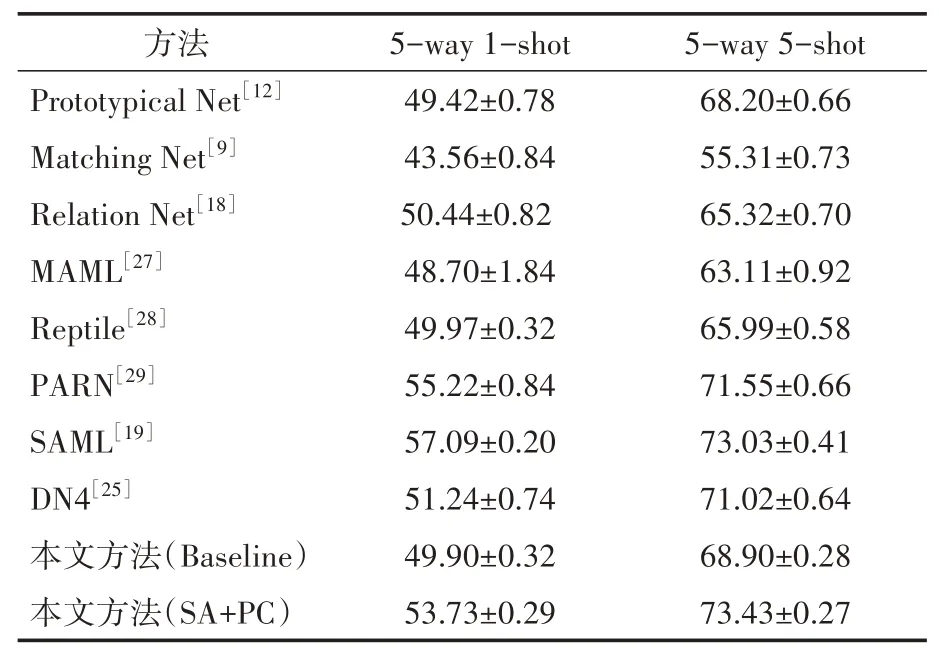
表2 miniImagenet數(shù)據(jù)集上小樣本分類準(zhǔn)確度/%
其中Baseline 是本文復(fù)現(xiàn)的結(jié)果,表示特征提取網(wǎng)絡(luò)提取特征之后直接送入分類器所得到的準(zhǔn)確度,SA+PC 表示在Baseline 的基礎(chǔ)上加入空間注意力模塊和位置編碼模塊的結(jié)果。可以看到本文中的方法相較于原型網(wǎng)絡(luò)和匹配網(wǎng)絡(luò)等方法在兩種不同的實(shí)驗(yàn)設(shè)定上準(zhǔn)確度均有大幅提升,說明文中的空間注意力模塊能夠有效地加強(qiáng)局部區(qū)域特征,位置編碼模塊能夠有效地對(duì)齊具有相同語義信息的區(qū)域。
2.3 在CUB-200-2011數(shù)據(jù)集上的實(shí)驗(yàn)
CUB-200-2011是Wah等針對(duì)細(xì)粒度分類提出的數(shù)據(jù)集,常用于小樣本分類任務(wù)。該數(shù)據(jù)集共包含了11788 張圖片,200 個(gè)類別。通常隨機(jī)選取100 個(gè)類別作為訓(xùn)練集,50 個(gè)類別作為驗(yàn)證集,50 個(gè)類別作為測(cè)試集。本文在設(shè)定每個(gè)類別查詢樣本= 15 的基礎(chǔ)上,分別從5-way 5-shot 和5-way 1-shot 兩種實(shí)驗(yàn)設(shè)定與其他方法進(jìn)行比較,實(shí)驗(yàn)結(jié)果見表3。
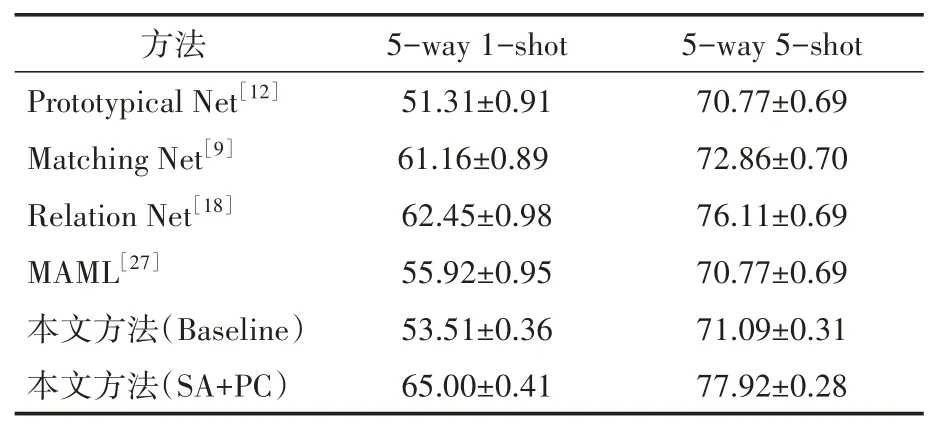
表3 CUB-200-2011數(shù)據(jù)集上小樣本分類準(zhǔn)確度/%
分析表格可知,在細(xì)粒度方面相較于傳統(tǒng)方法,無論是5-way 5-shot 還是5-way 1-shot 的實(shí)驗(yàn)設(shè)置上,準(zhǔn)確度都有大幅的提升。實(shí)驗(yàn)結(jié)果表明,本文提出的方法能夠較好地提升小樣本學(xué)習(xí)的分類準(zhǔn)確度。
2.4 消融實(shí)驗(yàn)
為了探究文中各個(gè)模塊的作用,本文在保證其他條件與基礎(chǔ)實(shí)驗(yàn)相同的情況下,依次添加文中的模塊,并在miniImagenet 上進(jìn)行對(duì)比實(shí)驗(yàn),結(jié)果如表4 所示。其中Baseline 為卷積網(wǎng)絡(luò)(無池化層)提取特征之后直接使用度量函數(shù)分類結(jié)果。SA 為僅加入空間注意力模塊的結(jié)果,PC 為僅加入位置編碼模塊的結(jié)果,SA+PC 是組合了空間注意力和位置編碼模塊并加入網(wǎng)絡(luò)的結(jié)果。
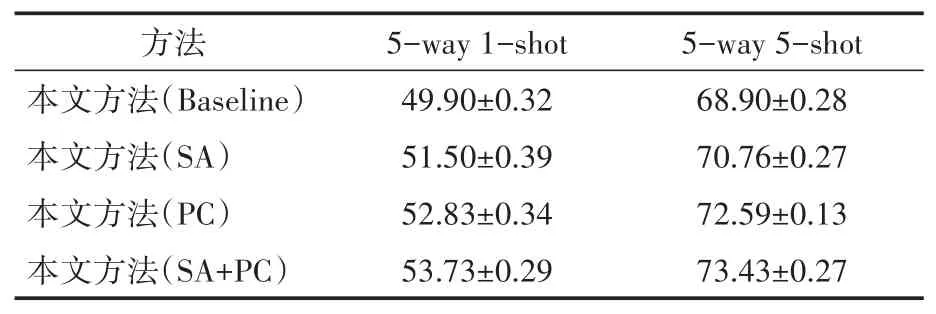
表4 在miniImagenet上添加不同模塊的分類準(zhǔn)確度/%
分析表4 可知,加入空間注意力模塊之后,網(wǎng)絡(luò)能夠加強(qiáng)具有判別性的局部區(qū)域特征,更好地完成分類。加入位置編碼模塊之后,在兩種實(shí)驗(yàn)設(shè)定上的分類結(jié)果均有大幅提升,可以說明在經(jīng)過位置編碼之后能夠使得具有相同語義信息的區(qū)域之間進(jìn)行比較,更好地完成分類。而在結(jié)合兩個(gè)模塊之后,在5-way 5-shot的實(shí)驗(yàn)設(shè)定上準(zhǔn)確率更是提高了4.43%,充分證明文中方法能夠更好地完成小樣本分類。
在位置編碼模塊中,為了更好地進(jìn)行位置編碼,我們引入了超參數(shù)n來確定對(duì)原始特征圖進(jìn)行位置映射的次數(shù),為了探究超參數(shù)n 的影響,我們?cè)诒WC其他條件相同的情況下,僅改變n 的大小在5-way 5-shot 的設(shè)定下進(jìn)行實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果如表5所示。

表5 在miniImagenet上不同位置映射次數(shù)的分類準(zhǔn)確度/%
可以看到,在加入了位置編碼模塊的兩組對(duì)照實(shí)驗(yàn)中,適當(dāng)?shù)脑黾游恢糜成涞拇螖?shù)可以有效地對(duì)齊具有相同語義信息的區(qū)域,但是映射次數(shù)過大反而會(huì)導(dǎo)致準(zhǔn)確率下降,其原因可能是由于網(wǎng)絡(luò)過于復(fù)雜引起過擬合現(xiàn)象所致。
3 結(jié)語
本文針對(duì)在小樣本分類任務(wù)中直接計(jì)算圖片級(jí)特征可能會(huì)出現(xiàn)的不同語義信息之間相互比較的問題,提出了一種基于局部信息的位置編碼網(wǎng)絡(luò)。不同于之前的方法,本文沒有復(fù)雜的計(jì)算模塊,創(chuàng)新性地提出了一種可學(xué)習(xí)的模塊,并通過端到端的方法更新參數(shù)。該網(wǎng)絡(luò)在加強(qiáng)局部具有判別性的特征之后,對(duì)局部特征的位置進(jìn)行重新編碼,使得重新編碼后的特征圖在相同的位置處具有同樣的語義信息。最后在不同網(wǎng)絡(luò)和不同數(shù)據(jù)集上進(jìn)行對(duì)比實(shí)驗(yàn),結(jié)果表明,本方法能夠有效地對(duì)齊不同區(qū)域之間的特征,從而提升分類的準(zhǔn)確度。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
