深度網絡對比學習及其視頻理解應用研究綜述
2022-08-01 04:21:44胡正平劉文亞毛建增鄭智鑫
燕山大學學報 2022年4期
胡正平,劉文亞,毛建增,鄭智鑫,方 鑫
(1.燕山大學 信息科學與工程學院,河北 秦皇島 066004; 2.燕山大學 河北省信息傳輸與信號處理重點實驗室,河北 秦皇島 066004)
0 引言
由于深度神經網絡具有學習不同層次視覺特征的強大能力,其已成為計算機視覺(Computer Vision,CV)應用的基本結構,如目標檢測[1]、視頻動作識別[2]等。采用監督學習方法訓練神經網絡需要大規模的數據集,但數據集的收集和注釋費時且昂貴,例如用于深度卷積神經網絡訓練的ImageNet數據集中包含約130萬張標簽圖像,人工標記這些圖像需要花費大量的時間。用于訓練卷積神經網絡進行視頻動作識別的Kinetics數據集中包含50萬個視頻,且每個視頻持續時間約10 s,這需要花費更長的時間對數據集進行注釋。為避免耗時和昂貴的數據標注,無監督對比學習應運而生,無監督對比學習直接利用數據本身作為監督信息學習樣本數據的特征表達,然后應用于下游任務,深度學習巨頭Bengio和LeCun曾在 ICLR 2020上預測無監督對比學習是人工智能(Artificial Intelligence,AI)的未來。深度學習的本質為表示學習和歸納偏好學習。學好樣本的表示,在不涉及邏輯、推理等的問題上,AI系統都可取得好的效果,如涉及更高層的語義、組合邏輯,則需要設計一些過程來輔助AI系統去分解復雜的任務,因為歸納偏好的設計更多的是任務相關,所以需要精心設計。最近的很多研究工作都與表示學習相關,例如雙向編碼表征模型(Bidirectional Encoder Representation from Transformers,BERT)就是利用大規模的語料進行預訓練得到文本數據的好的表示。那么,CV領域的 BERT 是什么呢?答案就是對比學習。
無監督對比學習是一種鑒別模型,目的是將正樣本間的距離拉近,正樣本與負樣本距離拉遠,如圖1所示。對于計算機視覺任務而言,樣本由不同的視圖進行表示,原樣本的增強樣本為正樣本,而其他樣本為負樣本,通過對比學習對模型進行訓練,使其學會區分正樣本和負樣本,從而學習視頻表征,并轉移到下游任務。在沒有任何監督信號的情況下,通過獨立但相關的數據來學習的核心思想可追溯到1992年,Becker和Hinton[3]通過最大化同一場景的不同視圖之間的互信息來學習數據表征,并將問題表述為學習不變表示,而Bromley等人[4]將兩個相同的權值共享網絡構造成“Siamese網絡”,直接比較不同訓練樣本對來學習一般表示。2005年,Chopra、Hadsell和LeCun[5]創建對比學習框架和對比對損失的區別模型來學習不變映射。2008年,Chechik等人將三聯體損失應用于深度神經網絡,并證明其能夠學習有用的特征表示[6]。為解決三聯體損失收斂緩慢和不穩定的問題,Song等人[7]和Sohn[8]提出了使用多個負樣本的非參數化分類損失(N-pair 損失),N-pairs損失的核心思想是為每個錨配對一個正樣本,同時配對所有的負樣本,利用負樣本指導梯度更新。為降低原有概率方法學習度量嵌入的計算要求,Gutmann和Hyv?rinen[9]在2010年提出噪聲對比估計損失函數,該損失函數通過學習一個分類器,將數據樣本和噪聲樣本進行區分,并從模型中學習數據的特有屬性。2017年,文獻[10]討論了4種無監督預訓練任務及其組合方法,在多任務的訓練下學習更統一的表示。2018年,文獻[11]通過深度神經網絡編碼器的輸入和輸出之間的互信息最大化來進行無監督表示學習。文獻[12]提出動量對比方法,通過使用一個隊列來存儲和采樣負樣本的方法降低對GPU內存的要求。文獻[13]在已學習的表示上使用投影變換網絡來分離學習表征任務和優化分類目標。最近,文獻[14]基于局部聚合的方法使相似數據的數據特征靠近,差距較大的數據特征遠離,這類似于聚類的原理,從而提出聚類和實例判別對比學習相結合的思路。文獻[15]基于負樣本是否完全必要的假想提出一個不同的對比損失函數,以避免算法因附加的隱式約束而崩潰。
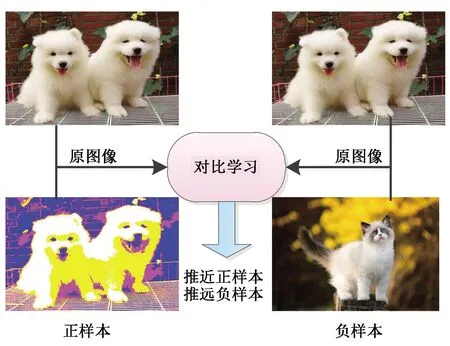
圖1 對比學習原理Fig.1 Principle of contrastive learning
1 預訓練任務
預訓練任務可以理解為是為達到特定訓練任務而設計的間接任務,其作用是簡化原任務的求解,在深度學習領域就是避免人工標記樣本,實現無監督的語義特征提取。兩種任務之間關系的本質是遷移學習,通過預訓練學到的模型直接用于特定的下游任務,從而避免從頭訓練,提高優化模型學習效率。從預訓練任務中學習到的特征表示模型能夠用于計算機視覺的相關下游任務,如視頻分類、分割、識別等。
1.1 多視圖數據關聯信息預訓練任務
在一些實際問題中,可以從多種不同的途徑或不同的角度對同一事物進行描述,這多種描述構成事物的多個視圖,多視圖數據具有潛在的一致性和互補性。可以使用多個傳感器獲得同一事物的多個視圖表示,例如文獻[16]就是通過提取來自同一場景的不同攝像機同時拍攝的兩個視圖進行對比學習。也可以通過不同的傳感器獲得同一視頻的不同模態的視圖表示,例如文獻[17]利用視覺數據和音頻文本數據學習視頻的特征表示。
1.2 數據增強預訓練任務
實際情況下,通過多個傳感器獲得多視圖視頻數據的方法費時且昂貴,這里可以利用已有的數據進行數據增強獲得數據的多個視圖表示。數據增強方法,如拼圖、裁剪、模糊、顏色變換等,是在保持數據內容語義含義(如類標簽)的同時獲得不同視圖表示的有效方法,如圖2所示。數據增強方法能夠破壞低級的視覺特征,迫使模型通過對比方法學習不變表示,例如文獻[18]就是采用數據增強方法學習圖像特征表示,該方法同樣適用于視頻數據,通過對視頻幀的增強處理獲得多視圖表示,從而進行視頻表征學習。

圖2 數據增強Fig.2 Data augmentation
1.3 全局和局部融合的預訓練任務
從數據樣本中提取出全局特征和局部特征也可以獲得相同場景的多個視圖表示,全局特征是指數據的整體特征,局部特征則是從數據局部區域中抽取的特征。在無監督對比學習中,同一視圖的局部特征與全局特征構成正樣本對,與其他視圖構成負樣本對。針對視頻數據而言,對比預測編碼模型的表征性能較好,其中全局特征是對過去輸入數據的總結,然后與來自未來數據的局部特征組成正樣本對,與噪聲樣本的局部特征組成負樣本對,通過改進的噪聲估計損失函數(Info Noise Contrastive Estimation loss,InfoNCE)學習視頻表征,原理框架如圖3所示。
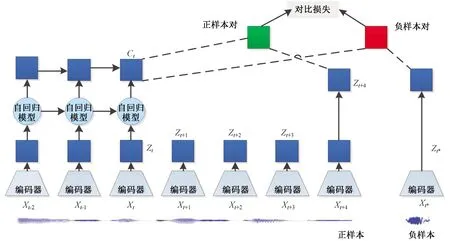
圖3 對比預測編碼模型Fig.3 Contrastive predictive coding model
1.4 時空一致性預訓練任務
在無監督對比方法中,除上述方法外,還可以利用空間和時間上的一致性來進行模型的預訓練, 該方法適用于可以分解為一系列更小單元的數據樣本,例如可以分解為一系列幀的視頻數據等,視頻序列中連續視點的視頻幀為正樣本對,同一序列或不同序列中的不連續的樣本對和相距較遠的樣本對均為負樣本對。這種對比方法在表征學習中使用了慢速假設,即重要特征是緩慢變化的。因此,通過學習視頻序列中緩慢變化的特征,模型將逐漸具有更強的特征表示能力。例如文獻[19]中的時間對比網絡使用多視圖同步視頻進行對比學習,而文獻[16]中的時間對比網絡則利用視頻序列中的時間相干性進行對比學習,如圖4所示,即同一時間窗口的視頻幀為正樣本對,其余為負樣本對,在三聯體損失函數的作用下學習視頻表征。視頻幀的時間一致性也是數據轉換的自然來源。在視頻中,一個物體可以經歷一系列的變化,如物體變形、遮擋、視角和光照的變化,這些變化在文獻[20]利用這些變化學習視頻中的特征表示,而不需要任何額外的標簽。

圖4 序列相干性Fig.4 Sequential coherence
1.5 自然聚類預訓練任務
聚類是將物理或抽象對象的集合分成由類似的對象組成的多個類的過程,其目標是同一類對象的相似度盡可能大,不同類對象之間的相似度盡可能小。自然聚類是指不同的對象與不同的類別變量能夠自然地聯系在一起,不同類間的距離表示類別之間的相似性。與基于實例的對比學習不同,這里使用聚類結果作為偽標簽進行特征表示。可以將自下而上的對比方法和自上而下的聚類方法相結合,這樣就能夠同時進行表示學習和聚類分析,例如文獻[21]提出將聚類任務統一到對比表示學習框架當中。
2 對比學習框架
本節首先梳理對比學習框架,利用框架描述視頻領域內的對比學習方法,然后對框架的每個組成部分及其分類進行說明,上節已經闡述獲取不同視圖的方法,此節不再額外敘述。
2.1 通用框架
對比學習框架的組成部分包括:查詢樣本、正樣本和負樣本,編碼器、投影變換網絡以及對比損失函數,框架如圖5所示。

圖5 對比學習框架Fig.5 Framework ofcontrastive learning
各模塊功能分別描述為: (1)正負樣本:k+表示正樣本,k-表示負樣本,查詢樣本的增強版本為正樣本,其余樣本為負樣本。(2)編碼器:特征編碼器用來提取輸入數據的特征,將輸入視圖映射為特征表示張量v。(3)投影變換:投影變換將特征表示v轉化為度量表示z。根據具體的應用,投影變換可分為降維投影、聚合投影和量化投影。4)對比損失函數:對比損失測量度量表示之間的相似度(或距離)并進行強制約束,使正樣本對之間的相似度最大(距離最小),負樣本對之間的相似度最小(距離最遠)。
2.2 編碼器分類
無監督對比學習中,從輸入數據空間到度量表示空間需要經過編碼器和投影變換兩部分,編碼器將輸入數據投影到特征表示空間,其目的是學習從輸入空間到特征表示空間的映射。根據架構的不同,編碼器可分為端到端編碼器、內存庫編碼器、動量編碼器和聚類編碼器。
2.2.1端到端編碼器
端到端架構是自然架構,如圖6(a)所示,查詢編碼器和鍵值編碼器直接使用對比損失函數反向傳播的梯度進行更新,查詢編碼器在原始樣本上訓練,鍵值編碼器在其增強版本及負樣本上訓練,使用相似度函數度量編碼器生成的特征與其他特征之間的相似性。文獻[13]提出端到端模型,并證實端到端的架構具有較低的復雜性,在大批次和更多迭代次數的情況下性能更好。Oord等人使用強大的自回歸模型以及對比損失來學習高維時間序列數據的特征表示。因為對比學習學到的表征質量常常依賴負樣本數量,所以端到端架構需要較大的GPU內存,這在大部分情況下難以滿足,例如文獻[22]指出:對于較大的批處理規模,該架構面臨著小批次優化問題,需要有效的優化方法。
2.2.2內存庫編碼器
為了避免較大的批處理規模對訓練、優化產生負面影響,一些研究者提出新的編碼器架構,如圖6(b)所示。內存庫包含數據集中每個樣本的特征表示,用該內存庫替代負樣本,每次訓練直接從內存庫中隨機抽樣,不進行反向傳播,這能夠避免增加訓練批次的尺寸。文獻[18]采用該架構的編碼器學習圖像視覺表示,其內存庫中包含用于對比學習的所有負樣本的移動平均表示,Wu等人[23]隨機抽取內存庫中的特征表示作為負樣本進行模型的訓練,并使用查詢編碼器得到的表示更新內存庫,以便后面迭代使用,該架構編碼器能避免冗余計算,但更新內存庫中的特征表示會導致很高的計算成本。
2.2.3動量編碼器
為了解決內存庫編碼器問題,動量對比學習(Momentum Contrast Learning,MoCo)方法使用動量編碼模塊代替內存庫,如圖6(c)所示。動量編碼器生成一個字典,該字典鍵由數據樣本動態定義,并被構建為一個隊列,當前小批次樣本進入隊列,舊的小批次樣本退出隊列。動量編碼器與查詢編碼器具有相同的參數,但動量編碼器不進行梯度更新,而是根據下式進行緩慢的更新:
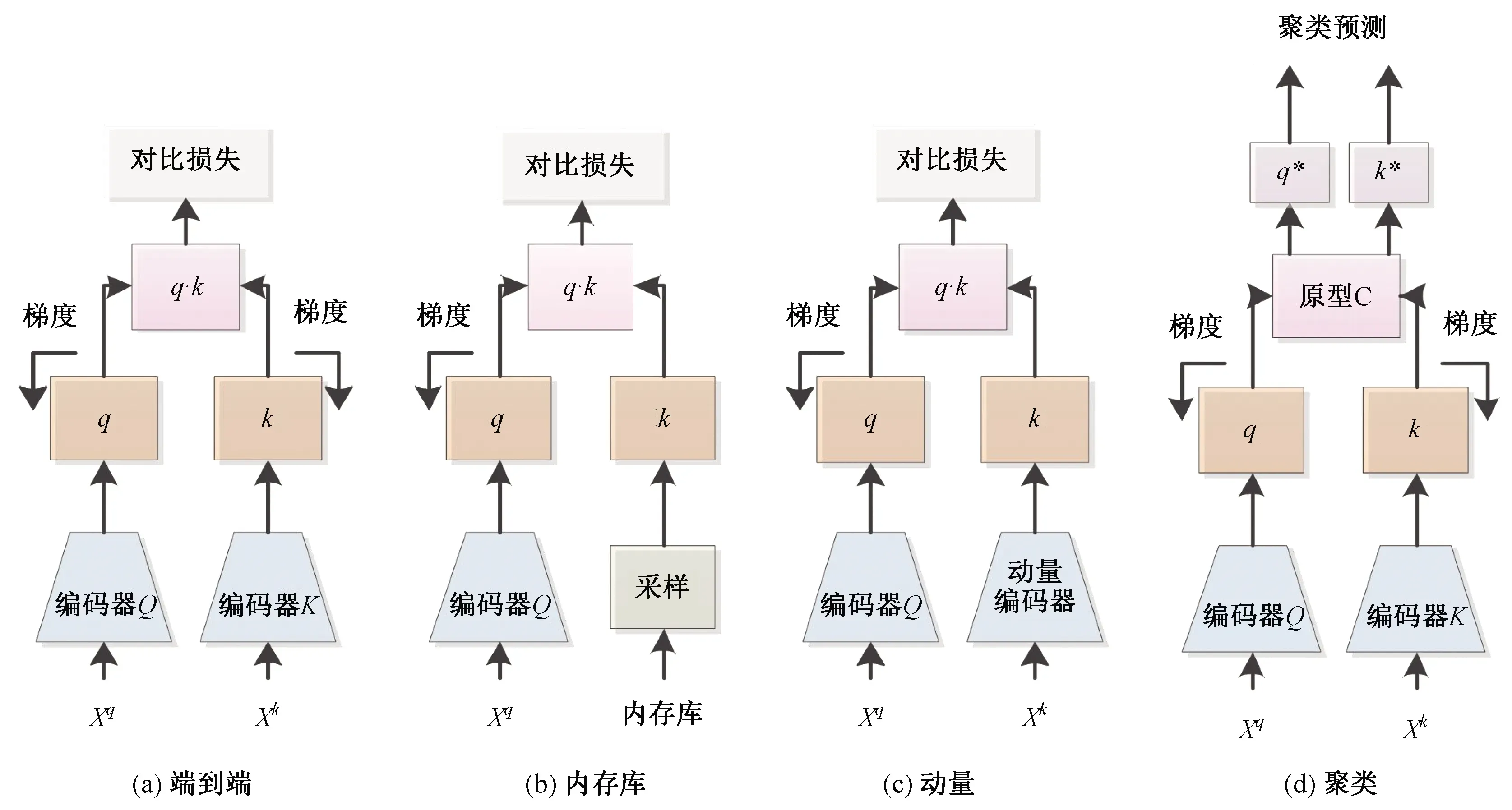
圖6 多種架構的編碼器Fig.6 Encoders with multiple architectures
θk=mθk+(1-m)θq,(1)
式中,m∈[0,1)為動量系數,參數θq通過反向傳播更新,參數θk通過動量更新。雖然該架構使用兩個編碼器,但是動量編碼器是根據查詢編碼器的參數進行緩慢更新的,兩個編碼器互相緩慢調整,與前兩種架構相比,該架構不需訓練兩個單獨的編碼器。
2.2.4聚類編碼器
以上的三種結構都是計算度量樣本之間的相似度,并通過對比損失函數使正樣本的距離拉近,負樣本的距離拉遠,從而使模型具有表征能力。聚類編碼器如圖6(d)所示,與上述三種結構不同,它不是基于實例對比,而是使用聚類算法將相似的特征分組在一起。圖7展示了基于實例的對比學習方法和基于聚類的方法之間的區別。基于實例的對比學習方法把數據集中的每個樣本都視為離散樣本,當負樣本與正樣本屬于同一類時,就會迫使模型學習區分屬于同一類的樣本,聚類編碼器能夠隱式地解決該問題。聚類的目標不僅是使一對樣本彼此接近,而且還要確保所有其他相似的樣本形成集群,因此能夠學習更好的表征。
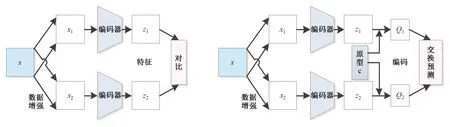
圖7 對比實例學習與聚類學習Fig.7 The based instance contrastive learning and clustering learning
2.3 投影變換
無監督對比學習中,從輸入數據到度量表示空間需要經過編碼器和投影變換兩部分,投影變換是將特征表示空間投影到度量空間,該度量空間能夠有效地計算和最大化相似性表示,投影變換分為三種類型,即降維投影、聚合投影和量化投影。
2.3.1降維投影變換
最常用投影變換為降維投影變換,目的是降低特征表示的維度,便于更高效的計算。降維投影變換可分為線性投影變換和非線性投影變換,例如文獻[24]使用一個線性的多層感知器(Multi-Layer Perceptron,MLP)作為投影變換部分,文獻[13]使用一個非線性的2層MLP作為編碼器后的投影變換部分。除了將查詢編碼器和鍵值編碼器的特征表示投影到度量空間外,還可用投影變換從一個度量空間投影到另一個度量空間,例如文獻[25]除了特征表示空間到度量空間的投影變換外,還使用一個額外的網絡將在線網絡的度量表示投影為離線編碼器的度量表示。
2.3.2聚合投影變換
降維投影變換能夠簡單地將特征表示向下投影到更低的維度,從而進行更高效的計算,但在某些情況下,需要將多個特征表示聚合為一個特征表示,這就需要聚合投影變換,例如對比預測編碼模型中,需要使用門控循環單元將過去輸入數據的信息聚合起來,與未來的局部信息形成正樣本,與噪聲樣本形成負樣本對,從而進行表征的學習。文獻[11]使用聚合投影變換將局部特征圖聚合為單個全局特征向量。類似地,在互信息的圖級表示中,基于對比學習的圖網絡需要聚合投影變換將部分表示歸納為一個固定長度的圖級表示。可見,聚合投影變換得到的度量表示具有多種信息,根據不同的下游任務,度量表示z具有不同作用。
2.3.3量化投影變換
聚合投影變換是將多個特征表示聚合為一個特征表示,而量化投影變換是將多個表示映射到同一表示來降低表示空間的復雜性,例如將連續音頻信號映射到一組離散的潛在向量中。在對比學習與聚類相結合的方法中,SwAV使用Sinkhorn-Knopp算法進行投影變換,將單樣本的特征表示映射到軟聚類分配向量中。
3 損失函數
對比損失用來計算度量表示之間的相似度(或距離),并強制約束正樣本對之間的相似度最大(距離最小),負樣本對之間的相似度最小(距離最遠)。對比損失函數通常可以分為一個度量函數和一個計算實際損失的函數,前者用來計算樣本對間的相似度或距離,后者對樣本間的距離進行約束。如果只將正樣本對之間的距離進行最小化,將會導致災難性的問題,為此對比損失函數需要明確地使用負樣本對或者其他假設和架構約束,例如文獻[15]中雖然沒有顯式地使用負樣本對,但是該文獻仍通過對比方法計算查詢樣本和正樣本之間的相似度。下面將討論不同類型的度量函數以及常見的對比損失函數。
3.1 度量函數
度量函數用來計算兩個度量表示之間的相似度或距離,計算距離的度量函數包括曼哈頓或歐氏距離(也稱為L1和L2范數距離)。常使用的相似性度量函數為余弦相似度函數,例如文獻[13]中提出的NT-Xent損失函數。另一種相似性度量函數為雙線性模型S(q,k)=qTAk,矩陣A是從q的子空間到k的子空間的線性投影,然后再進行點積運算,原始的InfoNCE損失使用這種雙線性模型作為度量函數。
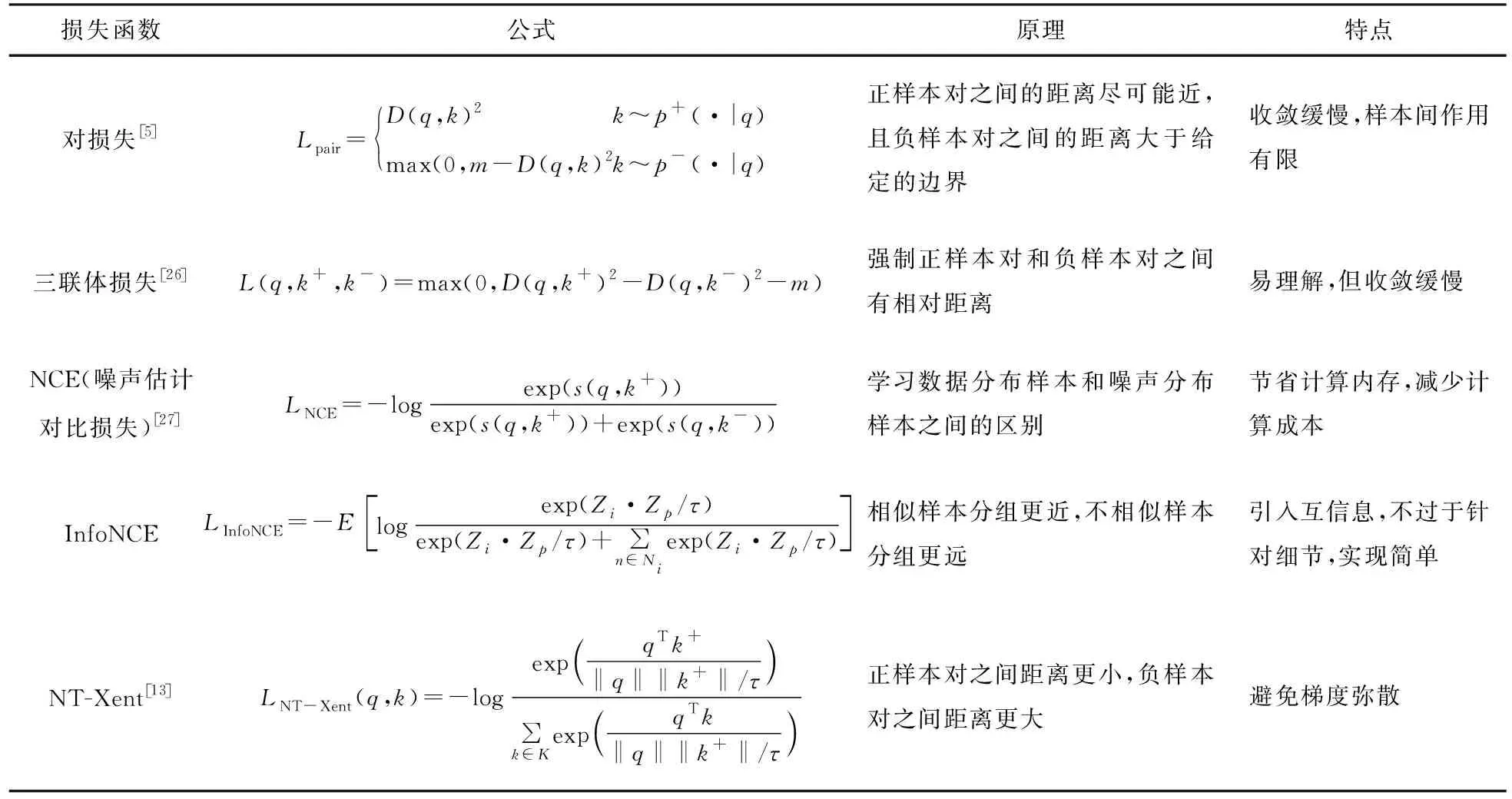
表1 對比損失函數Tab.1 Contrast loss function
3.2 對比損失函數
在能量模型啟發下,Chopra、Hadsell和LeCun[5]重新表述原始“對比損失”。對比損失函數使用歐幾里得距離D(q,k)=‖q-k‖2作為度量空間的度量函數,其核心思想是使正樣本對之間的距離盡可能近,且負樣本對之間的距離大于給定的邊界,描述如下:
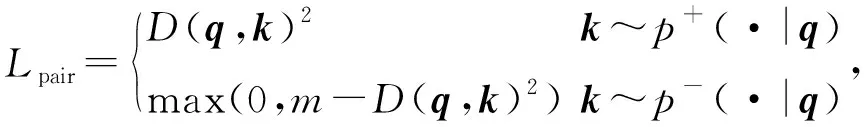
(2)
其中,邊界m(m>0)控制查詢范圍,將該范圍內負樣本k-推離查詢樣本q,該對比損失函數易理解、易操作,但只作用于一對樣本,樣本之間的相互作用有限。
3.3 三聯體損失函數
上述對比損失函數只要求負樣本對的距離大于一個固定的邊界,三聯體損失[26]函數在原損失函數的基礎上進行改進,強制在(查詢樣本,正樣本,負樣本)三聯體中給定正樣本對和負樣本對之間的相對距離:
L(q,k+,k-)=max(0,D(q,k+)2-
D(q,k-)2-m)。(3)
三聯體損失函數廣泛應用于對比學習,但三聯體損失函數收斂緩慢且只計算一個正樣本對和一個負樣本對之間的距離,文獻[7]改進三聯體損失函數的邊界公式,使其能夠增加查詢的交互次數,同時考慮多個樣本對。
3.4 噪聲對比估計損失函數
噪聲對比估計損失函數(Noise Contrastive Estimation,NCE)由文獻[9]提出,后來由Jozefowicz等人[27]加以改進,NCE核心思想是通過學習數據分布樣本和噪聲分布樣本之間的區別,從而發現數據中的特性,因為該方法需要與噪聲數據進行對比,所以稱為“噪聲對比估計”。更具體來說,NCE 將問題轉換成為二分類問題,分類器能夠區分數據樣本和噪聲樣本,其形式為

(4)
其中,q表示查詢樣本,k+代表正樣本,k-代表負樣本,s()函數是度量函數,但通常是余弦相似度函數。
3.5 InfoNCE損失函數
InfoNCE損失函數在NCE的基礎上進行改進,能夠更精準的區分正負樣本,Oord,Li和Vinyals證明了最小化InfoNCE損失等同于最大化互信息的下界。設有數據增強函數φ(·;a),其中a從一組預定義的數據增強變換A中進行選取,該函數應用于數據集D,對于特定的樣本xi,正樣本對Pi和負樣本對Ni定義如下:
Pi={φ(xi;a)|a∈A},
Ni={φ(xn;a)|?n≠i,a∈A},
當給定Zi=f(φ(xi;·))時,InfoNCE損失函數為
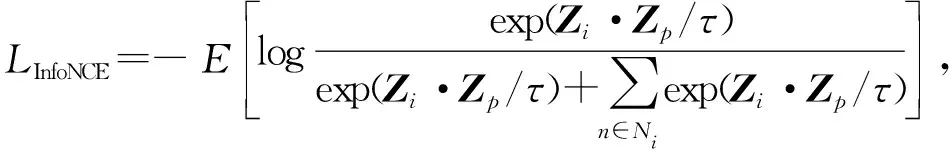
(5)
Zi·Zp表示兩個向量之間的點積,從本質上講,優化的目標可以被視為實例區分,即在同一實例的增強視圖之間的相似性得分更高。
3.6 NT-Xent損失函數
文獻[13]提出歸一化溫度交叉熵(NT-Xent)損失,其使用余弦相似度作為度量函數,隨機抽取N個樣本作為模型的輸入,并在其增強版本上求解預訓練任務,該損失函數沒有顯式使用負樣本,其描述為
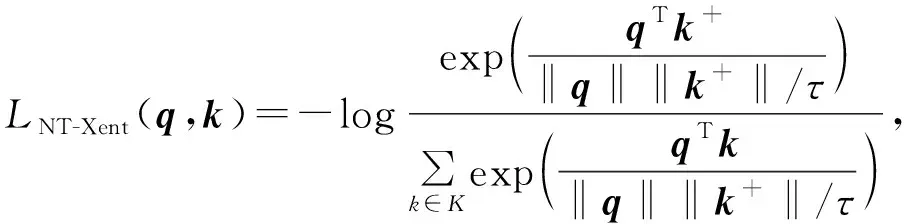
(6)
其中,q表示查詢樣本,k+代表正樣本。τ是最近大多數方法中使用的超參數,稱為溫度系數,作用是調節對數據樣本的關注程度,從而得到更均勻的表示。
4 評估表征質量的下游任務及性能分析
為評估學習到的視頻表征質量,可將預訓練任務學習的模型用于下游任務,如動作識別、最近鄰檢測等,此過程為遷移學習,即將已訓練好的模型參數遷移到新的模型來幫助新模型訓練,在無監督對比學習中,將預訓練任務中的編碼器直接用于下游任務中,新模型訓練完成后直接用于測試視頻表征的質量。
4.1 定性可視化
可通過定性可視化方法來評價對比學習特征的質量,常用的有核可視化、特征可視化等。核可視化指的是定性的可視化預訓練任務學習的第一個卷積層的核,然后通過比較監督模型和無監督對比模型卷積核的相似度驗證對比學習方法的有效性。特征可視化是通過比較監督模型和無監督對比學習模型不同區域的激活程度來評估表征的質量,激活區域示例如圖8所示。

圖8 監督模型與無監督對比學習模型的激活區域Fig.8 The activation regions of supervised model and unsupervised contrastive learning model
4.2 動作分類
視頻動作分類是常見的下游任務,該任務用來識別人們在視頻中所做的動作,并對其進行分類,動作分類任務通常被用來評價視頻表征的質量。首先通過預訓練任務對無標記視頻數據進行訓練,然后在帶有人類注釋的視頻數據集上進行建模,最后將動作分類任務的測試結果與其他方法進行比較。表2給出現有視頻特征對比學習方法在Kinetics、UCF101和HMDB51數據集上的性能。其中R3D表示3D-ResNet,?表示該模型已經在另一個數據集上進行了訓練,并使用特定的數據集進行了進一步的微調,K表示Kinetics數據集。
表2中展示了監督學習和無監督對比學習在視頻動作分類中的top1準確率。當僅考慮已進行模型微調的情況時,SeCo intra+intra+order[37]在UCF101數據集上的準確率優于監督學習在UCF101數據集上的準確率(88.26?% vs 84.4?%),在HMDB51數據集上的準確率與監督學習基本持平。當同時考慮兩種情況(未進行微調和已進行微調)時,無監督對比學習的top1準確率逐漸接近監督學習的top1準確率,甚至超過監督學習,SeCo intra+intra+order[37]在UCF101數據集上的top1準確率(88.26?%)高于3DResNet-18和P3D在UCF101上的top1準確率(84.4?%),MMV-VA[38]在UCF101數據集上的top1準確率為86.2%,該數據沒有在特定的數據集上進行微調,但仍優于已微調的監督學習的top1準確率。HMDB51數據集更適合進行目標檢測等任務,當用于視頻動作分類時,相比于UCF101數據集,其性能略差,由表2中可得監督學習在HMDB51數據集上的top1準確率為56.4?%,SeCo intra+intra+order[37]在HMDB51上的top1準確率與監督學習基本持平,MMV-VA[38]未進行微調的準確度仍高于已進行微調的3DResNet-18。CVRL[35]在Kinetics數據集上的性能也有一定的提升。由此可看出,無監督對比學習在一定程度上優于監督學習,具有良好的性能。
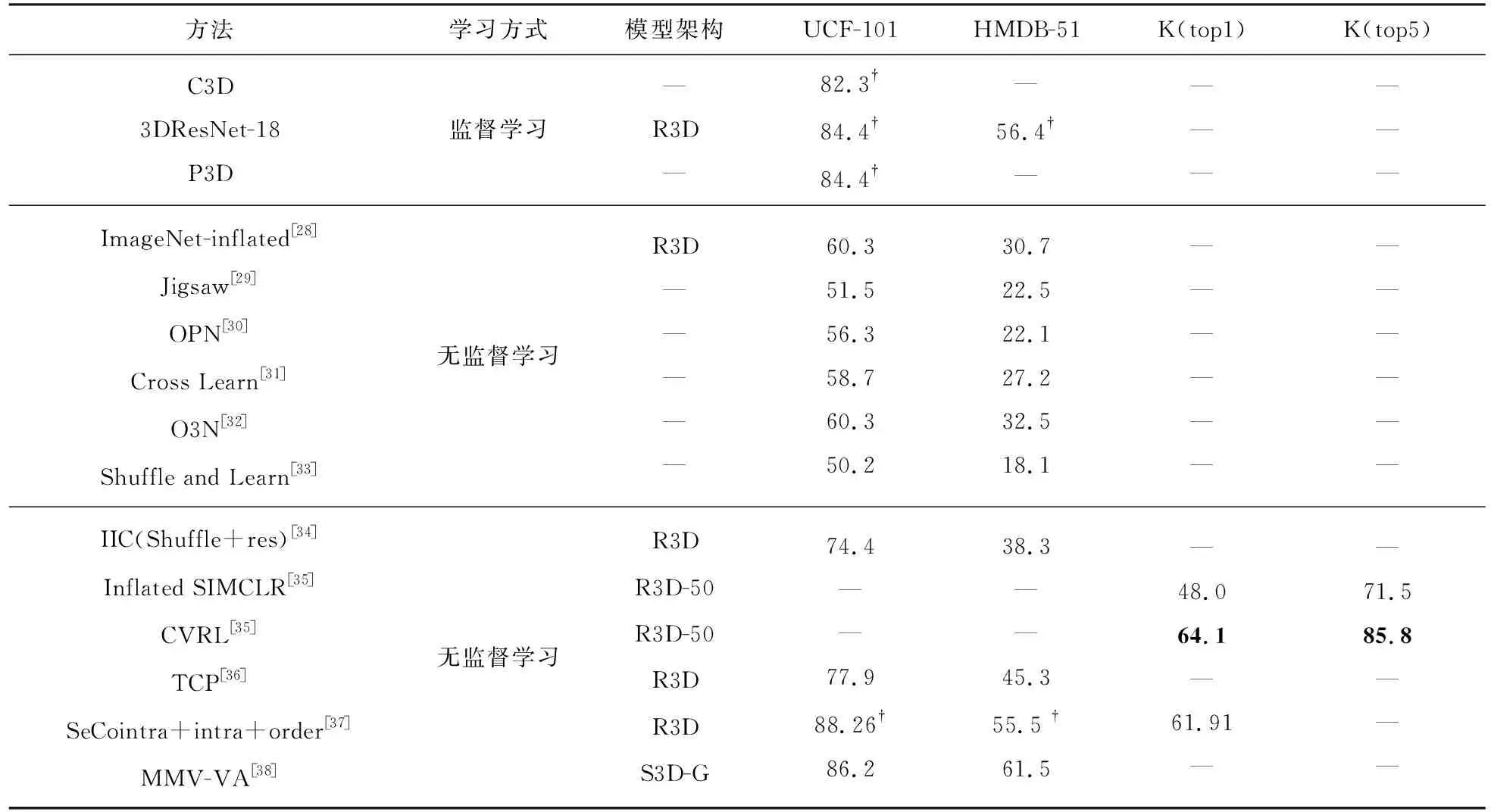
表2 動作分類準確率Tab.2 Action classification accuracy%
4.3 最近鄰檢索
一般情況下,屬于同一類的樣本在特征空間中更接近彼此。可以通過對數據集中的樣本進行top-k檢索來分析對比方法是否達到預期效果,由于該方法直接將提取的特征用于最近鄰檢索,不再進行任何的訓練,所以最能體現模型表征的質量。表3展示了不同表征學習方法在UCF101和HMDB51上的視頻檢索性能,使用測試集檢索訓練集視頻,除SpeedNet之外,所有模型都只在UCF101進行預訓練,top-k檢索指的是:如果前k個最近鄰包含一個相同類的視頻,則正確檢索計數,k的取值為1,5,10,20。
表3列舉了近幾年無監督對比學習模型在最近鄰檢索上的性能,當k增加時,最近鄰檢測的準確度也會增加。當只考慮在UCF101數據集上進行預訓練的對比學習方法時,可以看出:k相同時,不同模型的準確度基本成上升趨勢,這也說明模型的表征質量也在逐漸提高。SpeedNet[43]是在Kinetics數據集上進行預訓練,然后在UCF101上進行最近鄰檢索,因為兩個數據集的差異,top-k檢索的準確度會降低。表3中的CoCLR[44]在UCF101和HMDB51數據集上的性能遠遠優于其他方法,這是因為CoCLR[44]是在原有的無監督對比學習模型的基礎上增加了RGB網絡和Flow網絡的協同訓練,若不進行協同訓練,其在UCF101數據集上的準確率為33.1%(k=1時),仍優于其他方法。無監督對比學習方法學習到的視頻表征能力在不斷提升,這說明無監督對比學習還有進一步提升的空間,有很大潛力能夠超越監督學習。
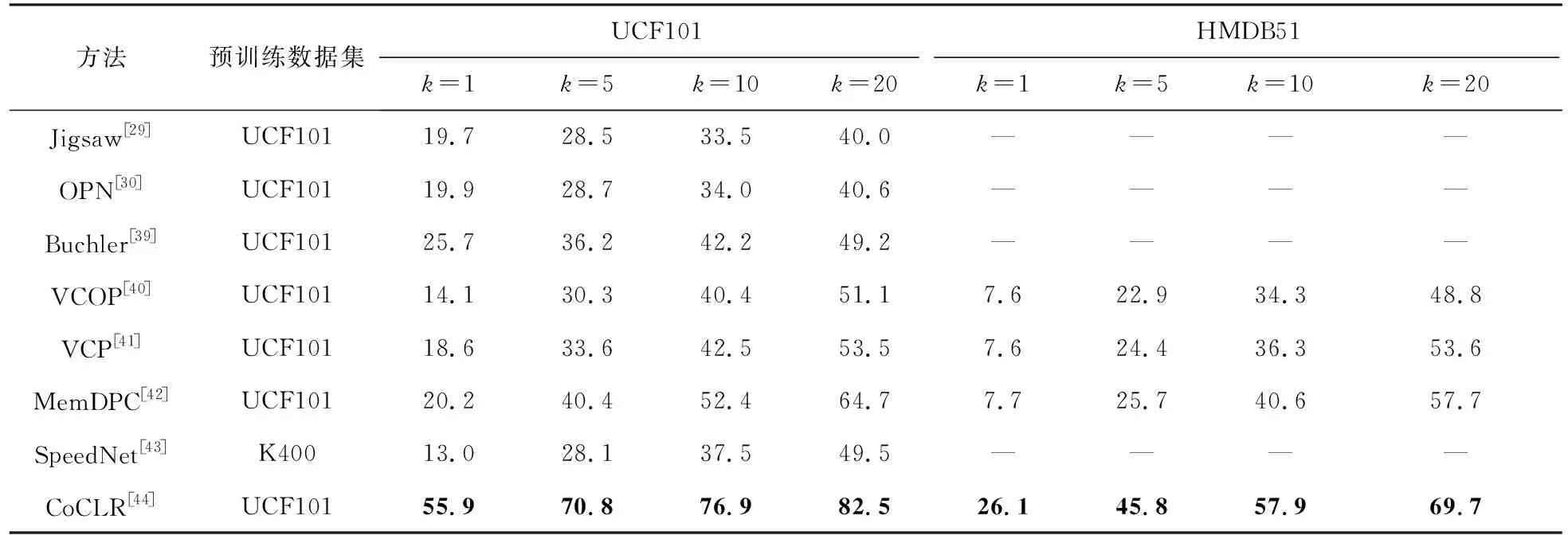
表3 最近鄰視頻檢索方法性能比較Tab.3 Performance comparison of nearest neighbor video retrieval method%
5 視頻理解中的對比學習
5.1 視頻理解任務
視頻理解是一個高層語義信息與底層視覺特征信息自然融合的過程,通過有效地對視頻信息進行分析以及根據視頻的特有知識挖掘其中有價值的信息來實現視頻內容的理解,從而實現視頻的有效管理、分類和檢索等。視頻理解任務的關鍵是特征提取與歸納,目前用來提取特征信息的網絡結構有很多,包括基于二維卷積神經網絡的方法、基于三維卷積神經網絡的方法、基于長短期記憶網絡(Long Short Term Memory networks,LSTM)的方法等。基于二維卷積神經網絡的方法將二維卷積神經網絡應用于每一幀,并將多幀圖像特征融合為視頻特征,基于三維卷積網絡的方法采用三維卷積運算從多幀圖像中同時提取時空特征,基于LSTM的方法利用LSTM對視頻中的長期動態進行建模。對于無監督對比學習而言,視頻特征的歸納就是從多個視圖的特征圖中學習不變表示。
5.2 視頻理解中對比學習應用
視頻理解包括視頻定位、視頻動作識別和視頻目標跟蹤等,將在下面的例子中說明視頻理解中對比學習的應用。
5.2.1視頻聲源定位
視頻聲源定位是視頻定位的一種,是對視頻中發出特定聲音的物體進行定位。文獻[45]采用無監督對比學習的方法學習視頻表征,即視頻中的視覺和音頻作為兩種不同的視圖進行輸入,通過兩個不同的編碼器分別提取特征表示,在對比損失函數的作用下學習視覺和音頻的對應關系,并將學習到的視頻表征應用于下游任務。當輸入同一視頻的不同視圖時,通過對比學習方法學習音頻和視頻之間的對應關系并進行數據可視化(熱圖),然后設立軟閾值,閾值大于0.6的部分判斷為正區域(發出聲音的物體區域),閾值小于0.4的區域判斷為負區域(不產生聲音的區域),閾值在0.4~0.6的區域不進行任何處理,從而實現視頻聲源定位,如圖9所示。
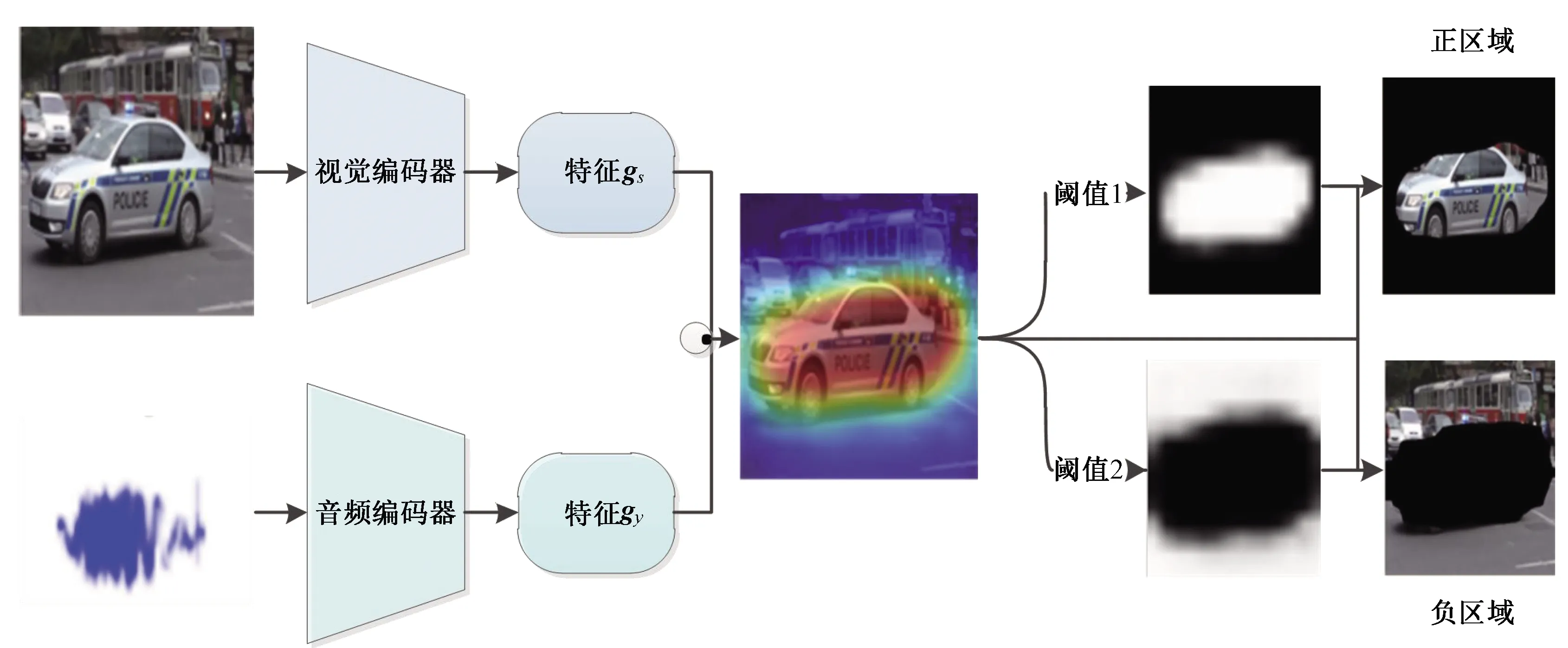
圖9 視頻聲源定位模型Fig.9 Video sound source localization model
5.2.2視頻動作識別
動作識別是視頻理解中的經典問題,給定一個視頻,通過提取視頻中的時間和空間特征識別出視頻里的主要動作類型。可以利用無監督對比方法提高域適應能力,進一步提高目標域動作識別的準確度。例如文獻[46]提出多模式無監督域適應方法,通過對源域和目標域同時進行多模態自監督,并利用多模態鑒別器進行聯合優化,實現目標域性能的提高,如圖10所示。該模型主要分為域對齊部分、自監督部分和分類部分,域對齊部分采用對抗訓練的方法實現源域和目標域的分布對齊,自監督部分在對比學習方法的基礎上利用模態的對應關系(只關注于動作)創建偽標簽來實現模態之間的時序對齊,其中,正樣本從每個模態的相同或不同時間的相同動作中采樣,負樣本從每個模態的不同動作中采樣,該部分網絡訓練后具有預測模態是否對應的表征能力。在對抗學習進行域適應的基礎上加上自監督部分,能夠進一步提高域適應的性能,提高目標域動作識別的準確度。
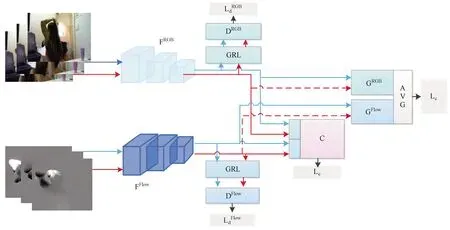
圖10 多模態域適應動作識別模型Fig.10 Multi-modal domain adaptive action recognition model
5.2.3視頻目標跟蹤
三維目標跟蹤是三維數據序列中多幀目標的檢測和關聯問題。例如,自動駕駛汽車對周圍環境的持續感知是通過激光雷達等傳感器完成的,這些傳感器產生3D數據序列,車輛必須根據這些數據估計車輛周圍環境中物體的位置。此外,為實現安全導航,感知算法必須動態跟蹤對象,如車輛和行人等。目標跟蹤算法首先在每一幀上運行一個目標檢測器進行目標檢測,然后將未來幀中的目標檢測結果與現有軌跡進行匹配,從而實現目標的跟蹤。文獻[47]使用對比方法學習3D嵌入,并用來改進多目標跟蹤,模型如圖11所示。對于幀t中的任何錨點,計算與同一幀中其他樣本的余弦相似度,選擇相似度最大的作為負樣本,從與錨點有相同的軌跡且相關聯的另一幀的檢測中選擇置信度最大的樣本作為正樣本,采用三聯體損失函數進行訓練,使嵌入正樣本對比嵌入負樣本對更相似,如圖11(a)所示。對比學習生成的偽標簽不一定完全準確,需要評估樣本的不確定性,通過忽略不確定性高的樣本,從而減少訓練中錯誤標簽的生成。在測試時,從一幀中的每個候選檢測中提取自監督嵌入,并進一步利用相似度進行幀間的精確數據關聯,如圖11(b)所示。該文獻將學習的 嵌入和馬氏距離相結合來改進多目標跟蹤,其目的是對多個目標進行數據關聯,改進后的多目標跟蹤算法的性能得到一定的提升。
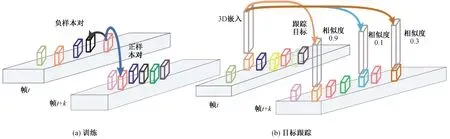
圖11 基于對比學習的目標跟蹤模型Fig.11 Object tracking model based on contrastive learning
6 討論和展望
無監督對比學習能夠避免使用人工標注的大規模的數據集,但是其也有局限性。基于NCE的理論和經驗,高質量的表征需要大量負樣本的比較,所以模型需要在大型GPU集群上進行訓練,但這在大部分情況下難以滿足。緩解該問題的一種方法是使用動量編碼器。另一種方法是不使用負樣本,負樣本的存在只是為了防止特征表示坍縮成單個簇,那么是否可以完全消除對負樣本的需要,通過對度量空間施加額外的約束,以防止它坍縮[21-22]。此外,人們更多關注負樣本的數量,而忽略了負樣本的質量,質量較好的負樣本可以提高模型表征的質量,由此提出使用負樣本進行對比學習時質量與數量權衡的問題。盡管互信息為對比損失函數提供了理論支撐,但是對比學習的成功不能只歸功于互信息最大化。如果能夠從新的角度看待對比損失,或許能夠設計出更好的、在計算和內存方面效率更高的對比損失函數。
7 結論
無監督對比學習是解決標記訓練數據無法獲取或者數據不足的方法之一。目前,對比學習逐漸從圖像領域轉移到視頻領域,這無疑需要更多的計算資源,但是對比學習模型能夠應用于更廣泛的下游任務中,并能表現出較好的性能。無監督對比學習雖然不能解決數據分類、預測等方面的所有問題,但是其利用遷移學習能夠減少新模型訓練所需的計算資源,并能提高其性能,具有很高的研究價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年4期)2020-09-21 03:39:12
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
光學精密工程(2016年6期)2016-11-07 09:07:19
