適用于室內動態場景的視覺SLAM算法研究
2022-08-01 04:21:50馮一博張小俊王金剛
燕山大學學報 2022年4期
馮一博,張小俊,王金剛
(河北工業大學 機械工程學院,天津 300130)
0 引言
近年來,同步定位與地圖構建技術(Simultaneous Localization and Mapping,SLAM)[1]作為高精度地圖的代表被廣泛應用到智能汽車領域。智能汽車SLAM問題可以描述為:智能汽車從未知環境的未知地點出發,在移動的過程中,通過傳感器信息定位自身的位置和姿態,進而構建增量式地圖,使智能汽車達到同步定位與地圖構建的目的。因此,SLAM技術的發展會極大地影響智能汽車的發展,研究智能汽車SLAM技術具有一定的實際意義。
1986年由Smith Self 和Cheeseman首次提出SLAM技術,截止目前已經發展三十多年,主要經歷了三個發展階段。第一個階段是傳統階段:SLAM問題的提出,并將該問題轉換為一個狀態估計問題,利用擴展卡爾曼濾波[2]、粒子濾波[3]及最大似然估計[4]等手段來求解。將視覺同步定位與地圖構建問題轉換為一個狀態估計問題,傳統階段的傳感器主要依據就激光雷達為主,該階段的缺陷在于忽略了地圖的收斂性質,把定位問題與地圖構建問題分開處理。第二個階段是算法分析階段(2004-2015):2007年A. J. Davison教授提出的MonoSLAM[5]是第一個實時的單目視覺SLAM系統,但它不能在線運行,只能離線地進行定位與建圖;同年Klein等人提出了PTAM[6](Parallel Tracking and Mapping),該算法雖然第一個使用非線性優化作為后端并且實現了跟蹤與建圖過程的并行化,但是它只適用于小場景下,而且在跟蹤過程中容易丟失;2015 年MurArtal 等人提出的ORB-SLAM[7]是 PTAM 的繼承者之一,它圍繞ORB特征進行位姿估計,以詞袋模型的方式克服累積誤差問題,但它在旋轉時容易丟幀。第三階段就是魯棒性-預測性階段(2015-):魯棒性、高級別的場景理解、計算資源優化、任務驅動的環境感知等,這些都伴隨著人工智能技術的發展,讓深度學習逐漸融入到視覺SLAM之中。而在SLAM系統中,當一個新的幀到來時,通過應用YOLO[8]、SSD[9]、SegNet[10]、Mask R-CNN[11]等先進的CNN結構,可以獲得特征的語義標簽。文獻[12]使用目標檢測網絡SSD來檢測可移動的物體,如人、狗、貓和汽車。文獻[13]使用YOLO來獲取語義信息,他們認為總是位于運動物體上的特征是不穩定的,并將其過濾掉。文獻[14]使用SegNet在一個單獨的線程中獲得像素語義標簽,如果一個特征被分割成“人”,則使用外極幾何約束進行進一步的移動一致性檢查;如果檢查結果是動態的,那么語義標簽為“person”的所有特征都將被分類為動態并被刪除。這種方法實際上是將帶有標簽“person”的特征作為一個整體來處理,并且取兩個結果的交集:只有在語義上和幾何上都是動態的特征才被認為是動態的。文獻[15]結合了Mask R-CNN和多視圖幾何的語義分割結果,將語義動態或幾何動態的特征都被認為是動態的。
傳統的視覺SLAM在建圖的過程中,需要考慮兩方面,一方面如何依據拍攝的圖像序列估計車輛的運動軌跡,另一方面如何在三維場景中構建幾何結構。而解決SLAM問題的關鍵是從獲取的環境圖像中快速提取精確特征,描述相機環境的局部特征,最后計算空間三維坐標和其他信息實現視覺的自主定位和地圖構建。
特征是圖像信息的另一種表達方式,特征點是圖像中一些特別的地方,所以需要特征點在相機運動之后保持穩定,而傳統的特征提取方法,如著名的SIFT[16]、SURF[17]、ORB[18]等在復雜環境下,容易受灰度值、動態物干擾,面對圖像時會出現性能下降。因此,在傳統的特征點提取中加入了語義信息,改進了SLAM系統,主要內容包括:
1) 深度學習與特征提取相結合,本文選用YOLO v3端對端的目標檢測方法,準確識別地下車庫中的動態物體,并且算法適應地下環境變化,有效提取圖像特征。
2) 能夠過濾出動態物體,快速提取穩定的局部特征點進行幀間匹配、位姿估計,提高了SLAM定位精度,增強車輛在地下出庫場景中的環境感知。
1 基于YOLO v3與ORB-SLAM2的動態建圖算法
本文算法依托ORB-SLAM2[19]為主體框架,視覺前端的特征點提取融合了深度學習的算法,通過分割圖像中的靜態和動態特征并將動態部分視為離群值,可以提高SLAM算法的魯棒性。根據選擇性跟蹤算法,在視覺前端中計算出靜態特征點,進行姿態估計和非線性優化,可以避免動態物體的干擾。圖1給出了本文SLAM的主體框架。

圖1 算法流程圖Fig. 1 Algorithm flow chart
1.1 目標檢測原理
YOLO v3主干網絡由Darknet-53構成,它利用53個卷積層進行特征提取,而卷積層對于分析物體特征最為有效。
在前向過程中,YOLO v3輸出了3個不同尺度的特征圖:y1,y2,y3,其中y1檢測大型物體,y2檢測中型物體,y3檢測小型物體,輸出特征圖輸出維度為
R=N×N(3×(4+1+M)),
(1)
其中,N×N為輸出特征圖格點數,3表示每個特征圖y一共3個錨框,4表示4維的檢測框位置(tx,ty,tw,th),1表示檢測置信度1維,M為分類個數。
在反向過程中,預測框共分3種情況:正例、負例、忽略樣例。損失函數[20]為3個特征輸出圖的損失函數值和,分別為置信度損失、分類損失和定位損失。置信度損失用于優化框架的準確性,分類損失用于優化檢測和分類,定位損失用于優化中心點坐標和寬度檢測框。
損失的計算:
L(O,o,C,c,l,g)=λ1Lconf(o,c)+
λ2Lcla(O,C)+λ3Lloc(l.g)
(2)
其中,λ1,λ2,λ3為平衡系數。Lconf(o,c)為置信度損失,Lcla(O,C)為分類損失,Lloc(l,g)為定位損失。
置信度損失:
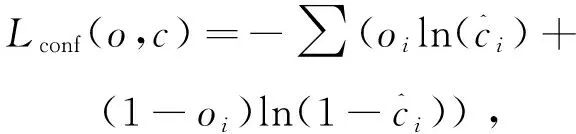
(3)
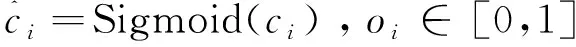
類別損失:
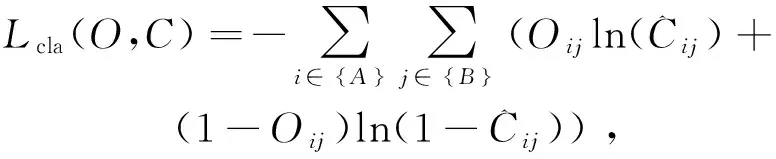
(4)
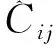
定位損失:
(5)
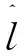
1.2 動態特征點剔除
圖2是動態目標剔除算法的整體框架圖,它在傳統的視覺前端加入了一個并行線程:YOLO v3模塊。本文使用的YOLO v3目標檢測方法能夠輸出3個特征圖,分別用于檢測大型和中小型物體;并且自制了地下車庫VOC數據集,標注了可能移動的類(汽車、人、自行車、公共汽車等),之后對測試集進行訓練,得到預訓練權重,這樣能夠更好地檢測識別出地下車庫中的動態目標,從而剔除動態特征點。
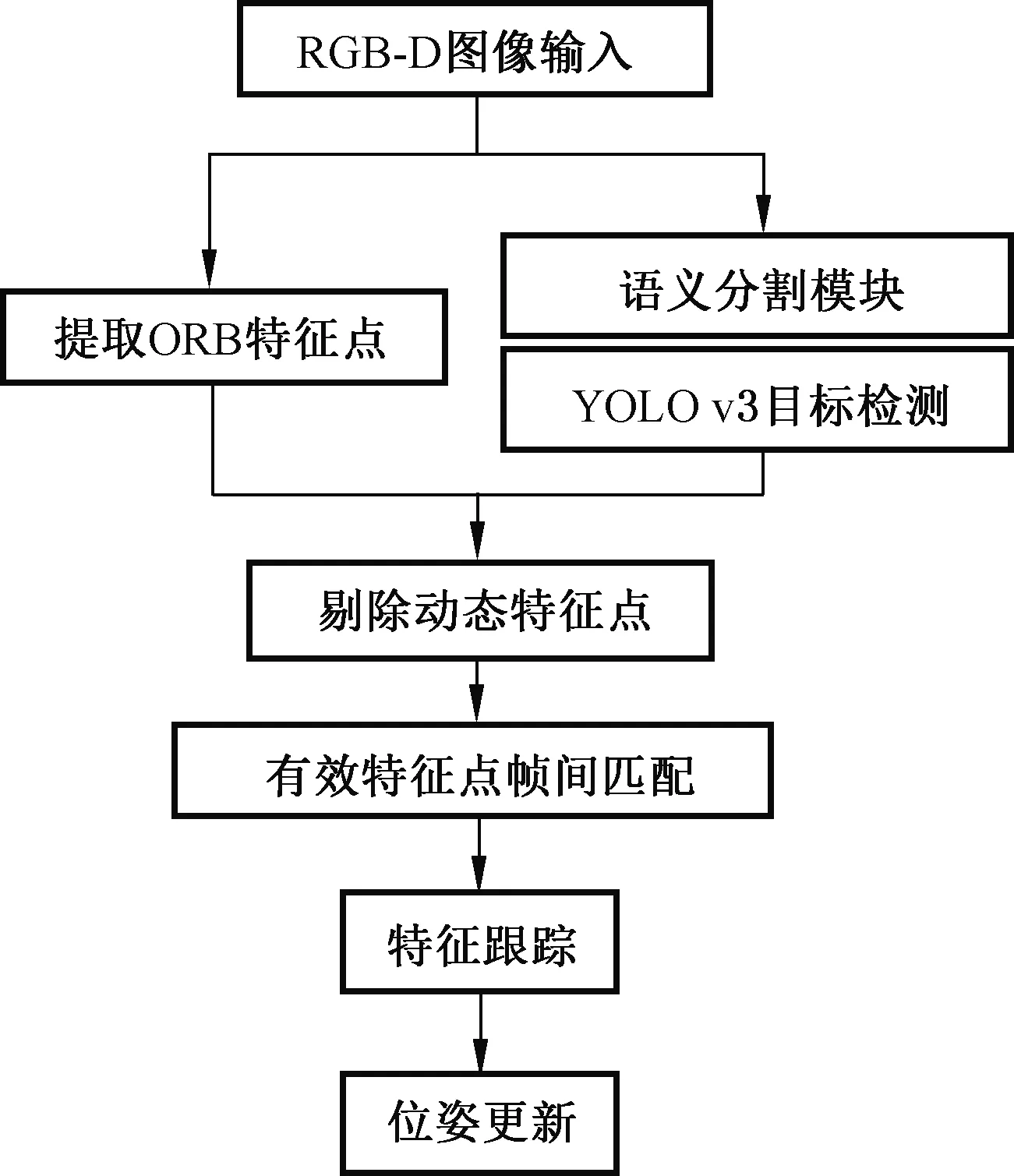
圖2 動態目標剔除算法框架Fig. 2 Dynamic target elimination algorithm framework
1.3 軌跡重建
優化的算法主體框架與ORB-SLAM2相當,它可以說是ORB-SLAM2的延伸,主要是由跟蹤線程、局部建圖線程與閉環檢測線程組成。各個線程的主要任務如下:
1) 跟蹤線程:根據目標檢測傳回的目標區域進行特征剔除,接著進行位姿跟蹤。
2) 局部建圖線程:最大的特點就是借助跟蹤線程的關鍵幀,更新地圖點和位姿,從而進行局部束極調整,最后對每一個匹配好的特征點建立方程,解出最優的位姿矩陣和空間點坐標。
3) 閉環檢測線程:首先計算圖像的詞袋向量,根據詞袋之間的相似度判斷是否閉環,若閉環則使用閉環關鍵幀對地圖點進行閉環融合處理,最終位姿通過本質圖優化來校正累計誤差。
進入跟蹤線程的前提是需要對算法進行初始化,而初始化的關鍵就是通過評分的方式選取合適的基本矩陣(Fundamental)或者單應矩陣(Homograph)。由于跟蹤線程中使用雙目相機或者RGB-D相機可以對一些3D點進行恢復,因此,單幀可創建關鍵點,關鍵幀;然而對于單目攝像頭,恢復3D點只能借助時間序列上的兩幀恢復。無論哪種相機,都需要借助評分選擇一個更好的模型來初始化。
Fundamental模型評分:
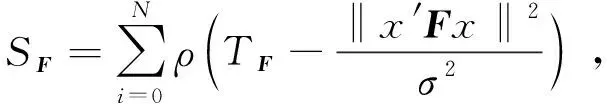
(6)
Homograph模型評分:
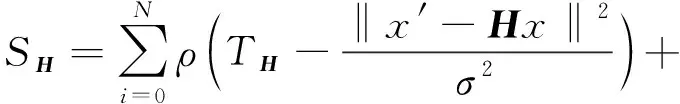
(7)
其中,當x≤0時,ρ(x)=0,當x>0時,ρ(x)=x。TF取固定閾值3.84,TH取固定閾值5.99。式(6)和式(7)中x′和x為同一個3D點在o和o′坐標系下坐標,F為基本矩陣,H為單應矩陣,i表示特征點序號,n表示特征點個數,σ為標準差。
兩個模型的選擇條件為
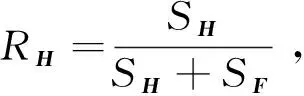
(8)
當RH≥0.45時,表示當前場景較為平坦并且視差較低,選擇單應矩陣;其他的情況,選擇基本矩陣。
局部建圖線程主要是為了進行束極調整,先根據相機模型和A、B圖像特征匹配好的像素坐標,求出A圖像上的像素坐標的歸一化的空間點坐標,然后根據空間點的坐標計算投影到B圖像上的像素坐標,可以發現,重投影的像素坐標(估計值)與匹配好的B圖像上的像素坐標(測量值)不會完全重合,這時候就需要束極調整。束極調整的目的就是對每一個匹配好的特征點建立方程,然后聯立形成超定方程,解出最優的位姿矩陣或空間點坐標。
閉環檢測線程主要由檢測回閉環、計算Sim3、閉環融合以及優化本質圖四個部分所組成。在閉環檢測中,首先要求閉環與閉環之間必須超過十幀,然后計算當前幀與相鄰幀之間的詞袋得分,從而得到最小相似度,之后以最小相似度作為基準,若大于該基準則可能是關鍵幀,這就將閉環檢測轉變為一個類似于模式識別的問題,當相機再次來到之前到過的場景,就會因為看到相同的景物,而得到類似的詞袋描述,從而檢測到閉環。其次在計算Sim3中,單目系統中存在尺度的不確定性,因為針對一個三維點P來說,在單目拍攝的兩幅中可以匹配到PL和PR,但是無法確定其在三角化里的具體位置,所以存在尺度模糊,而對于雙目相機或者RGB-D相機,尺度可以唯一確定。之后閉環矯正是融合重復的點云,并且在共視圖中插入新的邊以連接閉環,接下來當前幀的位姿會根據相似變換而被矯正,與此同時所有與其相連的幀也會被矯正,矯正之后所有的被閉環處的關鍵幀觀察到的地圖通過映射在一個小范圍里,然后去搜索它的近鄰匹配,這樣就可以對所有匹配的點進行更有效的數據融合。最后為了更好地完成閉環,將回環誤差均攤到所有關鍵幀上,使用本質圖優化所有關鍵幀的位姿姿態。
2 實驗與分析
2.1 數據準備
采集制作含有動態目標的地下車庫VOC數據,該數據集分為有車有人、有車無人、無車無人、無車有人4種情況。利用目標檢測工具labelimg對采集的地下車庫圖片進行標注,分為person、car、bus、rider類,制作成VOC數據集。將數據集按照8∶1∶1的比例劃分為訓練集、驗證集和測試集,即訓練集包括3 200張圖片,驗證集和測試集各包括400張照片。
之后對測試集訓練,用平均損失曲線以及平均交并比(Intersection Over Union,IOU)曲線作為訓練的評價標準。由圖3、4可以看出在經過40 000多次迭代后平均損失曲線接近于0.06趨向于擬合,平均交并比曲線代表預測的邊界框和真實框的交集與并集之比接近于1,由此訓練結果可以用來進行地下車庫試驗。
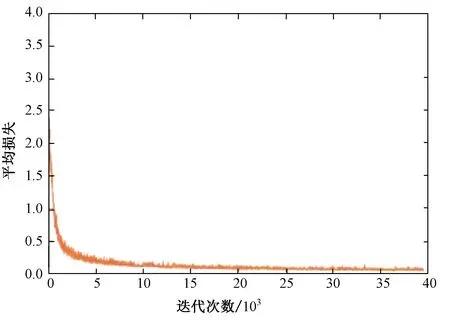
圖3 平均損失曲線Fig. 3 Average loss curve
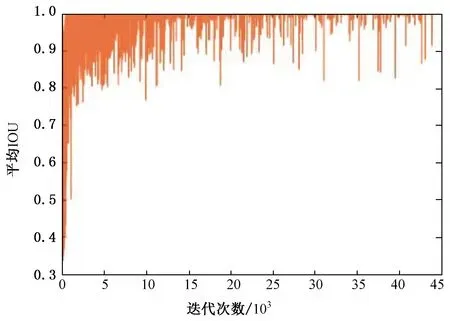
圖4 平均交并比曲線 Fig. 4 Average IOU curve
2.2 檢測驗證
傳統的視覺SLAM難以從平面像素中定義動態對象,也難以檢測跟蹤動態對象,因此,本文測試了ORB-SLAM2以及優化的SLAM的操作效果。
使用ORB-SLAM2的特征提取如圖5所示,可以看出特征點集中在人車這些動態物上,ORB特征點大多是雜亂無章,并且對于SLAM的建圖有很大影響,不但會增加冗余計算量、影響建圖速度,甚至會產生漂移等影響。圖6表示的是應用YOLO v3的目標檢測方法進行的動態目標檢測,圖7表示的是識別全部的ORB特征點,圖8表示的是動態特征點的剔除。

圖5 ORB-SLAM2的特征提取Fig. 5 Feature extraction of ORB-SLAM

圖6 YOLO v3的目標檢測Fig. 6 Target detection of YOLO v3

圖7 全部特征點的識別Fig. 7 Recognition of all feature points

圖8 動態特征點的剔除Fig. 8 Removal of dynamic feature points
2.3 車庫軌跡驗證
地下車庫數據集是由智能汽車平臺搭載的RGB-D相機錄制,數據集經歷了3個場景,分別是靜態場景、低動態場景、高動態場景。
用激光雷達算法LOAM測試完整個數據集,當作該數據集的真實軌跡圖,圖9展示了不同算法的運行軌跡,本文改進的SLAM算法相機軌跡估計比ORB-SLAM2更接近地面真實情況。在靜態場景下,本文算法和ORB-SLAM2都貼近于真實軌跡;隨后經歷低動態場景,ORB-SLAM2產生了些許的漂移,根據回環校正,依舊可以跟蹤上一幀,進行幀間匹配建圖,然而到了高動態場景中,ORB-SLAM2算法中由于提取的特征點大多集中在車中,出現了嚴重的漂移,導致建圖未能成功;相反改進的SLAM算法由于特征點提取范圍從整幅圖像縮小到非動態區域,能夠進行有效的幀間匹配,完成建圖。與ORB-SLAM2算法相比,改進的SLAM算法在動態場景中具有更強的魯棒性,攝像機軌跡估精度也有很大提高。
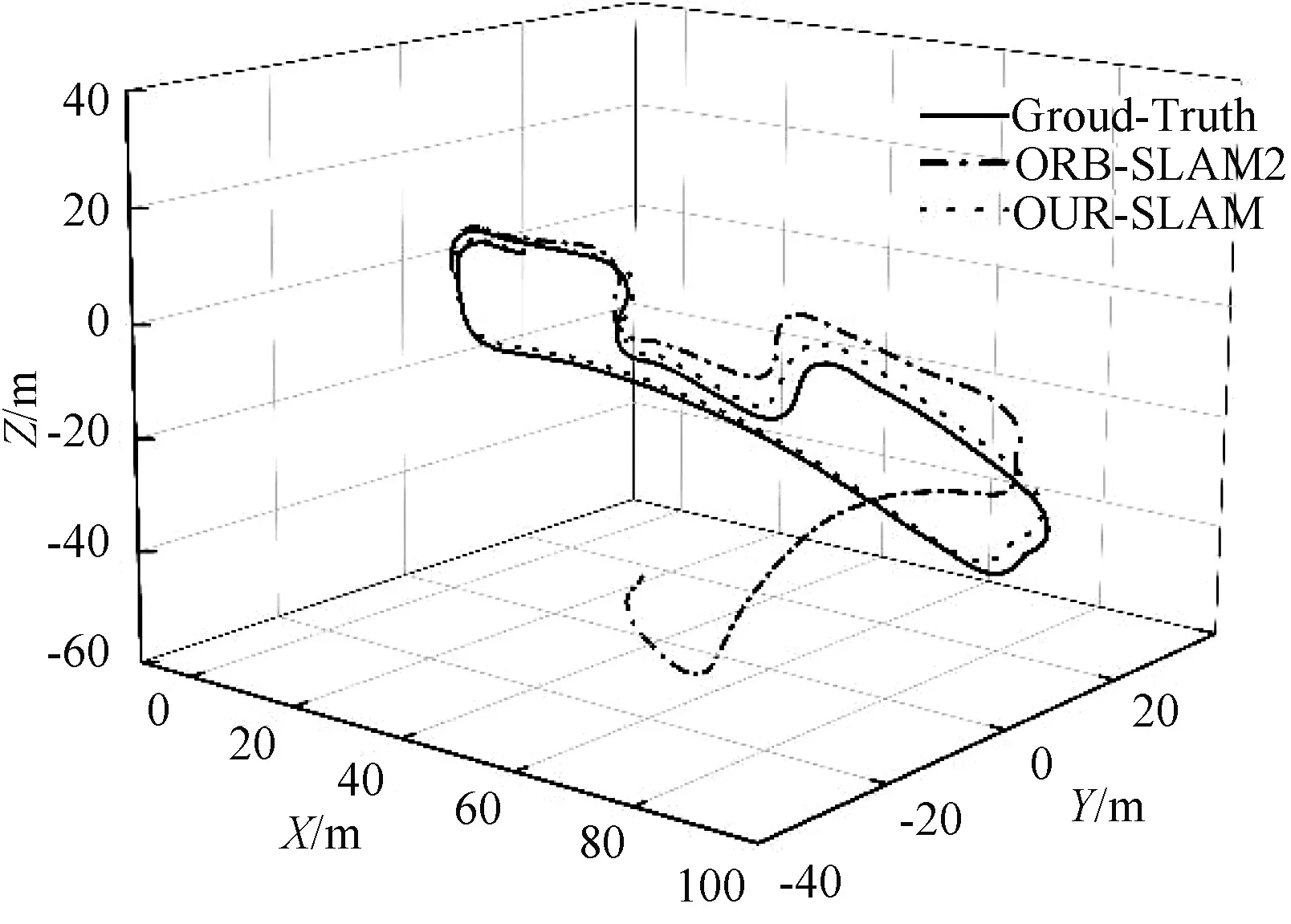
圖9 不同算法的軌跡對比圖Fig. 9 Trajectory comparison diagram of different algorithms
3 評價指標
對優化的SLAM算法評估可以從多個方面考慮,例如時耗、復雜度、精度。其中,算法對精度要求最高,本文采用絕對軌跡誤差(Absolute Trajectory Error, ATE)和相對位姿誤差(Relative Pose Error,RPE)兩個精度指標。ATE被廣泛用于定量評估,它評估兩條軌跡之間的絕對姿態差,采用均方根誤差(Root Mean Square Error, RMSE)、平均誤差(Mean Error)、中位誤差(Median Error)和標準差(Standard Deviation, SD)等指標進行測量。在這些指標中,RMSE和SD在反映視覺SLAM系統性能力方面更為重要。RMSE是測量誤差的標準差,用ERMSE表示,它很好反映測量的精度,ERMSE越小,估計軌跡越接近地面真值軌跡。
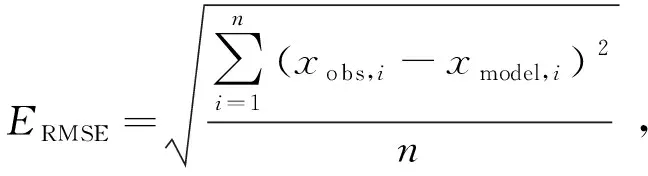
(9)
其中,n表示觀測次數,i表示第i個關鍵幀,xobs,i表示第i個關鍵幀姿態的地面真實值,xmodel,i表示第i個關鍵幀姿態的觀測值。
SD可以反映觀測值的分散程度,用ESD表示
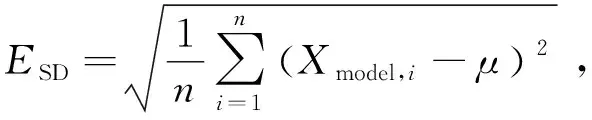
(10)
其中,n表示關鍵幀的數目,Xmodel,i表示第i個關鍵幀的觀測姿態,μ是Xmodel,i的平均值。
ME是觀測姿態與地面真值之間誤差的算術平均值,用Emean表示:
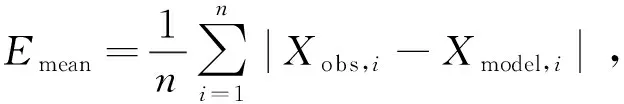
(11)
其中,n表示觀測次數,i表示第i個關鍵幀,Xobs,i表示第i個關鍵幀姿態的地面真實值,Xmodel,i表示第i個關鍵幀姿態的觀測值。
中位誤差是觀測姿態和地面真實值之間的誤差的中間值。
RPE主要描述的是相隔固定時間差兩幀位姿差的精度(相比真實位姿),相當于直接測量里程計的誤差。因此第i幀的RPE定義如下:
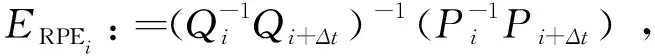
(12)
其中,Pi表示第i幀算法估計位姿,Qi表示第i幀真實位姿,Δt表示時間間隔t,Ei表示i時刻絕對或相對位姿估計誤差。
采用ERMSE統計誤差總體值:

(13)
其中,n表示觀測次數,Δt表示時間間隔t,得到m,m=n-Δt×ERPE,Ei表示i時刻絕對或相對位姿估計誤差,trans(Ei)代表相對位姿誤差中的平移部分。
但是,在大多數情況下,Δt有許多選擇,為了綜合衡量算法的表現,計算遍歷了所有時間間隔的ERMSE的平均值:
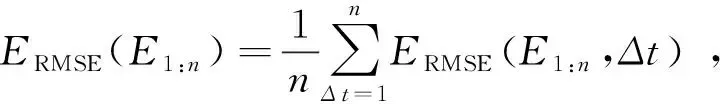
(14)
其中,n表示觀測次數,Δt表示時間間隔t(t從1開始取直到觀察結束n次為止),ERMSE表示均方根誤差。
若遍歷所有時間間隔,則存在計算復雜程度高、耗時問題,因此通過計算固定數量的RPE樣本獲取估計值作為最終結果。
采用系數K對比優化的SLAM算法與ORB-SLAM2的改進值:
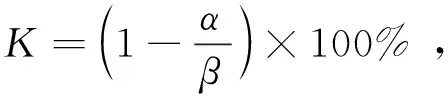
(15)
其中,α是優化的SLAM獲得的值,β是ORB-SLAM2獲得的值。
圖10、11對ORB-SLAM2和優化的SLAM進行ATE評測:對比真值位姿,ORB-SLAM2的均方根誤差為22.49 m,優化的SLAM的均方根誤差為1.46 m,提升了93.50%;ORB-SLAM2的標準差為11.92 m,優化的SLAM的標準差為0.65 m,提升了94.53%。可以看出優化的SLAM算法漂移量以及分散程度明顯優于ORB-SLAM2。
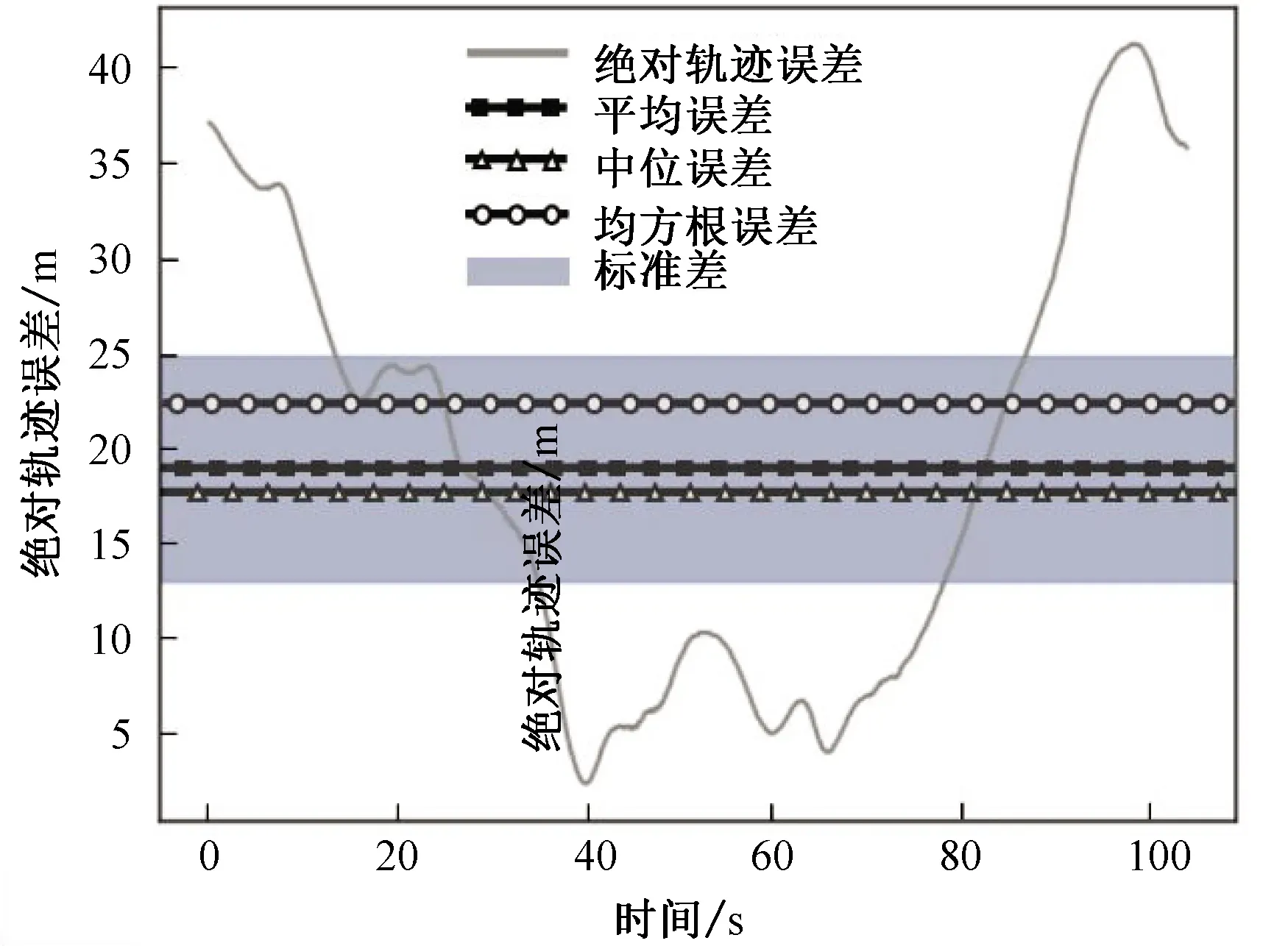
圖10 ORB-SLAM2位姿與真值位姿之間的絕對軌跡誤差Fig. 10 ATE between ORB-SLAM2 pose and true value pose
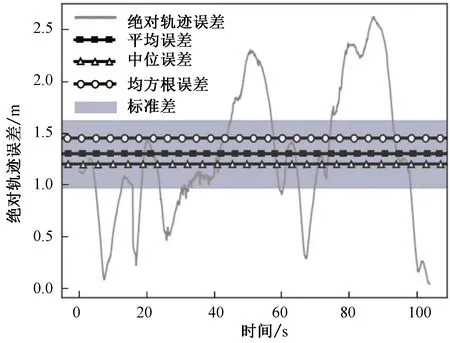
圖11 優化的算法位姿與真值位姿之間的絕對軌跡誤差Fig. 11 ATE between optimized algorithm and true value pose
圖12、13對ORB-SLAM2和優化的SLAM分別進行RPE評測:對比真值位姿,ORB-SLAM2的均方根誤差為0.24 m;優化的SLAM的均方根誤差為0.040 8 m;提升了83.03%。可以看出,優化的SLAM算法漂移量明顯低于ORB-SLAM2。

圖12 ORB-SLAM2位姿與真值位姿之間的相對位姿誤差Fig. 12 RPE between ORB-SLAM2 pose and true value pose
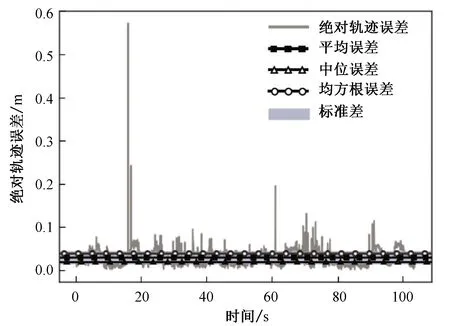
圖13 優化的算法位姿與真值位姿之間的相對位姿誤差Fig. 13 RPE between optimized algorithm and true value pose
4 結論
針對在地下車庫光照不足,容易受動態物影響的問題,本文構造了一個完整的SLAM框架,提出了一種基于YOLO v3和ORB-SLAM2相結合的動態場景視覺SLAM算法。實驗結果表明,在綜合場景下本文提出的算法位姿估計精度相比于ORB-SLAM2提升了93.50%,改進后的算法大幅度提高了SLAM系統在動態環境下精度與魯棒性,并且保證了實時性。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
