院內膿毒癥風險管理系統設計與實現*
2022-08-04 00:46:42陳珊黎龐書麗王穎晶丁粉華邵維君賈紅巖吳曉萍
醫學信息學雜志 2022年5期
關鍵詞:系統
陳珊黎 龐書麗 鄭 濤 王穎晶 丁粉華 邵維君 賈紅巖 韓 剛 吳曉萍
(上海交通大學醫學院附屬仁濟醫院 上海 200127)
1 引言
1.1 膿毒癥概述
膿毒癥(Sepsis)是感染引起宿主反應失調進而導致危及生命的器官功能損害的癥候群,具有起病急、進展快、死亡率高的特點,是醫院重癥加強護理病房(Intensive Care Unit,ICU)患者死亡的最重要病因。我國一項針對44所醫院ICU的研究顯示,ICU患者膿毒癥發病率為20.6%,病死率為35.5%,嚴重膿毒癥病死率高達50%及以上[1]。膿毒癥診治、預后與治療時間密切相關,患者每延遲1小時治療死亡率增加7.6%[2]。因此《中國膿毒癥早期預防與阻斷急診專家共識》、中國預防膿毒癥行動(Preventing Sepsis Campaign in China,PSCC)等提出將預防膿毒癥發生和阻斷進展作為行動關鍵節點,以降低膿毒癥發生率和病死率[3]。
1.2 膿毒癥定義與診斷標準發展
膿毒癥定義與診斷標準歷經3次版本演變。1991年提出的Sepsis 1.0采用全身炎癥反應綜合征(Systemic Inflammatory Response Syndrome,SIRS)診斷標準,但過于敏感并缺乏特異性;2001年提出的Sepsis 2.0在SIRS基礎上增加21個指標及參數,過于復雜而阻礙臨床應用[4];2016年發布的Sepsis 3.0將“序貫性器官衰竭評分(Sequential Organ Failure Assessment,SOFA)≥2分”、且發生“感染”兩個指標作為膿毒癥診斷標準,推薦快速序貫器官衰竭評分(quick Sequential Organ Failure Assessment,qSOFA)為住院患者疑似膿毒癥篩查工具。Sepsis 3.0能有效反映膿毒癥患者病理及生理過程且在診斷操作上更簡單,能夠達到早診早治目的,值得臨床使用[5]。
1.3 膿毒癥防治存在的問題
膿毒癥實際臨床診治中延誤診斷、關鍵指標評估率低等問題突出。一項涉及華中地區79家醫院的急診膿毒癥防治現狀調查顯示,急診醫務人員對PSCC知曉率僅39.3%,對Sepsis 3.0知曉率為64.7%,認為影響膿毒癥診治效果的最主要原因是早期識別能力有限,導致臨床診斷率偏低[6]。該問題主要由于以下3方面原因:一是膿毒癥臨床癥狀不典型;二是SOFA評估體系繁瑣,涉及呼吸系統、血液系統等器官11項變量,臨床難以實現準確而持續的評估;三是全院性管理問題,非急診ICU醫生缺乏主動篩查防治意識,指南依從性低。
1.4 膿毒癥防治最新進展
近年來人工智能技術逐漸應用于疾病風險預測領域研究中,運用機器學習算法挖掘患者臨床數據,建立膿毒癥預測與診斷模型,能夠提高膿毒癥早期檢出率[7],提高治療效率,改善不良結局[8]。
2 資料與方法
2.1 研究方法
國內外已有多項利用人工智能(Artificial Intelligence,AI)算法建模預測膿毒癥風險的研究,但多為驗證性研究或應用于死亡風險預測,缺乏基于Sepsis 3.0的膿毒癥預測與早診應用。基于Sepsis 1.0與2.0標準的應用可能導致誤診、漏診[4],本研究基于Sepsis 3.0診斷標準,面向設置病房的臨床科室與醫務管理部門,采用自然語言處理、深度學習算法等人工智能技術,進行患者臨床數據挖掘分析,構建院內膿毒癥風險管理系統,對在院患者進行膿毒癥風險與診斷指標的持續監測、實時預警,對該病種質控情況進行多維度統計、分析,以實現全院膿毒癥風險的早期識別與診斷、患者死亡風險預測,減輕臨床SOFA評估負擔,為臨床及時治療爭取時間,最終達到持續改進醫療質量與安全的目的。
2.2 研究內容
主要包括針對臨床科室與醫務部門的業務需求設定系統核心節點、管理流程;基于患者臨床數據與Sepsis 3.0診斷標準進行算法建模;制定預測模型的驗證流程。
3 系統設計
3.1 監測指標設定
為實現膿毒癥風險預警,支撐臨床決策,減輕臨床工作負擔,膿毒癥風險管理系統監測指標參考膿毒癥臨床指南與專家共識,遵循膿毒癥臨床診斷標準,由ICU科室專家與系統研發團隊共同制定,見表1。
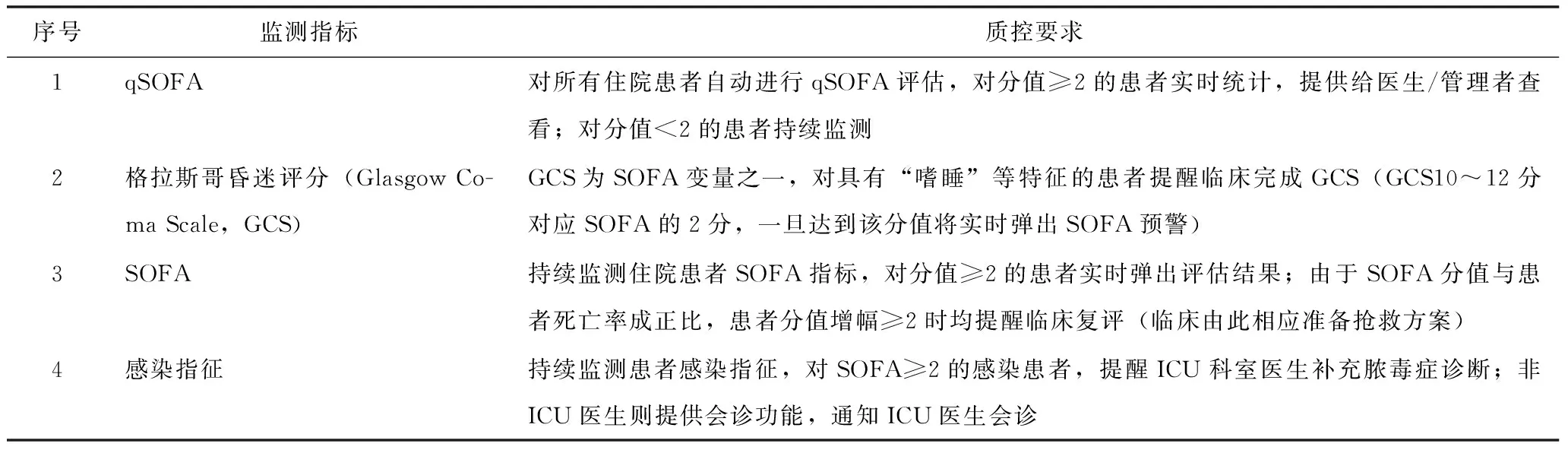
表1 系統核心監測指標
3.2 管理流程設定
根據qSOFA、Glasgow昏迷評分、SOFA、感染指征4個指標,系統在患者住院期間通過解析病歷內容變化進行持續監測,一旦達到質控標準將實時做出預警、提醒補充診斷等。由于急診科患者相關回顧性研究指出qSOFA評分價值有限,其識別膿毒癥能力不如其他評估模型[9],因此設定系統對于自動評估結果為qSOFA≥2的患者僅在后臺進行統計,而非醫生工作界面實時提醒。另外GCS量表中變量均為主觀性評價,而非生命體征等證據類數據,所以該類評分設定為提醒醫生人工執行將更為準確。對于SOFA≥2以及符合診斷標準的患者,均在醫生工作界面進行自動評價與實時提醒。在既定監測指標與質控邏輯下,系統管理流程,見圖1。
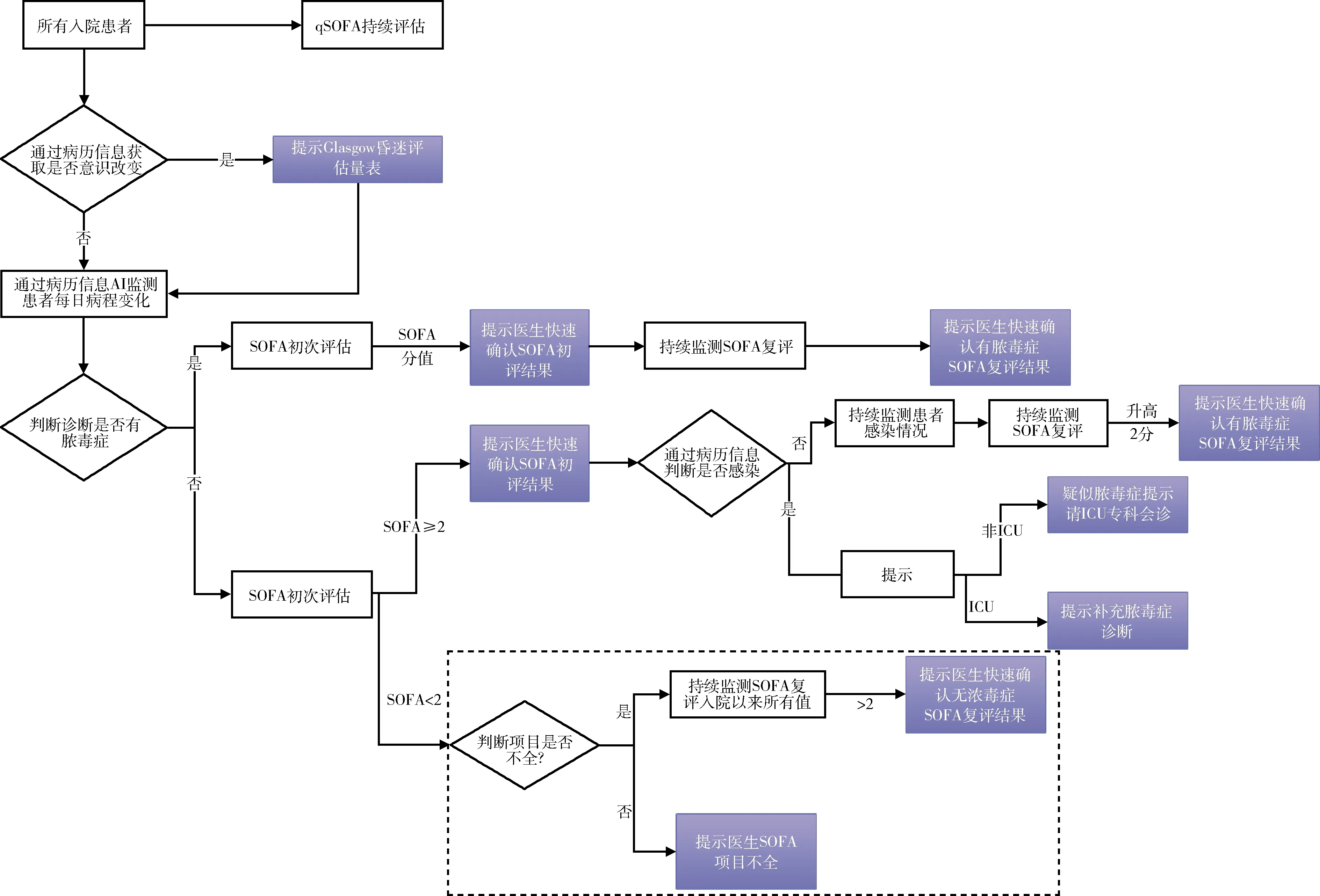
圖1 系統管理流程注:紫色模塊為醫生工作界面提醒內容。
3.3 所需數據
膿毒癥風險管理系統基于患者臨床數據進行相關指標評價,在系統實施上線前先與ICU臨床醫生確定該應用場景數據采集需求。為確保系統數據采集完整性,提高系統預測性能,醫院真實病歷采用2.0版的國際疾病分類第10次修訂本(International Classification of Disease V10,ICD-10)診斷字典和ICD-10手術字典。應集成的數據及業務系統包括但不限于住院電子醫囑系統,住院電子病歷系統,醫院信息系統(Hospital Information System,HIS),檢驗信息系統(Laboratory Information System,LIS),放射信息系統(Radiology Information System,RIS),護理信息系統(Nursing Information System,NIS)。其中能夠采集到的數據盡量是患者入院前3天門/急診LIS、RIS、NIS數據以及入院后所有LIS、RIS、NIS、病歷文書數據,以確保SOFA評估量表中的血小板計數、血清膽紅素濃度等項目數據、疑似感染或感染信息能夠被抓取與識別。
3.4 關鍵技術
膿毒癥風險管理系統在技術層面的3個要素是后結構化數據、知識圖譜、規則推理引擎,見圖2。鑒于膿毒癥風險管理系統通過智能接口直接獲取的臨床數據結構化程度低且具有多源異構特點[10],需要使用自然語言處理技術來完成臨床數據抽取與實體分類。目前國內病歷文本識別領域尚未形成完整、標準的分類tag標簽,導致很多重要屬性類實體,如“陰性/陽性/是否本人/既往/現在/時間”等醫學信息沒有被抽取覆蓋[11-12]。在構建膿毒癥風險管理系統過程中,通過融合國際性、多語種、包含內容廣泛的臨床醫學術語集[13]——SNOMED CT術語概念,和電子病歷包含眾多醫學命名實體與屬性集合的特點,構建自洽性更強的中文病歷實體分類標簽體系。新的標簽體系共設計26個標簽類型,形成完善的中文術語詞表,自然處理技術在標簽基礎上,通過分句、分詞、詞性標注、實體鏈接與編碼,進一步完成患者臨床數據分類提取與后結構化處理。在知識圖譜構建上,采用有監督式深度學習算法,引入醫學人工標注方式抽取國內外膿毒癥權威指南文獻、專家共識、醫學教材等中的醫學邏輯,構建疾病知識與知識規則庫,形成覆蓋3 000余病種、萬余篇權威文獻的醫學知識圖譜。醫學知識圖譜結合真實臨床環境診療數據抽取的關鍵信息,使知識圖譜的知識規則得以更新迭代,完整性與標準性進一步提高。基于上述自然語言處理形成的標準化信息及醫學知識圖譜,采用深度學習算法完成膿毒癥預測模型構建,輸出為風險評估、診斷等知識表示,從而在臨床診療過程中能夠對住院患者完整臨床病歷數據進行實時分析,將智能提示推送到醫生工作站界面。
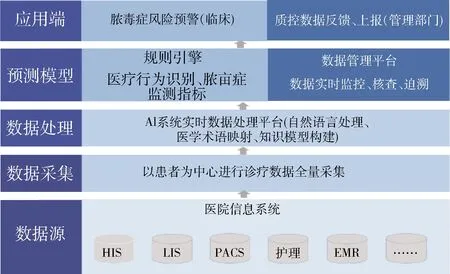
圖2 系統技術架構
3.5 系統驗證
系統上線前先組織臨床醫生通過人機評分對比方式對系統自動完成的SOFA評估結果進行審核,以判定系統評估準確性(目標值為95%以上)。人工評測流程主要包括4個步驟:一是選擇臨床經驗豐富的ICU科室醫生作為系統評分驗證人員;二是在ICU科室真實臨床環境中選擇數據記錄較完整、準確的住院患者,進行SOFA各項變量的AI評估準確性評測(與人工評估一致即視為準確);三是將系統完成的每個ICU患者SOFA評估細項結果導出成表,逐項人工審核;四是經系統驗證人員審核,對系統評估錯誤與遺漏情況進行匯總統計,提交給系統研發團隊分析問題產生根源,制定解決方案優化算法。在本次研究中共進行了兩輪系統測評,每次選擇10位ICU住院患者進行SOFA評估。其中第1輪測評結果顯示,SOFA評估表中的循環系統、呼吸系統、腎臟系統相關變量評估準確率為100%,平均準確率為76%;經過問題查因與算法優化后,第2輪評測除血小板評估準確率90%外,其余變量評估準確率均為100%,平均準確率為98.75%。經過持續算法優化后,系統準確率不斷提升。
4 結果
4.1 事中質量評價
患者入院后,在醫生書寫病歷過程中系統自動對接醫院信息系統中的患者臨床數據,挖掘與監測指標相關聯數據,通過qSOFA指標實時評估,幫助醫生鑒別出疑似感染患者;通過預警SOFA指標分值變化,幫助臨床密切關注患者死亡風險,實現每2小時重復評分;通過對臨床做出診斷等個性化管理,實現ICU、非ICU科室膿毒癥早期診斷。由于系統知識庫已納入膿毒癥相關疾病知識與評估表,醫生需要查詢文獻資料、實施GCS評分等,可直接在系統上操作,提升工作便捷性。
4.2 質控數據統計
系統上線前醫院管理者對感染患者SOFA指標是否有漏評,診斷是否及時等情況難以實時了解,依靠強大算法能力,系統能夠實時統計匯總全院、科室、醫生膿毒癥風險管理情況,支持對各項指標進行縱橫向比較,幫助醫院醫務處、科室管理者實時獲悉重點患者相關指標評估、會診等情況,實現精細化疾病管理并相應地改進質量管理方案。
5 結語
系統在全院推廣使用前,先選定ICU作為試點科室,經過前期臨床效果驗證與知識模型迭代優化,再逐步增加應用科室以提高臨床接受度。同時采取電子卡控方案,促使醫生及時確認系統評估結果和補充診斷,提高指南依從性。此外在系統實施與運行過程中,可采取3個策略進行數據治理,為系統應用提供高質數據:一是對數據采集所在醫院信息系統的技術框架和成熟程度進行調研,確定數據治理具體技術;二是與系統研發團隊合作,制定數據質量標準,例如數據邏輯標準、病歷文書結構化標準等,利用目前市場上已有的數據治理工具對數據進行自動化校驗,從病歷內容覆蓋率、準確率多維度提高數據質量;三是結合人工標注提升病歷數據后結構化精準度。通過形成智能應用與數據基礎的治理循環,相互發現問題、優化改進。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
