深度學習訓練數據分布對植物病害識別的影響研究
2022-08-13 07:10:30王宏樂王興林李文波葉全洲林涌海
廣東農業科學 2022年6期
王宏樂,王興林,,李文波,葉全洲,林涌海,謝 輝,鄧 烈
(1.華南理工大學環境與能源學院,廣東 廣州 510006;2.深圳市豐農控股有限公司,廣東 深圳 518055;3.深圳市五谷網絡科技有限公司,廣東 深圳 518055;4.深圳市宇眾物聯科技有限公司,廣東 深圳 518126)
【研究意義】在植物病害智能識別技術的研究中,傳統的機器學習技術已有了不錯的識別效果,新出現的深度學習技術進一步推進了植物病害識別技術的發展,并成為該領域研究的熱點。關于深度學習技術用于植物病害識別已有諸多報道,目前已報道了約20 種作物上的數百種植物病害的智能識別,識別準確率高達90%以上[1-3]。但是,這類模型多數使用實驗室場景下的標準病害圖片作 為訓練集,其建立的病害識別模型應用到田間識別時,識別準確率降至6%~45%之間[1,4-5]。作為訓練集的實驗室場景圖片大多背景一致,拍攝角度差別不大,采集方法和數據相對標準一致,這類圖片具有清晰的病害特征,有利于模型訓練中的病害特征學習;而應用場景的田間場景圖片往往情況復雜,存在不同光線、角度和病害特征清晰度不同等問題,采集技術和標準較難統一,病害特征不顯著,背景因子干擾較大,因而對田間場景圖片的識別率較低[1,6]。如何優化植物病害識別深度學習模型,從而跨越實驗室和田間不同場景的鴻溝,增強模型魯棒性,以實現深度學習模型在田間實際場景下的穩定且準確識別,成為迫切需要解決的問題。
【前人研究進展】關于模型優化的相關報道有很多,目前普遍認為可以通過兩個方面對深度學習訓練的病害識別模型進行優化,包括對算法的優化及訓練數據的優化。至今,已有諸多關于通過優化算法提高識別率的報道,其中主要包括數據增強、數據均衡、訓練模型和參數優化等方法。Fuentes 等[7]通過對靶標植物病蟲害數據進行標注和特征提取來進行數據增強,提高模型識別率約30%,可同時解決實際應用場景中的9 種番茄常見病蟲害識別問題,該方法可以降低背景干擾,同時解決田間識別中存在的多標簽問題。Perez 等[8]建立了一個基于神經網絡的數據增強模型,可以提高約7%的識別率。Montalbo 等[9]對大粒咖啡病蟲害識別模型進行優化,通過調整深度學習中的參數和超參數來解決過擬合問題。Fuentes 等[10]采取前人報道的方法對網絡結構進行修改,大大減少了識別結果的假陽性,識別率提升達13%。還有研究者通過運用雙邊分支網絡(Bilateral-Branch Netwo rk,BBN)解決了數據不均衡問題,可提升精度5%以上[11-12]。在訓練數據優化方面也有一些報道:Monhanty 等[1]研究發現,使用彩色圖片或是去除背景的圖片訓練集得到的模型較使用灰度圖片訓練集得到的模型的識別率高3%~6%;Lee 等[5]嘗試通過優化數據集,合并不同作物相同病害的數據用于模型訓練,模型對實驗室場景圖片的識別率雖略有降低,但對田間場景圖片的識別率遠高于傳統作物-病害模型,并且可以識別未經訓練作物的相同病害。總體而言,通過 優化數據集實現病害識別模型優化的研究較少,在該方向還可開展更多的探索。
【本研究切入點】農作物病蟲害發生存在周期性。從采集困難程度來說,實驗室場景圖片收集往往較為容易,收集成本低廉,但是病癥的多樣性反映不足;田間場景圖片可以較好反映病害的癥狀表現和多樣性特征,但采集周期性較長,場景復雜,費用高昂。目前普遍反映基于實驗室場景圖片建立的病害識別模型準確率存在嚴重不足,無法滿足農業生產和數字農業的需求。【擬解決的關鍵問題】本研究結合已報道的人工智能深度學習技術在植物病蟲害識別的應用方法,通過調整模型訓練集不同來源數據組成用于模型訓練來優化模型,從而減少深度學習模型對田間場景數據的依賴,縮短模型建立初期對田間數據采集周期,降低田間數據采集成本,同時提高深度學習病蟲害識別模型在實際運用中的準確率、適用性和穩定性,為人工智能深度學習技術進一步運用于智慧農業的病蟲害防治提供理論和實踐基礎。
1 材料與方法
1.1 數據集
本研究所用數據集為包含3 組感染病害的葉片和1 組用于組內對比的健康葉片,共計5 720 張圖片,其中5 200 張用于訓練集,520 張為測試集。訓練集包含柑橘黃龍病1 200 張,蘋果黑星病1 200 張,芒果細菌性斑點病800 張,以及健康芒果葉片2 000 張;測試集包含病害圖片數量為該類別所對應的訓練集圖片數量的10%;訓練集和測試集中,來源于實驗室和田間采集的數量相等。圖片部分來源于Plant Village 數據集[13],其余為田間和實驗室采集,圖片情況見圖1。所有數據集的圖片壓縮為224×224 像素大小后用于訓練、測試及驗證。

圖1 訓練集圖片樣例Fig.1 Image samples of training datasets
1.2 深度學習模型訓練實驗設計
不同的神經網絡模型在植物病害分類任務中的表現有所不同,選擇合適的神經網絡模型架構可提高模型的識別率。本研究結合前人研究成果[1-7],選擇Split-Attention Networks(RestNeSt-50)[14]、Visual Geometry Group Network-16(VGG-16)[15]和Residual Network-50(ResNet-50)[16]3 種深度學習模型架構用于模型訓練。這3 種模型均在ImageNet 數據集上進行預訓練。本研究使用遷移學習(Transfer Learning)的方式進一步對模型進行訓練。為避免訓練過程中數據分布發生改變,采取全部采樣的方法,即全部數據均參與訓練,每張圖片僅采樣1 次。
1.2.1 圖片總數不變的訓練集內2 種場景數據分布對模型識別率的影響 在訓練集圖片總張數不變的情況下,通過調整訓練集的實驗室場景和田間場景圖片的比例,探索訓練集內不同來源數據集分布對模型識別率的影響。本實驗設計5 組圖片數量相同而數據分布不同的訓練集:F0 數據分布為實驗室場景圖片占比100%的情況;F30為實驗室場景圖片占比70%、田間場景圖片占比30%的情況;F50 為實驗室場景與田間圖片占比各50%的情況;F70 為實驗室場景圖片占比30%、田間場景圖片占比70%的情況;F100 的數據分布為田間場景圖片占比100%的情況。
1.2.2 圖片總數增加的訓練集內2 種場景數據的分布對模型識別率的影響 通過在一種場景圖片條件下逐漸增加另一種場景的數據集圖片,探索數據集分布改變對識別率的影響。本實驗分別設計了在訓練集的全部實驗室場景圖片中逐漸添加田間場景圖片的情況(LF),以及在訓練集的全部田間場景圖片中逐漸添加實驗室場景圖片的情況(FL),每組設計5 個添加梯度。在實驗室場景圖片中添加田間場景圖片,添加圖片數量的梯度占比分別為0%(LF0)、30%(LF30)、50%(LF50)、70%(LF70)和100%(LF100);在田間場景圖片中添加實驗室場景圖片,添加圖片數量的梯度分別為0%(FL0)、30%(FL30)、50%(FL50)、70%(FL70)和100%(FL100)。
本研究使用3 種不同的深度學習網絡結構進行模型訓練,根據數據添加情況不同,將通過在實驗室場景圖片中梯度添加田間場景圖片的數據集訓練得到的模型歸類為ResNeSt50-LF、VGG16-LF 和ResNet50-LF;以及將通過在田間場景圖片中梯度添加實驗室場景圖片的數據集訓練得到的模型歸類為ResNeSt50-FL、VGG16-FL和ResNet50-FL。
1.2.3 訓練參數 本研究使用PyTorch 深度學習框架,計算平臺為一臺臺式計算機,操作系統為Ubuntu 18.04 LTS 64 位系統,配有單塊型號為NVIDIA V100s 的圖形處理器(GPU),搭載Intel Core i5-7500 CPU,內存為 32 GB。訓練過程中所有層的參數均設為可學習,批處理設為32,輸入圖像統一為224×224 分辨率,總訓練周期數為150,同時使用衰減權重為0.0005,動量為0.9的隨機梯度下降(Stochastic Gradient Descent)作為優化器。初始的學習率設置為0.01,學習率調整策略使用帶熱重啟的隨機梯度下降(Stochastic Gradient Descent with Warm Restart)[17-19],退火方式使用余弦退火[20]。為使結果便于相互比較,所有模型訓練使用的超參數(hyper-parameters)相同。
1.3 模型評價
為了評價模型的優劣,以及評價模型是否存在過擬合,我們將實際訓練集按80-20(訓練集的80%用于訓練,剩余20%用于驗證)分為訓練集-驗證集,驗證集的數據分布情況與訓練集一致。本研究另外準備520 張測試集,由相同數量的實驗室場景圖片及田間場景圖片組成。本研究對每組實驗的平均F1 分數、平均損失值(Loss)、準確率以及總精度進行計算[1]。
2 結果與分析
2.1 圖片總數不變的訓練集內2 種場景數據的分布對模型識別率的影響
分別使用RestNeSt-50、VGG-16 和ResNet-50等3 種網絡結構對5 組圖片總張數相同而場景分布不同的訓練集數據進行訓練,并使用與訓練數據分布一致的驗證集數據進行評價。結果表明,在3 種網絡結構中,使用100%由實驗室場景圖片組成的訓練集F0 訓練得到的模型的平均F1 分數皆最高,平均損失值皆最小,在RestNeSt-50、VGG16和ResNet-50上平均F1分數分別為0.9988、0.9981和0.9979,平均損失值分別為0.0011、0.0048和0.0022(圖2)。
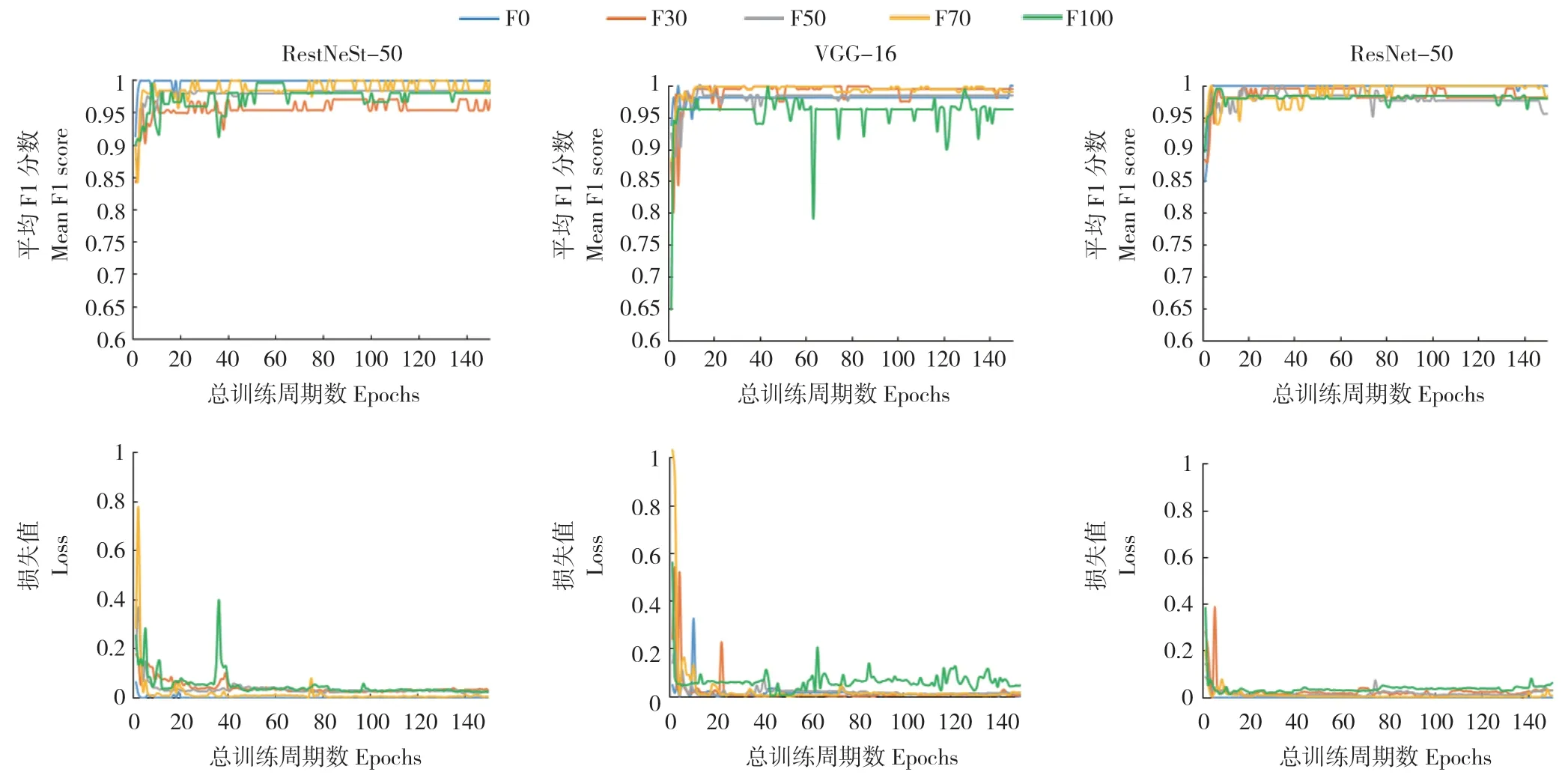
圖2 不同植物病害識別模型在驗證集上的平均F1 分數與損失值Fig.2 Mean F1 score and loss of different plant diseases recognition models on validation sets
使用實驗室場景與田間場景圖片比例為1∶1的測試集對訓練得到的模型進行評價,結果顯示,準確率最低的為僅使用實驗室場景圖片訓練集(F0)訓練的模 型,在RestNeSt-50、VGG-16和ResNet-50 上的總精度分別為73.00%、78.67%和73.33%;3 組模型在實驗室場景圖片的測試集上表現較好,準確率均在90%以上,但對田間場景的測試集的識別準確率約為50%。隨著田間場景圖片的比例增加,模型對測試集數據的識別準確率提升緩慢。除訓練集F0 訓練的模型外,其他各組的總精度都在90%以上。使用實驗室場景圖片和田間場景圖片比例為7∶3 的訓練集(F30)訓練的模型,在RestNeSt-50、VGG-16和ResNet-50 上的總精度分別為96.67%、97.33%和93.33%,相對于F0 有大幅度提升。使用實驗室場景圖片和田間場景圖片比例相等的訓練集(F50)訓練的模型,在RestNeSt-50、VGG-16和ResNet-50 上的總精度分別為96.00%、98.67%和97.67%。使用實驗室場景圖片和田間場景圖片比例為3∶7 的訓練集(F70)訓練的模型,在RestNeSt-50、VGG-16 和ResNet-50 上的總精度分別為98.00%、98.33%和98.00%。使用僅含有田間場景圖片的訓練集(F100)訓練的模型,在RestNeSt-50、VGG-16 和ResNet-50 上的總精度分別為95.67%、97.67%和95.67%。綜上所述,使用僅含有實驗室場景的圖片作為訓練集時,模型對田間場景圖片識別準確率很低,且總精度最低;僅使用田間場景來源的圖片作為訓練集時,模型對實驗室場景圖片識別準確率可達90%以上;訓練集內田間場景的圖片比例增加可以提高模型的準確率,訓練集含30%的田間場景圖片比例即可大幅度提升模型在測試集上的準確度(圖3)。
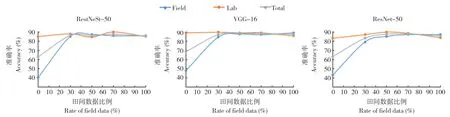
圖3 不同植物病害識別模型在測試集上的識別準確率Fig.3 Accuracies of different plant diseases recognition models on test sets
2.2 圖片總張數增加的訓練集內2 種場景數據的分布對模型識別率的影響
在實驗來源數據中按比例添加田間場景數據,F1 分數先下降再上升,損失值先上升后下降。當添加田間場景圖片為實驗室場景圖片數量的0% 時(LF0),在RestNeSt-50、VGG-16 和ResNet-50 上平均F1 分數分別為0.9988、0.9981和0.9979,損失值分別為0.0011、0.0048 和0.0022。當添加田間場景圖片數量為實驗室場景圖片數量 的50% 時(LF50),RestNeSt-50、VGG-16和ResNet-50 的平均F1 分數達到最低值,分別為0.9693、0.9695 和0.9773;損失值達到最高,分別為0.0826、0.0652 和0.0612。而后隨著訓練集內田間場景圖片數量的增加,F1 分數開始上升,損失值開始下降。當添加田間場景圖片數量為實驗室場景圖片數量的100%時(LF100),在RestNeSt-50、VGG-16 和ResNet-50 上平均F1 分數分別為0.9922、0.9881 和0.9953,損失值分別為0.0094、0.0119 和0.0075(圖4)。
在田間來源數據中添加實驗室場景數據,F1 分數隨圖片數量增加上升,損失值也隨之下降。當添加實驗室場景圖片數量為田間場景圖片數量的0% 時(FL0),在RestNeSt-50、VGG-16 和ResNet-50 上平均F1 分數分別為0.9806、0.9597 和0.9659,損失值分別為0.0309、0.0643 和0.0673。隨著添加的實驗室場景圖片數量增加,3 組模型的平均F1 分數均隨圖片數量增加上升,損失值也均隨之下降。當添加實驗室場景圖片數量為田間場景圖片數量的100%時(FL100),在RestNeSt-50、VGG-16 和ResNet-50 上平均F1 分數分別為0.9922、0.9881 和0.9953,平均損失值分別為0.0094、0.0119 和0.0075(圖4)。
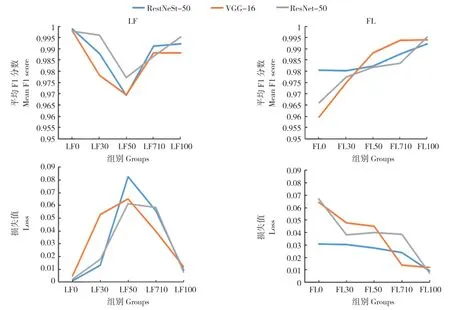
圖4 訓練集數據集改變對植物病害識別模型在驗證集上的平均F1 分數與損失值的影響Fig.4 Mean F1 score and loss of plant diseases recognition models of the training with different datasets on validation sets
使用實驗室場景與田間場景來源圖片比例為1∶1 的測試集對上述模型進行評價。LF0 在RestNeSt-50、VGG-16 和ResNet-50 上的總精度分別為73.00%、78.67% 和73.33%;LF30 在RestNeSt-50、VGG-16 和ResNet-50 上的總精度分別為97.33%、96.00%和97.33%,相比LF0 有大幅度提升。FL0 在RestNeSt-50、VGG-16 和ResNet-50 上的總精度分別為95.67%、97.67%和95.67%;FL30 在RestNeSt-50、VGG-16 和ResNet-50 上的總精度分別為97.33%、97.00%和97.00%;FL100 在RestNeSt-50、VGG-16 和ResNet-50 上的總精度分別為99.33%、98.00%和99.33%,相比FL0 有小幅度提升。總體而言,模型的識別總精度隨圖片數量增加而增加;當在100%實驗室場景圖片訓練集內增加30%的田間場景圖片,模型總精度明顯提高;當訓練集增加的另一種場景圖片數量為原先場景圖片數量的70%~100%時,總精度趨于穩定(圖5)。
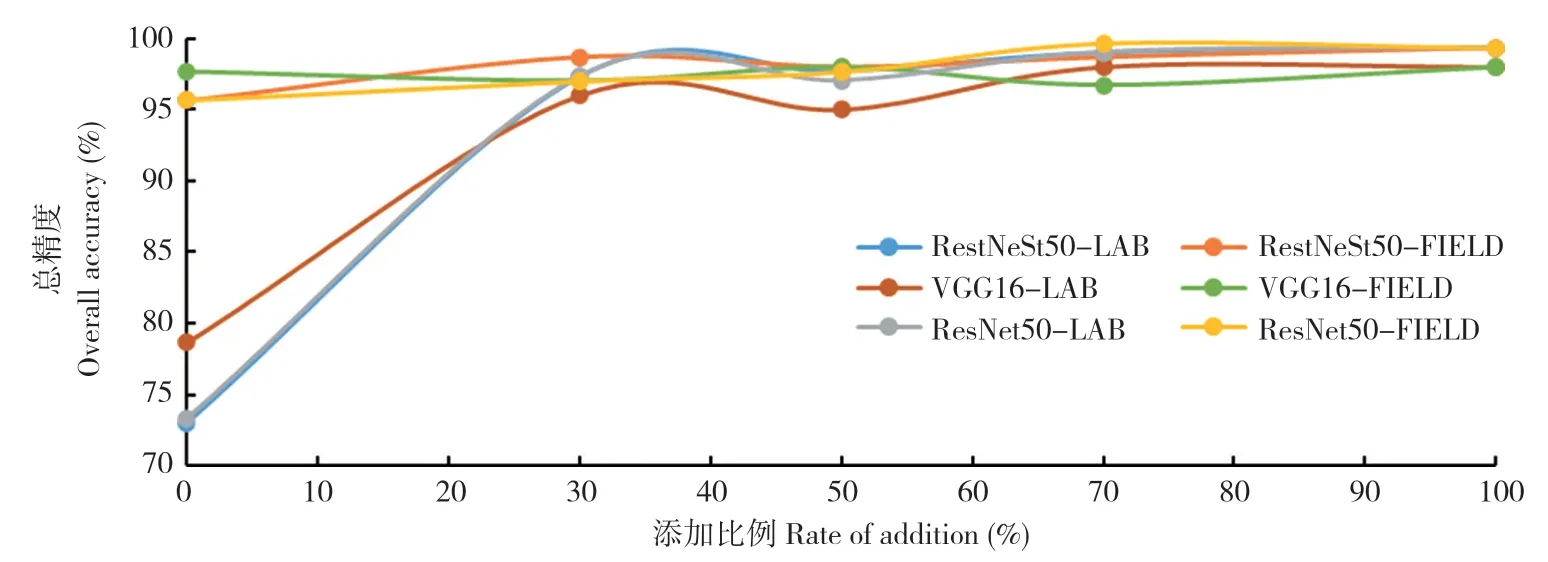
圖5 訓練集數據集改變的不同網絡結構在測試集上的識別準確率Fig.5 Recognition accuracies of different network structures change by the training datasets on test sets
3 討論
諸多研究表明,建立高精度的深度學習病害識別模型,需要大量的作物病害及健康數據,其中健康作物的數據有利于增強深度學習模型對病害特征的學習[1,5],如已報道的Plant Village 數據集[13]包含38 種作物感病-健康配對數據。但健康作物的數據并非必要存在,以Plant Village數據集為例,其中的柑桔黃龍病以及南瓜白粉病并無相應健康作物數據與之配對。另有報道稱將不同作物的相同病害或健康數據進行合并,能夠提高深度學習模型對田間病害識別的準確率[5]。本實驗設計時,曾考慮病害識別模型對不同作物不同病害的特征識別(柑桔、蘋果、芒果),以及同一作物健康與感病情況的區分(健康芒果與芒果細菌性斑點病)。本實驗結果表明,通過調整數據分布的方法,模型對不同的作物病害以及同一作物的不同類別的識別均有提升。目前本方法所應用的數據集偏小,有待進一步放大數據集,同時擴大應用和優化范圍。
實驗室場景采集到的圖片往往具有一定的采集標準,其圖片的病害特征清晰,且大多背景一致,拍攝角度差別不大,而田間場景圖片往往情況復雜,采集標準較難統一,采集時存在不同光照強度及角度,背景復雜多變,因而模型對田間場景圖片識別的準確率往往較低。諸多報道表明,僅使用以實驗室場景圖片訓練的模型,對實驗室場景圖片識別的準確率多在90%以上[1,3-7,9-10],而對田間場景圖片識別的準確率大大低于實驗室場景圖片[1,4-5],本研究也得到相同結果。Lee 等[5]研究表明,使用以田間場景圖片訓練的模型用于實驗室場景圖片識別,其準確率約為60%,本研究獲得的準確率略高于該報道。基于此,本研究認為,訓練集場景過于單一不利于建立農業生產復雜環境下的識別模型。調整訓練 集內不同場景圖片數據的比例,是提升病害識別模型準確率和魯棒性的一個行之有效的方案。
因而,在基于深度學習的植物病害識別模型中,訓練集的圖片類型對模型的識別準確率十分重要。Fuentes 等報道了可識別29 種植物病害模型訓練及準確度的測試結果,通過比較訓練集內不同病害種類不同場景圖片的分布,認為訓練集為混合場景圖片數據的,病害類別識別準確率整體優于單一場景照片訓練集數據[10]。本研究也得到相似的結果,進一步證實了訓練集使用混合場景圖片數據更有利于提升病害識別模型在田間場景下的識別準確率。
在植物病害識別模型研究中,ResNet-50 和VGG-16 是最為常見的深度學習網絡結構[1-7]。ResNet-50 解決了梯度彌散問題,比VGG-16 具有更高的預測精度[21-25]。ResNeSt-50 為2020 年報道的拆分注意力深度學習網絡結構,具有不錯的預測精度[16]。近年來,該網絡結構逐漸運用于植物病蟲害識別領域,已報道的有木薯病害識別、無人機采集的玉米草地貪夜蛾危害狀識別及水稻病害識別等,預測精度均優于其他網絡[25-27]。在本研究結果中,3 種網絡結構的總精度差別不大,變化趨勢基本一致,VGG-16 的預測總精度稍低于ResNet-50 和ResNeSt-50,ResNeSt-50 的預測總精度略優于ResNet-50。本研究側重于研究不同場景的數據分布對深度學習模型準確率的影響,獲得了較好的效果,為建立更加科學、高效的病害識別模型提供了重要參考和借鑒。今后還將結合實際生產應用需要,增加數據量和場景差異性,進一步對病害識別模型進行改進、優化與驗證。
4 結論
本實驗通過調整實驗室和田間場景的病害圖片的配比,使用3 種不同的網絡結構分別進行訓練,以了解數據結構變化對病蟲識別模型準確率的影響,結果表明:(1)在數據集數量不增加的情況下,通過調整不同場景數據比例,對訓練得到的模型的準確率存在影響,當田間場景圖片比例達到30%時即可大幅度提升模型的準確率。(2)訓練圖片數量的增加可以提高模型的識別準確率。在實驗室場景圖片中增加30%的田間場景圖片,即可大幅度提升模型準確率。在田間場景圖片中增加實驗室場景圖片,對模型的準確率有一定提升,但提升幅度不大。(3)通過在訓練集為實驗室場景圖片中增加田間場景圖片的方法,得到的病害識別模型對實驗室場景和田間場景圖片均具有相當的識別準確率。
綜上所述,該方法適用于農業復雜環境下的高準確度植物病害識別模型的快速建立,可以減少深度學習模型對田間場景數據的依賴,縮短田間數據采集周期,降低田間數據采集成本,同時提高深度學習植物病害識別模型在實際運用中的準確率、適用性和穩定性,為人工智能深度學習技術進一步運用于智慧農業的病蟲害防治提供理論和實踐基礎。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
電子競技(2020年4期)2020-07-13 09:18:06
數學物理學報(2020年2期)2020-06-02 11:29:24
電子競技(2020年2期)2020-04-14 04:40:38
電子競技(2019年22期)2019-03-07 05:17:26
電子競技(2019年21期)2019-02-24 06:55:52
電子競技(2019年20期)2019-02-24 06:55:35
電子競技(2019年19期)2019-01-16 05:36:09
光學精密工程(2016年6期)2016-11-07 09:07:19
