基于卷積神經網絡的高通量藍相液晶識別
2022-08-13 12:20:38張亞倩崔永豐何萬里李宇展
液晶與顯示 2022年8期
關鍵詞:模型
張亞倩,崔永豐,王 浩,何萬里,張 磊,楊 洲,曹 暉,王 冬,李宇展
(北京科技大學 材料科學與工程學院,北京 100083)
1 引言
藍相(Blue phase)是液晶中具有特殊性質的一個相態,是各種膽甾相液晶在稍低于清亮點時存在的熱力學穩定相。它是介于膽甾相和各向同性相狹窄溫度區間(約0.5~2 ℃)的一種相態,由于通常呈現藍色,故稱藍相[1]。由于選擇性反射,迄今為止,所有已知的藍相在沒有電場的情況下都是光學各向同性的,這是藍相在實際應用中最重要的特性之一[2-5]。
類似于普通棒狀和盤狀液晶能夠應用于顯示以及有機太陽能電池[6]等領域,藍相液晶(Blue phase liquid crystal,BPLC)也可以應用于顯示領域,而且具有寬視角、無需定向層、亞毫秒級的響應速度等優點,因而吸引著國內外眾多感興趣科學家的關注[7-10]。當然藍相液晶用于顯示也存在以下亟待解決的問題:存在的溫度區間過窄,它只存在于各向同性相與膽甾相之間大約0.5~2 ℃的范圍中。雖然隨著聚合物穩定藍相液晶的發現,BPLC 存在的溫度范圍已擴展到-10~50 ℃甚至更寬[11-12],但是仍然面臨著驅動電壓過高,透明度不夠高,長期穩定性不佳等諸多挑戰。由于藍相液晶存在的溫度區間過窄,且在觀察藍相時升降溫的速率非常緩慢,目前關于藍相液晶的檢測都是單通道的,使得不同批次測量的數據很容易產生不同,所以在觀察和記錄不同液晶體系配方藍相的存在溫度區間時,需要花費大量的時間和精力,同樣現有方法無法快速大批量篩選出具有藍相液晶的配比方案,并且藍相液晶檢測對外界條件的變化非常敏感,所以很容易出現誤差。因此,如何在短時間內判斷大量液晶樣品是否具有藍相相態,并且在確認樣品出現藍相之后,獲得其藍相溫域區間成為本領域亟待解決的問題。
隨著信息技術的發展,卷積神經網絡(Convolutional Neural Network,CNN)成為最流行的神經網絡模型,在分類、人臉識別等許多領域取得了長足的進步,并能夠解決各種問題[13]。1998年推出的LeNet 是第一個減少參數數量并能夠從原始圖像自動學習特征的CNN 架構。該模型可用于識別郵局的數字手稿模式和郵政編碼[14]。隨后的AlexNet 被認為是第一個用于分類和識別任務的深層CNN 體系結構,但是訓練過程非常復雜,該模型直到2012 年才被使用[15]。2013 年,在ZFNet 模型(AlexNet 的改進版)上創建了一種可視化技術,即所謂的去卷積網絡[16]。GoogleNet,也稱為Inception-V1,于2014 年推出,該體系結構的主要目的是通過降低計算成本實現高精度[17]。牛津大學的研究人員在2014 年推出了一個名為Visual Geometry Group(VGG)的模型,同時使用較小尺寸的過濾器可以完成與較大過濾器相同的任務,還可以降低計算復雜度[18]。2015 年引入的殘差神經網絡(ResNet)改變了CNN 的產生。在ImageNet 數據集上進行訓練和實施后,甚至比人類識別精度高[19]。隨后推出的Inception-v3是GoogleNet 的改進版,參數數量進一步減少,該模型還使用多級提取,使其執行速度更快[20]。2017 年推出的ResNeXt 是ResNet 和VGGNet 模型的組合,該模型使用了一個簡單的模塊化架構對圖像進行分類,“分割-轉換-合并”策略取代了標準剩余塊[21]。DenseNet 是2017 年推出的用于識別視覺對象的最新、最強大的神經網絡之一。它可以減少梯度計算問題,最小化參數數量,并重用特征[22]。在2017 年推出的Xception 可以被認為是改進后的Inception。Xception 架構是具有殘差連接的深度可分離Conv 段的線性堆棧,理論基礎是卷積神經網絡特征圖中的跨通道相關性和空間相關性可以完全解耦。這個想法比Inception-V3、ResNet-50、ResNet-101、ResNet-152、VGGNet 更有效,表明網絡在計算方面變得更加高效[23]。
基于上述藍相液晶的性質和研究者對于卷積神經網絡結構的優化,本文將機器學習中的圖像識別和分類應用于材料學科,通過將制作好的不同液晶相態的數據集送入到搭建的神經網絡模型中進行訓練學習,進而得到一種機器學習模型。此模型可以實現輸入一張某溫度下液晶相態的圖片,可以輸出此圖片屬于哪種液晶相態,如果將不同溫度下的液晶相態圖片依次輸入到該模型中,則可以判斷得到藍相存在時的溫度區間。同樣地,通過將不同配比的液晶體系在不同溫度下的相態圖片依次輸入到訓練好的神經網絡模型中,則可以得到這一批樣品藍相存在的溫度區間,達到高效快速篩選液晶體系配方的目的。本文通過Labview 軟件調用Python 接口的方式實現了高通量藍相液晶相態的識別和相應藍相溫域的讀取,經過粗略計算,此機器學習方法結合高通量液晶體系制備在識別計算1 000 個樣品點時比普通混配在偏光顯微鏡下觀察測試藍相溫域效率高近100 倍,為藍相液晶的高效快速識別和相應的配方篩選提供了一種新思路,大大節省了人力和時間。
2 實驗
2.1 實驗材料
實驗中采用噴墨打印機高通量制備的不同配比液晶庫作為數據來源。通過攝像機采集降溫時不同溫度下偏光設備中的各樣品相態圖片,截取感興趣區域(Region of interest,ROI)樣品點位置大約30×30 像素大小的圖像進行分類并制作成數據集。該數據集依據液晶相態的顏色和織構信息主要劃分為3 個類別,分別是各向同性相(Isotropic phase)、藍相(Blue phase)、膽甾相(Cholesteric)。每個類別大致由1 000 張圖像組成,總計3 000 張圖像,每個類別分別按照9∶1 的比例制作成訓練集和測試集。圖1 分別為3 種不同相態樣品在偏光顯微鏡下和數據集中截取的圖像展示。


圖1 偏光顯微鏡下(左)和數據集內(右)的部分液晶相態圖像。(a1)~(a2)各向同性相部分圖像;(b1)~(b2)藍相部分圖像;(c1)~(c2)膽甾相部分圖像。Fig.1 Partial liquid crystal phase state images under polarized light microscope(left)and in the data set(right).(a1)~(a2)Images of isotropic phase;(b1)~(b2)Images of blue phase;(c1)~(c2)Images of cholesteric Phase.
2.2 神經網絡模型的搭建和訓練
本模型均在TensorFlow 框架下進行試驗。硬件環境:Inter(R)Xeon(R)W-2123 CPU@3.6 GHz,92GBRAM,NVIDIAGeForceGTX1080GPU,8GBVideoMemory。軟件環境:CUDAtoolkit10.0,cuDNN10.0,Windows10 64 bit,Python3.7,TensorFlow2.0.0。
由于Python 易讀、易維護和用途廣泛等優點,成為了大量用戶所歡迎的的語言。并且Python 提供大量機器學習的代碼庫和框架,在數學運算方面有NumPy、SciPy,在可視化方面有MatplotLib、SeaBorn,結構化數據操作可以通過Pandas。針對各種垂直領域,如圖像、語音,文本在預處理階段都有成熟的庫可以調用,所以在機器學習領域被廣泛使用。圖2 為本文高通量藍相液晶識別的整體流程圖。
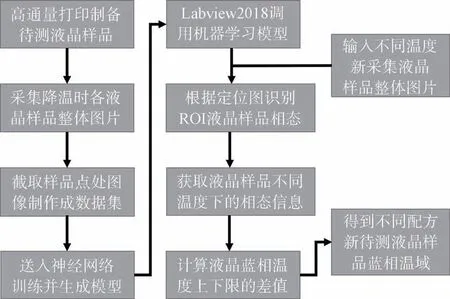
圖2 高通量識別藍相液晶流程圖Fig.2 Flow chart of high-throughput blue phase liquid crystal recognition
本文利用Python 中的模塊提取出數據集中每個圖像的RGB 信息,將訓練信息送入圖3 所示的神經網絡中。該神經網絡利用TensorFlow 框架搭建而成,搭建的神經網絡包括由輸入至輸出依次連接的輸入層、隱藏層、輸出層,輸入層是由訓練集的實例特征向量傳入,輸入的數據為RGB 3 個參數,經過連接節點的權重傳入下一層,在下一層中加權求和,隱藏層設置有3 層,3 層的神經元個數分別為512,1 024,512,每層隱藏層的每個神經元是前一層的所有神經元的權重相加,然后經過非線性激活函數(ReLu 函數)的轉化將輸出作為下一層的輸入,經過多層的訓練學習從而得到神經網絡模型,公式如式(1)所示:
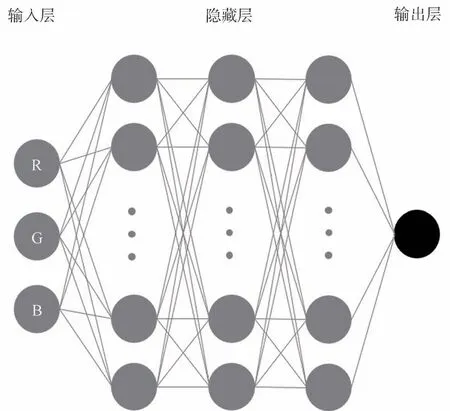
圖3 神經網絡模型示意圖Fig.3 Schematic diagram of neural network model

其中,f(x)為某神經元的值;Aj為該神經元前一層的所有神經元的權重之和,表達式如式(2):
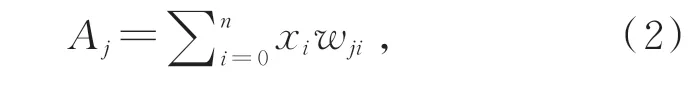
其中,xi表示上一層的第i個神經元,wji表示第i個神經元的權重,權值的初始值可采用任意值。
首先讀取制作好的數據集圖片,并對圖片進行大小尺寸變換,統一設置尺寸為100×100 大小,然后將3 通道的顏色數據值經過歸一化處理壓縮到0~1 之間,數據歸一化可以消除奇異樣本數據導致的不良影響,且會使最優解的尋優過程明顯變得平緩,更容易正確地收斂到最優解。然后將歸一化后的數據作為神經網絡模型的輸入層,依次經過由3 組卷積-池化-舍棄層組成的隱藏層后送入到全連接層,然后再經過舍棄層隨機放棄一部分神經元的更新后進入輸出層返回訓練結果。其中3 組隱藏層的濾波器(卷積核)大小為3,卷積核數量為64,池化區域大小和池化步幅均為2,使用的激活函數為ReLu 激活函數,隨后的全連接層使用的也為ReLu 激活函數,所有的舍棄層均隨機舍棄50%的神經元,最后的輸出層使用Softmax 激活函數,通過此激活函數將輸出值轉換為概率值,則在所有輸出中得分最高的也就是最有可能的類別,可以很直觀地表示分類問題。
在神經網絡中,每次訓練結束都可以得到一個輸出值,通過損失函數(交叉熵)可以對比輸出值和目標值從而監測模型的誤差,交叉熵損失函數公式如式(3)所示:
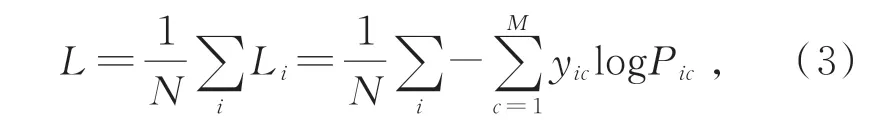
其中,M表示類別的數量,yic表示符號函數(0 或1),如果樣本i的真實類別等于c取1,否則取0,pic表示觀測樣本i屬于類別c的預測概率。
然后根據誤差來調整神經網絡中的權重參數,經過多層訓練學習后,通過不斷調整網絡中的參數使得損失函數達到最小時,輸出值和目標值基本一致,最終得到誤差較小的預期神經網絡模型,證明網絡符合預期,模型穩定可用。本文中模型訓練時使用交叉熵(CrossEntropy)作為損失函數,選擇自適應矩估計(Adam)優化器,學習率設置為0.001,使用GPU 進行訓練,訓練后得到的損失和準確率變化如圖4 所示。
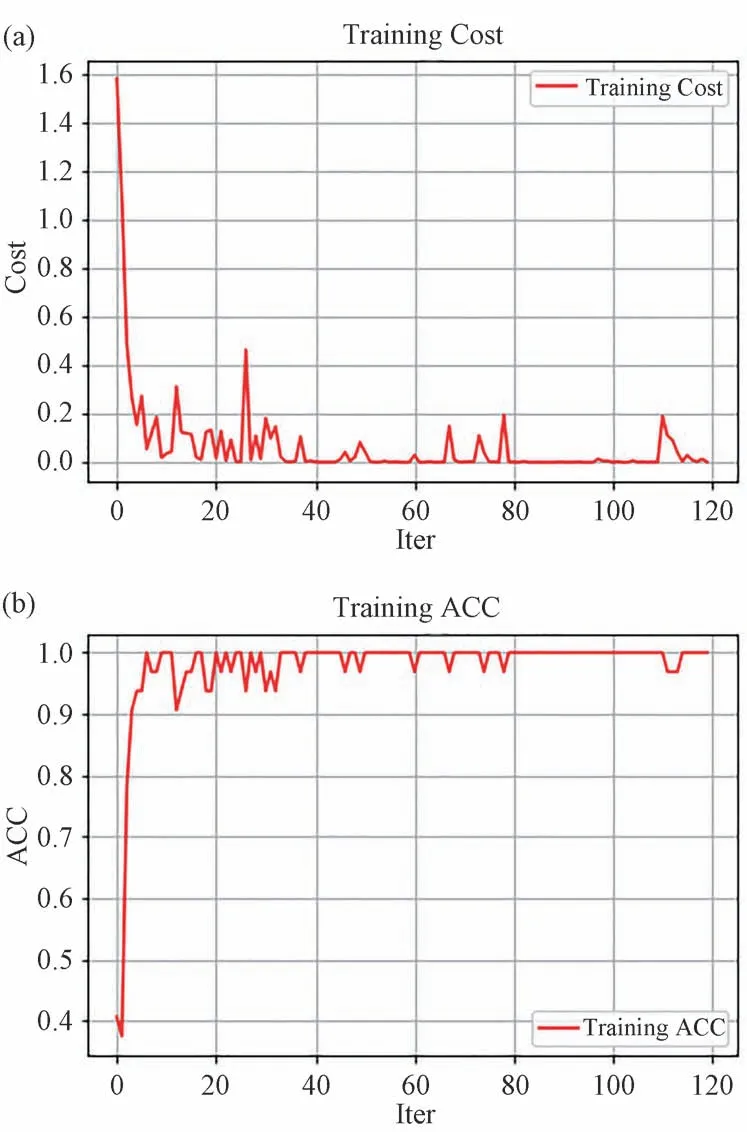
圖4 模型訓練時的損失(a)和準確率(b)變化圖。Fig.4 Loss(a)and accuracy rate(b)change graph of model training.
從模型訓練時的損失圖和準確率圖可以看出,隨著模型訓練迭代輪數的增加,模型的損失越來越小,輸出值與目標值之間的誤差越來越小,在40 輪迭代之后,模型的損失基本趨于穩定;模型的準確率在40 輪迭代之后準確率接近1,并且浮動非常小,說明整體模型在訓練集上表現良好。
2.3 藍相溫域的高通量讀取
Labview 作為一款成熟的工程化應用軟件,為用戶提供了豐富的使用接口。其中Labview2018提供了關于Python 的接口,此接口可以實現對Python 程序的調用,從而將相應的結果輸出。Labview 強大的自動化測試、測量及分析、處理能力非常適用于本實驗中高通量識別和計算,所以利用Labview 調用Python 可以完美地滿足本實驗的需求。
藍相存在的溫度區間即藍相溫域的計算方法為:在降溫過程中,樣品點從各向同性相開始轉變為藍相的溫度作為藍相溫域的起始溫度,藍相轉變為膽甾相的溫度作為藍相溫域的終止溫度,藍相存在的起始溫度與終止溫度的差值即該樣品點的藍相溫域。每個樣品點的藍相溫域計算是通過Labview2018 調用Python 接口來實現的,其中利用Python 模塊進行機器學習模型的訓練,訓練好的模型可以實現給定ROI 位置樣品點的相態識別,并將識別結果輸出。Labview2018通過調用Python 接口得知不同溫度下所述位置樣品點的液晶相態,其中位置的給定是Labview2018 通過識別制作的定位圖中圓的中心坐標來實現的,以定位圖中圓的中心坐標為依據,將其作為樣品點ROI 方形的中心,以此提取每個樣品點的RGB 顏色信息。將提取到的不同溫度下每個樣品點的顏色信息自動讀取到模型中進行識別,識別后依次輸出每個樣品點分別屬于的相態類別,這樣就可以知曉每個樣品點藍相出現的上下限溫度,通過將藍相出現的上下限溫度作差即可得到該樣品的藍相溫域,同時也可以知曉該樣品的清亮點,對各不同配方樣品的篩選具有極其重要的指導意義。圖5 為Labview2018 調用Python 接口基本框架和Python 節點展示。
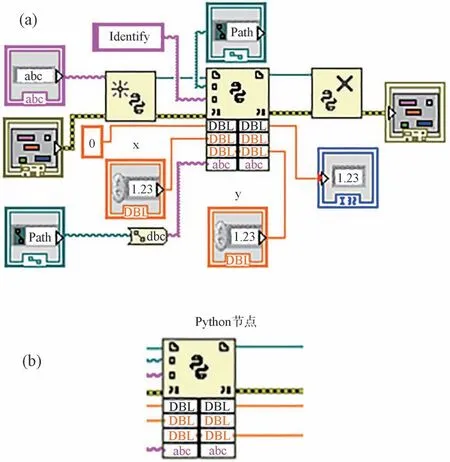
圖5 (a)Labview2018 調 用python 接 口 的基本框架;(b)Python 節點各引腳展示。Fig.5 (a)Basic framework of Labview2018 calls python interface;(b)Display of each pin of Python node.
該Labview 程序實現批量讀取藍相溫域時需要將被調用Python 子程序所在路徑、名稱以及Python 的版本號告知給Labview,通過對Python子程序中識別函數(Identify)的調用,可以實現單個樣品點的相態識別,調用識別函數時同樣需要輸入待識別樣品點的路徑,然后經過建立Labview 中的循環函數結合定位圖中給定的樣品點位置,即可實現高通量樣品的藍相溫域檢測,并且實際識別效率非常高。此Labview 程序在進行識別時可以實時輸出當前樣品序號、坐標位置和樣品相態,最后 依次自動寫入到excel 表格中,方便數據處理和分析,同時可以通過設計多線程程序的方式進一步提高識別效率。
拍攝圖像時,將高通量打印制備好的樣品點置于偏光設備中進行升降溫處理并拍攝各溫度下所有樣品點的相態圖。本實驗共采集了148 張降溫過程中的液晶相態圖像,每張圖像上有1 080 個樣品點,降溫時的平均降溫速率為0.5 ℃/min,總的溫度區間為90~16 ℃。
2.4 實驗結果
利用訓練穩定的神經網絡模型來識別圖片中樣品點處的相態信息,我們將偏光設備中獲得的某溫度下某樣品點真實相態為藍相約30×30大小的圖像輸入到訓練好的神經網絡模型中,結果如圖6 所示,模型可以輸出該樣品點的液晶相態圖片和利用人工神經網絡(Artificial neural networks,ANN)對液晶相態的預測結果。可以看到ANN 對該圖片相態的預測結果為BP,并且預測為BP 的概率接近100%,這與偏光顯微鏡下觀察到的液晶組織相態完全一致。所以測試圖片的樣品點被準確地分類,并且識別時間很短,證明了這種方法對不同溫度下各個樣品點液晶相態的識別和表示是精確且快速的。此外,還可以根據不同溫度下各個樣品點的液晶相態計算出該樣品點的藍相溫域以及清亮點。
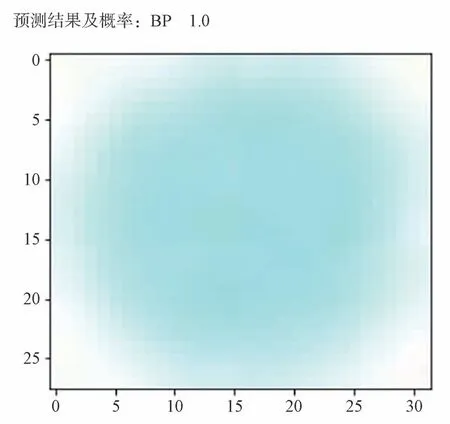
圖6 調用模型識別單個樣品相態結果圖(圖中顯示了識別的結果及概率,BP 表示藍相,1.0 表示識別結果為藍相的概率為1)。Fig.6 Result of calling the model to identify a single sample phase state.The figure shows the recognition result and probability,BP means blue phase,1.0 means the probability of the recognition result being blue phase is close to 1.
圖7 是不同溫度下各個樣品點液晶相態的分類準確率,對角線上的元素是不同溫度下各個樣品點液晶相態被準確識別的準確率,非對角線上的元素是某溫度下某個樣品點的液晶相態和某溫度下其他樣品點的液晶相態混淆的概率。可以看到識別不同溫度下各個樣品點液晶相態的準確率都在93%以上。
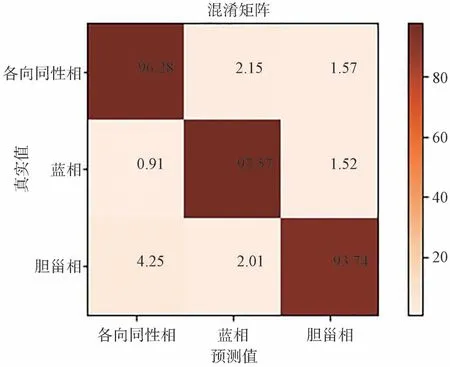
圖7 液晶相態的高通量分類準確率混淆矩陣圖Fig.7 High throughput classification accuracy confusion matrix of liquid crystal phase states
3 機器學習效率
在不考慮手工制樣或者高通量打印樣品所需時間的情況下,我們可以通過簡單的計算得出傳統的手工制作液晶盒測試藍相溫域的方法與高通量打印機器學習識別測試藍相溫域的方法在時間效率方面的差異:
(a)常規方式測試1 080 個樣品需要時間:1 min/(0.5 ℃)(降溫速率)×2×10(藍相平均溫域)×1 080(樣品點數)=21 600 min=360 h=15 天;
(b)高通量打印機器學習識別測試1 080 個樣品需要時間:1 min/(0.5 ℃)(降溫速率)×2×(100-30)(所有點最高到最低溫)+60 min(機器學習識別需要時間)=200 min=3.33 h。
以上計算可以看出兩者之間明顯的差異。高通量打印機器學習識別的方法具有非常高的效率,這種快速識別不同溫度下各個樣品點液晶相態的方法對液晶的應用有著巨大意義,它大幅縮短了測試藍相溫域所需的時間,能夠快速篩選出不同配比下液晶體系中藍相溫域較大的配比,從而指導實驗研究。
4 結論
本實驗將人工神經網絡與高通量噴墨打印制備液晶混合體系相結合,以不同溫度下所述打印液晶體系截取圖像的色度值R、G、B 作為輸入神經元,近3 000 張所述打印液晶體系截圖作為數據集,訓練出一種可以利用偏光設備中攝像機拍攝的圖像來分辨3 種液晶相態的神經網絡模型。液晶相態包括各向同性相、藍相、膽甾相,其中有1 080個不同配比的液晶體系高通量打印在旋涂好的玻璃基板上,通過搭建好的卷積神經網絡來訓練模型,同時使用Labview2018 調用Python接口的方式實現了對不同溫度下液晶相態快速、準確的識別和分類以及藍相溫域的高效準確計算,在實驗過程中對159 840 張樣品點相態圖像的整體識別準確率在93%以上。希望此實驗研究可以為藍相溫域的拓寬以及寬溫域藍相液晶配方的篩選提供一種有效可行的方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
