引入外部知識的社交平臺立場檢測模型
2022-08-25 09:56:38周珂馨周立欣陸嘯塵
軟件導(dǎo)刊 2022年8期
劉 臣,周珂馨,周立欣,陸嘯塵
(上海理工大學(xué)管理學(xué)院,上海 200093)
0 引言
立場是在給定話題下用戶觀點的表達(dá),而立場檢測是自動檢測用戶對于給定話題發(fā)表的評論是支持、反對或者中立[1]。隨著社交媒體的不斷發(fā)展,人們更愿意通過微博、Twitter 及Facebook 等在線社交平臺來表達(dá)自己的觀點立場,發(fā)表對熱門話題的評論,使得從在線評論中自動提取特征信息進(jìn)行立場檢測得到了學(xué)術(shù)界的廣泛關(guān)注[2]。
隨著立場研究的發(fā)展,立場檢測任務(wù)在國內(nèi)的NLPCC及國外的Semeval 等多個競賽中被相繼提出。根據(jù)這些競賽提出的立場檢測任務(wù),有諸多學(xué)者利用該任務(wù)提供的數(shù)據(jù)集構(gòu)建立場檢測模型。如Vijayaraghavan 等[3]首先將給定數(shù)據(jù)根據(jù)立場類別進(jìn)行劃分,然后基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)分別從單詞級和字符級兩個層面構(gòu)建立場檢測模型,最后針對每個類別的數(shù)據(jù)選擇兩個檢測模型中性能最佳的模型進(jìn)行預(yù)測。實驗結(jié)果表明,該方法具有一定的魯棒性,但是采用多個深度學(xué)習(xí)模型的方法存在計算量過大的問題。為了減少計算量,Siddiqua 等[4]提出基于深度學(xué)習(xí)方法的單個立場檢測模型,該模型利用卷積核過濾輸入的評論文本嵌入表征,然后將過濾好的向量分別輸入到基于注意力機(jī)制的雙向長短期記憶網(wǎng)絡(luò)(Bi-LSTM)[5]和嵌入的長短期記憶網(wǎng)絡(luò)(LSTM)[6]中得到特征向量,最后將兩個特征拼接后進(jìn)行分類。該模型通過構(gòu)建基于注意力機(jī)制的長短期記憶網(wǎng)絡(luò)集成模型,從而有效捕獲立場信息。
目前已有研究采用的方法大多是基于評論文本特征的模型,而這些模型無法捕獲到評論與評論之間的網(wǎng)絡(luò)結(jié)構(gòu)關(guān)系[7]。為獲取評論之間的網(wǎng)絡(luò)結(jié)構(gòu)關(guān)系,本文采用門控圖神經(jīng)網(wǎng)絡(luò)(GGNN)技術(shù)捕獲評論的立場特征。此外,還有研究在對評論進(jìn)行數(shù)據(jù)預(yù)處理時,將手動提取的文本特征和預(yù)訓(xùn)練模型(如word2vec、bert 等)獲取的特征向量相結(jié)合,得到評論的表征向量[8]。雖然采用這些方法可有效提高立場檢測的準(zhǔn)確性,但是對于一些給出文本信息不足的評論并不能有效提取特征信息。Kapanipathi 等[9]的研究表明,通過引入外部知識提供評論文本的背景知識,可有效應(yīng)對文本上下文信息有限的問題。因此,本文通過知識圖譜對評論的關(guān)鍵信息引入外部知識,并基于RGCN模型獲取評論的特征表示。
本文訓(xùn)練了一個引入外部知識的門控神經(jīng)網(wǎng)絡(luò)模型KRGGNN,在捕獲評論與評論之間網(wǎng)絡(luò)結(jié)構(gòu)關(guān)系的同時,解決了評論文本可提取信息不足的問題。首先,利用開源的知識圖譜WordNet 針對評論文本關(guān)鍵單詞進(jìn)行外部知識的引入,并將這些知識作為實體構(gòu)建圖模型,然后利用RGCN 獲取推文的文本表征,接下來將評論之間的網(wǎng)絡(luò)結(jié)構(gòu)及相應(yīng)的表征向量輸入到GGNN 中獲取立場信息,最后將最終評論的特征向量輸入到Softmax 層進(jìn)行立場分類。
1 相關(guān)研究
隨著互聯(lián)網(wǎng)信息技術(shù)的發(fā)展,立場檢測任務(wù)在多個競賽中被相繼提出。立場檢測研究方法主要分為以下兩類:
(1)基于特征工程的機(jī)器學(xué)習(xí)立場檢測方法。傳統(tǒng)研究主要采用機(jī)器學(xué)習(xí)方法進(jìn)行文本立場檢測,包括支持向量機(jī)(SVM)、邏輯回歸、樸素貝葉斯以及決策樹等。Kü?ük等[10]針對多目標(biāo)的立場檢測任務(wù),采用SVM 分類器對與體育相關(guān)的3 個不同版本的推文進(jìn)行立場分類,同時在對推文進(jìn)行特征表示時使用了聯(lián)合特征;Addawood 等[11]分別采用SVM、樸素貝葉斯及決策樹對推文進(jìn)行立場分類,同時在構(gòu)建文本特征時結(jié)合了情感、推文論證等多個特征。實驗結(jié)果表明,推文的情感及語氣等對立場分類起著重要影響,基于SVM 的模型在測試集中取得了較好效果。但是,這些研究主要通過人工提取特征構(gòu)建文本特征表示,通過輸入分類器進(jìn)行信息獲取,因此人工成本較高。
(2)基于深度學(xué)習(xí)的立場檢測方法。與傳統(tǒng)機(jī)器學(xué)習(xí)方法不同,基于深度學(xué)習(xí)的方法能夠?qū)ξ谋咎卣鬟M(jìn)行自學(xué)習(xí)與篩選,不僅能減少人力成本,而且能提升模型的穩(wěn)定性。Mohtarami 等[12]利用端到端的方式自動進(jìn)行立場檢測,分別利用CNN 和LSTM 對輸入的推文信息進(jìn)行特征提取,引入相似性矩陣計算與推文目標(biāo)話題或聲明的相關(guān)性,提取與聲明或話題更相關(guān)的文本特征信息。雖然該方法可自動學(xué)習(xí)文本特征,并能獲取有利的文本信息,但其只關(guān)注評論的文本特征,而忽略了評論相互之間的網(wǎng)絡(luò)結(jié)構(gòu)信息。Kochkina 等[13]以社交平臺推文為對象,基于評論之間的相互關(guān)系建立多個分支,并利用LSTM 實現(xiàn)構(gòu)建的評論分支中前后評論之間信息的相互傳遞。該方法將文本特征與推文之間的網(wǎng)絡(luò)結(jié)構(gòu)信息相結(jié)合,可有效地捕獲推文立場信息。Li 等[14]以新聞文章為研究對象,采用Hierarchical LSTM[15]等多種方法,基于圖卷積神經(jīng)網(wǎng)絡(luò)(GCN)對以政治人物、用戶和新聞文章為對象構(gòu)建的圖模型,獲取推文之間的網(wǎng)絡(luò)信息。實驗結(jié)果表明,聯(lián)合文本與網(wǎng)絡(luò)特征進(jìn)行立場檢測的效果明顯優(yōu)于僅利用其中之一的特征進(jìn)行立場檢測。因此,本文在構(gòu)建評論文本特征的基礎(chǔ)上,根據(jù)評論之間的網(wǎng)絡(luò)結(jié)構(gòu)構(gòu)建圖模型,并利用GGNN 獲取評論之間的網(wǎng)絡(luò)結(jié)構(gòu)信息。
針對立場檢測任務(wù),給定評論的文本語言表達(dá)情況對最終分類結(jié)果起著非常重要的影響。然而,目前大多數(shù)研究的關(guān)注重點僅限于給定的評論文本,若遇到文本質(zhì)量不佳或可獲取信息不足的情況,則可能導(dǎo)致最終的預(yù)測效果不佳。Kapanipathi 等[9]將立場檢測轉(zhuǎn)變?yōu)槲谋咎N含任務(wù),利用知識圖譜實現(xiàn)文本外部知識的引入,提取句子內(nèi)外相關(guān)實體構(gòu)建圖模型,并利用RGCN 進(jìn)行分類。Li 等[14]提取句子的有用詞,針對這些詞引入同義詞、上位詞、下位詞等外部信息,并利用注意力機(jī)制對其進(jìn)行編碼,最終進(jìn)行句子分類。以上研究表明,對給定的目標(biāo)對象引入外部知識可有效彌補(bǔ)句子內(nèi)部缺失的信息。本文在進(jìn)行立場檢測前對評論文本進(jìn)行關(guān)鍵詞提取,利用WordNet 知識圖譜檢索與該關(guān)鍵詞有關(guān)的其他詞匯以構(gòu)建知識圖模型,再利用RGCN 進(jìn)行推文特征提取以獲取推文的初始表征。
針對RumorEval 2019 的立場檢測問題,本文不僅將推文的文本特征與網(wǎng)絡(luò)結(jié)構(gòu)相結(jié)合,利用GGNN 進(jìn)行立場檢測,而且在構(gòu)建文本表征時通過引入文本外部知識,獲取基于評論文本的額外背景知識。
2 基于GGNN 并引入外部知識的立場檢測模型
本文利用WordNet 知識圖譜對數(shù)據(jù)集的評論信息引入外部知識,補(bǔ)全評論文本可能缺失的信息。本文提取評論文本中的關(guān)鍵單詞映射到知識圖譜中構(gòu)建節(jié)點,并檢索與該節(jié)點相關(guān)的一階鄰點以獲取全局圖G。為了提取知識圖譜中有價值的信息,通過PPR 過濾方法對該全局圖G提取相關(guān)子圖G′,并利用RGCN 進(jìn)行圖表示學(xué)習(xí),進(jìn)而獲取評論的知識表示。同時,利用門控神經(jīng)網(wǎng)絡(luò)(GGNN)技術(shù)將評論文本特征與評論結(jié)構(gòu)關(guān)系相結(jié)合進(jìn)行立場檢測。具體模型架構(gòu)KRGGNN 如圖1所示。

Fig.1 Stance detection model KRGGNN based on GGNN and introducing external knowledge圖1 基于GGNN并引入外部知識的立場檢測模型KRGGNN
2.1 引入外部知識的評論表示學(xué)習(xí)
2.1.1 基于知識圖譜的評論全局圖構(gòu)建
首先,針對目標(biāo)評論TC進(jìn)行語義信息提取,利用nltk庫對目標(biāo)評論TC進(jìn)行了分詞。從評論TC中提取關(guān)鍵信息所構(gòu)建的單詞集合W如下:

式中,TC為目標(biāo)評論,W為TC中提取的關(guān)鍵單詞集合,wi為在TC中提取的某個關(guān)鍵單詞。
Kapanipathi 等[9]的研究表明,對文本對象引入外部知識可有效捕獲缺失信息并構(gòu)建文本特征表示。為引入與評論相關(guān)的外部知識,需要將評論TC提取的單詞集合W映射到WordNet 知識圖譜,并檢索其他與W相關(guān)的外部單詞。即針對評論TC中的單詞wp,在WordNet詞典中檢索與該單詞有關(guān)的其他單詞,分別為:上位詞、下位詞、同義詞和蘊含詞。
針對評論TC中的單詞wp,從以上搜索空間中檢索外部單詞集合Wp′,并將wp作為圖G的內(nèi)部節(jié)點ip,Wp′作為圖G的外部節(jié)點集合op,且該集合為節(jié)點ip的一階鄰點。
為構(gòu)建關(guān)于目標(biāo)評論TC的全局圖G,將詞集W中所有提取的單詞作為圖G中的內(nèi)部節(jié)點集I,并將引入的外部詞集W′作為圖G的外部節(jié)點集O。由于目標(biāo)評論中各個單詞通過引入外部知識構(gòu)建的子圖是相互獨立的,為充分捕獲評論中所有單詞的相互關(guān)系,對所有子圖構(gòu)建的外部節(jié)點集O和內(nèi)部節(jié)點集I中有關(guān)系的節(jié)點添加連邊e(i,j)=(ni∈I,nj∈O)。在構(gòu)建全局圖G之后,由于引入的外部知識過多會使數(shù)據(jù)集產(chǎn)生很大噪聲,Kapanipathi 等[9]證明了通過節(jié)點過濾方法(PageRank 算法[16])可有效解決噪聲過大的問題。因此,本文需要對全局圖G中的所有節(jié)點進(jìn)行過濾,從而提取一個大小合適,且包含的節(jié)點與評論TC較為相關(guān)的子圖。
2.1.2 全局圖節(jié)點過濾
本文使用PPR 算法對全局圖進(jìn)行節(jié)點過濾,獲得與內(nèi)部節(jié)點最相關(guān)的外部鄰居節(jié)點。針對圖G中的所有節(jié)點,首先需要初始化圖中每個節(jié)點的概率分?jǐn)?shù)p∈P:

式中,I表示圖中的內(nèi)部節(jié)點集合,即評論中的關(guān)鍵單詞集合。針對圖中節(jié)點是評論中的單詞,初始化節(jié)點的概率分?jǐn)?shù)為并且外部節(jié)點的概率分?jǐn)?shù)p為0。從初始的概率分?jǐn)?shù)可以看出,內(nèi)部節(jié)點對于圖G的重要性較高。接下來需要計算圖G中節(jié)點的概率分?jǐn)?shù):
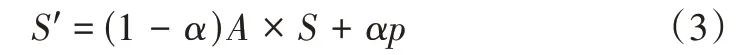
式中,S∈Rn是圖中所有節(jié)點的PPR 分?jǐn)?shù),A∈Rn×n是圖G的鄰接矩陣。α∈(0,1)為衰減因子,通過設(shè)置α參數(shù),可將節(jié)點的PPR 分?jǐn)?shù)在迭代更新后收斂于某一固定值,最終獲取每個節(jié)點的RRP 得分Si∈R。本文設(shè)置一個閾值θ,利用該參數(shù)過濾掉圖G中引入的外部節(jié)點O中Si∈R分?jǐn)?shù)小于閾值的節(jié)點,并刪除連接該節(jié)點的邊。
2.1.3 基于RGCN的子圖編碼
為獲取評論X的向量表示,本節(jié)采用RGCN 方法[17]計算子圖G′的圖表示。該方法是圖卷積GCN 方法的擴(kuò)展,基于該方法可處理不同類型邊的圖模型:

式中,R代表圖G′不同屬性邊的集合,Nu,r表示節(jié)點u連接邊屬性為r的鄰居節(jié)點集合是可學(xué)習(xí)參數(shù)。cu,r是常量,在本文中將該常量設(shè)為,即鄰居節(jié)點個數(shù)。同時,對于圖G′中的每一個節(jié)點都額外添加一條自循環(huán)邊,使得模型在編碼過程中保留節(jié)點自身屬性。本文設(shè)置了兩種類型的邊,分別為自循環(huán)邊以及圖G′中節(jié)點之間的連邊。
最后,對于圖G′中每個節(jié)點的隱藏表示hv,需要將其聚合形成基于TC評論的圖表示:

其中,V是圖G′的節(jié)點集合,W為可學(xué)習(xí)參數(shù)。通過將所有節(jié)點聚合形成圖表示,從而獲取評論TC的特征表示。
2.2 模型構(gòu)建
2.2.1 圖模型構(gòu)建
本文采用端到端的方式對評論進(jìn)行立場檢測。在2.1節(jié)中引入外部知識構(gòu)建評論文本的特征表示后,本節(jié)考慮了評論之間的外部結(jié)構(gòu)關(guān)系。鑒于給定數(shù)據(jù)集RumourEval 2019 是以對話線程的形式給出,本節(jié)針對數(shù)據(jù)集給定的對話線程構(gòu)建圖模型,并采用GGNN 技術(shù)捕獲評論之間的結(jié)構(gòu)關(guān)系。首先給出了對話線程的定義:
針對某一特定話題T,S是對該話題發(fā)布的一則原始評論。同時,針對該評論S有一系列回復(fù)Ri,如圖2所示。

Fig.2 Conversation thread and graph model圖2 對話線程與圖模型
在圖2 中,原始評論S被id 分別為6l5b2no、dl5xleh、dl5hnsx 的用戶進(jìn)行了回復(fù),同時用戶dl5xleh 又被用戶dl6bm8l 進(jìn)行了回復(fù)。通過以上用戶之間的互動,將原始評論及用戶之間的所有回復(fù)評論作為一個對話線程,每一條評論都持有對話題T的立場。因此,對話線程由原始評論和多條回復(fù)評論構(gòu)成,即:C<—{Source,Reply1,Reply2,Reply3,Reply4},并且評論與評論之間存在相互關(guān)系。接下來,針對圖2(a)的對話線程構(gòu)建圖2 的圖模型。其中,每個節(jié)點代表一條評論,每一個節(jié)點都帶有立場標(biāo)簽,不同顏色的邊代表不同屬性。
2.2.2 基于GGNN的立場檢測模型
本文采用GGNN[18]實現(xiàn)對話線程評論的信息傳播。利用GRU 單元對目標(biāo)節(jié)點的鄰點進(jìn)行信息傳播。在將節(jié)點的特征表示X∈Rd傳入到GGNN 模型之前,需要針對圖模型構(gòu)建鄰接矩陣A。為了使建立的立場檢測模型可以處理有向異質(zhì)圖,本文考慮到了出入射邊以及邊的類型。接下來是對鄰接矩陣的定義:
假設(shè)圖模型的節(jié)點集合N∈Rn具有r個類型的邊,且深度為m的某一子節(jié)點Ni的父節(jié)點為Nj。對于鄰接矩陣有:


式(8)中,H(1)∈Rn×d為初始化的節(jié)點隱藏狀態(tài),X∈Rn×d為圖模型特征矩陣。在信息傳播之前,用節(jié)點的初始表征X來初始化圖G的隱藏狀態(tài)H(1)。

其中,W1、W2、b1、b2、Wz、Wr、Uz、Ur、W和U為可學(xué)習(xí)參數(shù)。Iin、Iout分別為入出射邊的隱藏表示。通過以上的節(jié)點信息傳播,在迭代了一定的時間步T之后,得到最終所有節(jié)點的隱藏表示,其中d′為節(jié)點輸出維度。
通過將對話線程的初始特征矩陣X∈Rd與最終隱藏表示H(T)進(jìn)行拼接,以保留節(jié)點自身的特征,然后將y∈Rn×c輸入到Softmax 的激活函數(shù)中進(jìn)行立場檢測,將預(yù)測概率最大的評論作為預(yù)測立場:

考慮到本文所解決的問題是一個多分類問題,即支持、否定、評論和中立,本文采用交叉熵?fù)p失函數(shù)來訓(xùn)練模型。
3 實驗與分析
3.1 實驗數(shù)據(jù)集及評價指標(biāo)
本文采用的數(shù)據(jù)集是由Semeval 2019大賽發(fā)布的謠言立場檢測數(shù)據(jù),其中持有支持立場的數(shù)據(jù)有1 184 條,否定的有606 條,質(zhì)疑的有608 條,評論的有6 176 條。數(shù)據(jù)中所有評論信息的立場均是針對氣候變化、自然災(zāi)害等9 個不同主題的突發(fā)事件。
首先對數(shù)據(jù)中的評論文本進(jìn)行數(shù)據(jù)清洗。由于評論文本中存在空白或含有無用字符的情況,本文刪除了這些無用的評論文本,以防止類似情況給模型訓(xùn)練帶來噪聲。預(yù)處理后的數(shù)據(jù)集分布如表1所示。

Table 1 Dataset distribution表1 數(shù)據(jù)集分布
接下來將過濾后的數(shù)據(jù)集作為訓(xùn)練語料庫,用nltk 庫對評論文本進(jìn)行分詞。為了引入外部信息,本文檢索了WordNet 的corpus 中與評論中提取單詞相關(guān)的上位詞、下位詞、同義詞等,利用Glove獲取評論信息的詞向量。
由于本文采用的數(shù)據(jù)集存在嚴(yán)重的數(shù)據(jù)分布不均勻的問題,本文使用宏平均(MacroF1)作為立場檢測模型的主要評估指標(biāo),其余評估指標(biāo)也具有一定參考性。具體公式如下:

其中,P、R、F1 表示單個立場類別的評估指標(biāo),分別為精確率、召回率,以及P和R的調(diào)和平均值。TP、FP、FN、TN分別表示預(yù)測正樣本正確的個數(shù)、預(yù)測正樣本錯誤的個數(shù)、預(yù)測負(fù)樣本錯誤的個數(shù)和預(yù)測負(fù)樣本正確的個數(shù)。宏平均的計算公式如下:
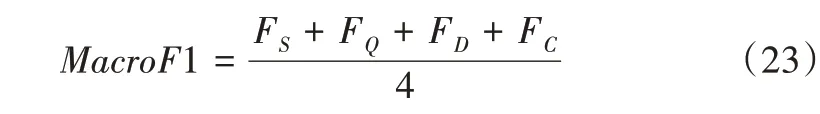
其中,S、Q、D和C表示評論的立場類別分別為:支持、質(zhì)疑、否定和中立。針對多分類任務(wù)而言,對每個評估指標(biāo)求均值得到宏平均MacroF1。宏平均MacroF1 值越高,模型預(yù)測性能越好。
3.2 實驗參數(shù)設(shè)置
通過對比不同參數(shù)值的實驗結(jié)果后,本文設(shè)置詞向量維度為200d。PPR 的閾值θ也被作為超參數(shù)進(jìn)行調(diào)整。本文對θ分別在{0.2,0.4,0.6,0.8}中進(jìn)行實驗取值,實驗結(jié)果表明,當(dāng)θ值為0.8時效果最佳。
接下來將局部子圖輸入RGCN 以獲取每條評論的特征表示,并利用GGNN 捕獲對話線程中評論與評論之間的外部結(jié)構(gòu)關(guān)系。具體實驗參數(shù)設(shè)置如表2所示。

Table 2 Hyperparameters setup表2 超參數(shù)設(shè)置
其中,hidden_size 表示局部子圖輸入到RGCN 中的單詞隱藏層大小,num_bases 表示RGCN 的基向量個數(shù),num_layers 表示RGCN 的堆疊層數(shù)。為了避免數(shù)據(jù)在訓(xùn)練過程中過擬合,本文設(shè)置dropout 值為0.5。n_steps 表示通過對話線程構(gòu)建圖模型時,在GGNN 中進(jìn)行3 次信息傳播。同時,本文通過多次實驗比較,發(fā)現(xiàn)設(shè)置學(xué)習(xí)率為0.001時,模型性能表現(xiàn)最好。
3.3 對比實驗
(1)KGRGCN:是本文提出模型的一個子模型。該模型是基于本文提出的模型KRGGNN 去掉網(wǎng)絡(luò)結(jié)構(gòu)部分。本實驗首先利用WordNet 知識圖譜對原始數(shù)據(jù)引入外部知識,然后利用RGCN 對構(gòu)建的子模型進(jìn)行信息傳播,最后直接利用Softmax 進(jìn)行立場分類。
(2)TreeGGNN:是本文提出模型的一種變體。實驗在數(shù)據(jù)預(yù)處理階段利用word2vec 得到的詞向量取均值,并與其他特征拼接得到評論的初始向量,然后采用GGNN 捕獲立場信息。
(3)CLEARumor[19]:預(yù)處理階段采用ELMo 方法[20],該方法基于雙向長短期記憶網(wǎng)絡(luò)(BLSTM)獲取評論文本的上下文信息,并利用卷積神經(jīng)網(wǎng)絡(luò)模型進(jìn)行立場檢測。
(4)BranchLSTM:基于LSTM 模型對對話線程構(gòu)建的分支架構(gòu)進(jìn)行評論表征向量信息獲取,該模型在充分利用文本表征的同時,也考慮到了評論之間的網(wǎng)絡(luò)結(jié)構(gòu)關(guān)系[13]。
3.4 實驗結(jié)果分析
本文實驗針對社交平臺Twitter 和Reddit 的評論信息進(jìn)行立場檢測。表3 通過將KRGGNN 立場檢測模型和其他基準(zhǔn)模型進(jìn)行比較來驗證本文模型的有效性。其中,采用MacroF1 和Precision 進(jìn)行模型性能評估。從表3 中可以看出,KRGGNN 模型在所有模型中,宏平均和精準(zhǔn)度都最高。相較于其它模型,CLEARumor 模型的整體評估性能最差,因為該模型只利用文本的上下文信息,并沒有充分從給定文本中提取立場信息。TreeGGNN 模型在評估指標(biāo)的性能表現(xiàn)上與KRGGNN 相當(dāng),表明在考慮文本特征的同時,GGNN 能有效提取評論之間的網(wǎng)絡(luò)結(jié)構(gòu)關(guān)系。同時,KRGGNN 的性能優(yōu)于TreeGGNN,說明利用知識圖譜引入外部知識可更加充分地捕獲評論的文本特征信息,為立場檢測模型提供更準(zhǔn)確的評論初始表征。
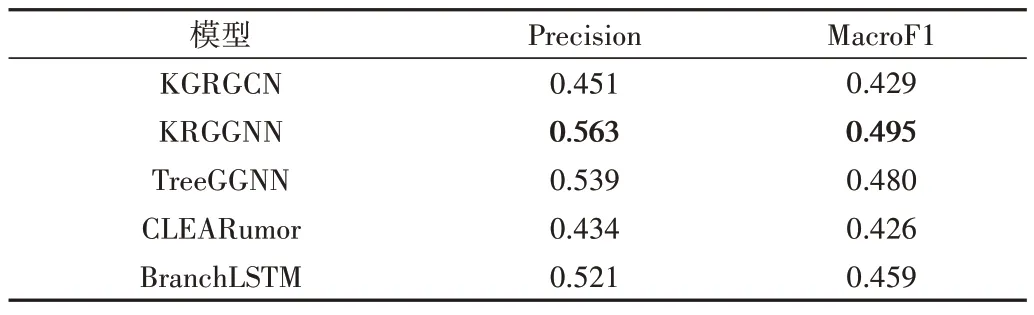
Table 3 Comparison of the evaluation metrics of each model表3 模型各項評估指標(biāo)比較
表4 為各個模型基于4 個立場類別的F1 分?jǐn)?shù)。由表可知,“否認(rèn)”的評估分?jǐn)?shù)在所有模型中明顯低于其他類別,可能存在兩方面原因:①原始數(shù)據(jù)集分布不均勻,“否認(rèn)”的數(shù)據(jù)與其他數(shù)據(jù)的比例為1:11,這也導(dǎo)致模型對其他類別數(shù)據(jù)具有一定偏見,并對該類別的數(shù)據(jù)訓(xùn)練不足;②針對給定的“否認(rèn)”評論文本,一般表現(xiàn)為含蓄地表達(dá)否定的想法,因此文本語氣以及表達(dá)方式對模型能否精準(zhǔn)提取有效信息具有非常重要的作用。同時,相比于其他baseline,雖然本文模型存在某些類別的F1 分?jǐn)?shù)不如其他模型的情況,但其在各個類別中的性能與其他模型相比較為平均。因此,本文模型相比其他模型存在更少的偏見,泛化能力更強(qiáng)。

Table 4 Comparison of F1 scores of each model表4 各個模型的F1分?jǐn)?shù)比較
鑒于數(shù)據(jù)集是由Reddit 及Twitter 兩個平臺的數(shù)據(jù)集構(gòu)成,本文進(jìn)一步探討了平臺數(shù)據(jù)對模型的影響,如圖3所示。
實驗結(jié)果表明,模型對Reddit 平臺數(shù)據(jù)集的評估性能基本優(yōu)于Twitter,可能的原因為Reddit 平臺用戶在發(fā)表評論時較為正式,而Twitter 平臺的評論較為口語化,導(dǎo)致模型相較于Twitter 平臺而言,更易于從Reddit 平臺評論中提取特征信息。然而,在立場類別“Deny”上,模型的F1 為0。由于給定的Reddit 平臺數(shù)據(jù)中含“Deny”的數(shù)量很少,導(dǎo)致模型在訓(xùn)練過程中不能學(xué)習(xí)到關(guān)于“Deny”類別評論的基本特征,因此其預(yù)測該類別的能力很差。總體而言,本文研究通過結(jié)合知識圖譜模型和RGCN 模型,將推文的文本特征與結(jié)構(gòu)信息相結(jié)合并引入外部知識,有助于模型的立場檢測性能和表現(xiàn)。

Fig.3 Comparison of predictive performance of models based on different platforms圖3 基于不同平臺預(yù)測性能比較
4 結(jié)語
本文提出一種基于GGNN 并引入外部知識的KRGGNN 立場檢測模型,能夠在應(yīng)對評論文本上下文信息不足問題的同時,考慮評論之間的網(wǎng)絡(luò)結(jié)構(gòu)關(guān)系。首先通過對評論文本基于知識圖譜引入外部知識來構(gòu)建圖模型,利用RGCN 獲取評論文本的初始表征,然后采用門控圖神經(jīng)網(wǎng)絡(luò)(GGNN)模型在獲取文本特征的同時,結(jié)合評論之間的網(wǎng)絡(luò)結(jié)構(gòu)關(guān)系實現(xiàn)評論之間的信息傳播。實驗結(jié)果證明,針對評論引入外部知識獲取文本表征,并考慮評論之間的網(wǎng)絡(luò)結(jié)構(gòu)關(guān)系能夠有效提升立場檢測模型性能。然而,由于數(shù)據(jù)集的分布不均勻,使得訓(xùn)練之后的立場檢測模型存在預(yù)測不穩(wěn)定以及偏見較強(qiáng)的問題。在接下來的工作中將嘗試?yán)镁徑馄姷膿p失函數(shù)以及下采樣等方法提高模型檢測的穩(wěn)定性。
猜你喜歡
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
智慧少年·故事叮當(dāng)(2018年11期)2018-05-14 11:48:18
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
河南科技(2014年23期)2014-02-27 14:19:15
