一種面向空間機械臂目標定位的注視點估計方法
2022-08-26 06:42:34曲思霖王從慶展文豪
載人航天 2022年4期
關鍵詞:機械
曲思霖,王從慶,展文豪
(南京航空航天大學 自動化學院,南京 210016;2.中國航天員科研訓練中心人因工程重點實驗室,北京 100094)
1 引言
航天任務中,航天員利用固定在核心艙或空間機械臂上的攝像機獲取艙外信息,通過注視點估計注視操作界面控制艙外設備,對艙外目標進行拾取、操作等。自1901年起,用照相機拍攝圖像用于注視點估計成為了主流方法。二維注視點估計方法目前比較成熟且應用最廣,通過計算注視點的二維信息,建立注視點與屏幕的對應關系,得出視線在屏幕上的對應位置。二維注視點估計可以分為基于模型的注視估計方法和基于外觀的注視估計方法。其中基于模型的注視估計方法包括瞳孔跟蹤法、鞏膜—虹膜邊緣法、瞳孔角膜反射法、普金野象法等;基于外觀的注視估計方法直接將人眼圖像作為輸入,經過圖像處理提取表征眼動的特征,推斷眼睛在計算機屏幕上的注視位置。瞳孔跟蹤法需要引入紅外光源,提高瞳孔的辨識度,可克服垂直方向的遮擋,但要求受試者頭部相對固定;鞏膜-虹膜邊緣法通過圖像處理提取異色邊緣,利用邊緣相對位置計算注視點坐標,要求受試者頭部相對固定,且只適合測量水平方向眼動;瞳孔角膜反射法也需要引入紅外光源獲得瞳孔和角膜亮斑,視線方向由瞳孔中心相對于角膜反射的位置確定,允許頭部輕微運動,市面上多數頭戴式和桌面式眼動儀如Eyelink眼動儀、Tobbi眼動儀、Iview X HED眼動儀都是根據這個原理設計,為用戶提供視線跟蹤體驗;普金野象法需要特征光源與實驗設備,且在水平方向測量誤差較大。基于外觀的注視估計方法將整個眼部圖像信息作為輸入通過圖像處理技術獲得瞳孔位置、眼角位置等信息進行注視點定位,實現簡單,價格低廉,可以處理低像素圖像,允許受試者頭部輕微運動,但精準度較低,魯棒性不足,且需要大量樣本進行訓練。
目前,國內外已提出了多種基于外觀的注視估計方法。Williams等提出一種稀疏半監督高斯過程回歸模型將人眼圖像映射到屏幕坐標。Marrinez等提出提取多級HOG作為特征,利用支持向量回歸和相關向量回歸得到眼睛特征與注視坐標之間的映射函數。Tan等提出一種利用線性插值近似外觀流形模型的注視點估計方法,平均角度誤差為0.38°。Lu等采用優化的方法得到自適應線性回歸的最優解,達到通過稀疏的訓練樣本進行精確的映射的目的,還將問題分解為固定頭部姿態下的初始估計和后續對頭部轉動和眼睛外觀變形引起的估計偏差進行補償,以增加自由頭部運動的6個自由度。Liu等等提出了一種兩步訓練網絡Gaze Estimator,以提高移動設備上注視位置的估計精度。毛云豐等采用深度卷積神經網絡定位虹膜中心與眼角位置映射計算屏幕上的注視點,并在公開數據庫MPIIGaze和Swith上驗證該算法,提高了在低分辨率圖像上進行注視點估計的準確率。孟春寧提出了一種基于矩形積分方差算子的虹膜定位算法,利用支持向量回歸機估計注視方向。
對于空間站機械臂,其中一個重要的任務是完成空間艙外目標的拾取、搬運、定位和釋放。利用安裝在空間站核心艙或空間機械臂上的相機拍攝空間目標,航天員或地面指揮中心通過顯示屏觀察空間環境,注視空間目標所在位置,計算空間目標在空間機械臂坐標下的三維坐標。本文設計了虛擬環境下的空間機械臂多模態人機交互仿真平臺,利用固定操作顯示屏上單目照相機拍攝操作者注視空間目標主視圖與左視圖時的圖像,經過圖像預處理、特征提取和多流卷積神經網絡訓練,得到航天員(操作者)注視點所在矩形框的標簽與空間機械臂待捕獲目標的空間坐標,然后通過空間機械臂運動學反解計算得到關節角,并控制空間機械臂末端向空間目標運動。
2 基于目標定位的注視點估計
2.1 數據集的建立
通過注視點位置估計人臉圖像與屏幕坐標的對應關系,許多國內外的研究團隊已經做了大量的工作。2007年德國烏爾姆大學Weidenbacher等公開了一組包括20名受試者,共2220張圖片的不同的頭姿與視線的組合數據集。2016年麻省理工學院的Antonio Torralba研究小組利用iPhone和平板自帶的前置攝像頭拍攝人臉圖像,并建立數據集GazeCapture,包括1400多人,240多萬樣本,截取左眼圖像、右眼圖像、人臉圖像與人臉位置,將這些數據輸入多流卷積網絡,在iPhone上計算歐氏距離誤差為1.71 cm,在平板上計算歐氏距離誤差為2.53 cm。2017年美國萊斯大學公開了針對平板電腦注視點采集的包括51名受試者,4個不同頭部姿勢、35個注視點的數據集TabletGaze,提取多級HOG特征,用隨機森林回歸,得到的歐氏距離誤差為3.17 cm。雖然有很多公開的數據集,但多數應用于手機、平板電腦。
本文中仿真平臺空間環境顯示界面為24寸(53.30 cm×29.90 cm),屏幕顯示分辨率為1920×1080,即屏幕的長寬比為16∶9。為保證每個矩形塊大小相同,長寬相等,將電腦屏幕平均分為16×9,共144個矩形塊,每個矩形塊的分辨率為120×120。使用單目攝像機采集9名受試者單一頭姿的144個注視點數據集。將單目攝像機放置在屏幕上邊正中心的位置,調整攝像頭角度,使拍攝畫面能完整顯示受試者桌面以上身體部分,采集數據集圖片時,要求受試者頭部正對攝像頭,瞳孔轉動依次注視144個矩形塊正中心部分,利用攝像機拍攝,每人每個矩形塊拍攝約10張照片,過程中保持環境光線不變,允許受試者頭部輕微晃動。實驗采集9名22~25歲受試者的注視圖像,其中7名男性,2名女性,數據集共16 395張圖片。
使用攝像機拍攝的圖片中包含實驗室環境、無關人員的背影、側臉等干擾條件,因此,需要對攝像機拍攝圖像進行預處理,截取人臉部分。目前,人臉檢測的方法包括Haar級聯檢測、ACF人臉檢測、DPM算法、SURF級聯檢測等基于圖像特征的方法。隨著深度學習網絡的發展,多種卷積神經網絡應用于人臉檢測方向,如2015年提出的級聯CNN、2018年提出的Faceness-Net等。雖然深度學習算法更精準,但本文數據集中單張圖片只包含一個正臉任務較簡單,因此選擇目前人臉檢測速度最快的Haar級聯檢測器截取人臉部分。
2.2 圖像預處理與特征提取
利用OpenCV中的Haar級聯檢測器檢測圖片中人臉部分,利用dlib檢測器截取左、右眼部分。在Haar級聯檢測器中包含左眼檢測器與右眼檢測器,但存在一些問題,如易誤采集到眉毛部分且截取人眼圖片大小不一。dlib人眼檢測較Haar級聯檢測器更穩定、更精準,且可設置截取圖片大小。dlib檢測器提取HOG作為特征,采用支持向量機進行臉部特征點識別,標記人臉68個特征點。截取左眼、右眼部分,截取圖片像素大小為28 px×69 px,截取的左眼、右眼部分如圖1所示。

圖1 dlib檢測器截取左右眼部分Fig.1 Left and right eyes intercepted with a dlib detector
為了增加數據集樣本數,提高定位準確率,通過改變圖片大小擴展數據集。綜合考慮算法速度與實現效果,本文選擇線性插值的方法改變圖片大小。將左、右眼截取圖像像素值變為36 px×60 px。
最后,在提取圖像特征前,需要將RGB圖像灰度化。將圖片灰度化有利于識別物品邊緣,計算梯度值,將圖像矩陣變為二維矩陣,加快提取特征。
2.3 圖像特征提取
利用圖像特征提取方法描述特定區域,使該區域區別于周圍其他點,具有高可分度。HOG算法通過計算和統計圖像局部區域的梯度方向直方圖來構成特征,計算圖像每個像素的梯度,捕獲輪廓信息,進一步弱化光照的干擾,保持圖像幾何不變性。獲取人眼圖像與注視點坐標的關系,需要得到瞳孔與眼角的相對位置。因此,本文選擇HOG特征提取方法。左、右眼的梯度直方圖如圖2所示。
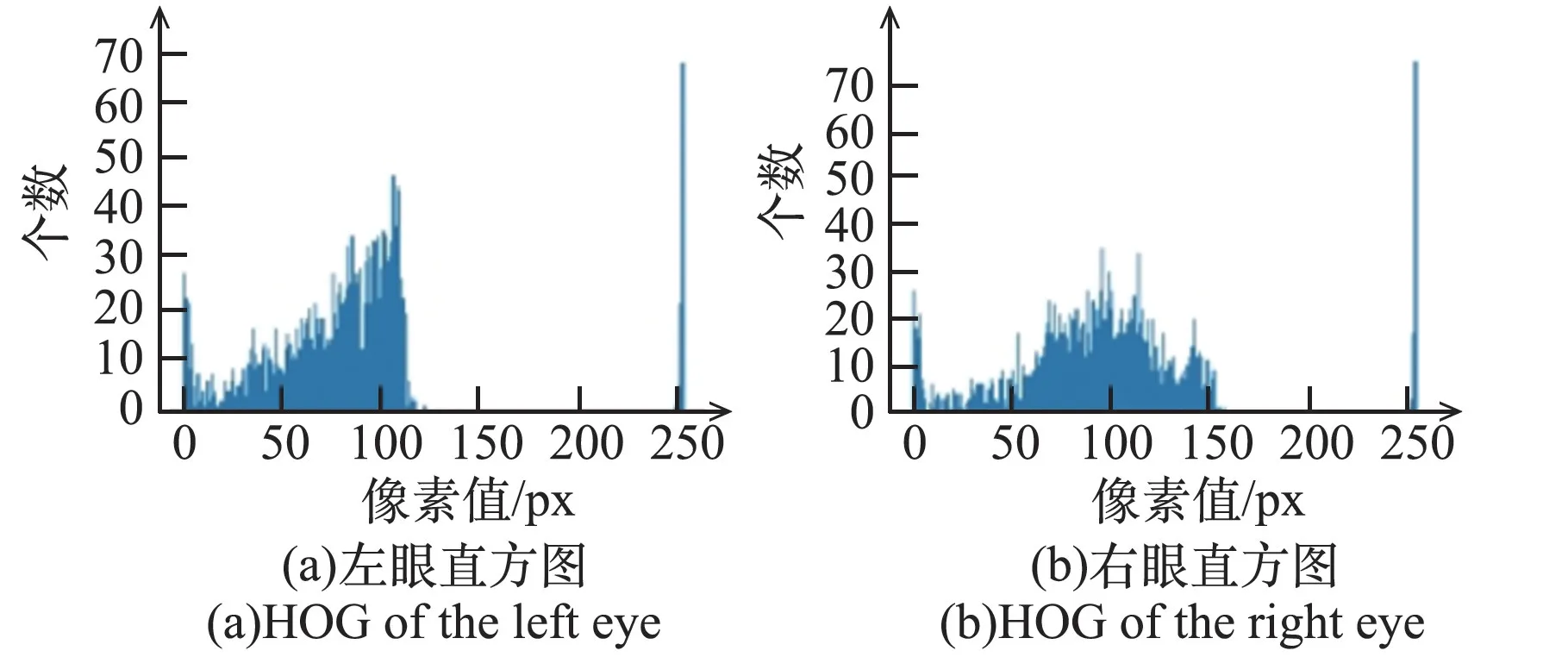
圖2 左、右眼梯度直方圖Fig.2 HOG of left and right eyes
由圖2可知,圖像的灰度級集中在低亮度范圍,個別的像素點出現在255處,使用直方圖均衡化將直方圖變成均勻分布,增加像素之間灰度值的動態范圍,對在圖像中像素個數多的灰度值進行展寬,而對像素個數少的灰度值進行歸并,增大圖像對比度。左、右眼均衡化直方圖如圖3所示。
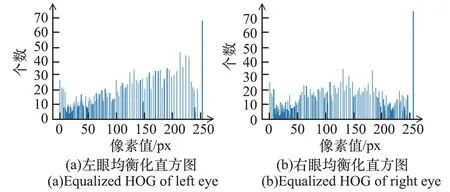
圖3 左、右眼均衡化直方圖Fig.3 Equalized HOG of left and right eyes
經過直方圖均衡化后的左右眼圖像如圖4所示。由圖可知,直方圖均衡化后的圖像增大了瞳孔與虹膜之間的對比度,有利于分辨瞳孔與眼角的相對位置,提高注視點定位的準確率。

圖4 直方圖均衡化后的左右眼圖像Fig.4 Left and right eyes after HOG equalized
為了進一步消除膚色對實驗結果的影響,采用閾值方法處理人眼圖像。由雙眼直方圖可知,大部分像素集中在0~150區間,保持瞳孔像素大小不變的情況下,降低無關因素影響,本文采用截斷閾值方法,截斷閾值設置為80,圖像中大于80的像素值設置為80,小于80的像素值保持不變。經過閾值截斷后的左、右眼圖像如圖5所示。

圖5 閾值截斷后的左右眼圖像Fig.5 Left and right eyes after threshold truncation
2.4 多流卷積神經網絡模型設計
本文設計了一種多流卷積網絡學習左右眼圖像與144個注視點位置之間的映射關系。將預處理及特征提取后的大小為28 px×69 px的左、右眼圖像輸入如圖6的卷積網絡中,訓練模型參數。將預處理及特征提取后的大小為36 px×60 px的左、右眼圖像輸入如圖7的卷積網絡中,訓練模型參數。將4組人眼圖像(36 px×60 px的左、右眼圖像、28 px×69 px的左、右眼圖像)分別輸入對應網絡中,利用全連接層融合,搭建如圖7的多流卷積神經網絡模型,在數據集上驗證注視點位置估計準確率。所有的模型都在一臺包含Intel i7核心CPU、16GB RAM的Linux操作系統下的計算機上進行訓練,程序開發環境為Tensorflow,使用NVIDIA GEFORCE RTX 3080 GPU加速訓練過程。本文設計的所有卷積神經網絡訓練時迭代次數均為400次,批尺寸為32個,選擇交叉熵計算損失值,以及對稀疏數據表現更好的AdaDelta優化算法。
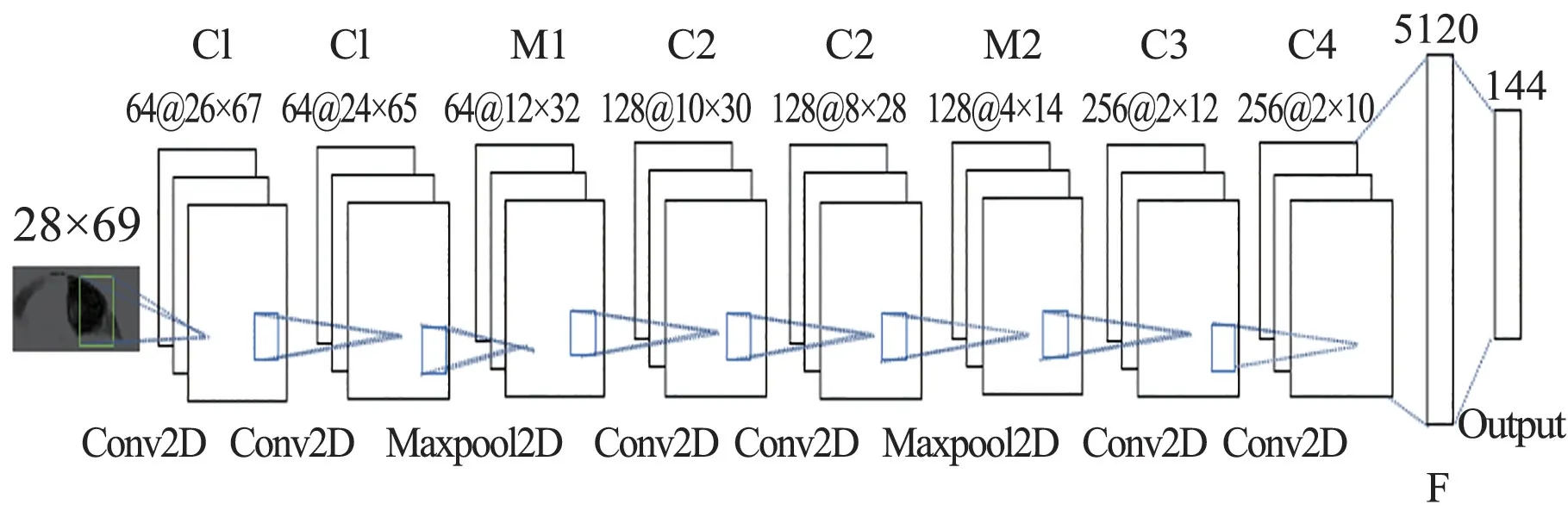
圖6 輸入為28 px×69 px的卷積神經網絡模型Fig.6 CNN model with input of 28 px×69 px

圖7 輸入為36 px×60 px的卷積神經網絡模型Fig.7 CNN model with input of 36 px×60 px
圖中C1、C2、C3、C4為卷積層,M1、M2為池化層,F為Flatten層。卷積核大小/通道數為C1:3×3/64,C2:3×3/128,C3:3×3/256,C4:1×3/256,激活函數為ReLU。選擇最大池化作為池化層的池化方式,池化核大小/通道數為M1:2×2/64,M2:2×2/128,激活函數為ReLU。輸出層有144個神經元,對應144個注視點編號,激活函數為Softmax函數。
B型網絡與A型網絡比較,將C4卷積層換為C3卷積層,即卷積核大小為3×3,并加入池化層M3,輸入M3的矩陣大小為2×8,輸出通道數為256,輸出矩陣大小為1×4。
調整圖6中卷積神經網絡(A型網絡)和圖7中卷積神經網絡(B型網絡的結構),形成如圖8所示的多流卷積神經網絡模型(以下簡稱AB型網絡)。將28 px×69 px的左右眼圖像輸入A型網絡,進行訓練,在A型網絡中Flatten層之前增加一個C4層,輸出通道數為256,大小為2×8。將36 px×60 px的左右眼圖像輸入B型網絡,進行訓練,B型網絡去掉M3層。將4個輸出矩陣通道合并,Flatten層將三維矩陣壓縮為一維向量,向量長度為2×8×1024=16 284,增加一個全連接層FC,神經元數為256,激活函數為ReLU,輸出層輸出144個預測注視點編號。
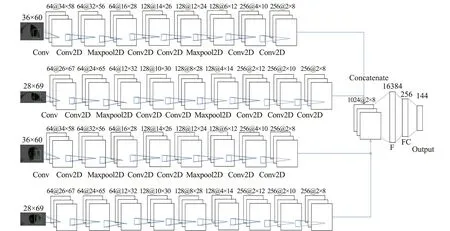
圖8 多流卷積神經網絡模型Fig.8 Multi-stream CNN model
3 結果與分析
3.1 注視點位置估計準確性分析
為了測試多流卷積神經網絡對注視點位置估計的準確性,隨機選擇80%作為訓練集訓練模型,并將訓練好的模型在測試集上驗證。A型網絡訓練大小為28 px×69 px的左右眼圖像、B型網絡訓練大小為36 px×60 px的左右眼圖像、AB型網絡訓練左眼圖像、AB型網絡訓練右眼圖像以及AB型網絡訓練4個眼部圖像的識別準確率如表1所示。
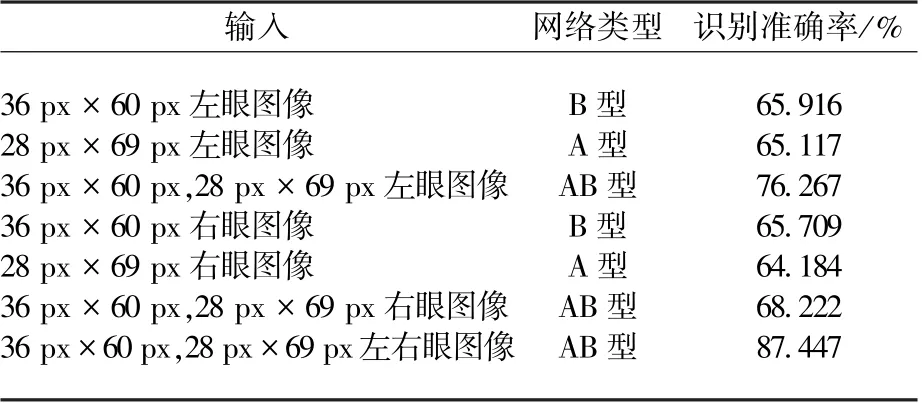
表1 不同輸入圖像在卷積模型下的識別準確率Table 1 The accuracy of classification with different input images and CNNs
由表1可知,像素大小為28 px×69 px的左、右眼圖像在A型網絡下的注視點位置估計準確率分為65.117%和64.184%,像素大小為36 px×60 px的左、右眼圖像在B型網絡下的注視點位置估計準確率分為65.916%和65.709%。將像素大小為28 px×69 px和36 px×60 px的左眼或右眼圖像輸入AB型網絡,注視點位置估計準確率分別達到76.267%和68.222%,較單一輸入時有些許提高,而將像素大小為28 px×69 px和36 px×60 px的左眼和右眼圖像一同輸入AB型網絡時,注視點位置估計準確率能達到87.447%,有顯著提高。
在數據集上采用其他的特征提取方法與分類方法,比較不同方法在本文數據集上的識別準確率,如表2所示。

表2 不同特征提取及分類方法在數據集上準確率Table 2 The accuracy comparison of different feature extraction and classification methods on the dataset
表2中,mHOG(multi-level Histogram of Gradient)是多尺度梯度直方圖,按照Martinez等提出的方法劃分圖像,計算mHOG。將36 px×60 px的人眼圖像分別劃分為1×2、3×1、3×2、6×4區塊,每個區塊建立2×2個細胞單元,每個細胞單元對應9個梯度直方圖,利用范數對每個區塊歸一化獲得長度為2520的特征向量。采用主成分分析(Principle Component Analysis,PCA)將特征向量長度降至143,最后用隨機森林分類(Random Forest Classifier,RFC)或決策樹分類(Decision Tree Classifier,DTC)進行分類。Basilio等改變圖像大小至6 px×10 px,計算歸一化直方圖作為特征,左右眼圖像共獲得120個特征,并采用支持向量機(Support Vector Machine,SVM)進行識別。提取mHOG時按細胞單元計算梯度直方圖以及縮小圖像大小的作用與卷積核相似,都是合并區域內像素值,降低特征維度,有利于分類器進行分類。由表2所知,提取多尺度直方圖作為特征時,RFC較DTC具有更好的分類效果。提取整張圖的直方圖作為特征時,SVM分類效果最好。提取多尺度梯度直方圖較提取整張圖片梯度直方圖,識別準確率更高。但提取數據集雙眼的多尺度直方圖即同一點像素值多次計算,使計算的數據量成倍增加,對于本數據集的圖像,計算多尺度梯度直方圖的數據量達到44.8 GB,計算機處理速度慢。因此,綜合考慮計算速度和識別準確率的條件下,本文提取的多流卷積神經網絡具有較大優勢。
采用文本方法識別注視點位置,144個注視點從電腦屏幕的左上角至屏幕的右下角依次編號1~144,每列9個注視點,共16列。每個注視點所在的矩形塊大小為3.322 cm×3.322 cm,對應的像素范圍為120 px×120 px。
輸入為36 px×60 px,28 px×69 px左右眼圖像,采用多流卷積網絡進行分類,144個注視點中有88.89%的注視點識別率在80%以上,驗證了該算法在解決注視點估計問題上的有效性。
3.2 虛擬環境下空間機械臂目標定位仿真實驗
空間目標定位實現步驟如圖9所示。

圖9 空間目標定位流程圖Fig.9 Process of spatial target positioning
操作者首先注視空間環境主視圖正投影中空間目標位置,利用固定在屏幕上方的照相機拍攝受試者照片,采用本文注視點估計算法獲得此時空間目標所在矩形塊標簽1,計算空間機械臂坐標系下空間目標的二維坐標(x,z),如式(1)、(2)所示。其中每個矩形塊對應空間機械臂坐標系,軸坐標范圍為50,軸坐標范圍為60。
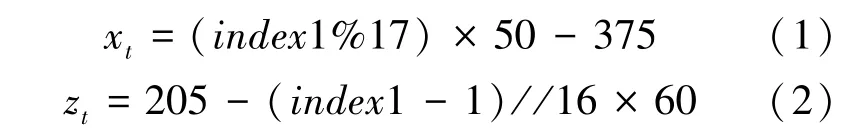
式中%表示余數,//表示整除。然后,操作者注視空間環境左視圖正投影中空間目標位置,采用上述方法獲得此時空間目標矩形塊標簽2,計算空間機械臂坐標系下空間目標的二維坐標(y,z),如式(3)、(4)所示。每個矩形塊邊長對應空間機械臂坐標系下的軸坐標范圍為50。
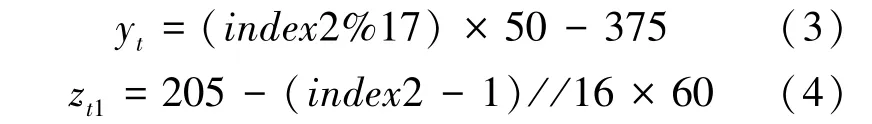
通過計算可知,=獲得空間目標的三維坐標(x,y,z)。
空間機械臂模型各關節尺寸如圖10所示。
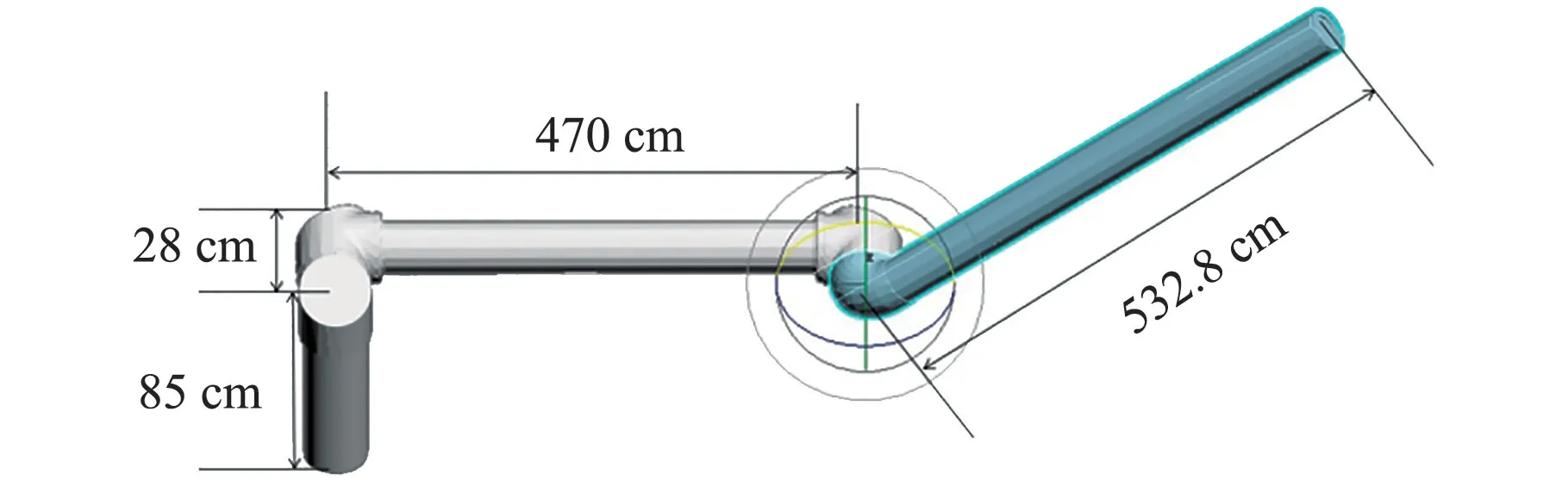
圖10 空間機械臂尺寸Fig.10 Size of the space manipulator
空間機械臂模型腰部長85 cm,在OpenGL空間坐標系下長34;大臂長470.0 cm,在OpenGL空間坐標系下長187;小臂長532.8 cm,在OpenGL空間坐標系下長212,腰部與大臂的連接處長28 cm,在OpenGL空間坐標系下長11。
空間機械臂3個關節角設置如圖11所示。表示腰部平面法向量與垂直方向的夾角,表示大臂軸線與水平方向夾角,表示小臂軸線與大臂軸線的夾角。
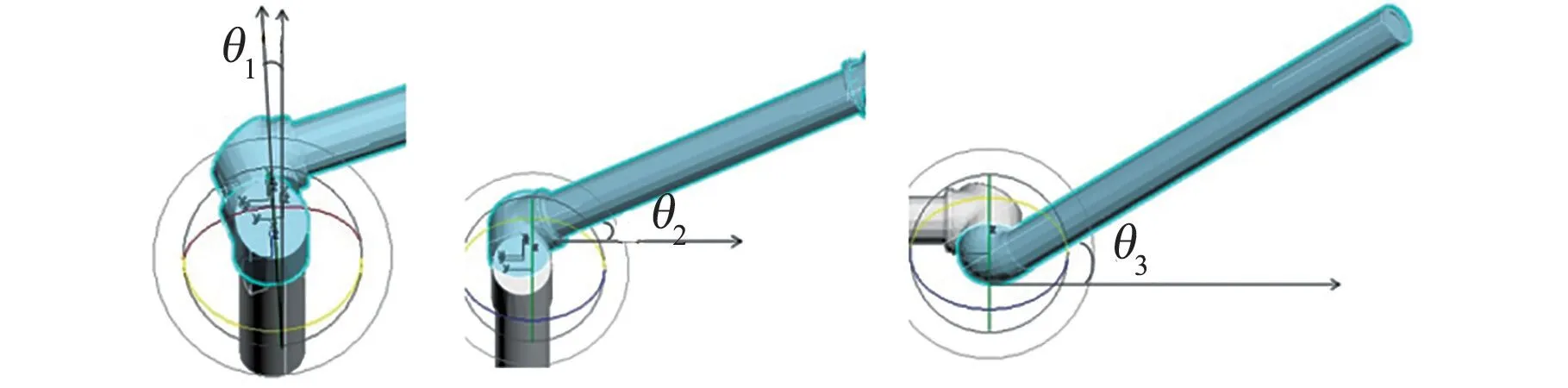
圖11 空間機械臂關節角Fig.11 Joint angles of the space manipulator
在空間機械臂坐標系下,水平方向向右為軸正方向,垂直方向向上為軸正方向,垂直于電腦屏幕向內為軸正方向,空間機械臂與航天器連接處為坐標原點,計算空間機械臂模型小臂末端位置三維坐標。該空間機械臂的運動學變換矩陣見式(5)。
通過上述運動學變換矩陣和空間目標的三維坐標(,,)反解求出3個關節角大小見式(6)。
虛擬環境下的空間機械臂人機交互仿真軟件系統由客戶端、服務器端、網絡通訊3部分構成。設計的虛擬環境下空間機械臂人機交互仿真平臺客戶端如圖12所示。
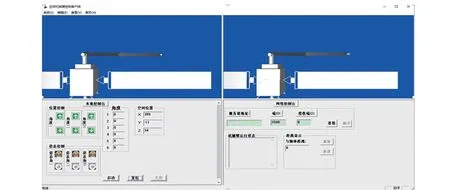
圖12 虛擬環境下的空間機械臂人機交互仿真平臺客戶端Fig.12 The client of human-computer interaction simulation platform for the space manipulator in virtual environment
客戶端的交互界面主要包括了本地控制臺與網絡控制臺兩個部分,其中左上角部分為本地控制臺OpenGL繪制操作者要求的空間機械臂運動姿態,即顯示出遠端空間機械臂應該達到的運動姿態。網絡控制臺顯示OpenGL繪制的虛擬遠端空間環境即服務器端的空間環境與空間機械臂的運動姿態,使操作者了解遠地端的空間機械臂的狀態。
虛擬環境下空間機械臂人機交互仿真平臺服務器如圖13所示。
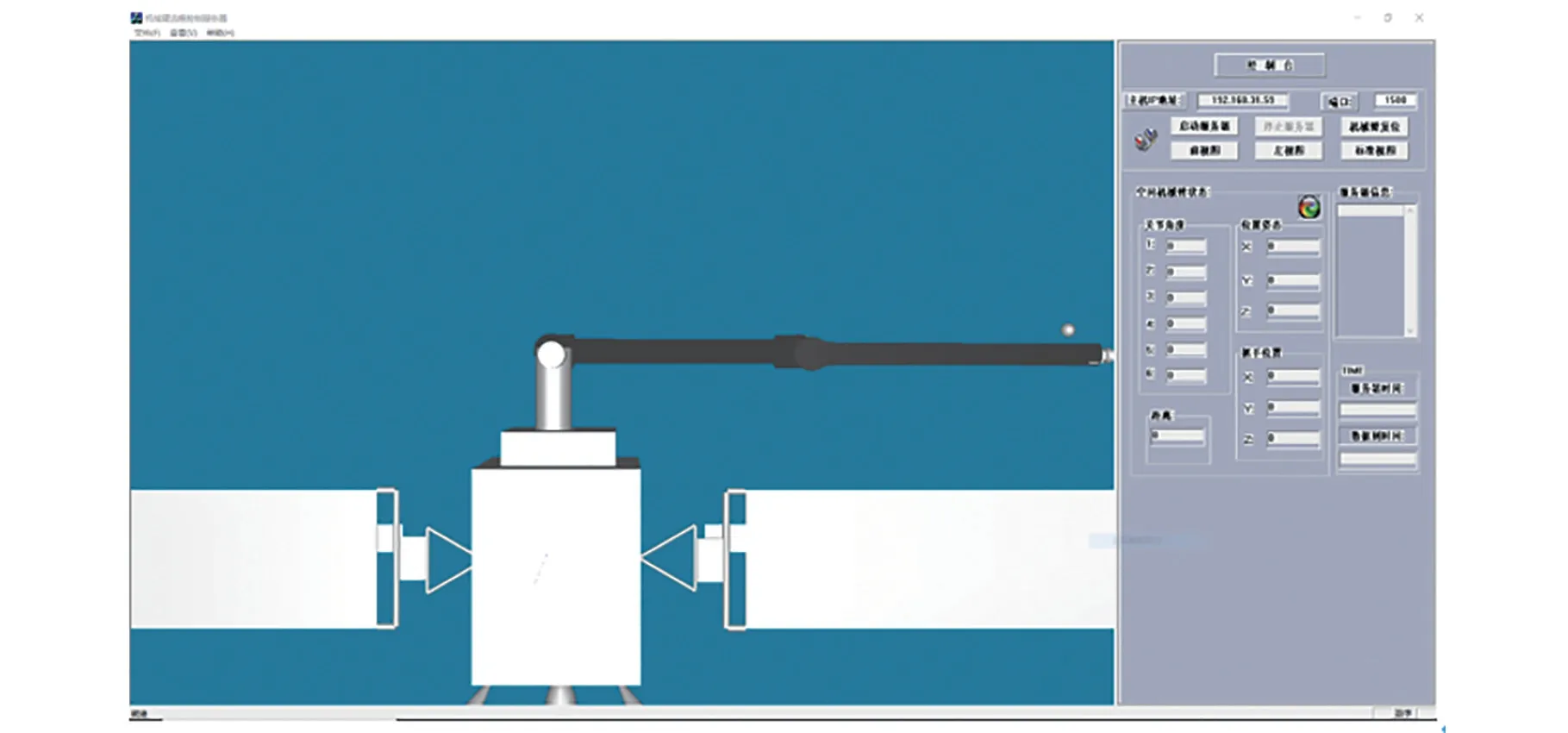
圖13 虛擬環境下的空間機械臂人機交互仿真平臺服務器Fig.13 The server of human-computer interaction simulation platform for the space manipulator in virtual environment
在網絡控制臺與服務器連接后,服務器端、網絡控制臺交互界面中機械臂位置、姿態與本地控制臺交互界面中空間機械臂保持一致,在機械臂運行狀態消息框中顯示系統時間與角度變化,在服務器端計算空間機械臂末端手爪與空間目標之間的距離,傳輸到客戶端并顯示。
以圖中實驗為例,空間機械臂處于初始位置時,空間機械臂末端手爪距空間目標的距離為359.203,經過注視點定位得到空間目標三維坐標并反解調節3個關節角位置后,空間機械臂末端手爪距空間目標的距離為21.9101,大幅度縮小了空間機械臂末端手爪距空間目標的距離。最后鼠標點擊按鍵微調關節角大小。由于空間目標的半徑為10,當機械臂末端手爪坐標與目標中心距離小于設置值10時,抓取目標,并在客戶端機械臂運行狀態消息框中顯示“物體已經抓取”。
在人機交互仿真平臺服務器界面中,空間機械臂抓取目標如圖14所示。
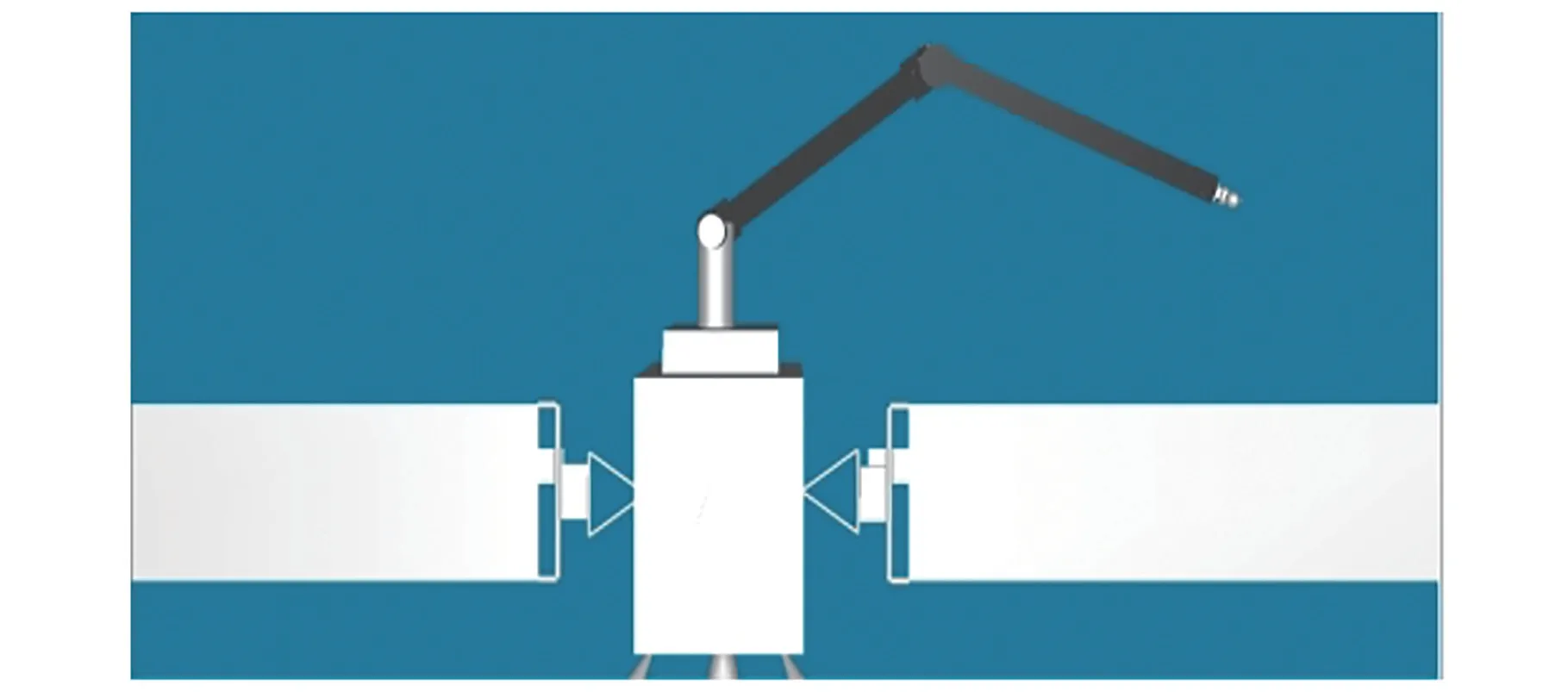
圖14 空間機械臂抓取注視的空間目標Fig.14 The space manipulator grabs the gazed space target
造成空間目標定位誤差的主要因素有2點:①利用注視點估計方法得到的注視點標簽轉換為坐標時,計算的是矩形塊中心點坐標。若空間目標靠近矩形塊頂點處,則計算誤差較大,最大誤差達46.368。②反解關節角時,省略了3個關節角的小數部分。
4 結論
本文提出了一種基于空間機械臂目標估計的注視點估計方法。
1)建立基于電腦屏幕注視點的人眼圖像數據集,補充了電腦屏幕注視點估計數據集的空缺。對數據集中的圖像進行預處理、提取圖像的均衡化HOG作為特征。
2)設計一種多流卷積神經網絡識別144個注視點位置,注視點識別準確率達到87.447%,其中,有88.89%的注視點識別率在80%以上。對本文方法與參考文獻中算法在數據集上驗證的識別準確率進行比較,實驗結果表明了該算法在解決注視點估計問題上識別準確率高、運算速度快的優點。
3)搭建了一個虛擬環境下的空間機械臂人機交互仿真平臺,利用本文提出的注視點估計方法,計算虛擬環境下的空間機械臂人機交互仿真平臺中空間目標位置,進行了仿真驗證。仿真實驗表明,本文注視點估計方法能正確定位空間目標位置,反解計算空間機械臂關節角大小,大幅度縮小了空間機械臂末端手爪距空間目標的距離。為完成空間機械臂抓取空間目標提供可行性。
4)針對空間環境中空間目標位置未知的問題,本文采用單目照相機拍攝操作者照片,基于外觀注視點估計及視覺轉換的方法定位空間目標,避免了眼動儀對航天員增加的負擔,具有創新性與實用性。
猜你喜歡
機械工程材料(2022年10期)2022-11-21 12:08:44
小學科學(學生版)(2021年9期)2021-11-02 05:26:46
電腦報(2020年35期)2020-09-17 13:25:53
當代工人(2020年8期)2020-05-25 09:07:38
電腦報(2019年40期)2019-09-10 07:22:44
建材發展導向(2019年13期)2019-08-24 06:37:40
電子制作(2018年14期)2018-08-21 01:38:14
小溪流(畫刊)(2017年12期)2018-01-10 16:07:29
筑路機械與施工機械化(2017年6期)2017-07-10 11:54:50
科技知識動漫(2016年8期)2016-07-29 20:40:09
