基于信譽值的實用拜占庭容錯改進算法研究
2022-08-28 07:44:00王啟河
現代信息科技 2022年10期
王啟河
(華北電力大學 控制與計算機工程學院,河北 保定 071003)
0 引 言
近2008年中本聰提出一種點對點的電子現金系統即比特幣,使得區塊鏈底層技術得到了社會廣泛關注。區塊鏈具有不可篡改性、去中心化、安全性高等特點。這些特點使得區塊鏈技術在各業界的應用得到迅速發展。共識算法直接影響區塊鏈的效率,對共識算法的研究是區塊鏈技術的研究熱點之一。
區塊鏈可以根據去中心化程度分為公有鏈、聯盟鏈和私有鏈三種類型。公有鏈去中心化程度最高,其特點是用戶量大、節點數較多、且節點出入系統隨意。公有鏈常用的共識算法為PoW。PoW 計算消耗大,為了爭奪主節點獎勵會產生不必要的消耗,后續出現了其他的公有鏈共識算法。私有鏈去中心化程度最低,一般的共識算法為Paxos和Raft等,這些算法記賬效率高于公有鏈和聯盟鏈,但去中心化程度低,一般是用于私人或一個公司內部使用。聯盟鏈的去中心化程度介于公有鏈和私有鏈之間,一般用于組織聯盟之間,應用范圍較廣。聯盟鏈的共識機制是BFT 和PBFT。BFT 是1982年由Leslie Lamport等人提出,要求算法能夠在有三分之一惡意節點的情況下完成共識。原文中僅提出了口信消息型和簽名消息型兩種解決方案,注重理論上的可解,算法復雜度太高,共識效率太低,不具備實用價值。Miguel Castro 和Barbara Liskov對BFT 改進后提出PBFT算法,成功將BFT算法的復雜度由指數級降低到多項式級別,使得拜占庭容錯機制得以在實際實現中變得可行。
PBFT 算法使得聯盟鏈中的拜占庭將軍問題在實際運用中可行,但算法仍存在主節點選取隨意,網絡通信開銷較大,公平性較低等問題。本文針對這些問題,提出一種基于信譽值的PBFT 改進算法,對主節點的選取方式、達成共識的判斷條件進行改進,優化了共識過程,減少了通信量,提高了系統公平性。
1 相關工作
1.1 實用拜占庭容錯算法
實用拜占庭容錯算法(PBFT)能在有3+1 個節點的系統中,容忍存在個惡意或故障節點存在的情況下以多項式級別的通信量完成共識,采用密碼學相關技術確保消息傳遞過程無法被篡改和破壞。在PBFT 算法中所有節點被分為客戶端節點,主節點和備份節點三種類型,其中主節點和備份節點統稱為副本節點。每一個節點都有一個編號,每一輪共識稱為一個視圖,視圖編號為。每個視圖都要經過請求(request),預準備(pre-prepare),準備(prepare),確認(commit)和響應(reply)五個階段。算法執行流程如圖1所示。
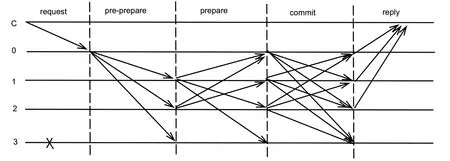
圖1 PBFT 算法執行流程
具體步驟為:
請求階段:由客戶端節點發起提案請求給主節點,主節點的編號按照=mod||計算得到,為節點總數。提案請求格式為<request,o,t,c>,request 包含消息內容以及的摘要(),表示執行的操作,表示時間戳,表示客戶端C 的標識。
預準備階段:當主節點收到客戶端的請求并驗證成功后,主節點向除了自己以外的所有其他節點發送預準備信息。預準備信息格式為<<pre-prepare,v,n,d>,m>,為節點給請求分配的編號,為請求消息的摘要。需要備份節點給<pre-prepare,v,n,d>進行簽名。
準備階段:當其他節點收到驗證成功的預準備信息后,向包括自己在內的節點發送準備信息,并把預準備信息寫入日志。準備信息格式為<prepare,v,n,d,i>,表示當前節點的編號。且節點要對<prepare,v,n,d,i>進行簽名。
確認階段:當節點收到2+1 條驗證成功的準備信息(包括請求和預準備信息)后,節點向所有節點發送確認信息。確認信息格式為<commit,v,n,d,i>,節點需要對<commit,v,n,d,i>簽名。
響應階段:當節點收到2+1 條驗證成功的確認信息后,節點向客戶端發送一條響應信息。響應信息格式為:<reply,v,t,c,i,r>,為請求操作結果。當客戶端收到+1 條相同的響應信息后表示客戶端的請求達成共識。
1.2 PBFT 算法相關改進研究
目前對PBFT 的改進方向有兩種:一是減少參加共識的節點數量,即每輪只選取一部分節點進行公示,達到減少通信量的目的;二是優化共識過程,通過改進共識過程或增加節點評判機制,減少不必要的通信,達到增加共識效率的目的。
在減少參加共識的節點數量改進方面:文獻[13]提出一種VPBFT 算法。引入投票機制,將節點分為投票者、管理者、候選人、普通用戶四類,每種節點有不同權限,這樣做的本質是減少參加共識過程節點的數量。文獻[14]提出一種基于網絡自聚的NAC-PBFT 算法,文獻[15]也提出一種K-PBFT類聚算法,兩種算法核心思想都是將節點分組,每個分組內共識后由骨干節點再進行公示,在有大量節點的情況下減少通信量。此種類聚算法本質上是分組類聚減少每次共識的節點數量。文獻[16]提出一種基于樹形網絡拓撲圖的共識算法,通過對全網共識任務進行拆分,減小任務的整體規模。以上的四類算法都是通過減少參與共識過程的節點來達到減少通信量的目的。通過聚類分組或以其他分組結構(如樹形網絡拓撲)的方式分組進行公示,最后達到全局共識。此類算法適用于節點數目較多的情況,若節點數太少優勢不明顯。
在優化共識過程方面:文獻[17]提出一種IPBFT 算法,將節點分為協商節點和執行節點,引入節點的自證機制,使得在長期共識過程中的共識效率提高,是一種優化共識過程的算法。文獻[18]提出一種基于時間權重的PBFT 算法。算法給每個節點賦予一個時間權重,存在時間越長權重越大,對共識影響越大。對主節點選取算法根據權重選取,優化共識流程,提高系統安全性。文獻[19]提出一種E-PBFT 算法,通過優化主節點選舉方式以及優化共識流程對算法進行改進,減少算法的通信量。文獻[20]提出一種PBFT 改進算法,通過對交易分類為平等交易和不平等交易,只對錯誤交易進行公示,減少共識次數來增加區塊鏈共識的效率且增加了算法的可擴展性。文獻[21]提出一種RB-PBFT 算法,引入信譽模型和節點的可信度評估,對惡意節點有懲罰機制。RBPBFT算法通過信譽值排名來決定哪些節點進入下一輪共識,減少參與共識節點數目。以上幾類算法的核心思想都是增加信譽值或者其他方式,對PBFT 算法流程進行改進,達到減少通信量和提高算法公平性的目的。
通過對以上算法的研究,本文提出一種改進的PBFT 算法,算法引入一種更合理的信譽機制,提高算法的公平性。同時,改進算對共識流程進行優化,優化部分不必要的通信,減少共識所需要的通信量。
2 改進算法
2.1 算法思想概述
PBFT 算法中每一輪共識中所有節點的影響力都相同,這樣對于誠實節點來說是不公平的。在實際情況中,故障節點和作惡節點對于共識的貢獻是零甚至是在破壞共識,所以共識成功的節點應該在下一輪的共識中更有影響力。本文提出一種PBFT 的改進算法,對每個節點增加一個信譽值。信譽值會隨著節點的行為變化,信譽值的大小就是節點在共識過程中影響力的大小。隨著共識輪次的增加,系統中故障節點和惡意節點影響力變小,誠實節點影響力變大。
2.2 信譽值調節機制
節點的信譽值情況由節點在本地進行維護。每經過一輪共識,各個節點根據接收到的數據確認情況更新信譽值。誠實節點信譽值會得到提升,故障節點和惡意節點信譽值會不同程度的降低。節點按照表1分為誠實節點、故障節點、惡意節點三種節點類型。高信譽值節點也可能會在某一輪共識中作惡,懲罰方案是信譽值越高,作惡懲罰越大。
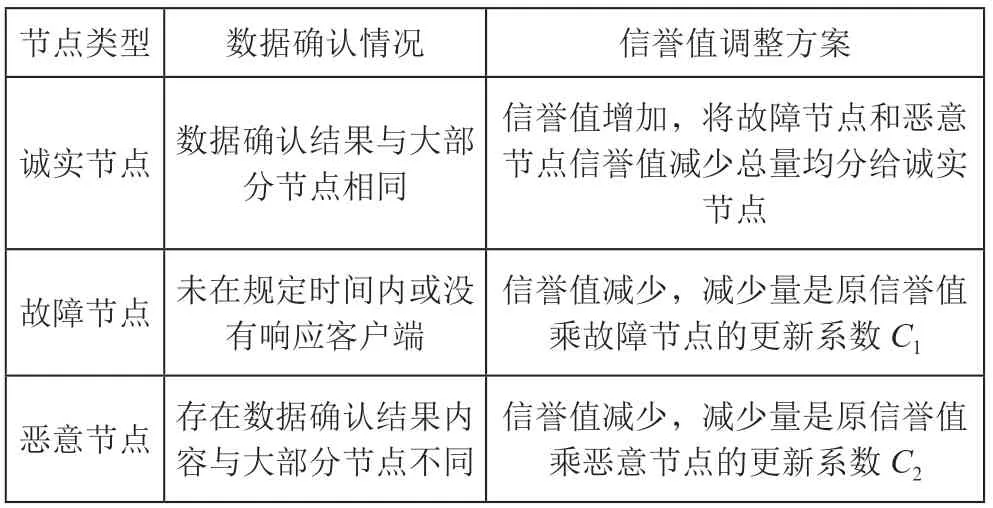
表1 節點分類表
假設共有個節點,一輪共識后有個誠實節點,個故障節點,個惡意節點(++=)
故障節點信譽值更新公式:

其中表示第個故障節點更新后的值,表示第個故障節點更新前的值,為故障節點更新系數。1≤≤,0 <<1。
故障節點信譽值降低值總和:
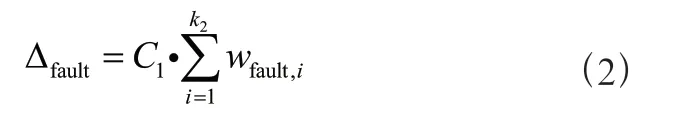
惡意節點信譽值更新公式:

其中表示第個惡意節點更新后的值,表示第個惡意節點更新前的值,為無效響應節點更新系數。1≤≤,0 <<1。
惡意節點信譽值降低值總和:

所有非誠實節點信譽值降低總和為:

誠實節點信譽值更新公式為:
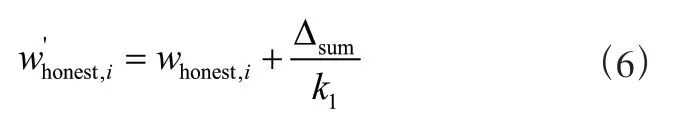
其中w表示第個有效響應節點更新后的值,w表示第個惡意節點更新前的值。
2.3 主節點選取算法
PBFT 算法中主節點選取方式是客戶端節點根據視圖編號計算得出,對節點本質上沒有任何篩選,通過視圖轉換協議解決惡意節點或故障節點成為主節點的問題會影響共識效率。本文主節點選取算法為:
根據節點信譽值序列w篩選出信譽值大于主節點最低值的所有節點,節點編號和信譽值分別存入備選主節點編號序列c和備選主節點信譽值序列b中,1≤≤,為備選節點總數。
根據式(7)算出主節點備選序列的累積和序列,1≤≤+1。

隨機生成一個隨機數,0 <<s+1。
遍歷序列b,若滿足b<<b,則編號為c的節點成為主節點。
所有節點在驗證視圖更換請求時,需要驗證客戶端節點所請求的主節點的信譽值是否大于,若大于則可以接受,若小于則拒絕。
2.4 算法流程
PBFT 算法的確認階段是統計系統中大部分(大于等于2+1)節點已經共識成功,但又將結果廣播于所有節點,所有節點又進行一次統計工作才將結果響應給客戶端。兩次廣播導致算法通信復雜度較高。在改進算法中,節點對于數據的驗證和確認只在第一個廣播階段完成,第二個階段更新節點信譽值。改進算法的五個階段為:預提案階段(preproposal)、提案階段(proposal)、數據確認階段(data-commit)、信譽值更新階段(reputation-update)、響應階段(reply)。基于信譽值的PBFT 算法消息發送過程如圖2所示。
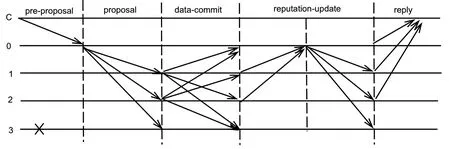
圖2 基于信譽值的PBFT 算法消息發送過程
預提案階段:客戶端節點通過主節點選取算法得到主節點編號,向主節點發送一條提案請求消息。預提案請求格式為<pre-proposal,o,t,c,j>,其中表示請求的操作,表示時間戳,為客戶端C 的標識,為主節點編號。preproposal 中包含請求消息以及消息摘要(m),且客戶端需要對預提案請求進行簽名。
提案階段:當主節點收到預提案請求后,驗證客戶端請求是否合法,檢驗客戶端節點提供的信譽值序列與節點本地保存的信譽值序列是否一致以及主節點的信譽值是否大于。驗證通過后主節點為提案編一個序號,然后向除了自己以外的其余節點發送一條提案信息。提案信息格式為<<proposal,n,j,d(m)>,m>,且需要對<proposal,n,j,d>進行簽名。
數據確認階段:當副本節點收到提案信息后(主節點完成預提案階段后直接到數據確認階段),驗證提案信息的合法性,同時對請求數據進行驗證。若通過則先將提案信息內容記錄到日志,然后向所有節點發送一條數據確認信息。數據確認信息格式為:<data-commit,n,j,d(m),i>,為當前節點編號。且需要對<data-commit,n,j,d(m),i>簽名。
信譽值更新階段:當副本節點收到一條數據確認信息后,先對信息進行合法性驗證。節點進入此階段后啟用一個計時器,設置一個此階段的最大等待時間,在此階段內接收到的數據確認信息進行下一步分類,此時間段之外的節點直接認定為故障節點。計時結束后,副本節點需要記錄所接收到數據確認信息的來源,完成節點分類序列。計時結束后,向主節點發送一條信譽情況<reputation,<p,i,n,j>>,副本節點需要對<p,i,n,j>進行簽名。主節點需要將各個節點的信譽消息匯總成信譽消息矩陣PI,PI 由主節點所接受到的所有信譽情況信息組成。然后向其余節點發送一條信譽更新信息<reputation-update,PI,n,j>,主節點需要對此消息簽名。此階段轉發過程如圖3所示。
圖3 信譽消息轉播示意圖
其中,分類序列中值為1 表示對應節點為誠實節點。為表示一般情況,用表示不確定值。
響應階段:當副本節點收到信譽更新信息后,先對信息進行合法性驗證,然后根據信息中的信譽消息矩陣PI 進行計算得到共識結果以及得到共識過程中各個節點的分類情況,根據分類情況按信譽機制對各個節點信譽值進行更新。此后,副本節點向客戶端發送一條響應信息<reply,t,c,i,j,w,r>,為驗證結果,為更新后的信譽值序列。當客戶端節點收到相同響應信息對應節點信譽值累積和大于+1 時,表示共識完成。
3 算法分析
3.1 一致性分析
算法的一致性主要是需要所有誠實節點對數據共識結果以及對各節點的信譽值的更新結果保持一致,信譽值在共識過程中起到判斷條件的作用,不同信譽值序列可能會出現不同的結果。本算法是在每一輪共識結束后,需要保持最終一致性。每一輪算法經歷兩次共識。第一次是在數據確認階段,完成對數據的共識。各節點并沒有在此時就直接認定此數據能通過,而是在進行各節點的行為統計,為后面的信譽值更新做準備。第二次共識是在信譽值更新階段,完成各節點信譽值更新的共識。
在信譽值更新階段最后各個節點會收到來自主節點發送來的信譽消息矩陣PI,為了便于說明,假設系統3f+1 個節點中節點編號1 至2+1 的2+1 個節點為誠實節點,節點編號2+2 至3+1 的個節點可能是故障節點或惡意節點。對于一次成功的共識來說,各節點收到的信譽消息矩陣如表2所示。其中共識結果中第行第列的值為1 表示編號為的節點在數據確認階段收到節點的數據確認消息,為0 則表示未收到數據確認消息,為了表示情況的一般性,用表示不確定,即值為時值可能為0 或1。

表2 信譽消息矩陣
對于誠實節點來說,在一次成功的共識中該節點一定能接收到其他誠實節點的確認信息,所以編號為1 至2+1 的節點之間的值一定都為1。對于編號為2+2 至3+1 的節點,其余節點不確定是否能收到確認信息,且主節點不一定能收到該節點的信譽情況消息,所以涉及這些節點通信的值都為不確定。當各節點收到此消息矩陣時,便可以通過此矩陣得到共識結果以及對于信譽值的更新結果。顯然,只要各個節點所收到的信譽消息矩陣一致,最終各節點對信譽值的更新結果和對數據的共識結果都是一致的。
3.2 通信量分析
通信量就是在一輪共識過程中,系統各節點之間通信次數之和。本算法中通信量與原PBFT 算法不同的地方主要是在信譽值更新階段。在個節點的系統中,原PBFT 算法在準備階段和確認階段進行了兩次全體廣播,而改進算法只在數據確認階段進行一次全體廣播以及在信譽值更新階段進一次主節點轉播,所以改進算法通信減少量為一次全體廣播的次通信減去一次主節點轉播的2(-1)次通信,即本文算法通信量為(2-2)-(-2(-1))=+-2。
本文改進PBFT 算法的通信復雜度還是()量級,但通信量大約減少了一半。原PBFT 算法,文獻[21]提出的RB-PBFT 算法以及本文改進PBFT 算法通信量對比如表3所示。其中RB-PBFT 算法中的為該算法中每次篩選節點參與共識的節點的比例。RB-PBFT 算法是通過減少參與共識的節點數來減少通信量,與取值有關。
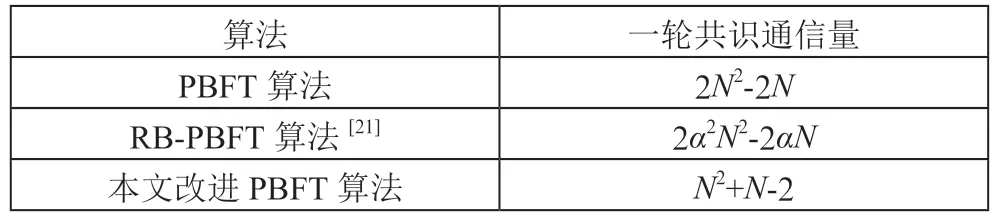
表3 算法通信量對比
3.3 公平性分析
本文算法與現有的引入信譽機制的RB-PBFT 算法相比,在公平性上也有一定的提升。RB-PBFT 算法是通過給節點信譽值排名,然后取信譽值排名靠前的一部分參加共識,這樣做雖然避免了一部分惡意節點的作惡,但這屬于一刀切策略。對于一些節點,可能只是因為網絡延遲等原因在某次共識后導致信譽值靠后,結果被踢出系統。對于一個公平的系統來說,共識過程應該是所有節點都能參與共識,只是信譽值不同的節點對共識的影響不同,改進算法很好地做到了這一點。
原PBFT、RB-PBFT 算法和本文改進算法公平性對比如表4所示。
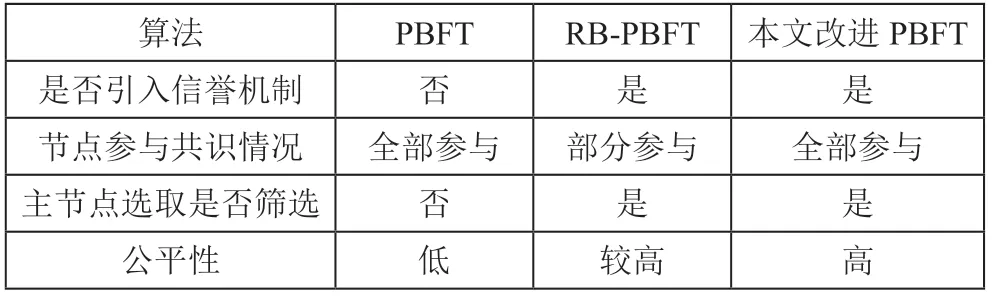
表4 各算法公平性對比表
4 結 論
本文針對PBFT 共識機制通信量高,主節點選取未篩選以及對各節點在共識過程中行為缺乏賞罰機制等問題,在PBFT 算法基礎上引入信譽值機制。通過信譽機制的引入,對各節點在每一輪共識的行為進行評判,逐漸減小故障節點和惡意節點對共識結果的影響,通過對信譽值更新達到對節點進行賞罰的目的。在選取主節點時,從信譽值達到條件的節點中篩選,減少了新的主節點仍是非誠實節點的可能性。信譽機制的引入也提高了算法的公平性。此外,改進算法還對共識流程進行了優化,在保證一致性和安全性的同時降低了每輪共識的通信量。改進算法與原PBFT 算法相比,會產生更多關于維護節點信譽值時所產生的計算上和內存空間上的消耗,如何減少這些消耗是接下來的進一步研究方向。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
中華手工(2017年2期)2017-06-06 23:00:31
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年2期)2015-04-17 01:30:34
汽車維護與修理(2015年2期)2015-02-28 12:15:39
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
