基于輕量化神經網絡的端到端人臉識別技術研究
2022-08-31 08:11:57曹戈楊周有
電腦知識與技術 2022年18期
關鍵詞:人臉識別
曹戈楊 周有

摘要:移動端設備由于計算能力有限和實時使用的速度限制,需要開發輕量化的人臉識別的深度學習算法。算法核心在于通過網絡的結構與計算參數設計,減少無關的特征冗余與非必要數據流動。本研究設計以Ghost模塊嵌入的TinyYOLO- MobileNet V3端到端識別網絡,總結出在特征圖中以小尺度替代大尺度,在計算上以線性計算代替小尺度卷積計算的設計思想。基于該思想,本研究完成了端到端架構設計并在實驗中完成了對框架的性能測試。
關鍵詞:人臉識別;Ghost模塊;TinyYOLO;MobileNet V3
中圖分類號:TP311? ? ?文獻標識碼:A
文章編號:1009-3044(2022)18-0003-03
開放科學(資源服務)標識碼(OSID):
1 引言(Introduction)
人臉作為特殊的生物ID具有自然性、唯一性和不一致性,如何高效低耗地利用人臉特性做圖像識別是人臉識別的主要任務[1]。基于空間利用[2]、深度、多路徑、寬度、特征圖利用、通道提升和注意力提升等用于人臉識別的DCNN技術層出不窮[3]。但現有模型在執行端到端識別任務過程中計算代價與復雜度過高,不適合移動端和邊緣計算設備等不具備高性能圖形處理單元(GPU)的場景。
常用圖像識別輕量卷積神經網絡主要有 SqueezeNet[4]、BlazeFaceNet[5]、MnasNet[6]、TinyYOLO[7]、GhostNet[8]、EfficientNet[9]、MobileNet[10~12]等。這些輕量級架構在移動端檢測的端到端架構中檢測識別精度受限。該問題主要來源于架構的輕量化追求與特征提取的過參數化要求的矛盾,輕量化網絡較少的參數不可避免帶來的是擬合能力的弱化。針對該問題,本研究設計了基于深度可分離卷積的TinyYOLO-MobileNet V3的端到端架構,并在MobileNet V3中引入Ghost模塊保證輕量化并增益精度。最后針對公開數據集和作者實拍數據,完成測試。
2 輕量級神經網絡技術(Light weight neural network technology)
2.1 TinyYOLO 算法簡介
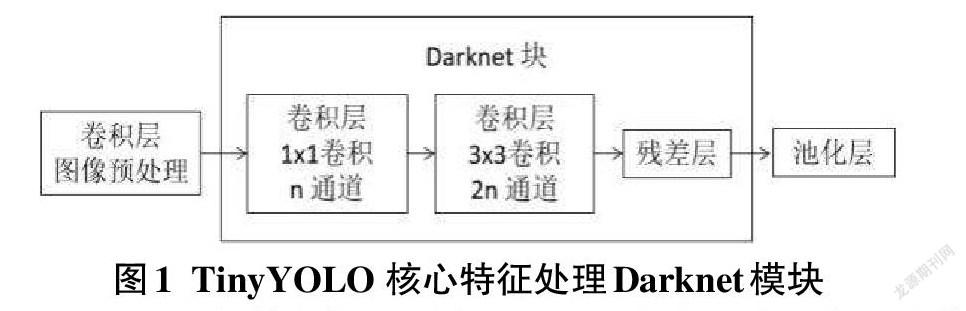
TinyYOLO的特征提取器為Darknet,由卷積殘差塊和池化層組成,結構如圖1所示,由卷積層和中間的最大集合層組成,最后一個卷積層用于進行邊界框預測。與其他網絡不同,TinyYOLO不是一個傳統的分類器,而是通過將圖像劃分成不同的邊框網格,輸出一個置信度分數,預測邊框實際上包圍了某個對象的確定性。對于每個邊界框,單元格還預測一個類別并給出所有可能類的概率分布,最后通過一個卷積層有一個1×1的內核,用于將數據減少到被劃分成的網格的大小。
2.2 MobileNet算法簡介
用計算成本更低的深度可分離卷積代替傳統卷積以降低計算成本,如圖2所示。在MobileNet V3中,網絡沒有使用最大池化來減少空間維度,但一些深度層的跨度為2,最后是一個全局平均池化層,然后是一個全連接層或1×1卷積,用于做分類。各層使用Swish作為激活函數,如圖3所示。
在深度卷積層之前是一個作為擴展層卷積,該層增加了通道的數量。整個Mobile Net V3堆疊了多個上圖2所示的架構塊以替代傳統的深度卷積殘差網絡,做了替代達到加速計算的目的。Hardwish層使用了h-swish函數,如式(1)所示。
[h_swish(x) = x×ReLU6(x + 3)6]? ? ? ? ? ? ? ? ? (1)
式中,[x]為輸入。h-swish函數作為激活函數是Google 為Android 設備(原型測試于Google Pixel的移動平臺上,以TensorFlow Lite 為開發框架)。V3中使用了Squeeze-and-Excitation Networks(SE)模塊,通過對特征通道間的相關性進行建模,把重要的特征進行強化來提升準確率。模塊沒有使用sigmoid,而是使用h-swish函數作為粗略的近似值。通過采用近似計算的方法,節省了激活函數的計算成本。在V3的架構能夠處理更小的1×1特征圖,并由于摒棄了其他輕量級網絡的瓶頸層和深度卷積層,提高了精度損失。
3 端到端人臉識別架構(End-to-end face recognition architecture)
3.1 GhostNet模塊
通常卷積層中的卷積核越少,速度越快,但表現力也越差,因為最終得到的特征圖越少。而GhostNet的設計思想為:通過使用比完全卷積更便宜的特征提取操作(被稱為原主干網絡的Ghost),合成額外的特征圖可以彌補這一點[12]。因為不同通道的特征圖在CNN的訓練過程中很類似。
本研究在此提出基于深度可分離卷積的Ghost模塊,結構如圖4所示。首先通過Keras深度學習框架的Lambda層分割數據,執行小規模的深度可分離卷積,生成了少量的特征圖。然后通過簡單的線性變換創建Ghost特征。這些特征圖與原特征圖相連接通過線性層加權輸出,從而達到以更具成本效益的方式復現了這些冗余的特征圖,參數量降低為原來的一半。
3.2 端到端架構
本文基于TinyYOLO與MobileNetV3搭建如圖5所示的端到端人臉識別框架,其中,TinyYOLO負責人臉定位,MobileNet負責人臉識別。TinyYOLO的主干網絡,主干網絡采用一個7層卷積加最大池化層的網絡提取特征,YOLO嫁接網絡采用的是58*56、26*26的分辨率探測網絡,TinyYOLO去輸出層將框定的人臉特征直接輸入融合了Ghost Module的MobileNetV3中,最后通過SoftMax完成識別。
該網絡的優勢在于通過下列方法兼顧精度與運算速度:在神經網絡的層間數據流動中,通過更多的小型特征圖彌補對單個大型特征圖的計算不足(權衡寬度乘法與深度乘法);通過廉價的線性或小尺度計算替代昂貴的卷積運算;在模塊中大量運用了深度可分離卷積處理輸出。
4 實驗分析(Experimental analysis)
4.1實驗數據與訓練細節
采用FDDB公開數據集[13]完成算法的訓練,該數據集包含2845張圖片,共有5171個人臉作為測試集。測試集范圍包括:不同姿勢、不同分辨率、旋轉和遮擋等圖片。并采用手機拍照收集的圖片作為驗證集。并在實測中比較所提出架構與YOLO-SqueezeNet和YoLo-MobileNetV3_Small等端到端框架的檢驗識別能力,在訓練中的評價函數為識別的RMSE誤差。訓練平臺為Colab,步數為500。訓練結果如圖6所示,可以看出,所提出的架構訓練成本低,算法迅速收斂并且所提出的Ghost模塊能有效捕捉人臉特征。
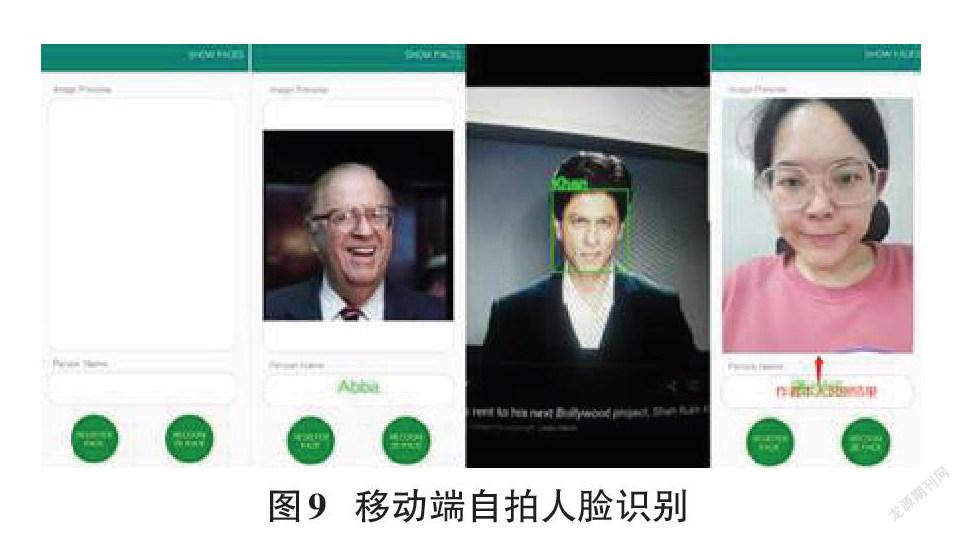
在移動端,基于tensorflow lite將算法遷移到用TensorFlow自帶的工具來fine-tuning訓練上訴架構,將生成的pb文件轉換為tflite文件,后用Android studio打包成apk。在實際環境中,通過手機相冊數據及實時自拍檢測部署后的識別能力。
4.2 實驗結果
與其他典型輕量化端到端框架的對比結果詳見表1,通過實驗結果可知,本研究方法具有更輕量化的架構和更高的識別精度。
在實拍和手機端對移植算法的檢測中,可以看出,算法能有效定位和識別人臉。
5 結論(Conclusion)
本研究設計了基于TinyYOlO與Ghost模塊改進的MobileNet V3的端到端人臉識別框架,總結了兼顧輕量化和精度的設計思想,并最終在現有數據集和作者自拍識別的實驗中進行驗證,實驗結果證明了該架構的精確有效。相較于主流架構YOLO-SqueezeNet(3.8M 參數量,0.5092s檢測識別速度,72%識別精度)與YOLO-MobileNetV3_Small(3.9M參數量, 0.6106s檢測識別速度,82%識別精度),本文的架構在1.4M參數量下,檢測識別速度為0.2192s,識別精度為90%。
參考文獻:
[1] Nirkin Y,Wolf L,Keller Y,et al.DeepFake detection based on
discrepancies between faces and their context[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2021.
[2] Khan A,Sohail A,Zahoora U,et al.A survey of the recent architectures of deep convolutional neural networks[J].Artificial Intelligence Review,2020,53(8):5455-5516.
[3] Chai J Y,Zeng H,Li A M,et al.Deep learning in computer vision:a critical review of emerging techniques and application scenarios[J].Machine Learning With Applications,2021,6:100-134.
[4] Li G F,Tong N N,Zhang Y S,et al.Moving target detection classifier for airborne radar using SqueezeNet[J].Journal of Physics:Conference Series,2021,1883(1):012003.
[5] Bazarevsky V,Kartynnik Y,Vakunov A,et al.Blazeface: Sub-millisecond neural face detection on mobile gpus[J].arXiv preprint arXiv:1907.05047,2019.
[6] 楊國亮,朱晨,李放,等.基于改進MnasNet網絡的低分辨率圖像分類算法[J].傳感器與微系統,2021,40(2):142-145,153.
[7] 燕紅文,劉振宇,崔清亮,等.基于改進Tiny-YOLO模型的群養生豬臉部姿態檢測[J].農業工程學報,2019,35(18):169-179.
[8] 程春陽,吳小俊,徐天陽.基于GhostNet的端到端紅外和可見光圖像融合方法[J].模式識別與人工智能,2021,34(11):1028-1037.
[9] Xiao Y H,Zhou J Y,Yu Y Z,et al.Active jamming recognition based on bilinear EfficientNet and attention mechanism[J].IET Radar,Sonar & Navigation,2021,15(9):957-968.
[10] 郭奕君,阿里木江·阿布迪日依木,努爾畢亞·亞地卡爾,等.基于MobileNet網絡多國人臉分類識別[J].圖像與信號處理,2020(3):146-155.
[11] Kadam K,Ahirrao S,Kotecha K,et al.Detection and localization of multiple image splicing using MobileNet V1[J].IEEE Access,9:162499-162519.
[12] Han K,Wang Y H,Tian Q,et al.GhostNet:more features from cheap operations[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 13-19,2020,Seattle,WA,USA.IEEE,2020:1577-1586.
[13] Jain V,Learned-Miller E.Fddb:A benchmark for face detection in unconstrained settings[R].UMass Amherst technical report,2010.
【通聯編輯:梁書】
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
學生天地(2020年31期)2020-06-01 02:32:06
電子制作(2019年14期)2019-08-20 05:43:34
中國交通信息化(2018年1期)2018-06-06 07:29:55
電子制作(2017年17期)2017-12-18 06:40:55
中國公共安全(2017年7期)2017-10-13 08:18:26
電子制作(2017年1期)2017-05-17 03:54:46
中國公共安全(2017年9期)2017-02-06 03:05:32
現代工業經濟和信息化(2016年6期)2016-05-17 05:36:23
華東理工大學學報(自然科學版)(2015年2期)2015-11-07 09:16:51
