基于生成式對抗網(wǎng)絡的書法圖像修復研究
2022-08-31 13:57:02何仁杰張立輝郭秀娟
吉林工程技術師范學院學報 2022年6期
何仁杰,張立輝,郭秀娟
(吉林建筑大學,吉林 長春 130118)
圖像修復技術是一項依據(jù)殘缺圖像已有的圖像特征推測并試圖還原殘缺處的技術手段,是極具競爭力的革命性技術,其應用領域遍及各類行業(yè)。傳統(tǒng)的圖像修復技術基于圖像的紋理、內(nèi)容的相似性,通過數(shù)學與物理理論建模,達到修復的目的。傳統(tǒng)圖像修復方法在解決大面積圖像殘缺問題時顯得捉襟見肘,這是受限于計算機缺乏圖像感知力和圖像理解能力,導致修復結果內(nèi)容缺失。現(xiàn)今,隨著計算機科學與通信技術的迅速發(fā)展,各類深度學習模型如雨后春筍般出現(xiàn)。Goodfellow等人基于博弈思想與擬合數(shù)據(jù)分布提出生成式對抗網(wǎng)絡(Generative Adversarial Networks,簡稱GAN)模型,使得圖像修復技術有了突破性進展。生成式對抗網(wǎng)絡在自然語言和計算機視覺領域中扮演著重要角色。本文基于生成式對抗網(wǎng)絡建立雙生成器模型在書法圖像修復中的應用,闡明基于損失函數(shù)的優(yōu)化可提升圖像生成及模型收斂的速度,并對未來GAN的發(fā)展與研究方向作出展望。
一、GAN網(wǎng)絡模型介紹
Goodfellow提出的GAN網(wǎng)絡模型如圖1所示,它的最重要的組成部分是生成器與判別器,通過彼此之間的相互博弈,達到模型平衡。它是一種生成式模型,相對于其他生成模型,只用到了反向傳播,而不需要復雜的馬爾科夫鏈[1]。
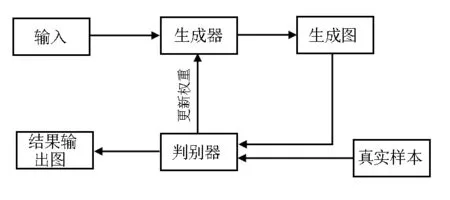
圖1 GAN網(wǎng)絡模型
式中,E(*)是分布函數(shù)期望值,Pdata(x)代表真實樣本分布,Pdata(z)是定義在低維的噪聲分布,D(x)是生成樣本,D(G(z))是生成樣本的判別。
(一)雙生成器GAN模型
雙生成器GAN模型是在經(jīng)典GAN 網(wǎng)絡模型的基礎上進一步優(yōu)化得來的,模型結構如圖2所示。利用雙生成器能夠快速生成圖像的特點,能夠加快整個模型的收斂速度。
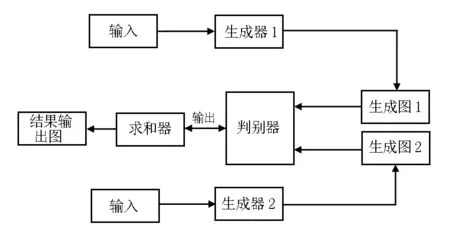
圖2 雙生成器GAN模型
向生成器G1、G2中輸入兩張預處理過的殘缺圖像,通過f(z)的映射關系將生成隨機修復分布gi與gj。基于博弈對抗思想,訓練生成模型與判別模型,經(jīng)過多次迭代后,得到生成模型與判別模型最優(yōu)的修復網(wǎng)絡模型[3]。與一般的GAN相比,雙生成器GAN網(wǎng)絡模型輸入的是殘缺圖像,并不是隨機噪聲,具有兩個生成器,這就提高了圖像生成與模型參數(shù)尋優(yōu)的速度,加快了整個模型的收斂,從理論上來說,收斂速度是一般模型的2倍[4]。
(二)判別器損失函數(shù)
GAN訓練是獨自交替迭代的,因此損失函數(shù)同樣是依次對判別器和生成器進行優(yōu)化。第一對判別器進行優(yōu)化,由于每次迭代都是由雙生成器產(chǎn)生兩個隨機修復分布數(shù)據(jù),所以判別器的損失函數(shù)由gi與gj決定[5],表達式如下:
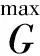
判斷結果越接近1越好,因此損失函數(shù)為log(D(x)),而z是隨機輸入的,G(z)代表生成的樣本,對于生成的樣本,判別器的判斷結果D(G(z))越接近0越好,也就是讓總數(shù)值最大,所以兩個生成器的隨機修復數(shù)據(jù)期望分布選取最小值[6]。
(三)生成器損失函數(shù)
為了讓雙生成器生成更好的生成樣本,可以讓判別網(wǎng)絡使兩個生成器同概率提高,因此需要輸出判別網(wǎng)絡最小值,生成器損失函數(shù)如下:
陳果夫:《上蔣委員長建議今后黨的宣傳工作宜重人才培養(yǎng)延攬、啟發(fā)鼓勵書》(1943年5月7日),李云漢主編:《陳果夫先生文集》,(臺灣)“國民黨中央黨史會”1993年版,第27頁。
(四)模型的可行性分析
在實驗之前,本文采用MNIST手寫數(shù)據(jù)集來驗證該模型的可行性。MNIST是28×28 的手寫數(shù)字數(shù)據(jù)集,訓練集包含60000個示例。這時網(wǎng)絡的每次輸入是兩個隨機噪聲,主要是驗證網(wǎng)絡模型尋優(yōu)參數(shù)的速度以及圖像生成收斂速度。MNIST手寫數(shù)據(jù)生成圖見圖3。

圖3 MNIST手寫數(shù)據(jù)生成圖
在圖3中,每張圖片是間隔迭代100次的生成圖,利用雙生成器網(wǎng)絡模型,1200步時已經(jīng)達到了非常好的效果,可行性實驗證明該模型的參數(shù)尋優(yōu)速度比一般模型快了近2倍。這是由于每次迭代的兩個隨機修復分布數(shù)據(jù)都是取最小值去更新生成器G的參數(shù)[7],這使得梯度下降加快,從而加快了尋求全局最優(yōu)點的速度。驗證實驗數(shù)據(jù)如圖4所示。
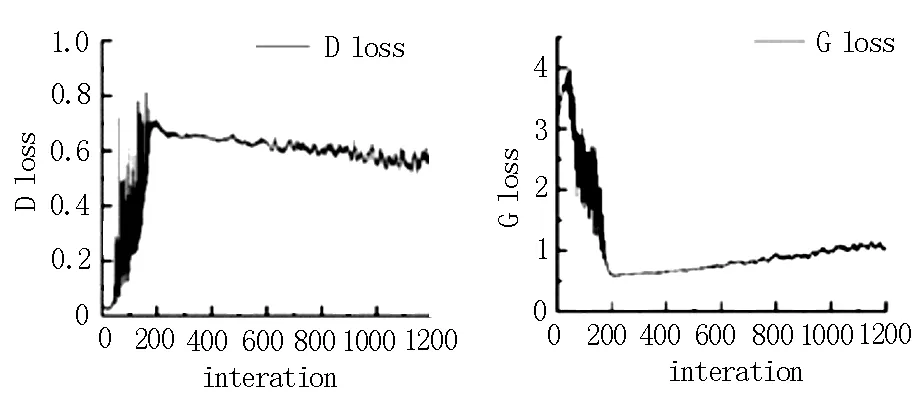
圖4 DG模型的損失值
圖4是判別器模型與生成器模型在訓練過程中的損失值變化數(shù)據(jù),橫坐標表示訓練迭代次數(shù),可以清楚地看到Gloss在訓練之處損失值迅速下降,在迭代200次時逐漸平緩。這里的Gloss數(shù)值取的是兩個生成器損失值的平均值[8],公式如下:
GLoss=average(G1 Loss+G2 Loss)
GAN網(wǎng)絡模型就是通過生成器與判別器不斷地博弈來更新網(wǎng)絡參數(shù),提升網(wǎng)絡的性能。最理想的網(wǎng)絡模型是生成一張圖片,判別器判別結果是50%為真,50%為假,這就是網(wǎng)絡模型的納什平衡狀態(tài)[9]。驗證實驗的判別準確率如圖5所示。
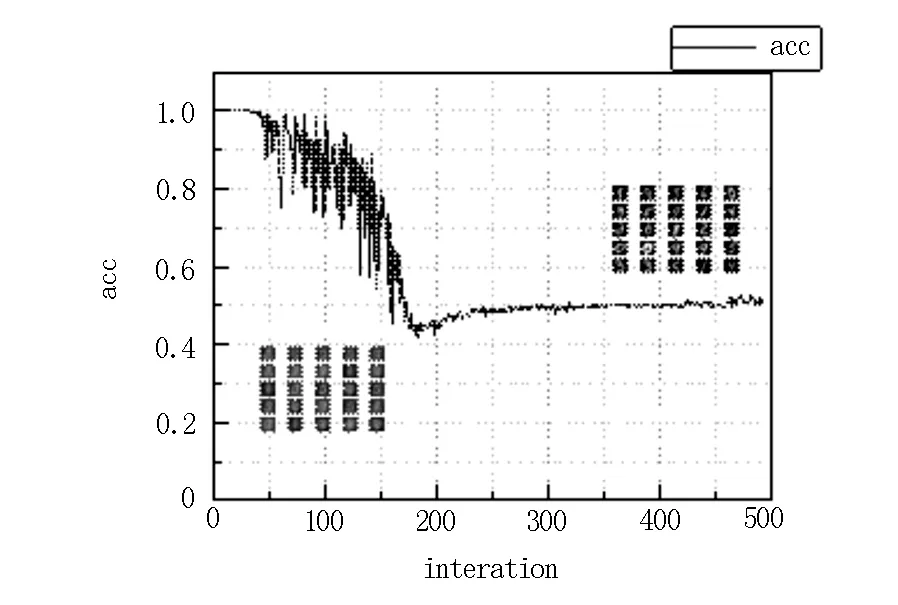
圖5 判別準確率
在實驗迭代100次時,判別準確值的波動非常大,可以判定生成器還處于“盲猜”水平,輸出迭代100次時的圖像非常模糊。當訓練繼續(xù)進行后,500次迭代時基本上處于納什平衡狀態(tài),輸出的生成圖片相當清晰,與實驗思路基本符合。此實驗結果表明雙生成器GAN網(wǎng)絡模型在圖像處理方面是可行的。
二、實驗
(一)數(shù)據(jù)集
本文提出對殘缺書法圖像進行修復的方案,數(shù)據(jù)集是100個漢字,每個漢字400張, 為不同書法風格,像素值為160×160,總計40000張圖片,將其中的一半進行隨機高斯掩膜處理,得到殘缺圖像,如圖6所示。

圖6 奉、白、常掩膜殘缺圖示
將圖片進行隨機掩膜處理,每張圖片的殘缺位置隨機,這樣就有效避免了同一位置掩膜導致模型欠擬合的問題。在數(shù)據(jù)集在被訓練之前,為了更加有效地利用數(shù)據(jù)集,還要進行批量的歸一化處理,采用批標準化Batch Normalize(BN)的方法。BN網(wǎng)絡擁有加速網(wǎng)絡收斂速度、防止“梯度彌散”、可以使用較大的學習率等優(yōu)點。公式如下:
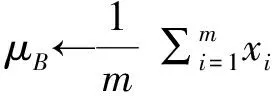
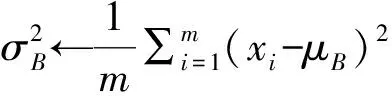
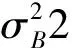
每張圖片的殘缺位置隨機,為了快速定位殘缺位置,本文以SSD框架對殘缺圖像進行精確定位。SSD框架可以被簡單地理解為YOLO與快速卷積的優(yōu)點集合。這種做法可以使模型快速地定位于待修復區(qū)域,從而有效地提升模型的性能。
(二)訓練過程
生成式對抗網(wǎng)絡訓練分兩步走,當訓練其中一種模型時,另一種模型的參數(shù)保持不變,這就是確定標準化,可以有效地避免模型在訓練過程中不穩(wěn)定,難以達到理想的結果。以“白”字為例,對其進行隨機掩膜處理之后,打亂樣本,以輸入順序作為訓練集,經(jīng)過幾次迭代,結果如圖7所示。

圖7 訓練損失值
在圖7中,上下兩條曲線是對于生成器與判別器訓練損失的擬合曲線。Gloss代表兩個生成器損失值的均值,數(shù)值先快速下降,然后發(fā)生平緩變化。Dloss代表判別器的損失值,在輸出Gloss值時添加負號,為了讓其能更好地取到最小值以及畫圖時與Dloss能夠區(qū)分開來,Dloss下降一點兒之后便開始平緩變化。隨著生成函數(shù)的損失值逐漸變小,判別函數(shù)損失值變大后逐步調(diào)整,輸入的殘缺圖像逐漸得到修復。從圖7可以看出,當模型訓練迭代200次之后,損失值變化浮動不大,表明模型的穩(wěn)定性較好。
(三)實驗結果
將殘缺的書法圖片輸入網(wǎng)絡模型中,將學習率調(diào)為0.001,經(jīng)過1000次迭代,從模型的生成文件中可以看到圖像被修復之后的樣子。圖8為“奉”“白”“常”修復圖片。

圖8 奉、白、常修復圖片
圖8中三個漢字的修復效果達到了實驗的預期效果,在“白”字的虛化圖像中,也有較好的表現(xiàn),表明該模型在修復書法方面有著很好的實用性。
單生成器與雙生成器模型修復圖像質(zhì)量評價數(shù)值見表1。
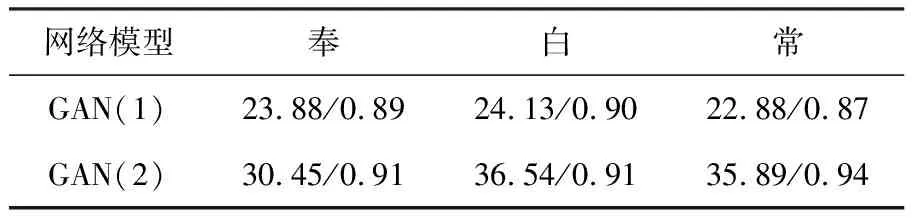
表1 兩種模型圖像質(zhì)量評價標準PSNR/SSIM數(shù)值
由表1中的數(shù)據(jù)可以看出,雙生成器的GAN模型PSNR/SSIM數(shù)值要大于單生成器的GAN模型PSNR/SSIM數(shù)值,這說明本文提出的模型在書法修復應用上,修復圖像的質(zhì)量優(yōu)于單生成器模型。
三、結語
本文提出的生成器模型在殘缺書法修復上的應用是具有可行性的,并且達到了實驗的預期結果,后續(xù)改善網(wǎng)絡模型可以從更大的數(shù)據(jù)集以及損失函數(shù)構建著手。更大的數(shù)據(jù)集可以修復和完善更多的漢字,優(yōu)化損失函數(shù),更加契合網(wǎng)絡快速收斂的特性,服務于古字畫研究。筆者希望今后驗證在兩個G損失函數(shù)中選擇下降最快的損失更新參數(shù)的算法模型。本文提到的快速收斂是相對于其他模型來說的,在生成式對抗網(wǎng)絡模型中,收斂問題一直是非常棘手的問題。為了最終收斂,需要添加設置參數(shù)去平衡生成器與判別器,這就給模型增加了更多的計算量,這可以通過設計更好的網(wǎng)絡模型和一些訓練技巧來解決。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
核科學與工程(2015年4期)2015-09-26 11:59:03
