招聘數據可視化分析系統的設計與實現
2022-08-31 19:18:39黃錦帆梁少華張佳
電腦知識與技術 2022年18期
黃錦帆 梁少華 張佳
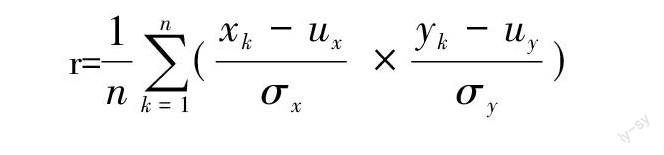
摘要:通過對當今的招聘現狀進行研究,該文設計并開發出一款可視化分析系統,主要分為數據采集、存儲與處理、數據分析、可視化等功能模塊。通過網絡爬蟲爬取到的招聘數據,經預處理和分析之后,將學歷、熱門職位、福利待遇及技能要求等進行可視化展示,采用基于用戶的協同過濾算法對職位進行推薦并實現動態更新。在一定程度上可幫助求職者了解目前的社會人才招聘需求,快速找準自身定位。
關鍵詞:網絡爬蟲;招聘數據;協同過濾;可視化分析
中圖分類號:TP311? 文獻標識碼:A
文章編號:1009-3044(2022)18-0039-03
開放科學(資源服務)標識碼(OSID):
1 引言
隨著國內互聯網行業的飛速發展,以及一些非傳統因素的影響,網絡求職招聘愈發受到人們的歡迎。但其中也出現了一些問題,最突出的就是信息繁多雜亂,人崗的信息匹配度不是很理想。求職者希望可以直觀地看到某行業的現狀、發展前景以及招聘要求[1]。因此,我們可以利用相應的數據可視化技術,采用圖表及圖示等方式來展示分析后的結果,幫助他們提高求職效率。
2 相關技術
2.1 Scrapy爬蟲
它是基于Python開發的一個快速抓取Web站點并提取結構化數據的一個爬蟲框架,其主要由調度器、下載器、爬蟲、實體管道、Scrapy引擎構成。它的優勢就是使用了Twisted異步網絡框架處理網絡通信,大大加快了下載速率。工作流程如下:首先爬蟲將發送請求的URL經引擎交給調度器,然后其處理后通過下載中間件傳給下載器,下載器對網頁發起請求并接受下載響應經過引擎傳給爬蟲,爬蟲接收響應并解析提取數據,最后將數據通過實體管道保存到本地或對應數據庫[2],根據所需重復上述過程直到停止。
2.2 職位推薦算法
對求職者進行相應的職位推薦,需要精準地了解到每個人的個性職位需求, 通過他們對某類職位的搜索次數以及對詳細信息的查看收藏次數,系統會進行相關熱度的計算并排序。這里采用了基于用戶的協同過濾算法,對歷史行為數據進行度量打分,根據不同的求職者對某職位的偏好程度,使用歐幾里得距離評價公式來計算他們之間的系數關系。通過求職者之間的相似度數值,選擇關系最接近的用戶,利用他們的喜好為當前用戶進行相應的職位推薦[3]。 職位推薦信息將會隨著用戶的點擊不斷地動態實時更新,更加智能化地幫助求職者找到合適的崗位。
2.3 可視化技術
可視化技術就是將大量雜亂的數據轉化為人們直觀易懂的可視化形式,突出重點、條理分明地將分析結果展示出來,其中包含了科學計算可視化、數據可視化及信息可視化。Python中封裝了大量的繪制圖表庫,如:matplotlib、bokeh等。在對網絡招聘數據的分析中,如何去設計頁面,使其美觀又不突兀,展示出所需的結果,是需要考慮的問題。本文通過對目前主流的可視化庫進行比較,最后采用的是pyecharts可視化庫,它將基于百度可視化設計開源的Echarts庫和Python語言相結合,方便在Python中調用Echarts接口[4],直接生成可視化圖表,還可以生成可視化的HTML網頁,使用起來很方便。
3 系統設計
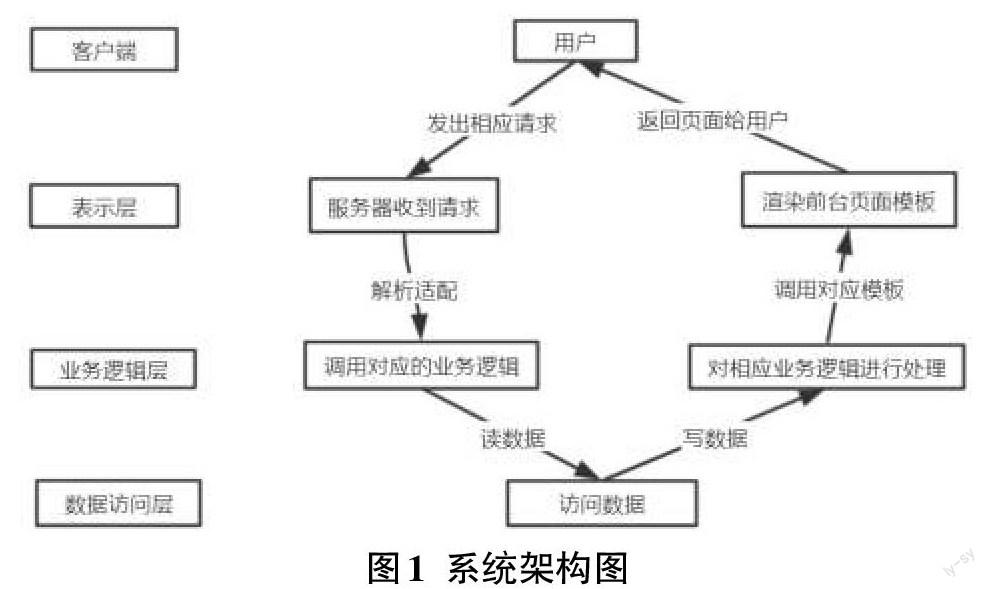
本系統基于B/S架構開發,主要分為數據采集、存儲和處理、數據分析、可視化四大功能模塊,將大量的業務邏輯直接在服務器端實現,降低了開發和維護成本,也方便了用戶使用。使用三層結構對系統進行切片分層,模塊化的迭代式開發,保證了各功能模塊的獨立性,便于開發和維護工作的展開。從上到下依次分為表示層、業務邏輯層、數據訪問層。架構圖如圖1所示。
4 系統實現
4.1 數據采集模塊
網絡爬蟲主要是通過偽裝瀏覽器頭等繞開反爬機制,編寫遵循一定規則的腳本或者程序對網站的信息進行爬取,設計適宜的解析結構對網頁結構進行解析得到數據。首先訪問Boss直聘,點擊不同的界面觀察,右鍵檢查進入開發者工具,點擊Network,按F5刷新,觀察URL結構。然后設計爬蟲的基本結構,構造動態的URL來爬取想要的信息。為了繞開反扒機制,通過在瀏覽器的Headers中看到的User-Agent和Accept-Language以及Cookie,以此構造表頭,讓瀏覽器允許爬蟲腳本訪問。將需要爬取的key關鍵字存儲在字典中,通過item方法進行關鍵字的獲取,以便后面的爬取[5],使用的是request庫中的request.get()方法來獲取頁面,返回response對象。在Resopnse中可以看到爬取的字段的網頁構造,以便于后面的解析數據。
4.2 數據存儲和處理模塊
由于爬蟲獲取到的數據并不都是符合規范的,存在著重復、不一致、錯誤、空值等問題。為了解決此不足,本文使用了Pandas庫來進行數據處理的工作。首先將數據轉換為DataFrame格式,通過使用其中的isnull()方法來判斷數據是否為空值,DataFrame.fillna()方法對數據進行填充;DataFrame.drop_duplicates()可以快速按行檢測并刪除重復的記錄[6]。
Python中包含了很多的常見存儲方式,如:MySQL、CSV文件、JSON文件等,這里使用的是MongoDB非關系型數據庫,它基于Key-Value保存數據,能很好地適應爬蟲字段變化,非常適合存儲爬取到的招聘信息中的職位名稱、工作地點、薪資福利待遇、學歷和技能要求等結構化文本字段。用它存儲數據時,需要事先安裝好MongoDB數據庫并啟動相應服務,在Python中導入pymongo庫,然后使用client=pymongo.MongoClient(host=‘localhost,port=27017)創建數據庫連接對象,導入處理之后的數據集。
4.3 數據分析模塊
數據分析是整個流程中最重要的階段,它主要的工作是將上階段經過清洗處理之后的數據按照一定的規則方法進行分析,為之后的可視化展示提供數據支撐[7]。主要涉及:中文分詞、工作經驗及學歷與薪資關系、熱門職位、繪制職位技能關鍵詞和福利待遇詞云圖、崗位地點分布等。
1)中文分詞:招聘信息多為中文文本,這里采用了jieba作為分詞工具。它基于前綴詞典實現高效的詞圖掃描,生成句子中漢字所有可能成詞情況所構成的DAG,采用動態規劃去查找最大的概率路徑, 找出基于詞頻的最大切分組合。具有高性能、準確率高、速度快等特點。
2)工作經驗、學歷與薪資的相關性:采用最小二乘法計算兩組數據的線性相關程度,公式如下:
r=[1nk=1n(xk- uxσx? × yk- uyσy)]
其中,[ux]、[σx]分別表示數據列x的平均值和標準差,[uy]、[σy]分別表示數據列y的平均值和標準差。相關系數r的值越接近于[±]1,說明相關程度越強;r越接近于0,說明數據相關性越差。
3)熱門職位:首先使用K-means聚類算法,將數據中的職位名稱字段進行分類,統計出數量最多的職位類別。在此類中對職位名稱字段使用jieba進行中文分詞處理,統計它們出現的詞頻大小,得到出現次數最多的幾個職位關鍵詞,則它們就是此類中的熱門職位。
4)繪制技能及福利詞云圖:每個行業類型的職位技能關鍵字和福利待遇詞云的實現主要是通過遍歷所有的職位信息,再使用jieba分析統計各種關鍵字出現的次數,統計詞頻進行格式的轉換。最后使用Python的List.sort()方法設定參數進行排序,就可以得到其頻率順序,從而通過Python中的WordCloud庫繪制這些詞的詞云,在可視化界面進行展示。
5)崗位地點分布:通過對工作城市關鍵字進行分詞統計,計算每個的總數大小。繪制分布圖來展示全國的工作崗位城市分布圖,可以通過圖上的顏色深淺大小來判斷崗位的數量。
4.4 數據可視化模塊
系統最后就是要實現對網絡招聘數據的可視化分析,將分析之后的結果以圖表或圖畫的形式展現在前臺界面上。主要使用了目前的主流開發Python Web框架Django以及pyecharts開源可視化庫[8]。
Django框架采用的是MVT模式,系統中的settings.py存放的是項目的各類配置文件,urls.py存放的是路由,wsgi.py是Web服務器與Django交互的入口。工作原理如下:首先是用戶通過瀏覽器來對頁面發起請求,之后請求會到達Request MiddlewaRes,其會對request做預處理或者是直接response回應,URLConf會將請求的url用來和urls.py中的進行匹配,從而找到相應的views。找到之后,就可以調用視圖views中的對應函數對業務邏輯進行處理。視圖views作為溝通橋梁,可以通過調用Model層來對數據庫中的數據進行訪問并返回。views接收到請求之后,構造一個HttpResponse響應對象,可以使用context來對上下文進行處理,context被傳遞給template用來生成頁面。調用模板template里的render()方法并使用context傳進的參數渲染HTML界面,將響應對象返回到瀏覽器,呈現給用戶。
5 可視化分析結果
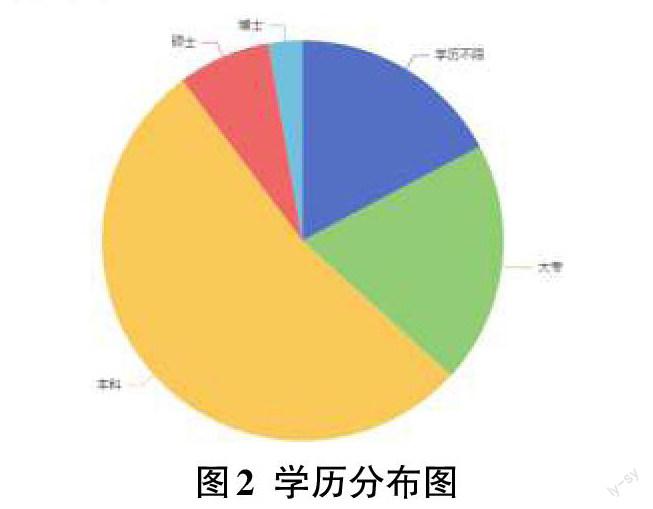
1)學歷分布狀況
在這個科技高速發展的時代,學歷是求職的敲門磚。對于沒有實踐經驗的應屆畢業生來說,更是衡量其學習能力、自身素質的重要因素。從分析結果可知,本科占據了大多數,與目前的教育狀況有關。另外,我們可以了解到現在的企業對求職者的學歷層次要求,更好地找準自身定位[9]。
2)熱門職位展示
隨著科學技術的飛速發展,以人工智能領域為例,自動駕駛、元宇宙風頭正盛,但也急需新的人工智能算法去解決出現的問題。因此,使得算法工程師、圖像處理、數據挖掘等領域也日趨熱門。隨著國家政策的不斷投入,工業產業鏈升級,相關的人才缺口巨大,創造了很多的就業機會。
3)數據挖掘的福利待遇詞云圖
以數據挖掘崗位為例,在眾多的福利待遇中,五險一金是其中最基本最重要的保障,隨之是績效和年終獎等,這是激勵求職者的重要手段。
4)職位技能要求詞云圖
以Python開發工程師為例,可以看到的是對于數據庫以及Web框架、工作經驗、競賽還是比較看重的。對于之后有志從事于此的學生,要注意這方面的積累,打好堅實的專業基礎。
6 結束語
針對眾多的線上招聘信息,本文設計開發出一款基于網絡爬蟲的招聘數據可視化分析系統。采用的開發技術和方式,占用內存少,完整地實現了功能。采用基于用戶的協同過濾算法對求職者進行職位推薦,以各類圖表以及詞云的形式直觀地給用戶展示了各類分析結果,為他們展示了一個清晰的招聘求職現狀。它在一定程度上幫助人們找準定位,及時調整求職方式和策略,具有積極的指導意義。
參考文獻:
[1] 韓月喬.中小企業網絡招聘問題研究[J].價值工程,2020,39(16):223-224.
[2] 黎妍,肖卓宇.引入Scrapy框架的Python網絡爬蟲應用研究[J].福建電腦,2021,37(10):58-60.
[3] 王碩.基于協同過濾的農業新聞推薦系統的研究[D].長春:吉林農業大學,2021.
[4] 侯瑾菲,梁藝多.基于Python的政府開放數據可視化應用研究[J].科學技術創新,2021(34):160-162.
[5] 黎曦.基于網絡爬蟲的論壇數據分析系統的設計與實現[D].武漢:華中科技大學,2019.
[6] 殷麗鳳,張浩然.基于Python網上招聘信息的爬取和分析[J].電子設計工程,2019,27(20):22-26.
[7] 孫亞紅.基于Python的招聘信息爬蟲系統設計[J].軟件,2020,41(10):213-214,235.
[8] 白昌盛.基于 Django的 Python Web開發[J].信息與電腦,2019,31(24):37-40.
[9] 扶明亮,李剛.基于招聘網站大數據分析的求職者需求與企業需求匹配研究[J].統計與管理,2021,36(8):91-97.
【通聯編輯:梁書】
