NDN 中邊緣計算與緩存的聯合優化
2022-09-03 10:30:38張宇程旻
通信學報 2022年8期
張宇,程旻
(1.北京理工大學信息與電子學院,北京 100081;2.上海機電工程研究所,上海 201109)
0 引言
隨著互聯網業務的蓬勃發展,網絡的業務模式正在由傳統的點對點數據傳輸模式演變為以信息共享為主的轉發模式。通信方式中數據物理位置的重要性被逐漸淡化,用戶關注的重心轉向了數據內容本身。在此趨勢下,美國國家科學基金會針對基于TCP/IP 的傳統網絡架構提出的解決方案——命名數據網絡(NDN,named data networking),其采用基于內容名稱的路由和轉發實現對數據的檢索和獲取[1],成為當前的研究熱點。與此同時,隨著計算和存儲逐漸成為網絡的重要功能,計算、存儲與網絡基礎設施的融合也正成為未來網絡發展的重要趨勢。邊緣計算作為5G 網絡的關鍵技術之一,將計算和存儲資源一同下沉到靠近終端用戶的邊緣節點,以緩解帶寬壓力、改善用戶體驗。NDN 的相關機制如基于內容名稱進行路由、節點具備一定存儲能力等,與邊緣計算的設計方向不謀而合,恰好能夠為構建網絡、計算、存儲一體化的未來網絡提供重要的技術支撐,因此在NDN 中設計與邊緣計算相結合的綜合框架并實現對計算和緩存資源的協同管理具有重要的研究意義與價值。
傳統的資源分配和緩存策略根據特定的數學模型做出決策[2-7],忽略了節點之間流量波動的相關性和不同區域用戶偏好的差異性,使計算和緩存資源不能得以有效利用。此外,雖然全球每天產生約80 EB 的數據量,但用戶對其中絕大部分內容的評價是沒有記錄的,而長尾理論表明,在網絡時代,冷門內容的運營收益未必會低于當前關注度高的內容。事實上,當前大多數緩存策略的設計都忽略了長尾內容的潛在收益。
現有的優化方法如凸優化和博弈論等雖然已被廣泛應用于改進資源分配方案和緩存策略,但仍存在以下問題:1)一些關鍵因素如無線信道條件、不同應用的具體要求和內容流行度等被提前設定,而在現實中,這些信息難以直接獲得且會隨時間變化;2)除Lyapunov 優化[8]外,目前大多數算法只對系統快照進行優化而沒有考慮到當前決策對資源管理的長期影響,即系統的動態問題沒有得到很好的解決。
機器學習作為一種新興的數據分析及處理手段,可以從傳統方法難以建模和分析的數據中得到隱含的趨勢和關聯,能夠更好地在內容流行度未知且動態變化的網絡中賦予計算和緩存更多的自主性和智能性,幫助其學習如何根據已有的經驗進行協調優化,有望推動實現未來網絡的內生智能。深度強化學習作為機器學習領域中最具潛力的研究方向之一,將深度學習的感知能力和強化學習的決策能力相結合,有助于解決實際場景中的復雜問題。深度Q 網絡(DQN,deep Q network)算法作為經典的深度強化學習算法,雖然解決了高維觀察空間的問題,但其依賴于找到使價值函數最大的動作[9-10],在連續域的情況下需要在每個步驟進行迭代優化,因此目前只能處理離散和低維的動作空間。此外,DQN 采取隨機的動作策略,即每次進入相同狀態的時候,輸出的動作會服從一個概率分布,這導致智能體的行為具有較大的異變性,參數更新的方向很可能不是策略梯度的最優方向。
針對上述問題,本文提出在NDN 邊緣節點部署計算模塊,使節點兼具緩存和計算能力,在網絡邊緣創建分布式的輕型數據處理中心[11];利用深度確定性策略梯度(DDPG,deep deterministic policy gradient)算法對計算和緩存資源的管理進行聯合優化,以實現網絡、計算和緩存功能動態協調的綜合框架。具體創新點如下。
1)在NDN 中設計與邊緣計算相結合的綜合框架。在NDN 邊緣節點部署計算模塊和智能體,在將內容和資源向終端用戶靠近的同時,實時感知網絡狀態,在與環境的交互中學習最優的計算和緩存的資源分配以及緩存放置策略。
2)提出基于矩陣分解[12]的局部內容流行度預測算法。矩陣分解算法引入了隱向量的概念,將高維矩陣映射成2 個低維矩陣的乘積,使之具有強大的處理稀疏矩陣的能力;通過補全用戶對內容的評分矩陣,將與邊緣節點直接連接的所有用戶對某個內容的相對評分作為該內容的局部內容流行度。
3)在平均時延的約束下,以系統運營收益最大化為目標,利用DDPG 算法對計算和緩存資源分配以及緩存放置策略進行聯合優化。DDPG 算法將動作策略的探索和更新分離,前者采用隨機策略,后者采用確定性策略[13];可以在高維的連續動作空間中學習策略,適用于邊緣計算和緩存聯合優化時的連續性控制問題。
4)在ndnSIM 中構建仿真環境,通過DDPG 算法和經典的DQN 算法在邊緣計算和緩存的聯合優化問題上的橫向對比,證明本文方案在穩定性、收斂速度和性能表現上都有明顯優勢;與傳統緩存放置策略相比,本文方案可以有效地提高緩存命中率、降低系統成本和平均時延,改善用戶體驗。
1 框架設計
NDN 中基于機器學習實現網絡、計算和緩存動態協調的綜合框架如圖1 所示,在邊緣節點部署計算模塊,結合NDN 的網內緩存機制,將網絡功能、內容和資源向終端用戶靠近[14-15];為了優化資源分配,處理具有多樣性和時變性的復雜問題,在邊緣節點部署智能體,通過狀態、行動和獎勵與環境互動。智能體首先實時地感知網絡狀態,例如,與節點直接連接的用戶發布的計算任務和請求的內容、節點當前可用的計算資源和緩存容量、局部內容流行度等,繼而根據當前狀態自主地設計行動,包括計算和緩存的資源分配以及緩存放置策略,最后基于環境反饋的獎勵來更新和改進其行動策略,形成感知?動作?學習的循環結構。
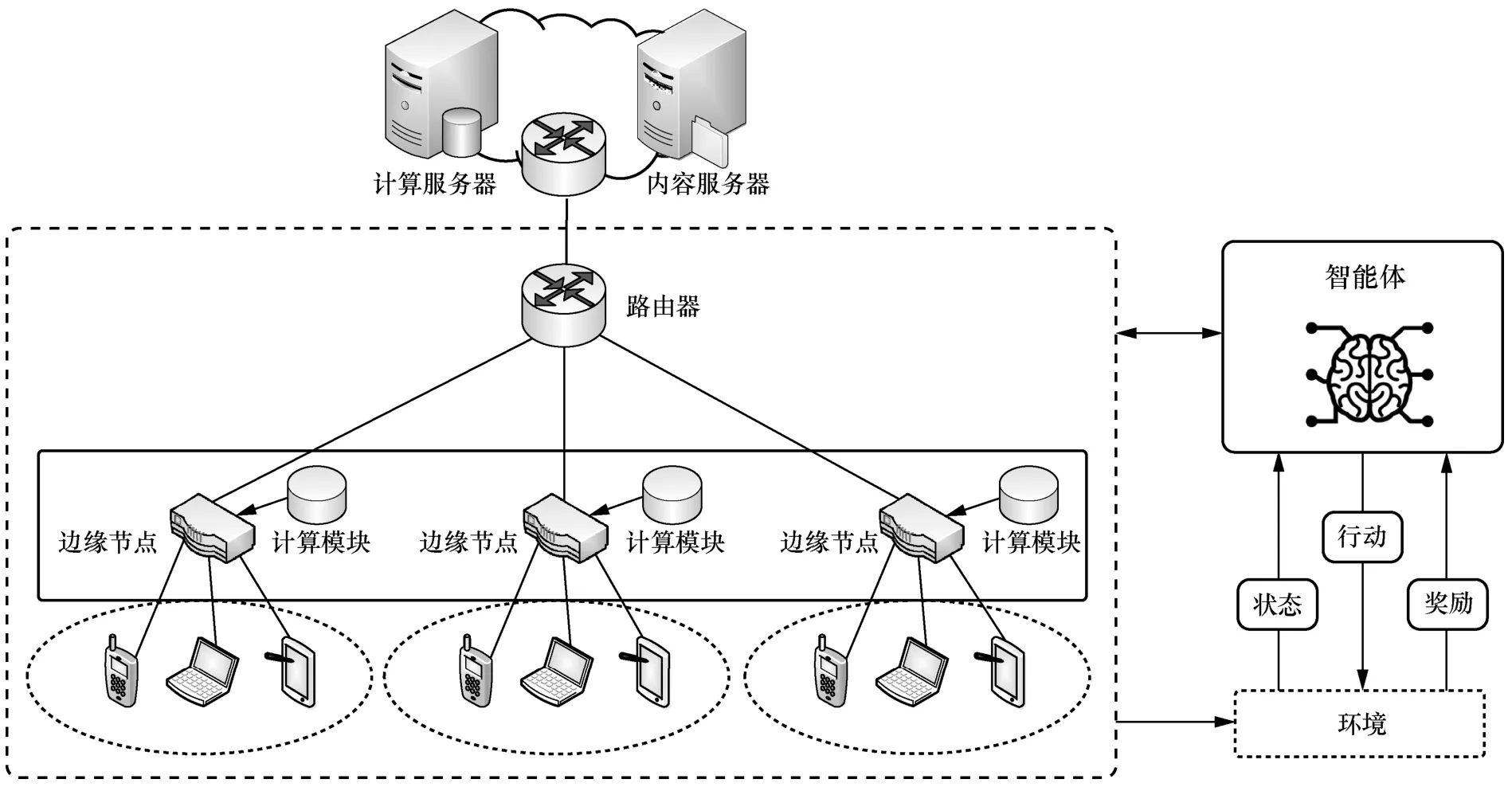
圖1 NDN 中基于機器學習實現網絡、計算和緩存動態協調的綜合框架
在此框架中,邊緣節點為其覆蓋區域內的用戶提供通信、計算和緩存功能,同時考慮到節點計算和緩存能力的變化、不同區域用戶偏好的差異性以及內容流行度的時變性,智能體自適應地調整行動策略,為不同區域的用戶提供個性化的解決方案。相比邊緣節點,遠程服務器具有更豐富的計算和緩存資源。當邊緣節點不足以支持用戶的計算任務或沒有緩存用戶的請求內容時,計算任務或請求內容可以被卸載到遠程服務器(即計算服務器和內容服務器)。因此,智能體在優化計算資源和緩存容量外,還需要學習在邊緣節點緩存更受歡迎的內容和處理時延敏感的計算任務,以降低網絡時延、改善用戶體驗。
2 具體方案
2.1 局部內容流行度預測
互聯網時代信息量的成倍增長導致了信息過載問題,即不僅用戶在海量數據面前束手無策,網絡運營商也很難發現用戶的興趣點為其提供個性化的服務。推薦系統通過研究用戶的歷史行為、興趣偏好或者不同區域的人口統計學特征,產生用戶可能感興趣的內容列表,精準高效地滿足不同用戶的信息需求。將每個節點對所有內容的評分抽象為一個m行(m個與該節點直接連接用戶)、n列(n個內容)的矩陣,然而由于大多數用戶只對網絡中極少部分的內容有過評價記錄,這個矩陣是很稀疏的。基于矩陣分解的協同過濾算法引入了隱向量的概念,將高維矩陣映射成2 個低維矩陣的乘積,加強了處理稀疏矩陣的能力,同時能挖掘更深層的用戶與用戶、用戶與內容間的關系,較高的預測精度使之成為當前熱門的推薦系統主流算法。矩陣分解對原稀疏矩陣進行填充,達到了通過分析已有數據來預測未知數據的目的,從而有助于邊緣節點提前緩存當前冷門但未來很可能會流行的內容,挖掘長尾內容的潛在收益。
如圖2 所示,矩陣分解算法將m×n維的共現矩陣R分解為m×k維的用戶矩陣U和k×n維的內容矩陣I相乘的形式,其中,m為用戶的數量,n為內容的數量,k為隱向量維度。k的大小決定了隱向量表達能力的強弱,k的取值越小,隱向量包含的信息就越少,但泛化能力較高;反之,k取值越大,隱向量的表達能力就越強,但泛化能力相對降低。通常k在實驗中折中取值,以保證推薦效果和空間開銷的平衡。
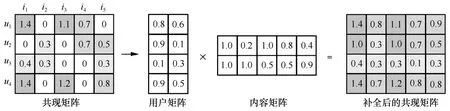
圖2 矩陣分解算法
用戶u對內容i的預估評分為

其中,pu是用戶u在用戶矩陣U中對應的行向量,qi是內容i在內容矩陣I中對應的列向量。
采用梯度下降法優化。定義目標函數為
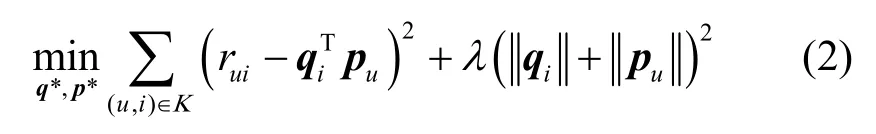
其中,K是共現矩陣中已知評分rui的集合,λ是正則項系數。系統基于已知的評分以最小化均方誤差為目標來學習qi和pu,并通過引入正則化項來避免過擬合。
分別對qi和pu求偏導數,得到梯度下降的方向和幅度分別為
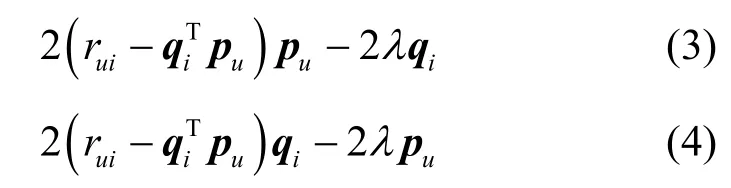
其中,γ是學習率。然后,沿梯度的反方向對qi和pu進行更新,即
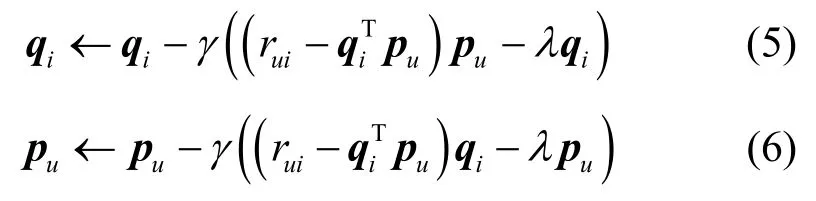
重復式(3)~式(6),直至迭代次數達到設定的上限或者損失函數(目標函數)收斂,由此得到節點對所有內容的評分矩陣。
在補全邊緣節點覆蓋區域內的用戶(與該邊緣節點直接連接的所有用戶)對所有內容的評分矩陣后,將該區域內所有用戶對某個內容的評分之和除以對所有內容的評分之和(即相對評分)作為該區域內該內容的局部流行度。局部流行度即當地用戶對該內容的請求概率,記為P={P1,P2,…,PI},其中,I為網絡內容總數,Pi∈P為內容i的局部流行度,有
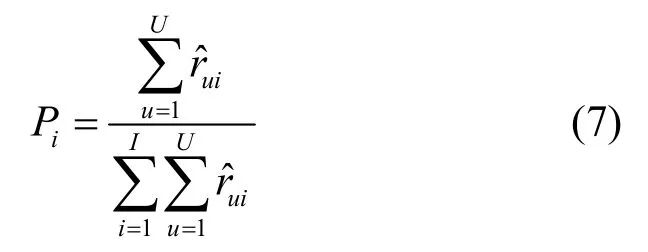
其中,U為與節點直接連接的用戶總數。
2.2 邊緣計算和緩存的聯合優化
設緩存放置策略為C={C1,C2,…,CI},其中,Ci∈C表示內容i是否被選擇緩存。Ci=0時表示未緩存該內容,Ci=1時表示已緩存。緩存命中率η表示為

設δ1為因沒有緩存而經完整回程鏈路傳輸一個內容的成本。假設各內容大小一致,且所有用戶都處于請求內容狀態,根據緩存放置策略C,有η的概率可以直接從節點獲取,所以因緩存放置而無須經回程鏈路傳輸請求內容的收益為ηUδ1。
設δ2為節點內部署單位緩存容量的成本。總緩存部署成本隨緩存容量V的增大而增大,所以部署緩存容量的支出為Vδ2。
設 Δτ為在最后期限τmax前完成計算任務的平均節省時間。設δ3為運營商執行計算任務期間支付的成本。假設與節點直接連接的用戶都處于發布計算任務狀態,由于在節點部署了計算模塊,部分計算任務可由節點處理而無須卸載到遠程計算服務器,因此計算收益為 ΔτUδ3。如果節點在其最后期限前完成任務,則節省的時間為正,相應的計算收益也為正;否則節約的時間和計算收益皆為負,因為對于時延敏感的任務來說,如果沒有在最后期限前完成,可能會導致一定的損失。
設δ4為節點內部署單位計算資源的成本。總計算部署成本隨著計算資源S的增大而增大。所以部署計算資源的支出為Sδ4。
上述部署緩存容量和計算資源的支出Vδ2和Sδ4為經濟成本,而因緩存放置直接從節點獲取內容和因部署計算模塊提前完成計算任務的收益ηUδ1和 ΔτUδ3并不直接反映在經濟盈利上,其不僅包含無須經完整回程鏈路傳輸所節約的能量,也包含用戶愿意為了更低時延而支付的費用以及運營商因為更低的帶寬資源消耗所減少的開銷。從網絡優化的角度看,支出和收益都是可以通過經濟指標來衡量的,因此優化目標為:使利潤(運營收益)ρ=ηUδ1?Vδ2+Δτ Uδ3?Sδ4最大。約束條件如下。
3)計算資源:S≤U。S個用戶發布的計算任務由邊緣節點處理,根據不同用戶不同應用對時延的要求選擇這S個用戶。
綜上,在平均時延的約束下,以系統運營收益最大化為目標,資源分配與緩存放置策略的聯合優化問題可表示為
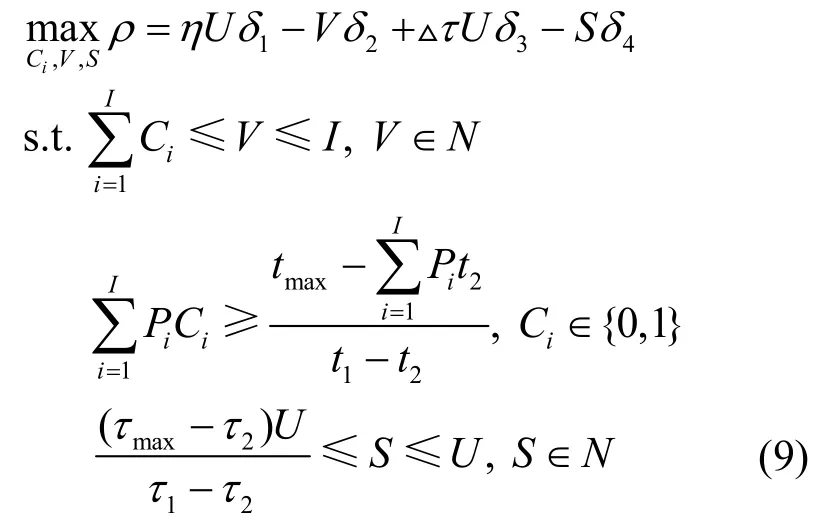
顯然,這是一個混合整數規劃問題,且是NP-Complete 的,本文利用深度強化學習對其進行求解。邊緣節點的計算及緩存能力、用戶發布的計算任務和請求的內容以及局部內容流行度等信息被收集并發送給智能體,在獲得上述信息后,智能體會設計一個動作來執行資源分配和緩存放置策略,由此進入新的環境狀態,并計算系統運營收益作為對該行動的反饋。上述過程對應深度強化學習中的3 個關鍵要素,即狀態、行動和獎勵。
1)狀態。作為深度強化學習算法的輸入,狀態包含了智能體做出動作所需要的全部信息。本文的狀態由3 個部分組成:State=(ui,si,vi),其中,ui是與節點i直接連接的所有用戶的狀態,包括其發布的計算任務、請求的內容、任務的截止期限以及該區域的局部內容流行度;si和vi分別是該節點的可用計算資源和緩存容量。
2)行動。作為深度強化學習算法的輸出,行動是智能體對環境產生影響的方式。本文的行動由3 個部分組成:Action=(Si,Vi,Ci),其中,Si和Vi分別是智能體分配給節點i的計算資源和緩存容量,Ci是該節點采取的緩存放置策略。
3)獎勵。作為智能體學習的指導,從Learning=Representation+Evaluation+Optimization 的角度看,獎勵是Evaluation 的重要組成成分。由于深度強化學習的目標是最大化累積獎勵,故即時獎勵的設置應與上述聯合優化問題的目標(盡可能找到使系統運營收益最高的資源分配和緩存放置策略)相關。本文將當前的系統運營收益ρ與現有的最高系統運營收益ρmax的差值作為即時獎勵 Reward=ρ?ρmax。當累積獎勵收斂時,表明最佳資源分配和緩存放置策略訓練完成。
本文基于DDPG 算法對計算和緩存的資源分配以及緩存放置策略進行聯合優化,算法流程如圖3 所示。DDPG 智能體由3 個部分構成:主網絡、目標網絡和經驗回放池。
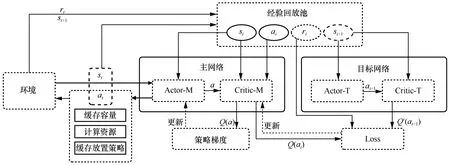
圖3 DDPG 算法流程
主網絡由2 個深度神經網絡組成,即一個行動網絡Actor-M 和一個評價網絡Critic-M。行動網絡用于動作的探索,根據隨機動作策略盡可能完整地探索動作空間,即通過引入隨機噪聲,將動作的決策由確定性過程轉變為隨機過程,再從該隨機過程中采樣得到要采取的行動。評價網絡通過Q值評估行動網絡選擇的動作,并通過計算策略梯度來更新行動網絡。
目標網絡包括一個目標行動網絡Actor-T 和一個目標評價網絡Critic-T。目標網絡的輸入是經驗元組(si,ai,ri,si+1)的下一個狀態si+1,輸出是用于更新Critic-M 的目標Q值。
經驗回放池用于儲存經驗元組,經驗元組為智能體在與環境交互過程中所得到的狀態轉移序列(si,ai,ri,si+1),包括當前狀態、所選動作、獎勵和下一個狀態。在主網絡和目標網絡的更新階段,會從經驗回放池中隨機采樣,以減小數據相關性的影響。
基于DDPG 算法的詳細工作過程如下。
1)將當前環境狀態st輸入主網絡的Actor-M,智能體根據隨機動作策略采取行動at,即計算資源和緩存容量的分配以及緩存放置策略。
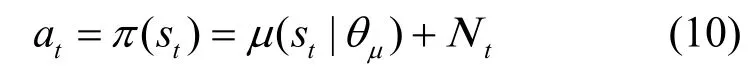
其中,μ是由Actor-M 的卷積神經網絡(CNN,convolutional neural network)模擬的確定性動作策略,θμ是Actor-M 的動作策略參數,Νt是動作探索噪聲。
2)環境進入下一個狀態st+1,并向智能體反饋即時獎勵rt。
3)將(st,at,rt,st+1)存入經驗回放池。
4)從經驗回放池中隨機采樣小批量的含有N個經驗元組(si,ai,ri,si+1)。
5)將si和ai輸入主網絡的Critic-M,Critic-M利用CNN 模擬貝爾曼方程計算在狀態si下選擇動作ai的Q值為
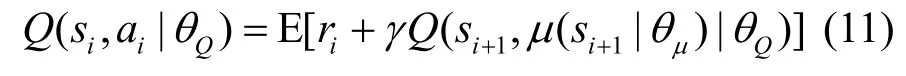
其中,θQ是Critic-M 的Q值參數。
6)將si+1輸入目標網絡的Actor-T,Actor-T 通過確定性動作策略μ′得到動作ai+1=μ′(si+1|θμ′),其中,θμ′是Actor-T 的動作策略參數。再將si+1和ai+1輸入Critic-T,得到在狀態si+1下、選擇動作ai+1的目標Q值Q′(si+1,μ′(si+1|θμ′)|θQ′),其中,θQ′是Critic-T 的Q值參數。由ri和Q′(si+1,μ′(si+1|θμ′)|θQ′)得到在狀態si下選擇動作ai的目標Q值為
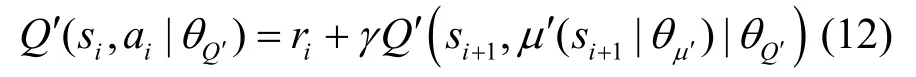
7)將Q′(si,a i|θQ′)傳入Critic-M,通過最小化損失函數Loss 來更新Critic-M 的Q值參數θQ,即
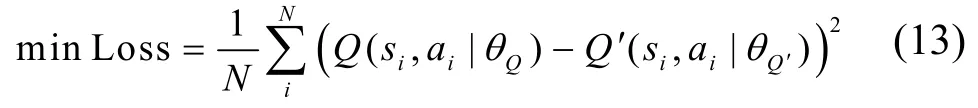
8)將si輸入主網絡的Actor-M,Actor-M 通過確定性動作策略μ選擇動作a=μ(si|θμ)。再將si和a輸入Critic-M,通過策略梯度來更新Actor-M的動作策略參數θμ,即
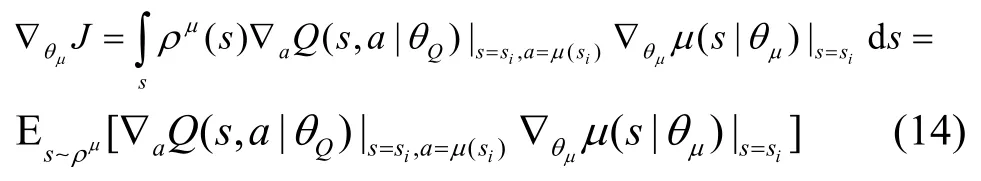
其中,ρμ(s)是在確定性動作策略μ下狀態s服從的分布函數;是狀態s服從ρμ(s)分布時,智能體根據策略μ選擇動作能夠產生的Q值的期望,用以衡量策略μ的表現。
基于蒙特卡羅方法,將小批量N的經驗元組數據代入式(14),可以作為對策略梯度的無偏估計。

9)通過軟更新算法對目標網絡中Critic-T 的Q值參數θQ'和Actor-T 的動作策略參數θμ'進行更新。
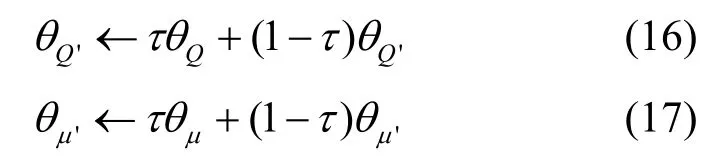
其中,τ=0.001。
如果當前的資源分配和緩存放置策略滿足聯合優化問題的所有約束條件,并且當前的系統運營收益大于現有的最高系統運營收益,則每幕(episode)的最高系統運營收益更新為當前的系統運營收益,且節點基于當前的資源分配和緩存放置策略更新其狀態。如果當前的資源分配和緩存放置策略滿足聯合優化問題的所有約束條件,但當前的系統運營收益小于或等于現有的最高系統運營收益,則表明智能體沒有產生更好的優化方案,每幕的最高運營收益保持不變,且節點仍根據現有的最佳資源分配和緩存放置策略進行狀態更新。如果當前的資源分配和緩存放置策略不能滿足聯合優化問題的任一約束條件,智能體將受到懲罰。
基于DDPG 算法聯合優化資源分配和緩存放置策略的偽代碼如算法1 所示。


3 仿真分析
3.1 實驗環境和參數設置
本文的仿真使用ndnSIM2.8 模擬器。仿真場景如圖4 所示,3 個邊緣路由器(即邊緣節點)覆蓋了3 個不同區域內的用戶。在豆瓣電影數據集中收集了3 個省份共500 名用戶對1 000 部電影的評分(包含未評分,即一些用戶只對其中某些電影打過分)來預測局部內容流行度。對應的遠程內容服務器提供1 000 種不同的內容,每種內容的大小相同。為了體現內容流行度的地域差異性,各邊緣路由器覆蓋區域內的用戶均來自同一省份,每個用戶群共50 人,用戶請求興趣包的頻率為100 個/秒,興趣包的請求概率分布與局部內容流行度一致。緩存替換策略均采用最近最少使用(LRU,least recently used)策略,仿真時長為100 s,從用戶到遠程服務器的路徑時延為60 ms。性能評價指標采用各邊緣節點的運營收益、緩存命中率、用戶獲取數據包的平均時延、平均跳數和遠程服務器負載。
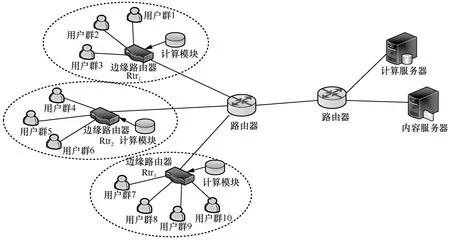
圖4 仿真場景
3.2 結果分析
矩陣分解算法中的可調節參數為學習率γ、正則項系數λ和隱向量維度k。學習率決定每次更新的幅度。對于固定的學習率,如果設置偏大,則會導致結果振蕩不收斂;反之,則會導致收斂速度過慢。本文采用指數衰減學習率。
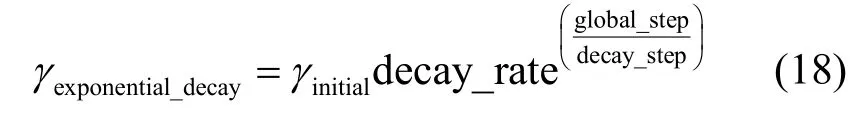
其中,γinitial=0.002為初始學習率,decay_rate=0.9為衰減系數,decay_step=50 用來控制衰減速度。在訓練前期,采用較大的學習率可以快速獲得一個較優的解,隨著迭代的繼續,學習率逐漸減小,使模型在訓練后期更加穩定。
圖5 對比了不同的正則項系數λ和隱向量維度k組合對矩陣分解損失函數的影響,得出當λ=0.005、k=100時損失函數最小,故在后續仿真中均采用此組合。
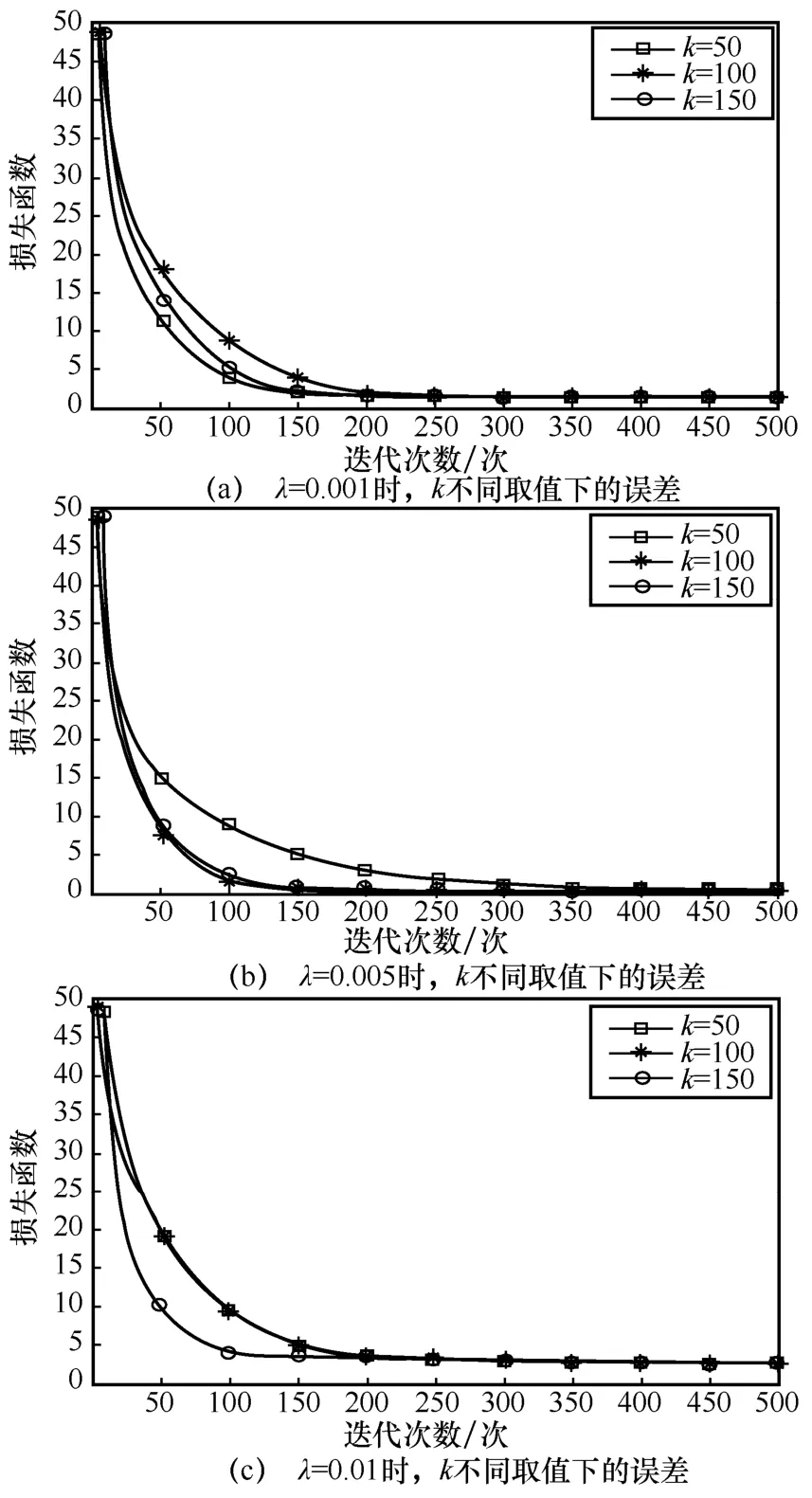
圖5 不同參數組合的矩陣分解誤差對比
在確定了矩陣分解的參數組合之后,按照2.1 節的算法來預測內容流行度。圖6 以全局流行度排名前100 位的內容為參照,展示了全局和局部內容流行度的差異性。其中,數據集內全部500 名用戶的評分反映全局內容流行度,而局部內容流行度則由在同一省份隨機抽取的50 名用戶計算而得。
如圖6 所示,全局內容流行度大致符合Zipf 分布,即網絡中的少數內容占據了用戶的大部分關注度,但在尾部也有持續穩定的小眾需求。局部內容流行度則更顯著地表現了冷門內容的潛力,出現了很多突出的尾部內容。全局和局部內容流行度的差異性表明本文基于局部內容流行度制定緩存放置策略更加有效,為不同區域用戶提供個性化網絡服務的同時,還能獲得更高的系統運營收益。
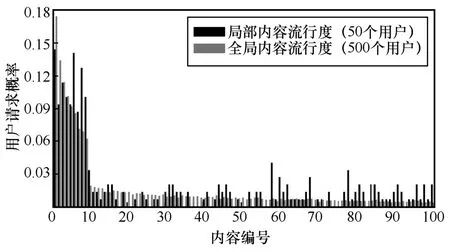
圖6 全局和局部內容流行度對比
在對局部內容流行度完成預測后,邊緣節點Rtr1、Rtr2和Rtr3以系統運營收益最大化為目標,基于DDPG 算法對計算和緩存的資源分配以及緩存放置策略進行聯合優化。圖7 顯示了各邊緣節點每幕運營收益最高時的資源分配情況及最高運營收益。當節點緩存容量V=108,計算資源S=127時,運營收益達到峰值。
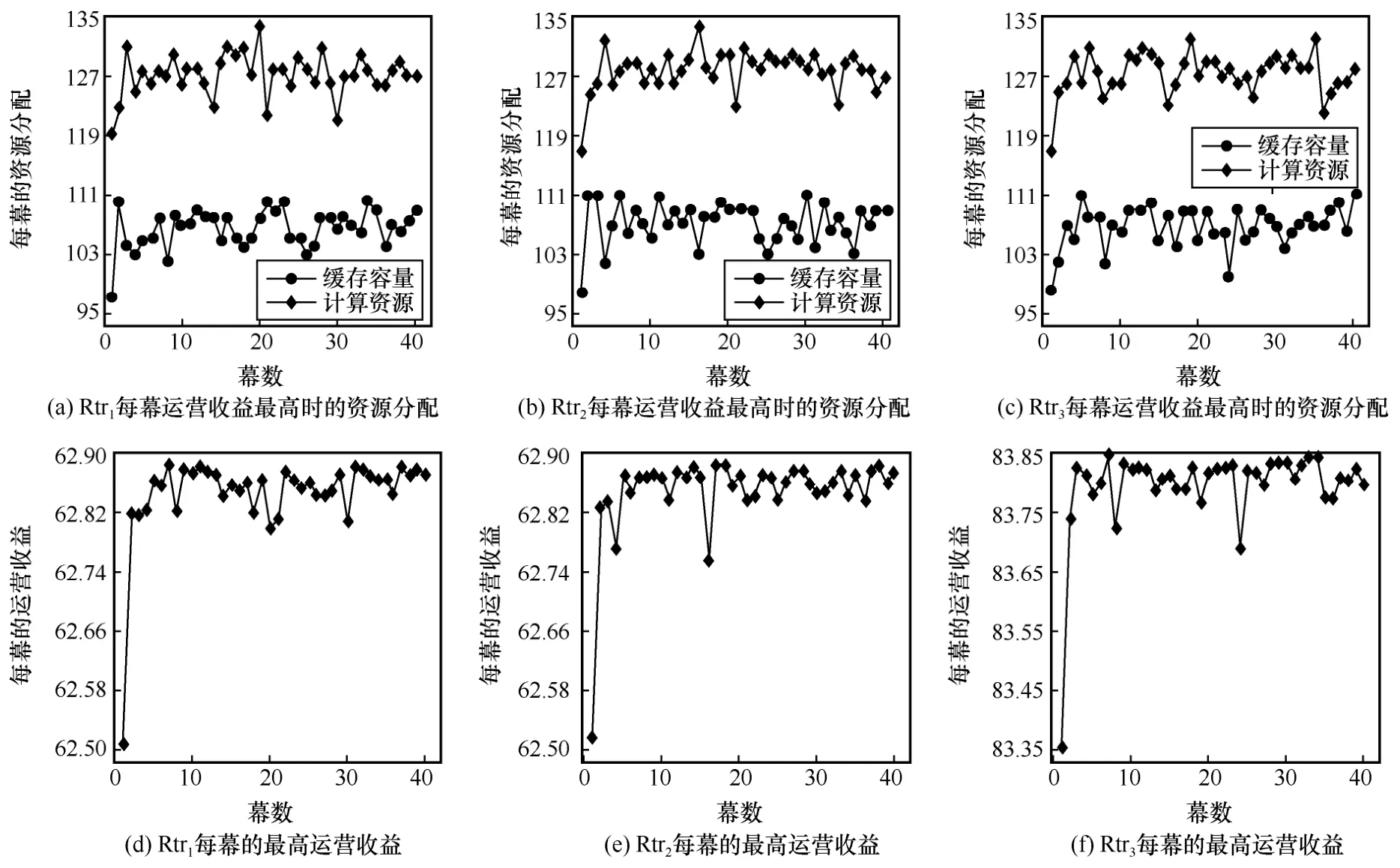
圖7 基于DDPG 算法優化的各邊緣節點的資源分配和運營收益
δ1(經完整回程鏈路傳輸一個內容的成本)、δ2(節點內部署單位緩存容量的成本)、δ3(運營商執行計算任務期間支付的成本)和δ4(節點內部署單位計算資源的成本)的值皆根據實際邊緣計算和緩存設備廠商提供的相關價格資料設置,表1 對比了δ1、δ2、δ3和δ4不同組合下運營收益最高時的資源分配情況。本文方案在不同組合下能夠自適應地調節計算和緩存資源的分配,達到相對穩定的平均收益。

表1 δ1、δ2、δ3和δ4不同組合下的資源分配和運營收益
本文將DDPG 算法和經典的DQN 算法進行了橫向對比,如圖8 所示,DDPG 算法在平均緩存命中率和平均運營收益兩方面的表現都明顯優于DQN 算法,主要原因為DDPG 采用軟更新算法更新目標網絡的參數,這種加權移動平均法保證了目標網絡訓練的穩定性;與DQN 在每步都計算所有可能動作的Q值來進行決策不同,DDPG 采用確定性策略,直接由神經網絡Actor預測出該狀態下需要采取的動作,降低了算法復雜度、加快了收斂速度。
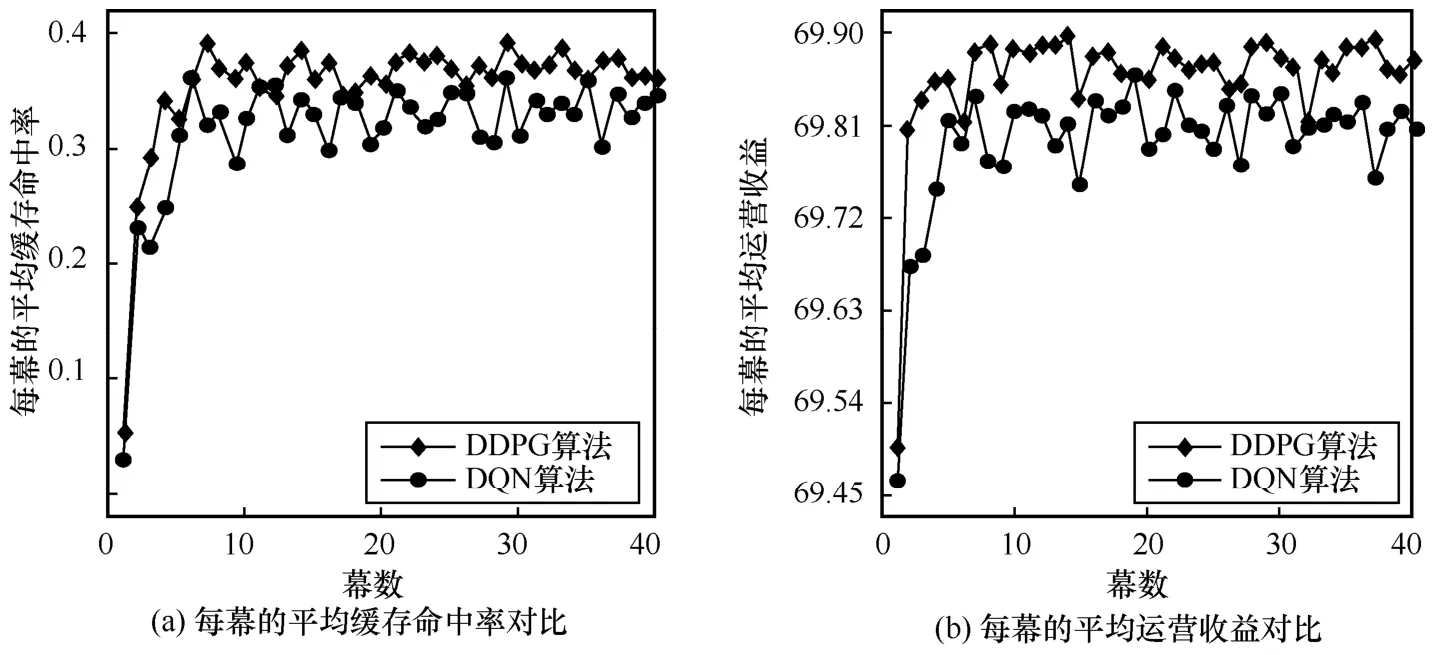
圖8 基于DDPG 算法和基于DQN 算法優化的性能對比
LCE(leave copy everywhere)策略和LCD(leave copy down)策略[16]是NDN 緩存放置的基準策略。LCE 策略是NDN 中默認采用的緩存放置策略,其在數據包返回路徑上的每個節點都會緩存該內容的副本,這極易導致網內緩存的冗余度較高且在緩存容量較小時緩存替換頻繁。LCD策略相對LCE 策略更加保守,只在命中節點的下一跳進行緩存,避免了相同內容在網絡中大量復制,在一定程度上降低了緩存冗余度;此外,LCD策略需要對同一內容進行多次請求才能將其緩存到網絡邊緣,間接地考慮了內容流行度,使緩存利用率有所提升。
圖9 對比了在節點緩存容量為108(運營收益最高時的緩存容量)和108×2 時,本文LCD 策略和LCE 策略的相關性能。在緩存命中率、平均時延、平均跳數(數據包從遠程服務器或緩存節點返回所經過的網絡跳數)和遠程服務器負載方面,本文方案都優于LCD 策略和LCE 策略,尤其在緩存容量相對較小時,其優勢更加明顯:在節點緩存容量為108 時,相對LCD 策略,本文方案的緩存命中率提高了70.97%,平均時延、平均跳數和遠程服務器負載分別降低了 25.97%、21.11%和9.91%。
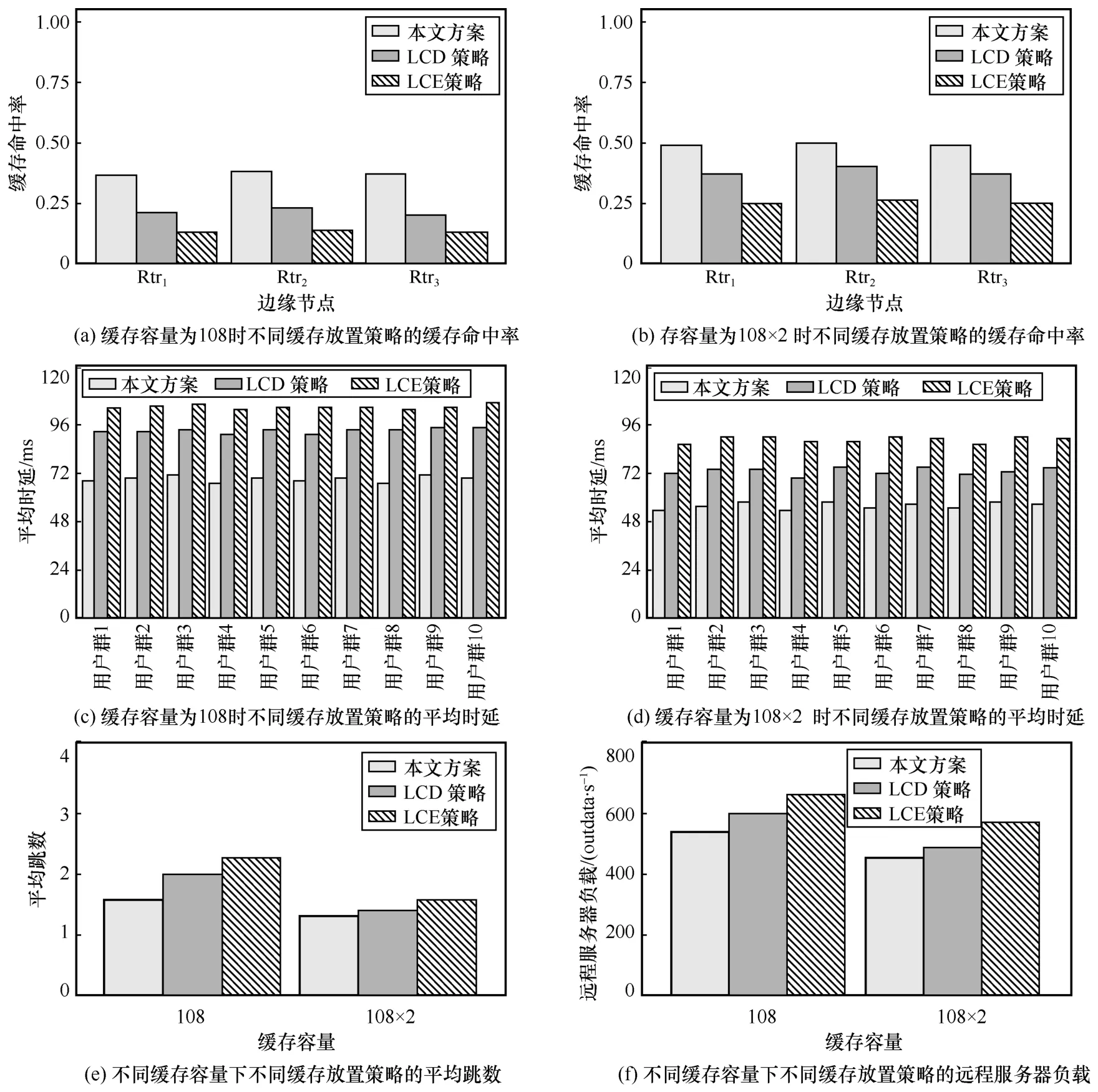
圖9 不同緩存容量下不同緩存放置策略的性能對比
4 未來方向
前文討論了基于機器學習在NDN 網絡邊緣聯合優化計算和緩存的潛力,通過仿真證明了其對運營收益和系統性能的提升。在此基礎上,本文提出以下未來的研究方向。
1)通過各邊緣節點間的相互合作進行實時的情境感知[17-21],包括信道條件、用戶的移動性、計算任務和內容請求的規模與優先級等,以優化移動性管理和主動資源分配。例如,實現對計算任務的自適應分流,緩解單一邊緣節點計算壓力的同時,充分利用當前相鄰區域的閑置資源,提供更低時延的計算服務;挖掘不同區域內容流行度之間的相關關系,預判和緩存呈現由局部到全局流行態勢的內容,縮短用戶獲取內容的時延。
2)利用聯邦學習這一面向隱私保護的分布式機器學習框架[22]。聯邦學習在不共享原始數據的基礎上,聚合各邊緣節點的本地訓練的中間結果,構建具有較高泛化能力的共享模型,以推進全局范圍內的性能優化,既保證了各參與方之間的數據隔離,又實現了數據價值的安全流通。
3)利用機器學習優化種類龐雜的計算和緩存服務時,往往需要一定的時間才能使模型收斂,如何提高邊緣節點機器學習的效率亦是一個亟待解決的問題。可以基于軟件定義網絡(SDN,software defined network)和網絡功能虛擬化(NFV,network function virtualization)實現網絡切片[23],結合機器學習為不同類型的服務提供差異化的支持,實現高效靈活的邊緣計算和緩存,并采用靈活以太網(FlexE,flexible Ethernet)技術使業務流以最短、最快的路徑抵達用戶[24]。
5 結束語
本文提出了一個NDN 與邊緣計算相結合的綜合框架并基于深度強化學習對資源分配與緩存放置策略進行聯合優化,以實現網絡、計算和緩存的動態協調。首先,在NDN 邊緣節點部署計算模塊,結合NDN 的網內緩存機制,將網絡功能、內容和資源向終端用戶靠近;然后,利用矩陣分解算法強大的處理稀疏矩陣的能力,補全各區域用戶對內容的評分矩陣,將區域內所有用戶對某個內容的相對評分作為該區域內該內容的局部流行度;最后,在平均時延的約束下,以系統運營收益最大化為目標,利用DDPG 算法對計算和緩存資源分配以及緩存放置策略進行聯合優化。仿真結果顯示,本文方案在穩定性、收斂速度和性能表現上都優于經典的DQN 算法;與傳統的緩存放置策略相比,本文方案可以更有效地提高緩存命中率、降低用戶獲取內容的平均時延,綜合提升運營收益和用戶體驗質量。
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
商用汽車(2016年11期)2016-12-19 01:20:16
臺聲(2016年2期)2016-09-16 01:06:53
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
