結合顯式句法依賴與分層注意力進行方面級情感分析
2022-09-06 01:30:16范明煒張云華
軟件工程 2022年9期
范明煒,張云華
(浙江理工大學信息學院,浙江 杭州 310018)
719068852@qq.com;605498519@qq.com
1 引言(Introduction)
方面級這種細粒度的情感分析解決了針對一段評論的不同方面,情感的判斷可能出現兩種相反結果的問題,因此目前方面級情感分析逐漸成為研究的熱點,對商品評論、推薦系統等領域具有重要意義。
現有的深度學習模型在情感分析方面取得了較好的效果。基于語義的方法將輸入的句子看作單詞序列,通過注意力建模,例如RNN、Transformer等;基于語法的方法通過引入句法依賴關系樹構造輸入句子的語法結構,采用GNN通過依賴關系樹上下文詞的表示來豐富方面表示;但它們均未充分利用上下文詞與方面詞之間的語法依賴。XIONG等采用字符級別詞嵌入實現文本分類。YANG等做出改進,提出了基于TD-LSTM的方法。但邵興林通過實體信息與屬性信息的比較,發現實體信息更加重要,同時評論可能會有多個句子,選出情感更加強烈的句子也具有重要意義。
受此啟發,本文提出結合分層注意力機制與顯式句法依賴的多層網絡,結合依賴路徑編碼和實體信息的嵌入表示一并發送到注意力層。構建單詞-句子、句子-文檔的層次結構,通過加入多級注意力機制,使模型對不同單詞、句子賦予不同的注意力權重,對最后的結果做出更準確的判斷。
2 相關工作(Related work)
2.1 Stanford Parser
Stanford Parser是基于概率統計的開源句法分析器。基于Penn Treebank作為分析器的訓練數據,面向中文、英文等語種提供句法分析功能,可以輸出句法分析樹,如圖1所示。
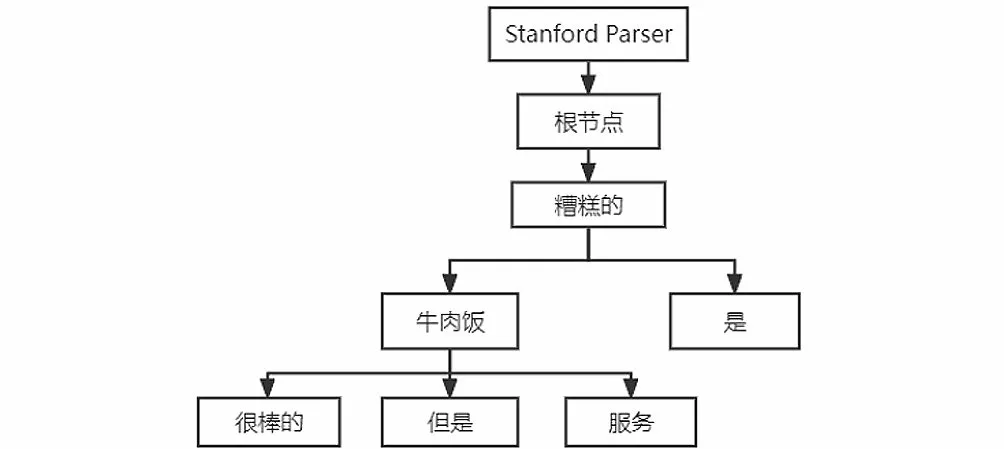
圖1 句法分析樹Fig.1 Syntactic parse tree
2.2 層次注意力
注意力機制就是關注輸入權重分配,可以理解成一個由查詢矩陣和對應的鍵,以及需加權平均的值構成的一層感知機。
層次注意力用于解決多層次問題。如在分析評論時,把詞作為一層,把句子作為一層,這樣就有了多層,下一層對上一層產生影響,因此建立了一種堆疊的層次注意力模型,如圖2所示。
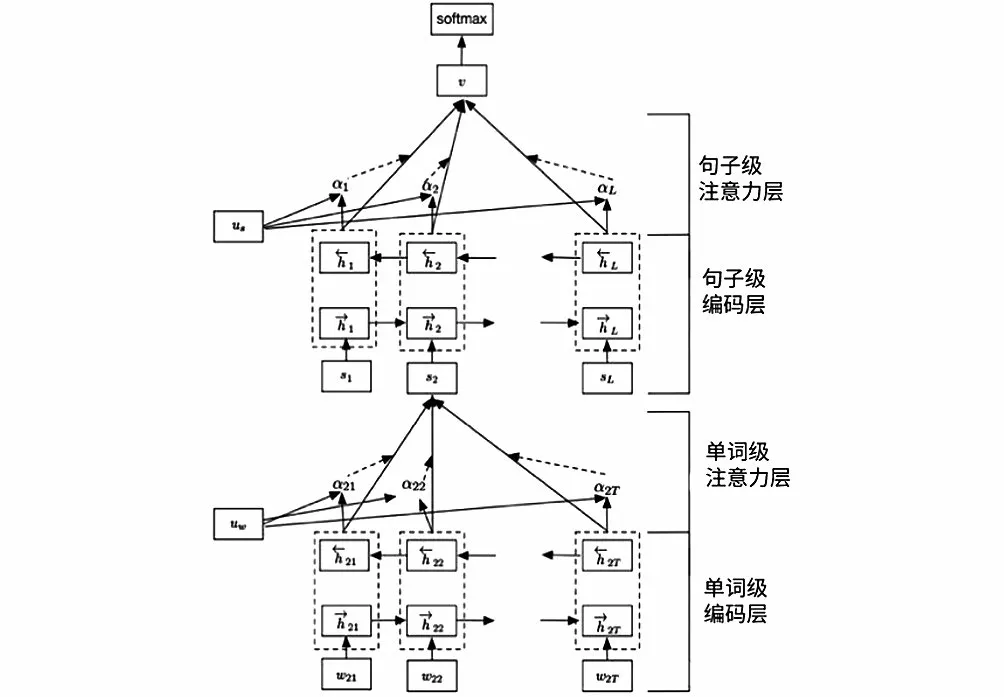
圖2 層次注意力模型Fig.2 Hierarchical attention model
2.3 LSTM
LSTM是一種特殊的RNN,主要是為了解決長序列訓練過程的梯度消失和爆炸問題,長序列使用LSTM有更好的表現。傳輸過程中,通過門控狀態來控制需要長時間記憶的和忘記不重要的信息,其內部可劃分為忘記階段、選擇記憶階段以及輸出階段,如圖3所示。
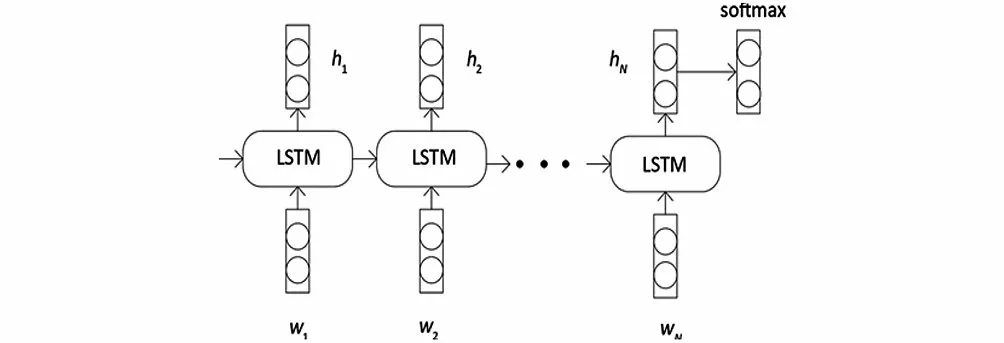
圖3 LSTMFig.3 LSTM
3 模型構建(Model building)
給定長度為的句子={1,2,3,…,},以及長度為(0<<)的方面項={[+1],…,[+]},其中∈,可以是詞或者短語。目標是對方面項進行情感分析,最終分為積極、消極、中性。
圖4展示了模型的整體設計。在詞級別,通過句法分析獲取句法依賴樹,從而得到每個單詞到方面項的路徑編碼和距離。同時獲取句子中單詞的詞性及方面項的實體信息,結合上述路徑編碼和距離一起饋送到各自的編碼層,通過注意力網絡得到句子表示。在句子級別,評論中的其他句子表示獲取同上,通過LSTM及注意力給予重要的句子更大的權重。這樣,單詞和句子都有了自己的注意力權重。
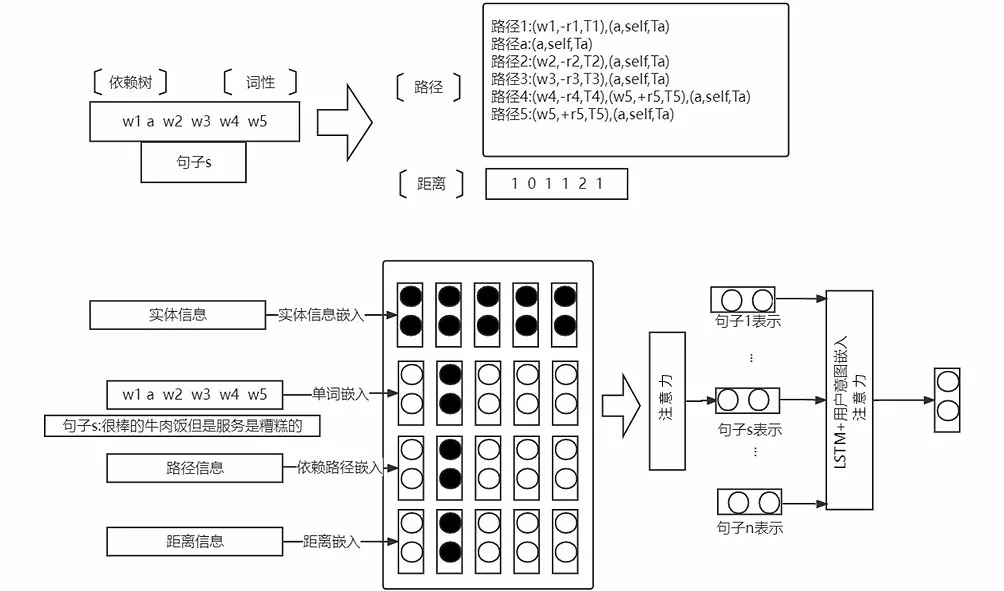
圖4 模型整體設計Fig.4 Overall design of the model
3.1 輸入層
通過Stanford Parser獲取句子結構樹與每個單詞的詞性。詞性對于情感分析任務是非常重要的,通常形容詞和動詞比名詞表達的程度更深。句法結構樹包含詞對的關系,在句法依賴路徑編碼中需要用到。
句法依賴樹中每個詞到方面詞的有向關系路徑稱為句法依賴路徑,路徑上邊的個數稱為距離。例如圖1中的依賴樹,針對“牛肉飯”這一方面詞,句中單詞到它的距離為{1,0,1,1,2,1}。針對“很棒的”到“服務”這一方面詞的路徑,“很棒的—(-amod)→牛肉飯—(+conj)→服務”可以被轉換為“[(很棒的,-amod,JJ),(牛肉飯,+conj,NN),(服務,self,NN)]”。“+”和“-”表示有向路徑的正反,即關系的方向,并且在最后為方面詞附加一個預定義的關系“self”。簡單地將依賴路徑進行分解容易丟失路徑的全局特征,因此使用LSTM對依賴路徑序列進行編碼,如圖5所示。
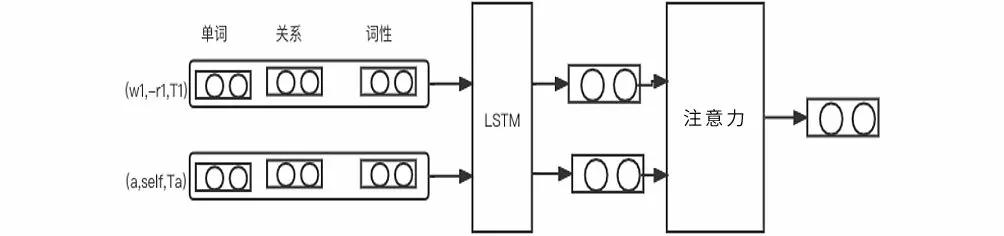
圖5 依賴路徑編碼Fig.5 Dependent path encoding
實體信息對方面級情感分析具有重要作用,如“牛肉飯”這一方面詞的實體信息為“食物”,將“食物”通過詞向量矩陣獲取詞向量,同時結合依賴路徑編碼與距離編碼,將上述組成的向量送入注意力層,獲得句子向量表示。
3.2 分層注意力
一段評論可能包含多個句子,給句子加入注意力可以使模型提取更適合的句子進行情感極性分析。本文加入新一層句子級別的注意力機制,依照句子向量表示的方法,對每一句話都獲取向量表示,將這些句子向量表示作為LSTM新的輸入,再將LSTM的輸出與實體信息結合,通過注意力機制提取對評論情感極性更加重要的句子,以獲取最終評論的向量表示。
3.3 模型訓練
利用交叉熵損失函數和L2正則化對模型進行訓練,公式如下:
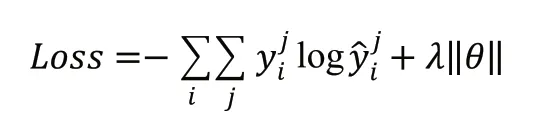
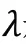
4 實驗結果分析(Experimental results and analysis)
4.1 數據集
為了驗證模型的有效性,本文使用了SemEval 2014 Task 4中的restaurants數據集,包含三種情感和五個方面,如表1所示。
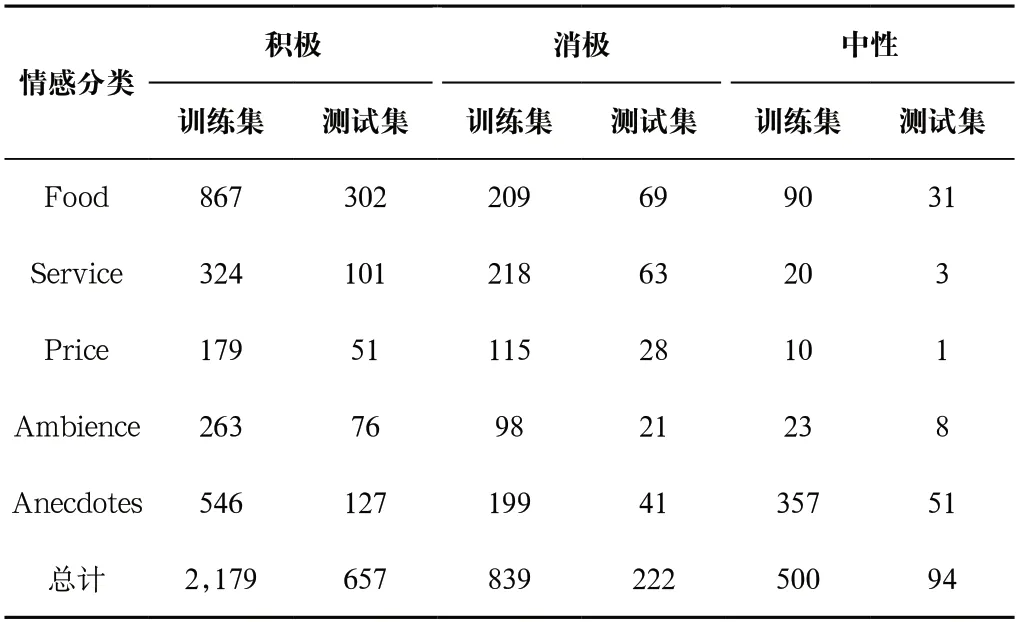
表1 數據集分類統計表Tab.1 Statistical table of the dataset classification
4.2 注意力機制有效性
對于例句“很棒的牛肉飯,但是服務是糟糕的”,當給定實體為“食物”時,“牛肉飯”和“很棒的”被賦予了更高的權重,在句子情感分析中二者起到重要作用。對于該評論“很棒的牛肉飯”和“但是服務是糟糕的”這兩個句子,第一句在情感分析中起到重要的作用,而這句話是實體“食物”對應的句子,結果符合預期,如圖6所示。
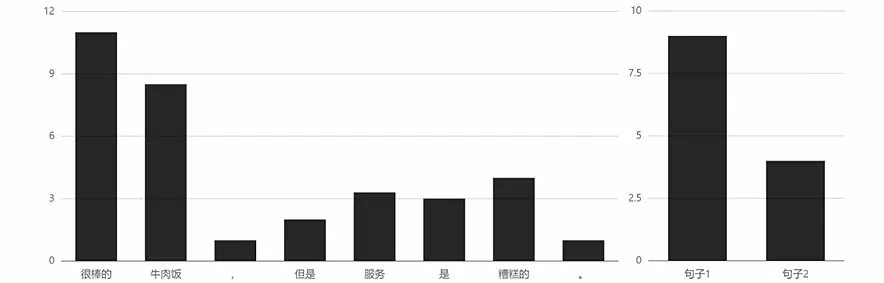
圖6 針對“食物”的注意力權重分布Fig.6 Attention weight distribution for "food"
同理,將實體換為“服務”時,單詞和句子的注意力權重數據也同樣符合預期,如圖7所示。
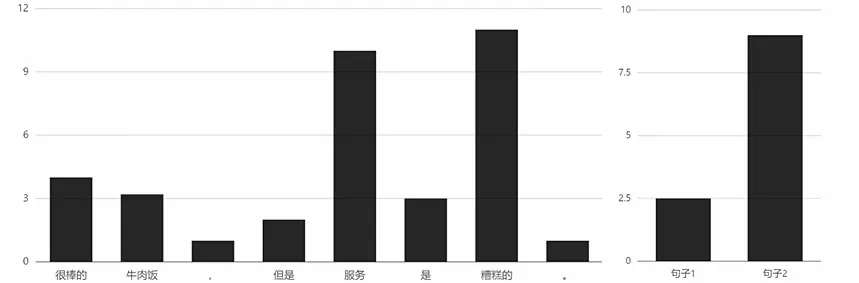
圖7 針對“服務”的注意力權重分布Fig.7 Attention weight distribution for "service"
4.3 模型對比
通過在相同數據集中與其他模型進行對比,驗證本文模型的有效性,主要采用F1值和Acc值(準確率)進行評估。對比的模型主要有BiLSTM-AMM、BiGRU-AAM、Bi-LSTM、ATAE-LSTM等。
如表2所示,從實驗結果來看,本文的方法在數據集上相比于基本的深度學習模型,Acc值和F1值都有所提高,主要是因為模型通過引入實體信息,充分利用顯式語法結構獲取到更加有用的信息;其次,分層注意力機制的引入也使得結果變得更加精確。
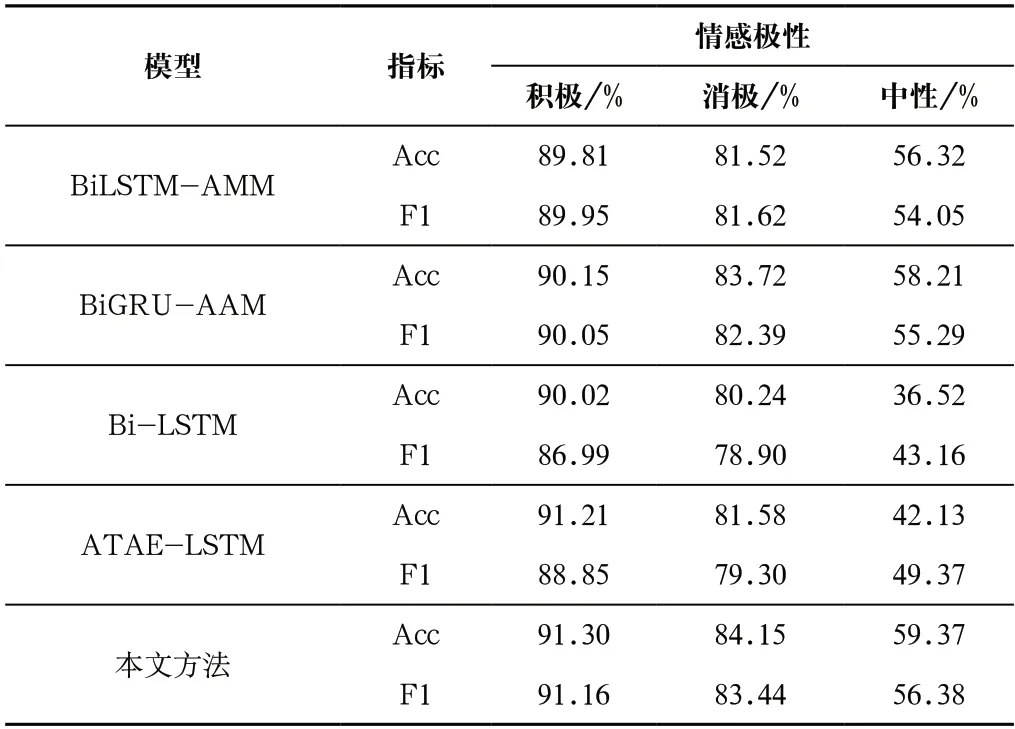
表2 不同模型在數據集中的結果Tab.2 Results of different models on the dataset
5 結論(Conclusion)
針對方面級情感分析中未對句法結構信息與屬性信息進行深度挖掘的問題,本文提出的模型一方面利用句法結構、實體信息加強特征獲取的能力,另一方面利用分層注意力機制使模型能夠賦予重要單詞和句子更大的權重。從實驗結果來看,該模型能有效提高情感分類的效果。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
海外英語(2006年8期)2006-09-28 08:49:00
