基于Neo4j的人員關系知識圖譜構建及應用
2022-09-06 01:30:16陸楓
軟件工程 2022年9期
陸 楓
(河南警察學院,河南 鄭州 450046)
279840745@qq.com
1 引言(Introduction)
“知識圖譜”這一概念在2012 年被Google正式提出。2013 年之后,隨著智能信息服務和應用的不斷發展,知識圖譜、大數據和深度學習一起,成為推動互聯網和人工智能發展的核心驅動力。知識圖譜用圖形顯示知識發展進程與結構關系,以可視化技術來描述知識資源,構建、分析、挖掘和顯示知識資源及它們之間的相互聯系。從目前大數據的數據分析結果來看,追蹤人員活動軌跡、構建關系知識圖譜和定位傳播路徑等是人們關注的重點內容。
本文提出一種基于病例人員關系圖數據庫的知識圖譜,該知識圖譜以圖的形式展示了病例人員的信息和接觸關系,系統采用Neo4j圖數據庫存儲,對碎片化的病例關系數據進行知識建模與關聯聚合,實現知識層面的數據融合與集成,構建可視化的病例人員關系知識圖譜,形成病例人員關系圖,同時專業人員也可以分析其接觸關系及病例人員的感染力。
2 知識圖譜和Neo4j(Knowledge graph and Neo4j)
2.1 知識圖譜和Neo4j的定義
知識圖譜又稱為科學知識圖譜,是一種叫作語義網絡(semantic network)的知識庫。知識圖譜用于以符號形式描述物理世界中的概念及其相互關系,它的基本組成單位是“實體、關系、實體”三元組,實體間通過關系相互聯結,構成網狀的知識結構。
Neo4j是一種NoSQL的圖數據庫,也是目前應用較多的圖數據庫,它基于Java的高性能、高可靠性、可擴展性強的開源圖數據庫。Neo4j的創始人們選擇用圖模型來存儲關系,并在此系統中實現了變長的遍歷運算。Neo4j的數據存儲形式主要是用節點(Node)和邊(Edge)來組織數據。節點代表知識圖譜中的實體,邊代表實體間的關系,關系可以有方向,兩端對應開始節點和結束節點。
2.2 知識圖譜的構建
目前,知識圖譜的構建方式主要有自頂向下和自底向上兩種方式。自頂向下構建方式需要先定義好本體(Ontology,或稱為Schema),再基于輸入數據完成知識抽取到圖譜構建的過程。該方式更適用于專業知識方面圖譜的構建,比如企業知識圖譜,面向專業領域用戶使用。自底向上構建方式則是借助一些技術手段,從公開收集的數據信息中抽取置信度較高的信息,加入知識庫中。該方式適用于常識性知識圖譜的構建。
本文構建的病例關系知識圖譜采用自頂向下的構建方式。下面側重介紹自頂向下構建方式的相關流程和技術,其知識圖譜的關鍵技術架構如圖1所示。
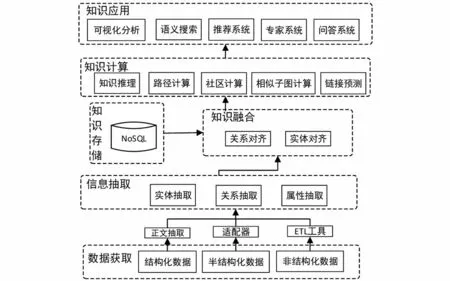
圖1 知識圖譜的關鍵技術架構圖Fig.1 Key technology architecture diagram of knowledge graph
3 基于Neo4j的病例關系知識圖譜構建(Construction of case relationship knowledge graph based on Neo4j)
病例關系知識圖譜的構建主要包括數據獲取、信息抽取、知識存儲、知識融合和知識應用等部分。首先,獲取某地病例人員的數據信息;其次,進行信息抽取,完成對獲取數據的識別并抽取相關實體、關系和屬性;第三,采用Neo4j圖數據庫實現知識存儲;然后,將獲取來源不同的等價或相關實體進行整合和知識融合,以消除矛盾和歧義,比如某些實體可能有多種表達,某個特定稱謂也許對應多個不同的實體等;最后,知識應用主要采用Neo4j的中心度算法和度中心性算法對病例人員進行關系分析。
3.1 數據獲取
數據獲取主要完成對知識圖譜所在領域的數據源信息收集,這些數據主要包括結構化數據、半結構化數據與非結構化數據。本文的數據主要來自某地病例人員的信息,信息的數據內容包括確診病例的姓名、性別、職業、居住地址、所在區域、工作地址、確診日期及接觸關系,這些數據多為文本內容和半結構化信息。因此,本文采用分詞方式將關鍵信息提取出來形成結構化數據庫,為后續抽取實體和關系形成圖數據庫做準備。
3.2 信息抽取
信息抽取也叫知識抽取,是一種通過自動化的方式從半結構化或非結構化數據中抽取實體、關系、屬性信息的技術。在早期,知識抽取主要通過啟發式算法與規則相結合的方式來實現,現在常用的方法有借助本體與詞匯集、借助多層神經網絡和自然語言處理等。
病例關系的知識抽取是從病例中抽取所需要的內容,包含實體、關系和屬性。首先,對病例實體的數據屬性和關系屬性進行梳理和抽取。病例實體主要包括“確診病例”“無癥狀感染”“外地確診病例”三種;實體的屬性有姓名、性別、職業、居住地址、所在區域、工作地址和確診日期等;實體關系的屬性主要有“密接”“同空間”“親戚”“同住”“同事”等幾種關系。其次,依據確定的病例本體核心類,利用Protégé工具對病例本體類與關系屬性進行創建,設置“are responsible for”“SubClass of”“cooperate”等五種關系。第三,結合所構建的病例關系知識模型,抽取病例中的病例姓名、居住地點、工作地點、感染時間等關鍵實例數據并導入,形成病例關系應用本體,其構建本體的部分截圖如圖2所示。最后,導出為RDF數據,為病例關系知識圖譜的構建奠定基礎。
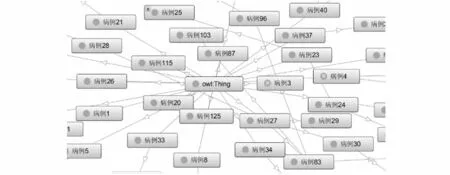
圖2 Protégé構建本體的部分截圖Fig.2 Partial screenshot of building ontology with Protégé
3.3 知識存儲
知識存儲主要研究知識圖譜采用何種方式進行存儲。目前知識圖譜主要有兩種存儲方式:一種是基于RDF結構的存儲方式;另一種是基于圖數據庫的存儲方式。病例關系知識圖譜采用基于圖數據庫Neo4j的存儲方式。Neo4j存儲數據可以采用多種導入方式,本系統存儲采用將RDF數據導入Neo4j中進行存儲,然后利用Neo4j的Cypher語言對實體、關系以及屬性進行知識圖譜的設計,實現圖形化交互式查詢和關聯化推理,其病例關系知識圖譜的部分截圖如圖3所示。
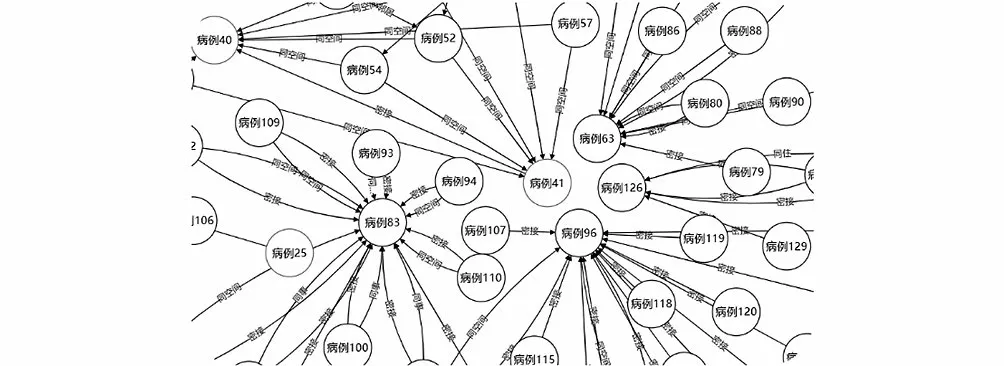
圖3 病例關系知識圖譜的部分截圖Fig.3 Partial screenshot of case relationship knowledge graph
由病例關系知識圖譜可以看出,病例關系以層次化的圖結構形式將其病例接觸關系呈現出來,實現了Neo4j高效的圖查詢和分析應用。
4 病例關系知識圖譜的應用(Application of case relationship knowledge graph)
病例關系知識圖譜通過Neo4j中的Cypher語言實現對病例數據進行更新、查詢和分析,主要利用Neo4j的度中心性算法和中心度算法分析病例中感染力較強和接觸人數較多的人員,從而更好地了解病例人員及其接觸關系,提高流行性疾病的預防能力,進一步完善疾病防控體系。
4.1 數據更新
為了使本知識圖譜能充分映射現實世界中的真實情況,應該對模型中的數據記錄不斷更新,對實體和關系進行增減操作,即修改模型中的實體記錄和關系記錄。
CREATE(病例a:Person1{name:'病例a',狀態:'確診病例',職業:'職員',居住區域:'B區',居住地址:'B區陽光大道',工作地址:'B區陽光大道',data:'2022-4-28'})//增加一個實體
MATCH(n:Person1),(m:Person1) WHERE n.name="病例83"AND m.name="病例103" CREATE(n)-[r:密接]->(m) RETURN r//在病例83和病例103中直接增加一個“密接”關系
刪除單個實體有兩種方法:通過name屬性或者id屬性刪除實體;如果兩個實體之間存在關系,應該先刪除關系,然后再刪除實體。
MATCH (n:Person1{name:'temp'}) delete n//通過name屬性,刪除name為'temp'的實體
MATCH (n) DETACH delete n//刪除所有實體
MATCH (a:Person1)-[r:密接]-(b:Person1) where ID(a)=47 and ID(b)=48 DETACH delete a,b,r//刪除實體a、實體b及實體a和實體b的“密接”關系
4.2 信息查詢
信息查詢是對病例人員及關系的查詢,主要了解和病例人員接觸的相關人員關系。信息查詢主要根據實體屬性和關系屬性進行查詢,首先提取查詢條件,如實體的屬性:姓名、感染時間等,或實體的關系:“密接”“同空間”等;然后利用Neo4j的Cypher語言進行查詢,查詢結果可以以圖的形式顯示符合條件的病例關系圖,也可以以表的形式顯示病例人員信息表。本文以實體“病例83”為例,主要以實體的屬性、實體的關系或實體的屬性和關系相結合作為條件進行信息查詢。
查找某時間感染的所有病例人員,例如查找2022 年4 月21 日的病例人員,運行結果如圖4所示,其Cypher執行語句如下:
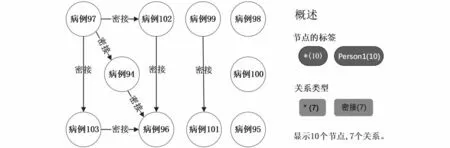
圖4 某時間感染的所有病例人員圖Fig.4 Diagram of all infected persons at a given time
MATCH (n:Person1{data:"2022-4-21"}) RETURN n
運行結果圖4的左邊顯示了2022 年4 月21 日所有病例人員及關系圖;右邊顯示了共有病例10 個,其中通過“密接”感染的有7 人。
中國高技術制造業增加值影響因素的面板數據模型分析 ……………………………………… 劉 碩 胡澤文 智 晨(4/17)
查找與病例人員有“密接”關系的所有病例人員信息,運行結果如圖5所示,其Cypher執行語句如下:
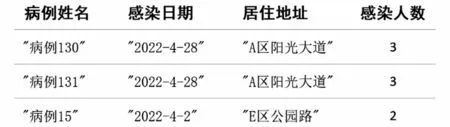
圖5 按“密接”關系查找所有病例圖Fig.5 Diagram of finding all cases by close contact relationship
MATCH (p:Person1)-[a:密接]->()
RETURN p.name AS 病例姓名,p.data AS 感染日期,p.'居住地址' AS 居住地址,COUNT(a) AS 感染人數ORDER BY 感染人數 DESC
根據病例的name屬性查找與“病例83”“密接”的人員,運行結果如圖6所示,其Cypher執行語句如下:
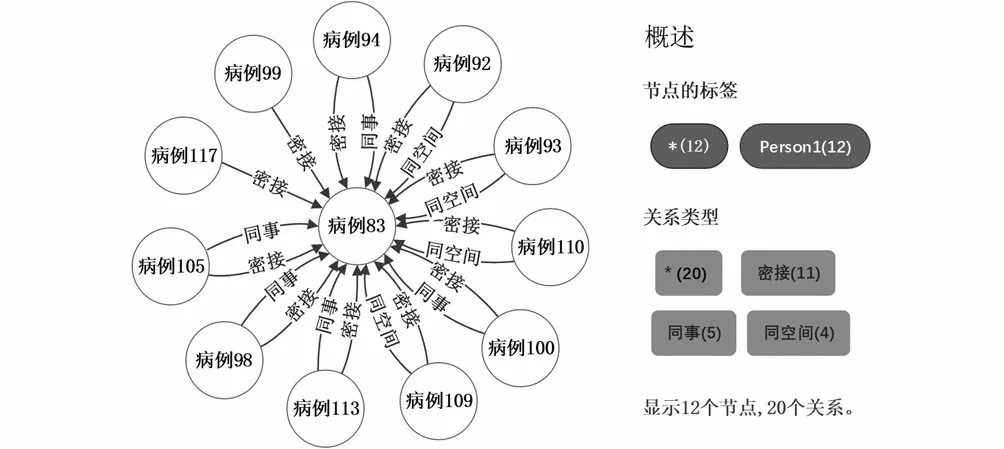
圖6 與“病例83”“密接”的人員圖Fig.6 Diagram of close contacts with case 83
MATCH n=(:Person1{name:"病例83"})-[:'密接']-()RETURN n
運行結果圖6的左邊顯示了與“病例83”“密接”的人員關系圖;右邊顯示了與“病例83”“密接”的人員有11 個,其中有4 人與“病例83”同空間,有5 人與“病例83”是同事關系。
4.3 利用Neo4j算法對病例關系進行分析
本文對病例人員關系的分析主要利用Neo4j的中心度算法和度中心性算法。其中,中心度算法用來分析病例人員的感染力,度中心性算法用來分析和病例人員接觸的人數,通過這兩個算法分析和發現病例中出現的感染力較強、接觸人數較多的情況,及時掌握目前病例人員的狀況。
PageRank算法是一種用于測量實體的傳遞性或定向性影響的算法。它已在Google中進行推廣,被廣泛認為是一種檢測任何網絡中有影響力實體的方法。PageRank已用于對公共場所或街道進行排名,預測這些區域的交通流量和人員流動等。
在本文的病例關系研究中,PageRank算法的分數(score)可以反映出每個病例的感染力大小,分數值越高越有影響力,因此可以分析出病例中最有影響力的感染者,運行結果如圖7所示,其Cypher執行語句如下:

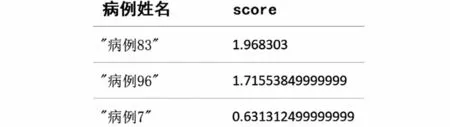
圖7 PageRank算法分析結果圖Fig.7 Diagram of PageRank algorithm analysis result
從運行結果圖7中可以分析出“病例83”的分數最高,感染力也較大;“病例96”的感染力次之。
度中心性算法是由Linton C.Freeman于1979 年提出的,該算法經常用于找出單個實體的受歡迎程度,常作為對全圖進行最小度、最大度、平均度及標準差整體分析的一部分。它是任何通過查看入度和出度關系數量進行影響力分析的重要組成部分。
在本文的病例關系研究中,病例關系圖的入度用于記錄感染該病例人員的人數(即感染人數),出度用于記錄被該病例人員感染的人數(即被感染人數),運行結果如圖8所示,其Cypher執行語句如下:


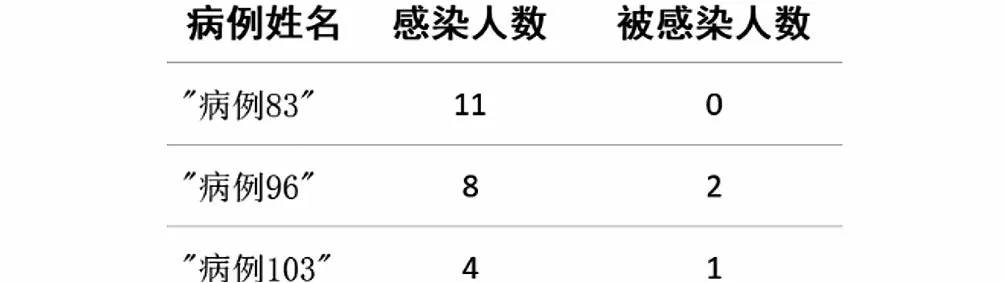
圖8 度中心性算法分析結果圖Fig.8 Diagram of degree centrality algorithm analysis result
從運行結果圖8中可以分析出每個病例的接觸和被接觸人數,動態掌握病例接觸情況。例如,接觸“病例83”的有11 人;接觸“病例96”的有8 人,“病例96”接觸的病例者為2 人。
5 結論(Conclusion)
本文首先介紹知識圖譜和圖數據庫Neo4j的定義以及構建知識圖譜的關鍵技術,然后根據病例關系知識圖譜的構建流程和構建技術,對獲取的數據源進行數據提取和對實體、關系和屬性的信息抽取,再用Protégé工具構建本體RDF數據導入圖數據庫Neo4j中進行存儲,實現多種查詢檢索和關系分析。病例關系知識圖譜的構建也為病例關系分析提供了參考,進一步完善了傳染疾病防控體系,從而有針對性地提供較為完善的防控措施。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
中華手工(2017年2期)2017-06-06 23:00:31
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中外會展(2014年4期)2014-11-27 07:46:46
財經(2010年20期)2010-10-19 01:48:32
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
