俄語情感分析研究綜述
2022-09-06 11:07:58徐琳宏林鴻飛
計算機工程與應用 2022年17期
徐琳宏,劉 鑫,閻 月,原 偉,林鴻飛
1.大連外國語大學 語言智能研究中心,遼寧 大連116044
2.錦州師范高等專科學校,遼寧 錦州 121000
3.信息工程大學 洛陽校區,河南 洛陽 471003
4.大連理工大學 計算機系,遼寧 大連 116024
情感分析通過對信息的處理、識別和統計,獲取其中蘊含的情感及分布規律,數據主要來源于社交媒體中用戶評論,是一個多學科交叉的研究方向。隨著移動應用和互聯網信息的不斷增加,分析龐大用戶群體的情感特征,提取其中有價值的信息成為一個研究熱點。情感分析的研究有助于了解民眾對時事熱點、政策規定和商貿產品等的真實態度和想法,能為政策的制定和調整提供依據。但目前情感分析的研究還是以英語為主,俄語情感分析方面無論是模型構建還是數據儲備都處在不斷探索中。
在“一帶一路”倡議和合作共贏的大環境下,俄羅斯作為我國的全面戰略協作伙伴,是具有重要影響力的大國。同時俄語作為東斯拉夫語支的重要語種,在前蘇聯15個加盟共和國所在區域也是使用最廣泛的語言,其中俄羅斯聯邦、白俄羅斯、哈薩克斯坦和吉爾吉斯斯坦都把俄語作為官方語言。因此,解析俄語區民眾在社交媒體里表達的態度有助于探索與各國在經濟等領域的合作模式,也對我國國際政策的順利開展有積極的推動作用。
社交媒體中蘊含著大量的文本、語音和視頻信息,為情感分析的研究提供了大量真實的研究數據。目前俄羅斯的互聯網普及率達到83%,根據Deloitte[1]2020年發布的俄羅斯互聯網使用報告,YouTube、VKontakte、Instagram 和Odnoklassniki 是目前最為流行的四種社交媒體軟件,大約有77%的用戶周末在線時間超過3 小時,即使工作日也有68%的人使用社交媒體軟件。從用戶年齡角度分析,VKontakte的用戶主要集中在30歲以下的年輕人,而Odnoklassniki則以老年用戶為主。由此可見,在俄羅斯各個年齡段的人群均在長時間地使用社交媒體,由此產生的海量信息為俄語情感分析提供了便利,同時也是一個巨大的挑戰。
本文的主要目的是梳理俄語情感分析的傳統模型和最新成果,在此基礎上總結現有研究的相關資源、識別方法和應用場景,為后續俄語情感分析的系統研究提供依據,并發現進一步探索的方向和研究熱點。
1 數據獲取方法及情感分析流程
本文以“emotion+russian”和“sentiment+russian”以及“俄語”“俄文”和“俄漢”與“情感”和“情緒”兩組詞的交叉組合作為檢索詞分別在Web of Science(WoS)、DataBase Systems and Logic Programming(DBLP)和CNKI 中進行檢索,獲取相關文獻190 篇。閱讀每篇文獻并提取其中與俄語情感分析相關的參考文獻,最終篩選出與本文研究主題相關的73 篇文獻,對俄語情感分析的已有研究進行細致梳理和總結。
情感分析研究的一般研究框架如圖1所示,首先選擇研究領域,獲取相關語料,接著完成數據的預處理,在合理的標注規范和標注原則指導下完成情感標注工作,然后對數據進行識別或分析。識別工作多采用機器學習或深度學習模型,借助詞典和形態分析工具等資源,以相關的評估指標為指導,旨在完成更大規模語料的自動識別。數據分析工作多是統計人工或自動方式標注的數據,發掘網絡中積極和消極情感的分布規律和傳播方式等。也有很多研究先通過機器自動識別大規模的情感數據,再采用統計的方法分析數據的分布特征。本文將在后續的章節中按情感分析的研究框架逐一梳理俄語情感分析的研究工作。

圖1 情感分析研究框架Fig.1 Research framework of sentiment analysis
2 俄語情感分析資源
資源的使用貫穿于情感分析的每個階段,無論是語料預處理還是針對情感自動識別的特征提取,都需要用到情感詞典和各類相關工具。而數據集不但是開展分析工作的基礎,也是研究結論可靠性和魯棒性的重要保障。與資源比較豐富的英語情感分析相比,俄語情感分析在規模和數量上相對比較匱乏,因此每個資源更顯得彌足珍貴,本章將介紹俄語的情感詞典和帶標注數據集兩類資源。
2.1 俄語情感詞典
表1 中列出了現有的俄語情感詞典資源,其中LinisCrowd和RuSentiLex是兩個規模較大、建設質量較高、引用頻次較多的詞典。它們都是采用半自動的方法創建,即先采用模式匹配的方法從大規模語料中自動抽取候選詞列表,然后通過人工的篩選確定情感類別,例如RuSentiLex詞典就采用了35種負面模式和20種正面模式獲取候選情感詞。自動構建詞典多是采用與種子詞計算相似度[13]、與帶標注文檔計算PMI[14]或者利用圖傳播[12]的方法。一般來說,完全自動的方式構建的詞典規模較大,但質量相對較低。純手工創建的情感詞典雖然質量較高,但考慮人工成本,詞典規模都不會太大,且大多局限于某個領域,例如Tutubalina2016 和Blinov2013語料分別來源于汽車和電影評論兩個領域,規模都在5 000詞左右。
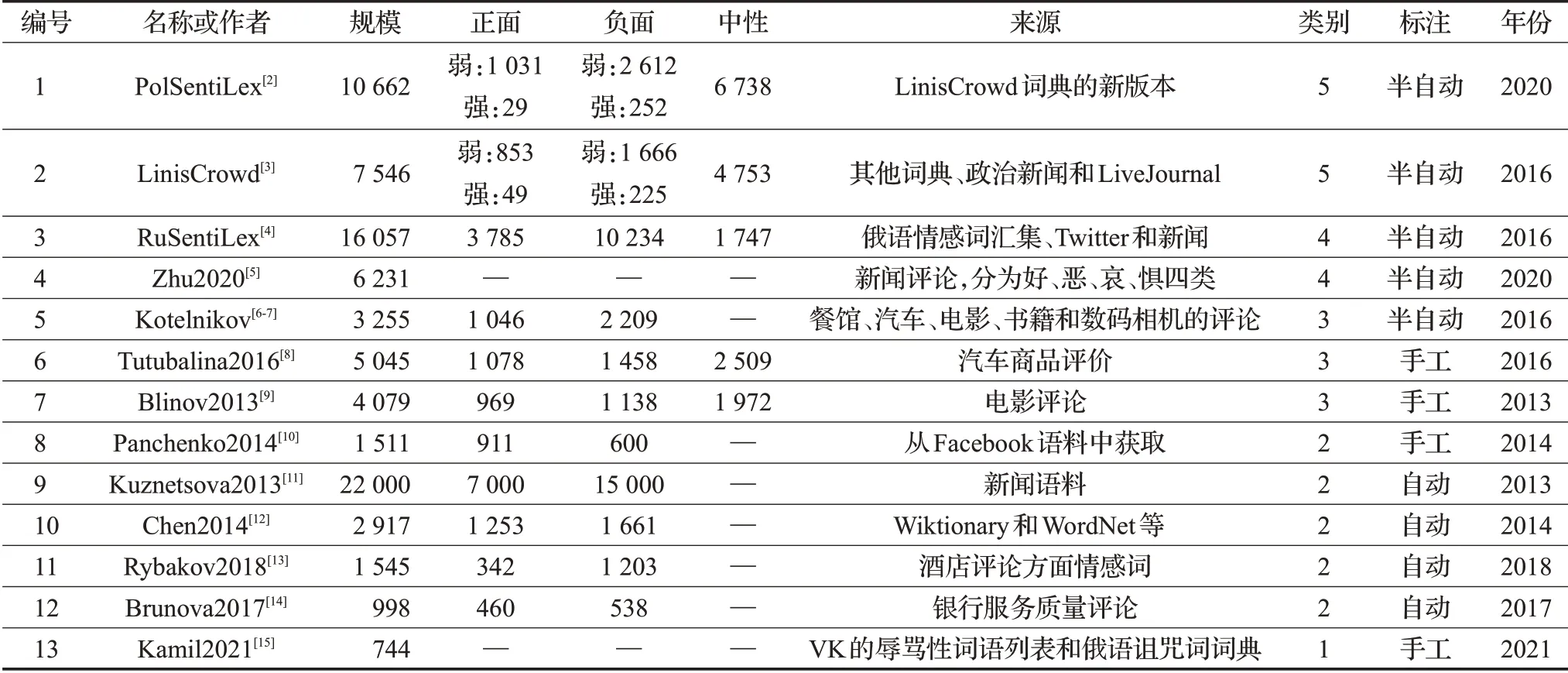
表1 俄語情感詞典匯總Table 1 Russian sentiment lexicon
情感詞典的分類以三分類和二分類居多,三分類是將詞匯分為正面、負面和中性,而二分類則是去掉中性類別,五分類就是在此基礎上將正面和負面分別劃分為強和弱兩種。單分類的情感詞典只有Kamil2021 的辱罵語詞典,詞表中詞匯都是辱罵語。RuSentiLex詞典是四分類的,它是三分類的基礎上增加了一個亦正亦負的類別,就是說某些詞匯具有情感,但在不同語境下情感類別不同,從單一詞匯角度無法確定極性,這類詞匯在詞典中有291 個。其他詞典并沒有考慮詞匯在不同語境中情感的差異性,一個詞匯只能屬于單一類別,這樣會影響詞匯表達語義時的多樣性,因此,這將是未來俄語情感詞典構建工作需要加強和改進的方面。
情感詞典的數據來源主要集中在已有詞典、新聞和評論幾種語料。LinisCrowd、RuSentiLex、Chen2014 和Kamil2021 都利用了已有的詞典和WordNet 等電子資源。而評論類語料來源既包括餐館、酒店和銀行等實體對象,也包括電影、書籍、相機和汽車等產品。產品評論類的情感詞匯多與產品的不同方面有關,主要應用于方面級情感分析。語料大多源自相關的社交媒體平臺,如VKontakte、Twitter和LiveJournal等。此外,質量較高的英語情感詞典LIWC也有相應的俄語翻譯版本,未在表格中列出。從來源看,情感詞典在繼承已有知識的基礎上,語料來源比較廣泛,保證了詞匯的多樣性。未來可以考慮整合所有的情感詞典,同時還可以利用手工構建的詞典進一步評估自動詞典的質量,構建一個規模更大、詞匯更加豐富和準確的高質量俄語情感詞典。
2.2 俄語情感分析數據集
表2中列出了俄語情感分析的相關數據集的規模、分類方法、數據來源和模態等信息。與詞典構建不同,大部分數據集是人工參與標注和審核的,單純自動方式構建的數據集只有7個,一般是根據用戶評分結果直接分類[27-28]或者根據語句中的表情符號分類[25],目前還沒有發現使用自動識別模型進行標注的數據集,這可能與俄語情感識別準確率總體比較低,難以保證情感分類質量有關。在所有的數據集中,RuSentiment 和LinisCrowd2016 的質量相對較高,都是五分類的語料,RuTweetCorp 和RuReviews 規模相對較大,均是以自動方式構建的。現有數據集以文本形式的語料為主,分為一般文本情感分析和方面級情感分析兩類。
表2中包含8個與評測相關的數據集。俄語情感分析的評測從2011 開始出現,分別由俄羅斯信息檢索研討會(ROMIP)、SentiRuEval 和SemEval 發起。ROMIP是一個類似于TREC 的俄語競賽,關于情感分析的競賽項目集中在2011 和2012 年發布。SentiRuEval 和SemEval都是針對情感分析任務的競賽,前者專門面向俄語情感分析,辦了2015 年和2016 年兩屆。SemEval包含各個語種的情感分析任務,每年都會舉辦,其中2016 年的任務5 是針對俄語情感分析的。上述三個競賽的語料均來源于用戶評論,ROMIP 評測語料是來自Imhonet和Yandex網站用戶關于電影、書籍、相機評論,訓練集根據用戶評分自動分類,測試集經過人工標注。SentiRuEval 是Twitter 中關于電信和銀行的評論,2016年的數據是在2015 年的基礎上追加了部分數據,兩者有部分重合。SemEval 的任務5 是關于餐館評論的,除了正面、負面和中性的三分類,還有少部分語料標注為“沖突”類。
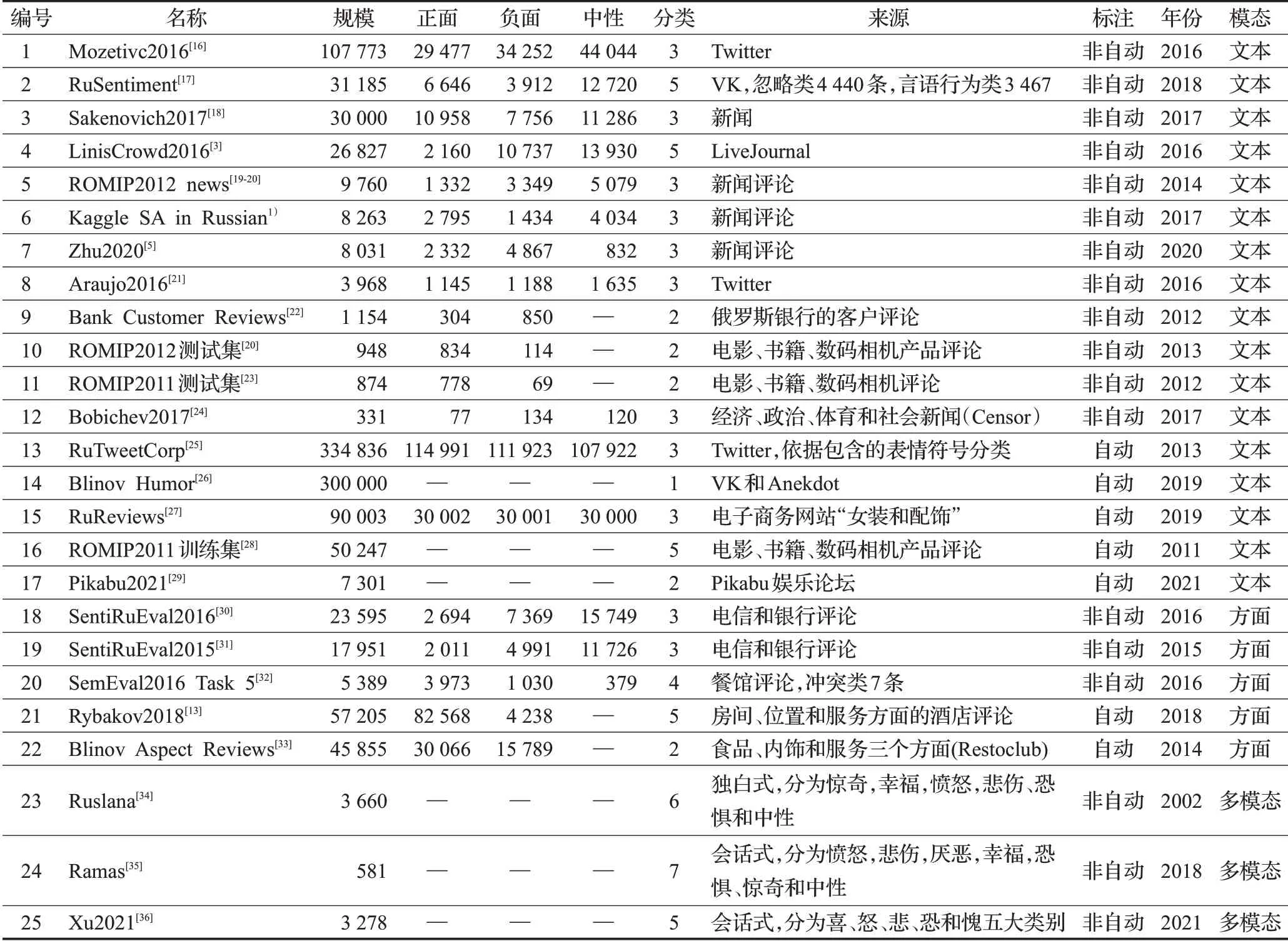
表2 俄語情感數據集Table 2 Datasets of Russian sentiment analysis
SentiRuEval 和SemEval 都是對產品或餐館的某個方面進行情感標注,因此可以應用于方面級情感分析的任務,但是語料中大部分數據都是一條數據對應一個方面,所以也可以用于一般的文本情感分類任務。需要注意的是方面情感標注中正面、負面和中性的數量是按方面計算,因為一個評論可以包含多個方面,因此每類標注數量的總和會大于總評論數。從數據來源看,新聞和用戶觀點類的語料主要來自VK、Twitter、LiveJournal和Censor,而產品評論類的語料主要來源是電子商務類的網站,包括Imhonet、Yandex、banki.ru、TripAdvisor 和Restoclub 等。從發布時間看,文本類的情感標注語料從2012年開始,前期主要以手工標注為主,近幾年開始出現大規模的自動標注語料。語料發布集中在2012—2013 和2016—2017 這兩個時間段內,這可能是因為俄語情感分析的研究工作在2016年以后逐步獲得更多研究者的關注。從各情感類別的數據分布看,大部分語料中性類數據較多,正面和負面數據相對較少,正面和負面語料的比例也差異較大,數據的不平衡性比較明顯,這也為俄語情感分析的自動識別提出了挑戰。
此外,數據集中還有兩個關于幽默的語料,Blinov Humor[26]和Pikabu2021[29]將文本分為幽默和非幽默兩類,適用于俄語的幽默識別研究。除了文本語料外,表2還包含三個多模態語料,Ruslana[34]、Ramas[35]和Xu2021[36]。它們的情感類別比較多,主要分為驚奇、幸福、憤怒、悲傷、恐懼和中性,Ramas 在Ruslana 的基礎上增加了“厭惡”類別,這兩個語料庫都是以視頻形式展現,由專業演員演繹各類情感。Ramas除了視頻模態,還采集了表演者的面部表情、語音、運動以及生理信號等信息。Xu2021則是以俄語情景劇《我是如何成為俄羅斯人的》的視頻為數據源,人工標注完成。三個多模態語料中,Ramas 和Xu2021 都是會話式語料,數據包含多人的對話,上下句之間具有一定的情感連續性,而Ruslana是獨白式的語料,視頻中只出現一個人的自述,兩種類型的語料在多模態情感分析的模型選擇上差異較大,不同的應用場景需要選擇不同類型的數據集。
3 俄語情感分析的方法
俄語情感分析的研究分為幾種類型,一類是針對固定領域的標注語料進行統計,解析社交網絡數據的規律和特點,為相關政策的制定和調整提供依據。還有一類是從語言學的角度出發,重點分析俄語中情感詞匯的表達方式。此外,更多的研究是先構建自動識別模型,獲取大規模語料,然后在大規模語料上完成數據分析。成功構建自動識別模型是后續研究順利進行的基礎,模型結果的準確性也是研究結論正確與否的保障,因此這一章中側重綜述與俄語情感分析自動識別模型相關的工作,并補充部分俄語情感詞匯分析和數據分析的研究文章。梳理過程中參考了已有的綜述文獻[37-41],但與其他相關綜述不同的是本文以情感分析的流程為線索,分階段總結當前俄語情感分析工作的特點,并且詳細列出了自動模型的分類方法和實驗結果等信息。
3.1 俄語情感的自動識別模型
隨著互聯網的高速發展,數量龐大的社交媒體用戶每天產生海量文本,單純依靠人工標注方式難以獲取大規模的用戶情感數據,這就需要借助情感分析的自動識別模型。早期的情感分析方法有基于規則和機器學習兩種,基于規則的方法通常以情感詞典為基礎,配合固定的情感表達模式,這種方法的準確率取決于詞典的規模、質量以及歸納的模式是否全面,很難應對互聯網中層出不窮的新詞匯和表達方式。與基于規則的方法相比,機器學習的方法更節省人力資源,除了特征提取外多數工作依靠機器自動完成,其中特征提取和機器學習模型的配合是研究的重點。2016年后,隨著深度學習方法廣泛應用,許多研究者發現在俄語情感分析工作中,選擇和搭配適當的深層神經網絡和預訓練模型更為重要。表3從數據來源、模型方法和分類結果幾個方面對比和總結了俄語情感分析自動識別的工作。
表3中的數據大體按其發表的年份排列,其中編號1~19的相關研究針對一般情感分析,編號20~23的工作是關于方面級情感分析的。該表匯總了在特定數據集上的最好結果,為了兼顧分類結果的準確率和召回率,本文以分類評估最常用的宏平均(F1)作為主要的測量指標,對于沒有提供F1值的部分研究,則給出其分類結果的準確率(accuracy,Acc)。有些工作中結合了多個模型實現俄語情感分析,表3中只列出了對應文獻中特定數據集上效果最佳的模型及其實驗結果。
從表3 中可以看出,2012 年到2016 年間,俄語情感自動識別模型以機器學習為主,效果較好的模型包括SVM、NB、LR 和MaxEnt,大多研究工作在對比多種機器學習算法之后,發現SVM 效果最好。機器學習模型分類的結果不僅依賴算法的選擇,更依賴特征的選擇,俄語情感分析中常用的特征包括詞匯級和語句級兩大類。詞匯級特征在語料預處理階段主要體現在詞干化和形態還原等,模型輸入層多以情感詞典為基礎[28,43],并通過同義詞和近義詞等方式進行擴充和分組。語句級的特征一般有Unigram、Bigram、Tf*idf[42]以及句法結構[31,55]和語法關系[44-45]等。2016 年以后,俄語情感分析中開始引入多種深度學習模型,其中包括CNN、LSTM和GRU 等,大部分研究者采用單一的神經網絡模型[18,27,49,51,54],少部分研究者則針對不同模型的優點對其進行組合和改進[56]。
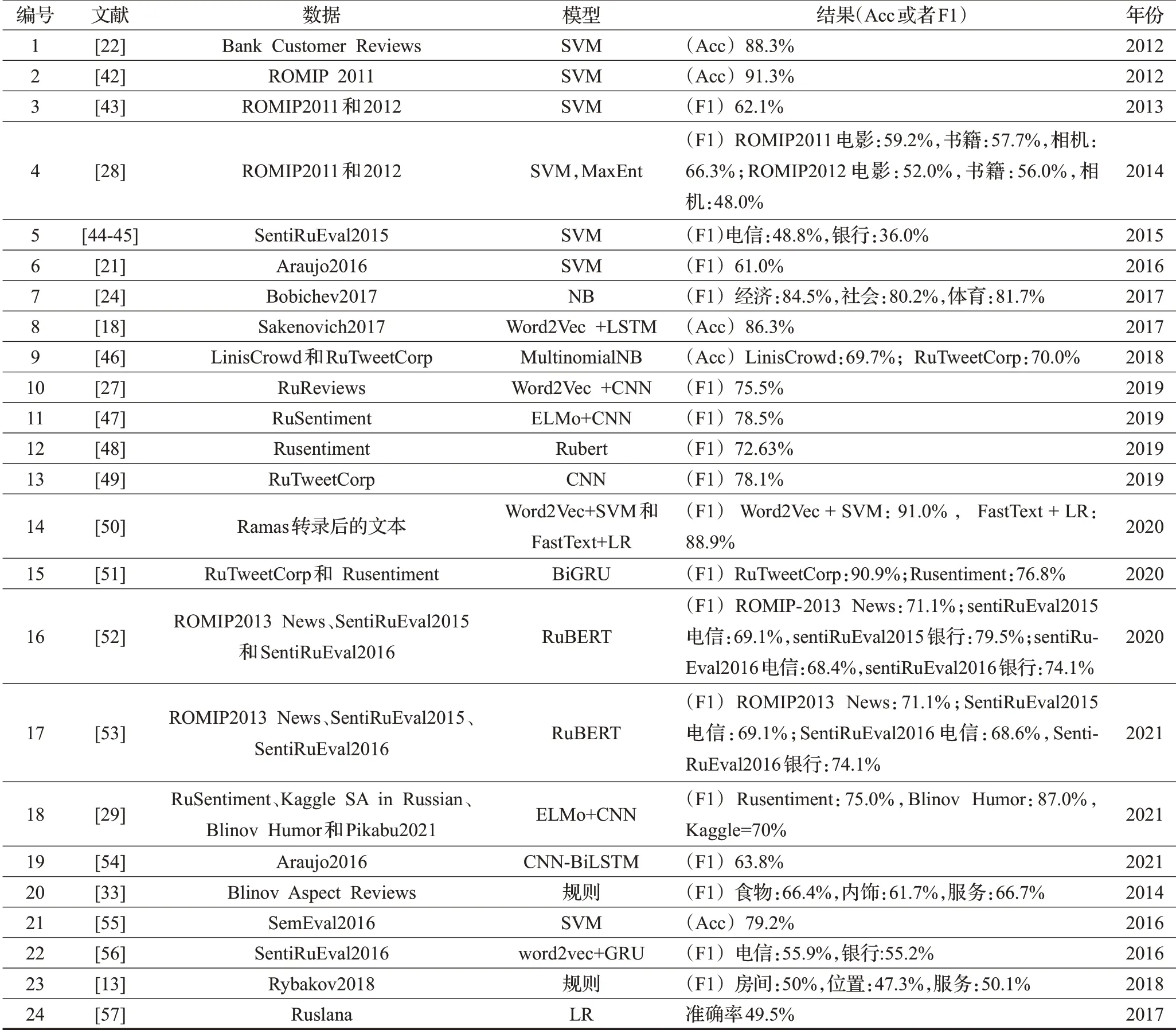
表3 俄語情感分析模型匯總Table 3 Summary of Russian sentiment analysis model
隨著深度學習在自然語言處理領域的不斷應用,基于語言模型的詞向量技術也在不斷發展。早期的研究者多數使用Word2Vec、GloVe 和FastText 等靜態詞向量,但由于同一單詞在不同的語境中對應的詞向量不變,故而很難解決一詞多義問題。因此越來越多的研究者通過ELMo、GPT 和Bert 等預訓練模型生成動態詞向量,充分提取單詞的上下文特征信息,根據不同的語境動態調整詞向量,較好地解決了一詞多義問題。RuBert[41]是Bert 模型在大規模俄文語料上訓練之后得到的預訓練模型,它受到了許多學者的青睞,并在很多研究中取得較好的結果。值得一提的是,還有一些學者試圖融合重構基于特征提取的機器學習模型和基于詞向量的深度學習模型,例如將詞向量作為特征輸入到傳統機器學習模型中[50],或者將人工提取的特征加入到深度學習模型的各層架構中[54]。
除了RuSentiment、RuTweetCorp、RuReviews、Linis-Crowd等常見語料庫之外,Kaggle、ROMIP和SentiRuEval等評測數據集也被眾多研究者所采用。部分研究工作涵蓋了多種數據集[29,46,51-53],大部分工作的實驗結論僅針某個單一的數據集。在各常用語料庫上,目前表現最好的模型及其分類結果依次為:在RuSentiment 上采用預訓練模型ELMo 與CNN[47]模型結合,最終獲得78.5%的F1值;在RuTweetCorp上采用雙向GRU(BiGRU)模型[51]獲得90.9%的F1 值;在RuReviews 上采用CNN 模型獲得75.5%[27]的F1 值。而在各種評測數據集上的研究現狀如下:RuBert 在SentiRuEval 的電信數據和銀行數據中分別獲得69.1%和79.5%的F1 值;Loukachevitch 等[28]將SVM 和最大熵模型分別應用在ROMIP2011 和2012數據集上,并完成二分類、三分類和五分類實驗。觀察表3中的三分類結果可以發現,其研究成果在2011年和2012 年的相機類評論數據集上表現差異較大,F1 值從62.3%下降為48.0%,可見即使在同一領域的數據中,模型的波動也較大。俄語情感分析領域的深度學習模型相對都比較簡單,以RuSentiment 數據集上效果最好CNN模型為例,首先將詞向量嵌入到三個卷積中,每個卷積具有相同數量的過濾器和不同的內核大小,經ReLU 激活后進行連接,最后通過softmax 激活,獲取最終結果[47]。具體模型如圖2所示。
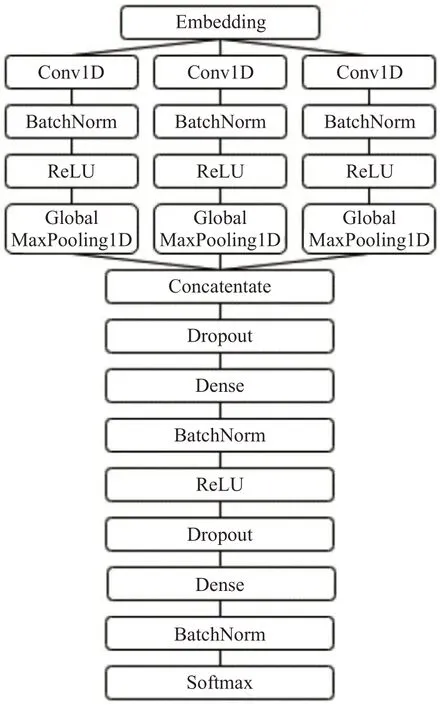
圖2 Shallow-and-wide卷積神經網絡Fig.2 Shallow-and-wide CNN
從評測的總體結果看,二分類任務結果較高,接近90%,三分類任務一般在75%左右,五分類任務的結果最差,接近50%[19,28]。除了上述旨在提高自動分類結果的研究外,還有一些研究分析不同外在因素對分類結果的影響,如Rubtsova[58]研究不同年份數據的自動分類性能差異,Araslanov 等[59]基于NB 和LR 算法評估俄語短文本預處理對分類結果的影響。
在俄語情感分析中,以SVM、NB 等為代表的傳統機器學習模型具有較完美的數學理論解釋,面向海量數據時模型的訓練時長相對較短。深度學習則更偏重經驗主義驅動,其多數模型的可解釋性研究進展較為緩慢。然而,近年來越來越多的實驗表明,深度學習模型在進行訓練學習時,能保留更多對于數據的擬合度、攜帶更多的語義信息,其性能優于傳統的機器學習模型。
在深度學習模型中,主體由卷積層構成的CNN 模型結構相對簡單,模型訓練時并行運算能力更強,對識別目標任務的結構具有一定的優勢。以GRU 和LSTM為代表的RNN 模型訓練時間相對較長,但由于其記憶功能對序列識別建模具備優勢,因此更為廣泛地應用于多種NLP 任務。與上述深度學習模型相比,以ELMo、GPT 和BERT 等為代表的預訓練模型提供了更好的模型初始化,通常具有更好的泛化性能,并能加速對目標任務的收斂。
從近年來的研究結果來看,在情感分析任務中深度學習模型并未能全面超越傳統模型。例如,在Matheus2016 數據集上采用SVM 方法可取得61.0%的F1 值,其與CNN-BiLSTM 模型的結果相差不大。在多模態這一情感分析的最新研究領域中,目前針對俄語相關語料的自動識別研究很少,尚處于起步階段。
綜上所述,在基于規則的情感分析方法之后,俄語情感自動識別模型的發展具有較為鮮明的時代特征,可以劃分為傳統的機器學習和深度學習兩個階段,雖然分類算法的選擇對模型的自動識別效果很重要,但語料的預處理方法、特征提取和預訓練模型的微調也會對識別準確率產生較大影響,一個好的研究方案應該綜合考慮上述多個方面。另外,俄語情感識別的結果普遍較低,當數據集的規模較大時,三分類的宏平均基本在75%左右,這與實際應用的需求還有一定差距,尚有較大的提升空間。此外,模型的穩定性也是自動情感分類算法未能大范圍推廣的重要原因,自動識別算法的魯棒性和泛化性還有待進一步提高。
3.2 俄語情感語料的數據分析
俄語情感的數據分析是在人工或者自動標注語料的基礎上,分析數據中情感表達的特點,進而發掘公眾對新聞事件的觀點,探索用戶評論中蘊含的情感以及情緒的分布和傳播規律等。按分析對象的粒度可以分為詞匯級和語句級,國內有很多學者研究了俄語詞匯的情感表達,如研究俄語中帶有情感意義的成語[60]、俄語情感類心理動詞[61]、俄語情感態度動詞以及俄語情感詞匯的表達手段[62-63】等。國內以語句為單位的相關研究不多,原偉等[64]在構建并分析俄漢可比語料庫的基礎上,發現俄文評論趨向使用長評論、形容詞和動詞表達情感,而中文網評趨向使用短評論、名詞和動詞表達情感,俄文新聞評論中存在冗余消極評價的現象等。朱姍姍等[5]為考察俄語情感詞匯的表達手段,人工標注了8 031條用戶評論,構建了包括6 321條詞匯的俄語情感詞典,并在此基礎上分析了俄語情感表達的手段。
除了文本模態的詞匯外,語音等多模態情感詞匯的研究很早就已經開展,它們多以Ruslana語料庫為基礎,探索俄語情感表達中的聲學特征[65],分析情感狀態對俄語擦音和塞擦音特征的影響[66],探查持續時間、能量、共振峰和動態范圍對俄語情緒表達的影響[67],討論加入表達者的信息是否有助于語音情感識別[68]。
在國外,以情感自動或手工創建的俄語情感語料為基礎,統計和分析數據的研究很多,文獻[40]中按數據來源的類型劃分,詳細梳理了此類相關的研究,這里不再贅述,本文在此補充部分未提及的俄語情感數據分析相關的研究。Litvinova等[69]研究欺騙檢測的問題,分析俄語真假文本在統計上是否有顯著差異,發現男性和女性說謊的方式不同,且應為不同性別、年齡和心理特征的人設計不同的模型。Bodrunova等[70]分析俄語可解性與情感的關系,用統計學的方法探究自動識別模型(LDA、WNTM 和BTM)和人工標注在可解性方面的差異,發現可解釋的話題越多,負面情緒就越重。Alvarez等[71]研究Facebook廣告文本中的情感,發現與負面廣告比,大多數的廣告都有積極情緒,且廣告中的情感在2016美國總統大選前后波動比較明顯。
4 俄語情感分析的述評及展望
本文以情感分析研究工作的具體流程為線索,詳細梳理了俄語情感分析的資源、自動識別模型和數據分析三個方面的工作,總結了以往研究中的常用方法和當前的主流模型。現有的俄語情感分析資源包括情感詞典和情感語料兩種類型,在此基礎上總結了主流的自動情感識別模型,機器學習模型和深度學習模型。主要的研究結論有以下幾點:
(1)資源建設方面,俄語情感分析的資源建設目前已經初具規模,為情感分析的后續研究工作提供了保障。情感詞典中詞匯的數量已經能涵蓋大部分俄語的常用情感詞匯,現有的數據集中也包含了一些大規模、高質量的語料庫,但數據來源有限,還需要進一步拓展,同時對各類資源的整合工作也需要加強。
(2)自動識別方面,主流的模型分為傳統的機器學習和深度學習兩種,整體識別的效率和準確率還有待提高。機器學習模型以SVM 算法為主,選擇的特征有NGram、詞法和句法等。深度學習模型選擇算法主要有CNN、RNN和RuBert等。在幾個大規模數據集中,三分類的宏平均最好結果基本在75%左右。
(3)數據分析及應用方面,目前大部分的數據分析工作是以大規模自動識別的語料為基礎的,應用范圍從宏觀的熱點話題監控和輿情分析到微觀的產品和服務的創新和改進,在多個領域都有廣泛的應用價值。然而自動識別模型的分類效果難以像人工一樣準確,因此對研究結論的有效性會產生一定影響。
俄語情感分析的研究工作雖然已經取得了一定的進展,但是與比較成熟的英文情感分析的綜述[72]和研究工作[73]相比,整體研究水平還處于初級階段,存在著很多的不足之處,主要體現在以下幾個方面:
(1)從俄語自身的特點出發構建的模型較少。當前的很多自動識別工作是簡單地參考英文情感分析模型,沒有考慮俄語自身的特性,導致識別的準確率普遍較低。俄語作為一種高度屈折的語言,情感表達的方式有很多獨有的特點,未來可以將這些特性添加到模型中,提高識別的效果。
(2)資源共享性有待加強,語料來源需要不斷拓寬。雖然現有俄語情感分析的詞典和數據資源較多,但部分資源不能公開獲取,例如大規模的語料資源RuSentiment,因為社交平臺的信息授權問題不能繼續提供下載。此外,方面級語料資源多來自電影、餐館、銀行和相機等領域,范圍較窄,還需不斷收集不同領域的數據,拓寬研究范圍。
(3)利用資源豐富的其他語種語料庫的遷移工作比較少。英語等語種的情感分析的研究資源比較豐富,可以考慮采用遷移學習等手段,利用其他語種的現有資源,不斷擴展俄語情感分析的研究方法和資源。
(4)俄語情感分析工作基本上都是文本模態,語音和圖像等多模態的研究工作還處于起步階段。情感表達是一個多層次、多角度的展現過程,單純依賴文本表達必然會損失很多情感信息,因此多種模態信息的互補以及與俄語語音等多個學科的交叉將是未來一個重要研究領域。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2018年5期)2018-11-06 07:15:40
特別健康(2018年3期)2018-07-04 00:40:18
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年26期)2016-08-22 03:23:28
