成敗歷史存檔的融合龍格庫塔-黏菌算法
2022-09-06 11:08:06劉宇凇
計算機工程與應用 2022年17期
劉宇凇,劉 升
上海工程技術大學 管理學院,上海 201600
群智能啟發式算法因其工程應用[1]和人工智能[2]等多種優化領域中優秀的表現和低廉的算力要求在近十幾年間愈發流行。黏菌算法[3(]slime mould algorithm,SMA)是2020 年Li 等人提出的一個用于求解隨機優化問題的新算法,其由自然中黏菌的振蕩模式啟發而設計,通過生物振蕩來傳遞不同位置食物信息的正向或負向反饋,從而尋找到最優的食物位置或最短路徑。基本黏菌算法通過設置不同的移動方式平衡了中群智能算法中的勘探和開采階段,同時使用了非線性自適應參數等成熟的算法改進機制,其獨特的權重機制作為獎懲學習[4]的一種形式,可以為種群提供正向和負向的反饋。由此,黏菌算法具有區別于其他群智能算法的特點且依舊具有良好的可擴展性,其改進和應用受到了國外研究者廣泛的關注。目前該算法已成功應用于光伏模型參數優化[5]、機器學習特征篩選[6]、醫學X光圖像分割[7]、計算機視覺圖像閾值[8]等實際問題,在金融科技、數據挖掘、工業工程等領域具有廣闊的發展前景。
然而黏菌算法依舊存在著收斂速度慢、求解精度低等問題,雖然現階段對SMA算法的研究相對較少,國內外學者依舊使用不同的策略進行改進獲得了不同的成果。文獻[6]使用名為“覓食-進攻”的策略,基于貪婪策略和高斯變異,針對單個個體位置每輪迭代中進行新位置的嘗試,使得求解精度大大提高;文獻[7]將黏菌算法與多年來表現良好的鯨魚優化算法[9]進行融合,在算法啟動階段使用鯨魚優化算法進行搜索,基于其強大的全局探索能力幫助黏菌算法擴大初始搜索空間,之后使用參數控制鯨魚優化算法停止同時啟動黏菌算法;文獻[8]將領導機制引入黏菌算法,通過每輪迭代選出三個候選領導個體的方式,引導整個種群向最優位置加速逼近,提高了算法的收斂性能。
基于對原始黏菌算法特點和計算細節的深入理解和分析,本文提出了成敗歷史存檔的融合龍格庫塔-黏菌算法(SFHRUN-SMA),通過添加改進的成敗歷史存檔機制提高算法精度和速度,使用融合龍格庫塔算法引導種群跳出局部最優,保持種群多樣性,兩種策略平衡了種群的全局和局部搜索階段。實驗中,測試了CEC2017基準測試函數,并探索了CEC2017 測試函數的高維部分,實驗結果驗證了改進策略對算法求解精度和魯棒性的積極影響。
1 基本黏菌算法
黏菌算法中的黏菌一般是指多頭絨泡菌,因其最初被歸類為真菌,所以被命名為“黏菌”。黏菌是一種生活在寒冷潮濕地方的真核生物,黏菌的活躍動態階段是黏菌算法研究的主要階段。在這個階段,黏菌使用體內的有機物尋找食物,包圍它,并分泌酶來消化它。在黏菌遷移過程中,其前端會延伸成扇形,后端則連接著一個靜脈網絡,保證細胞質在其中流動,從而達到信息的溝通,并且根據搜尋到食物的質量和密度動態調整靜脈直徑的大小,最終將整個黏菌的位置調整至最優食物處。受到黏菌這種行為模式的啟發,Li及其團隊設計開發了黏菌算法。
基本黏菌算法的抽象數學描述如下:假設n個黏菌分布在d維搜索空間中,第t次迭代第i個黏菌的位置可以表示為Xi(t),max_t為最大迭代次數,全局最優位置Xb表示食物位置。黏菌的覓食尋優過程分為三個階段:
(1)接近食物
黏菌可以根據空氣中的氣味接近食物,下式模擬了其接近食物的過程:
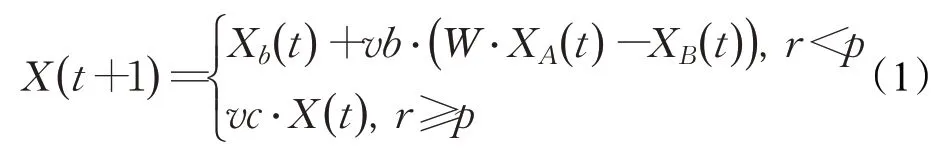
其中,vb模擬了黏菌個體從種群中其他個體學習的程度,是服從[-a,a] 均勻分布的系數,vc模擬了黏菌個體對自身信息的保留程度,其從1到0線性遞減,t代表當前迭代輪次,Xb代表目前為止找到食物濃度最高的個體的位置,即當前全局最優解,X代表黏菌位置,XA和XB代表兩個從黏菌種群中隨機抽取的個體,W代表黏菌個體的權重。
計算p的公式如下:

其中,i∈1,2,…,n,S(i)表示黏菌個體的適應度值,DF表示所有迭代輪次中找到的最優適應度。
計算vb的公式如下:

其中,a為隨迭代次數減小的動態參數,用來收縮隨機數vb的生成范圍,以此模擬黏菌接近食物源過程中靜脈逐漸收縮提高尋優精度的過程,a的計算公式如下:
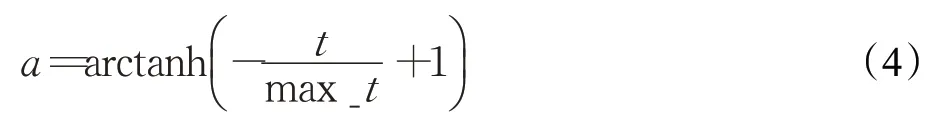
計算權重W的公式如下:

其中,選擇分支的判斷條件condition為適應度排名位于前一半種群,r為[0,1]間的一個隨機數,max_t表示最大迭代次數,bF表示當前輪次獲得的最優適應度值,相對的,wF表示當前輪次獲得的最差適應度值,SmellIndex表示按照適應度值大小排序的黏菌個體索引(在求解最小值問題時使用升序排序方法)。
(2)纏繞食物
該階段模擬了黏菌搜索食物過程中靜脈結構的收縮模式,當黏菌靜脈接觸到的食物濃度越大,其通過生物振蕩反應產生的波就越強,細胞質流動就越快,靜脈細胞質粘稠程度也就越高。公式(5)描述了黏菌在搜索區域基于食物濃度或質量的判斷獲得的反饋,若該位置的食物濃度處于整個種群截至目前所有搜索結果的上位,則給予該位置黏菌正向反饋,反之給予下位黏菌反向反饋,以此方式充分利用適應度的計算結果信息來調整不同位置黏菌的權重,進一步調整整個種群的搜索方式。同時,隨機數r保證了黏菌個體間的多樣性。
基于上述理論,黏菌的位置更新公式如下:

其中,LB和UB代表了搜索空間的上下邊界約束,rand和r代表了[0,1]間隨機數。轉換概率z在Li的參數實驗中被證設置為0.03時整個算法表現最好,故本文中z同樣設置為固定值0.03。
公式(7)所示黏菌算法框架通過非線性自適應參數p平衡了黏菌算法勘探和開采的不同移動方式,同時轉換概率z的存在使得種群有一定概率進行自身位置的重置,有利于種群跳出局部最優,保持種群的多樣性。
(3)振蕩反應
黏菌依靠生物的震蕩反應來調整靜脈中細胞質的流動從而調整自身位置搜索最優食物位置。黏菌算法中的參數W、vb、vc用來模擬黏菌的振蕩反應,W根據適應度選擇不同振蕩模式的行為模擬了黏菌個體根據其他位置個體搜索到的食物情況選擇自身下一步行為的搜索模式,vb動態調整振蕩過程中使用其他個體信息的口徑模擬了黏菌靜脈直徑變化的過程,vc線性變化模擬了黏菌對自身歷史信息保留程度的變化。
2 成敗歷史存檔的融合龍格庫塔-黏菌算法
2.1 龍格庫塔算法
龍格庫塔算法[10(]RUNgeKutta optimizer,RUN)是Ahmadianfa 等人提出的基于龍格庫塔法數學模型進行搜索和迭代的優化算法。RUN的核心思想基于龍格庫塔法的斜率計算方法,使用計算得出的斜率作為在搜索空間內進行搜索的邏輯,同時構建了一系列規則幫助種群進化迭代,形成了群智能優化算法。
2.1.1 核心搜索機制
RUN 優化算法使用四階龍格庫塔法(RK4)作為搜索框架,RK4的基本數學表示如下:
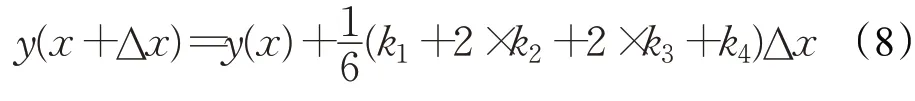
其中,權重因子k1、k2、k3和k4的數學表示如下:
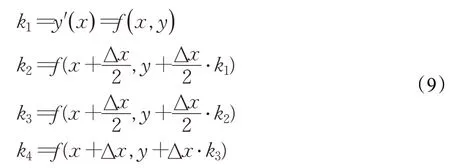
RUN算法中將種群中一個個體的位置x的兩個鄰居點x-Δx與x+Δx分別看作一輪迭代中該個體周圍的最優的位置和最差的位置,即xb和xw。因此RK4中的k1在RUN算法中表示如下:

為了強化探索的搜索能力并創造一定隨機性,上式在RUN中最終表示為:
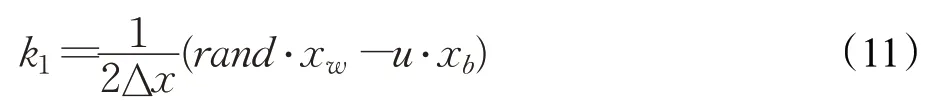
其中:
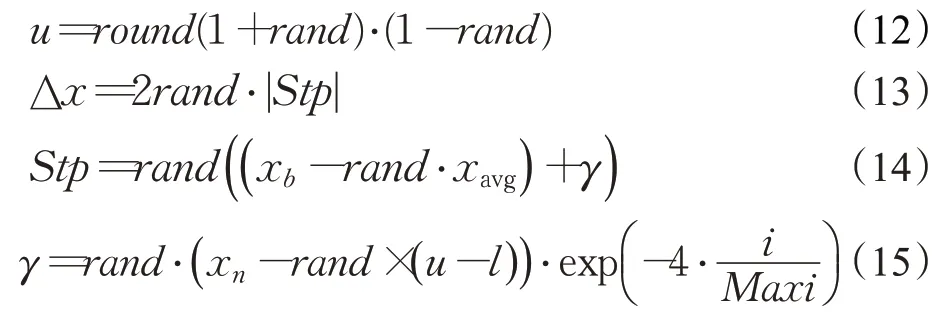
式中,Δx由步長參數Stp確定,步長參數Stp由種群最優位置xb和種群平均位置xavg的差分確定,參數γ由解的空間大小確定,rand表示[0,1]均勻分布的隨機數。由此計算出RK4中其他各項參數如下:
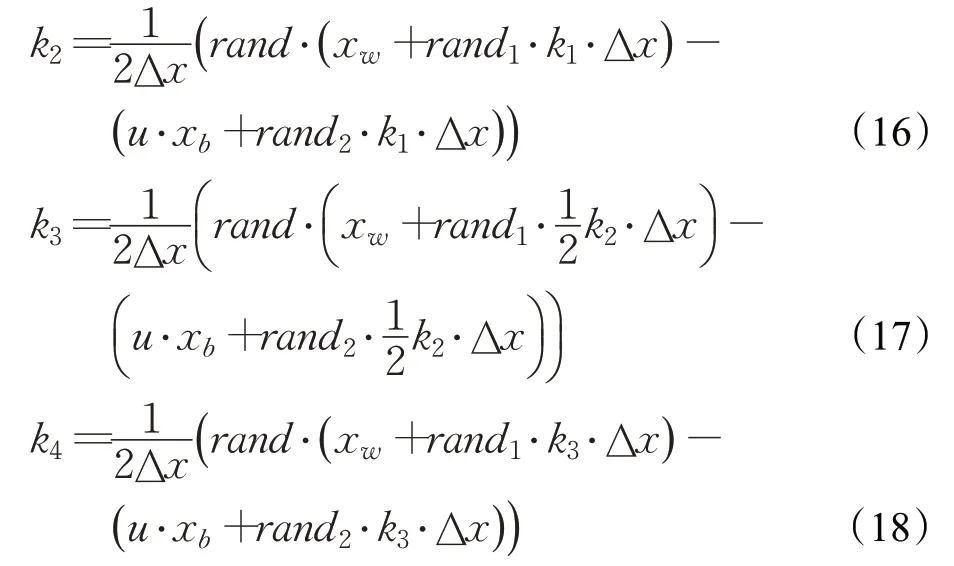
最終RUN核心搜索機制的數學表達式如下:

其中:

2.1.2 更新搜索結果
為了進一步平衡探索和開采,RUN 采用了如下的結構進行迭代間的結果更新:
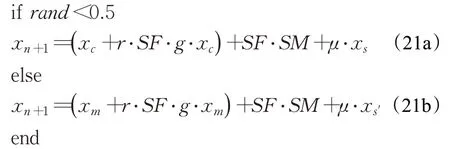
其中:
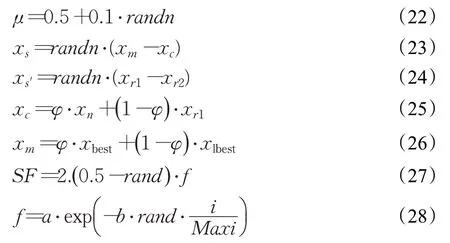
2.1.3 強化解的質量
在RUN算法中,強化解的質量機制(enhanced solution quality,ESQ)被應用于增強解的質量和跳出局部最優。其過程如下:

其中,r為取值為1,0,或-1的隨機數,其他參數的表示如下:

上述過程使用了大量的隨機成分以及位置平均值的計算,作為龍格庫塔算法基本移動后的機制,其一方面幫助成功尋優的個體強化其尋優方向獲得更優,另一方面為未成功尋優的個體提供擾動,幫助種群跳出局部最優。
2.2 改進的成敗歷史存檔機制
成功歷史存檔機制首次由Viktorin等人在基于成功歷史的自適應差分進化算法[11(]success-history based adaptive differential evolution,SHADE)中提出,其思想來源于參數自適應的差分進化算法[12]和差分進化算法本身的框架[13]。原始的成功歷史存檔機制用于存儲差分進化算法中的縮放因子和交叉概率兩個參數,其中只有使種群適應度得到更優值的參數才會被儲存,故稱為成功歷史存檔。同時,根據每輪迭代使用不同參數更新位置后的種群適應度值變化的程度賦予成功存檔中不同參數值對應的權重,最終將所有檔案中參數和權重加權平均,產生下一輪迭代使用的新參數。
上述文章中證明了成功歷史存檔機制能夠幫助算法具有更好的搜索精度和收斂效率,故本文中根據黏菌算法本身的特性和具體計算方法提出了一種改進的成敗歷史存檔機制。首先,將原始成功歷史存檔存儲參數信息的行為修改為存儲種群個體位置信息;其次,將原始成功歷史存檔擴展為成功失敗歷史存檔;最后,將種群適應度值的變化作為成功歷史存檔中每個位置信息被后續計算過程選取的概率值。
2.2.1 存儲位置信息的成功歷史存檔
由上文中黏菌算法的數學表達式可知,黏菌算法中所有的參數均具有自適應的屬性,且自適應方式各不相同,若繼續使用成功歷史存檔存儲黏菌算法的參數信息一定程度上會破壞黏菌算法的自適應能力。此外,黏菌算法的核心優勢在于如公式(5)所示的用來表示自然界中黏菌靜脈大小變化的權重計算過程,但若種群中沒有優質的個體位置信息或具有優質位置信息的個體較少的情況,權重計算過程會失效,最終導致黏菌算法的精度提升出現瓶頸。
因此,本文提出了一種存儲位置信息的成功歷史存檔S_Archive,即個體在搜索過程中若得到比自身當前適應度更好的適應度,則新的位置會被記錄在成功歷史存檔中。設置一個參數S_Archive_N用來限定成功歷史存檔的容量,若成功歷史存檔存儲的位置信息達到容量上限,則從存檔的起始位置依次更新存儲的位置信息。
2.2.2 成功失敗歷史存檔
原始的黏菌算法中,最基礎的位置移動方式如公式(1)所示,其中,XA和XB代表兩個從黏菌種群中隨機抽取的個體,因此公式(1)中(W·XA(t)-XB(t))部分并不能確定個體移動的方向是向更優位置移動還是向更差位置移動,加之取值可正可負的表示隨機步長的參數vb后,使得黏菌算法最基本的搜索方式隨機程度較大,缺乏一定的方向性。
因此,本文擴展了上述的成功歷史存檔機制,提出了一種存儲位置信息的成敗歷史存檔。構建失敗歷史存檔F_Archive,個體在搜索過程中若得到比自身當前適應度更差的適應度,則新的位置會被記錄在失敗歷史存檔中。構建成功歷史存檔和失敗存檔后,將原始黏菌算法公式(1)中XA和XB替換為XA_S和XB_F,即一個從成功歷史存檔中隨機選取的位置和一個從失敗歷史存檔中隨機選取的位置。公式(1)則改寫為:
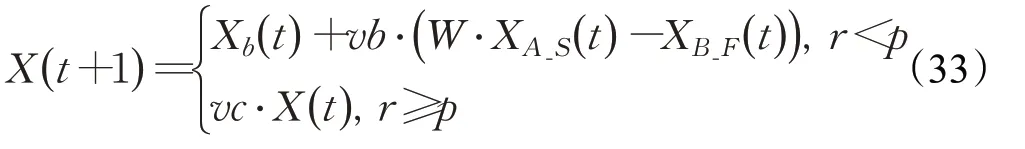
此時,若vb的值取到正數,黏菌個體的基本移動行為確定為從失敗歷史位置向成功歷史位置移動的方向;若vb的值取到負數,則基本移動可以視為具有一定程度的反向學習特征,擴大種群的搜索空間,保持種群的多樣性。
傳統的反向學習策略或其他新位置生成策略都需要計算新位置的適應度,增加了算法的復雜度,在目標函數復雜的現實問題中,該類策略運行的效率會大打折扣。上述成敗歷史存檔機制不同于反向學習等學習策略,無需增加種群個體位置適應度的計算過程,僅為更新的位置信息添加了“成功”或“失敗”的標簽,節約運算時間的同時,賦予種群個體移動時一定的方向,加快種群的收斂速度。
通過分析可以發現,高校自主招生與高考統一招生對人才的選拔與評價模式有所不同,有其自身明確的特征。如自主招生與高考招生的評價方面不同,自主招生是從德智體三方面評價學生的,更加全面化,而高考招生考察較為單一,只針對學生的“智”,即是學習成績進行考察。自主招生與高考招生選拔標準化不同,自主招生選拔人才更加尊重學生的個性發展與個性化差異,重視學科專長突出的學生,而高考招生考察多科目,從綜合成績評價學生。同時,自主招生注重學生的綜合素質與人格發展,而高考主要是從成績評價學生。
2.2.3 作為概率的適應度變化值
原始的成功歷史存檔機制中,將適應度值的變化量作為存檔中參數的權重,最后通過加權平均得到新的參數。文獻[14]指出,在存檔中使用普通算術平均會使最終結果收斂至一個很小的取值范圍內,由此提出了使用加權平均計算平均值,其中權重為種群適應度的變化值。此后,使用適應度變化值作為評價學習結果重要程度的機制被保留并使用于多種基于存檔的改進算法中。受此啟發,本文中同樣使用成功歷史存檔S_Archive保存個體在移動中適應度值的變化量,不同的是將該變化量作為該位置之后被選取的概率,即XA_S的選取過程不再服從均勻分布,而是服從不同適應度值變化量的分布,得到更大適應度值提升的位置更有可能被選取,得到較小適應度值提升的位置則被選取的可能性較小。該過程首先保證了所有位置并沒有通過任何運算進行改變,即保留了黏菌算法從種群中其他個體獲取信息的特點;其次使對種群適應度提升較大的成功位置更有機會引導其他種群個體;最后使用概率的方式使對種群適應度提升較小的個體依舊有機會被選取,保證了種群的多樣性,同時一定程度上避免了種群陷入局部最優。
上述概率值的機制僅使用在成功歷史存檔中,而不使用在失敗歷史存檔中。因為失敗歷史記錄的適應度值變得更差的變化量無助于確定未來更優的搜索方向,若從舊位置更新到新位置后適應度變差的值很大,將該變化值作為概率后,只能幫助個體從更差位置移動向較優位置,而個體從次優位置移動向更優位置才是算法不斷迭代的目的。
2.3 自定義的長短結合交流時機
本文采用并行計算-信息交流的機制將上述龍格庫塔算法與成敗歷史存檔機制改進的黏菌算法進行融合。經過大量實驗發現,頻繁的信息交流會嚴重損失兩算法各自的特性和按照迭代輪次積累的自適應參數的價值,時間間隔較長的信息交流則會出現某一算法始終優于另一算法的情況,融合過程變得冗余。
本文通過大量實驗比較分析,提出了一種自定義的長短時間間隔結合的交流時機,用來確定兩個種群什么時候交流,具體交流時機如圖1所示。
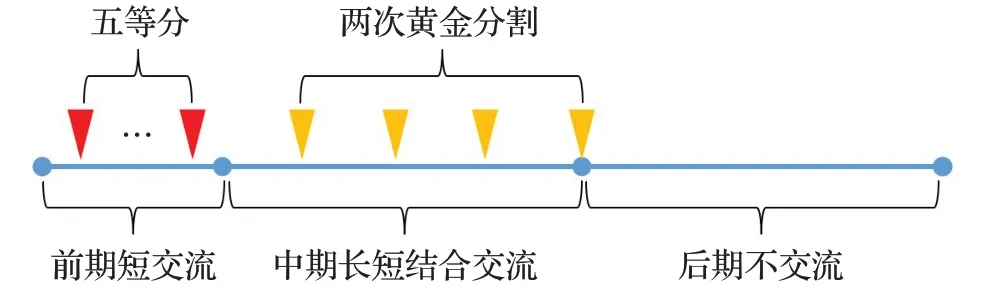
圖1 自定義的長短時間間隔結合的交流時機示意圖Fig.1 Customized long-short interval timing of communication
其中根據最大迭代輪次,前五分之一視為短期,將其均勻分割為五等份,每份結尾進行交流;中間五分之二視為中期,將其進行兩次黃金分割后,每份結尾進行交流;最后五分之二視為后期,不進行交流。以最大迭代次數500 為例,交流時機的取值則為[20,40,60,80,100,129,176,223,300]。
2.4 基于空間移動的信息交流機制
傳統的多種群信息交流多為最優位置或整個種群的直接替換。在龍格庫塔算法中,個體移動過程使用了種群位置的平均值、最優值等;在黏菌算法中,個體移動過程的權重使用了所有個體的位置和最優位置,若按傳統方法進行信息交流,一定程度上會損失兩算法各自的搜索特點和計算優勢。
因此,本文受Jafari 等人[15]融合粒子群算法和文化算法的工作啟發,提出了基于空間移動的信息交流機制。實驗中發現,龍格庫塔算法在高精度求解空間中表現優秀,但整體求解過程方差巨大,極易陷入局部最優,導致迭代的停滯;黏菌算法穩定性較好,但缺乏在高精度空間進一步提升的潛力。故本文中將龍格庫塔算法作為輔助算法,改進的黏菌算法作為主體算法,將龍格庫塔算法的最優位置和改進黏菌算法的成敗歷史檔案構成的空間作為信息交流的兩個主體。
首先,將龍格庫塔算法的種群規模設置為改進黏菌算法的一半,放大基本移動中種群受最優位置的影響,減弱種群受平均位置影響的不穩定性,同時減少雙種群融合的運算開銷。其次,將成敗歷史存檔作為參與信息交流的空間主體,有助于保留黏菌算法本身的位置信息和相關參數的有效性,移動后的成敗歷史存檔可以更好地引導黏菌算法進行位置更新。再次,劃分最優位置和位置空間之間的相對關系。最后,根據每種相對關系構建一系列基于空間移動的信息交流模式,實現種群間信息有效的交流。信息交流的過程如下所示:

當改進的黏菌算法最優適應度優于龍格庫塔算法時:若龍格庫塔算法的最優位置處于黏菌算法目前的種群空間中,將龍格庫塔算法最優位置的值賦予失敗歷史存檔,加速黏菌算法向更優空間的移動;若龍格庫塔算法的最優位置不處于黏菌算法目前的種群空間中,說明龍格庫塔算法目前的最優位置信息質量較差,將其替換為黏菌算法的最優位置。當龍格庫塔算法最優適應度優于改進的黏菌算法時:若龍格庫塔算法的最優位置處于黏菌算法目前的種群空間中,說明當前搜索范圍有效但不夠精確,將成敗歷史存檔同時向龍格庫塔算法最優位置移動;若龍格庫塔算法的最優位置不處于黏菌算法目前的種群空間中,說明成敗歷史存檔已完全落后于龍格庫塔算法,將成功歷史存檔降級為失敗歷史存檔,同時將龍格庫塔算法最優位置賦予黏菌算法,引導主算法進行躍進。
2.5 成敗歷史存檔的融合龍格庫塔-黏菌算法
本文提出了成敗歷史存檔的融合龍格庫塔-黏菌算法(success fail history based hybrid RUNgeKutta optimizer and slime mould algorithm,SFHRUN-SMA)。首先,提出了改進的成敗歷史機制,設置成功失敗歷史存檔存儲位置信息,適應度的變化量作為成功存檔中的概率,將該機制加入原始黏菌算法,有效地將黏菌算法的基礎移動方向調整為“成功”到“失敗”,加速黏菌算法的啟動;其次,引入龍格庫塔算法作為輔助算法,將其種群規模設置為黏菌算法的一半,使用并經計算-信息交流的模式將其和改進后的黏菌算法進行融合;再次,自定義了兩種群交流的時機,實現了兩算法各自運算特點的保留;最后,基于空間移動,提出了一系列按不同情況進行不同行為的信息交流方式,使得作為輔助算法的半種群規模龍格庫塔算法調整速度更快,同時間接的交流調整方式使得作為主算法的全種群規模黏菌算法的調整更為精準和謹慎。
通過文獻和實驗可知,黏菌算法最大的優勢是其穩定性,但其隨機程度較大的勘探階段移動方式和較為簡單的開采階段移動方式導致了其啟動較慢和后期求解精度不足的缺陷。改進的成敗歷史存檔機制可以幫助黏菌算法在前期的勘探中更具方向性。龍格庫塔算法的輔助可以幫助黏菌算法在后期的開采中更具潛力,同時兩算法融合后,黏菌算法穩定的表現可以引導龍格庫塔算法規避陷入不穩定的波動中,龍格庫塔算法高精度的求解潛力可以引導黏菌算法更加精細地獲得最優解。分別基于群智能技術和數學方法設計的兩算法相輔相成,融合后可以成為既適合大規模低精度問題又適合小規模高精度問題的綜合算法。此外,改進的成敗歷史存檔可以作為兩算法融合后交流的橋梁,規避傳統交流方法導致的多種群信息部分損失的缺陷,同時更加高效地按照具體情況對不同種群的信息進行調整實現了多種策略間有機地結合。
在黏菌算法框架中,轉換概率可以使個體小概率地進行自身位置的重置;在龍格庫塔算法框架中,強化解的質量機制可以為未成功尋優個體提供擾動;在改進的成敗歷史存檔機制中,作為概率的適應度變化值保證了個體小概率偏離當前局部最優方向的可能。故本文算法在局部最優跳出問題上具有一定的對策,且相較于傳統的多種分布隨機擾動的方法,本文算法局部最優跳出方法更加與算法本身、改進機制本身相匹配,所需的適應度函數計算計算次數更少。綜上所述,融合了兩算法各自的計算優勢,同時彌補了兩算法存在的缺陷,使算法的求解精度和魯棒性得到提升。
2.6 改進算法的步驟
SFHRUN-SMA算法的流程圖如圖2所示。
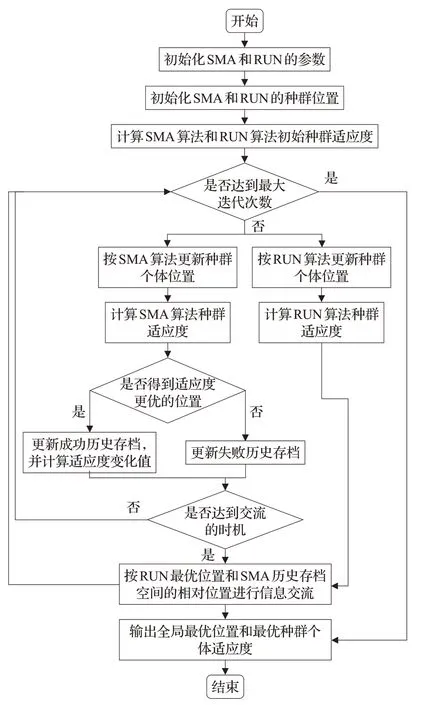
圖2 SFHRUN-SMA算法流程圖Fig.2 Flow chart of SFHRUN-SMA
2.7 時間復雜度分析
假設種群規模為N,搜索空間維度為D,最大迭代次數為T,原始SMA 算法的時間復雜度主要來源于初始化、適應度計算和位置更新,其時間復雜度為:O(N)+O(N·T)+O(N·D·T)。原始RUN 算法的時間復雜度與上式相同。SFHRUN-SMA算法主要由成敗歷史存檔機制和融合龍格庫塔算法兩個改進策略組成,由于作為輔助算法的龍格庫塔算法在前述中設置為黏菌算法種群規模的一半,則本算法全種群初始化過程的時間復雜度為O(N+0.5N)。同時,成敗歷史存檔機制并不需要增加個體適應度計算的過程,故計算個體適應度的時間復雜度為O( (N+0.5N)·T)。在位置更新過程中,按照作為概率的適應度值變化量選取個體位置的過程需要對成敗存檔中個體進行排序,并隨機選取一個位置參與計算,該過程時間復雜度為O( 0.5N·lg( 0.5N)·T)。綜上所述,SFHRUN-SMA 的時間復雜度為:O(N·(1.5+(1.5+0.5 lg( 0.5N)+1.5D)·T))。
在維度更高、適應度函數計算更為復雜的實際工程優化問題中,本文算法相較于傳統反向學習改進的算法和使用貪婪策略的其他算法具有更少的適應度函數計算次數,整體的時間復雜度與其相當甚至更低,因此在實際的工程應用問題中是可行的。
3 仿真實驗及結果分析
實驗環境為Windows10,64 位操作系統,CPU 為Inter Core i7-6700HQ,主頻2.6 GHz,內存8 GB,算法基于MATLAB2020b編寫。
實驗1為了充分驗證本文所提出的SFHRUNSMA 在求解函數優化問題時的求解精度和魯棒性,將SFHRUN-SMA 算法與其他算法在CEC2017 測試函數上進行求解,并進行實驗結果的對比。對比用算法包括最新的改進黏菌算法AFSMA[6]、原始的黏菌算法SMA[1]、同一科研團隊提出的哈里斯鷹算法HHO[16]、近幾年表現優秀的正余弦算法SCA[17]和經典的鯨魚優化算法WOA[9]。
為保證每種算法對比時的公平性,實驗中種群規模設置為30,最大迭代次數設置為500,并獨立運行30 次計算得出統計結果。對比用算法參數設置均來源于對應文獻設置,如表1 所示。其中SFHRUN-SMA 算法的成敗歷史存檔規模分別設置為種群規模的一半,即15。

表1 主要參數Table 1 Main parameters
本文選用了表2 所列示的29 個CEC2017 基準測試函數,其類型包含單峰(unimodal,UM)、多峰(multimodal,MM)、混合(hybrid,H)及復合(composition,C),維度可選用10、30、50、100,此處實驗使用標準維度30維,02號函數由于高維的不穩定性習慣上不使用。
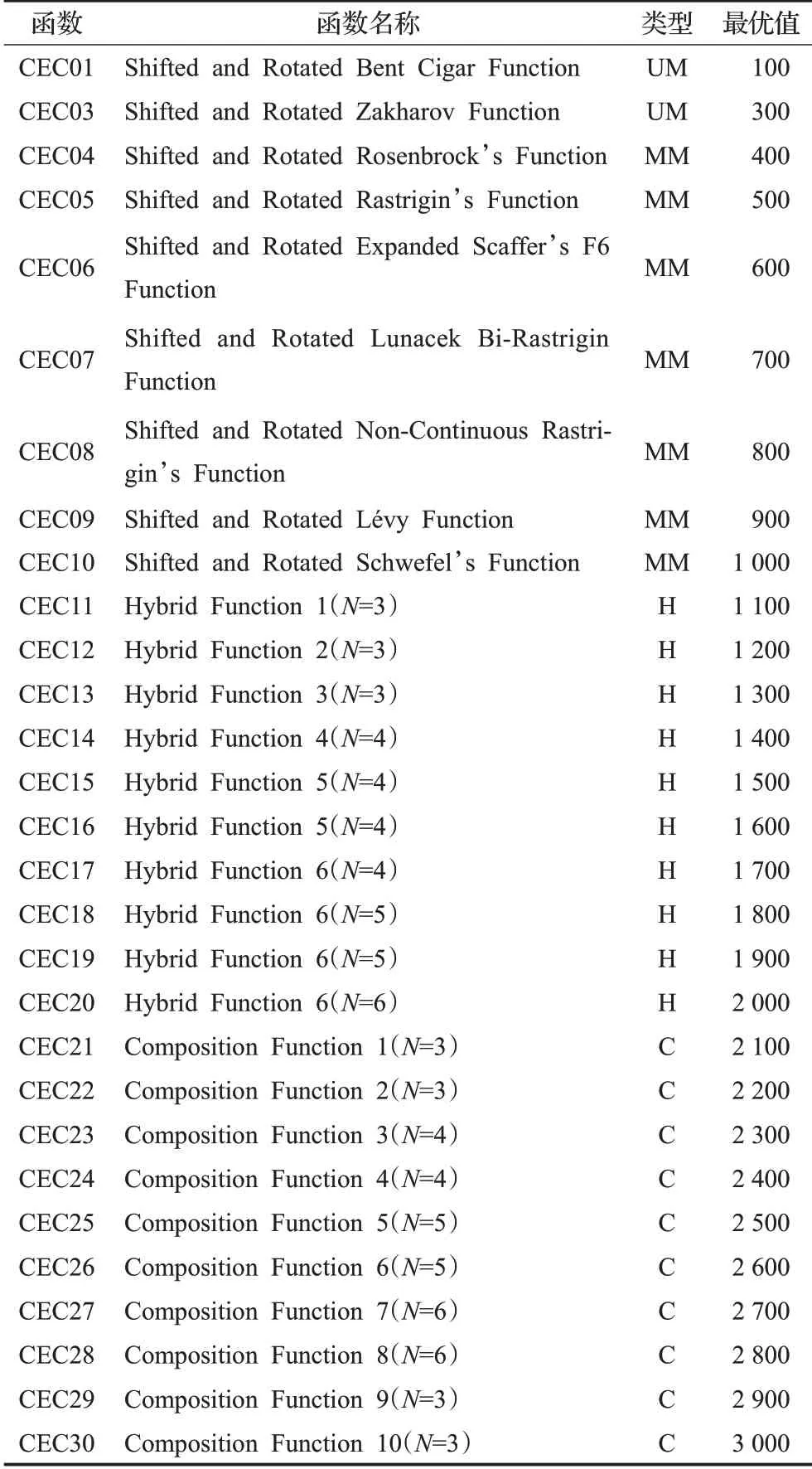
表2 CEC2017函數Table 2 CEC2017 function
表3為SFHRUN-SMA與第一部分算法進行對比的實驗結果。總體上看,SFHRUN-SMA在29個CEC2017基準測試函數中在23個函數上平均求解精度的表現優于其他所有對比算法,另外6 個測試函數上均由原始SMA算法取得更優,但在此基礎上SFHRUN-SMA算法的求解精度均高于改進算法AFSMA,針對更復雜的、更接近現實的問題SFHRUN-SMA 具有更好的求解精度和收斂速度。
為了進一步驗證改進算法的有效性,需要對群智能算法結果進行統計檢驗[18],本文選擇Wilcoxon 秩和檢驗進行統計檢驗,顯著性水平設置為5%,表3展示了SFHRUN-SMA 算法與其他五種算法的檢驗結果,每列最后一個符號為SFHRUN-SMA 分別與五種算法成對比較結果的勝負標記,其中“+”代表優于比較算法,“-”代表劣于比較算法,最后一行為優于和劣于的函數數量合計。表3 結果表明SFHRUN-SMA 算法對于每個CEC2017 基準測試函數的求解結果對于SCA、HHO、WOA三個對比算法分布完全不同,可以證明SFHRUNSMA算法的求解精度明顯優于該三種算法。相較于改進算法AFSMA,SFHRUN-SMA算法在三分之二的測試函數上分布不同,并且整體求解精度優于AFSMA,可以證明改進策略對算法求解精度的提升有顯著的影響。相較于原始SMA,接近半數的測試函數結果分布無法證明有明顯差異,分析可知SFHRUN-SMA 算法盡可能地保留了原始SMA 算法動態權重、自適應轉換概率等優點,故分布并未出現明顯差異,但同樣的在求解精度上有較大提升,可以證明SFHRUN-SMA在求解CEC2017基準測試函數上表現更優。
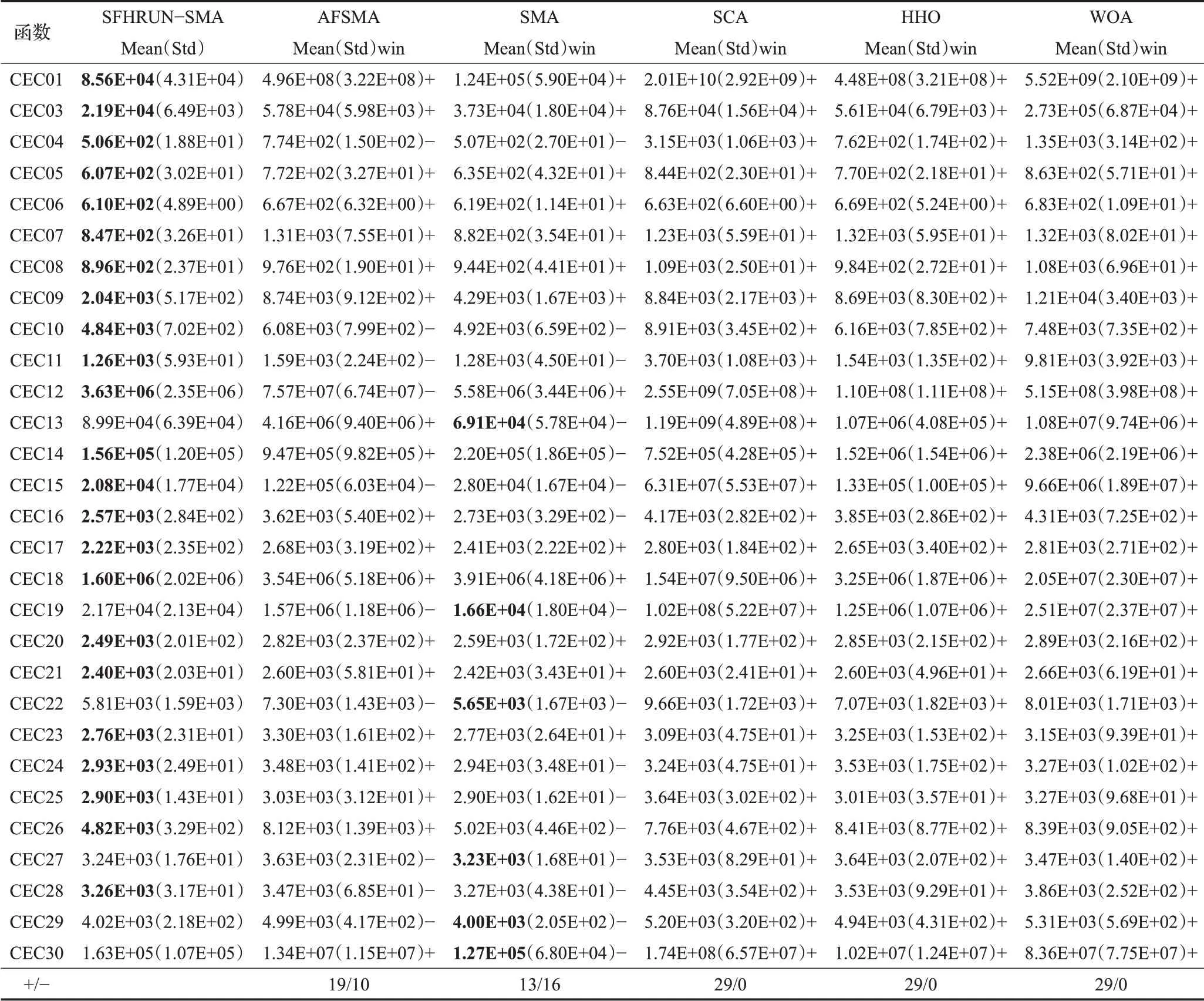
表3 CEC2017測試函數和Wilcoxon秩和檢驗的結果對比Table 3 Comparison of CEC2017 function results and Wilcoxon’s rank-sumtest
為了形象地觀察改進算法的收斂性能,對SFHRUNSMA與AFSMA、SMA、SCA、HHO、WOA進行收斂性分析。圖3給出部分基準測試函數的收斂曲線圖,各算法曲線圖例與圖3(f)一致。為了便于觀察高精度的曲線收斂情況,縱坐標取以10 為底的對數繪制所有曲線圖像。觀察可得,SFHRUN-SMA 算法在迭代前中期展現出和原始SMA 類似但效果更好的尋優線路,說明了成敗歷史存檔機制在保留了SMA原本的特點和優點的基礎上加快了SMA 算法的收斂速度。同時,在迭代中后期得益于RUN 算法的引導SFHRUN-SMA 算法可以執行更為精細化的搜索,保證了整體算法搜索到更優解的潛力。直觀來看,本文改進策略的組合對算法的收斂速度和局部最優的跳出有積極影響。
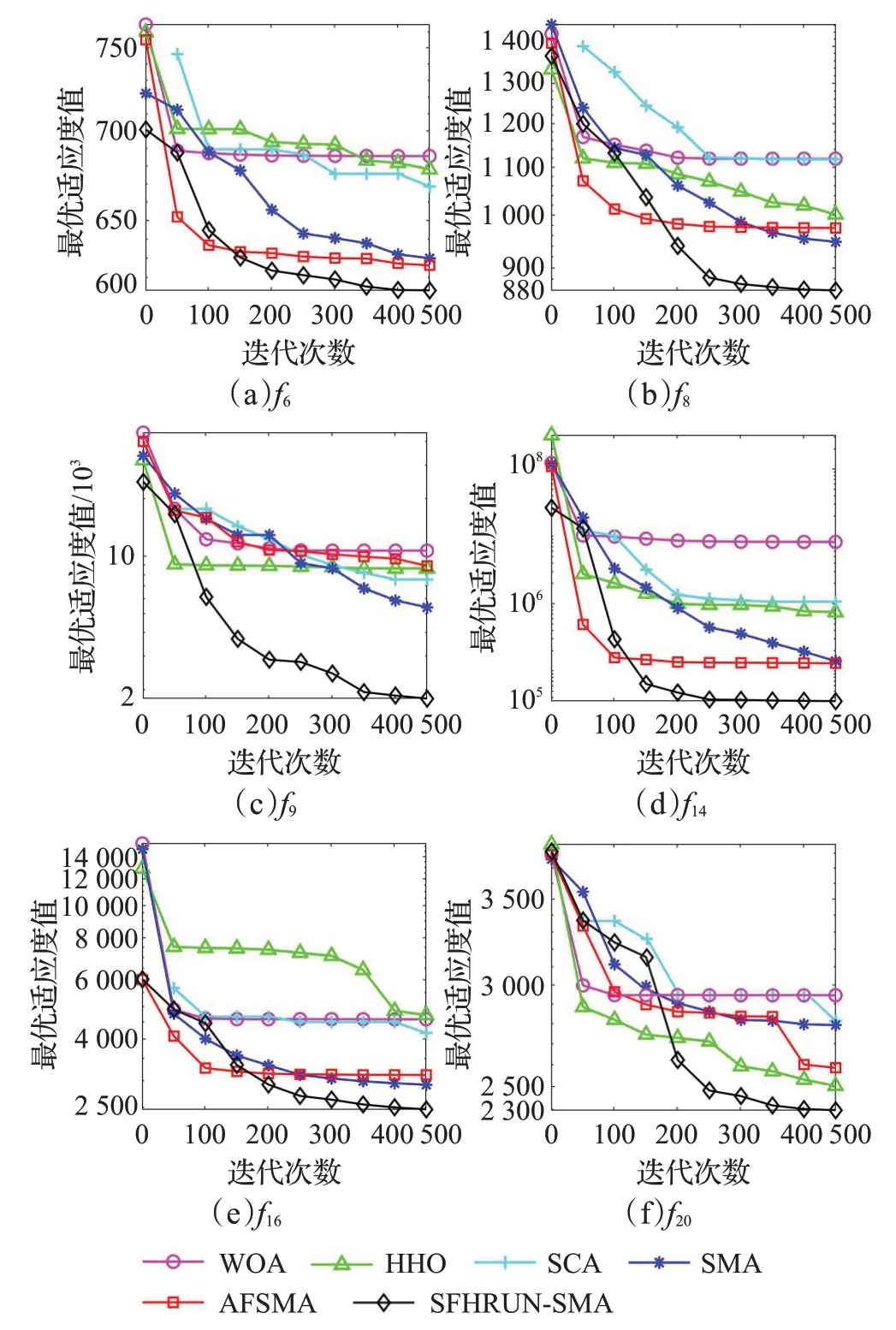
圖3 CEC2017測試函數收斂曲線Fig.3 CEC2017 Function average convergence curve
為了綜合地評估SFHRUN-SMA 與其他算法對比的競爭性,使用平均絕對誤差MAE 對上述算法進行排序[19]。表4 展示了所有算法基于29 個CEC2017 基準測試函數的MAE。MAE計算公式如下:
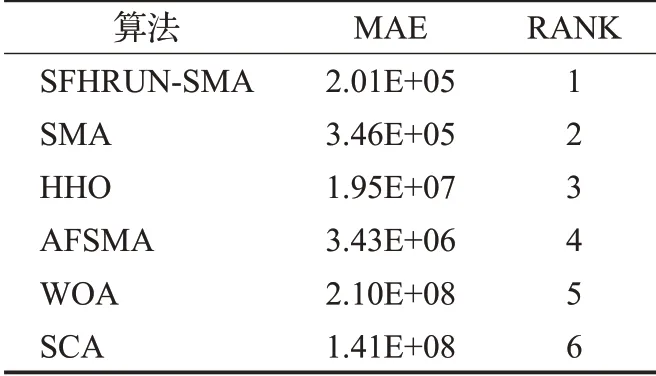
表4 MAE算法排名Table 4 MAE algorithm ranking
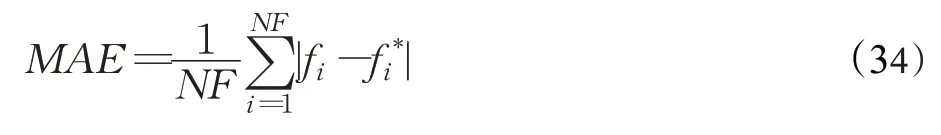
其中,NF為函數個數,fi為算法在第i個函數上求解結果的平均值,fi*為第i個函數的理論最優值。
由表5可知,SFHRUN-SMA排名第一,原始算法SMA排名第二。并且SFHRUN-SMA 的MAE 值明顯小于其他算法,更加綜合地表明了該算法的有效性和魯棒性。
實驗2 隨著測試函數搜索維度的升高,最優值的求解困難程度也隨之升高,求解高維問題有助于讓基準測試函數的求解難度更加接近于現實中復雜的問題,以此可以間接檢驗算法應用于現實問題中的表現。使用CEC2017基準測試函數,搜索維度設置為50和100兩個高維進行實驗,表5展示了實驗結果。由表5可知,當維數上升至50維后,SFHRUN-SMA在22個測試函數上求解精度占優,改進算法AFSMA在4個測試函數上占優,原始SMA 在3 個測試函數上占優;當維數上升至CEC2017 測試函數設置的最大維數時,SFHRUN-SMA在22個測試函數上占優,改進算法AFSMA在4個測試函數上占優,原始算法SMA 在2 個測試函數上占優,HHO算法在1個測試函數上占優。可以說明,在高維環境下SFHRUN-SMA 的改進策略依舊有效,從成敗歷史存檔和RUN算法的引導大大加速了高維空間中算法的啟動速度,從而更快地收縮搜索空間,為精細搜索創造先機,相對于對比算法有著更強的穩定性和魯棒性。
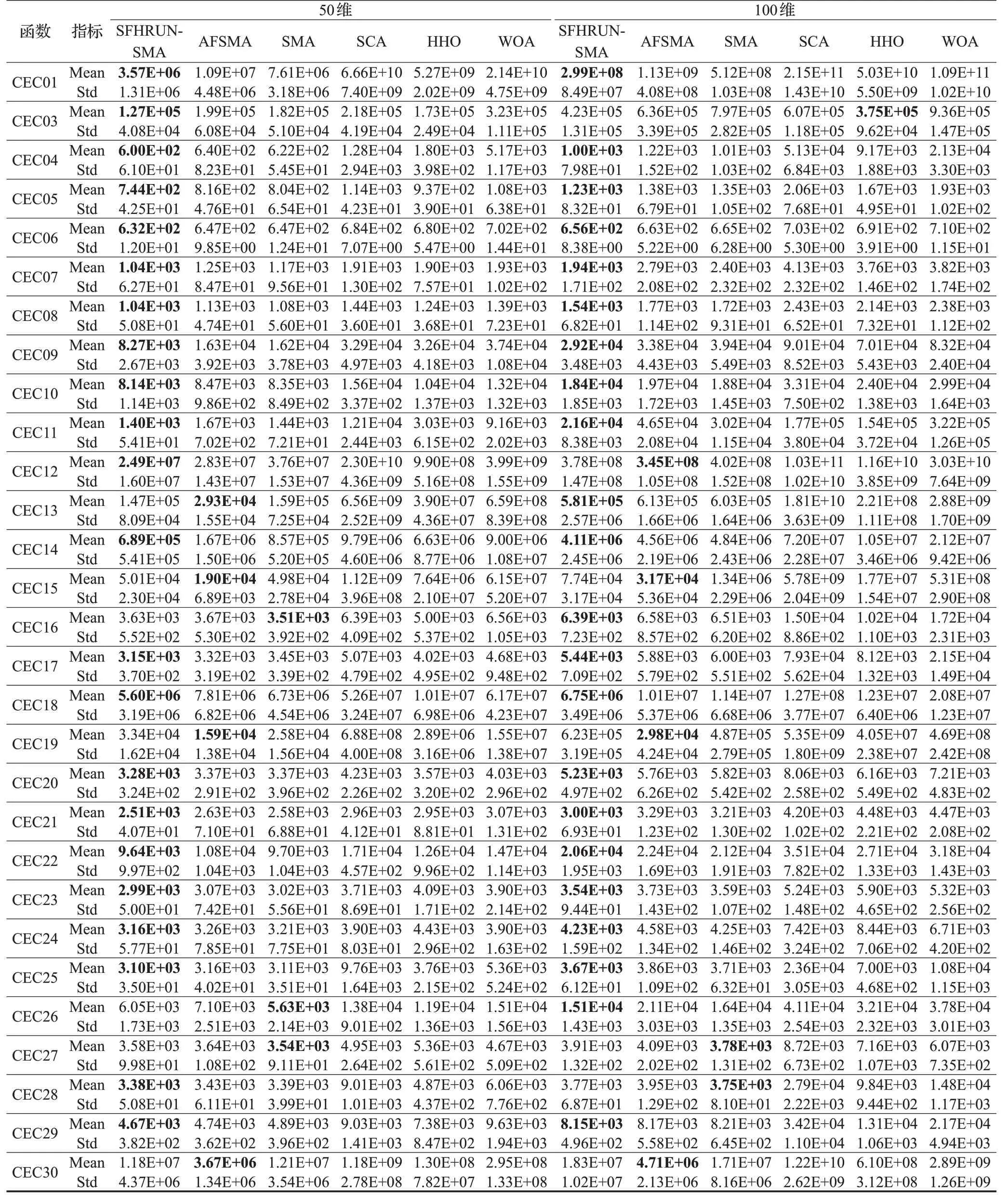
表5 高維CEC2017測試函數的結果對比Table 5 Comparison of high dimension CEC2017 test function results
實驗3 為了驗證SFHRUN-SMA 算法改進的有效性,需要對比分析不完全算法[20],使用CEC2017基準測試函數進行SFHRUN-SMA 與其不完全算法SFHSMA 與RUN進行對比,表6展示了更加綜合和直觀的MAE排名結果。由表6可見,SFHRUN-SMA算法在所有維度上均取得第1,且在100維度上優勢更加明顯,因此SFHRUNSMA在求解問題普遍的適用性上強于兩個不完全算法。

表6 MAE不完全算法排名Table 6 MAE incomplete algorithm ranking
SFHSMA在較低維度最終的求解效果與原始SMA相似,分析可知單純的成敗歷史存檔并不能為種群帶來不同于原始種群位置信息的新知識,固表現與原始SMA相似。同時,SFHSMA 在100 維度求解精度高于RUN,由此可知成敗歷史存檔機制加強了SMA算法在更高維度中的穩定性。RUN 算法在低維的求解精度較高,但在高維缺乏穩定性,將其與SFHSMA 融合構成本文算法后,SFHRUN-SMA 在三類維度中表現均超過獨立的SFHSMA 和RUN。一方面說明作為輔助算法的RUN成功地對SFHSMA 起到了引導作用,幫助其在各個維度取得更優結果,另一方面說明SFHSMA 幫助RUN 規避了求解不穩定的缺陷。此外,SFHRUN-SMA的MAE結果與排名第2的算法差距較大,側面說明了本文構建的兩種群交流機制在實現交流的基礎上對整體算法精度的提升也有一定貢獻。綜上,兩種改進策略及相關交流策略的結合有利于本文算法有效性和魯棒性的提升。
4 結束語
針對SMA 算法存在的不足,本文使用了改進的成敗歷史存檔機制和融合龍格庫塔算法兩個策略對原始SMA進行改進,提出了成敗歷史存檔的融合龍格庫塔-黏菌算法SFHRUN-SMA,并將該算法應用于CEC2017測試函數進行求解。改進的成敗歷史存檔機制通過對成功失敗位置信息的存儲并將適應度的變化值作為概率賦予每個位置信息,提高了原始黏菌算法逼近最優解的啟動速度,對不同特點的測試函數具有普遍適用性,且該機制具有一定的可遷移性;迭代過程中,將種群規模為SMA一半的RUN算法作為輔助算法,并定制了一系列兩種群間交流的機制,保留兩算法優勢的同時彌補
兩算法的固有缺陷,利用RUN 更強的深度求解潛力引導SMA,利用SMA更穩定的求解路徑平衡RUN多次重復求解的方差,在保證種群多樣性的前提下提高算法求解精度。此外,為了多維度綜合地評估改進算法的有效性和同其他算法相比的競爭力,本文使用了MAE、Wilcoxon秩和檢驗等指標,同時對CEC2017基準測試函數的高維進行探索和測試,多角度地證明了本文所提出算法的求解精度和魯棒性。
在未來的研究中,希望對黏菌算法進行進一步的改進和測試,提高該算法針對更多樣、更復雜問題的適用性,并將其應用于金融科技和數據挖掘等領域,進一步落實群智能算法的實際應用。
猜你喜歡
四川勞動保障(2021年9期)2022-01-18 05:11:08
文苑(2018年21期)2018-11-09 01:23:06
中國衛生(2016年9期)2016-11-12 13:28:08
全體育(2016年4期)2016-11-02 18:57:28
中國衛生(2015年9期)2015-11-10 03:11:12
科普童話·百科探秘(2015年6期)2015-10-13 07:21:18
科普童話·百科探秘(2015年9期)2015-09-22 07:36:52
科普童話·百科探秘(2015年8期)2015-08-14 07:13:06
科普童話·百科探秘(2015年5期)2015-05-26 07:28:14
科普童話·百科探秘(2015年4期)2015-05-14 07:25:32
