仿真圖像作為模板的遙感影像小目標檢測方法
2022-09-06 11:08:36曹亞明
計算機工程與應用 2022年17期
曹亞明,肖 奇,楊 震
1.中國科學院 國家空間科學中心,北京 100190
2.中國科學院大學,北京 100049
隨著航天航空技術的突飛猛進,遙感技術也得到了快速成長,遙感技術在許多領域中都發揮著巨大作用,在交通、環境、農業等領域中遙感技術都得到了廣泛的應用。遙感技術的發展使得遙感影像的精度越來越高,遙感影像視角較高,包含豐富的位置、特征等信息[1-2]。因此,遙感影像中的目標檢測受到了越來越多的關注。傳統的遙感影像目標檢測任務是通過基于人工篩選特征、滑動窗口、分類器的方法來完成的[3-5]。深度學習在眾多計算機視覺任務中取得了很好的效果之后,基于深度學習的方法已經被廣泛地應用于目標檢測任務中,并且基于深度學習的目標檢測模型準確率也遠遠高于基于人工篩選特征的方法[6-7]。然而,由于遙感影像中的目標具有視角特殊、尺寸小、特征少、背景復雜、方向多變以及易受云霧遮擋等問題,導致將常規目標檢測任務中表現優秀的目標檢測模型,直接應用于遙感影像目標檢測時效果較差,存在大量漏檢、誤檢[8]。與此同時,成像仿真技術越發成熟[9],很多3D 建模軟件在工業、建筑等領域中的使用也變得越來越頻繁。虛擬圖像,尤其是將仿真圖像應用于深度神經網絡訓練與學習的應用變得越來越多。在成像仿真技術的支持下,可以得到小目標的更多特征,在與深度學習結合的過程中,更多的特征可以使得神經網絡的結果得到提升。成像仿真的結果相當于人類的常識,加入到神經網絡中后,會使得神經網絡的訓練更快收斂、提高效率,并且加入仿真圖像以后,可以增強檢測結果的可解釋性。因此,本文提出一種基于仿真圖像的深度學習方法——TMSI-Net(template matching based on simulation image),利用模板匹配方法將仿真圖像所包含的特征與神經網絡提取的特征進行融合,來解決遙感影像小目標檢測問題。成像仿真技術生成的仿真圖像包含了遙感小目標的更多特征,如幾何形狀、材質等。在與深度學習結合之后,更多的特征可以提升神經網絡檢測遙感影像小目標的準確率。用大型遙感數據集VEDAI[10]以及加云霧之后的VEDAI-Cloud 對模型進行了測試。結果表明將基于仿真圖像的模板匹配方法應用于深度學習之后,對于遙感影像小目標取得了較好的檢測效果,尤其是針對受云霧等天氣干擾的小目標。
遙感影像小目標檢測任務是分析和理解遙感影像所面臨的基本問題。該問題在很多的民用、軍用場景中頻繁出現。由于遙感影像中的目標尺寸小,受云霧遮擋的影響大,角度特殊,所以該問題一直都很難被很好地解決。本文的實驗結果表明利用待檢測目標的仿真圖像作為模板,以模板匹配的方式加入到神經網絡之后,可以很好地提高網絡在遙感影像中的目標檢測準確率。
目前為止,深度神經網絡是用來解決遙感影像目標檢測任務最常用的方法。如何設計網絡結構,以便使得網絡能夠提取或學習到足夠多的小目標特征用于檢測,是深度神經網絡方法的關鍵。針對遙感目標與常規目標的視角差異,許多研究者通過修改網絡結構來適應遙感影像小目標檢測任務。本文提出的TMSI-Net通過改變網絡深度、將更淺層的特征圖用于檢測等改動,加快了網絡訓練過程,并且可以去除掉對于小目標檢測沒有意義的冗余信息。淺層的特征圖用于遙感影像目標檢測可以提供更多的小目標特征和信息,如位置、幾何等[11-12]。有的研究者通過改變RPN網絡輸入的卷積層、調整RPN網絡中的錨點尺寸來使得Faster R-CNN網絡更好地適應遙感目標檢測[6]。由此可以得出,改變網絡結構已經成為一種將深度學習應用于遙感影像數據集的基本方法。
同時,也有很多方法通過對遙感數據集進行預處理,去解決遙感影像小目標檢測困難的問題。如果直接將高分辨率的遙感影像數據用于目標檢測,確實會包含更多的目標特征,但是高分辨率的遙感影像數據通常尺寸都很大,對于網絡的訓練異常耗時,并且也會使得訓練時每批次的數據有限,影響網絡的訓練效果[13]。因此,有很多人考慮將大尺度的遙感數據集進行剪切和分割,然后再將剪切之后的圖片塊用于網絡的訓練與推理,但是這種方法會導致另一個問題的出現,如何能夠使得目標在切割的過程中不被破壞[14]。有人提出了一種方法,將高分辨率遙感數據進行下采樣到合適網絡訓練的尺寸,然后再用其進行網絡的訓練與推理[10]。這種方法的不足之處在于下采樣之后的圖像沒有足夠多的小目標特征可以用于檢測。本文提出的通過將仿真圖像以模板方式加入到神經網絡中的方法,可以解決遙感影像數據集中缺乏小目標特征用于檢測的問題。表現優異的實驗結果也可以證明仿真圖像的加入確實可以提供更多小目標特征與信息,提高網絡檢測結果。從本文的實驗結果中,也可以看出云霧的遮擋對于遙感影像小目標檢測有很大的干擾,而加入仿真圖像之后,可以起到很好的抗干擾作用。本文提出的加入仿真圖像的方法,也為神經網絡在應用于某些特征學習受限的場景中時,提供了一種新的思路。將知識與常識以模板的方式加入到神經網絡中可以提高網絡的表現,并且能增強網絡的可解釋性。
1 算法概述
1.1 TMSI-Net網絡結構
TMSI-Net結構如圖1所示。TMSI-Net的主干網絡為去掉最后一個殘差模塊的Darknet-53,共53 個卷積層,包含5 個殘差模塊,每個殘差模塊包含多個殘差單元。Conv 表示神經網絡中的一個學習單元,具體為一個卷積層、一個批歸一化(batch normalization)層和一個池化層。池化層是通過改變卷積核的步長來實現的。每個殘差模塊包含不同數量的殘差單元,具體數字在圖1 中進行了標注。Concat 操作為指定兩個向量的某一維度進行拼接,而其他維度固定。
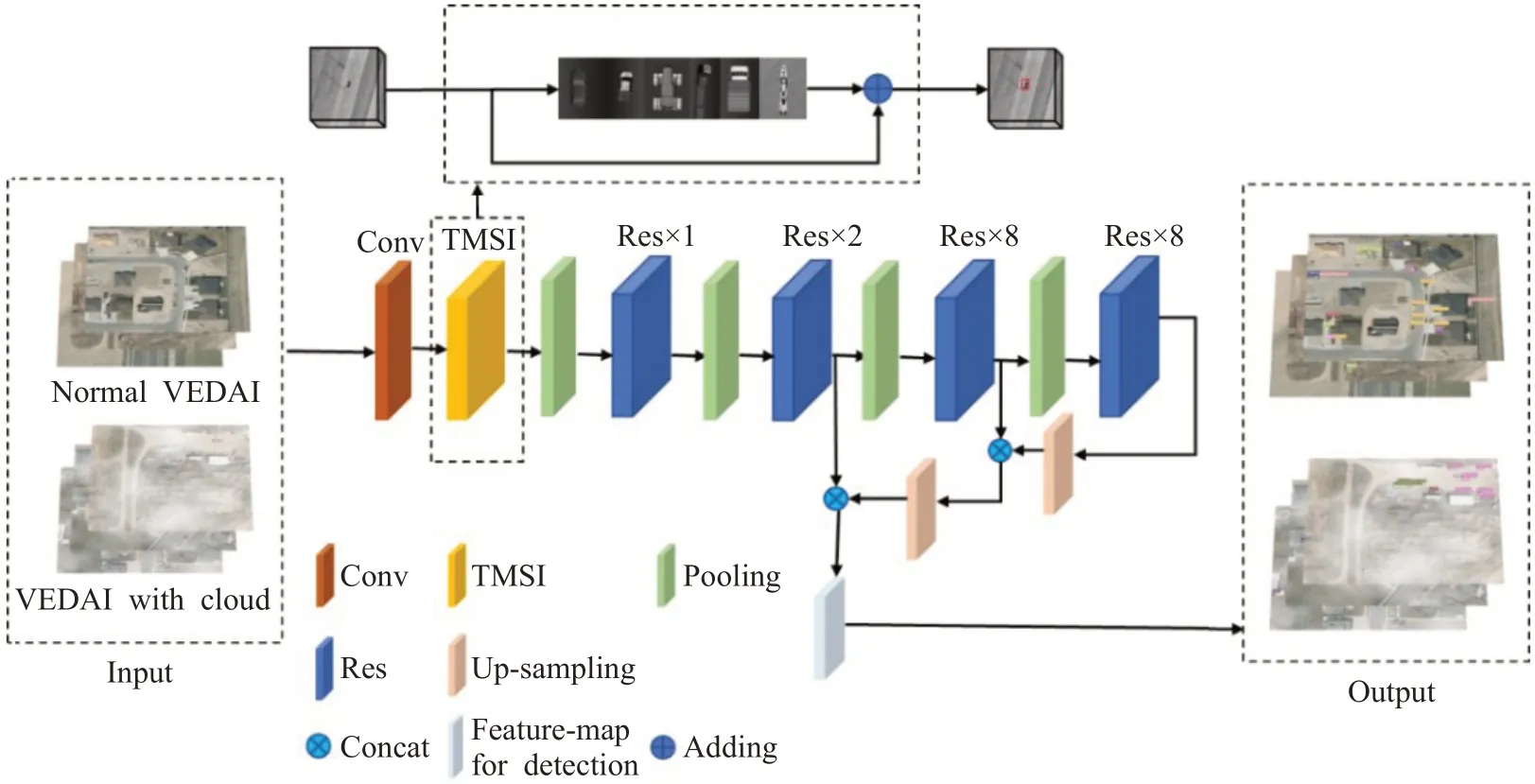
圖1 TMSI-NetFig.1 TMSI-Net
通過將TMSI-Net 和其他模型分別在VEDAI、加云霧遮擋作為干擾的VEDAI 數據集上進行測試,來驗證TMSI 算法的有效性。在實驗過程中,兩個數據集都按照5∶1的比例將圖像隨機地分為訓練集、驗證集。
1.2 仿真圖像與數據集
仿真圖像是通過成像仿真技術生成的,而仿真成像技術是基于數學或物理方法來構建全鏈路成像模型,最終由模型生成圖像的方法。構建成像仿真系統的第一步是搭建成像仿真框架[15]。全鏈路的成像仿真框架從太陽直射、天空漫射開始,目標經過材質劃分、并通過貼圖的方式來體現不同材質的反射特性。材質反射后的光照強度再經過大氣傳輸模型,即大氣要素計算,最后進入相機成像模塊。相機成像模塊主要負責將成像前來到相機模塊的光照強度根據一定計算規則轉化為相應的電信號,然后經過信號處理模塊,最終形成可見光仿真圖像,整個成像仿真系統的閉環鏈路就此搭建完成,全鏈路成像仿真框架如圖2所示。
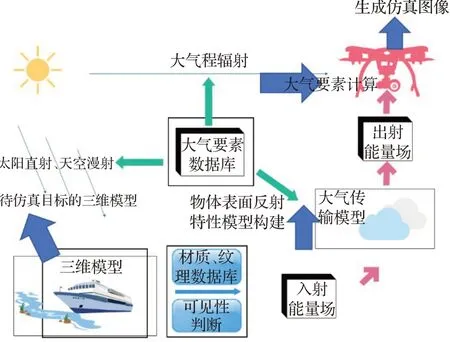
圖2 全鏈路成像仿真框架Fig.2 Full link imaging simulation framework
TMSI 算法完成了仿真圖像與神經網絡特征圖的匹配,并且將匹配過程中得到的有效信息加入到原來的特征圖中。在TMSI 算法過程中用到的仿真圖像如圖3所示。在生成仿真圖像的過程中,考慮只對數據集中的6 個類別進行仿真,分別是船(boat)、轎車(car)、皮卡(pickup)、拖拉機(tractor)、卡車(truck)以及貨車(van)。仿真圖像的顏色和尺寸也進行了適應性的修改。首先,根據數據集中待檢測目標的大小對仿真圖像的尺寸進行調整。VEDAI數據集中一共有9個類別,分別是:飛機、船、小轎車、卡車、拖拉機、露營車、貨車、皮卡和其他類別。在VEDAI數據集中平均每幅圖像包含5.5 個車輛,大概占據了一幅圖像總像素的0.7%。在實驗過程中所使用的VEDAI圖像的尺寸為512×512,經過簡單的計算,可以得到在圖像中的每個目標所占據的像素大概為20×20。因此,為了更好地匹配特征圖中的目標,在尺度上將生成的仿真圖像尺寸調整為30×30。為了適應俯拍所得到的遙感影像中的目標角度多樣性,對生成的小目標仿真圖像進行平面旋轉。仿真圖像數量越多,則在匹配過程中的計算消耗也會越大。因此,按照類別分別從生成的所有仿真圖像中挑選出6 張仿真圖,然后分別旋轉4等分角度(90°,180°,270°)來盡可能地捕捉遙感影像中角度多樣的小目標,最后得到數量為24的仿真模板庫。遙感影像中的目標背景通常比較復雜并且多變,例如,在VEDAI數據集中的很多船是在陸地上而不是常見的以水為背景。所以在仿真圖像的生成過程中不會添加特定的背景,如在生成船的仿真圖像時,不會添加水面等作為目標背景,轎車等交通工具也沒有特定的道路作為背景,如圖3 所示,仿真圖像的主體即為待檢測目標。為了盡可能地消除匹配時同一類別目標的類內顏色差異性,同時考慮到與仿真圖像進行匹配的是特征圖,不是輸入圖,所以在將所有的仿真圖像尺寸進行調整之后,將它們全部轉為灰度圖。在仿真圖像的生成過程中,通過調整待檢測目標三維模型的水平角與俯仰角,可以得到如圖3 所示的多角度、多尺度的待檢測目標的仿真圖像。

圖3 用作模板的仿真圖樣例Fig.3 Examples of simulation images used as templates
2 TMSI算法
在TMSI算法中使用OpenCV中的CV_TM_CCOEFF_NORMED模板匹配算法進行仿真圖像與神經網絡特征圖的匹配。在匹配前分別對模板T(i,j)和原圖I(i,j)進行歸一化處理,如式(1)、(2)所示。(wT,hT)和(wI,hI)分別代表模板與原圖的寬、高。原圖與模板在經過式(1)、(2)之后,完成了匹配前的標準化。最后由式(3)得到模板與原圖對應區域的相關系數,以及原圖中與模板最相近的區域。
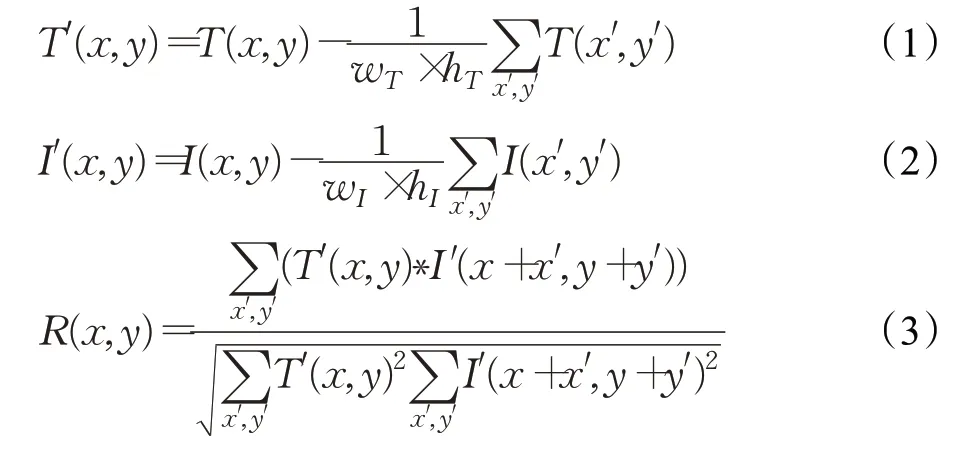
TMSI算法的本質是通過作為模板的仿真圖像來增強特征圖中與小目標相關的特征。TMSI算法的輸入為通過CNN 產生的特征圖與作為模板的仿真圖像,不同類別與角度的仿真圖像用來增強不同的小目標特征。為了避免例如類內顏色多樣性等非關鍵特征對模板的匹配效果產生影響,同時考慮到過多的下采樣層與大步長的卷積層會損失很多的小目標特征,采用Darknet-53中第一個池化層前的特征圖作為TMSI算法的輸入。在訓練的過程中,batch size 設置為8,而Darknet-53 的第一個卷積層有32個卷積核,所以TMSI算法中輸入的特征圖F尺寸為8×32×512×512。由仿真圖像組成的模板庫S為24×1×30×30。在模板匹配的過程中,超參數δ是用來衡量相關系數r的。如果特征圖中某個特定區域的相關系數r大于超參數δ,則認為當前的區域與對應模板類別的小目標最為相近,將該區域利用相關系數r進行直接擴大。在實驗的過程中,設定超參數δ的值為0.6。TMSI的整個結構與殘差結構相似,殘差結構最后的輸出是通過向量拼接得到,而TMSI 最后的結果則是通過輸入與對應擴大區域的相加得到。當特征圖與所有的模板匹配之后,最可能具有小目標的區域得到增強,更多的小目標關鍵特征與信息被用于目標檢測。特征圖與作為模板的仿真圖像進行匹配時,考慮到每個通道的特征圖與仿真圖像的匹配相互獨立,所以利用CPU多核并行處理數據。使用Intel?Xeon?E5-2696 V4@2.20 GHz×50 處理器對數據進行并行處理之后,特征圖F與模板庫S的匹配過程平均需要8.9 s。算法1 中的偽代碼描述了TMSI 算法的過程。其中,I表示匹配算法中的輸入圖;T表示匹配算法中的模板圖;r表示I與T之間的標準協相關系數;(xr,yr)表示當前r所對應的I中的坐標。

3 實驗結果與分析
TMSI算法通過利用仿真圖像作為模板與特征圖進行匹配增加神經網絡可以學習到的遙感影像小目標的關鍵特征。本文算法同時以仿真圖像的形式將光學、物理模型等知識加入到了神經網絡,TMSI-Net 網絡的可解釋性也得到了提高。通過在VEDAI 數據集、加云霧遮擋的VEDAI數據集上的實驗,驗證了TMSI算法的有效性。在實驗過程中分別比較了TMSI-Net、YOLO V3[16]、YOLO V5[17]和SEN[18]模型的表現,并且通過對內部神經元可視化的方式分析了各個模型在不同數據集上表現差異的原因。
3.1 VEDAI驗證TMSI算法實驗
首先,在VEDAI數據集上分別對YOLO V3、YOLO V5、SEN 和TMSI-Net 進行訓練,并進行推理測試。YOLO V3、SEN和TMSI-Net的網絡主體都為Darknet-53,所以對這三個模型訓練時損失(loss)隨著訓練輪次的變化進行比較,共40×125 輪迭代次數。圖4 表示YOLO V3、SEN和TMSI-Net模型在VEDAI數據集上的訓練過程,從中可以看出SEN 和TMSI-Net 的收斂速度都要優于YOLO V3,其中,TMSI-Net模型收斂最快,并且在訓練的過程中震蕩最少。
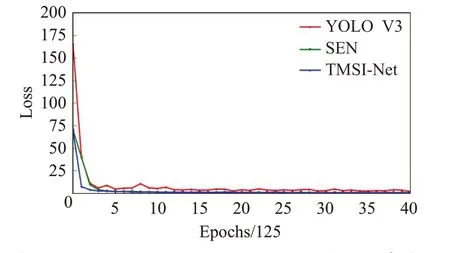
圖4 YOLO V3、SEN和TMSI-Net模型訓練過程1Fig.4 Training process of YOLO V3,SEN and TMSI-Net 1
通過對表1 中所有模型在VEDAI 數據集上的檢測結果比較,可以看到本文提出的TMSI-Net在貨車(van)之外的所有類別的AP以及mAP上都有很大的提高,證明了TMSI算法在遙感影像小目標檢測任務上有很好的表現。并且,TMSI-Net 中加入了仿真圖像作為模板的類的準確率提升得更多,如轎車、卡車、拖拉機和船等。主要原因是加入仿真圖像作為模板進行匹配后,小目標的更多特征被網絡所學習到并用于檢測。然而,對于貨車,雖然也有對應的仿真圖像作為模板加入,檢測準確率卻沒有達到所有模型中的最好,原因可能是該類別的仿真圖像的風格與待檢測的該類小目標相差較大。圖像中的該類別目標稀少也可能是其中的原因。還可以從表1 中觀察到有一些類別雖然沒有加入對應的仿真圖像作為模板,但檢測結果也得到了提升。這個原因可能是網絡可以學習到更多的加入仿真圖像作為模板的類別的小目標特征,沒有加入仿真圖像作為模板的類別的小目標被誤檢為其他目標的可能性更小了。從表1的結果中也可以看出,新提出YOLO V5的檢測準確率要低于YOLO V3,這在某種程度上說明對于遙感影像小目標檢測來說,并不意味著網絡越復雜、層數越多就會有更好的效果。針對某種場景設計、具有特定結構的神經網絡才可以在遙感影像小目標檢測任務中取得更好的效果。總體而言,在加入仿真圖像作為模板之后,網絡對所有類別的小目標的檢測準確率都得到了提高,平均準確率(mAP)更是比其他三個模型中最好的結果高了將近20 個百分點,仿真圖像作為模板加入到神經網絡確實提供了更多有效的小目標特征。
3.2 VEDAI-Cloud驗證TMSI算法實驗
與常規的圖像相比較而言,遙感影像更容易受到云霧遮擋以及光照變化的影響。尤其是考慮到地球表面的66%經常被云霧所遮蓋[19-20],在云霧干擾下準確地檢測遙感影像小目標成為必須面對和解決的難題[21-22]。因此,考慮在VEDAI 數據集的基礎上通過人為地增加云霧干擾構造新的數據集VEDAI-Cloud來進行實驗,檢驗各個模型在云霧干擾下對于遙感影像小目標檢測的效果。數據集中的云霧通過隨機位置、隨機厚薄的方式來加入,使得VEDAI-Cloud 數據集盡可能地接近真實場景中被云霧遮擋之后的效果。通過將YOLO V3、YOLO V5、SEN和TMSI-Net模型在VEDAI-Cloud數據集上進行訓練并測試,來觀察所有模型的表現。在訓練的過程中,依然比較了YOLO V3、SEN 和TMSI-net 的損失曲線,共40×125輪迭代次數。圖5表示YOLO V3、SEN和TMSI-net模型在VEDAI-Cloud數據集上的訓練過程,從中可以看出,TMSI-Net收斂最快、震蕩最少,依然是所有模型中訓練過程中表現最好的模型。
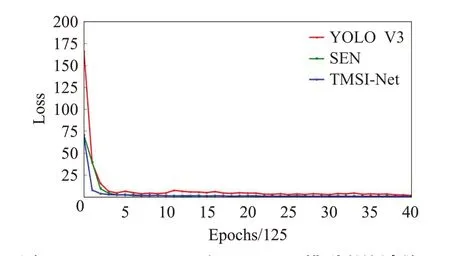
圖5 YOLO V3、SEN和TMSI-Net模型訓練過程2Fig.5 Training process of YOLO V3,SEN and TMSI-Net 2
表2 列出了所有模型在VEDAI-Cloud 數據集上所有類別的準確率。與表1 相比較,除了TMSI-Net 模型之外,所有模型在加入云霧遮擋作為干擾之后的準確率都下降了很多。從表2 中可以看出加入云霧作為干擾之后,基于仿真圖像模板匹配的TMSI-Net表現最好,平均準確率比排名第二的模型SEN 高出了27.2 個百分點。表2中的結果表明,加入了仿真圖像作為模板的對應類別的準確率提升最為明顯,如轎車。相反,其他模型在加云霧遮擋之后,所有類別的檢測準確率都受到了極大的影響,下降很多。在有干擾的時候TMSI 算法依然可以為小目標檢測提供很多有效的關鍵特征。

表1 所有模型在VEDAI數據集上的檢測結果Table 1 Detection results of all models on VEDAI dataset %

表2 所有模型在VEDAI-Cloud數據集上的檢測結果Table 2 Detection results of all models on VEDAI-Cloud dataset %
圖6和圖7是TMSI-Net、SEN、YOLO V3和YOLO V5在VEDAI 和VEDAI-Cloud 數據集上的部分檢測結果比較。圖6 中的小目標背景相對簡單,而圖7 的背景相對復雜、干擾較多。其中圖6 從上到下分別為輸入(VEDAI、VEDAI-Cloud);TMSI-Net方法檢測結果;SEN方法檢測結果;YOLO V3方法檢測結果;YOLO V5方法檢測結果。圖7 從左到右分別為,(a)輸入(VEDAI、VEDAI-Cloud);(b)TMSI-Net方法檢測結果;(c)SEN方法檢測結果;(d)YOLO V3 方法檢測結果;(e)YOLO V5 方法檢測結果。正如圖6、圖7 結果所示,TMSI-Net方法在VEDAI 和VEDAI-Cloud 數據集上都取得了最好的檢測結果,所有的目標都被檢測出來,并做出了正確的分類。SEN 方法在VEDAI 數據集上的結果與TMSI-Net 相似,然而,在加入云霧遮擋作為干擾之后,該方法有大量的漏檢、誤檢。尤其是在圖7背景復雜且有云霧干擾的情況下,SEN方法將大部分的轎車檢測為皮卡,并且將背景中的屋頂以及地面物體識別為轎車和露營車。YOLO V3和YOLO V5方法則有更多的錯誤分類與錯誤檢測,尤其是在加入云霧作為遮擋之后,表現更差。TMSI-Net方法的效果顯著,優于其他方法,觀察每個方法在圖6、圖7中的檢測結果,可以定性地得出結論,在遙感小目標檢測的過程中,缺乏小目標的關鍵特征,受云霧遮擋干擾以及復雜背景是很多方法誤檢、漏檢的主要原因。

圖7 所有模型的檢測結果比較2Fig.7 Comparison of detection results of all models 2
圖8 和圖9 是TMSI-Net、SEN、YOLO V3 和YOLO V5 在VEDAI 數據集上的高清局部檢測結果比較圖。其中,圖8 是圖6 檢測結果的高清局部顯示。在圖8 左下角、圖9 右下角都標明了該檢測結果所對應的方法。從圖8、圖9中高分辨率局部圖像的檢測結果比較來看,TMSI 算法無論是在目標的定位方面,還是目標類別的識別方面都取得了最好的效果,而其他算法則有較多的錯檢、漏檢以及誤檢結果。圖8 與圖9 中的標記是各個算法在同一幅遙感圖像上的檢測結果,該標記包括所檢測出的目標的類別,用英文標簽標注,以及該目標所對應的位置,用與該目標標簽同一顏色的方框進行標記。TMSI-Net在圖8與圖9中的標簽標記與真值相同,方框位置也與真值非常接近。

圖6 所有模型的檢測結果比較1Fig.6 Comparison of detection results of all models 1

圖8 所有模型的高清局部檢測結果比較1Fig.8 Comparison of high-definition local detection results of all models 1

圖9 所有模型的高清局部檢測結果比較2Fig.9 Comparison of high-definition local detection results of all models 2
從圖8 結果比較來看,YOLO V3 算法以及YOLO V5 算法在轎車(Car)與皮卡(Pickup)的類別識別方面存在較大誤差。無論是小目標類別還是小目標位置,TMSI-Net 與SEN 方法都在圖8 中有優異的檢測表現。在圖9中,所有算法都實現了對道路上的兩輛轎車的正確檢測。而對于圖像正中央的兩輛卡車(Truck)目標,除了TMSI算法之外,其他算法在識別、定位方面都有很大的誤差。SEN方法錯誤地將卡車頭識別為船與轎車,并且僅僅將卡車廂識別為卡車,在目標位置方面也做出了錯誤的標記。YOLO V3、YOLO V5 方法同樣在卡車目標類別判斷與位置標記方面都有很大偏差,主要表現為不能將卡車目標的車頭與車廂作為一個整體進行檢測。
圖10 是針對圖6 中的具體遙感影像在TMSI 算法作用前后的特征圖可視化結果,該遙感影像來自于VEDAI-Cloud 數據集,即加入云霧干擾之后的遙感圖像。從圖10 中可以發現,在TMSI 算法作用之前,所得到的特征圖受云霧遮擋嚴重,有的小目標直接消失在了圖像中。而在加入TMSI 算法之后,整個圖像中的云霧與圖像本身之間的差異得到放大,小目標所處位置的云霧噪聲更加清晰,淹沒在云霧噪聲中的小目標也重新凸顯。由此可見,TMSI 算法中用于匹配的仿真圖像與特征圖進行模板匹配算法之后,對于云霧遮擋情況下小目標的檢測可以提供更多的幾何等特征,最后得到更好的檢測結果。

圖10 TMSI算法應用前后的特征圖可視化比較Fig.10 Visualization comparison of feature map before and after TMSI algorithm application
在圖11 中通過可視化的方式比較了TMSI-Net、YOLO V3以及SEN方法的第二個卷積層通道0的特征圖,第一列是在VEDAI數據集下的,第二列是在VEDAICloud 數據集下的,從上到下分別是TMSI-Net、SEN、YOLO V3。這三個方法的網絡主體都是Darknet-53,所以它們的特征圖具有可比性。如圖11 所示,可以觀察到TMSI-Net 方法的特征圖是三個模型在VEDAI、VEDAI-Cloud 數據集上的所有特征圖中包含小目標特征與信息最多的特征圖。將仿真圖像作為模板加入到神經網絡之后,目標與背景之的差異得到放大,目標可以被更好地檢測到。YOLO V3 與SEN 方法提取到的小目標的關鍵特征在加入云霧作為干擾之后急劇減少,不利于小目標檢測。與之相反,TMSI-Net 在云霧的干擾之下依然可以提取到足夠多的有效小目標特征用于檢測。從圖11中的定性比較中可以看出仿真圖像作為模板的有效性,以及TMSI-Net 方法在遙感影像小目標檢測任務中的優越表現。

圖11 TMSI-Net、SEN和YOLO V3方法的可視化結果比較Fig.11 Comparison of visualization results among TMSI-Net,SEN and YOLO V3 methods
4 結論
針對遙感影像小目標檢測時存在提取到的特征不足、檢測效果差等問題,本文提出了一種將仿真圖像作為模板加入到神經網絡的方法,可以使網絡學習到更多的小目標特征,提高遙感影像小目標檢測的準確率。并且,將仿真圖像加入到神經網絡之后,也提高了模型在面對具有云霧干擾的遙感影像小目標時的檢測準確率。在VEDAI、VEDAI-Cloud 數據集上的實驗結果都證明了TMSI算法的有效性與穩定性。通過對神經網絡內部神經元可視化的過程,可以清晰地看到TMSI-Net學習到了更多的小目標特征,并且減弱了背景的干擾。仿真圖像是通過明確的物理光學模型生成的,在物理性質上是可以解釋的。當仿真圖像作為模板加入到神經網絡時,像是一種先驗知識或是常識,指導網絡的學習與推理,不僅提高了網絡的準確率,也提高了網絡的可解釋性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
